
Redes neuronales en el trading: Generalización de series temporales sin vinculación a datos (Mamba4Cast)

Introducción
El mercado es un entorno testarudo y caprichoso. No da una segunda oportunidad a quienes se equivocan al evaluar las señales, especialmente en nuestra época, cuando el flujo de noticias se propaga más rápido de lo que una vela puede destellar en un gráfico de minutos. El tráder moderno no trabaja con el pasado, sino con lo que emerge en el flujo de datos: anticipar la aparición de un patrón antes que demás le da una ventaja. Por consiguiente, el desafío para los algoritmos modernos es solo uno: predecir antes de que se vuelva obvio. Y al mismo tiempo, resulta deseable no ahogarse en las dificultades técnicas de configuración y mantenimiento del modelo.
En esta carrera, los modelos tradicionales, como las arquitecturas recurrentes, ya empiezan a patinar notablemente. Sí, son excelentes para seguir patrones repetitivos y recordar bien secuencias, pero a menudo se pierden en el comportamiento caótico del mercado real. Asimismo, muestran dificultades para captar impulsos, no les gustan las discontinuidades, no soportan bien los valores atípicos y requieren de adaptación a cada nuevo entorno. Hoy en día el mercado requiere una herramienta más flexible y predictiva.
Las arquitecturas basadas en el Transformer han agregado inteligencia y precisión, especialmente para problemas de series temporales largas. Sin embargo, junto con esto trajeron complejidad computacional y volumen arquitectónico. Conforme el volumen de datos crece y el horizonte de planificación se hace más largo, estos modelos se vuelven cada vez menos adecuados para las tareas en tiempo real. En la práctica, esto significa más recursos, más tiempo y más problemas.
En este contexto, surge el framework Mamba4Cast, presentado en el artículo "Mamba4Cast: Efficient Zero-Shot Time Series Forecasting with State Space Models". Este se siente como un soplo de aire fresco y se basa en dos ideas clave: la arquitectura ligera pero expresiva de Mamba y el concepto revolucionario de Prior-data Fitted Networks (PFNs). Juntos, forman la base de una nueva ola de enfoques para la previsión de series temporales, especialmente en industrias dinámicas como el comercio.
El concepto PFN supone una revolución en el pensamiento. A diferencia de los enfoques clásicos, donde un modelo se entrena previamente en un conjunto de datos y luego se somete a un reentrenamiento extenso en otro, las PFN proponen entrenar previamente el modelo en tareas generadas sintéticamente. Es decir, en lugar de una tarea real, el modelo se entrena con un millón de tareas diferentes, aunque imperfectas. Esto lo hace verdaderamente versátil y resistente a nuevos desarrollos. En el trading, esto significa que el modelo no está vinculado a un instrumento o marco temporal específico: es capaz de adaptarse sobre la marcha.
El framework Mamba4Cast usa plenamente el enfoque PFN. Al usar datos generados sintéticamente que cubren una variedad de escenarios, le otorga al modelo un amplio alcance de comportamiento. Gracias a esto, el modelo posee una intuición única: la capacidad de generalizar patrones incluso en condiciones de alta volatilidad y dinámica inestable.
La segunda característica fundamental es la arquitectura Mamba, que posee una complejidad computacional lineal en la longitud de la secuencia. A diferencia de los transformadores, Mamba no requiere operaciones cuadráticas en matrices de atención y, por consiguiente, puede procesar largas secuencias de datos de entrada de manera rápida y eficiente. Lo que resulta especialmente importante para los tráders es que Mamba4Cast puede pronosticar una ventana completa de valores futuros en una sola pasada. Esto reduce drásticamente los errores ocurridos durante el pronóstico autorregresivo y permite responder más rápidamente a los cambios en el panorama del mercado.
Además, al generar pronósticos varios pasos por delante, el modelo resulta ideal para crear estrategias comerciales complejas: desde el análisis de señales hasta decisiones comerciales directas. Mamba4Cast puede convertirse en algo más que un simple punto de referencia, sino en un módulo de pronóstico central completamente desarrollado en un sistema comercial automatizado.
Algoritmo del framework Mamba4Cast
El framework Mamba4Cast supone un paso audaz y prometedor en la evolución de los sistemas de pronóstico de series temporales. Se basa en una combinación de una base matemática rigurosa y algoritmos flexibles de aprendizaje profundo que pueden ver el mercado como un entorno complejo donde el pasado, el presente y el futuro se entrelazan en una sola imagen.
En el enfoque tradicional, los modelos se entrenan con datos históricos de un solo activo y luego repiten los patrones aprendidos. Este enfoque produjo excelentes resultados en su momento, pero hoy enfrenta bastantes limitaciones: los mercados son cada vez más dinámicos y los eventos son cada vez menos predecibles. Mamba4Cast ofrece un enfoque distinto: en lugar de almacenar series temporales específicas, utiliza la técnica PFN (Prior-data Fitted Networks). Imagine que entrenamos a un analista no sobre el precio real de una sola acción, sino sobre innumerables escenarios sintéticos: por ejemplo, tendencias, estancamientos, la calma antes de la tormenta y después una explosión de noticias. De esta manera se forma una inteligencia de mercado universal, lista para actuar “fuera de la caja” en cualquier instrumento.
El corazón de este sistema es la arquitectura Mamba, basada en State Space Modeling. A diferencia de las voluminosas capas de Self-Attention de los transformadores, Mamba opera linealmente en la longitud de la secuencia, lo que permite procesar cientos o miles de puntos temporales sin aumentar los costos computacionales. Esta eficiencia no solo acelera los cálculos, sino que abre la puerta al análisis de datos en tiempo real, donde cada milisegundo cuenta. Esta solución ahorra recursos y hace que el sistema resulte adecuado para procesar flujos de datos en tiempo real en condiciones altamente volátiles.
En la primera etapa, se escala la serie temporal original. Para ello se usa la normalización estándar Min-Max, en la que cada valor x t se transforma según la fórmula:
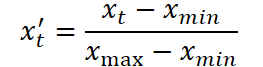
donde xmin y xmax están determinados por el rango dentro de la muestra de entrenamiento. Esto elimina el desequilibrio entre las características de distintas escalas y prepara los datos para un entrenamiento efectivo.
Luego viene la parte clave del preprocesamiento: la codificación posicional. Las marcas temporales como minutos, horas, días de la semana, días del mes, meses y años se extraen por separado y se convierten en representaciones vectoriales. Aquí se usa un esquema de codificación sinusoidal similar a los transformadores, pero adaptado a los componentes periódicos de las series temporales. Para cada componente temporal, se calculan varios armónicos de los senos y cosenos del producto del periodo y las potencias de dos:
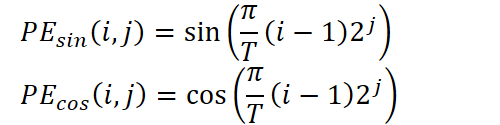
donde T es el periodo del componente correspondiente, i es el índice del punto temporal y j es el índice de frecuencia en el espectro.
Estos vectores codifican dependencias temporales en múltiples escalas, lo cual permite que el modelo capte ciclos diurnos, estacionalidad y fases macroeconómicas.
Después de esto, se concatenan con los valores normalizados de las propias series. El vector resultante representa la incorporación del punto temporal.
El siguiente paso consiste en procesar la secuencia utilizando un conjunto de capas convolucionales causales. Las múltiples convoluciones paralelas con ventanas únicas permiten abarcar diferentes escalas temporales. Cada convolución captura información en su propio nivel: desde las fluctuaciones más locales hasta las tendencias a largo plazo. Los resultados de estas capas se combinan para formar una representación rica y variada para cada punto temporal. Esto resulta especialmente importante en el contexto de los datos financieros, donde la misma vela puede tener un impulso a corto plazo y ser parte de una tendencia de mercado más amplia.
Luego se aplica una proyección en un espacio de alta dimensionalidad, lo cual permite preparar los datos para su transmisión al bloque principal del modelo. Aquí también se incluye una capa inception modificada, que combina convoluciones de diferentes tamaños, uniendo características locales y globales. La activación final en un punto temporal contiene información de distintos niveles de generalización, al tiempo que preserva la dimensionalidad de salida y garantiza la robustez ante omisiones y ruido.
El corazón de la arquitectura son bloques basados en el módulo Mamba, una implementación innovadora de State Space Models (SSM) con complejidad lineal en la longitud de secuencia. Cada bloque implementa una estructura SSM generalizada, donde el estado oculto se actualiza a través de las matrices A, B, C, D entrenadas junto con otros parámetros del modelo:
![]()
Por tanto, cada momento en el tiempo depende del estado anterior y de la entrada actual. Esto garantiza una memoria estable a largo plazo y una adaptación flexible al contexto actual. Después de cada capa, se aplica la Layer Normalization, que elimina los sesgos y normaliza la distribución de activaciones, lo cual hace que el entrenamiento sea más estable. A esto le sigue otra capa convolucional causal, que mantiene el flujo de información a lo largo del eje temporal.
El número de estos bloques en la pila puede variar según la profundidad de generalización requerida. Los niveles inferiores se especializan en captar patrones cortos: retrocesos rápidos, impulsos y fluctuaciones de noticias. Los bloques superiores ofrecen información sobre los ciclos del mercado, los movimientos estacionales y los patrones recurrentes. La pila funciona como un espectro neuronal donde cada nivel es responsable de su propio rango de frecuencias temporales.
La etapa final es la decodificación. Todas las activaciones recibidas se proyectan usando una capa lineal en uno o más canales de salida. Si se requiere una estimación de incertidumbre adicional, se utiliza un encabezado aparte que predice la varianza en una escala logarítmica:
![]()
Para los problemas de clasificación se usa una cabeza SoftMax, que produce las probabilidades de las clases analizadas.
La característica única de Mamba4Cast es su capacidad de generalización Zero-Shot. Para lograrlo, los autores propusieron una etapa única de entrenamiento previo con un gran conjunto de datos sintéticos. Este incluye series temporales generadas por ecuaciones diferenciales estocásticas ( SDE ), patrones especificados manualmente (reversiones, consolidaciones, impulsos) e incluso reglas generativas aleatorias.
El modelo se entrena usando varias funciones de pérdida a la vez: error cuadrático medio, verosimilitud logarítmica negativa y entropía cruzada de cambio de modo. Esto nos permite desarrollar una visión sólida y universal de los patrones del mercado que pueda adaptarse a nuevos activos y escalas temporales.
Todo esto hace que Mamba4Cast no sea solo un modelo experimental, sino una base completa para construir sistemas comerciales predictivos, algoritmos para evaluar las fases del mercado y pronosticar la volatilidad.
A continuación le presentamos la visualización del framework Mamba4Cast por parte del autor.
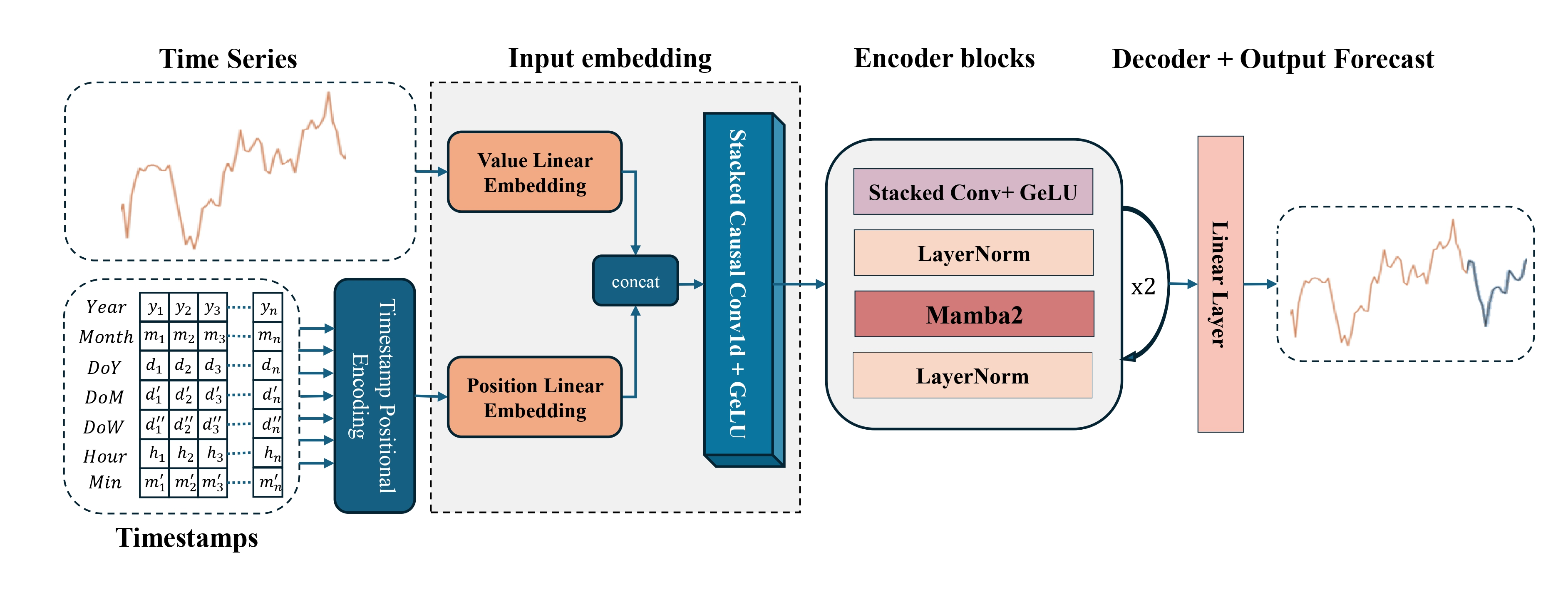
Implementación con MQL5
Después de una inmersión profunda en la arquitectura de Mamba4Cast, vamos a abordar la verdadera esencia del tema: la implementación práctica de los bloques clave del framework utilizando MQL5. Y en primer lugar, debemos abordar el objeto de la codificación posicional, sin el cual ningún modelo predictivo moderno será capaz de percibir correctamente la secuencia analizada como una escala temporal real.
Nuestra biblioteca ya contiene implementaciones clásicas de incorporaciones posicionales (desde simples de seno-coseno hasta tablas entrenables), pero todas ven una serie temporal como un conjunto de elementos consecutivos, sin tener en cuenta el momento de la adquisición de datos del entorno. Mientras tanto, los autores de Mamba4Cast insisten en que cada paso debe codificarse teniendo en cuenta el periodo real: minuto, hora, día de la semana, día del mes, mes e incluso el año; todo esto afecta la dinámica del mercado. Su enfoque consiste en construir una descomposición sinusoidal única para cada componente temporal, y es a esta contabilidad temporal profunda a la que dedicaremos el primer bloque de trabajo práctico.
Este paso define realmente cómo el modelo verá el tiempo: no solo una secuencia de barras, sino un flujo vivo de eventos con momentos claramente definidos. Sin un registro temporal preciso, incluso el algoritmo más avanzado carecerá de sentido; después de todo, el mercado reacciona de manera completamente diferente al minuto, la hora y el día.
Codificación temporal en el lado de OpenCL
En nuestra implementación, en lugar del enfoque atractivo pero engorroso de las tablas de funciones armónicas precalculadas, vamos a usar el kernel OpenCL para calcular instantáneamente la codificación posicional basada en marcas temporales reales. Esta solución elimina la necesidad de almacenar grandes arrays de valores de seno y coseno en la memoria, elimina los escalones al pasar de un punto a otro y simplifica al máximo la lógica del asesor.
En nuestro enfoque, cada paso temporal llega al núcleo OpenCL con dos conjuntos informativos: las características numéricas (precio, volumen, indicadores) y la hora del evento. Precisamente este momento convertimos en un vector que le dice al modelo cuándo ha ocurrido: en medio de una sesión o en la tranquilidad del mediodía de un fin de semana, a principios de mes o en vísperas de un nuevo año.
Los beneficios de este método se sienten inmediatamente. En primer lugar, obtenemos una codificación posicional absolutamente fluida: ningún salto entre índices adyacentes violará la integridad de las incorporaciones. En segundo lugar, la ausencia de tablas implica menos código, menos errores de sincronización y menos memoria asignada en la plataforma. En tercer lugar, los cálculos sobre la marcha hacen que la incorporación resulte aún más relevante: no hay necesidad de reconstruir tablas al cambiar configuraciones o periodos: simplemente cambiamos los valores del periodo y el modelo se adapta instantáneamente a los nuevos requisitos.
El algoritmo para añadir la codificación temporal a los datos analizados en el lado del núcleo OpenCL consiste en rodear cada barra con su propio vector armónico, reflejando en qué punto de cada uno de los ciclos se ha formado. Los parámetros del kernel TSPositionEncoder pasan los punteros a tres arrays:
- los datos de origen data,
- el array de marcas temporales time,
- el array de periodos period, que especifica la duración de cada ciclo del calendario.
__kernel void TSPositonEncoder(__global const float2* __attribute__((aligned(8))) data, __global const float* time, __global float2* __attribute__((aligned(8))) output, __global const float* period ) { const int id = get_global_id(0); const int freq = get_global_id(1); const int p = get_global_id(2); const int total = get_global_size(0); const int freqs = get_global_size(1); const int periods = get_global_size(2);
Planeamos ejecutar este kernel en un espacio de tareas tridimensional:
- el tamaño de la secuencia analizada (número de pasos temporales),
- el número de armónicos para cada periodo,
- el número de periodos.
Y en el cuerpo del kernel identificamos inmediatamente el flujo actual de operaciones en todas las dimensiones del espacio de tareas.
Primero, para cada punto temporal (índice id ) y para cada armónico (freq) en el periodo (p), el núcleo calcula la coordenada dentro del periodo: el tiempo real se divide por la longitud del ciclo, convirtiendo el valor absoluto time[id] en el número de periodos completos, y luego se multiplica la parte fraccionaria por π y por la potencia de dos 2^(freq+1). Esto nos permite obtener el argumento val para el seno y el coseno, donde el primer armónico cubre todo el ciclo, el segundo lo divide en dos, el tercero en cuartos, y así sucesivamente.
const int shift = id * freqs + freq; const float2 d = data[shift * periods + p]; const float t = time[id] / period[p]; float val = M_PI_F * t * pow(2.0f, freq + 1);
Luego, este valor se añade a la incorporación original: El flujo OpenCL carga un par de números a partir de los datos data correspondientes al tiempo, el armónico y el ciclo actuales, y luego incrementa la primera mitad de este par en sin(val) y la segunda mitad en cos(val). El vector resultante se guarda en el búfer output. Es esta operación la que colorea cada punto de la serie temporal con características adicionales que indican claramente su posición en los patrones del calendario.
output[shift * periods + p] = (float2)(d.s0 + sin(val), d.s1 + cos(val)); }
La ventaja de este enfoque es que el cálculo se realiza sobre la marcha, directamente en el núcleo de la GPU, sin acceder a tablas grandes y sin la lógica en el lado de la CPU. Cualquier cambio (por ejemplo, la adición de un nuevo periodo o el aumento del número de armónicos) se reduce a ajustar las dimensiones de la cuadrícula de flujo tridimensional y los valores en el array periods. Al mismo tiempo, mantenemos una suavidad absoluta: el seno y el coseno garantizan una representación continua del tiempo, y el paralelismo de la GPU nos permite procesar una gran cantidad de puntos a la vez sin retrasos.
Como resultado, cada evento recibe su propia incorporación única, considerando no solo el precio o el volumen, sino también el momento exacto en que ha ocurrido el evento. Esto le da a Mamba4Cast una profundidad de contexto completa y hace que el algoritmo de predicción resulte verdaderamente consciente del tiempo.
Dado que las marcas temporales de los eventos en nuestra aplicación no son parámetros entrenables, su procesamiento requiere solo la pasada directa (el paso de cálculo de los vectores de incorporación en el kernel OpenCL ). No necesitamos distribuir los gradientes de error a lo largo del tiempo ni actualizar las etiquetas en sí. Esto nos permite eliminar los procesos de pasada inversa, simplificando al máximo la arquitectura y reduciendo el cálculo de la codificación posicional a una función puramente determinista del tiempo.
Objeto de codificación temporal
En el lado principal del programa, los algoritmos para la codificación temporal de la secuencia analizada se implementan en la clase CNeuronTSPositionEncoder, cuya estructura se presenta a continuación.
class CNeuronTSPositionEncoder : public CNeuronBaseOCL { protected: CNeuronConvOCL cProjection; CNeuronBatchNormOCL cNorm; CBufferFloat cPeriods; //--- virtual bool AddPE(CBufferFloat *time); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronTSPositionEncoder(void) {}; ~CNeuronTSPositionEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint &periods[], uint freqs, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronTSPositionEncoder; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual uint GetWindow(void) const { return cProjection.GetWindow(); } virtual uint GetWindowOut(void) const { return cProjection.GetFilters(); } virtual uint GetUnits(void) const { return cProjection.GetUnits(); } };
En la estructura presentada, llaman inmediatamente la atención tres objetos internos que parecen redundantes dada la implementación de la codificación temporal en el lado de OpenCL. Sin embargo, estos son responsables de garantizar que cualquier secuencia de datos analizada esté perfectamente empaquetada y escalada antes de darle contexto temporal.
En primer lugar, cProjection toma como entrada absolutamente cualquier array de características que provengan de la capa anterior de la red neuronal y las convierte en vectores planos de dimensionalidad fija. Esto permite que otras partes del código no tengan que preocuparse por cuántas características hay dentro de un conjunto de datos determinado y cómo están agrupadas: la salida de cProjection siempre tiene una forma predecible, lista para la normalización por lotes y la codificación posicional.
En segundo lugar, cNorm actúa como garante de la estabilidad. En la práctica, los precios, los volúmenes y cualquier señal estocástica pueden saltar dentro de un rango de valores. Si mezclamos valores de seno-coseno en el rango [-1,1] inmediatamente después de la proyección, parte de la información corre el riesgo perderse. Para evitar que esto suceda, pasamos la salida de cProjection a través de una norma de lote, estableciendo la media en cero y la varianza en uno. Solo después de esto dejamos entrar los armónicos del tiempo. Es precisamente en este orden que las características temporales se convierten en una superestructura orgánica sobre los datos ya procesados, y no en ruido caótico.
Finalmente, cPeriods almacena un conjunto constante de periodicidades de ciclos temporales.
Es esta separación de preocupaciones lo que hace que la clase sea simultáneamente flexible (admite cualquier entrada), robusta (siempre alinea todo a una forma estable) y precisa (permitiendo una continuidad absoluta de la codificación temporal).
Para transformar la clase CNeuronTSPositionEncoder de una construcción declarativa a un nodo de trabajo real, todos sus componentes internos deben inicializarse de forma correcta. Este es precisamente el problema que resuelve el método Init.
bool CNeuronTSPositionEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint &periods[], uint freqs, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, 2 * units_count * freqs * periods.Size(), optimization_type, batch)) return false;
El método sigue estrictamente la lógica de arquitectura descrita anteriormente: proyección → normalización → adición de características temporales.
En la primera etapa, llamamos al método homónimo de la clase padre. Este especifica los parámetros generales del objeto. Tenga en cuenta que al indicar el tamaño del tensor de resultado, multiplicamos el producto de los parámetros obtenidos por 2. La razón de esto es la presentación de cada armónico temporal como dos componentes: seno y coseno.
Luego inicializamos el búfer de ciclos temporales. Su frecuencia se indica en segundos.
cPeriods.BufferFree(); if(!cPeriods.AssignArray(periods) || !cPeriods.BufferCreate(OpenCL)) return false;
A continuación, inicializamos la capa de proyección de los datos de origen en un espacio dimensional fijo: 2 × frecuencias × periodos. Este tamaño corresponde al número de canales que queremos dotar de características temporales. Básicamente, estamos configurando filtros que prepararán cada fragmento de la serie temporal para la adición de fases temporales.
int index = 0; if(!cProjection.Init(0, index, OpenCL, window, window, 2 * freqs * cPeriods.Total(), units_count, 1, optimization, iBatch)) return false; cProjection.SetActivationFunction(TANH);
El uso de la función de activación TANH en la etapa de proyección no es solo una elección estilística, sino una forma práctica de limitar la amplitud de los valores de salida al rango [-1;1]. Y esto ofrece varias ventajas importantes a la vez.
Si los datos de origen contienen ruido, saltos y extremos, TANH actúa en cambio como un limitador ligero, suavizando las desviaciones fuertes y haciendo que el comportamiento del modelo sea más estable. Esto resulta especialmente importante en entornos de series temporales financieras, donde las velas repentinas o los picos de volumen pueden desorientar a toda la red.
Además, la función TANH ofrece una derivada suave en todo el rango de entradas, lo cual resulta importante para una mayor propagación del gradiente. Esto reduce el riesgo de adherencia de las neuronas y promueve una convergencia más estable y rápida.
Una vez completada la convolución, su resultado se transmite a cNorm, donde se igualan los valores medios y la escala. Esto evita que las señales seno-coseno se pierdan en amplitudes demasiado grandes y garantiza la fiabilidad de la codificación temporal.
index++; if(!cNorm.Init(0, index, OpenCL, cProjection.Neurons(), iBatch, optimization)) return false; cNorm.SetActivationFunction(None);
Un toque final: dado que la codificación temporal no supone un nodo que se pueda entrenar en el sentido clásico, vamos a deshabilitar la activación global y simplemente pasaremos los gradientes de las interfaces externas a cNorm.
SetActivationFunction(None); if(!SetGradient(cNorm.getGradient(), true)) return false; //--- return true; }
Pasando a la implementación de la pasada directa en la clase CNeuronTSPositionEncoder, vale la pena enfatizar que esta etapa es la conclusión lógica de todo el procedimiento de codificación temporal. Aquí es donde la información proyectada y normalizada sobre la secuencia original se combina con la estructura temporal detallada como armónicos calculados según el tiempo real de recepción de datos.
El método feedForward divide claramente el proceso en tres etapas secuenciales. Tenga en cuenta que los parámetros del método pasan los punteros a dos fuentes de datos. El flujo de información principal presenta la secuencia analizada y el segundo presenta marcas temporales.
bool CNeuronTSPositionEncoder::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cProjection.FeedForward(NeuronOCL)) return false;
En primer lugar, se llama al método de pasada directa de la capa de proyección de datos de origen. En esta etapa, los datos iniciales de cualquier dimensionalidad se reducen a un número determinado de características, asegurando la consistencia de las dimensionalidades para la posterior imposición de un número determinado de armónicos de información temporal.
Las proyecciones resultantes pasan luego a través de una capa de normalización.
if(!cNorm.FeedForward(cProjection.AsObject())) return false;
El propósito de la normalización consiste suavizar las diferencias estadísticas entre las características de los datos analizados y prepararlos para la suma con armónicos temporales.
Y finalmente, el paso final consiste en llamar al método de envoltorio del kernel de codificación temporal descrito anteriormente, que en tiempo real, para cada paso temporal y cada frecuencia especificada, calcula los armónicos seno-coseno basándose en el valor actual de la marca temporal y un conjunto de periodos especificados.
return AddPE(SecondInput);
}
Esta operación no depende de los parámetros a entrenar y no requiere propagación de gradiente, ya que el tiempo es un factor externo y determinista.
El resultado es una representación rica que combina tanto las características sustanciales de los datos como el contexto preciso del momento en que se recibieron los datos, no según el número ordinal, sino según el ritmo real de los acontecimientos.
Los procesos de pasada inversa en la clase CNeuronTSPositionEncoder son extremadamente lacónicos en su estructura, pero no pierden su importancia. Todos los cálculos se reducen al esquema clásico de propagación del gradiente de error al nivel de los datos de origen. El flujo principal de cálculos pasa por dos componentes clave: la capa de proyección (cProjection) y la capa de normalización (cNorm). Cada uno de ellos contiene parámetros entrenables y requiere la optimización correspondiente.
En la práctica, esto significa que al llamar a los métodos updateInputWeights y calcInputGradients, nuestro objeto solo delega secuencialmente el control a los métodos correspondientes de los componentes internos.
Este enfoque garantiza la modularidad y la repetibilidad de la lógica: los cambios en el mecanismo de aprendizaje de una capa particular se propagan automáticamente por todo el sistema sin necesidad de reescribir el código de nivel superior. Esto resulta especialmente importante en el contexto de arquitecturas de redes neuronales escalables.
Sin embargo, hay un punto importante que debemos señalar. Aunque el método feedForward toma dos flujos de información: la secuencia original principal y un array de marcas temporales. En el proceso de propagación inversa del error solo interviene el flujo de información principal. Y esto está absolutamente justificado.
La razón es que la codificación temporal en CNeuronTSPositionEncoder no tiene parámetros entrenables. Representa una operación fija y determinista sobre una marca temporal. Además, deliberadamente no propagamos el gradiente de error al nivel de la marca temporal. Estos valores son externos al modelo y no deberían cambiar como resultado de la optimización.
Esta lógica hace que la arquitectura no solo sea limpia y estable, sino también lógicamente consistente: los datos temporales se utilizan para la contextualización, pero no para el aprendizaje.
El código completo de esta clase y todos sus métodos se ofrece en el archivo adjunto.
Poco a poco nos hemos ido acercando a los límites razonables del formato del artículo. Hemos desmontado los componentes centrales de la codificación temporal, hemos implementado las ideas clave e incorporado la arquitectura de capas de forma clara y coherente en el código. Pero, como dicen, no hay que hacer todo de golpe.
Nuestra implementación aún está incompleta. Hay mucho trabajo por delante que requiere un enfoque tranquilo y reflexivo. Tomemos un pequeño descanso, recuperemos el aliento y continuemos en el siguiente artículo.
Conclusión
En este artículo, hemos presentado el framework Mamba4Cast, diseñado para resolver uno de los problemas fundamentales en el análisis de series temporales: la construcción de un modelo flexible y escalable capaz de dar cuenta de la compleja estructura de las series temporales dinámicas. Asimismo, hemos visto cómo los autores del framework abordaron las limitaciones tradicionales de los modelos clásicos integrando enfoques constructivos de vanguardia, incluidos los modelos de espacio de estados (SSM) extendidos por el mecanismo de convolución causal, y complementando esto con una codificación posicional precisa basada en marcas temporales del mundo real.
Además, hemos profundizado gradualmente en la estructura del framework, examinando con detalle la lógica detrás de la formación de características temporales. También hemos analizado cómo, utilizando funciones armónicas simples pero potentes, podemos transformar marcas temporales simples en incorporaciones significativas que reflejen la naturaleza cíclica de los procesos del mercado. Utilizando una implementación de OpenCL como ejemplo, vamos a analizar cómo dichas incorporaciones pueden obtenerse de manera eficiente directamente en el núcleo informático, sin tablas ni demoras adicionales.
Pero nuestro trabajo aún no ha terminado: lo continuaremos en el próximo artículo, donde mostraremos cómo las incorporaciones temporales interactúan con los bloques constructivos del modelo, asegurando la integridad del análisis y aumentando la precisión de los pronósticos.
Enlaces
- Mamba4Cast: Efficient Zero-Shot Time Series Forecasting with State Space Models
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 4 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18116
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso