
开发多币种 EA 交易(第 21 部分):准备重要实验并优化代码
概述
在上一部分中,我们开始着手整理自动优化输送机,这使我们能够根据累积的价格数据获得新的最终 EA。然而,我们还没有实现完全自动化,因为仍然需要就如何最好地实施最后阶段做出艰难的决定。它们很难,因为如果我们做出了错误的选择,我们将不得不重做很多。因此,我真的想节省精力,并尝试做出正确的选择。在做出艰难的决定时,没有什么比推迟决定更有帮助了!特别是如果我们能够负担得起的话。
但我们可以用不同的方式推迟它们。与其简单地推迟选择的时刻,让我们试着切换到另一项似乎会让我们分心的任务,但事实上,它的解决方案至少可以帮助增加做出选择的动力,如果不能找到正确的道路。
有趣的问题
关于使用参数优化的许多争论中的绊脚石是,在将盈利能力和回撤保持在指定水平的同时,所获得的参数在未来一段时间内可用于交易的时间有多长。有可能做到这一点吗?
尽管有一种流行的观点认为,人们不能相信未来测试结果的可重复性,而且当策略“崩溃”时,这只是运气问题。可能几乎所有交易策略的开发人员都真的想相信这一点,否则就失去了在开发和测试上投入大量精力的意义。
人们已经多次尝试通过选择良好的参数来提高人们对该策略在一段时间内能够成功运作的信心。有些文章以某种方式考虑了定期自动选择最佳 EA 参数的主题。@fxsaber的 Validate EA 值得单独提及,因为它正是用于进行一项非常有趣的实验。
该工具允许我们选取任意 EA(正在研究的 EA),并选择一段特定的时间(例如 3 年),启动以下过程:正在研究的 EA 将在一定时期内(例如 2 个月)进行优化,之后,使用最佳设置在策略测试器中进行为期两周的交易。在每个两周时期结束时,所研究的 EA 将再次针对前两个月进行优化,并再次进行另外两周的交易。这将持续到选定的 3 年间隔结束为止。
最终结果将是一份交易报告,显示如果所研究的 EA 真的定期重新优化并使用更新的参数启动,它将如何在所有三年内进行交易。很明显,您可以自行决定任意选择上述时间间隔。如果任何 EA 能够通过这种重新优化显示出可接受的结果,那么这将表明其在真实交易中的使用潜力增加。
然而,该工具有一个明显的局限性 —— 所研究的 EA 必须具有开放的输入参数才能执行优化。例如,如果我们通过组合许多单个实例来获取前面部分中获得的最终 EA,它们就没有允许它们影响开仓交易逻辑的输入参数。我们不会考虑资金和风险管理的参数,因为它们的优化虽然可能,但没有什么意义。毕竟,很明显,如果我们增加持仓的规模,与之前通过较小头寸规模的通过获得的利润相比,通过的结果将显示出更大的利润。
因此,让我们尝试实现一些类似的东西,但适用于我们开发的 EA。
规划路径
一般来说,我们需要一个脚本来用几乎相同的项目填充数据库。主要区别仅在于优化周期的开始和结束日期。工作中的阶段、阶段作品和任务的组成可能完全相同。因此,目前,您可以使用少量输入参数来制作服务 EA,包括优化期的开始日期和持续时间。通过在优化模式下运行它并搜索开始日期,我们可以用类似的项目填充数据库。目前尚不清楚在输入中包含哪些其他参数是有意义的;随着开发的进展,我们将做出决定。
完全运行所有优化任务,即使是在单个项目中,也可能需要很长时间。如果没有一个这样的项目需要完成,而是十几个或更多,那么我们谈论的是相当耗时的任务。因此,看看是否有可能以某种方式加快阶段 EA 的工作是有意义的。为了检测需要修复的瓶颈,我们将使用 MetaEditor 附带的分析器。
接下来,我们需要决定如何从几个获得的初始化字符串中模拟工作(每个项目在完成任务后,将提供最终 EA 的一个初始化字符串)。最有可能的是,我们需要创建一个专门为这类工作设计的新测试 EA。但我可能会把这个问题推迟到下一篇文章再说。
我们首先从优化测试 EA 的代码开始。之后,我们将开始创建用于填充数据库的脚本。
代码优化
在我们深入研究主要任务的实现之前,让我们看看是否有任何方法可以加快自动优化中涉及的 EA 的代码。为了检测可能的瓶颈,让我们从上一部分中选取最后一个 EA 进行研究。它结合了 32 个单一交易策略实例(2 个交易品种 * 1 个时间周期 * 16 个实例 = 32)。当然,这比最终 EA 中预期的实例总数要少得多,但在优化过程中,我们的绝大多数通过将使用一个实例(在第一阶段)或不超过 16 个实例(在第二阶段)。因此,这样的测试主题 EA 将非常适合我们。
让我们在历史数据上以分析模式启动 EA。在此模式下运行时,将在策略测试器中自动编译并启动用于分析的特殊版本的 EA。让我们引用参考资料中关于使用分析的描述:
采用抽样方法进行分析。分析器暂停 MQL 程序的运行(每秒约 10,000 次)并收集特定代码部分发生暂停次数的统计数据。这包括对调用堆栈的分析,以确定每个函数对总代码执行时间的“贡献”。
抽样是一种轻量型且准确的方法。与其他方法不同,抽样不会对分析的代码做出任何更改,因为这可能会影响其运行速度。
分析报告以函数或程序行的形式显示,每个函数或程序行都有两个指标:
- 总 CPU [单位,%] — 函数在调用堆栈中出现的次数。
- 自身 CPU [衡量单位,%] — 直接在指定函数内出现的“暂停”次数。此变量对于识别瓶颈至关重要:根据统计数据,在需要更多处理器时间的情况下,暂停发生的频率更高。
该值显示为绝对数量和占总量的百分比。
这是我们完成通过后所得到的:
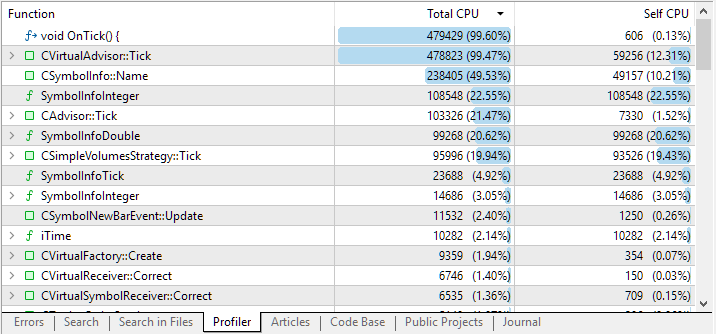
图 1.所研究 EA 代码的分析结果
默认情况下,分析结果列表显示位于顶层的大型函数。但是,通过单击带有函数名的字符串,我们可以看到从该字符串调用的函数的嵌套列表。这使我们能够更准确地确定哪些代码段占用了最多的 CPU 时间。
在前两个字符串中,我们预期会看到 OnTick() 处理程序,以及从中调用的 CVirtualAdvisor::Tick() 处理程序。事实上,除了初始化之外,EA 大部分时间都在处理传入的分时报价。但第三和第四组结果提出了合理的问题。
为什么我们对当前交易品种选择方法有如此多的调用?为什么要花这么多时间来获取交易品种的一些整数属性?让我们来弄清楚吧。
通过扩展与 CSymbolInfo::Name(string name) 方法调用对应的字符串,我们可以追踪到,几乎所有的时间都花在了从检查是否需要平仓的函数中调用它。
//+------------------------------------------------------------------+ //| Check the need to close by SL, TP or EX | //+------------------------------------------------------------------+ bool CVirtualOrder::CheckClose() { if(IsMarketOrder()) { // If this is a market virtual position, s_symbolInfo.Name(m_symbol); // Select the desired symbol s_symbolInfo.RefreshRates(); // Update information about current prices // ... } return false; }
这段代码是很久以前写的。那时,对我们来说,重要的是将开立的虚拟头寸正确地转化为实际头寸。关闭虚拟仓位应该会导致立即(或几乎立即)关闭一定数量的真实仓位。因此,应在每次报价和每个未平仓虚拟仓位上执行此检查。
为了自给自足,我们为每个 CVirtualOrder 类对象提供了其 CSymbolInfo 类对象实例,通过该实例,我们请求有关所需交易工具(交易品种)的价格和规格的所有必要信息。因此,对于 16 个使用 3 个虚拟仓位的交易策略实例,虚拟仓位数组中将有 16*3 = 48 个。如果 EA 包含数百个交易策略实例,并且还使用大量虚拟仓位,那么对交易品种选择方法的调用次数将会增加很多倍。但有必要吗?
我们什么时候真正需要调用交易品种名称选择器方法?仅当虚拟仓位交易品种发生变化时。如果自上次报价以来没有发生变化,那么调用此交易品种方法是无用的。仅当打开一个之前未打开过或以不同交易品种打开的虚拟仓位时,交易品种才会改变。显然,这种情况不会在每次发生时发生,而是发生频率要低得多。此外,在所使用的模型策略中,一个虚拟仓位的交易品种永远不会改变,因为交易策略的一个实例使用单个交易品种,该交易品种将成为该策略实例的所有虚拟仓位的交易品种。
然后,您可以将 CSymbolInfo 类对象发送到交易策略实例级别,但这也可能是多余的,因为不同的交易策略实例可能使用相同的交易品种。因此,我们将把它们提升到更高的水平 —— 全局水平。在这个层面上,我们只需要让 CSymbolInfo 类对象的实例数量等于 EA 中使用的不同交易品种的数量。仅当 EA 需要访问新交易品种的属性时,才会创建每个 CSymbolInfo 实例。创建后,副本将永久分配给特定交易品种。
受书中以下示例的启发,我们将创建自己的类 CSymbolsMonitor 。与示例不同,我们不会创建一个新类,尽管新类写得更简洁,但本质上会重复标准库中现有类的功能。我们的类将充当 CSymbolInfo 类的多个对象的容器,并确保为所使用的每个交易品种创建一个单独的类信息对象。
为了使其可以从代码中的任何位置访问,我们将在实现中再次使用 Singleton 设计模式。该类的基础由存储指向 CSymbolInfo 类对象的指针的 m_symbols[] 数组构成。
//+--------------------------------------------------------------------+ //| Class for obtaining information about trading instruments (symbols)| //+--------------------------------------------------------------------+ class CSymbolsMonitor { protected: // Static pointer to a single class instance static CSymbolsMonitor *s_instance; // Array of information objects for different symbols CSymbolInfo *m_symbols[]; //--- Private methods CSymbolsMonitor() {} // Closed constructor public: ~CSymbolsMonitor(); // Destructor //--- Static methods static CSymbolsMonitor *Instance(); // Singleton - creating and getting a single instance // Tick handling for objects of different symbols void Tick(); // Operator for getting an object with information about a specific symbol CSymbolInfo* operator[](const string &symbol); }; // Initializing a static pointer to a single class instance CSymbolsMonitor *CSymbolsMonitor::s_instance = NULL;
创建类的单个实例的静态方法的实现与之前遇到的实现类似。析构函数将包含一个用于删除已创建的信息对象的循环。
//+------------------------------------------------------------------+ //| Singleton - creating and getting a single instance | //+------------------------------------------------------------------+ CSymbolsMonitor* CSymbolsMonitor::Instance() { if(!s_instance) { s_instance = new CSymbolsMonitor(); } return s_instance; } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CSymbolsMonitor::~CSymbolsMonitor() { // Delete all created information objects for symbols FOREACH(m_symbols, if(!!m_symbols[i]) delete m_symbols[i]); }
公有的报价处理方法将定期更新交易品种规范和报价信息。该规范可能不会随着时间的推移而发生任何变化,但为了以防万一,我们将每天提供一次更新。我们将每分钟更新报价,因为我们将 EA 的操作模式设为仅于分钟柱开启(为了更好地重复 1 分钟 OHLC 模式和基于真实报价的每个报价模式中的建模结果)。
//+------------------------------------------------------------------+ //| Handle a tick for the array of virtual orders (positions) | //+------------------------------------------------------------------+ void CSymbolsMonitor::Tick() { // Update quotes every minute and specification once a day FOREACH(m_symbols, { if(IsNewBar(m_symbols[i].Name(), PERIOD_D1)) { m_symbols[i].Refresh(); } if(IsNewBar(m_symbols[i].Name(), PERIOD_M1)) { m_symbols[i].RefreshRates(); } }); }
最后,我们添加一个重载索引运算符,以根据交易品种名称获取指向所需对象的指针。在此运算符中,将自动为以前未通过此运算符访问过的交易品种创建新的信息对象。
//+-------------------------------------------------------------------------+ //| Operator for getting an object with information about a specific symbol | //+-------------------------------------------------------------------------+ CSymbolInfo* CSymbolsMonitor::operator[](const string &name) { // Search for the information object for the given symbol in the array int i; SEARCH(m_symbols, m_symbols[i].Name() == name, i); // If found, return it if(i != -1) { return m_symbols[i]; } else { // Otherwise, create a new information object CSymbolInfo *s = new CSymbolInfo(); // Select the desired symbol for it if(s.Name(name)) { // If the selection is successful, update the quotes s.RefreshRates(); // Add to the array of information objects and return it APPEND(m_symbols, s); return s; } else { PrintFormat(__FUNCTION__" | ERROR: can't create symbol with name [%s]", name); } } return NULL; }
将收到的代码保存在当前文件夹的 SymbolsMonitor.mqh 文件中。现在轮到使用所创建的类的代码了。
CVirtualAdvisor 修改
在这个类中,我们已经有几个存在于单个副本中并执行一些特定任务的对象:虚拟仓位交易量的接收器、风险管理器和用户信息界面。让我们为它们添加一个交易品种监视器对象。更准确地说,我们将创建一个类字段来存储指向交易品种监视器对象的指针:
class CVirtualAdvisor : public CAdvisor { protected: CSymbolsMonitor *m_symbols; // Symbol monitor object CVirtualReceiver *m_receiver; // Receiver object that brings positions to the market CVirtualInterface *m_interface; // Interface object to show the status to the user CVirtualRiskManager *m_riskManager; // Risk manager object ... public: ... };
与前面提到的其他对象类似,交易品种监视器对象的创建将在构造函数被调用时通过调用 CSymbolsMonitor::Instance() 静态方法启动。我们将在析构函数中添加对该对象的删除。
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(string p_params) { ... // If there are no read errors, if(IsValid()) { // Create a strategy group CREATE(CVirtualStrategyGroup, p_group, groupParams); // Initialize the symbol monitor with a static symbol monitor m_symbols = CSymbolsMonitor::Instance(); // Initialize the receiver with the static receiver m_receiver = CVirtualReceiver::Instance(p_magic); // Initialize the interface with the static interface m_interface = CVirtualInterface::Instance(p_magic); ... } } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ void CVirtualAdvisor::~CVirtualAdvisor() { if(!!m_symbols) delete m_symbols; // Remove the symbol monitor if(!!m_receiver) delete m_receiver; // Remove the recipient if(!!m_interface) delete m_interface; // Remove the interface if(!!m_riskManager) delete m_riskManager; // Remove risk manager DestroyNewBar(); // Remove the new bar tracking objects }
将调用 Tick() 方法添加到新的报价处理程序中以监视交易品种。EA 中使用的所有交易品种的报价都将在这里更新:
//+------------------------------------------------------------------+ //| OnTick event handler | //+------------------------------------------------------------------+ void CVirtualAdvisor::Tick(void) { // Define a new bar for all required symbols and timeframes bool isNewBar = UpdateNewBar(); // If there is no new bar anywhere, and we only work on new bars, then exit if(!isNewBar && m_useOnlyNewBar) { return; } // Symbol monitor updates quotes m_symbols.Tick(); // Receiver handles virtual positions m_receiver.Tick(); // Start handling in strategies CAdvisor::Tick(); // Risk manager handles virtual positions m_riskManager.Tick(); // Adjusting market volumes m_receiver.Correct(); // Save status Save(); // Render the interface m_interface.Redraw(); }
借此机会,让我们着眼于未来,将 ChartEvent 事件处理程序添加到此类中。目前其中会调用 m_interface 接口对象的同名方法。在这个阶段它什么也不做。
保存对当前文件夹中 VirtualAdvisor.mqh 文件所做的更改。
CVirtualOrder 修改
如前所述,获取有关交易品种的信息是在虚拟仓位类中执行的。因此,让我们从这个类开始进行修改,首先,让我们添加指向监视器( CSymbolsMonitor类)和交易品种信息对象( CSymbolInfo类)的指针:
class CVirtualOrder { private: //--- Static fields static ulong s_count; // Counter of all created CVirtualOrder objects CSymbolInfo *m_symbolInfo; // Object for getting symbol properties //--- Related recipient objects and strategies CSymbolsMonitor *m_symbols; CVirtualReceiver *m_receiver; CVirtualStrategy *m_strategy; ... }
向类字段的组合添加指针意味着应该为它们分配指向某些已创建对象的指针。如果这些对象是在该类的对象的方法内部创建的,那么就需要注意它们的正确删除。
让我们添加指向交易品种监视器的指针的初始化和指向交易品种信息对象的指针的清除。调用 CSymbolsMonitor::Instance() 静态方法来获取指向交易品种监视器的指针。将在其中创建一个单个监视器对象(如果不存在)。在析构函数中,如果信息对象已创建且尚未被删除,则添加删除操作:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualOrder::CVirtualOrder(CVirtualStrategy *p_strategy) : // Initialization list m_id(++s_count), // New ID = object counter + 1 ... m_point(0) { PrintFormat(__FUNCTION__ + "#%d | CREATED VirtualOrder", m_id); m_symbolInfo = NULL; m_symbols = CSymbolsMonitor::Instance(); } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CVirtualOrder::~CVirtualOrder() { if(!!m_symbolInfo) delete m_symbolInfo; }
我没有将接收指向 m_symbolInfo 信息对象的指针添加到构造函数中,因为在调用构造函数时可能并不总是确切知道将在此虚拟仓位使用哪个交易品种。只有在建立虚拟仓位时,即调用 CVirtualOrder::Open() 方法时,这一点才会变得清晰。我们将向其中添加指向交易品种信息对象的指针的初始化:
//+------------------------------------------------------------------+ //| Open a virtual position (order) | //+------------------------------------------------------------------+ bool CVirtualOrder::Open(string symbol, // Symbol ENUM_ORDER_TYPE type, // Type (BUY or SELL) double lot, // Volume double price = 0, // Open price double sl = 0, // StopLoss level (price or points) double tp = 0, // TakeProfit level (price or points) string comment = "", // Comment datetime expiration = 0, // Expiration time bool inPoints = false // Are the SL and TP levels set in points? ) { if(IsOpen()) { // If the position is already open, then do nothing PrintFormat(__FUNCTION__ "#%d | ERROR: Order is opened already!", m_id); return false; } // Get a pointer to the information object for the desired symbol from the symbol monitor m_symbolInfo = m_symbols[symbol]; if(!!m_symbolInfo) { // Actions to open ... return true; } else { ... return false; } }
现在,由于交易品种监视器负责更新交易品种报价信息,我们现在可以将 CVirtualOrder 类从对交易品种属性的 m_symbolInfo 信息对象的 Name() 和 RefreshRates() 方法的所有调用中解放出来。当在 m_symbolInfo 中开立虚拟仓位时,我们将保存指向已选择所需交易品种的对象的指针。当伴随先前打开的虚拟仓位时, RefreshRates() 方法已在此订单号上调用一次 — 这是由 CSymbolsMonitor::Tick() 方法中所有交易品种的交易品种监视器完成的。
让我们再次进行分析。图片已经变好了,但是调用 SymbolInfoDouble() 函数仍然占用了9%。快速搜索显示,需要这些调用才能获得点差值。但是我们可以用计算价格差异(卖价 - 买价)来代替这个操作,这个差异在调用 RefreshRates() 方法时已经获得,不需要额外的 SymbolInfoDouble() 函数调用。
此外,对此类所做的更改与提高操作速度没有直接关系,并且对于所考虑的模型策略来说也不是必需的:
- 添加将当前对象传递给 CVirtualStrategy::OnOpen() 和 CVirtualStrategy::OnClose() 处理程序;
- 增加了虚拟仓位平仓利润的计算;
- 增加了止损和获利水平的 getter 和 setter;
- 添加了在开立虚拟仓位时分配的唯一编号。
或许,这个库将面临一次更彻底的改造。因此,我们不会详细描述这些变化。
将所做的更改保存在当前文件夹中的 VirtualOrder.mqh 文件中。
策略修改
为了使用交易品种监视器,我们还需要对交易策略类进行一些小的编辑。首先,与虚拟仓位的类一样,我们使 m_symbolInfo 类的成员现在存储指向对象的指针,而不是对象本身:
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { protected: ... CSymbolInfo *m_symbolInfo; // Object for getting information about the symbol properties ... public: ... };
并在构造函数中添加其初始化:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { ... // Register the event handler for a new bar on the minimum timeframe //IsNewBar(m_symbol, PERIOD_M1); m_symbolInfo = CSymbolsMonitor::Instance()[m_symbol]; ... }
我们注释掉了新柱形事件处理过程的注册,因为它现在将在交易品种监视器中注册。
其次,我们从策略代码中删除了当前价格的更新(在检查开仓信号和开仓本身的方法中),因为交易品种监视器也会处理这个问题。
让我们将对当前文件夹中的 SimpleVolumesStrategy.mqh 文件所做的更改保存起来。
有效性检查
让我们比较一下在添加交易品种监视器相关更改之前和之后在同一时间间隔内测试所研究的 EA 的结果。
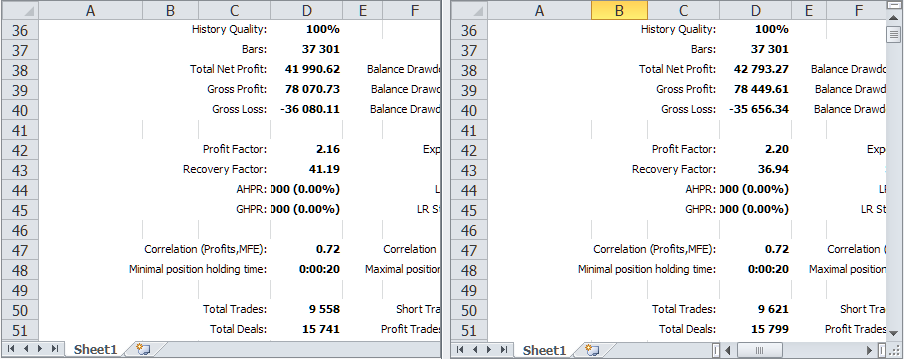
图 2.使用交易品种监视器比较先前版本和当前版本的测试结果
我们可以看到,它们总体上是相同的,但也存在一些细微的差别。为了清楚起见,我们以表格的形式展示它们。
| 版本 | 利润 | 回撤 | 标准化利润 |
|---|---|---|---|
| 先前版本 | 41 990.62 | 1 019.49(0.10%) | 6 867.78 |
| 当前版本 | 42 793.27 | 1 158.38(0.11%) | 6 159.87 |
如果我们比较报告中的第一批交易,我们可以看到,之前的版本具有当前版本中不存在的额外头寸,反之亦然。最有可能的原因是,当测试器在 EURGBP 符号上启动时,EURGBP 的新柱会出现在 mm:00,而对于另一个交易品种,例如 GBPUSD,它可能会出现在 mm:00 或 mm:20。
为了消除这种影响,我们将在策略中添加对新柱出现的额外检查:
//+------------------------------------------------------------------+ //| "Tick" event handler function | //+------------------------------------------------------------------+ void CSimpleVolumesStrategy::Tick() override { if(IsNewBar(m_symbol, PERIOD_M1)) { // If their number is less than allowed if(m_ordersTotal < m_maxCountOfOrders) { // Get an open signal int signal = SignalForOpen(); if(signal == 1 /* || m_ordersTotal < 1 */) { // If there is a buy signal, then OpenBuyOrder(); // open the BUY_STOP order } else if(signal == -1) { // If there is a sell signal, then OpenSellOrder(); // open the SELL_STOP order } } } }
经过这次修改,结果只会有所改善。当前版本显示最高标准化利润:
| 版本 | 利润 | 回撤 | 标准化利润 |
|---|---|---|---|
| 先前版本 | 46565.39 | 1 079.93(0.11%) | 7 189.77 |
| 当前版本 | 47 897.30 | 1 051.37(0.10%) | 7 596.31 |
因此,让我们保留所做的更改并继续创建数据库填充脚本。
用项目填充数据库
我们不会创建脚本,而是创建 EA,但它的行为会像脚本一样。所有工作都将在初始化函数中执行,之后 EA 将在第一次报价时卸载。如果我们想在指定限制内多次运行参数变化,此实现将允许我们在图表和优化器中运行它。
由于这是第一个实现,我们不会提前过多考虑哪一组输入更方便,但我们将尝试制作一个最小的工作原型。以下是我们最终得到的参数列表:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Database" sinput string fileName_ = "article.16373.db.sqlite"; // - Main database file input group "::: Project parameters" sinput string projectName_ = "SimpleVolumes"; // - Name sinput string projectVersion_ = "1.20"; // - Version sinput string symbols_ = "GBPUSD;EURUSD;EURGBP"; // - Symbols sinput string timeframes_ = "H1;M30;M15"; // - Timeframes input datetime fromDate_ = D'2018-01-01'; // - Start date input datetime toDate_ = D'2023-01-01'; // - End date
项目的名称和版本很明显,然后有两个参数,我们将在其中传递交易品种和时间周期的列表,以分号分隔。它们将用于获取交易策略的单个实例。对于每个交易品种,所有时间周期将依次采用。因此,如果我们在默认值中指定三个交易品种和三个时间周期,这将导致创建九个单个实例。
每个单独的实例都必须经过第一阶段的优化,在该阶段专门为其选择最佳的参数组合。更准确地说,在优化过程中,我们可能会尝试许多组合,然后从中选择一定数量的“好”组合。
这个选择将在优化的第二阶段做出。因此,我们将拥有一组在特定交易品种和时间周期内工作的多个“好”实例。对所有交易品种-时间周期组合重复第二步后,我们将得到每个组合的九组单一实例。
在第三步中,我们将组合这九个组,获取并在库中存储一个初始化字符串,该字符串可用于创建包含来自这些组的所有单个实例的 EA。
让我们回想一下,负责按顺序执行上述所有阶段的代码已经编写完成,并且只要数据库中生成了必要的“指令”,它就可以工作。在此之前,我们手动将它们添加到数据库中。现在我们要将这个例行程序转移到已开发的 EA 脚本中。
该 EA 的其余两个参数允许我们设置优化间隔的开始和结束日期。我们将使用它们来模拟周期性的重新优化,并看看重新优化后多久,最终的 EA 将与优化区间中的结果相同。
话虽如此,初始化函数代码可能看起来像这样:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the database DB::Connect(fileName_); // Create a project CreateProject(projectName_, projectVersion_, StringFormat("%s - %s", TimeToString(fromDate_, TIME_DATE), TimeToString(toDate_, TIME_DATE) ) ); // Create project stages CreateStages(); // Creating jobs and tasks CreateJobs(); // Queueing the project for execution QueueProject(); // Close the database DB::Close(); // Successful initialization return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Tick handling | //+------------------------------------------------------------------+ void OnTick() { // Since all work is done in OnInit(), delete the EA ExpertRemove(); }
也就是说,我们在项目表中顺序创建一个条目,然后将阶段添加到项目阶段表中,然后填写每个作业的工作表和任务表。最后,我们将项目状态设置为 “Queued”(排队)。由于数据库中的触发器,项目的所有阶段、作业和任务也将转移到排队状态。
现在让我们更详细地看一下所创建函数的代码。其中最简单的就是创建一个项目。它包含一个 SQL 查询,用于插入数据并将新创建的记录的 ID 存储在 id_project 全局变量中:
//+------------------------------------------------------------------+ //| Create a project | //+------------------------------------------------------------------+ void CreateProject(string name, string ver, string desc = "") { string query = StringFormat("INSERT INTO projects " " VALUES (NULL,'%s','%s','%s',NULL,'Done') RETURNING rowid;", name, ver, desc); PrintFormat(__FUNCTION__" | %s", query); id_project = DB::Insert(query); }
作为项目描述,我们从优化间隔的开始日期和结束日期形成一个字符串。这将使我们能够区分同一版本的交易策略的项目。
创建阶段的函数会稍微长一些:创建三个阶段需要三个 SQL 查询。当然,可能还有更多阶段,但现在我们只限于前面提到的三个阶段。创建每个阶段后,我们还将它们的 ID 存储在 id_stage1 、 id_stage2 和 id_stage3 全局变量中。
//+------------------------------------------------------------------+ //| Create three stages | //+------------------------------------------------------------------+ void CreateStages() { // Stage 1 - single instance optimization string query1 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%s," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project "NULL", // id_parent_stage "First", // name "SimpleVolumesStage1.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query1); id_stage1 = DB::Insert(query1); // Stage 2 - selection of a good group of single specimens string query2 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage1, // id_parent_stage "Second", // name "SimpleVolumesStage2.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query2); id_stage2 = DB::Insert(query2); // Stage 3 - saving the initialization string of the final EA to the library string query3 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage2, // id_parent_stage "Save to library", // name "SimpleVolumesStage3.ex5", // expert "GBPUSD", // symbol "H1", // period 0, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query3); id_stage3 = DB::Insert(query3); }
对于每个阶段,我们指定其名称、父阶段的 ID 和该阶段的 EA 名称。阶段表中的其余字段对于不同的阶段大致相同:优化间隔、初始存款等等。
主要工作落在创建作业和任务的函数 CreateJobs() 上。每项工作都与一个交易品种和时间周期的组合相关。因此,首先我们为输入中列出的所有使用的交易品种和时间周期创建数组。对于时间范围,我添加了 StringToTimeframe() 函数,它将时间周期名称从字符串转换为 ENUM_TIMEFRAMES 类型的值。
// Array of symbols for strategies string symbols[]; StringSplit(symbols_, ';', symbols); // Array of timeframes for strategies ENUM_TIMEFRAMES timeframes[]; string sTimeframes[]; StringSplit(timeframes_, ';', sTimeframes); FOREACH(sTimeframes, APPEND(timeframes, StringToTimeframe(sTimeframes[i])));
然后,在双循环中,我们遍历所有交易品种和时间周期的组合,并根据自定义标准创建三个优化任务。
// Stage 1 FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the first stage string params = StringFormat(paramsTemplate1, ""); // Request to create the first stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage1, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs1, id_job); // Create three tasks for this job for(int i = 0; i < 3; i++) { query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } } });
确定这个任务数量,一方面是因为我们已经在一个组合的优化过程中积累了至少 10-20 千次通过,另一方面,任务数量不会太多,否则优化所需的时间会太长。选择这三个任务的自定义标准是因为,在不同的运行中,该交易策略的遗传算法几乎总是收敛到不同的参数组合。因此,没有必要针对不同的运行使用不同的标准,对于策略的单个实例,我们已经有相当丰富的不同良好参数组合选择。
将来,使用的任务数量和优化标准可以包含在脚本参数中,但现在它们只是硬编码在代码中。
对于第一阶段的每个作业,我们使用相同的优化参数模板,该模板在 paramsTemplate1 全局变量中指定:
// Template of optimization parameters at the first stage string paramsTemplate1 = "; === Open signal parameters\n" "signalPeriod_=212||12||40||240||Y\n" "signalDeviation_=0.1||0.1||0.1||2.0||Y\n" "signaAddlDeviation_=0.8||0.1||0.1||2.0||Y\n" "; === Pending order parameters\n" "openDistance_=10||0||10||250||Y\n" "stopLevel_=16000||200.0||200.0||20000.0||Y\n" "takeLevel_=240||100||10||2000.0||Y\n" "ordersExpiration_=22000||1000||1000||60000||Y\n" "; === Capital management parameters\n" "maxCountOfOrders_=3||3||1||30||N\n";
将添加的作业的 ID 保存到 id_jobs1 数组中,以用于创建第二阶段作业。
为了创建第二阶段的工作,也使用 paramsTemplate2 全局变量中指定的模板,但它已经有一个变量部分:
// Template of optimization parameters for the second stage string paramsTemplate2 = "idParentJob_=%s\n" "useClusters_=false||false||0||true||N\n" "minCustomOntester_=500.0||0.0||0.000000||0.000000||N\n" "minTrades_=40||40||1||400||N\n" "minSharpeRatio_=0.7||0.7||0.070000||7.000000||N\n" "count_=8||8||1||80||N\n";
“idParentJob_=” 后面的值是使用特定交易品种和时间周期组合的第一阶段作业的 ID。在创建第一阶段作业之前,这些值是未知的,因此它们将在从 id_jobs1 数组创建每个第二阶段作业之前立即替换到此模板中。
此模板中的 count_ 参数等于 8,也就是说,我们将收集 8 个交易策略的单个实例的组。我们的第二阶段 EA 允许我们在此参数中设置从 1 到 16 的值。我选择值 8 的原因与第一阶段一项工作的任务数量相同 - 不太少,也不太多。我可能会稍后将其移到脚本输入参数中。
// Stage 2 int k = 0; FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the second stage string params = StringFormat(paramsTemplate2, IntegerToString(id_jobs1[k])); // Request to create a second stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage2, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs2, id_job); k++; // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } });
在第二阶段,我们仅为单个作业创建一个优化任务,因为在一个优化循环中,我们选择了相当不错的交易策略单个实例组。我们将使用用户标准作为优化标准。
我们还将添加的作业的 ID 保存到 id_jobs2 数组中(我们最终不需要它们)。这些 ID 在添加阶段时可能会有用,因此我们不会删除它们。
在第三阶段,参数模板仅包含最终组的名称,它将被添加到库中:
// Template of optimization parameters at the third stage string paramsTemplate3 = "groupName_=%s\n" "passes_=";
我们根据项目的名称和版本以及优化间隔的结束日期形成最终组的名称,并将其替换到用于创建第三阶段工作的模板中。由于在第三阶段,我们收集了所有先前阶段的结果,因此只创建了一个作业及其任务:
// Stage 3 // Use the optimization parameters template for the third stage string params = StringFormat(paramsTemplate3, projectName_ + "_v." + projectVersion_ + "_" + TimeToString(toDate_, TIME_DATE)); // // Request to create a third stage job string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage3, "GBPUSD", "D1", params); ulong id_job = DB::Insert(query); // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 0); DB::Execute(query);
在此之后,剩下的就是更改项目状态,使其排队等待执行:
//+------------------------------------------------------------------+ //| Queueing the project for execution | //+------------------------------------------------------------------+ void QueueProject() { string query = StringFormat("UPDATE projects SET status='Queued' WHERE id_project=%d;", id_project); DB::Execute(query); }
将所做的更改保存到当前文件夹中的新文件 CreateProject.mq5 。
还有一件事,可以安全地假设数据库结构是永久性的,因此可以将其集成到库中。为了完成这项任务,我们创建了 db.schema.sql 文件,其中数据库结构作为一组 SQL 命令,并将其作为资源连接到 Database.mqh :
// Import sql file for creating DB structure #resource "db.schema.sql" as string dbSchema
我们还稍微改变了 Connect() 方法的逻辑 —— 如果没有指定名称的数据库,它将使用SQL命令从作为资源加载的文件中自动创建。同时,我们去掉了 ExecuteFile() 方法,因为它不再在任何地方使用。
最后,我们可以尝试运行已实现的代码了。
填充数据库
我们不会同时生成很多项目,而是只限制为 4 个。为此,我们只需将 EA 脚本放置在任意图表上 4 次,每次设置必要的参数。让除结束日期之外的所有参数的值保持等于默认值。我们每次都会通过给测试间隔增加一个月来更改结束日期。
最终我们得到大致如下的数据库内容。项目表包含四个项目:
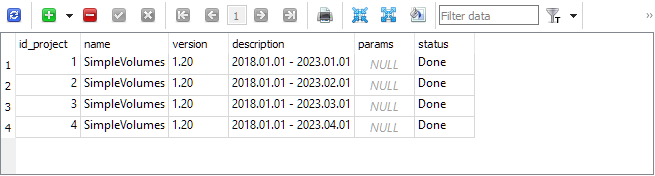
每个项目的阶段表有四个阶段。创建项目时会自动创建一个名为“单一测试器通过”的附加阶段,当我们想要在自动优化传送带之外启动单一策略测试器传递时使用该阶段:
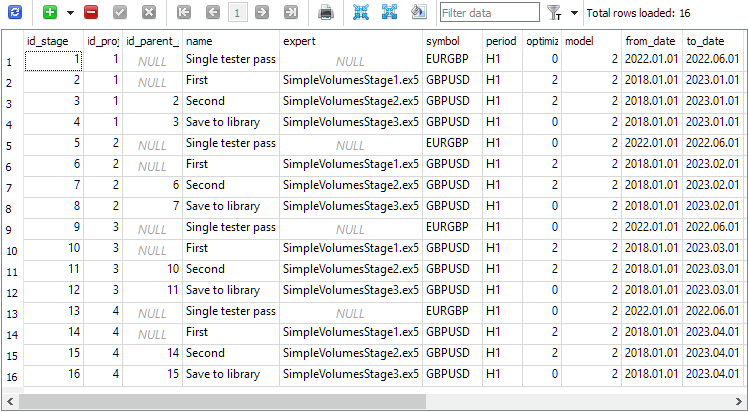
相应的作业已添加到作业表中:
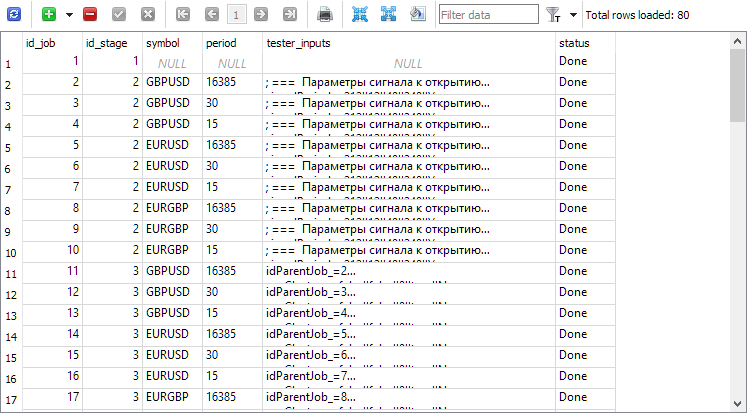
项目启动执行后,大约四天内就取得了成果。尽管努力优化性能,但这肯定不是一个很短的时间。但也不是太大,以致无法分配。我们可以在 strategy_groups 组库表中看到:

检查 id_pass 以查看 passes 表中的初始化字符串,例如:
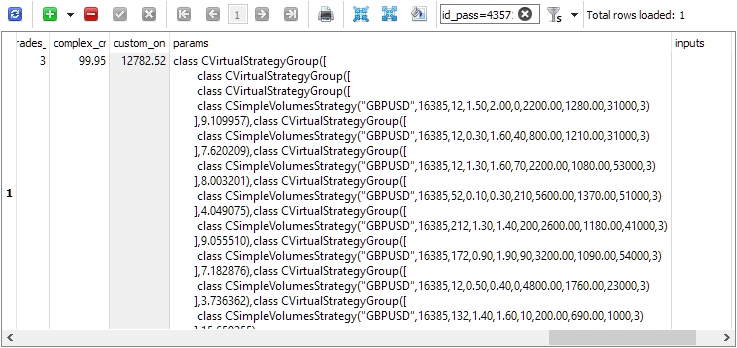
或者我们可以将通过 ID 替换为 SimpleVolumesStage3.ex5 第三阶段 EA 的输入,并在选定的时间间隔内在测试器中运行它:
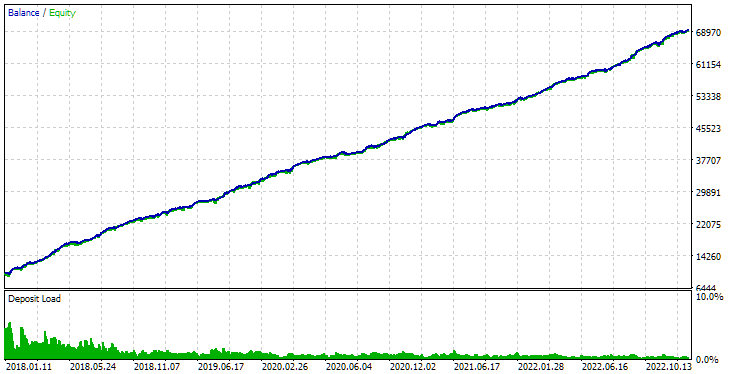
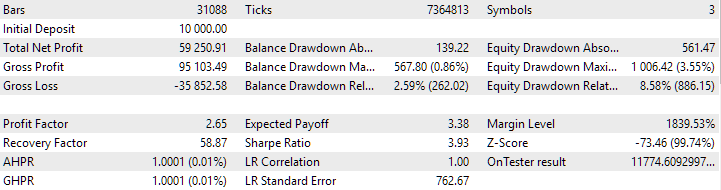
图 3.SimpleVolumesStage3.ex5 EA 在 2018.01.01 - 2023.01.01 区间内 id_pass =876663 的通过结果
我们现在就到此为止,在接下来的文章中对获得的结果进行更详细的分析。
结论
因此,我们能够自动创建任务来启动自动优化输送机,该输送机包括三个阶段。这仍然只是一份草案,将使我们能够确定进一步发展的首选方向。在每个项目的传送阶段完成后,实现自动合并或替换最终 EA 的初始化字符串的问题仍然悬而未决。
但有一件事已经可以肯定了,输送机中优化任务的执行顺序不是很好。现在我们必须等待第一阶段的所有工作全面完成才能开始第二阶段。同样,只有第二阶段的所有工作完成后,第三阶段才会开始。如果我们计划以某种方式实现最终 EA 初始化字符串的“热”替换,该替换与正在进行的优化并行地在帐户上持续工作,那么我们可以使这些更新更小,但更频繁。这可能会改善结果,但这仍然只是一个需要检验的假设。
同样值得注意的是,开发的 EA 脚本只专注于为所考虑的模型交易策略创建优化项目。另一种策略需要对源代码进行一些细微的更改。至少,在优化的第一阶段,您必须更改输入参数字符串的模板。我们还没有将这些模板移动到输入中,因为直接在那里设置它们很不方便。然而,进一步地,我们可能会开发一些格式来描述创建项目的任务,EA脚本将从文件上传该任务。
感谢您的关注!期待很快与您见面!
重要警告
本文和本系列之前的所有文章中的所有结果仅基于历史测试数据,并不保证未来会有任何利润。该项目中的工作具有研究性质。所有已发表的结果都可以由任何人使用,风险自负。
存档内容
| # | 名称 | 版本 | 描述 | 最近修改 |
|---|---|---|---|---|
| MQL5/Experts/Article.16373 | ||||
| 1 | Advisor.mqh | 1.04 | EA 基类 | 第 10 部分 |
| 2 | ClusteringStage1.py | 1.01 | 对第一阶段优化结果进行聚类的程序 | 第 20 部分 |
| 3 | CreateProject.mq5 | 1.00 | 用于创建具有阶段、作业和优化任务的项目的 EA 脚本。 | 第 21 部分 |
| 4 | Database.mqh | 1.09 | 处理数据库的类 | 第 21 部分 |
| 5 | db.schema.sql | 1.05 | 数据库结构 | 第 20 部分 |
| 6 | ExpertHistory.mqh | 1.00 | 用于将交易历史导出到文件的类 | 第 16 部分 |
| 7 | ExportedGroupsLibrary.mqh | — | 生成的文件列出了策略组名称及其初始化字符串数组 | 第 17 部分 |
| 8 | Factorable.mqh | 1.02 | 从字符串创建的对象的基类 | 第 19 部分 |
| 9 | GroupsLibrary.mqh | 1.01 | 用于处理选定策略组库的类 | 第 18 部分 |
| 10 | HistoryReceiverExpert.mq5 | 1.00 | 用于与风险管理器回放交易历史的 EA | 第 16 部分 |
| 11 | HistoryStrategy.mqh | 1.00 | 用于回放交易历史的交易策略类 | 第 16 部分 |
| 12 | Interface.mqh | 1.00 | 可视化各种对象的基类 | 第 4 部分 |
| 13 | LibraryExport.mq5 | 1.01 | EA 将库中选定通过的初始化字符串保存到 ExportedGroupsLibrary.mqh 文件 | 第 18 部分 |
| 14 | Macros.mqh | 1.02 | 用于数组操作的有用的宏 | 第 16 部分 |
| 15 | Money.mqh | 1.01 | 资金管理基类 | 第 12 部分 |
| 16 | NewBarEvent.mqh | 1.00 | 用于定义特定交易品种的新柱形的类 | 第 8 部分 |
| 17 | Optimization.mq5 | 1.03 | EA 管理优化任务的启动 | 第 19 部分 |
| 18 | Optimizer.mqh | 1.01 | 项目自动优化管理器类 | 第 20 部分 |
| 19 | OptimizerTask.mqh | 1.01 | 优化任务类 | 第 20 部分 |
| 20 | Receiver.mqh | 1.04 | 将未平仓交易量转换为市场仓位的基类 | 第 12 部分 |
| 21 | SimpleHistoryReceiverExpert.mq5 | 1.00 | 简化的EA,用于回放交易历史 | 第 16 部分 |
| 22 | SimpleVolumesExpert.mq5 | 1.20 | 用于多组模型策略并行运行的 EA。参数将从内置组库中获取。 | 第 17 部分 |
| 23 | SimpleVolumesStage1.mq5 | 1.18 | 交易策略单实例优化EA(第一阶段) | 第 19 部分 |
| 24 | SimpleVolumesStage2.mq5 | 1.02 | 交易策略实例组优化EA(第二阶段) | 第 19 部分 |
| 25 | SimpleVolumesStage3.mq5 | 1.02 | 将生成的标准化策略组保存到具有给定名称的组库中的 EA。 | 第 20 部分 |
| 26 | SimpleVolumesStrategy.mqh | 1.10 | 使用分时交易量的交易策略类 | 第 21 部分 |
| 27 | Strategy.mqh | 1.04 | 交易策略基类 | 第 10 部分 |
| 28 | SymbolsMonitor.mqh | 1.00 | 用于获取交易工具(交易品种)信息的类 | 第 21 部分 |
| 29 | TesterHandler.mqh | 1.05 | 优化事件处理类 | 第 19 部分 |
| 30 | VirtualAdvisor.mqh | 1.08 | 处理虚拟仓位(订单)的 EA 类 | 第 21 部分 |
| 31 | VirtualChartOrder.mqh | 1.01 | 图形虚拟仓位类 | 第 18 部分 |
| 32 | VirtualFactory.mqh | 1.04 | 对象工厂类 | 第 16 部分 |
| 33 | VirtualHistoryAdvisor.mqh | 1.00 | 交易历史回放 EA 类 | 第 16 部分 |
| 34 | VirtualInterface.mqh | 1.00 | EA GUI 类 | 第 4 部分 |
| 35 | VirtualOrder.mqh | 1.08 | 虚拟订单和仓位类 | 第 21 部分 |
| 36 | VirtualReceiver.mqh | 1.03 | 将未平仓交易量转换为市场仓位的类(接收方) | 第 12 部分 |
| 37 | VirtualRiskManager.mqh | 1.02 | 风险管理类(风险管理器) | 第 15 部分 |
| 38 | VirtualStrategy.mqh | 1.05 | 具有虚拟仓位的交易策略类 | 第 15 部分 |
| 39 | VirtualStrategyGroup.mqh | 1.00 | 交易策略组类 | 第 11 部分 |
| 40 | VirtualSymbolReceiver.mqh | 1.00 | 交易品种接收器类 | 第 3 部分 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/16373
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
开发多币种智能交易系统(第 21 部分)》一文已经发布:为重要实验做准备并优化代码:
作者:Yuriy Bykov
不幸的是, ,一切并不像 我们 希望的那样 简单 。 为了 能够启动第三阶段的 Expert Advisor , 有必要指定 作为 前几个阶段的优化 管道结果 而获得的通行证 的 ID。 如何获得 ,请参阅 。
明白了。不过,既然您花了这么多精力以更简单的方式来描述您的工作,如果您能制作一个视频教程来教授您正在创建的 EA 集的操作/优化,那就更好了。谢谢
我明白了。不过,既然您花了这么多精力来以更简单的方式描述您的工作,如果您能制作一个视频教程来教授您正在创建的一套 EA 的操作/优化,那就更好了。谢谢
您好,感谢您的建议。我不能保证我真的能为文章录制视频,但我会考虑如何以及以何种形式制作视频来帮助文章的读者。
你好,谢谢你的建议。我不能保证真的能为文章录制视频,但我会考虑如何以及以何种形式制作视频,为文章读者提供帮助。
谢谢。非常简单的几秒钟就足够了。由于 MT5 中的策略测试和优化比 MT4 中的更加复杂,正在过渡的人有时会感到困难。您所能做的就是在文章中显示您在获得这些结果时所使用的确切设置。
HI Download Last Part Files (21) How I Can User This Advisor Can u Help me please