
De novato a experto: Noticias animadas utilizando MQL5 (IV) Análisis de mercado sobre modelos de IA alojados localmente

Contenido:
- Introducción
- Descripción general
- Configuración y alojamiento local de un modelo de IA
- Integración de información de IA en MQL5: Mejora de News Headline EA
- Probando la integración
- Conclusión
- Lecciones clave
- Archivos adjuntos
Introducción
En este articulo, exploramos cómo aprovechar los modelos de IA de código abierto para mejorar nuestras herramientas de negociación algorítmica; específicamente, cómo ampliar el Asesor Experto (EA) de titulares de noticias con una franja AI Insights. El objetivo es ayudar a los recién llegados a encontrar un buen punto de partida. ¿Quién sabe? Hoy puede que estés integrando un modelo; mañana puede que estés construyendo uno. Pero todo comienza por comprender los cimientos que sentaron quienes nos precedieron.
No podemos hablar de los avances modernos sin mencionar la inteligencia artificial y su creciente influencia en las tareas humanas. En lo que respecta al trading algorítmico, el debate cobra aún más relevancia: el trading ya se basa en números y automatización, lo que convierte a la IA en una opción natural en comparación con otras áreas que todavía requieren un cambio desde los procesos manuales.
Si bien los modelos de IA se han convertido en herramientas poderosas en diversos campos, no todos tienen los recursos o la experiencia para construir sus propios modelos debido a la complejidad que implica el desarrollo de sistemas completamente funcionales. Afortunadamente, el auge de las iniciativas de código abierto ha hecho posible acceder a modelos preentrenados y beneficiarse de ellos sin coste alguno. Estas iniciativas impulsadas por la comunidad ofrecen un punto de partida práctico para muchos desarrolladores y aficionados.
Dicho esto, los modelos premium suelen ofrecer mayores prestaciones debido al extenso trabajo invertido en ellos. Aun así, los modelos de código abierto son un valioso punto de partida, especialmente para aquellos que buscan integrar la IA sin reinventar la rueda.
En la discusión anterior, nos centramos en Indicator Insights. Hoy veremos cómo aprovechar la IA de código abierto para el trading algorítmico alojando nosotros mismos un modelo de lenguaje cuantizado e integrándolo directamente en un asesor experto de MQL5. En la siguiente sección, comenzaremos con una breve introducción a las funciones de llama.cpp (el motor de inferencia ligero) y un modelo GGUF de 4 bits (el «cerebro» comprimido); a continuación, veremos cómo descargar y preparar el modelo, configurar un servidor de inferencia local basado en Python con FastAPI y, por último, integrarlo en el EA News Headline para crear una franja de AI Insights.
En el proceso, destacaremos las decisiones clave, solucionaremos los obstáculos comunes y mostraremos una prueba sencilla, todo ello diseñado para ofrecerle un plan integral y claro para incorporar comentarios de IA en tiempo real a su flujo de trabajo de negociación.
Descripción general
Para este proyecto, utilizamos una CPU Intel Core i7-8550U de 64 bits (1,80–1,99 GHz) con 8 GB de RAM. Dadas estas limitaciones de hardware, elegimos un modelo GGUF ligero cuantizado de 4 bits —específicamente stablelm-zephyr-3b.Q5_K_M.gguf— para garantizar un rendimiento eficiente de carga e inferencia en nuestro sistema. Más adelante, compartiré las especificaciones de hardware recomendadas para proyectos de esta naturaleza, junto con los planes de actualización para admitir modelos de IA más grandes y exigentes en el futuro.
Antes de continuar, es importante familiarizarnos con los componentes clave y los requisitos de hardware necesarios para que este proyecto funcione sin problemas. Con fines educativos, trabajamos con especificaciones modestas, pero si tiene acceso a hardware más potente, le animamos a que lo aproveche. También proporcionaré orientación sobre los modelos adecuados y las especificaciones recomendadas para configuraciones de mayor rendimiento.
Comprender Hugging Face
Hugging Face es una plataforma que alberga miles de modelos de aprendizaje automático preentrenados (NLP, visión, voz, etc.), junto con conjuntos de datos, métricas de evaluación y herramientas para desarrolladores, a los que se puede acceder a través de la web o de la biblioteca de Python huggingface_hub. Simplifica el descubrimiento de modelos, el control de versiones y la gestión de archivos grandes (Git LFS), y ofrece opciones de autoalojamiento gratuitas y una API de inferencia gestionada para implementaciones escalables. Con una documentación completa, soporte de la comunidad e integración perfecta con marcos de trabajo como PyTorch y TensorFlow, Hugging Face permite a cualquier persona encontrar, descargar y ejecutar rápidamente modelos de IA de vanguardia en sus aplicaciones.
Requisitos de hardware
Para un modelo GGUF de 4 bits y 3 B de parámetros que se ejecuta en llama-cpp-python, necesitará al menos:
- CPU: 4 núcleos/8 hilos (por ejemplo, Intel i5/i7 o AMD Ryzen 5/7) para inferencia por token en menos de un segundo.
- RAM: ~6–8 GB libres para cargar el modelo cuantizado de ~1,9 GB, más la memoria de trabajo.
- Almacenamiento: SSD con ≥3 GB libres para la caché del modelo (~1,9 GB) y la sobrecarga del sistema operativo.
- Red: Llamadas a localhost; no se requiere ancho de banda externo.
Actualizando las especificaciones
- Modelos más grandes: pase a modelos de 7B o 13B parámetros (cuantizados), pero planifique para CPU o GPU de 12 GB o más, o incluso más potentes.
- Aceleración por GPU: utilice GPU NVIDIA con CUDA/cuBLAS y el backend de GPU llama-cpp o marcos de trabajo como Triton/ONNX para obtener aceleraciones de hasta 10 veces.
- Escalado horizontal: utilice contenedores (Docker) o despliegue en clústeres de Kubernetes para equilibrar la carga de múltiples pods de inferencia; ideal para configuraciones de alto rendimiento o multiusuario.
- GPU/TPU en la nube: Cambie a instancias de AWS/GCP/Azure (por ejemplo, A10G, A100) para modelos con más de 13 parámetros B o acuerdos de nivel de servicio (SLA) en tiempo real.
Requisitos de software:
Nuestro flujo de trabajo utiliza varios entornos y shells complementarios para optimizar el desarrollo y las pruebas:
- Git Bash es nuestra herramienta preferida para descargar código y gestionarlo mediante control de versiones: úsala para clonar el repositorio de Hugging Face con git, ejecutar el script `download_model.py` de Python (una vez que tu versión preferida de Python esté en la ruta PATH) e incluso poner en marcha pruebas rápidas de validación si prefieres la sintaxis de Bash. Podemos usar el Símbolo del sistema de Windows u otros intérpretes de comandos para este mismo proceso.
- MSYS2 nos ofrece una capa POSIX completa en Windows; una vez que el modelo esté listo, podemos seguir en MSYS2 para ejecutar curl (o httpie) en http://localhost:8000/insights y comprobar que nuestro punto final de FastAPI está activo y devuelve datos JSON.
- En la línea de comandos de Anaconda creamos y activamos nuestro entorno Conda de ai-server (python=3.12), instalamos mediante conda los paquetes llama-cpp-python, FastAPI y Uvicorn, y, por último, ejecutamos el comando `uvicorn server:app --reload --port 8000`.
A continuación se muestra un diagrama de bloques que sirve de guía para los procesos que trataremos en este debate.
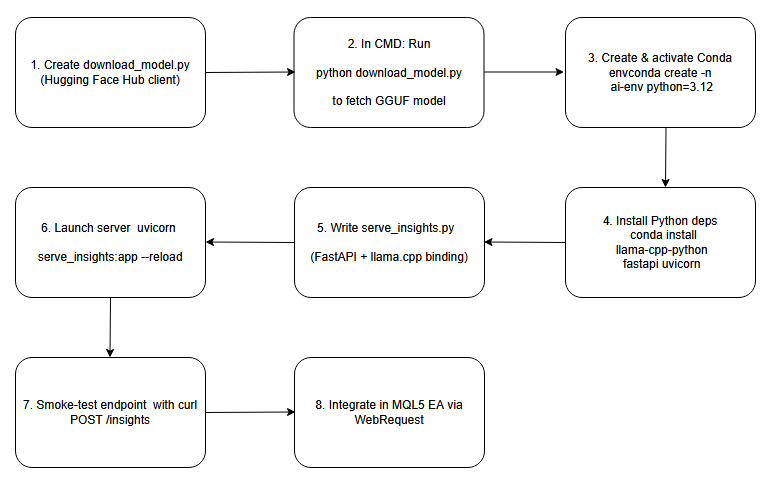
Diagrama de flujo.
Configuración y alojamiento local de un modelo de IA
Paso 1: Crear el script de descarga
Para empezar, escribimos un pequeño script de Python que utiliza el cliente Hugging Face Hub. En este script, especificamos el nombre del repositorio (por ejemplo, «TheBloke/stablelm‑zephyr‑3b.Q5_K_M.gguf») y llamamos a hf_hub_download() para descargar el archivo GGUF cuantificado a nuestra caché local. Al imprimir la ruta del archivo devuelto, obtenemos una referencia fiable y legible por máquina de la ubicación actual del modelo en el disco. Este enfoque automatiza la descarga y garantiza que se conozca la ubicación exacta de la caché, lo cual es fundamental para configurar el código de inferencia posterior sin tener que especificar de forma rígida directorios impredecibles.
# download_model.py from huggingface_hub import hf_hub_download # Download the public 4-bit GGUF model; no Hugging Face account required model_path = hf_hub_download( repo_id = "TheBloke/stablelm-zephyr-3b-GGUF", filename = "stablelm-zephyr-3b.Q5_K_M.gguf", repo_type = "model" ) print("Downloaded to:", model_path)
Paso 2: Ejecutar el script de descarga
A continuación, abre una ventana del símbolo del sistema de Windows y navega hasta el directorio que contiene tu script de descarga (por ejemplo, download_model.py). Al ejecutar el archivo `download_model.py` en Python, el cliente de Hugging Face se conectará a través de HTTPS, descargará los pesos de GGUF en su caché y mostrará la ruta completa (algo así como `C:\Users\You\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b.Q5_K_M\…\stablelm-zephyr-3b. Q5_K_M.gguf). Ver esa ruta confirma que el archivo está en su sitio y te permite copiarlo directamente en tu configuración de inferencia.
Línea de comandos en Windows:
python download_model.py
Ruta al modelo descargado:
Descargado en: C:\Users\BTA24\.cache\huggingface\hub\…\stablelm-zephyr-3b.Q5_K_M.gguf
Paso 3: Crear y activar un entorno Conda
conda create -n ai-env python=3.12 -y conda activate ai-env
Paso 4: Instalar las dependencias de Python
Con el entorno ai-server activo, utiliza pip install llama-cpp-python fastapi uvicorn (o conda install -c conda-forge llama-cpp-python, si lo prefieres) para instalar las bibliotecas principales. la biblioteca/binding llama-cpp-python envuelve el motor de inferencia en C++ de alto rendimiento necesario para cargar y ejecutar tu modelo GGUF, mientras que FastAPI y Uvicorn proporcionan un marco web asíncrono y un servidor (respectivamente) para exponer puntos de acceso que permiten generar información útil. En conjunto, estos paquetes constituyen la columna vertebral de tu servicio local de inferencia de IA.
conda install -c conda-forge llama-cpp-python fastapi uvicorn -y
Paso 5: Escribir el script del servidor FastAPI
En la carpeta de tu proyecto, crea un nuevo archivo (por ejemplo, server.py) e importa FastAPI y Llama desde llama_cpp. En el ámbito global, crea un objeto de la clase Llama con la ruta al archivo GGUF que has descargado. A continuación, define un punto final POST en /insights que acepte un cuerpo JSON (que contenga una cadena «prompt»), llame a llm.create() o a una función equivalente para generar texto y devuelva una respuesta JSON que contenga un campo «insight». Con solo unas pocas líneas, ya tienes un servicio de IA RESTful listo para recibir solicitudes y enviar los resultados del modelo.
# serve_insights.py from fastapi import FastAPI, Request from llama_cpp import Llama MODEL_PATH = r"C:\Users\BTA24\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b-GGUF\snapshots\<snapshot-id>\stablelm-zephyr-3b.Q5_K_M.gguf" llm = Llama(model_path=MODEL_PATH, n_threads=4, n_ctx=512) app = FastAPI() @app.post("/insights") async def insights(req: Request): data = await req.json() prompt = data.get("prompt", "") out = llm(prompt, max_tokens=64) text = out["choices"][0]["text"].strip() return {"insight": text}
Paso 6: Iniciar el servidor de inferencia
Sin salir del símbolo del sistema de Anaconda, ve al directorio de tu proyecto e inicia Uvicorn, indicándole que se conecte a la aplicación FastAPI. Activa la recarga automática para detectar los cambios en el script sobre la marcha y escucha en el puerto 8000 las solicitudes entrantes.
cd a la carpeta donde se encuentra server.py y ejecuta:
cd "C:\Users\YOUR_COMPUTER_NAME\PATH_TO_YOUR python serve insights file"
Una vez dentro, ejecutamos el servidor:
uvicorn serve_insights:app --host 0.0.0.0 --port 8000 --reload
Paso 7: Prueba básica de funcionamiento del endpoint
Desde cualquier terminal, envía una sencilla solicitud POST a http://localhost:8000/insights con una consulta de prueba en formato JSON. Comprueba que el servidor responda con un JSON válido que contenga el campo «insight».
curl -X POST http://localhost:8000/insights \ -H "Content-Type: application/json" \ -d '{"prompt":"One-sentence FX signal for EUR/USD."}'
Una respuesta correcta tendrá el siguiente formato:
{"insight":"Be mindful of daily open volatility…"}
Paso 8: Integrarlo en tu EA de MQL5
Ahora que el servidor de IA ya está en funcionamiento y verificado, es hora de volver a nuestro asesor experto de MQL5 y retomar el trabajo donde lo dejamos. Integraremos el punto final de AI-Insights en nuestro EA añadiendo una franja específica «AI Insights» al gráfico. Una vez integrado, tu EA llamará al punto final local /insights en el intervalo configurado, analizará el JSON devuelto e incorporará el texto resultante al mismo mecanismo de desplazamiento fluido que ya utilizas para las noticias y los indicadores. En la siguiente sección, analizaremos paso a paso la integración completa del código para crear una herramienta de negociación integral mejorada con IA.
Integración de información de IA en MQL5: Mejora de News Headline EA
Suponiendo que ya has leído nuestro artículo anterior, ahora nos centraremos en integrar únicamente la nueva función AI-Insights en el EA. En los siguientes pasos, voy a señalar y explicar cada modificación del código necesaria —sin tocar el resto del EA— y, al final de este análisis, proporcionaré el código completo y actualizado del EA.
1. Ampliación de los parámetros de entrada
En primer lugar, añadimos tres nuevos parámetros de entrada junto con los ya existentes. Incluimos un valor booleano para poder activar o desactivar la función de análisis de IA a voluntad, una cadena donde introducimos la URL de nuestro punto final de FastAPI (u otro de IA) y un número entero que establece cuántos segundos deben transcurrir entre llamadas POST sucesivas. Con estas opciones implementadas, podemos experimentar de forma interactiva: activar o desactivar la franja, apuntar a diferentes servidores o aumentar o disminuir la frecuencia de actualización sin tocar el código principal.
//--- 1) USER INPUTS ------------------------------------------------ input bool ShowAIInsights = true; input string InpAIInsightsURL = "http://127.0.0.1:8000/insights"; input int InpAIInsightsReloadSec = 60; // seconds between requests
2. Declaración de variables globales compartidas
A continuación, introducimos variables globales para almacenar y gestionar nuestros datos de IA. Mantenemos el texto de información actual en una sola cadena y registramos su desplazamiento horizontal en un número entero para poder desplazarlo en cada ciclo. Para evitar solicitudes superpuestas, añadimos un indicador que señala cuándo una solicitud web está en curso y almacenamos la marca de tiempo de nuestra última obtención exitosa. Estas variables globales garantizan que siempre tengamos algo que dibujar, sepamos exactamente cuándo enviar la siguiente llamada y evitemos las evitar solicitudes HTTP simultáneas.
//--- 3) GLOBALS ----------------------------------------------------- string latestAIInsight = "AI insights coming soon…"; int offAI; // scroll offset bool aiRequestInProgress = false; // prevent concurrent POSTs datetime lastAIInsightTime = 0; // last successful fetch time
3. Construyendo FetchAIInsights()
Encapsulamos toda nuestra lógica HTTP en una sola función. En el interior, primero comprobamos nuestro interruptor y tiempo de espera: si el carril de IA está desactivado, o si hemos realizado una solicitud demasiado recientemente (o si una solicitud anterior aún está pendiente), simplemente regresamos. De lo contrario, creamos una carga útil JSON mínima, que tal vez incluya el símbolo actual, y enviamos una solicitud WebRequest("POST"). En caso de éxito, extraemos el campo "insight" de la respuesta JSON y actualizamos nuestro texto y marca de tiempo globales. Si algo sale mal, mantenemos intacto el análisis anterior, por lo que la franja de desplazamiento nunca se queda en blanco.
void FetchAIInsights() { if(!ShowAIInsights || aiRequestInProgress) return; datetime now = TimeTradeServer(); if(now < lastAIInsightTime + InpAIInsightsReloadSec) return; aiRequestInProgress = true; string hdrs = "Content-Type: application/json\r\n"; string body = "{\"prompt\":\"Concise trading insight for " + Symbol() + "\"}"; uchar req[], resp[]; string hdr; StringToCharArray(body, req); int res = WebRequest("POST", InpAIInsightsURL, hdrs, 5000, req, resp, hdr); if(res > 0) { string js = CharArrayToString(resp,0,WHOLE_ARRAY); int p = StringFind(js, "\"insight\":"); if(p >= 0) { int start = StringFind(js, "\"", p+10) + 1; int end = StringFind(js, "\"", start); if(start>0 && end>start) latestAIInsight = StringSubstr(js, start, end-start); } lastAIInsightTime = now; } aiRequestInProgress = false; }
4. Inicialización del canvas en OnInit()
En nuestra rutina de inicialización, después de configurar todos los demás lienzos, también creamos el lienzo de IA. Le damos las mismas dimensiones y un fondo semitransparente, y luego lo colocamos justo debajo de las franjas existentes. Antes de que lleguen los datos, dibujamos un texto descriptivo ("Próximamente, información de IA...") para que el gráfico tenga un aspecto profesional. Finalmente, llamamos a FetchAIInsights() una sola vez de inmediato; esto garantiza que, incluso si comenzamos a mitad de sesión, el contenido real aparezca tan pronto como se complete la primera llamada de red.
int OnInit() { // … existing init … // AI Insights lane if(ShowAIInsights) { aiCanvas.CreateBitmapLabel("AiC", 0, 0, canvW, lineH, COLOR_FORMAT_ARGB_RAW); aiCanvas.TransparentLevelSet(120); offAI = canvW; SetCanvas("AiC", InpPositionTop, InpTopOffset + (InpSeparateLanes ? 8 : 5) * lineH); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); aiCanvas.Update(true); // initial fetch FetchAIInsights(); } EventSetMillisecondTimer(InpTimerMs); return INIT_SUCCEEDED; }
5. Actualización y desplazamiento en OnTimer()
Con cada tic del temporizador, ya estamos actualizando los eventos, las noticias y los indicadores. Justo después de eso, insertamos nuestros pasos de IA: llamamos a FetchAIInsights() (que no hace nada si no ha pasado el tiempo de espera), borramos el lienzo de IA, dibujamos la última información en su desplazamiento actual, decrementamos ese desplazamiento para un desplazamiento suave hacia la izquierda, lo envolvemos cuando sale de la pantalla y, finalmente, llamamos a Update(true) para aplicar los cambios de inmediato. El resultado es un mensaje de IA con un desplazamiento fluido que se actualiza solo cuando lo permitimos, combinando una animación fluida con un uso controlado de la red.
void OnTimer() { // … existing redraw for events/news/indicators … // fetch & draw AI lane FetchAIInsights(); if(ShowAIInsights) { aiCanvas.Erase(ARGB(120,0,0,0)); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); offAI -= InpAIInsightsSpeed; if(offAI + aiCanvas.TextWidth(latestAIInsight) < -20) offAI = canvW; aiCanvas.Update(true); } }
6. Limpieza en OnDeinit()
Cuando se descarga nuestro asesor experto, limpiamos los recursos correspondientes. Detenemos el temporizador, destruimos y eliminamos el lienzo de IA (solo si existe) y, a continuación, ejecutamos nuestro proceso de limpieza habitual para los demás lienzos, matrices de eventos y objetos dinámicos. Esto garantiza que no dejemos rastro alguno, por lo que recargar o volver a desplegar el EA siempre comienza desde cero.
void OnDeinit(const int reason) { EventKillTimer(); // … existing cleanup … if(ShowAIInsights) { aiCanvas.Destroy(); ObjectDelete(0, "AiC"); } }
Probando la integración
Ahora que hemos completado la integración, carguemos nuestro Asesor Experto actualizado en MetaTrader 5 y observemos su rendimiento en tiempo real. Asegúrate de mantener el servidor de IA funcionando en segundo plano; aún estoy explorando si podemos iniciarlo mediante programación desde el propio EA. En la captura de pantalla que aparece a continuación, verá la nueva columna de Análisis de IA situada debajo de las demás franjas, que muestra texto con información relevante en tiempo real.
Puedes modificar fácilmente su esquema de colores en el código; para esta demostración, lo dejamos con la configuración predeterminada. También notarás alguna pausa breve y ocasional al desplazarte, un efecto secundario de nuestro sistema actual de procesamiento de datos, que perfeccionaremos en futuras revisiones. Ahora que la función de IA integral está en pleno funcionamiento, pasaremos a analizar la implementación del lado del servidor para comprender exactamente cómo el sistema de backend genera estos análisis.

News Headline EA con análisis de mercado basados en IA a partir de un modelo alojado localmente
El fragmento que aparece a continuación se ha extraído directamente del Anaconda Prompt, donde Uvicorn gestiona nuestro punto final /insights. Al ver estos registros, nos damos cuenta de tres cosas
- El modelo se ha cargado correctamente, por lo que el motor de inferencia está listo.
- Uvicorn está en ejecución y a la escucha, por lo que el servidor HTTP está activo.
- La solicitud WebRequest de nuestro EA se ha enviado correctamente al servidor, lo que ha activado un nuevo ciclo de inferencia.
A continuación, he capturado cinco de esos ciclos de inferencia durante las pruebas; cada uno de ellos corresponde a una única solicitud POST del EA. Tras este fragmento de código, te explicaré uno de estos ciclos con detalle para que puedas ver exactamente qué ocurre entre bastidores.
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 83.42 ms / 64 runs ( 1.30 ms per token, 767.19 tokens per second) llama_print_timings: prompt eval time = 1890.97 ms / 6 tokens ( 315.16 ms per token, 3.17 tokens per second) llama_print_timings: eval time = 32868.44 ms / 63 runs ( 521.72 ms per token, 1.92 tokens per second) llama_print_timings: total time = 35799.69 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 51.40 ms / 64 runs ( 0.80 ms per token, 1245.21 tokens per second) llama_print_timings: prompt eval time = 1546.64 ms / 4 tokens ( 386.66 ms per token, 2.59 tokens per second) llama_print_timings: eval time = 29878.89 ms / 63 runs ( 474.27 ms per token, 2.11 tokens per second) llama_print_timings: total time = 32815.26 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 65.92 ms / 64 runs ( 1.03 ms per token, 970.80 tokens per second) llama_print_timings: prompt eval time = 1841.83 ms / 6 tokens ( 306.97 ms per token, 3.26 tokens per second) llama_print_timings: eval time = 31295.30 ms / 63 runs ( 496.75 ms per token, 2.01 tokens per second) llama_print_timings: total time = 34146.43 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 55.34 ms / 64 runs ( 0.86 ms per token, 1156.42 tokens per second) llama_print_timings: prompt eval time = 1663.61 ms / 4 tokens ( 415.90 ms per token, 2.40 tokens per second) llama_print_timings: eval time = 29311.62 ms / 63 runs ( 465.26 ms per token, 2.15 tokens per second) llama_print_timings: total time = 31952.19 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
Comprender el funcionamiento del Modelo y de WebRequest en Anaconda Prompt:
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
Cuando tu servidor FastAPI-Uvicorn carga el modelo GGUF, llama-cpp indica un «tiempo de carga» de unos 206 segundos; ese es el coste único que supone leer e inicializar toda la red cuantizada en la memoria. A partir de ahí, cada solicitud HTTP POST recibida en /insights sigue más o menos esta secuencia:
Evaluación del prompt (prompt eval time)
Aquí, llama-cpp procesa los primeros tokens de tu mensaje a través de la pila de transformadores del modelo para "preparar" la generación. En este registro, se tardó un total de 1,49 s en procesar 4 tokens, lo que equivale a unos 372 ms por token.
Generación de tokens (tiempo de evaluación + tiempo de muestreo)
- Por cada token subsiguiente que genera, la biblioteca hace dos cosas:
- Eval: calcular el paso hacia adelante del transformador (≈ 469 ms por token, es decir, ~2,13 tokens/s).
- Sample: aplicar muestreo nucleus/top-k/etc. para seleccionar el siguiente token (≈ 0,91 ms por token).
- En tu ejecución, generar 63 tokens tomó aproximadamente 29,6 s para las evaluaciones más 58 ms para muestrearlos todos.
Latencia total (tiempo total)
Sumando la evaluación de la solicitud, todas las evaluaciones de tokens y el muestreo, se obtienen 31,98 s desde el momento en que el modelo comenzó a calcular hasta que devolvió el texto final.
Una vez que esa generación se completa, Uvicorn registra algo como:
INFO: 127.0.0.1:52770 - "POST /insights HTTP/1.1" 200 OK
lo que significa que el servidor recibió la llamada WebRequest de tu EA («POST», «http://127.0.0.1:8000/insights», …), la procesó y devolvió una respuesta JSON con código de estado 200 que contiene tu «insight».
Por último, la línea i indica que llama-cpp ha reconocido una secuencia de tokens repetida (un prefijo) en su caché y ha evitado volver a calcular esas capas, lo que ha acelerado ligeramente la generación.
Llama.generate: prefix-match hit
Durante las pruebas, noté algunas pausas ocasionales en el desplazamiento por carril del EA. Resultó que llamar a FetchAIInsights() directamente en el bucle del temporizador provocaba que la solicitud WebRequest del EA se bloqueara —esperando hasta que se agotara el tiempo de espera— mientras Uvicorn ejecutaba todo el proceso de evaluación del modelo, generación de tokens y muestreo (unos 32 segundos) antes de devolver el JSON.
Al separar por completo la lógica de desplazamiento de nuestras llamadas HTTP —dibujando y desplazando el texto cada 20 ms antes de invocar FetchAIInsights()—, la banda de la interfaz de usuario puede seguir animándose sin interrupciones. Mientras tanto, la inferencia de gran volumen se ejecuta en el servidor, y solo cuando finaliza actualizamos latestAIInsight con la nueva respuesta.
Conclusión
En conclusión, este ejercicio ha demostrado lo versátil que puede ser MQL5 cuando se combina con servicios externos, ya sea para obtener eventos del calendario económico en tiempo real y titulares de Alpha Vantage o para enriquecer los gráficos con «notas» generadas por IA a partir de un modelo 4-bit alojado en un servidor propio. Aunque estos análisis basados en la inteligencia artificial no sustituyen a los datos en tiempo real ni a un sistema de negociación diseñado por profesionales, aportan una capa adicional de comentarios cualitativos o sugerencias para la reflexión que pueden dar lugar a nuevas ideas.
A lo largo del proceso, nos hemos familiarizado con Hugging Face y hemos aprendido a utilizar MSYS2, Git Bash y Miniconda para descargar modelos, configurar servidores y gestionar entornos aislados. Hemos combinado dos lenguajes —Python para la inferencia de modelos y FastAPI, y MQL5 para la integración en los gráficos—, ampliando así nuestro conjunto de herramientas de programación y demostrando cómo pueden colaborar ecosistemas tan diversos. Te animamos a que pruebes y compartas tus opiniones en la sección de comentarios.
De cara al futuro, prueba a introducir series de precios o valores de indicadores de MetaTrader 5 en tiempo real en tus indicaciones de IA para mejorar el contexto y la relevancia. Puedes probar diferentes formatos cuantizados, automatizar implementaciones sin tiempo de inactividad o distribuir la inferencia entre varios nodos. Pasarse a un modelo más potente y mejorar el hardware te permitirá obtener información más detallada y matizada; sin embargo, incluso las configuraciones más modestas pueden ofrecer herramientas de negociación potentes e interactivas. El campo de la negociación algorítmica y la IA autohospedada sigue estando por explorar; tu próximo avance podría redefinir la forma en que los operadores interactúan con los mercados.
A continuación encontrará los archivos de apoyo adjuntos. También he preparado una tabla con una breve descripción de cada archivo para ayudarte a entender para qué sirven.
Lecciones clave
| Lección | Descripción |
|---|---|
| Aislamiento del entorno | Utiliza Conda o virtualenv para crear entornos Python aislados, manteniendo separadas y reproducibles las dependencias como FastAPI y llama‑cpp‑python. |
| Almacenamiento en caché local | Descarga y almacena en caché los archivos de modelos GGUF de gran tamaño una sola vez a través del cliente de Hugging Face Hub para evitar transferencias de red repetidas y acelerar el inicio del servidor. |
| Limitación de velocidad | Aplica un limitador de intervalos mínimos (por ejemplo, 300 s) a las solicitudes de IA, para que la EA no sature el servidor ni genere una carga de inferencia excesiva. |
| Análisis sintáctico resistente a errores | Incorpora la decodificación de JSON en el manejo de errores y extrae únicamente el primer objeto válido, protegiendo al EA de respuestas mal formadas o con datos sobrantes. |
| Doble búfer de Canvas | Utiliza Canvas.Update(true) después de dibujar cada ciclo para aplicar los cambios, evitando así el parpadeo y garantizando animaciones fluidas en los gráficos. |
| Bucles controlados por temporizador | Controla todo el desplazamiento y la actualización de datos mediante un temporizador de un solo milisegundo (por ejemplo, 20 ms) para equilibrar la fluidez de la animación con la carga de la CPU. |
| Integración de WebRequest | Utiliza la función WebRequest de MQL5 para enviar un POST con datos JSON al servidor de IA local y obtener información; no olvides añadir la URL a la lista de sitios permitidos en las opciones del terminal. |
| Aleatorización en pro de la diversidad | Varía las indicaciones o selecciona aleatoriamente pares de divisas para cada solicitud de IA con el fin de generar información de trading variada y no repetitiva. |
| Limpieza de recursos | En OnDeinit, destruye todos los objetos Canvas, elimina las matrices dinámicas y desactiva los temporizadores para evitar fugas de memoria y objetos de gráfico huérfanos. |
| Diseño modular | Organiza el código en funciones claras —ReloadEvents, FetchAlphaVantageNews, FetchAIInsights, DrawLane— para mejorar la legibilidad y facilitar el mantenimiento. |
| Flexibilidad de los entornos de línea de comandos | Utiliza Git Bash para Git y la creación de scripts, MSYS2 para herramientas POSIX y compilaciones, Conda Prompt para entornos Python y CMD para tareas puntuales rápidas. |
| Alojamiento de modelos cuantificados | Ejecuta un modelo GGUF cuantificado de forma local para reducir el consumo de memoria y la latencia de inferencia en comparación con los pesos de precisión completa. |
| Separación entre servidor y cliente | Mantén los cálculos intensivos en el servidor FastAPI/Uvicorn y deja que el asesor experto (EA) siga siendo ligero, encargándose únicamente de las actualizaciones de la interfaz de usuario y de las solicitudes HTTP. |
| Renderizado desacoplado | Realiza siempre las operaciones de desplazamiento y dibujo antes de llamar a las funciones de red, para garantizar la capacidad de respuesta de la interfaz de usuario incluso durante las solicitudes largas. |
| Ingeniería de prompts | Redacta indicaciones JSON concisas y específicas —como «Análisis del EURUSD para hoy»— para reducir al mínimo el tiempo de evaluación de la indicación y centrar los resultados del modelo. |
| Estrategias de muestreo | Ajusta los parámetros de muestreo (top-k, top-p, temperatura) en tu aplicación FastAPI para lograr un equilibrio entre la creatividad y la coherencia en los resultados generados. |
| Puntos finales asíncronos | Utiliza los controladores «async def» de FastAPI para que Uvicorn pueda gestionar solicitudes de EA simultáneas sin bloquearse ante inferencias de larga duración. |
| Registro y observabilidad | Configura tanto el EA como el servidor con marcas de tiempo y niveles de registro —por ejemplo, llama_print_timings y los mensajes de la consola del EA— para diagnosticar problemas de rendimiento. |
| Indicadores de rendimiento | Publicar métricas (por ejemplo, a través de Prometheus), como la latencia de las solicitudes, los tokens por segundo y el tiempo de carga del modelo, para supervisar y optimizar el rendimiento del sistema. |
| Estrategias alternativas | Mostrar un mensaje predeterminado de «información no disponible» en EA si falla la solicitud WebRequest o el servidor está inactivo, manteniendo así la estabilidad de la interfaz de usuario en caso de error. |
Archivos adjuntos
| Nombre del archivo | Descripción |
|---|---|
| News Headline EA.mq5 | Script de asesor experto para MetaTrader 5 que muestra barras deslizantes con eventos del calendario económico, noticias de Alpha Vantage, información de indicadores en el gráfico (RSI, estocástico, MACD, CCI) y una barra de señales de mercado basada en IA con control de frecuencia. |
| download_model.py | Script independiente de Python que utiliza el cliente Hugging Face Hub para descargar y almacenar en caché el modelo StableLM-Zephyr cuantificado con GGUF de 4 bits, y que muestra su ruta local para consultarla posteriormente durante la configuración del servidor. |
| serve_insights.py | Aplicación FastAPI que carga el modelo GGUF almacenado en caché a través de llama-cpp-python, expone un punto final POST /insights para aceptar solicitudes JSON, ejecuta la inferencia y devuelve los datos de mercado generados. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/18685
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso