
Red neuronal en la práctica: la práctica lleva a la perfección

Introducción
Hola a todos, y bienvenidos a un artículo más sobre Red neuronal.
En el artículo anterior, Red neuronal en la práctica: La primera neurona, construimos nuestra primera neurona. Sin embargo, no todo es tan sencillo cuando se trata de programación. Mucha gente simplemente crea, o mejor dicho, copia un código y empieza a usarlo. Definitivamente, esto no es, ni de lejos, un problema. Hacer esto no está mal. Muy al contrario. Es una práctica bastante inteligente, siempre que, por supuesto, estudies el código e intentes mejorarlo, de modo que se adapte a tus necesidades. Lo incorrecto es querer usar algo sin entenderlo. O, peor aún, quejarte de algo, o salir hablando de algo de lo que definitivamente no tienes ningún conocimiento.
Aquel mismo código que vimos en el artículo anterior, a pesar de funcionar, no es, en ningún caso, algo que debas usar en una aplicación más compleja. Esto, para que las cosas se ejecuten en un tiempo adecuado, o incluso dentro de cierta expectativa de resultados.
Para que tú, mi querido y estimado lector, puedas entender de qué estoy hablando, veamos cómo están las cosas y qué problemas podemos tener si las cambiamos solo un poco. Pero, para que quede más claro, veamos esto en un nuevo tema.
Haciendo inviable el tiempo de ejecución
Muy bien, nuestra sencilla y única neurona puede verse en el código siguiente.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. #define macroSigmoid(a) (1.0 / (1 + MathExp(-a))) 06. //+------------------------------------------------------------------+ 07. double Train[][3] { 08. {0, 0, 0}, 09. {0, 1, 0}, 10. {1, 0, 0}, 11. {1, 1, 1}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 3; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w0, const double w1, const double b) 18. { 19. double err; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); 24. 25. return err / nTrain; 26. } 27. //+------------------------------------------------------------------+ 28. void OnStart() 29. { 30. double w0, w1, err, ew0, ew1, eb, bias; 31. ulong count, it0, it1; 32. 33. Print("The Neuron - Tutor ..."); 34. MathSrand(512); 35. w0 = (double)macroRandom; 36. w1 = (double)macroRandom; 37. bias = (double)macroRandom; 38. 39. it0 = GetTickCount(); 40. 41. for (count = 0; (count < ULONG_MAX) && ((err = Cost(w0, w1, bias)) > eps); count++) 42. { 43. ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; 44. ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; 45. eb = (Cost(w0, w1, bias + eps) - err) / eps; 46. w0 -= (ew0 * eps); 47. w1 -= (ew1 * eps); 48. bias -= (eb * eps); 49. } 50. 51. it1 = GetTickCount(); 52. Print("Time: ", (it1 - it0) / 1000.0, " seconds."); 53. PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", count, w0, ew0, w1, ew1, bias, eb, err); 54. Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); 55. Print("Error Weight 0: ", ew0); 56. Print("Error Weight 1: ", ew1); 57. Print("Error Bias: ", eb); 58. Print("Error: ", err); 59. 60. Print("Testing the neuron..."); 61. for (uchar p0 = 0; p0 < 2; p0++) 62. for (uchar p1 = 0; p1 < 2; p1++) 63. PrintFormat("%d AND %d IS %f", p0, p1, macroSigmoid((p0 * w0) + (p1 * w1) + bias)); 64. 65. Print("************************************"); 66. } 67. //+------------------------------------------------------------------+
He cambiado algunas cosas en el código con respecto a lo publicado en el artículo anterior. Y la razón por la que se hizo esto es bastante simple. Quiero mostrar cómo un simple cambio puede afectar, de manera notoria, todo el tiempo de ejecución, así como los resultados esperados. Este código anterior, si se ejecuta en MetaTrader 5, generará algo muy parecido a lo que puede verse en la imagen inferior.
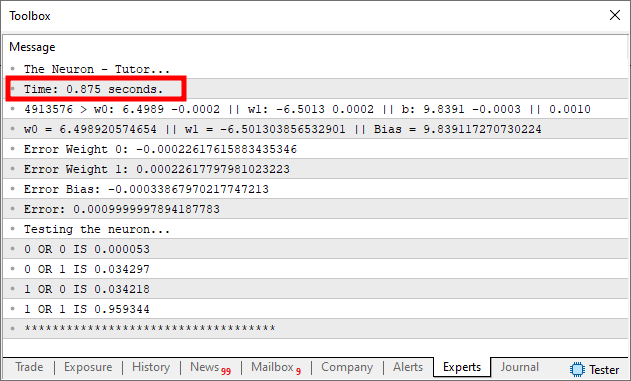
Presta atención a algunos datos que se ven en esta imagen superior. La más evidente, por supuesto, la estoy destacando, que es justamente el tiempo de ejecución del código. Este tiempo tiene en cuenta únicamente el hecho de que estamos factorizando las cosas. Puedes ver esto observando el código. Fíjate en que, en la línea 39, capturamos el momento exacto antes de comenzar a factorizar los datos de entrenamiento de la neurona. Y, en la línea 51, volvemos a capturar el momento exacto en que terminó el entrenamiento. La diferencia entre estos dos valores nos da el tiempo de ejecución del entrenamiento. Observa que, en la línea 52, hacemos un pequeño cálculo. Como el tiempo capturado está en el orden de los milisegundos, al dividir entre mil la diferencia de valor entre los tiempos, obtenemos un valor aproximado del tiempo en segundos. Este mismo tiempo es el que se está destacando en la imagen superior.
Ahora veamos qué vamos a hacer. En la línea 15 de este mismo código que se muestra arriba, estamos definiendo el error como 0,001. Ahora, ¿qué sucede en términos de tiempo de ejecución para este mismo código si cambiamos el error a 0,0001 o 1e-4?
Bien, haz esto en tu máquina para ver qué sucede. Pero, de cualquier manera, obtendrás algo muy parecido a lo que se ve en la imagen inferior.
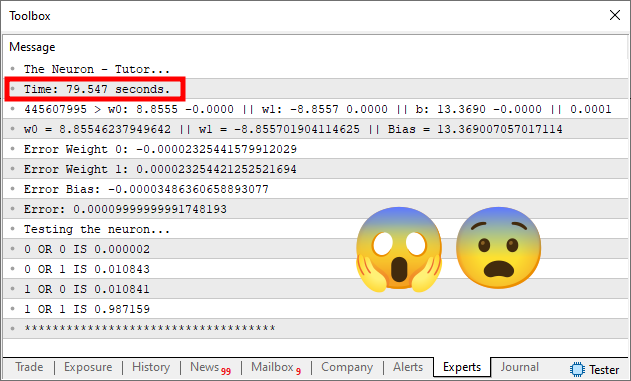
Ahora observa lo siguiente. El simple hecho de haber cambiado el error de 1e-3 a 1e-4 hace que el tiempo de ejecución pase de menos de 1 segundo a casi 80 segundos. Así es, tal como lo estás viendo. El simple hecho de haber cambiado la precisión en solo 10 veces hizo que el tiempo de ejecución aumentara más de 80 veces.
Es justamente este tipo de cosas lo que acaba destruyendo los sueños de muchos principiantes, pero principalmente de personas que no tienen la menor idea de que programar no es precisamente una de las tareas más simples. Cuando decimos que cada programa, muchas veces, está orientado a ejecutar una determinada tarea, muchos se quedan perplejos al oír algo así. Aún más cuando muchas otras personas dicen que una red neuronal puede hacer cualquier cosa de forma muy rápida, cuando, en realidad, no es exactamente así.
Quiero llamar tu atención sobre este hecho, mi querido lector. Antes de entrar en la cuestión de agregar más neuronas a la red, saber cómo se construirá la red y con qué propósito marca toda la diferencia. Para demostrarlo, vamos a tomar esta misma neurona simple y sencilla y cambiarla por algo un poco diferente, pero orientado a resolver el mismo problema que se ve en el código. Es decir, vamos a hacer que esta neurona se vuelva especialista en lo que necesita hacer. No desde el punto de vista de la factorización, sino del número de entradas. Para separar las cosas, veamos esto en otro tema.
Ajustando el código para obtener mejores resultados
Muy bien, pensemos en lo siguiente: ¿qué sentido tiene que una sola neurona tarde 80 veces más para mejorar la precisión solo 10 veces? Este tipo de cosa no tiene ningún sentido. Sin embargo, si sabemos de antemano que la neurona, durante toda su vida útil, va a trabajar con dos entradas y una salida, podemos mejorar su código. Esto hará que sea más rápida, para que pueda aprender de una manera más eficiente.
Hacer este cambio puede parecer algo extremadamente complicado, y que solo quien tenga un gran conocimiento será capaz de lograr tal hazaña. Sin embargo, no es exactamente así. Todo lo que necesitas entender, mi querido lector, es cómo funciona el programa y cuál es su propósito. Si sabes esto y entiendes cómo fue escrito el programa en un lenguaje determinado, lograrás, aunque tardes un poco, implementar una solución mucho mejor.
Y, para demostrarlo, vamos a modificar el código del tema anterior, pero manteniendo todavía presente el código original. El objetivo de esto es entender si vamos por el camino correcto o no. Un buen programador nunca intenta cambiar un código desconocido. Primero intenta entender el código, entender cómo funciona y, así, tratar de introducir alguna mejora en él. Siguiendo estas premisas, el nuevo código puede verse más abajo:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. #define macroSigmoid(a) (1.0 / (1 + MathExp(-a))) 06. //+------------------------------------------------------------------+ 07. #define def_Fast 08. //+------------------------------------------------------------------+ 09. double Train[][3] { 10. {0, 0, 0}, 11. {0, 1, 0}, 12. {1, 0, 0}, 13. {1, 1, 1}, 14. }; 15. //+------------------------------------------------------------------+ 16. const uint nTrain = Train.Size() / 3; 17. const double eps = 1e-4; 18. //+------------------------------------------------------------------+ 19. double Cost(const double w0, const double w1, const double b) 20. { 21. double err; 22. 23. err = 0; 24. for (uint c = 0; c < nTrain; c++) 25. err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); 26. 27. return err / nTrain; 28. } 29. //+------------------------------------------------------------------+ 30. double Cost_2(double &w0, double &w1, double &b) 31. { 32. double err, ew0, ew1, eb; 33. 34. err = ew0 = ew1 = eb = 0; 35. for (uint c = 0; c < nTrain; c++) 36. { 37. err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); 38. ew0 += MathPow((macroSigmoid((Train[c][0] * (w0 + eps)) + (Train[c][1] * w1) + b) - Train[c][2]), 2); 39. ew1 += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * (w1 + eps)) + b) - Train[c][2]), 2); 40. eb += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + (b + eps)) - Train[c][2]), 2); 41. } 42. 43. w0 -= (((ew0 - err)/ eps) * eps); 44. w1 -= (((ew1 - err)/ eps) * eps); 45. b -= (((eb - err)/ eps) * eps); 46. 47. return err / nTrain; 48. } 49. //+------------------------------------------------------------------+ 50. void OnStart() 51. { 52. double w0, w1, err, ew0, ew1, eb, bias; 53. ulong count, it0, it1; 54. 55. Print("The Neuron - Tutor..."); 56. MathSrand(512); 57. w0 = (double)macroRandom; 58. w1 = (double)macroRandom; 59. bias = (double)macroRandom; 60. 61. it0 = GetTickCount(); 62. #ifdef def_Fast 63. for (count = 0; (count < ULONG_MAX) && ((err = Cost_2(w0, w1, bias)) > eps); count++); 64. #else 65. for (count = 0; (count < ULONG_MAX) && ((err = Cost(w0, w1, bias)) > eps); count++) 66. { 67. ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; 68. ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; 69. eb = (Cost(w0, w1, bias + eps) - err) / eps; 70. w0 -= (ew0 * eps); 71. w1 -= (ew1 * eps); 72. bias -= (eb * eps); 73. } 74. #endif 75. it1 = GetTickCount(); 76. Print("Time: ", (it1 - it0) / 1000.0, " seconds."); 77. PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", count, w0, ew0, w1, ew1, bias, eb, err); 78. Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); 79. Print("Error Weight 0: ", ew0); 80. Print("Error Weight 1: ", ew1); 81. Print("Error Bias: ", eb); 82. Print("Error: ", err); 83. 84. Print("Testing the neuron..."); 85. for (uchar p0 = 0; p0 < 2; p0++) 86. for (uchar p1 = 0; p1 < 2; p1++) 87. PrintFormat("%d AND %d IS %f", p0, p1, macroSigmoid((p0 * w0) + (p1 * w1) + bias)); 88. 89. Print("************************************"); 90. } 91. //+------------------------------------------------------------------+
No te preocupes por escribir este código. Si lo deseas, puedes hacerlo para asimilar mejor cómo programar en MQL5, ya que, cuando escribimos un código, logramos entender mejor cómo se está creando. Además, también afianzamos diversas otras cuestiones relacionadas con la sintaxis del lenguaje en el que estamos programando. Pero, en el anexo, tendrás acceso a él. Así que queda a tu criterio cómo hacer uso de este conocimiento.
Bien, entonces veamos qué obtendremos en términos de tiempo de ejecución. Esto puede verse en la imagen inferior.
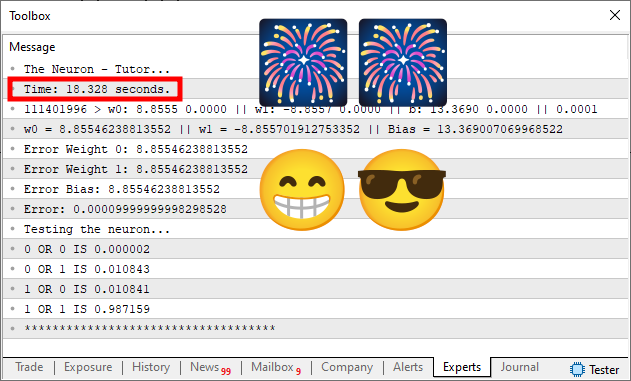
¿Qué? ¿Pero cómo fue posible hacer esto? ¿Cómo el tiempo empleado cayó de casi 80 segundos a poco más de 18 segundos? Esto es completamente imposible. Ah, ya sé, cambiaste de computadora, usaste una computadora mejor para hacer esto. O incluso, muy probablemente, y es casi seguro, hiciste algún tipo de trampa, colocando un error diferente en el sistema o cambiando alguna otra cosa. Así, en la primera ejecución gastarías más tiempo, como puede verse en la primera imagen. Pero después gastarías mucho menos tiempo, usando algún tipo de trampa. Y, así, producirías lo que puede verse en esta segunda imagen.
Bien, mi querido lector. Tal vez incluso podría haber hecho eso. Pero no, por esta razón dejo el código en el anexo. Así, podrás entender lo que ocurrió, probando en tu máquina este mismo código. Pero, antes de hacer eso, primero vamos a entender qué está ocurriendo para que el código, que antes se ejecutaba en casi 80 segundos, haya pasado a ejecutarse en poco más de 18 segundos. Y, antes de comenzar, no existe magia ni nada por el estilo. Se trata de saber qué necesita aprender la neurona.
Si observas el código, podrías pensar que es muy complicado. Más aún si estás empezando en la programación. Sin embargo, no te asustes, es bastante simple, y me he preocupado por mantenerlo así. De esta forma, resulta más didáctico y práctico explicar cómo funciona.
Comencemos por la línea siete. Allí tenemos una definición, y ese es uno de los pocos puntos en los que tú, principiante y entusiasta, deberás modificar el código, sin riesgo de volverlo inestable. Si eliminas esta línea siete, dejarás el código exactamente como se vio en el tema anterior. Es decir, lento y torpe, pero genérico. Sin embargo, si esta línea siete está de la forma en que se ve aquí en el artículo, la versión rápida del código será la que se use, mostrando así el resultado que se ve en la imagen superior.
Ahora quiero que compares la imagen de este tema con las imágenes del tema anterior. Pero quiero que observes el valor del error. Fíjate en que son muy parecidos. Sobre todo la última imagen del tema anterior y la que se ve en este tema. Es decir, estamos usando un error de 1e-4 en ambos casos. Entonces, espera un momento. ¿Estás diciendo que, a pesar de que estamos usando la misma precisión, el tiempo de ejecución terminó cayendo bruscamente? Sí, mi querido lector. Eso es exactamente lo que ocurrió. Pero ¿por qué ocurrió esto? ¿Sabrías decírmelo?
Bien, para entenderlo, es necesario observar algunas cosas en el código. Vamos a saltarnos gran parte del código y dirigirnos al procedimiento OnStart, que se encuentra en la línea 50. Ahora, hace falta un poco de calma. Pero no es nada complicado entender lo que está ocurriendo. Observa que, dentro de este procedimiento, gran parte del código puede verse en el tema anterior. Estas partes iguales son las que hacen que la neurona sea idéntica a la que hemos visto hasta ahora. Sin embargo, precisamente en la línea 62, le pedimos al compilador que haga una prueba cuando vaya a crear el ejecutable final. Esta prueba comprobará si la línea siete existe o no.
En caso de que no exista, el código que se creará será igual al que se vio en el tema anterior. En caso de que la línea siete exista, el código del tema anterior será sustituido por el código presente en la línea 63. Presta atención a esto. Estamos sustituyendo el código entre las líneas 65 y 73 por el código de la línea 63. Todo lo demás permanecerá idéntico e intacto.
Pero ahora, al observar el contenido de la línea 63, notas que se trata de un bucle for. Este se parece mucho al código de la línea 65. Claro, la diferencia es que, en la línea 65, estamos llamando a Cost y, en la línea 63, estamos llamando a Cost_2. Aparte de eso, el código es idéntico. Pero esto no explica por qué, en una ejecución, se necesitan casi 80 segundos, mientras que, en la otra, solo se necesitan 18 segundos. Este tipo de cosa no tiene el menor sentido. Pero ahí es donde te equivocas, mi querido lector. Este simple cambio marca toda la diferencia. Observa que, aunque estés mirando solo la línea 65, en realidad la función Cost se llama en cuatro momentos diferentes: en la línea 65, en la 67, en la 68 y en la 69.
En cada una de estas llamadas, toda la tabla, base de datos o, en nuestro caso, el array de entrenamiento, debe analizarse. Piensa un momento en esto. Observa que nuestro array de entrenamiento contiene solo cuatro líneas de datos. Esto puede verse en la línea nueve del código. Solo cuatro líneas de datos. Sin embargo, cada vez que es necesario llamar a la función Cost, presente en la línea 19, el bucle de la línea 24 volverá a leer y calcular todo otra vez. Y esto, para cada una de las llamadas presentes en el procedimiento OnStart.
Aunque es mucho más simple programar las cosas de esta forma, esto, en términos generales, no es nada eficiente. Sin embargo, esta misma forma de programar hace que la neurona sea mucho más genérica. Esto se debe a que podemos colocar tantas entradas o salidas como sean necesarias. Y todo ello sin necesidad de cambiar absolutamente nada en el código. En este punto es donde saber lo que estás haciendo, o conocer el tipo de resultado previsto o esperado, marca toda la diferencia. Muchos tomarían esta función de la línea 19 y la transformarían en un código OpenCL. O incluso en un código que podría ejecutarse en sistemas paralelos. En algunos casos, las máquinas que ejecutan aplicaciones paralelas pueden ser bastante caras.
En otros casos, una buena GPU consigue encargarse de todo. De cualquier manera, solo estaríamos cambiando una cosa por otra, ya que el código, aun así, seguiría siendo poco eficiente. Y lo digo porque, en cada llamada para calcular el costo, tendríamos que recorrer toda la base de datos usada para el entrenamiento. Piensa en una base de datos que contenga miles de megabytes de datos.
Ahora volvamos a la cuestión de la línea 63. Aunque no sea ninguna maravilla, en ella tenemos una llamada a una función especializada. Esto hace que la ejecución sea mucho más rápida, en comparación con una ejecución no especializada. Sin embargo, el hecho de tener una neurona especializada hace que la cosa sea un poco más complicada en términos de programación, ya que, si necesitamos cambiar algo en la neurona, ya sea el número de entradas o el número de salidas, tendríamos que cambiar por completo el código de la función Cost_2, que se llama menos veces en la línea 63. Y la razón por la que se la llama menos veces está justamente en la forma en que trabaja. Veamos cómo funciona esto y pasemos a la línea 30, donde se está implementando Cost_2. Pero, para que la explicación resulte más didáctica, veamos esta función en un nuevo tema.
Haciendo que una sola neurona se especialice
Bien, para quien desee estudiar las cosas con más calma y, de hecho, entender cómo funcionan, vamos a descomponer la función Cost_2 en dos partes. Así, será más sencillo explicar por qué es más rápida que la versión genérica.
Bien, la primera parte está entre las líneas 35 y 41. ¿Y qué está haciendo el código de esas líneas? Pues bien, está haciendo lo que antes hacían las líneas 65, 67, 68 y 69. Además, por supuesto, también hace lo que se hacía en el bucle for de la línea 24. Es decir, al final, estamos ejecutando la línea 25. Solo que, a diferencia de lo que se hacía antes, ahora lo estamos haciendo todo al mismo tiempo. Entonces, necesitamos más variables de las que hacían falta antes. Cada una de las variables declaradas en la línea 32 sirve para acelerar el código. Así, en la línea 37, estamos calculando el error general de la neurona. Esto no acelera las cosas. Pero, en las líneas 38, 39 y 40, calculamos todos los demás errores, que antes se hacían allí, en el bucle for presente en la línea 65.
Ahora viene la parte complicada del asunto. La línea 40 forma parte de cualquier neurona. Es decir, es un código genérico, al igual que la línea 37. Pero las líneas 38 y 39 no. Son ellas las que especializan la neurona. Es decir, si necesitas agregar más entradas a la neurona, tendrás que agregar más de estas líneas en el código, y una neurona creada para un propósito muy probablemente no servirá para otra cosa. Sin embargo, el hecho de que el código esté hecho de esta manera hace que sea mucho más rápido de lo que sería un código muy parecido, pero mal optimizado para un propósito específico.
La segunda parte del código está justamente en las líneas 43, 44 y 45. Allí reajustamos los valores para la siguiente llamada a la función de costo. Antes, esto se hacía en las líneas 70, 71 y 72.
El simple hecho de haber hecho estos pequeños y sencillos cambios en el código hizo posible que la neurona se volviera mucho más rápida, aprendiendo o, mejor dicho, devolviendo un conjunto de valores que hiciera posible almacenar una base de conocimientos previos. Y esa es la verdadera gracia de programar este tipo de cosas. No por el desafío en sí, sino por el placer de ver que podemos hacer las cosas de una forma mucho más eficiente. Y observa que ni siquiera fue necesario usar OpenCL, ni programar pensando en paralelizar los cálculos. Todo mucho más emocionante y divertido que toda esa pesadez que muchos andan mostrando por ahí, más aún cuando el tema son las redes neuronales.
Muy bien, este fue un ejemplo bastante simple de cómo podemos hacer las cosas. Pero podemos avanzar un poco más en esta misma cuestión. Porque, aunque esta neurona simple y sencilla sea capaz de hacer varias cosas y tenga como única limitación el hecho de que siempre necesitamos aumentar o reducir el número de entradas, buscando, por supuesto, hacerla siempre lo más rápida posible, todavía no es lo suficientemente "inteligente" como para lidiar con ciertos tipos de situaciones. Por esta razón, esto de la inteligencia artificial o las redes neuronales no es un asunto tan simple como muchos creen. Del mismo modo, tampoco podemos considerar que una neurona será capaz de lidiar con cualquier tipo de situación dentro de un escenario concreto.
Para ejemplificar esto, vamos a hacer un pequeño ejercicio mental. Nada muy complicado, solo quiero mostrarte, mi querido lector, algo que muchos pasan por alto al estudiar las redes neuronales. Se trata de algo que muchos no dicen, o no quieren decir, pero que, si logras entender, percibirás que nada de lo programado realmente podrá superar a la mente que lo programó.
Pensemos en los datos usados para el entrenamiento. Hay situaciones en las que no conseguimos que una neurona pueda manejar los datos. No es que sean datos extremadamente complicados ni nada por el estilo. De hecho, son datos simples. Sin embargo, una neurona no, y lo voy a repetir, NO logra resolver el problema, por lo que es necesario que usemos más de una neurona para ello. Entonces, voy a dar una rápida pincelada sobre el tema que se tratará más adelante. Sin embargo, en casos específicos, sí es admisible simular una pequeña red neuronal usando una sola neurona. Todo depende del tipo de problema para el que estemos buscando una solución.
Así, en muchos casos, y de hecho la mayoría de las veces, una neurona puede construirse o, mejor dicho, programarse, de manera que pueda usarse en el futuro para implementar una red neuronal. Y no estoy hablando de una red neuronal tipo chatbot, ni nada por el estilo. Estoy hablando de algo infinitamente más simple. Sin embargo, hay casos en los que podemos forzar a una sola neurona a resolver un tipo de problema para el que haría falta una pequeña red neuronal. Y no necesitaremos crear un BIG DATA, con un volumen enorme de datos, para encontrar una situación en la que esto ocurra. Podemos hacer esto usando este mismo código que se está mostrando en este artículo.
Vaya, ahora sí se complicó de verdad. ¿Cómo es eso? Déjame ver si entendí bien tu planteamiento. ¿Me estás diciendo que esta neurona con la que estamos trabajando no podrá lidiar con algo que podemos representar en esta misma base de datos, pero que, si sabemos cómo trabajar con ella, podemos forzarla a simular una pequeña red neuronal y, así, conseguir resolver algo que por sí sola no podría? ¿Es eso? Sí, eso mismo. Observa que esta base de datos que estamos usando se asemeja a una tabla de puertas lógicas. Es decir, podemos poner en ella combinaciones de ceros y unos, y pedirle a la neurona que intente encontrar una ecuación o, mejor dicho, una regresión lineal que pueda representar la puerta lógica.
Sin embargo, hay dos casos, aunque podemos tratarlos como un solo caso. Esto se debe a que ambos son inversos entre sí. En ellos, esta sencilla neurona no logrará encontrar la ecuación correcta. Pero, si la fuerzas a trabajar de una determinada forma, logrará encontrar la ecuación correcta.
Para entender de forma más simple lo que quiero explicar, mira la imagen siguiente.
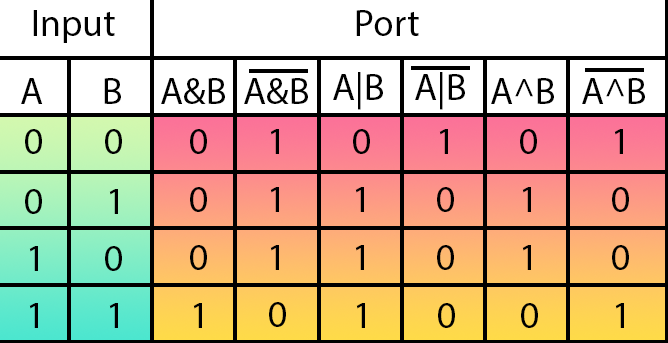
Esta imagen muestra todas las puertas lógicas que existen. En la parte verde están las entradas de la puerta. En la parte en tonos rojos y naranjas están las salidas de cada una de las puertas. En la parte superior de cada salida se está definiendo el tipo de puerta lógica.
Pues bien, veamos qué quiere decir esto. De izquierda a derecha, tenemos las puertas en el siguiente orden: AND, NAND, OR, NOR, XOR y NXOR.
¿Y qué importancia tiene para nosotros aquí esta tabla que se muestra en esa imagen, si el tema son las redes neuronales? Para comprenderlo, vuelve a mirar el código de la neurona. Observa que, en la línea nueve, donde definimos las reglas de entrenamiento, tenemos exactamente algo parecido a la tabla mostrada en esa imagen.
Ahora viene la parte interesante. Los dos primeros valores son las entradas. El tercer valor, en cambio, es la salida. Compara lo que se ve en el código con la tabla que se muestra en la imagen. ¿Qué logras notar, mi querido lector? Bien, si prestas un poco de atención, acabarás notando que estamos definiendo, en el entrenamiento, una puerta AND.
Puedes experimentar cambiando los valores del tercer argumento usado en el entrenamiento. Y verás que conseguirás hacer que la neurona aprenda, o genere una ecuación capaz de representar, casi todas las puertas. Digo casi porque la neurona no podrá aprender dos de ellas. Esas puertas son justamente la XOR y su inversa, que es la NXOR.
Vaya. Pero espera un momento. ¿Cómo que la neurona no va a conseguir aprender a generar las puertas XOR y NXOR? Tienes que estar bromeando. Todos los valores están compuestos únicamente por ceros y unos. Esto solo puede ser una broma o una tomadura de pelo. Te estás burlando de mí.
Hasta me gustaría estar bromeando, tomándote el pelo. Pero no. Esto es un hecho, y puedes comprobarlo. Si intentas entrenar una sola neurona usando solo ceros y unos, habrá casos en los que la neurona no logrará aprender a tratar la situación. Esto se debe a que la solución es mucho más compleja de lo que una sola neurona puede modelar.
Difícilmente verás a alguien hablar de este tipo de cosas, o siquiera mencionarlas. Esto ocurre cuando el tema que estamos leyendo está, de algún modo, relacionado con la inteligencia artificial, las redes neuronales o la programación de neuronas. Las personas no piensan en intentar todas las alternativas. Si funciona para un caso específico, enseguida empiezan a difundirlo y a hablar del asunto. Pero, si empiezas a cuestionarlas sobre determinados escenarios, comienzan a dar rodeos o ignoran la pregunta.
Sin embargo, existe una forma de forzar a la neurona a aprender a lidiar con estas situaciones, como en el caso en que necesitamos resolver el problema de la puerta XOR o de su inversa, la NXOR. Como este tema es algo complicado de explicar en el tiempo que queda de este artículo, en el próximo artículo veremos cómo resolver este tipo de cuestión. Pero, hasta que se publique el próximo artículo, quién sabe, tal vez tú, mi querido lector y entusiasta del tema, consigas pensar en una forma de resolver el problema de la puerta XOR y su inversa, la puerta NXOR. Detalle: no vale usar más de una neurona. Pues hacerlo sería hacer trampa. La regla es: solo puedes usar una neurona para implementar la solución.
Consideraciones finales
En este artículo, mostré cómo un simple cambio en el código, a fin de hacer que la neurona sea un poco más especializada, puede hacer que la fase de entrenamiento sea considerablemente más rápida. Puesto que, una vez que la neurona, o red neuronal, como se verá más adelante, ya haya sido entrenada, el trabajo que realice será mucho más rápido. Tanto es así que, en el código presente, tanto en el artículo como en el anexo, puedes notar que la generación de resultados a partir de los valores de entrada se hace de manera muy rápida. Siempre que, por supuesto, ya sepamos cuáles son los valores que deben usarse en el cálculo.
Aquí también mencioné un problema que existe y del que casi nadie habla o menciona. Se trata justamente del hecho de que una neurona no logra lidiar con todos los escenarios posibles, a diferencia de lo que muchos creen. La máquina no es tan superior, ni capaz de superar a un ser vivo. Una sola neurona viva consigue resolver cualquier tipo de escenario simple. Sin embargo, una neurona programada, o implementada en silicio, no puede lograr tal hazaña.
Entonces, en el próximo artículo seguiremos viendo este asunto. Hasta luego. Y nos vemos pronto.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/13748
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso