
Redes neuronales en el trading: Framework de predicción cruzada de dominios de series temporales (TimeFound)

Introducción
La previsión de series temporales ha sido durante mucho tiempo una herramienta indispensable para los analistas financieros. Si alguna vez ha intentado predecir hacia dónde irán los precios de las acciones o cómo cambiará la volatilidad de un índice financiero, sabrá que es como intentar adivinar el futuro mirando los posos de café. Sin embargo, sin esta adivinación, ningún fondo serio sobreviviría.
Antes se usaban modelos estadísticos clásicos: ARIMA, el suavizado exponencial. Es más, incluso la regresión lineal a menudo daba frutos. Los argumentos sobre por qué el modelo debería ser más simple sonaban convincentes hasta que las redes neuronales profundas entraron en escena. Hoy en día, no solo están dando frutos, sino también recolectando una cosecha notable, sorprendente por la precisión y velocidad de procesamiento de terabytes de datos históricos.
No obstante, como cualquier arma poderosa, los modelos profundos tienen sus efectos secundarios. Para entrenarse, necesitan toda un yacimiento de datos etiquetados sobre una tarea específica. Sin esto, la red neuronal del Gran Hermano no funcionará. ¿Pero qué pasa si solo tenemos a nuestra disposición un pequeño fragmento de la historia o si el mercado recién ha comenzado a negociar? ¿Cómo podemos predecir el precio de un token recién emitido cuando el terminal de corretaje aún no ha acumulado datos? Aquí es donde entra en juego el concepto de Zero‑Shot Forecasting: un enfoque pensado para que el modelo funcione allí donde los enfoques clásicos simplemente fallan.
Los investigadores de series temporales han establecido analogías con grandes modelos lingüísticos (Large Language Models). Los LLM famosos trabajan con éxito con textos: traducen, escriben poesía y responden preguntas. ¿Por qué no aplicar sus ideas a la previsión de tendencias de precios? Así nació el boom de los llamados Foundation Models para series temporales. Imagínese: un modelo universal al que no le importa si predice los precios de las acciones, el consumo de electricidad o la tasa de desempleo. Lo principal es entrenarlo correctamente con un conjunto de datos diverso.
Inspirados por esta fundamentalidad, los autores del artículo "TimeFound: A Foundation Model for Time Series Forecasting" presentaron un nuevo framework para la previsión de series temporales basado en la arquitectura del Transformer, el TimeFound. Para ello, tomaron las mejores ideas del mundo del NLP y las adaptaron a la previsión de series temporales.
El framework TimeFound está construido sobre el esquema clásico Codificador-Decodificador. El Codificador examina una serie de datos históricos y extrae contexto de ella. El Decodificador, a su vez, imagina el futuro, preservando las relaciones de causa y efecto.
El modelo se basa en un nuevo enfoque para parchear series temporales. Olvidémonos del tamaño fijo de la ventana: los autores del framework proponen dividir la secuencia en varios parches de diferentes tamaños. Imagínese que está estudiando el comportamiento de las acciones de una empresa: las fluctuaciones mensuales parecen uniformes, mientras que las fluctuaciones intradiarias están llenas de saltos bruscos. El Multi-resolution patching nos permite captar tanto la tendencia a largo plazo como el ruido de la volatilidad.
Para el entrenamiento preliminar, los autores del framework recopilaron un enorme conjunto de datos multidominio: toda esta diversidad es necesaria para que el modelo aprenda a captar patrones universales. Cuantos más datos, más rico será el vocabulario de los patrones aprendidos por el modelo.
El objetivo de aprendizaje es simple: un problema de pronóstico autorregresivo. Como entrada se introduce un conjunto de datos históricos y el modelo aprende a predecir el siguiente paso a paso. No obstante, en este caso, el paso de pronóstico puede diferir del paso de datos históricos. La cuestión es que el modelo retorna resultados en forma de parches, y un parche puede incluir varios pasos del sistema analizado.
El algoritmo TimeFound
TimeFound es un modelo universal desarrollado como base para construir sistemas de pronóstico en varios dominios, incluidos, entre otros, los mercados financieros. La arquitectura del modelo está construida en el formato Codificador-Decodificador con un principio de procesamiento de datos modular. Cuenta con normalización central, parcheo multinivel, atención de posicionamiento relativo y aprendizaje conjunto usando errores de predicción de puntos y cuantiles.
El algoritmo del framework comienza con una preparación cuidadosa de la serie temporal inicial, porque sin una base fiable cualquier pronóstico corre el riesgo de ser inestable. Primero, convertimos los datos a una forma comparable: normalizamos cada serie usando la normalización clásica, restando el valor medio de toda la secuencia de cada punto y dividiendo por su desviación estándar. Gracias a esta técnica, el modelo no se perderá cuando un movimiento del mercado parezca una pequeña onda sinusoidal en comparación con un aumento colosal en el consumo de energía y, por el contrario, detectará incluso fluctuaciones sutiles cuando estas realmente importen.
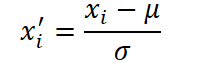
donde μ y σ suponen la media y la desviación estándar de la serie X. Esto alinea la escala de datos sin perder la estructura temporal.
Una vez establecida la escala, es el momento de dividir la serie en fragmentos o parches. En las soluciones clásicas, todos los parches son iguales, pero sabemos que la misma serie temporal puede ocultar picos rápidos y tendencias lentas. Por ello, los autores del framework TimeFound proponen parches de múltiples escalas. En el primer nivel se forman parches de escala mínima. Su número máximo. A medida que aumenta el nivel, el tamaño del parche también lo hace, con una reducción múltiple en su número. Los autores del framework usaron en su trabajo parches cuyo tamaño es una potencia de 2.
Cada uno de estos parches contiene una parte de la historia temporal, ya sea un aumento a corto plazo de la volatilidad o un descenso más prolongado.
Luego, se agrega un enmascaramiento binario a los parches generados, lo cual indica dónde se encuentran los datos reales y dónde se están rellenando hasta obtener un tamaño uniforme. Y cada fragmento de la serie temporal pasa a través de su propio perceptrón de dos capas con conexiones residuales. Estos proyectores MLP mapean parches de distintas longitudes en un único espacio latente de dimensión d, donde cada vector refleja la esencia del comportamiento local de la serie analizada.
Sin embargo, todavía no todo está listo. Como hemos mencionado antes, el proceso de parcheo de múltiples escalas genera una cantidad diferente de objetos en cada nivel: los bloques pequeños son muchas veces más numerosos que los grandes. Para combinarlos, los autores del framework proponen duplicar (replicar) representaciones de parches grandes la cantidad de veces necesaria para alinear su número con el número de parches más pequeños. Como resultado, en cada paso temporal obtenemos una representación multicanal estéreo en la que se fusionan los vectores de todas las escalas. Después de esto, sus características se combinan en una matriz latente. Precisamente esto entra en el bloque de atención, asegurando la interacción entre escalas.
El modelo se basa en un Codificador-Decodificador con atención modificada. El Codificador analiza cuidadosamente la secuencia recibida utilizando atención bidireccional. Esto significa que cada posición puede preguntar a todas las demás cómo se desarrollaron los acontecimientos antes y después de ella y, basándose en las respuestas consideradas, formar una comprensión más profunda. El mecanismo de atención se basa en la posición relativa de los parches: el modelo detecta que un fragmento reciente (digamos, de hace tres parches) es más importante que uno distante (digamos, de hace veinte parches) y asigna los pesos en consecuencia.
Cuando el Codificador ha completado su trabajo, sus resultados se pasan al Decodificador, que en realidad ya no tiene derecho a mirar hacia adelante, sino que solo se basa en datos históricos. El mecanismo de atención impide que el modelo mire más allá en el futuro de lo cual permite la agregación de pronósticos realizados previamente, y por lo tanto cada nuevo pronóstico es preciso y justo. Un vínculo importante aquí es la Cross-Attention. El Decodificador, al formar una representación del próximo parche, nuevamente hace referencia a los ricos vectores de contexto del Codificador, extrayendo de ellos información acerca de las tendencias recientemente pasadas.
En la salida del Decodificador, obtenemos un vector predictivo para el parche posterior: una descripción comprimida de eventos anteriores y señales clave. Este vector se transmite al módulo de transformación, implementado como un MLP de dos capas con conexión residual. En él, la representación latente se despliega nuevamente en los valores habituales de la serie temporal, y luego se forma de inmediato un bloque de puntos futuros. Esta producción por lotes de pronósticos acelera la ejecución del modelo y resulta particularmente efectiva en horizontes a largo plazo.
Al realizar el entrenamiento, los autores del framework no se limitan únicamente a optimizar el ajuste al valor medio hacia los valores correctos. Junto con el MSE estándar, que penaliza la diferencia al cuadrado entre los valores predichos y los verdaderos, usan una función de pérdida de cuantiles, que obliga al modelo a ofrecer una estimación de la incertidumbre. Para cada paso temporal, aprende a generar, además de los valores promedio, por ejemplo, los percentiles 10, 50 y 90. La función de pérdida acumulada, que acumula el MSE y la pérdida cuantil, forma un equilibrio entre la precisión del pronóstico y la amplitud del intervalo de confianza.
De este modo, todo el algoritmo TimeFound supone en único pipeline bien diseñado. Este combina la potencia de los transformadores con la flexibilidad del parcheo multiescala y la sensibilidad a la incertidumbre, lo que hace que el modelo resulte adecuado para cualquier serie temporal.
Para entrenar previamente TimeFound, los autores del framework crearon un conjunto de datos completo y diverso que abarca series temporales reales y sintéticas en varios dominios. Asimismo, se recopilaron series temporales disponibles públicamente con diferentes frecuencias (desde 5 minutos hasta anual). Además se utilizaron datos de los mercados financieros (precios de acciones, futuros de divisas), el consumo de energía, las temperaturas y los volúmenes de ventas. Posteriormente su diversidad se incrementó mediante generaciones sintéticas. Esto permite que TimeFound forme representaciones universales de series temporales, ofreciendo una alta capacidad de generalización sin necesidad de volver a entrenar en nuevas tareas.
A continuación le presentamos la visualización del autor del framework TimeFound.

Implementación con MQL5
Tras revisar los aspectos teóricos del framework TimeFound, pasaremos a la parte práctica de nuestro artículo, en la que implementaremos nuestra propia visión de los enfoques propuestos por los autores del framework usando herramientas MQL5. Pero antes de profundizar en los detalles del código, deberemos tener una comprensión clara de la secuencia de tareas y cómo se relacionan entre sí. Nuestro viaje comienza con la preparación de los datos iniciales, y aquí es donde reside la calidad de todo el pronóstico posterior.
Para normalizar los datos de las series temporales analizadas, no reinventaremos la rueda: usaremos un bloque de normalización por lotes ya preparado. Este módulo escanea automáticamente el búfer de precios acumulado, calcula la media y la varianza en cada paso y nivela la distribución de datos en tiempo real, eliminando saltos bruscos en el modelo cuando cambian las condiciones del mercado. Usando esta normalización continua, preservamos la dinámica de patrones importantes y al mismo tiempo eliminamos la variabilidad que interfiere con el aprendizaje y la predicción estables.
Una vez que los datos están alineados a una única escala, es momento de abordar la tarea verdaderamente clave: la segmentación en parches a múltiples escalas. En el enfoque clásico de replicación secuencial, primero dividiríamos la serie en fragmentos de diferentes tamaños, luego contaríamos hasta la misma cantidad de bloques pequeños mediante un banal copia y pega de vectores grandes y, solo después, volveríamos a pegar todo lentamente. Este método resulta comprensible, pero inaceptable debido a los retrasos. Con cada entrada a una nueva vela, perdemos un tiempo precioso en la replicación y las incorporaciones a gran escala resultantes se duplican varias veces, perdiendo su singularidad.
En nuestra implementación procederemos de manera distinta. Utilizaremos el concepto de convolución multiventana. Imaginemos que en lugar de tres procedimientos separados, ejecutamos tres núcleos de capa convolucional en paralelo, cada cual con su propio tamaño de ventana. Gracias al relleno de ceros y la superposición, los filtros convolucionales con el mismo paso se enrollan cuidadosamente a lo largo de toda la longitud de la serie temporal analizada, formando simultáneamente tres arrays de características de la misma longitud.
Este enfoque nos ofrece varios efectos ganadores a la vez. En primer lugar, todos los cálculos se realizan simultáneamente: no debemos esperar a que se procesen parches pequeños para luego rellenarlos con los datos de los parches grandes. En segundo lugar, gracias a la ventana deslizante con un paso igual, cada nuevo valor de la serie se involucra en las tres transformaciones y no tenemos problemas con la alineación. Los tensores de salida se organizan directamente según un índice temporal. En tercer lugar, gracias a la superposición, la ventana de filtros amplios captura los segmentos adyacentes, lo que permite una mejor captura de tendencias lentas y fluctuaciones suaves, y no solo bloques estrictos.
Asimismo, no necesitaremos replicar o interpolar nada manualmente: el algoritmo mantiene un número igual de elementos y una representación uniforme para cada paso temporal.
El resultado será una sección transversal instantánea y compacta de la imagen de mercado con el nivel de detalle requerido, lista para ser proyectada en el espacio latente del proyector MLP.
Este parcheo multiescala paralelo representa el corazón del módulo de preprocesamiento: este preserva la singularidad de las incorporaciones en cada escala, elimina la replicación redundante y permite que nuestro robot tome decisiones más rápido y con mayor precisión, respondiendo simultáneamente tanto a microrráfagas como a tendencias a largo plazo.
A continuación, transformaremos las incorporaciones obtenidas en características altamente informativas. Tras la convolución multiventana, en cada paso temporal ya habrá un número específico de canales en forma de incorporaciones. Pero para un modelo profundo esto no resulta suficiente. Así, debemos agregar una capa de no linealidad y conexiones que se puedan aprender para obtener una representación verdaderamente expresiva. En el original, los autores de TimeFound proponen un MLP de dos capas con un patrón de enlace residual. Sin embargo, en nuestra implementación, utilizamos un bloque Feed-Forward multicabeza listo para usar del framework StockFormer.
Imagine que tienes tres flujos de características de diferentes escalas y que cada uno de ellos necesita llevarse a un único estándar de calidad. Nuestro bloque divide estos flujos en cabezas independientes, cada una procesada en paralelo con sus propios pesos y desplazamientos. Y luego todos los resultados se vuelven a sumar en un solo vector. Gracias a los enlaces residuales, la información sobre las incorporaciones primarias se conserva y se mezcla suavemente en la salida de la capa, lo que mejora la convergencia y hace que el modelo resulte más resistente al ruido en los datos.
Dentro de este bloque Feed-Forward, cada cabeza es un MLP de dos capas con no linealidad entre capas. Los resultados del MLP se suman con los datos de origen y se normalizan. De este modo, el vector final en cada paso temporal es una síntesis de patrones locales y características globales, lista para introducirse en el siguiente módulo.
Este enfoque permite mantener la cercanía conceptual con la arquitectura original de TimeFound, pero utilizando además un componente probado y optimizado del StockFormer, que ahorra tiempo de desarrollo y garantiza un alto rendimiento en tiempo real.
Tras preparar las características multiescala, agregaremos estas, y aquí la técnica de suma simple da paso a un mecanismo más flexible: una secuencia convolucional y pooling máximo. Imagine que tiene tres canales de integración, cada uno de los cuales contribuye a comprender lo que está sucediendo. Si sumamos estos canales elemento por elemento, todos obtendrán el mismo peso, independientemente de cuán significativos sean los picos de corto plazo o las tendencias de largo plazo en esa área. En su lugar, vamos a ejecutar una convolución en la que los filtros entrenables analizarán valores en diferentes escalas y extraerán las combinaciones más informativas.
A medida que la capa convolucional pasa a través del tensor de tres canales, cada filtro ve todas las escalas a la vez y busca patrones característicos en ellas. El resultado será un conjunto de nuevas características, cada una de las cuales refleja una combinación de señales locales y globales. Aquí es donde entra en juego el pooling máximo: deslizándose sobre los mapas de características resultantes, solo conservará las respuestas más fuertes, ignorando el ruido y las fluctuaciones sin importancia. Así, si en el mismo intervalo temporal el nivel micro ha registrado un salto brusco en el volumen, mientras que el nivel macro ha registrado un aumento constante, el pooling garantizará que ambas señales estén adecuadamente representadas en el vector final.
Como resultado de esta combinación convolucional y de pooling máximo, eliminaremos la necesidad de especificar manualmente pesos para cada escala. El propio modelo aprende a centrarse en el conjunto de características más relevantes para el pronóstico actual. Este mecanismo adaptativo no solo mejora la precisión de salida, sino que también hace que el algoritmo resulte más resistente a las fluctuaciones del mercado y al ruido, ya que las señales débiles o poco frecuentes se suavizan, mientras que los picos importantes se amplifican y llegan a las etapas del Codificador y el Decodificador sin pérdidas.
Ahora implementaremos el enfoque anterior dentro del objeto CNeuronTimeFoundPatching, cuya estructura se presenta a continuación.
class CNeuronTimeFoundPatching : public CNeuronConvOCL { protected: CNeuronTransposeOCL cToVarSeq; CNeuronMultiWindowsConvWPadOCL cProjecting; CNeuronTransposeVRCOCL cToVarProjSeq; CNeuronMultiWindowsConvWPadOCL cPatchingProj; CNeuronMHFeedForward cPatchsFeedForward; CNeuronConvOCL cPatchingAgr; CNeuronProofOCL cProof; CNeuronTransposeOCL cToPatchVarEmb; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronTimeFoundPatching(void) {}; ~CNeuronTimeFoundPatching(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint patchs, uint variables, uint embedding_size, uint patch_filters, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronTimeFoundPatching; } //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Todos los módulos internos de CNeuronTimeFoundPatching viven su propia vida independiente desde el comienzo del programa. Estos se declaran estáticamente y se inicializan al cargarse la biblioteca. Por ello, no necesitaremos crearlos en el constructor ni preocuparnos por limpiarlos en el destructor: estos métodos permanecerán vacíos y toda la magia de gestión de la arquitectura del objeto correrá a cargo de un método Init universal.
En los parámetros del método de inicialización obtenemos una serie de constantes que determinarán la arquitectura de los objetos internos.
bool CNeuronTimeFoundPatching::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint patchs, uint variables, uint embedding_size, uint patch_filters, ENUM_OPTIMIZATION optimization_type, uint batch) { uint inside_emb = MathMax((embedding_size + 2) / 6, 8); if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, 3 * inside_emb, 3 * inside_emb, embedding_size, patchs * variables, 1, optimization_type, batch)) return false; SetActivationFunction(SoftPlus);
Debemos decir que al construir este objeto, hemos tomado prestadas las mejores ideas del framework Mantis. En lugar de los tamaños de los parches codificados, nuestra clase solo admite como entrada la cantidad de segmentos para el nivel más pequeño y el tamaño de token de salida deseado. Esto ofrece mayor flexibilidad: podemos cambiar rápidamente la granularidad de la aplicación de parches sin editar el código.
Pero hemos ido más allá. Mantis utilizaba una única convolución para generar canales de características, mientras que nosotros hemos implementado una convolución multiventana que crea múltiples niveles de visualización de la señal original. Cuando llega el momento de inicialización, nuestra tarea consiste en calcular el tamaño interno del vector de token para cada uno de los niveles de detalle. El usuario puede indicar cualquier longitud de token en la salida del objeto, pero no siempre será divisible por el número de niveles sin resto. Y aquí es donde entra en juego la clase convolucional principal: esta ajusta cuidadosamente el número de canales al tamaño dado aplicando sus filtros optimizados y asegurando una representación consistente y uniforme de las características.
Al igual que antes, esperamos obtener un tensor bidimensional que describa una serie temporal multimodal como objeto de entrada, donde cada serie supone una descripción detallada de un paso temporal. Pero para que nuestro proceso de parcheo pueda percibir las características individuales como secuencias unitarias separadas, primero transpondremos la matriz de datos de origen.
Esta técnica simple pero importante garantiza que todas las operaciones posteriores funcionen según el estricto principio de una serie, una historia y no mezclen señales de diferentes fuentes. Así mantendremos la integridad y legibilidad de cada serie temporal.
int index = 0; if(!cToVarSeq.Init(0, index, OpenCL, count, variables, optimization, iBatch)) return false;
Luego llega el turno de la convolución multiventana. Ejecutamos tres filtros simultáneamente con tamaños de ventana de 3, 5 y 7 barras y un paso de 1. Gracias al relleno de ceros, la longitud de las series de salida sigue siendo la misma, pero cada valor ahora se enriquece con el conocimiento de sus vecinos inmediatos y su contexto.
index++;
{
int windows[] = {3, 5, 7};
if(!cProjecting.Init(0, index, OpenCL, windows, 1, inside_emb, count, variables,
optimization, iBatch))
return false;
cProjecting.SetActivationFunction(SoftPlus);
}
En esta etapa, hemos formado con éxito las características básicas para un análisis posterior. Ahora nos enfrentamos a la estructuración de estos datos para alimentar los bloques posteriores del modelo, es decir, realizar el parcheo. Pero antes de cortar la serie temporal en segmentos, deberemos realizar una operación técnica importante: reorganizar los últimos ejes en el tensor de cuatro dimensiones resultante.
El tensor formado en el paso anterior tiene la forma [Variable × Longitud de la serie × Número de canales × Número de características], donde cada paso temporal se describe mediante un vector de tres canales obtenidos de diferentes escalas convolucionales. Sin embargo, para trabajar con mayor comodidad con secuencias unitarias que se segmentarán independientemente, necesitamos convertir los datos al formato “[Variable × Número de canales × Número de características × Longitud de la serie]”. Esto permite que cada característica se procese como una secuencia temporal aparte y luego se corte en fragmentos de longitud fija, es decir, en parches.
index++; if(!cToVarProjSeq.Init(0, index, OpenCL, variables, count, 3 * inside_emb, optimization, iBatch)) return false;
Esta presentación resulta especialmente cómoda en los contextos financieros: cada canal, enriquecido con una convolución de multiventana, ahora actúa como un indicador de mercado independiente cuya dinámica se puede analizar en el marco de la aplicación de parches.
A continuación, procederemos al paso clave: la aplicación de parches multiescala, que constituye la base de nuestra arquitectura de preprocesamiento de series temporales. Aquí debemos implementar un concepto inspirado no tanto en los enfoques clásicos, sino en la práctica real del análisis de datos de mercado de alta frecuencia, donde tanto la profundidad de la cobertura como la velocidad de respuesta son importantes.
En lugar de cortar la secuencia en parches de manera rígida y unidimensional, vamos a usar una capa convolucional multiventana que nos permite trabajar en múltiples escalas simultáneamente. Esto le da al modelo la capacidad de observar el mercado desde diferentes marcos temporales, como un analista que observa velas de 1 minuto, gráficos horarios y gráficos diarios simultáneamente.
index++;
{
uint step = (count + patchs) / (patchs + 1);
uint windows[] = {step, 3 * step / 2, 2 * step};
if(!cPatchingProj.Init(0, index, OpenCL, windows, step, patch_filters, patchs,
3 * inside_emb * variables, optimization, iBatch))
return false;
cPatchingProj.SetActivationFunction(SoftPlus);
}
Los tamaños de las ventanas convolucionales, en este caso, se determinan automáticamente: dependen de la longitud de la secuencia temporal analizada y del número de parches especificados por el usuario. En escalas superiores, este valor se amplía con superposición para garantizar la coherencia y la continuidad de la información entre parches.
En el siguiente paso, los parches previamente extraídos se envían al módulo FeedForward multicabeza. Esto no es solo una formalidad: aquí es donde comienza el auténtico trabajo de comprensión. Cada parche obtenido desde diferentes escalas ahora se transforma en una incorporación completa, es decir, en una representación compacta y rica que codifica las características clave del fragmento correspondiente de la serie temporal. El resultado del trabajo del módulo será un conjunto de vectores compactos pero expresivos, cada uno de los cuales puede considerarse la quintaesencia del fragmento temporal correspondiente.
index++; if(!cPatchsFeedForward.Init(0, index, OpenCL, 3 * patch_filters, 6 * patch_filters, patchs, 3 * inside_emb * variables, 3, optimization, iBatch)) return false; index++;
Una vez que hemos obtenido incorporaciones expresivas para cada parche en todas las escalas, empieza la etapa de agregación de datos. Después de todo, para que un modelo forme una visión holística del contexto actual del mercado, necesita combinar información de distintos niveles de detalle en un único vector de características.
Para resolver este problema, usamos una combinación de convolución y pooling máximo. La capa convolucional nos permite identificar dependencias locales entre incorporaciones de diferentes escalas. Actúa como un analista que busca combinaciones características de patrones cortos y largos (por ejemplo, volatilidad a corto plazo en el contexto de una tendencia estable a largo plazo). Estas combinaciones suelen ser clave a la hora de tomar decisiones de trading, especialmente en condiciones de mercado difíciles.
A continuación, los datos pasan a través de un pooling máximo, que selecciona las características más fuertes y expresivas en cada región del tensor resultante. Como resultado, obtenemos un único vector de características agregadas. Es una representación compacta pero significativa de toda la historia de entrada, procesada en múltiples escalas.
index++; if(!cPatchingAgr.Init(0, index, OpenCL, 3 * patch_filters, 3 * patch_filters, patch_filters, patchs, 3 * inside_emb * variables, optimization, iBatch)) return false; cPatchingAgr.SetActivationFunction(SoftPlus); index++; if(!cProof.Init(0, index, OpenCL, patch_filters, patch_filters, 3 * patchs * inside_emb * variables, optimization, iBatch)) return false;
Pero antes de pasar los tokens resultantes a lo largo de la arquitectura, necesitamos ejecutar el paso más importante: transponer el tensor resultante, devolviendo el eje del tiempo al primer lugar.
index++; if(!cToPatchVarEmb.Init(0, index, OpenCL, variables * 3 * inside_emb, patchs, optimization, iBatch)) return false; //--- return true; }
¿Por qué hace falta esto? La cuestión es que en las etapas anteriores (en particular, al formar las incorporaciones y agregar los parches), los datos se presentaban en un formato en el que el foco principal estaba en los parches y las características. Este orden de ejes es cómodo para el procesamiento local, pero no resulta adecuado para mecanismos sensibles al tiempo.
Al devolver el eje del tiempo al principio, organizamos efectivamente los tokens recibidos en orden cronológico. Cada token se percibe ahora como un momento en el tiempo saturado de información de varios niveles de escala a la vez. Esto permite que el modelo perciba los datos como una secuencia temporal completa, en lugar de como un conjunto abstracto de características.
Precisamente de esta forma el tensor pasa a las siguientes etapas de procesamiento, donde entran en juego las dependencias temporales, el análisis del contexto y la generación de pronósticos. Este orden nos permite preservar la relación causal en los datos, sin la cual cualquier intento de modelar el mercado financiero perdería su sentido.
A pesar de la aparente complejidad de la arquitectura interna del objeto, la implementación de los algoritmos de pasada directa e inversa sigue siendo extremadamente sencilla. La lógica de cálculo se organiza paso a paso y secuencialmente, sin ciclos anidados ni ramificaciones complejas. Creo que no resultará difícil entender cómo funcionan estos métodos. Por ello, en este artículo no nos detendremos en su análisis detallado. Si le interesa profundizar en la implementación técnica del objeto CNeuronTimeFoundPatching, el código fuente completo, incluidos todos sus métodos, está disponible como archivo adjunto a este artículo.
Poco a poco nos acercamos al límite razonable para el formato del artículo. El volumen de los materiales ya es considerable. Sin embargo, como comprenderá, nuestro trabajo aún está lejos de concluir. Simplemente hemos sentado las bases e implementado un módulo de preprocesamiento de datos crítico que forma la base para todo el análisis posterior.
Así que nos tomaremos un breve descanso, recuperaremos el aliento y continuaremos nuestro viaje en el próximo artículo, implementando paso a paso los componentes restantes del framework que hemos discutido.
Conclusión
En este artículo, presentamos los aspectos teóricos de TimeFound, un framework capaz de transformar la estructura caótica de los datos de series temporales en un patrón formalizado y predecible.
Hoy hemos comenzado a implementar nuestra propia visión de los enfoques propuestos por los autores del framework. Nos hemos centrado principalmente en el módulo de preprocesamiento de datos, ya que este determina con qué precisión y expresividad percibirá el modelo la estructura de la señal de entrada.
Queda por delante un trabajo igualmente interesante, en el que profundizaremos en el próximo artículo.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | StudyEncoder.mq5 | Asesor | Asesor de entrenamiento del Codificador del entorno |
| 4 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 5 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 6 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 7 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 8 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 9 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18414
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola Dmitry Gizlyk, espero que te vaya muy bien.
¿En qué archivo implementaste la clase CNeuronTimeFoundPatching?
No entiendo, tal vez ya está en una de las carpetas del archivo zip, o es algo que aún no se ha subido como parte de los archivos de este artículo.
Muy interesante este planteamiento, espero ver pronto las siguientes partes (en español, mi lengua materna). Abrazos.
Hola Dmitry Gizlyk, espero que te vaya muy bien.
¿En qué archivo implementaste la clase CNeuronTimeFoundPatching?
No entiendo, tal vez ya está en una de las carpetas del archivo zip, o es algo que aún no se ha subido como parte de los archivos de este artículo.
Muy interesante este planteamiento, espero ver pronto las siguientes partes (en español, mi lengua materna). Abrazos.
Buenas tardes, Miguel.
La clase CNeuronTimeFoundPatching se presenta en la biblioteca NeuroNet.mqh .
Podrías (si es posible) detallar qué librerías complementan el código, ya que faltan muchas dependencias al intentar compilar cualquier archivo
(sólo están presentes los archivos "EXPERTS", pero quizás falten otros archivos, por ejemplo de "include").