
Redes neuronales en el trading: Generalización de series temporales sin vinculación a datos (Módulos básicos del modelo)

Introducción
En el artículo anterior, presentamos el framework Mamba4Cast y sus componentes básicos: El módulo SSM y los mecanismos de Prior‑data Fitted Networks (PFNs). Este framework establece una sólida base para la previsión de series temporales y puede convertirse en una herramienta poderosa en el arsenal de los tráderes.
Mamba4Cast no ha sido diseñado para un largo periodo de calentamiento en cada nueva serie temporal, sino para un funcionamiento inmediato. Gracias al concepto de pronóstico Zero-Shot, el modelo es capaz de producir inmediatamente pronósticos de alta calidad sobre datos reales sin entrenamiento adicional ni ajuste de hiperparámetros. Y el tráder ya no necesita pasar días seleccionando los parámetros óptimos.
La alta velocidad del modelo se basa en la complejidad lineal de los módulos SSM. A diferencia de los transformadores, cuya complejidad computacional crece de forma cuadrática con la longitud de la secuencia, cada paso en Mamba4Cast se procesa en tiempo constante. Esto garantiza una inferencia instantánea incluso para secuencias muy largas y una latencia mínima durante la inferencia. En un mundo donde la velocidad en la toma de decisiones a veces puede determinar el resultado de una transacción, esta ventaja resulta difícil de sobreestimar.
Además, Mamba4Cast produce inmediatamente un pronóstico completo para el horizonte especificado completo, en lugar de generarlo paso a paso. Este enfoque evita la acumulación de errores típicos de los modelos autorregresivos y asegura trayectorias más estables de desarrollos de eventos futuros. La estrategia comercial obtiene de inmediato una imagen completa, lo que significa que podemos contar con decisiones seguras y sin reservas.
No menos importante es el método de entrenamiento en escenarios sintéticos. Al modelo se le han suministrado millones de series generadas artificialmente. Gracias a esto, Mamba4Cast ha adquirido una intuición universal y ha aprendido a trabajar de forma fiable en una amplia variedad de condiciones. Este enfoque lo hace resistente al ruido y a los cambios repentinos. Como consecuencia de ello, se reduce el riesgo de fallos inesperados durante su explotación.
A pesar del poder de sus mecanismos fundamentales, Mamba4Cast sigue resultando eficiente en el uso de recursos. Los experimentos realizados por los autores del framework han demostrado que, si bien logra una precisión comparable a la de los modelos de transformadores fundamentales modernos, requiere una potencia de procesamiento significativamente menor. Esto permite su inicio incluso en infraestructuras limitadas y su integración directa en el terminal comercial sin necesidad de potentes clústeres de GPU.
Es su combinación de disponibilidad instantánea, velocidad de inferencia récord, pronóstico holístico, robustez ante el ruido y eficiencia de recursos lo que hace de Mamba4Cast una herramienta verdaderamente revolucionaria en el campo del pronóstico de series temporales.
A continuación le presentamos la visualización del autor del framework Mamba4Cast.
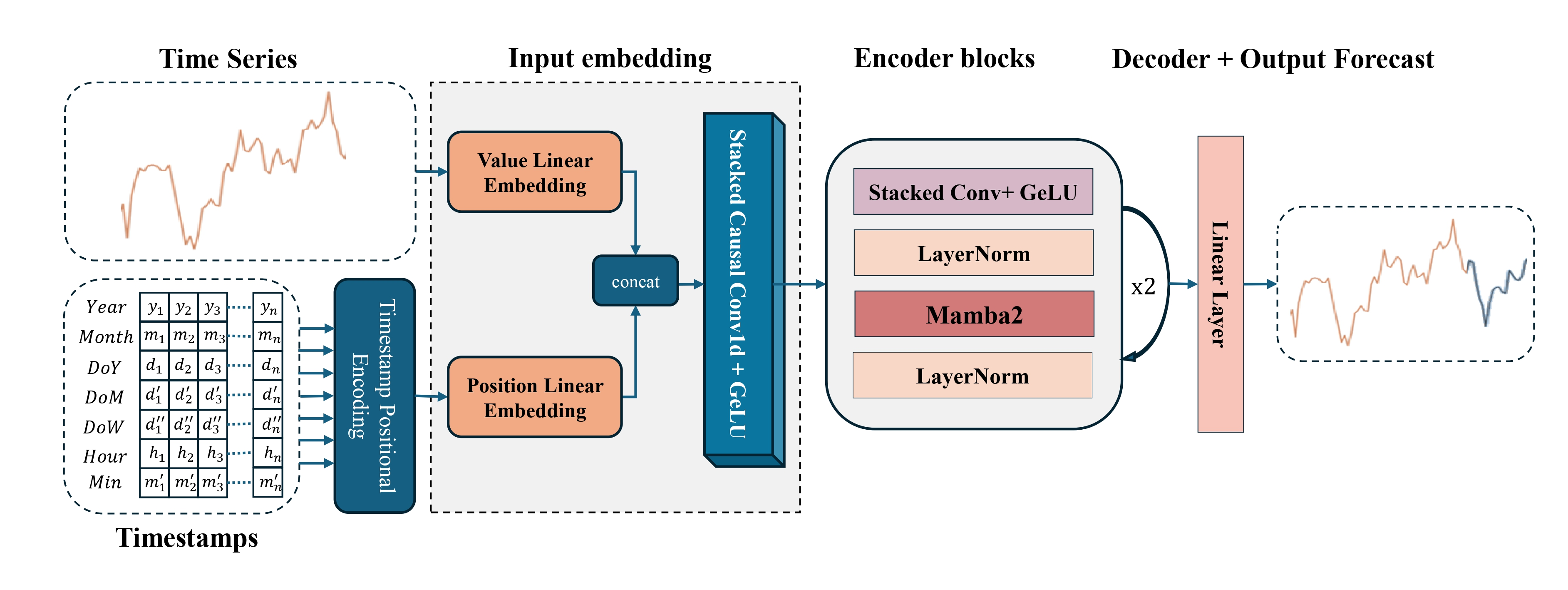
En la parte práctica del artículo anterior, concluimos con la construcción de un objeto de codificación temporal, el elemento clave responsable de la representación posicional de los datos de origen en una secuencia temporal. Este componente se convirtió en el cierre lógico del proceso general de inicialización del modelo y en una parte importante de la preparación constructiva de la señal analizada. Sin ella, el framework simplemente no podría distinguir correctamente entre las dependencias temporales.
Hoy continuaremos nuestro trabajo desde ese mismo lugar.
Módulo de preprocesamiento
La lógica detrás de este desarrollo es simple: antes de realizar cualquier cálculo, pronosticar movimientos de precios o generar señales comerciales, los datos deben prepararse de la forma adecuada. Al igual que ocurre con cualquier sistema de aprendizaje automático, el éxito del modelo Mamba4Cast depende directamente de la calidad del flujo de datos analizado. Si los datos de entrada contienen ruido, valores de diferentes escalas o estructuras irregulares, ni siquiera la arquitectura más avanzada podrá salvarlo. Por consiguiente, nuestro enfoque se centrará en el bloque de preprocesamiento de datos.
Este módulo no es solo un paso de soporte: sirve como vínculo entre los datos de origen del mercado y las entradas cuidadosas que el modelo puede interpretar. En él se realiza la normalización, el escalado, el uso de ventanas, el enmascaramiento y, fundamentalmente, la contextualización de los datos a través de canales adicionales. Todo esto preparará la información analizada para su procesamiento dentro del modelo principal y sentará las bases sobre las que se construirán los futuros pronósticos.
Nuestra tarea no consiste simplemente en cargar los datos de origen en forma de cotizaciones y lecturas de los indicadores analizados. Necesitamos llevarlos a una sola escala, identificar los límites de las ventanas completas, resaltar las máscaras de valores no disponibles y sincronizar todos los canales en el tiempo. Solo después de esto podemos transferir los datos al Codificador y esperar que se interpreten correctamente.
En la parte práctica del artículo anterior, completamos la construcción del objeto de codificación temporal, uno de los componentes clave del bloque de preprocesamiento de datos, que juega un papel importante en la arquitectura de Mamba4Cast. Este elemento permite al modelo percibir la secuencia de eventos del mercado no como un conjunto abstracto de números, sino como información estructurada con un cierto orden y ritmo.
Para implementar el enfoque propuesto, construiremos la clase especializada CMamba4CastEmbeding, que ocupa un lugar central en el bloque de preprocesamiento de los datos de origen. La estructura del mecanismo se resume a continuación.
class CMamba4CastEmbeding : public CNeuronBaseOCL { protected: CNeuronConvOCL cProjection; CNeuronBatchNormOCL cNorm; CNeuronTSPositionEncoder cProjectionWithTE; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CMamba4CastEmbeding(void) {}; ~CMamba4CastEmbeding(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint &periods[], ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defMamba4CastEmbeding; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
La idea principal consiste en transformar el flujo de información de origen en un esquema estructurado e informativo adecuado para las etapas posteriores de la previsión. Para lograr esto, utilizamos un enfoque modular: una clase combina varios módulos especializados, cada uno de los cuales es responsable de una transformación de datos específica.
Cabe señalar que todos los objetos internos de la clase CMamba4CastEmbeding se declaran estáticamente. Esto permite que el constructor y el destructor de la clase permanezcan vacíos, ya que no se requiere gestión de memoria dinámica: los objetos se crean y se destruyen de manera automática. Esta característica constructiva simplifica la lógica del ciclo de vida del objeto y reduce el riesgo de pérdidas de memoria y posibles errores asociados con la asignación de memoria dinámica, lo cual resulta extremadamente importante en los sistemas comerciales de alto rendimiento.
La inicialización directa de todos los módulos internos se realiza en el método Init, en cuyos parámetros obtenemos las características principales del objeto creado.
bool CMamba4CastEmbeding::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint &periods[], ENUM_OPTIMIZATION optimization_type, uint batch) { if(periods.Size() <= 0) return false; int freqs = (int(window_out / 2 + 2 * periods.Size()) - 1) / int(2 * periods.Size()); if(freqs <= 0) return false;
El cuerpo del método primero comprueba la presencia de datos en el array de periodos de series temporales analizados. Esto es necesario porque la codificación temporal requiere la presencia de al menos un periodo para un cálculo correcto. Y luego se calcula inmediatamente el valor del parámetro freqs, que representa el número de armónicos de frecuencia para cada periodo.
La lógica para determinar el valor de este parámetro requiere una explicación aparte. Uno de los parámetros del método de inicialización (window_out) especifica la dimensionalidad del vector de incorporación de un paso temporal. Como mencionamos anteriormente, el mismo segmento temporal de datos debe presentarse en dos formas: como un valor puro sin considerar el tiempo y en combinación con características temporales integradas en forma de componentes armónicos. De esta forma la incorporación final contiene ambos tipos de representación. Pero solo tenemos una cantidad de memoria asignada para esta representación. Por consiguiente, para codificar el componente temporal, podemos utilizar solo la mitad del tamaño de incorporación especificado por el usuario. La segunda mitad está reservada para la proyección normal de los datos de origen.
Vamos a analizar ahora cómo se distribuye exactamente esta mitad entre los componentes de frecuencia del codificador temporal. Los autores del framework Mamba4Cast utilizaron un enfoque similar a la codificación posicional en transformadores: para cada periodo dado, se crean funciones seno y coseno que describen la fase y la frecuencia de las oscilaciones. Por consiguiente, para cada componente de frecuencia del periodo hay dos armónicos: seno y coseno. Esto significa que el número total de componentes de frecuencia debe ser al menos el doble del número de periodos especificados en el array.
Para evitar confusiones, la fórmula aquí es simple pero requiere cierta atención por nuestra parte: así, dividimos la mitad de window_out por el doble del número de periodos especificados. El número resultante muestra cuántos componentes de frecuencia se pueden generar para cada periodo. Y este número deberá ser estrictamente mayor que cero, porque si resulta ser igual a cero, el modelo no podrá crear ni un solo armónico, lo cual significa que la codificación temporal simplemente no se llevará a cabo.
En la práctica, esto significa que al establecer el tamaño de incorporación de un paso temporal, no se debe actuar por el deseo de aumentar el modelo, sino por la necesidad real de abarcar cada uno de los periodos con al menos un par de armónicos.
A continuación, llamamos al método homónimo de la clase padre, donde ya está organizado el proceso de inicialización de objetos e interfaces heredados.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * units_count, optimization_type, batch)) return false;
Y después de ejecutarlos con éxito, procederemos a inicializar secuencialmente los módulos internos de nuestra clase. Primero, inicializamos la capa convolucional para proyectar los datos de origen en una representación compacta (cProjection).
int index = 0; if(!cProjection.Init(0, index, OpenCL, window, window, window_out - 2 * freqs * periods.Size(), units_count, 1, optimization, iBatch)) return false; cProjection.SetActivationFunction(TANH);
Este objeto es responsable de generar la incorporación de los datos de origen sin el componente temporal. Después utilizamos la función de activación TANH para realizar una transformación no lineal de los datos, lo cual sirve de ayuda al extraer características significativas ocultas en los datos numéricos sin procesar y minimizar el impacto de los valores atípicos.
La capa de normalización por lotes (cNorm) corrige los valores obtenidos, eliminando posibles desplazamientos y asegurando la estabilidad de los cálculos.
index++; if(!cNorm.Init(0, index, OpenCL, cProjection.Neurons(), iBatch, optimization)) return false; cNorm.SetActivationFunction(None);
La funcionalidad de generación de incorporaciones con componentes temporales recae en el módulo de codificación temporal (cProjectionWithTE), lo cual resulta especialmente relevante para la predicción de tendencias estacionales y cambios dinámicos en el comportamiento del mercado.
index++; if(!cProjectionWithTE.Init(0, index, OpenCL, window, units_count, periods, freqs, optimization, iBatch)) return false; SetActivationFunction(None); //--- return true; }
Dentro de la lógica del framework, la ejecución secuencial de las etapas de inicialización garantiza que cada submódulo reciba los parámetros coordinados correctamente, lo que permite integrar de manera eficiente la información temporal con los datos de origen.
Una de las etapas clave del bloque CMamba4CastEmbedding es la ejecución del método feedForward, un mecanismo que asegura la pasada directa de los datos a través de todos los enlaces de la arquitectura de preprocesamiento. Es aquí donde se sientan las bases para que los módulos posteriores puedan basarse no solo en datos de origen, sino en representaciones bien preparadas que ya tienen en cuenta tanto la estructura de la señal original como su contexto temporal.
bool CMamba4CastEmbeding::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cProjection.FeedForward(NeuronOCL)) return false;
El proceso comienza con el envío de los datos a analizar al módulo cProjection. Es un bloque convolucional compacto cuya tarea principal es proyectar la señal original en el espacio de características latentes. Este paso permite que el sistema se centre de inmediato en los cambios más pronunciados y significativos en el flujo de entrada.
Luego las características obtenidas se pasan al módulo cNorm. Esta es una capa de normalización que lleva los valores a una escala estable, eliminando saltos, valores atípicos y posibles desplazamientos en la distribución.
if(!cNorm.FeedForward(cProjection.AsObject())) return false;
Sin normalización, las arquitecturas profundas con frecuencia comienzan a salirse de escala o, por el contrario, pierden el gradiente de señal. Aquí, la normalización actúa como una especie de estabilizador, nivelando el comportamiento del modelo en el entrenamiento y el pronóstico.
No obstante, la peculiaridad de la arquitectura de Mamba4Cast radica en el siguiente flujo de información. Paralelamente, los datos de origen se transfieren a cProjectionWithTE, el módulo responsable de la codificación temporal.
if(!cProjectionWithTE.FeedForward(NeuronOCL, SecondInput)) return false;
A diferencia de la proyección inicial, donde solo se usan convoluciones, aquí se conecta adicionalmente una segunda entrada: SecondInput. Precisamente a través de esta las marcas temporales, previamente preparadas para cada paso temporal, se envían para su procesamiento. Esto permite que el módulo no se base simplemente en los valores, sino que considere el contexto temporal específico en el que surgieron, aumentando la sensibilidad del modelo a los componentes estacionales, cíclicos y de fase del mercado.
La culminación de este proceso es la operación de unificación. Las representaciones finales obtenidas de los dos flujos de información se unen en un único tensor mediante la concatenación.
if(!Concat(cNorm.getOutput(), cProjectionWithTE.getOutput(), Output, cProjection.GetFilters(), cProjectionWithTE.GetWindowOut(), cProjection.GetUnits())) return false; //--- return true; }
El resultado es una representación densa y de múltiples capas de cada paso temporal que contiene características directas y una estructura temporal enriquecida. Y es precisamente esta representación de la secuencia temporal la que se convierte en la base de todo el trabajo posterior del modelo.
Como ya sabemos, la transmisión directa de señales por sí sola resulta insuficiente para entrenar un modelo de red neuronal. Para que el modelo se adapte a los datos, debemos organizar una correcta propagación inversa del error. Este es exactamente el problema que resuelve el método calcInputGradients. En esencia, se trata de un mecanismo de análisis de errores internos que se inicia cuando el modelo ha generado un pronóstico y ahora debe comprender exactamente dónde ha cometido un error y cómo se puede corregir.
bool CMamba4CastEmbeding::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
En primer lugar, el método comprueba con qué objeto está trabajando. Aquí debemos asegurarnos de que todos los elementos involucrados en el cálculo de los gradientes se inicialicen correctamente. Después de ello, entra en juego el método DeConcat, diseñado para descomponer el vector de gradiente previamente combinado en 2 flujos de información.
if(!DeConcat(cNorm.getGradient(), cProjectionWithTE.getGradient(), Gradient, cProjection.GetFilters(), cProjectionWithTE.GetWindowOut(), cProjection.GetUnits())) return false;
Como recordatorio, en la etapa de pasada directa, las características normalizadas y las incorporaciones temporales se combinaron en una sola secuencia. Ahora, para entrenar cada módulo por separado, debemos separarlos cuidadosamente, restaurando la estructura original.
Una vez separadas las señales, comienza el proceso principal, es decir, el cálculo de los gradientes de error de los dos flujos de información hasta el nivel de los datos de origen. Primero, efectuamos operaciones en la línea troncal sin marcas temporales.
if(!cProjection.calcHiddenGradients(cNorm.AsObject())) return false; if(!NeuronOCL.calcHiddenGradients(cProjection.AsObject())) return false;
Luego la atención se desplaza hacia la línea troncal del contexto temporal. Pero antes de ejecutar el gradiente de error, necesitamos asegurar los datos obtenidos previamente. Para hacer esto, primero reemplazamos el puntero al búfer de gradiente de error del objeto de datos de origen. Y solo después de esto efectuamos las operaciones para determinar el error.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(NeuronOCL.getPrevOutput(), false) || !NeuronOCL.calcHiddenGradients(cProjectionWithTE.AsObject()) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, cProjection.GetWindow(), false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false) ) return false; //--- return true; }
La etapa final será la suma de los datos de los dos flujos de información. Después de esto, devolvemos los punteros a los búferes de datos a su estado original y finalizamos el método, retornando primero el resultado lógico de las operaciones al programa que realiza la llamada.
El resultado de este procedimiento bien establecido es una distribución correcta del gradiente de error a lo largo de toda la estructura del módulo, lo cual garantiza una actualización equilibrada de los pesos.
El método updateInputWeights es responsable de optimizar los coeficientes de peso en cada submódulo. La actualización se realiza mediante llamadas sucesivas a los métodos homónimos de los objetos internos. Este proceso de actualización paso a paso refleja el principio de gestión de peso aislada, que permite controlar al detalle el proceso de entrenamiento y la introducción de cambios sin interferir con la arquitectura general del sistema. Si al menos uno de los pasos de actualización falla, el método retornará un error, lo cual garantiza la integridad del estado del modelo actualizado.
El código para el método updateInputWeights se puede encontrar en el archivo adjunto al artículo. Ahí también se presenta el código completo de la clase CMamba4CastEmbeding y todos sus métodos.
En resumen, la clase CMamba4CastEmbeding no es solo un conjunto de algoritmos para la transformación de datos, sino un módulo elegantemente diseñado en el que cada función se encuentra estrechamente entrelazada con la lógica general del framework Mamba4Cast. Este ofrece un preprocesamiento de alta calidad de los datos de origen, lo que permite que el modelo extraiga eficazmente características esenciales, considere la dinámica temporal y se entrene correctamente con los gradientes de error obtenidos.
Codificador
La siguiente etapa de nuestro artículo es la construcción de los objetos de Codificador propuestos por los autores del framework Mamba4Cast, que juegan un papel importante en la extracción y estructuración de características para futuros pronósticos. La arquitectura de este bloque se basa en el uso de una pila de capas convolucionales con ventanas convolucionales de diferentes tamaños. Cada capa convolucional se centra en extraer aspectos específicos de los datos de origen, y sus resultados luego se combinan mediante concatenación y se normalizan para su posterior procesamiento por el módulo Mamba. Además, el número de repeticiones de dicho bloque está determinado por la profundidad de análisis requerida, lo que permite que el framework se adapte a tareas de complejidad diversa.
En este enfoque, la pila de capas convolucionales resulta de particular interés. El objeto de capa convolucional se ha implementado en nuestra biblioteca durante mucho tiempo y su uso no es difícil. No obstante, en el enfoque estándar, cada capa convolucional se crea como un objeto separado y se procesa secuencialmente. El uso de objetos con convoluciones de diferentes tamaños conlleva la creación de una gran cantidad de ellos, y el procesamiento secuencial de dichos objetos aumenta significativamente la complejidad computacional del modelo y, en consecuencia, su tiempo de entrenamiento.
Para resolver este problema, pensamos en crear un objeto especial que pudiese procesar múltiples capas convolucionales en paralelo. Un objeto de este tipo permitirá que el procesamiento de datos se inicie en varios subprocesos simultáneamente, lo que reducirá drásticamente el tiempo necesario para completar las operaciones. Dentro del nuevo objeto, podremos implementar mecanismos de distribución de tareas: la señal original se suministrará simultáneamente a varios filtros convolucionales con diferentes tamaños de ventana convolucional, y los resultados de su trabajo se concatenarán en un solo tensor. Esto no solo reducirá la cantidad de objetos intermedios, sino que también garantizará un uso más eficiente de los recursos informáticos, especialmente en el procesamiento multiproceso en las GPU modernas.
La idea no es nueva. Antes implementamos el objeto CNeuronMultiWindowsConvOCL, que nos permitió aplicar operaciones convolucionales a diferentes tamaños de ventana. Pero su algoritmo requería un bloque de datos separado para cada ventana convolucional. En este caso, nos enfrentamos a un problema distinto: necesitamos procesar el mismo flujo de información usando diferentes ventanas convolucionales.
El problema es que cambiar el tamaño de la ventana convolucional afecta la cantidad de posibles operaciones convolucionales. A medida que aumenta la ventana convolucional, disminuye el número de posiciones en las que se puede realizar la convolución. Esto da como resultado que la cantidad de subprocesos responsables de realizar cálculos con diferentes tamaños de ventanas convolucionales esté desequilibrada. Y esto dificulta la ejecución paralela eficiente.
Para solucionar este problema se decidió usar el rellenado de ceros, es decir, añadir ceros al principio y al final del vector analizado. Esta técnica nos permite estirar el vector a la longitud requerida para que se pueda utilizar el mismo número de subprocesos de operación independientemente del tamaño de la ventana convolucional. De este modo, el número de operaciones convolucionales está controlado únicamente por el tamaño del paso de la ventana convolucional que utilizamos de manera uniforme para todas las ventanas, equilibrando la carga entre subprocesos paralelos y simplificando significativamente el procesamiento paralelo.
La lógica clave al completo se compila en el lado del programa OpenCL en un kernel compacto pero potente, FeedForwardMultWinConvWPad, que procesa simultáneamente el mismo flujo de entrada a través de múltiples ventanas convolucionales de diferentes longitudes.
__kernel void FeedForwardMultWinConvWPad(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_o, __global const int *windows_in, const int inputs, const int step, const int window_out, const int activation ) { const size_t id = get_global_id(0); const size_t id_w = get_global_id(1); const size_t v = get_global_id(2); const size_t outputs = get_global_size(0); const size_t windows_total = get_global_size(1);
Cada flujo de trabajo está identificado por tres coordenadas:
- id — índice del elemento en el tensor de resultados,
- id_w — número de ventana convolucional,
- v — identificador del flujo unitario de datos de origen.
Esto permite el procesamiento paralelo de múltiples ventanas convolucionales, posiciones y secuencias de entrada con distintos parámetros de operación.
En el primer paso, el kernel determina la longitud de la ventana convolucional actual window_in obteniéndola del array windows_in utilizando el identificador de la ventana convolucional.
int window_in = windows_in[id_w];
A continuación, se calcula el desplazamiento de la posición inicial de la ventana convolucional en el búfer de datos de origen según el índice actual del elemento de tensor de resultados. Este desplazamiento se realiza considerando que el centro de la ventana debe caer en la posición id. Como las longitudes de las ventanas pueden variar, se aplica la fórmula (window_in + 1) / 2, lo cual garantiza que el centro de la ventana esté alineado.
int window_in = windows_in[id_w]; int mid_win = (window_in + 1) / 2; int shift_in = id * step - mid_win; int shift_in_var = v * inputs;
El desplazamiento shift_in_var se utiliza para direccionar correctamente la secuencia unitaria deseada en el array de datos de origen global.
El siguiente paso consiste en calcular shift_weight, el desplazamiento dentro del array global de parámetros entrenables. Como los pesos de cada ventana se ubican secuencialmente uno tras otro, considerando su longitud y coeficiente bias, debemos sumar los tamaños de todos los bloques de pesos que preceden a la ventana actual id_w. Esto nos permitirá determinar exactamente dónde comienzan los pesos para la convolución actual.
int shift_weight = 0; for(int w = 0; w < id_w; w++) shift_weight += (windows_in[w] + 1) * window_out;
A continuación, se inicia un ciclo anidado que procesa cada canal de salida w_out : esta es la dimensionalidad de la incorporación en el búfer de resultados obtenido después de aplicar la convolución.
for(int w_out = 0; w_out < window_out; w_out++) { float sum = matrix_w[shift_weight + window_in]; //--- for(int w = 0; w < window_in; w++) if((shift_in + w) >= 0 && (shift_in + w) < inputs) sum += IsNaNOrInf(matrix_i[shift_in_var + shift_in + w] * matrix_w[shift_weight + w], 0); //--- int shift_out = (v * outputs + id) * window_out + w_out; matrix_o[shift_out] = Activation(sum, activation); shift_weight += window_in + 1; } }
Para cada uno de estos canales, se inicializa la variable sum, que primero toma el valor bias (el último elemento del bloque de peso) y luego se le suman los productos de los valores de los datos de origen y los pesos correspondientes. En este caso, resulta necesario comprobar si el índice actual está fuera de los límites del array de datos de origen. Si esto sucede, se omite la operación, lo que equivale a aplicar el rellenado de ceros.
Cuando se completa el ciclo de la ventana, el resultado es procesado por la función de activación. Su tipo se especifica usando el parámetro activation y la función en sí se llama a través del contenedor auxiliar Activation. El valor resultante se escribe en el búfer de resultados global matrix_o considerando todos los desplazamientos.
Luego, el puntero al bloque de pesos shift_weight se desplaza hacia delante según el tamaño de la ventana más uno (bias) para pasar a los pesos del próximo filtro. De esta manera, dentro de un único flujo se produce el procesamiento secuencial de todos los canales, pero en paralelo para todas las ventanas y todas las secuencias unitarias de los datos de origen.
El algoritmo no solo es flexible sino también excepcionalmente eficiente: con él se aplican convoluciones de diferentes escalas a los datos simultáneamente, lo que proporciona una visión amplia y completa desde diferentes perspectivas. El rellenado de ceros elimina la necesidad de recortar datos manualmente o ajustar las dimensionalidades de incorporación posterior. Todo se hace de forma dinámica, justo en el momento de la ejecución en la GPU.
Esta implementación demuestra un principio clave: el alto rendimiento se logra no simplificando la lógica, sino mediante la división inteligente de los cálculos, el uso de procesamiento paralelo y el ajuste de todas las etapas de la transformación de datos.
El siguiente paso importante sería el cálculo de los gradientes de error a nivel de datos de origen. A diferencia de la pasada directa, aquí nos enfrentamos a una tarea más compleja: no solo necesitamos pasar los datos a través de un conjunto de filtros, sino también recopilar la contribución de cada filtro al error al nivel de los resultados en una pasada inversa. En este caso, debemos gestionar correctamente los desplazamientos y mantener la consistencia de la forma de los datos.
Implementaremos este algoritmo en el kernel OpenCL CalcHiddenGradientMultWinConvWPad. Su tarea consiste en agregar los gradientes de error considerando todas las ventanas convolucionales de diferentes longitudes y todos los canales de salida. En otras palabras, reconstruye el error a la secuencia original, considerando la no linealidad de activación y la estructura del filtro.
__kernel void CalcHiddenGradientMultWinConvWPad(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_ig, __global const float *matrix_og, __global const int *windows_in, const int outputs, const int step, const int window_out, const int activation ) { const size_t id_x = get_global_id(0); const size_t id_loc = get_local_id(1); const size_t id_win = id_loc / window_out; const size_t id_f = id_loc % window_out; const size_t v = get_global_id(2); const size_t inputs = get_global_size(0); const size_t size_loc = get_local_size(1); const size_t windows_total = size_loc / window_out;
Cada flujo del kernel es responsable de un elemento del gradiente en el nivel de datos de origen:
- id_x — índice de la posición en la secuencia original;
- id_loc — identificador local en el grupo de trabajo, que se divide en id_win (número de ventana) y id_f (número de filtro en el búfer de resultados);
- v — número de secuencia unitaria.
En el primer paso se calcula el desplazamiento shift_weight, que nos permite obtener el inicio exacto del bloque de pesos correspondiente a la ventana y canal actual. Aquí, como antes, tenemos que iterar todas las ventanas anteriores para sumar cuidadosamente sus longitudes y llegar a la posición deseada en el array global de parámetros matrix_w.
__local float temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)size_loc, (uint)LOCAL_ARRAY_SIZE); //--- int window_in = windows_in[id_win]; int shift_weight = id_f * (window_in + 1); for(int w = 0; w < id_win; w++) shift_weight += (windows_in[w] + 1) * window_out;
Después de esto, definimos el rango en el búfer de resultados en el que podría participar el elemento analizado de los datos de origen: shift_out. Este valor está limitado por cero y se calcula como la salida máxima posible en la que la ventana aún puede capturar la posición id_x.
int shift_out = max((int)((id_x - window_in) / step), 0);
Pero esto no resulta suficiente: a continuación se inicia un ciclo sobre todas las salidas posibles out en las que nuestro elemento podría participar en la pasada directa.
float grad = 0; int mid_win = (window_in + 1) / 2; for(int out = shift_out; out < outputs; out++) { int shift_in = out * step - mid_win; if(shift_in > id_x) break; int shift_w = id_x - shift_in; if(shift_w >= window_in) continue; int shift_g = ((v * outputs + out) * windows_total + id_win) * window_out + id_f; grad += IsNaNOrInf(matrix_w[shift_w + shift_weight] * matrix_og[shift_g], 0); }
En cada iteración de este ciclo, se comprueba si id_x está en la ventana actual. Si es así, se calculan el desplazamiento local shift_w dentro de la ventana y la posición del gradiente de salida deseado shift_g. Al multiplicar el peso correspondiente por el gradiente de error de salida matrix_og, obtenemos la contribución de esta convolución al error del elemento analizado. Todas estas contribuciones se acumulan en la variable grad.
En esta etapa tenemos un gradiente parcial para cada flujo. Sin embargo, debemos considerar que dentro de un grupo de trabajo puede haber varios flujos responsables del mismo id_x, pero diferentes filtros y canales. Por consiguiente, se introduce un array intermedio en la memoria local temp y se inicia un ciclo de suma con barreras de sincronización. Primero, cada flujo escribe su valor en temp.
for(int i = 0; i < size_loc; i += ls) { if(i <= id_loc && (i + ls) > id_loc) temp[id_loc % ls] = (i == 0 ? 0 : temp[id_loc % ls]) + grad; barrier(CLK_LOCAL_MEM_FENCE); }
Luego, usando la convolución de reducción paralela, el array se suma en potencias de dos, dejando en temp[0] el gradiente resultante sobre todos los canales y ventanas.
uint count = ls; do { count = (count + 1) / 2; if(id_loc < count && (id_loc + count) < ls) { temp[id_loc] += temp[id_loc + count]; temp[id_loc + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Finalmente, solo el flujo con id_loc == 0 escribe el valor del gradiente de error final en el array global matrix_ig. Pero antes de eso, se llama a la función Deactivation, que aplica la derivada de la función de activación a la matriz de valores de entrada matrix_i. Esto es importante: el gradiente debe ajustarse para tener en cuenta la forma de activación, de lo contrario el entrenamiento será incorrecto.
if(id_loc == 0) matrix_ig[v * inputs + id_x] = Deactivation(temp[0], matrix_i[v * inputs + id_x], activation); }
Este es uno de los tramos más laboriosos del camino de regreso. Al dividir los cálculos en ventanas y canales, además de usar la memoria local, se logra una alta eficiencia incluso con una gran cantidad de parámetros. Combinado con la pasada directa, este paso hace que nuestro algoritmo no solo sea modular y escalable, sino también capaz de manejar dependencias muy complejas en series temporales financieras sin perder precisión ni rendimiento.
El acorde final de la sinfonía convolucional es la actualización de los pesos. En esta etapa, traducimos los gradientes calculados en cambios reales en los parámetros del modelo. Además, no lo hacemos de cualquier manera, sino utilizando el método de optimización clásico, el método Adam, complementado con desplazamientos para convoluciones con ventanas de diferentes anchuras y considerando el rellenado de ceros. El kernel UpdateWeightsMultWinConvAdamWPad implementa cuidadosamente todas estas mecánicas.
__kernel void UpdateWeightsMultWinConvAdamWPad(__global float *matrix_w, __global const float *matrix_og, __global const float *matrix_i, __global float *matrix_m, __global float *matrix_v, __global const int *windows_in, const int windows_total, const int window_out, const int inputs, const int step, const int outputs, const float l, const float b1, const float b2 ) { const size_t i = get_global_id(0); // weight shift const size_t v = get_local_id(1); // variable const size_t variables = get_local_size(1);
Cada flujo de este kernel es responsable de actualizar un parámetro específico i, ya sea un coeficiente de filtro o un bias (sesgo, desplazamiento). La variable v aquí supone el índice de una secuencia unitaria, mientras que variables es su número total. Estas participan en la suma de gradientes sobre todo el flujo de datos de origen para hacer que la actualización final sea más estable.
Al principio, el flujo debe averiguar a qué filtro, a qué canal de salida y a qué peso específico pertenece su índice i. Esto se hace a través de un ciclo sobre todas las ventanas, donde se rastrea el desplazamiento de cada ventana en el array lineal de parámetros entrenables usando un contador shift_before clasificado.
__local float temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)variables, (uint)LOCAL_ARRAY_SIZE); //--- int step_out = window_out * windows_total; //--- int shift_before = 0; int window = 0; int number_w = 0; for(int w = 0; w < windows_total; w++) { int win = windows_in[w]; if(shift_before <= i && (win + 1)*window_out > (i - shift_before)) { window = win; number_w = w; } else shift_before += (win + 1) * window_out; }
Una vez que encontramos a qué ventana pertenece el índice i, determinamos:
- window — anchura de la ventana del filtro;
- number_w — número de ventana;
- id_f — número de filtro;
- shift_in — desplazamiento relativo al comienzo de la ventana (si es igual al tamaño de la ventana, entonces este será bias);
- bias — indicador booleano que determina si el elemento analizado es un parámetro de desplazamiento.
int shift_in = (i - shift_before) % (window + 1); int shift_in_var = v * inputs; bool bias = (shift_in == window); int mid_win = (window + 1) / 2; int id_f = (i - shift_before) / (window + 1); int shift_out = number_w * window_out + id_f; int shift_out_var = v * outputs * step_out;
En el caso de un coeficiente de filtro normal, se inicia un ciclo en todas las salidas outputs. En cada salida, verificamos si la posición de entrada correspondiente se encuentra dentro de los límites de datos válidos. En caso afirmativo, realizamos el procedimiento estándar: multiplicamos el gradiente de salida correspondiente matrix_og por la señal de entrada matrix_i, acumulando los productos en grad.
float grad = 0; if(!bias) { for(int out = 0; out < outputs; out++) { int in = out * step - mid_win + shift_in; if(in >= inputs) break; if(in < 0) continue; //--- grad += IsNaNOrInf(matrix_og[shift_out_var + shift_out + out * step_out] * matrix_i[shift_in_var + in], 0); } } else { for(int out = 0; out < outputs; out++) grad += IsNaNOrInf(matrix_og[shift_out_var + shift_out + out * step_out], 0); }
Si se trata de un parámetro de desplazamiento, entonces no se tienen en cuenta los datos de origen. Basta simplemente con sumar los gradientes a nivel de resultados para todas las posiciones.
A continuación viene una técnica familiar: la suma local a través del array temp. El objetivo es acumular gradientes en todas las secuencias unitarias y reducir la influencia de los valores atípicos. Nuevamente, usamos un árbol de reducción de barreras para sumar correctamente los valores dentro de un grupo de trabajo. Y solo el flujo con v == 0 (el primero) realiza la actualización final del peso.
//--- sum for(int s = 0; s < (int)variables; s += ls) { if(v >= s && v < (s + ls)) temp[v % ls] = (s == 0 ? 0 : temp[v % ls]) + grad; barrier(CLK_LOCAL_MEM_FENCE); } //--- uint count = ls; do { count = (count + 1) / 2; if(v < count && (v + count) < ls) { temp[v] += temp[v + count]; temp[v + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Aquí es donde entra en juego el algoritmo de Adam :
- La primera estimación del momento del gradiente mt se actualiza con suavizado exponencial a través del coeficiente b1.
- Luego se actualiza la segunda estimación del momento vt : la estimación de la varianza del gradiente con el coeficiente b2.
- El peso se actualiza usando la normalización mt / sqrt(vt) y se escala según la tasa de aprendizaje l.
- Todos los valores se fijan con la ayuda de clamp para evitar el desbordamiento de la escala y la división por cero.
if(v == 0) { grad = temp[0]; float mt = IsNaNOrInf(clamp(b1 * matrix_m[i] + (1 - b1) * grad, -1.0e5f, 1.0e5f), 0); float vt = IsNaNOrInf(clamp(b2 * matrix_v[i] + (1 - b2) * pow(grad, 2), 1.0e-6f, 1.0e6f), 1.0e-6f); float weight = clamp(matrix_w[i] + IsNaNOrInf(l * mt / sqrt(vt), 0), -MAX_WEIGHT, MAX_WEIGHT); matrix_w[i] = weight; matrix_m[i] = mt; matrix_v[i] = vt; } }
Finalmente, los valores actualizados se guardan nuevamente en la memoria global.
Combinado con las dos etapas anteriores (pasada directa y propagación inversa del error), este mecanismo hace que el bloque convolucional sea completamente autosuficiente, diferenciable y adecuado para el entrenamiento en una arquitectura de red neuronal profunda. Y lo más importante, es escalable y se adapta fácilmente a cualquier número de ventanas y canales. Esto le confiere al modelo una flexibilidad única para tratar con series temporales reales, no lineales y no estacionarias.
En el lado del programa principal, toda la funcionalidad convolucional multicanal con rellenado de ceros está encapsulada en la clase CNeuronMultiWindowsConvWPadOCL. Este módulo hereda del objeto de capa convolucional básico CNeuronConvOCL y sirve como interfaz para poner en cola todos los kernels OpenCL descritos anteriormente.
A continuación mostramos la estructura de clases:
class CNeuronMultiWindowsConvWPadOCL : public CNeuronConvOCL { protected: int aiWindows[]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronMultiWindowsConvWPadOCL(void) { activation = SoftPlus; iWindow = -1; } ~CNeuronMultiWindowsConvWPadOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMultiWindowsConvWPadOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual void SetOpenCL(COpenCLMy *obj); //--- virtual uint GetWindow(void) const { return aiWindows[0]; } virtual uint GetWindowsSize(void) const { return aiWindows.Size(); } virtual uint GetWindowOut(void) const { return iWindowOut; } virtual uint GetUnits(void) const { return Neurons()/(iVariables*GetWindowsSize()*iWindowOut); } };
Esta clase oculta todas las complejidades de la interacción con OpenCL y permite conectar fácilmente el bloque convolucional multidimensional a la arquitectura general del modelo. El código fuente completo de la clase, junto con la implementación de todos los métodos, está disponible en el archivo adjunto del artículo y está destinado al estudio independiente por parte del lector.
Desafortunadamente, el formato del artículo tiene sus límites, y hemos agotado el volumen disponible. Evaluaremos la efectividad de los enfoques implementados en el próximo artículo.
Conclusión
En este artículo, hemos continuado el desarrollo y la implementación de los enfoques propuestos por los autores del framework Mamba4Cast, centrándonos en dos módulos fundamentales: la incorporación de datos de origen considerando la codificación temporal y la convolución multicanal con rellenado de ceros. El objeto CMamba4CastEmbedding ha demostrado cómo combinar la proyección de datos sin procesar y el código armónico de marcas temporales en un solo bloque. Y los kernels OpenCL FeedForwardMultWinConvWPad, CalcHiddenGradientMultWinConvWPad y UpdateWeightsMultWinConvAdamWPad demostraron cómo implementar eficientemente el procesamiento paralelo de múltiples ventanas convolucionales simultáneamente y garantizar una diferenciabilidad completa durante el entrenamiento.
Hemos prestado especial atención no solo al rendimiento: el ajuste fino de los desplazamientos, el equilibrio de carga entre flujos y la agregación cuidadosa de gradientes a través de reducciones locales han hecho del bloque convolucional una herramienta verdaderamente escalable. Al mismo tiempo, la lógica completa sigue siendo transparente: la clase CNeuronMultiWindowsConvWPadOCL encapsula los detalles de la interacción con OpenCL y permite conectar fácilmente las soluciones implementadas a cualquier modelo.
En el próximo artículo, reuniremos todos los componentes desarrollados en un solo modelo, lo entrenaremos con datos históricos reales y evaluaremos la efectividad de los enfoques implementados.
Enlaces
- Mamba4Cast: Efficient Zero-Shot Time Series Forecasting with State Space Models
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 4 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18138
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso