
Desarrollamos un asesor experto multidivisas (Parte 22): Inicio de la transición a la sustitución dinámica de ajustes
Introducción
En las dos partes anteriores de nuestra serie de artículos, nos preparamos seriamente para continuar experimentando con la optimización automática de los asesores expertos comerciales. Hasta ahora hemos hecho hincapié en la creación de un proceso de optimización que consta de tres etapas:
- Optimización de instancias de estrategias individuales para combinaciones específicas de símbolos y marcos temporales.
- Formación de grupos a partir de los mejores ejemplares individuales obtenidos en la primera etapa.
- Generación de la cadena de inicialización del asesor experto final que une los grupos formados y guardarla en la biblioteca.
Para permitir la automatización de la creación de la propia línea troncal, hemos desarrollado un script especializado de asesor experto. Este permite poblar la base de datos con proyectos de optimización creando etapas, actividades y tareas para ellos según los parámetros y plantillas establecidos. Este enfoque garantiza que las tareas de optimización puedan seguir realizándose en un orden concreto, pasando de una etapa a otra.
También hemos buscado formas de mejorar el rendimiento mediante el perfilado y la optimización del código. Hemos prestado especial atención al trabajo con objetos que organizan la recepción de información sobre instrumentos (símbolos) comerciales. Esto ha reducido significativamente el número de llamadas a los métodos para recuperar los datos de precios y las especificaciones de los símbolos.
El resultado de este trabajo ha sido la generación automática de resultados que pueden utilizarse para experimentos y análisis posteriores. Esto abre el camino para probar hipótesis sobre cómo la frecuencia y el orden de la sobreoptimización pueden influir en los resultados comerciales. Pero ese camino aún está por recorrer.
En el nuevo artículo, profundizaremos en la implementación de un nuevo mecanismo de carga de parámetros de los asesores expertos finales, que debería permitir la sustitución parcial o completa de la composición y los parámetros de las instancias únicas de las estrategias comerciales tanto durante una sola pasada en el simulador de estrategias como durante el funcionamiento del asesor experto final en la cuenta comercial.
Trazando el camino
Vamos a intentar describir con más detalle lo que queremos conseguir. De forma ideal, el funcionamiento del sistema debería ser algo parecido a esto:
- Se genera un proyecto con la fecha actual como fecha final del periodo de optimización.
- El proyecto funciona como una cinta transportadora. Su ejecución tarda entre unos días y unas semanas en completarse.
- Los resultados se cargan en el asesor experto final. Si el asesor experto final aún no ha negociado, se ejecuta en una cuenta real. Si ya ha trabajado en una cuenta, sus parámetros se sustituyen por otros nuevos obtenidos después de que el último proyecto haya terminado de pasar por el pipeline.
- Vamos a pasar al punto 1.
Analizaremos cada uno de estos puntos. Para implementar el primero, ya disponemos de un script de asesor experto para generar el proyecto de la última parte, en el que podemos utilizar parámetros para seleccionar la fecha final de optimización. Pero hasta ahora solo se inicia manualmente. Esto puede solucionarse añadiendo una etapa adicional a la cadena de ejecución del proyecto, generando un nuevo proyecto cuando todas las demás etapas del proyecto actual hayan terminado. Entonces solo podremos ejecutarlo manualmente la primera vez.
Para el segundo punto, solo necesitamos tener un terminal con el asesor experto Optimisation.ex5 instalado; este tiene la base de datos requerida en sus parámetros. En cuanto aparezcan en él nuevas tareas de proyecto no finalizadas, se iniciará su ejecución por orden de prioridad. La última etapa, que precede a la de creación del nuevo proyecto, debe comunicar de alguna manera los resultados de la optimización del proyecto al asesor final.
El tercer punto es el más difícil. Ya hemos creado una variante de transmisión de parámetros al asesor experto final, pero esta aún requiere operaciones manuales: necesitamos ejecutar un asesor experto aparte que exporte la biblioteca de parámetros a un archivo, luego copiar este archivo a la carpeta del proyecto, y luego recompilar el asesor experto final. Aunque ahora podemos transferir la ejecución de estas operaciones al código del programa, el esquema en sí empieza a parecer demasiado farragoso. Querríamos hacer algo más sencillo y fiable.
Otra desventaja del método implementado de transferencia de parámetros al asesor experto final es la imposibilidad de sustituir parcialmente los parámetros. Solo se puede realizar una sustitución completa, lo cual implica cerrar todas las posiciones abiertas, si las hubiera, y empezar a negociar de cero. Y esta desventaja no es fundamentalmente corregible si uno se mantiene dentro del método existente.
Recordemos que por parámetros entendemos ahora los parámetros de un gran número de instancias de estrategias comerciales individuales que funcionan en paralelo en un asesor experto final. Si los parámetros antiguos se sustituyen momentáneamente por otros nuevos, aunque sean en su mayoría iguales a los antiguos, lo más probable es que la aplicación actual no pueda cargar correctamente la información sobre las posiciones virtuales anteriormente abiertas. Esto solo será posible si el número y el orden en que se han colocado los parámetros de las instancias únicas en la cadena de inicialización del asesor experto final coinciden completamente.
Para permitir la sustitución parcial de parámetros, hay que organizar de algún modo la existencia simultánea de los parámetros antiguos y los parámetros nuevos. En este caso, podemos desarrollar un algoritmo de transición suave sin modificar algunas de las instancias individuales. Sus posiciones virtuales deberían seguir en funcionamiento. Las posiciones de las instancias que no figuraren entre los nuevos parámetros deben cerrarse correctamente, y las nuevas que se acaban de añadir deberían empezar de cero.
Parece que se avecinan cambios más radicales de lo que querríamos. Pero qué se le va a hacer, si no ve otra forma de conseguir el resultado deseado, es mejor aceptar cuanto antes su necesidad. Si sigue avanzando en una dirección que no es la correcta, cuanto más se aleje, más difícil le resultará tomar un nuevo camino.
Por ello, es hora de pasar al lado oscuro del almacenamiento de toda la información sobre el funcionamiento del asesor experto en la base de datos. Además, en una base de datos separada, porque las bases de datos utilizadas para la optimización son muy pesadas (varios gigabytes por proyecto). No tiene sentido mantenerlas disponibles para la asesor experto final, ya que solo se necesitará una cantidad minúscula de información de ellas para el trabajo real.
También resulta deseable que podamos diseñar de forma diferente el orden de los pasos de la optimización automática. Ya lo mencionamos en la Parte 20, llamándolo agrupación por símbolos y marcos temporales. Pero entonces no lo elegimos, porque sin la posibilidad de sustitución parcial de parámetros, no había necesidad en tal posibilidad de orden. Ahora, si funciona, resultará más favorable. Pero primero vamos a intentar implementar la transición a la utilización de una base de datos independiente para el asesor experto final con posibilidad de sustitución dinámica de los parámetros de las instancias individuales de la estrategia comercial.
Transformación de la cadena de inicialización
La tarea que tenemos entre manos es bastante extensa, así que avanzaremos a pasos pequeños. Para empezar, necesitaremos almacenar información sobre instancias individuales de estrategias comerciales en la base de datos del asesor experto. Esta información se proporciona ahora en la cadena de inicialización del asesor experto. El asesor experto puede obtenerla de la base de datos de optimización o de los datos (constantes de cadena) incrustados en el código del asesor experto, tomados de la biblioteca de parámetros en la fase de compilación. El primer método se utiliza en los asesores expertos de optimización (SimpleVolumesStage2.mq5 y SimpleVolumesStage3.mq5), mientras que el segundo método se utiliza en el asesor experto final (SimpleVolumesExpert.mq5).
Queremos añadir una tercera forma: la cadena de inicialización deberá dividirse en partes relacionadas con distintas instancias individuales de estrategias comerciales; estas partes se almacenarán en la base de datos del asesor experto. Entonces, el asesor experto desde su base de datos podrá leerlas y formar una cadena de inicialización completa a partir de los trozos. La cadena se utilizará para crear el objeto experto que realizará todo el trabajo posterior.
Para entender cómo podemos dividir la cadena de inicialización, veremos un ejemplo típico de esta, tomado del artículo de la semana pasada. Es bastante grande (~200 líneas), por lo que mostraremos solo la parte mínima necesaria que dé una idea de su estructura.
class CVirtualStrategyGroup([ class CVirtualStrategyGroup([ class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,12,1.00,1.30,80,3200.00,930.00,12000,3) ],8.428150), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,172,1.40,1.20,140,2200.00,1220.00,19000,3) ],12.357884), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,12,1.20,0.10,0,1800.00,780.00,8000,3) ],4.756016), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,172,0.30,0.10,150,4400.00,1000.00,1000,3) ],4.459508), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,12,0.50,1.10,200,2800.00,1030.00,32000,3) ],5.021593), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,172,1.40,1.70,100,200.00,1640.00,32000,3) ],18.155410), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,12,0.10,0.40,160,8400.00,1080.00,44000,3) ],4.313320), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,52,0.50,1.00,110,3600.00,1030.00,53000,3) ],4.490144), ],4.615527), class CVirtualStrategyGroup([ class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,12,0.10,0.80,240,4800.00,1620.00,57000,3) ],6.805962), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,52,0.50,1.80,40,400.00,930.00,53000,3) ],11.825922), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,212,1.30,1.50,160,600.00,1000.00,28000,3) ],16.866251), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,12,0.30,1.50,30,3000.00,1280.00,28000,3) ],5.824790), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,12,1.30,0.10,10,2000.00,780.00,1000,3) ],3.476085), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,12,0.10,0.10,0,16000.00,700.00,11000,3) ],4.522636), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,52,0.40,1.80,80,2200.00,360.00,25000,3) ],8.206812), class CVirtualStrategyGroup([ class CSimpleVolumesStrategy("GBPUSD",16385,12,0.10,0.10,0,19200.00,700.00,44000,3) ],2.698618), ],5.362505), class CVirtualStrategyGroup([ ... ],5.149065), ... class CVirtualStrategyGroup([ ... ],2.718278), ],2.072066)
Esta cadena de inicialización consta de grupos de estrategias comerciales deprimer, segundo y tercer nivel. Las instancias individuales de las estrategias comerciales propiamente dichas solo están anidadas en los grupos de tercer nivel. En cada instancia se indican parámetros. Cada grupo tiene un multiplicador de escala; hay uno en el primer nivel, así como en el segundo y en el tercero. El uso de multiplicadores de escala se comentó en la Parte 5. Son necesarios para normalizar la reducción máxima alcanzada en el periodo de prueba a un valor del 10%. Además, el valor del multiplicador de escala de un grupo que contiene varios grupos anidados, o varias instancias anidadas de estrategias, se dividirá primero por el número de elementos de este grupo y, a continuación, este nuevo multiplicador se aplicará a todos los elementos anidados. Este es el aspecto que tiene en el código del archivo VirtualStrategyGroup.mqh:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualStrategyGroup::CVirtualStrategyGroup(string p_params) { // Save the initialization string m_params = p_params; ... // Read the scaling factor m_scale = ReadDouble(p_params); // Correct it if necessary if(m_scale <= 0.0) { m_scale = 1.0; } if(ArraySize(m_groups) > 0 && ArraySize(m_strategies) == 0) { // If we filled the array of groups, and the array of strategies is empty, then PrintFormat(__FUNCTION__" | Scale = %.2f, total groups = %d", m_scale, ArraySize(m_groups)); // Scale all groups Scale(m_scale / ArraySize(m_groups)); } else if(ArraySize(m_strategies) > 0 && ArraySize(m_groups) == 0) { // If we filled the array of strategies, and the array of groups is empty, then PrintFormat(__FUNCTION__" | Scale = %.2f, total strategies = %d", m_scale, ArraySize(m_strategies)); // Scale all strategies Scale(m_scale / ArraySize(m_strategies)); } else { // Otherwise, report an error in the initialization string SetInvalid(__FUNCTION__, StringFormat("Groups or strategies not found in Params:\n%s", p_params)); } }
Así, la cadena de inicialización tiene una estructura jerárquica, en la que los niveles superiores están ocupados por grupos de estrategias, mientras que las propias estrategias se sitúan en el nivel inferior. Aunque un grupo de estrategias puede contener varias estrategias, durante el desarrollo del proyecto hemos llegado a la conclusión de que, en el nivel inferior, nos resulta más cómodo usar no varias estrategias en un grupo, sino envolver cada instancia de estrategia en su propio grupo personal. De ahí viene el tercer nivel. Los dos primeros niveles son el resultado de agrupar los resultados de la primera etapa de optimización y, a continuación, agrupar los resultados de la segunda etapa de optimización en el pipeline.
Ciertamente, podemos crear una estructura de tablas en la base de datos para conservar la jerarquía existente entre estrategias y grupos, pero ¿es esto necesario? En realidad, no. En el pipeline de optimización se exige una estructura jerárquica. Al intentar ejecutar el asesor experto final en una cuenta comercial, solo importa la lista de estrategias comerciales de instancia única con los multiplicadores de escala recalculados correctamente. Y una lista así requeriría una simple tabla para almacenarla en una base de datos. Así que vamos a añadir un método que rellene una lista de este tipo desde la cadena de inicialización, así como un método que realice la tarea inversa, es decir, que utilice la lista de instancias individuales de las estrategias comerciales, con los multiplicadores apropiados, para generar la cadena de inicialización para el asesor experto final.
Exportando una lista de estrategias
Empezaremos por el método de obtención de la lista de estrategias del experto. Este método debería ser un método de la clase de experto, porque en él tenemos toda la información que queremos convertir en la forma deseada para guardarla. ¿Qué queremos conservar para cada instancia individual de una estrategia comercial? En primer lugar, sus parámetros de inicialización y el multiplicador de escala.
Cuando escribí el párrafo anterior, aún no existían ni los rudimentos de un código que hiciera este trabajo. Parecía que la incertidumbre en forma de libertad de elección de realización simplemente no permitiría decantarse por ninguna en particular. Había muchas preguntas relacionadas con su mejora, sobre todo en términos de uso futuro. Pero la falta de una idea clara de lo que necesitaríamos en el futuro, y de lo que no, nos impedía hacer hasta la elección más insignificante. Por ejemplo, ¿debemos incluir el número de versión en el nombre de archivo de la base de datos que utilizará el asesor experto? ¿Y el número mágico? ¿Debe fijarse este nombre en los parámetros del asesor experto final, o debe formarse según un algoritmo concreto a partir del nombre de la estrategia y el número mágico? ¿O alguna cosa más?
En general, para estos casos, solo hay una forma de salir de este círculo vicioso. Debemos tomar alguna decisión, aunque no sea la mejor, y, basándonos en ella, hacer la siguiente y así sucesivamente. De lo contrario, el asunto no se pondrá en marcha. Ahora el código ya está escrito, así que resulta segura volver la vista atrás y repasar los pasos que hemos tenido que dar durante el desarrollo. Sí, no todas las soluciones han llegado al código final, no todas las soluciones se han corregido, pero todas han ayudado a llegar al estado actual, que intentaremos describir a continuación.
Bien, hablemos de la lista de estrategias. En primer lugar, vamos a decidir de dónde tomará el nombre. Digamos que del asesor de la tercera etapa, que antes realizó la exportación del grupo de estrategias para el asesor final. Pero, como ya se ha mencionado, para usar esta información en la asesor experto final, ha sido necesario realizar adicionalmente otras manipulaciones. A la salida de la tercera etapa, solo obteníamos identificadores de pasadas con nombres asignados en la tabla strategy_groups de la base de datos de optimización. Este es el aspecto de su contenido tras la optimización realizada en el marco de los trabajos de la Parte 21:
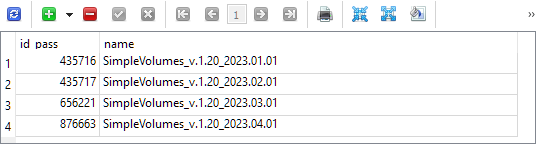
Cada uno de estas cuatro pasadas contiene una cadena de inicialización guardada de un grupo de instancias de estrategias comerciales individuales, elegidas durante la optimización en un intervalo de prueba con la misma fecha de inicio (2018.01.01) y una fecha de finalización ligeramente diferente especificada en el nombre del grupo.
En el archivo SimpleVolumesStage3.mq5, sustituiremos la llamada de la función que realizaba la exportación de este formulario por la llamada de otra función (que aún falta):
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Handle the completion of the pass in the EA object double res = expert.Tester(); // If the group name is not empty, save the pass to the library if(groupName_ != "") { // CGroupsLibrary::Add(CTesterHandler::s_idPass, groupName_, fileName_); expert.Export(groupName_, advFileName_); } return res; }
Asimismo, añadiremos un nuevo método Export() a la clase CVirtualAdvisor del asesor experto. Como parámetros, le transmitiremos el nombre del nuevo grupo y el nombre del archivo de base de datos del asesor experto al que se debe realizar la exportación. Tenga en cuenta que se trata ya de una nueva base de datos, no de la base de datos de optimización usada anteriormente. Para dar un valor a este argumento, añadiremos un parámetro de entrada al asesor de la tercera etapa:
input group "::: Saving to library" input string groupName_ = "SimpleVolumes_v.1.20_2023.01.01"; // - Version name (if empty - not saving) input string advFileName_ = "SimpleVolumes-27183.test.db.sqlite"; // - EA database name
A nivel de clase experta, aún no hemos trabajado directamente con la base de datos en ningún lugar. Todos los métodos que forman directamente consultas SQL se han colocado en una clase estática separada CTesterHandler. Así que no romperemos este esquema y redirigiremos los argumentos recibidos al nuevo método CTesterHandler::Export(), añadiéndoles un array de estrategias de asesor experto:
//+------------------------------------------------------------------+ //| Export the current strategy group to the specified EA database | //+------------------------------------------------------------------+ void CVirtualAdvisor::Export(string p_groupName, string p_advFileName) { CTesterHandler::Export(m_strategies, p_groupName, p_advFileName); }
Para poner en práctica este método, deberemos decidir la estructura de las tablas en la base de datos del asesor experto; la presencia de una nueva base de datos conllevará la necesidad de garantizar la capacidad de conectarse a diferentes bases de datos.
Acceso a diferentes bases de datos
Tras sudar un poco con la elección, nos hemos decidido por la siguiente opción. Vamos a modificar la clase CDatabase existente para que podamos especificar no solo el nombre del archivo de base de datos, sino también su tipo. Dado el nuevo tipo de base de datos, necesitaremos usar tres tipos diferentes:
- Base de datos de optimización. Se usa para organizar proyectos de optimización automática y para guardar la información sobre las pasadas del simulador de estrategias realizadas dentro del pipeline de optimización automática.
- Base de datos de selección de grupos (base de datos de optimización truncada). Se usa para enviar a los agentes de pruebas remotos la parte necesaria de la base de datos de optimización en la segunda fase del proceso de optimización automática.
- Base de datos de expertos (asesor final). Es la base de datos que será usada por el asesor experto final que trabaja en la cuenta comercial para guardar toda la información necesaria sobre su trabajo, incluyendo la composición del grupo utilizado de instancias únicas de estrategias comerciales.
Crea tres archivos para almacenar el código SQL para crear las bases de datos de cada tipo, conectándolas como recursos al archivo Database.mqh, y también crea una enumeración para los tres tipos de bases de datos:
// Import SQL files for creating database structures of different types #resource "db.opt.schema.sql" as string dbOptSchema #resource "db.cut.schema.sql" as string dbCutSchema #resource "db.adv.schema.sql" as string dbAdvSchema // Database type enum ENUM_DB_TYPE { DB_TYPE_OPT, // Optimization database DB_TYPE_CUT, // Database for group selection (stripped down optimization database) DB_TYPE_ADV, // EA (final EA) database };
Como ahora tendremos scripts disponibles para crear cualquiera de estos tres tipos de bases de datos (cuando las rellenemos con el contenido apropiado, por supuesto), podremos cambiar la lógica del método de conexión a bases de datos Connect(). Si resulta que la base de datos con el nombre transmitido no existe, en lugar de informar de un error, la crearemos desde el script y nos conectaremos a la base de datos recién creada.
Pero para entender qué tipo de base de datos necesitamos, vamos a añadir un parámetro de entrada al método de conexión, a través del cual podremos transmitir el tipo deseado. Para realizar menos cambios en el código existente, estableceremos el valor por defecto de este parámetro en el tipo de base de datos de optimización, ya que previamente nos hemos conectado a ella en todas partes:
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create(string p_schema) { bool res = Execute(p_schema); if(res) { PrintFormat(__FUNCTION__" | Database successfully created from %s", "db.*.schema.sql"); } } //+------------------------------------------------------------------+ //| Check connection to the database with the given name | //+------------------------------------------------------------------+ bool CDatabase::Connect(string p_fileName, ENUM_DB_TYPE p_dbType = DB_TYPE_OPT) { // If the database is open, close it Close(); // If a file name is specified, save it s_fileName = p_fileName; // Set the shared folder flag for the optimization and EA databases s_common = (p_dbType != DB_TYPE_CUT ? DATABASE_OPEN_COMMON : 0); // Open the database // Try to open an existing DB file s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | s_common); // If the DB file is not found, try to create it when opening if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | s_common); // Report an error in case of failure if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s Connect failed with code %d", s_fileName, GetLastError()); return false; } if(p_dbType == DB_TYPE_OPT) { Create(dbOptSchema); } else if(p_dbType == DB_TYPE_CUT) { Create(dbCutSchema); } else { Create(dbAdvSchema); } } return true; }
Tenga en cuenta que las bases de datos de optimización y de expertos se almacenan en la carpeta común del terminal, mientras que la base de datos para la selección de grupos se almacena en la carpeta de trabajo del terminal. De lo contrario, no será posible organizar su envío automático a los agentes de prueba.
Base de datos del experto
Para guardar la información sobre los grupos de estrategias formados en la base de datos del asesor experto, hemos decidido utilizar dos tablas: strategy_groups y strategies con la siguiente estructura:
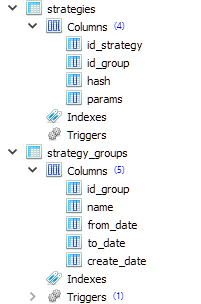
CREATE TABLE strategies ( id_strategy INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, id_group INTEGER REFERENCES strategy_groups (id_group) ON DELETE CASCADE ON UPDATE CASCADE, hash TEXT NOT NULL, params TEXT NOT NULL ); CREATE TABLE strategy_groups ( id_group INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT, from_date TEXT, to_date TEXT, create_date TEXT );
Como puede ver, cada entrada de la tabla de estrategias hace referencia a alguna entrada de la tabla de grupos de estrategias. Por consiguiente, podemos almacenar muchos grupos diferentes de estrategias en esta base de datos al mismo tiempo.
El campo hash de la tabla de strategies almacenará el valor hash de los parámetros de una única instancia de estrategia comercial. Puede usarse para comprender mejor si una instancia de un grupo es idéntica a una instancia de otro grupo.
El campo params de la tabla strategies almacenará la cadena de inicialización de una única instancia de estrategia comercial. A partir de ella, se podrá formar una cadena de inicialización común para todo el grupo de estrategias para crear un objeto de asesor experto (clase CVirtualAdvisor) en el asesor experto final.
Los campos from_date y to_date de la tabla strategy_groups almacenarán además las fechas de inicio y finalización del intervalo de optimización utilizado para obtener este grupo. Mientras tanto, estarán vacíos.
Y nuevamente sobre las estrategias de exportación
Ahora estamos listos para implementar el método de exportación de un grupo de estrategias a la base de datos del asesor experto en el archivo TesterHandler.mqh. Para ello, conéctese a la base de datos deseada, cree una entrada para un nuevo grupo de estrategias en la tabla strategy_groups, genere una cadena de inicialización para cada estrategia del grupo con su multiplicador normalizador actual (usando como envoltorio "class CVirtualStrategyGroup([strategy], scale)") y guárdelas en la tabla strategies.
//+------------------------------------------------------------------+ //| Export an array of strategies to the specified EA database | //| as a new group of strategies | //+------------------------------------------------------------------+ void CTesterHandler::Export(CStrategy* &p_strategies[], string p_groupName, string p_advFileName) { // Connect to the required EA database if(DB::Connect(p_advFileName, DB_TYPE_ADV)) { string fromDate = ""; // Start date of the optimization interval string toDate = ""; // End date of the optimization interval // Create an entry for a new strategy group string query = StringFormat("INSERT INTO strategy_groups VALUES(NULL, '%s', '%s', '%s', NULL) RETURNING rowid;", p_groupName, fromDate, toDate); ulong groupId = DB::Insert(query); PrintFormat(__FUNCTION__" | Export %d strategies into new group [%s] with ID=%I64u", ArraySize(p_strategies), p_groupName, groupId); // For each strategy FOREACH(p_strategies, { CVirtualStrategy *strategy = p_strategies[i]; // Form an initialization string as a group of one strategy with a normalizing factor string params = StringFormat("class CVirtualStrategyGroup([%s],%0.5f)", ~strategy, strategy.Scale()); // Save it in the EA database with the new group ID specified string query = StringFormat("INSERT INTO strategies " "VALUES (NULL, %I64u, '%s', '%s')", groupId, strategy.Hash(~strategy), params); DB::Execute(query); }); // Close the database DB::Close(); } }
Para calcular los valores hash a partir de los parámetros de la estrategia, trasladaremos un método existente de la clase de experto a la clase padre CFactorable. Por lo tanto, ahora estará disponible para todos los descendientes de esta clase, incluidas las clases de estrategia comercial.
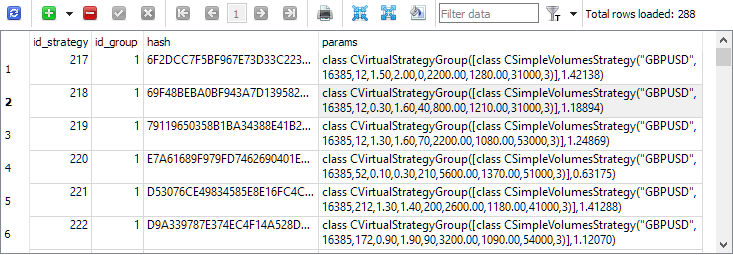
Ahora, si volvemos a ejecutar las terceras etapas de los proyectos de optimización, veremos que en la tabla strategies han aparecido entradas con instancias únicas de estrategias comerciales:
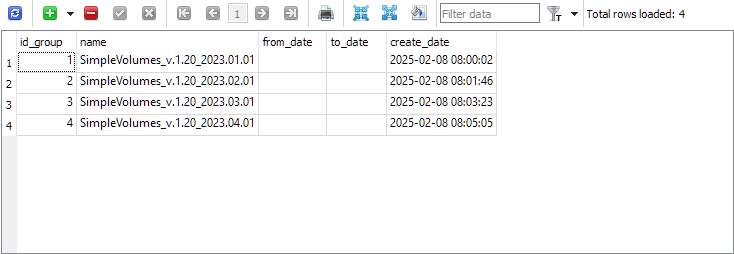
Mientras que en la tabla strategy_group han aparecido entradas de los grupos finales de cada proyecto:
Ya nos hemos aclarado con la exportación, ahora pasaremos a la operación inversa: la importación de estos grupos en el asesor experto final.
Estrategias de importación
No vamos a abandonar aún por completo el método de exportación de grupos aplicado anteriormente. Haremos posible el uso paralelo del nuevo método y el antiguo. Si el nuevo método demuestra ser bueno, podremos plantearnos abandonar el antiguo.
Ahora tomaremos nuestro asesor experto final SimpleVolumesExpert.mq5 y añadiremos un nuevo parámetro de entrada newGroupId_, a través del cual podremos establecer el valor del identificador del grupo de estrategias de la nueva biblioteca:
input group "::: Use a strategy group" input ENUM_GROUPS_LIBRARY groupId_ = -1; // - Group from the old library OR: input int newGroupId_ = 0; // - ID of the group from the new library (0 - last)
Luego añadiremos una constante para el nombre del asesor experto final:
#define __NAME__ "SimpleVolumes"
En la función de inicialización del asesor experto final, primero comprobaremos si se ha seleccionado algún grupo de la biblioteca antigua en el parámetro groupId_. Si no es así, obtendremos la cadena de inicialización de la nueva biblioteca. Para ello, añadiremos dos nuevos métodos estáticos a la clase de asesor experto CVirtualAdvisor: FileName() e Import(). Pueden llamarse antes de crearse el objeto de experto.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // ... // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the selected strategy group index from the library is valid, then if(groupId_ >= 0 && groupId_ < ArraySize(CGroupsLibrary::s_params)) { // Take the initialization string from the library for the selected group strategiesParams = CGroupsLibrary::s_params[groupId_]; } else { // Take the initialization string from the new library for the selected group // (from the EA database) strategiesParams = CVirtualAdvisor::Import( CVirtualAdvisor::FileName(__NAME__, magic_), newGroupId_ ); } // If the strategy group from the library is not specified, then we interrupt the operation if(strategiesParams == NULL) { return INIT_FAILED; } // ... // Successful initialization return(INIT_SUCCEEDED); }
Los cambios posteriores los realizaremos en el archivo VirtualAdvisor.mqh. Vamos a añadir los dos métodos mencionados:
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { protected: // ... public: // ... // Name of the file with the EA database static string FileName(string p_name, ulong p_magic = 1); // Get the strategy group initialization string // from the EA database with the given ID static string Import(string p_fileName, int p_groupId = 0); };
En el método FileName() especificaremos la regla de formación del nombre del archivo de la base de datos del asesor experto. Incluye el nombre del asesor experto final y su número mágico para que los asesores con números mágicos diferentes utilicen siempre bases de datos distintas. El sufijo ".test" también se añadirá automáticamente si el asesor experto se ejecuta en el simulador de estrategias. Esto se hace para que el asesor experto que se ejecuta en el simulador no sobrescriba accidentalmente la información en la base de datos del asesor experto que ya está trabajando en la cuenta comercial.
//+------------------------------------------------------------------+ //| Name of the file with the EA database | //+------------------------------------------------------------------+ string CVirtualAdvisor::FileName(string p_name, ulong p_magic = 1) { return StringFormat("%s-%d%s.db.sqlite", (p_name != "" ? p_name : "Expert"), p_magic, (MQLInfoInteger(MQL_TESTER) ? ".test" : "") ); }
En el método Import() obtendremos de la base de datos del asesor experto una lista de cadenas de inicialización de instancias únicas de estrategias comerciales pertenecientes a un grupo determinado. Si el ID del grupo deseado es igual a cero, se cargará la lista de estrategias del último grupo creado.
A partir de la lista resultante, formaremos la cadena de inicialización del grupo de estrategias concatenando las cadenas de inicialización de las estrategias mediante comas e insertando el resultado obtenido en el lugar deseado de la cadena formada de inicialización del grupo. El multiplicador de escala para el grupo en la cadena de inicialización se establecerá igual al número de estrategias. Esto es necesario para que al crear un asesor experto usando dicha cadena de inicialización de grupo, los multiplicadores de escala de todas las estrategias sean iguales a los almacenados en la base de datos del asesor experto. Después de todo, en el proceso de creación, los multiplicadores de todas las estrategias del grupo se dividen automáticamente por el número de estrategias del grupo. En este caso, simplemente nos estorbaba, y para evitar este obstáculo, aumentamos específicamente el multiplicador de grupo tantas veces como debería disminuir.
//+------------------------------------------------------------------+ //| Get the strategy group initialization string | //| from the EA database with the given ID | //+------------------------------------------------------------------+ string CVirtualAdvisor::Import(string p_fileName, int p_groupId = 0) { string params[]; // Array for strategy initialization strings // Request to get strategies of a given group or the last group string query = StringFormat("SELECT id_group, params " " FROM strategies" " WHERE id_group = %s;", (p_groupId > 0 ? (string) p_groupId : "(SELECT MAX(id_group) FROM strategy_groups)")); // Open the EA database if(DB::Connect(p_fileName, DB_TYPE_ADV)) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { int groupId; string params; } row; // Read data from the first result string while(DatabaseReadBind(request, row)) { // Remember the strategy group ID // in the static property of the EA class s_groupId = row.groupId; // Add another strategy initialization string to the array APPEND(params, row.params); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the EA database DB::Close(); } // Strategy group initialization string string groupParams = NULL; // Total number of strategies in the group int totalStrategies = ArraySize(params); // If there are strategies, then if(totalStrategies > 0) { // Concatenate their initialization strings with commas JOIN(params, groupParams, ","); // Create a strategy group initialization string groupParams = StringFormat("class CVirtualStrategyGroup([%s], %.5f)", groupParams, totalStrategies); } // Return the strategy group initialization string return groupParams; }
Este método no es del todo limpio porque además de devolver la cadena de inicialización del grupo, también establece el valor de una propiedad estática de la clase CVirtualAdvisor::s_groupId igual al ID del grupo de estrategias cargado. Esta forma de recordar qué grupo se carga desde la biblioteca parecía lo suficientemente sencilla y fiable, aunque no demasiado bonita.
Transferencia de datos del asesor final
Ya que hemos organizado una base de datos aparte para almacenar los parámetros de creación de instancias únicas de las estrategias comerciales utilizadas por el asesor experto final, no nos detendremos a mitad de camino y transferiremos el almacenamiento de otra información sobre el trabajo del asesor experto final en la cuenta comercial a la misma base de datos. Anteriormente, dicha información se guardaba en un archivo independiente mediante el método CVitrualAdvisor::Save() y se podía cargar desde él si era necesario mediante el método CVitrualAdvisor::Load().
La información guardada en un archivo incluye:
- Los parámetros generales del asesor experto: hora del último guardado, y... eso es todo por ahora. Pero esta lista puede ampliarse en el futuro.
- Los datos de cada estrategia: una lista de posiciones virtuales y cualquier dato que la estrategia necesitemos almacenar. Las estrategias actualmente en uso no requieren el almacenamiento de datos adicionales, pero para otros tipos de estrategias podría ser necesario.
- Los datos del gestor de riesgos: la situación actual, los niveles recientes de balance y fondos, los multiplicadores del tamaño de las posiciones, etc.
La desventaja del método de implementación elegido anteriormente es que el archivo de datos solo podía leerse e interpretarse en su totalidad. Si queremos, por ejemplo, aumentar el número de estrategias en la cadena de inicialización y reiniciar el asesor experto final, este no podrá leer sin errores el archivo con los datos guardados. Durante la lectura, el asesor experto final esperará que también haya información en el archivo para las estrategias añadidas. Pero no la habrá. Por lo tanto, el método de carga intentará interpretar los siguientes datos del archivo, que en realidad estarán relacionados con los datos del gestor de riesgos, como datos relacionados con estrategias comerciales adicionales. Está claro que esto no va a terminar bien.
Para resolver este problema, deberemos alejarnos del almacenamiento estrictamente secuencial de toda la información sobre el trabajo de la asesor experto final, y el uso de una base de datos será muy útil en este caso. Vamos a organizar en ella un simple almacén Key-Value de datos aleatorios.
Almacén Key-Value
Aunque antes hemos hablado de almacenar datos aleatorios, no hay que plantear el problema de forma tan amplia. Si nos fijamos en lo que se guarda actualmente en el archivo de datos final del asesor experto, podemos limitarnos a garantizar que se guarden los números individuales (enteros y reales) y los objetos de posición virtual. Recuerde también que cada estrategia tiene un array de posiciones virtuales de tamaño fijo. Este tamaño se fija en los parámetros de inicialización de la estrategia. Así que los objetos de posición virtual siempre existen como parte de algún array. Y para el futuro, contemplaremos la posibilidad de guardar no solo números individuales, sino también una serie de números de distintos tipos.
Considerando lo anterior, vamos a crear una nueva clase estática con los siguientes métodos:
- Conexiones a la base de datos deseada: Connect()/Close()
- Establecimiento de valores de distintos tipos: Set(...)
- Lectura de valores de distintos tipos: Get(...)
//+------------------------------------------------------------------+ //| Class for working with the EA database in the form of | //| Key-Value storage for properties and virtual positions | //+------------------------------------------------------------------+ class CStorage { protected: static bool s_res; // Result of all database read/write operations public: // Connect to the EA database static bool Connect(string p_fileName); // Close connection to the database static void Close(); // Save a virtual order/position static void Set(int i, CVirtualOrder* order); // Store a single value of an arbitrary simple type template<typename T> static void Set(string key, const T &value); // Store an array of values of an arbitrary simple type template<typename T> static void Set(string key, const T &values[]); // Get the value as a string for the given key static string Get(string key); // Get an array of virtual orders/positions for a given strategy hash static bool Get(string key, CVirtualOrder* &orders[]); // Get the value for a given key into a variable of an arbitrary simple type template<typename T> static bool Get(string key, T &value); // Get an array of values of a simple type by a given key into a variable template<typename T> static bool CStorage::Get(string key, T &values[]); // Result of operations static bool Res() { return s_res; } };
Hemos añadido una propiedad estática s_res a la clase y un método para leer su valor. Este almacenará la indicación de la aparición de cualquier error en las operaciones de lectura/escritura de la base de datos.
Como el uso de esta clase está destinado únicamente a guardar y cargar el estado del asesor experto final, la conexión a la base de datos también se realizará solo en estos momentos. No se realizará ninguna otra operación en la base de datos hasta que se cierre la conexión. Por consiguiente, el método de conexión a la base de datos abrirá inmediatamente una transacción dentro de la cual tendrán lugar todas las operaciones de la base de datos, mientras que en el método de cierre de la conexión esta transacción se confirmará o cancelará:
//+------------------------------------------------------------------+ //| Connect to the EA database | //+------------------------------------------------------------------+ bool CStorage::Connect(string p_fileName) { // Connect to the EA database if(DB::Connect(p_fileName, DB_TYPE_ADV)) { // No errors yet s_res = true; // Start a transaction DatabaseTransactionBegin(DB::Id()); return true; } return false; } //+------------------------------------------------------------------+ //| Close the database connection | //+------------------------------------------------------------------+ void CStorage::Close() { // If there are no errors, if(s_res) { // Confirm the transaction DatabaseTransactionCommit(DB::Id()); } else { // Otherwise, cancel the transaction DatabaseTransactionRollback(DB::Id()); } // Close connection to the database DB::Close(); }
Vamos a añadir dos tablas más con este conjunto de columnas a la estructura de la base de datos del asesor experto final:
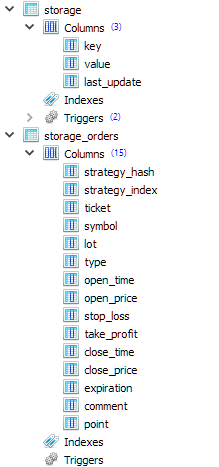
La primera tabla (strorage) se utilizará para almacenar valores numéricos individuales y arrays de valores numéricos. Las cadenas, sin embargo, también podrán almacenarse allí. La segunda tabla (storage_orders) se utilizará para almacenar información sobre elementos de arrays de posiciones virtuales para diferentes instancias de estrategias comerciales. Por lo tanto, la tabla comenzará con las columnas strategy_hash y strategy_index, que almacenan el valor hash de los parámetros de la estrategia (único para cada estrategia) y el índice de la posición virtual en el array de posiciones virtuales de la estrategia.
Todos los valores numéricos individuales se almacenarán llamando al método de plantilla Set(), que toma como parámetros una cadena con el nombre de la clave y una variable de tipo simple aleatorio T. Puede ser int, ulong o double, por ejemplo. Cuando se forma una consulta SQL para guardarla, el valor de esta variable se convierte al tipo string y se almacena en la base de datos como una cadena:
//+------------------------------------------------------------------+ //| Store a single value of an arbitrary simple type | //+------------------------------------------------------------------+ template<typename T> void CStorage::Set(string key, const T &value) { // Escape single quotes (can't avoid using them yet) // StringReplace(key, "'", "\\'"); // StringReplace(value, "'", "\\'"); // Request to save the value string query = StringFormat("REPLACE INTO storage(key, value) VALUES('%s', '%s');", key, (string) value); // Execute the request s_res &= DatabaseExecute(DB::Id(), query); if(!s_res) { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Execution failed in DB [adv], query:\n" "%s\n" "error code = %d", query, GetLastError()); } }
Si queremos almacenar un array de valores de un tipo simple para una clave, primero crearemos una cadena delimitada a partir de todos los valores del array transmitido. El carácter de coma se utilizará como separador. Esto ocurre en otro método de plantilla con el mismo nombre Set(), solo que su segundo parámetro no es una referencia a una variable de tipo simple, sino una referencia a un array de valores de tipo simple:
//+------------------------------------------------------------------+ //| Store an array of values of an arbitrary simple type | //+------------------------------------------------------------------+ template<typename T> void CStorage::Set(string key, const T &values[]) { string value = ""; // Concatenate all values from the array into one string separated by commas JOIN(values, value, ","); // Save a string with a specified key Set(key, value); }
Para realizar las operaciones inversas - leer de la base de datos - añadiremos el método Get(), que, según el valor de la clave, devolverá la cadena almacenada en la base de datos bajo esta clave. Para obtener un valor del tipo simple requerido, crearemos un método de plantilla con el mismo nombre, pero tomando adicionalmente una referencia a una variable de tipo simple aleatorio como segundo argumento. En él, primero obtendremos el valor de la base de datos como una cadena, y si ha sido recuperado, entonces convertiremos la cadena al tipo deseado y lo escribiremos en la variable transmitida.
//+------------------------------------------------------------------+ //| Get the value as a string for the given key | //+------------------------------------------------------------------+ string CStorage::Get(string key) { string value = NULL; // Return value // Request to get the value string query = StringFormat("SELECT value FROM storage WHERE key='%s'", key); // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Read data from the first result string DatabaseRead(request); if(!DatabaseColumnText(request, 0, value)) { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row in DB [adv] for request \n%s\n" "failed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Request in DB [adv] \n%s\nfailed with code %d", query, GetLastError()); } return value; } //+------------------------------------------------------------------+ //| Get the value for a given key into a variable | //| of an arbitrary simple type | //+------------------------------------------------------------------+ template<typename T> bool CStorage::Get(string key, T &value) { // Get the value as a string string res = Get(key); // If the value is received if(res != NULL) { // Cast it to type T and assign it to the target variable value = (T) res; return true; } return false; }
Utilizaremos los métodos añadidos para realizar el guardado y la carga del estado del asesor experto final.
Guardamos y cargamos el asesor experto
En el método CVirtualAdvisor::Save() para guardar el estado de asesor experto, solo tenemos que conectarnos a la base de datos del asesor experto y guardar todo lo necesario llamando directamente a los métodos de la clase CStorage, o indirectamente a través de la llamada a los métodos Save()/Load() en aquellos objetos que necesiten ser guardados.
Hasta ahora solo hemos almacenado directamente dos valores: la hora de los últimos cambios en las posiciones virtuales y el identificador del grupo de estrategias. A continuación, para todas las estrategias del ciclo, llamaremos a su método Save(). Y finalmente, llamaremos al método de guardado del gestor de riesgos. También deberemos realizar cambios en los métodos mencionados anteriormente para que también se guarden en la base de datos del asesor experto.
//+------------------------------------------------------------------+ //| Save status | //+------------------------------------------------------------------+ bool CVirtualAdvisor::Save() { // Save status if: if(true // later changes appeared && m_lastSaveTime < CVirtualReceiver::s_lastChangeTime // currently, there is no optimization && !MQLInfoInteger(MQL_OPTIMIZATION) // and there is no testing at the moment or there is a visual test at the moment && (!MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_VISUAL_MODE)) ) { // If the connection to the EA database is established if(CStorage::Connect(m_fileName)) { // Save the last modification time CStorage::Set("CVirtualReceiver::s_lastChangeTime", CVirtualReceiver::s_lastChangeTime); CStorage::Set("CVirtualAdvisor::s_groupId", CVirtualAdvisor::s_groupId); // Save all strategies FOREACH(m_strategies, ((CVirtualStrategy*) m_strategies[i]).Save()); // Save the risk manager m_riskManager.Save(); // Update the last save time m_lastSaveTime = CVirtualReceiver::s_lastChangeTime; PrintFormat(__FUNCTION__" | OK at %s to %s", TimeToString(m_lastSaveTime, TIME_DATE | TIME_MINUTES | TIME_SECONDS), m_fileName); // Close the connection CStorage::Close(); // Return the result return CStorage::Res(); } else { PrintFormat(__FUNCTION__" | ERROR: Can't open database [%s], LastError=%d", m_fileName, GetLastError()); return false; } } return true; }
En el método de carga CVirtualAdvisor::Load(), se realizarán las operaciones inversas: leeremos de la base de datos el valor de la última hora de modificación y el ID del grupo de estrategias, tras lo cual, cada estrategia y gestor de riesgos cargará su información. Si resulta que la hora del último cambio está en el futuro, no cargaremos nada más. Esta situación puede producirse al realizarse una pasada visual repetida del simulador de estrategias. La pasada anterior finalmente registra la información sobre la fecha de finalización de la prueba, y al comenzar la segunda pasada, el asesor experto utilizará la misma base de datos que la primera. Por lo tanto, solo deberá ignorar la información que ha llegado antes y empezar de cero.
Al llamar al método de carga, el objeto de asesor experto ya se habrá creado con el grupo de estrategias cuyo identificador se toma de los parámetros de entrada del asesor experto. Este identificador se almacena dentro del método CVirtualAdvisor::Import() en la propiedad estática CVirtualAdvisor::s_groupId. Por lo tanto, al cargar el identificador del grupo de estrategias desde la base de datos del asesor experto, tendremos la oportunidad de compararlo con un valor existente. Si son diferentes, significará que el asesor experto final se ha reiniciado con un nuevo grupo de estrategias, y probablemente necesite algunas acciones adicionales. Pero aún no está del todo claro qué medidas tendríamos que tomar necesariamente en este caso. Así que dejaremos el comentario correspondiente en el código para el futuro.
//+------------------------------------------------------------------+ //| Load status | //+------------------------------------------------------------------+ bool CVirtualAdvisor::Load() { bool res = true; ulong groupId = 0; // Load status if: if(true // file exists && FileIsExist(m_fileName, FILE_COMMON) // currently, there is no optimization && !MQLInfoInteger(MQL_OPTIMIZATION) // and there is no testing at the moment or there is a visual test at the moment && (!MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_VISUAL_MODE)) ) { // If the connection to the EA database is established if(CStorage::Connect(m_fileName)) { // Download the last modification time res &= CStorage::Get("CVirtualReceiver::s_lastChangeTime", m_lastSaveTime); // Download the saved strategy group ID res &= CStorage::Get("CVirtualAdvisor::s_groupId", groupId); // If the last modification time is in the future, then ignore the download if(m_lastSaveTime > TimeCurrent()) { PrintFormat(__FUNCTION__" | IGNORE LAST SAVE at %s in the future", TimeToString(m_lastSaveTime, TIME_DATE | TIME_MINUTES | TIME_SECONDS)); m_lastSaveTime = 0; return true; } PrintFormat(__FUNCTION__" | LAST SAVE at %s", TimeToString(m_lastSaveTime, TIME_DATE | TIME_MINUTES | TIME_SECONDS)); if(groupId != CVirtualAdvisor::s_groupId) { // Actions when launching an EA with a new group of strategies. // Nothing is happening here yet } // Load all strategies FOREACH(m_strategies, { res &= ((CVirtualStrategy*) m_strategies[i]).Load(); if(!res) break; }); if(!res) { PrintFormat(__FUNCTION__" | ERROR loading strategies from file %s", m_fileName); } // Download the risk manager res &= m_riskManager.Load(); if(!res) { PrintFormat(__FUNCTION__" | ERROR loading risk manager from file %s", m_fileName); } // Close the connection CStorage::Close(); return res; } } return true; }
Ahora bajaremos un nivel y veremos la implementación de los métodos para guardar y cargar estrategias.
Guardamos y cargamos la estrategia
En la clase CVirtualStrategy , implementaremos en estos métodos solo lo que será común a todas las estrategias que utilicen posiciones virtuales. Cada uno tiene un array de objetos de posiciones virtuales que necesita almacenarse y cargarse. La implementación detallada se reducirá a un nivel aún más bajo, y aquí solo llamaremos a los métodos especialmente creados de la clase CStorage:
//+------------------------------------------------------------------+ //| Save status | //+------------------------------------------------------------------+ void CVirtualStrategy::Save() { // Save virtual positions (orders) of the strategy FOREACH(m_orders, CStorage::Set(i, m_orders[i])); } //+------------------------------------------------------------------+ //| Load status | //+------------------------------------------------------------------+ bool CVirtualStrategy::Load() { bool res = true; // Download virtual positions (orders) of the strategy res = CStorage::Get(this.Hash(), m_orders); return res; }
Para los descendientes de la clase CVirtualStrategy (que incluye CSimpleVolumnesStrategy), además de almacenar un array de posiciones virtuales, podría ser necesario almacenar otra información. Nuestra estrategia de modelización es demasiado simple y no requiere guardar nada más que una lista de posiciones virtuales. Pero imaginemos que por algún motivo queremos almacenar un array de volúmenes de ticks y el valor del volumen medio de ticks. Como los métodos de guardado y carga se declaran virtuales, podemos redefinirlos en las clases herederas añadiendo el trabajo con los datos necesarios y llamando a los métodos de la clase básica para guardar y cargar posiciones virtuales:
//+------------------------------------------------------------------+ //| Save status | //+------------------------------------------------------------------+ void CSimpleVolumesStrategy::Save() { double avrVolume = ArrayAverage(m_volumes); // Let's form the common part of the key with the type and hash of the strategy string key = "CSimpleVolumesStrategy[" + this.Hash() + "]"; // Save the average tick volume CStorage::Set(key + ".avrVolume", avrVolume); // Save the array of tick volumes CStorage::Set(key + ".m_volumes", m_volumes); // Call the base class method (to save virtual positions) CVirtualStrategy::Save(); } //+------------------------------------------------------------------+ //| Load status | //+------------------------------------------------------------------+ bool CSimpleVolumesStrategy::Load() { bool res = true; double avrVolume = 0; // Let's form the common part of the key with the type and hash of the strategy string key = "CSimpleVolumesStrategy[" + this.Hash() + "]"; // Load the tick volume array res &= CStorage::Get(key + ".avrVolume", avrVolume); // Load the tick volume array res &= CStorage::Get(key + ".m_volumes", m_volumes); // Call the base class method (to load virtual positions) res &= CVirtualStrategy::Load(); return res; }
Lo único que quedará por hacer es guardar y cargar las posiciones virtuales.
Guardamos/cargamos posiciones virtuales
Anteriormente, en la clase de posición virtual, los métodos Save() y Load() realizaban directamente el guardado de la información deseada sobre el objeto de posición virtual actual en un archivo de datos. Ahora vamos a cambiar un poco el esquema. Para ello, añadiremos la estructura simple CVirtualOrderStruct, que tendrá campos para todos los datos de posición virtual requeridos:
// Structure for reading/writing // basic properties of a virtual order/position from the database struct VirtualOrderStruct { string strategyHash; int strategyIndex; ulong ticket; string symbol; double lot; ENUM_ORDER_TYPE type; datetime openTime; double openPrice; double stopLoss; double takeProfit; datetime closeTime; double closePrice; datetime expiration; string comment; double point; };
A diferencia de los objetos de posición virtuales, para los que todas las instancias creadas se registran estrictamente y se procesan automáticamente en el módulo del receptor de volúmenes comerciales, estas estructuras pueden crearse tantas veces como queramos y cuando queramos. Las utilizaremos para transferir información entre los objetos de posiciones virtuales y los métodos de guardado/carga en la base de datos del asesor experto implementados en la clase CStorage. Entonces los métodos de guardado y carga en la propia clase de posiciones virtuales solo rellenarán la estructura pasada o tomarán los valores de los campos de la estructura pasada para escribirlos en sus propiedades:
//+------------------------------------------------------------------+ //| Load status | //+------------------------------------------------------------------+ void CVirtualOrder::Load(const VirtualOrderStruct &o) { m_ticket = o.ticket; m_symbol = o.symbol; m_lot = o.lot; m_type = o.type; m_openPrice = o.openPrice; m_stopLoss = o.stopLoss; m_takeProfit = o.takeProfit; m_openTime = o.openTime; m_closePrice = o.closePrice; m_closeTime = o.closeTime; m_expiration = o.expiration; m_comment = o.comment; m_point = o.point; PrintFormat(__FUNCTION__" | %s", ~this); s_ticket = MathMax(s_ticket, m_ticket); m_symbolInfo = m_symbols[m_symbol]; // Notify the recipient and the strategy that the position (order) is open if(IsOpen()) { m_receiver.OnOpen(&this); m_strategy.OnOpen(&this); } else { m_receiver.OnClose(&this); m_strategy.OnClose(&this); } } //+------------------------------------------------------------------+ //| Save status | //+------------------------------------------------------------------+ void CVirtualOrder::Save(VirtualOrderStruct &o) { o.ticket = m_ticket; o.symbol = m_symbol; o.lot = m_lot; o.type = m_type; o.openPrice = m_openPrice; o.stopLoss = m_stopLoss; o.takeProfit = m_takeProfit; o.openTime = m_openTime; o.closePrice = m_closePrice; o.closeTime = m_closeTime; o.expiration = m_expiration; o.comment = m_comment; o.point = m_point; }
Por último, utilizaremos la tabla storage_orders creada en la base de datos del asesor experto para guardar allí las propiedades de cada posición virtual. Con ella trabará el método CStorage::Set(), al que deberemos transmitir el índice de posición virtual y el propio objeto de posición virtual:
//+------------------------------------------------------------------+ //| Save a virtual order/position | //+------------------------------------------------------------------+ void CStorage::Set(int i, CVirtualOrder* order) { VirtualOrderStruct o; // Structure for virtual position data order.Save(o); // Fill it // Escape quotes in the comment StringReplace(o.comment, "'", "\\'"); // Request to save string query = StringFormat("REPLACE INTO storage_orders VALUES(" "'%s',%d,%I64u," "'%s',%.2f,%d,%I64d,%f,%f,%f,%I64d,%f,%I64d,'%s',%f);", order.Strategy().Hash(), i, o.ticket, o.symbol, o.lot, o.type, o.openTime, o.openPrice, o.stopLoss, o.takeProfit, o.closeTime, o.closePrice, o.expiration, o.comment, o.point); // Execute the request s_res &= DatabaseExecute(DB::Id(), query); if(!s_res) { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Execution failed in DB [adv], query:\n" "%s\n" "error code = %d", query, GetLastError()); } }
El método CStorage::Get(), al que se transmite un array de objetos de posiciones virtuales como segundo argumento, cargará la información sobre las posiciones virtuales de la estrategia con el valor hash especificado en el primer argumento desde la tabla storage_orders:
//+------------------------------------------------------------------+ //| Get an array of virtual orders/positions | //| by the given strategy hash | //+------------------------------------------------------------------+ bool CStorage::Get(string key, CVirtualOrder* &orders[]) { // Request to obtain data on virtual positions string query = StringFormat("SELECT * FROM storage_orders " " WHERE strategy_hash = '%s' " " ORDER BY strategy_index ASC;", key); // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Structure for virtual position information VirtualOrderStruct row; // Read the data from the query result string by string while(DatabaseReadBind(request, row)) { orders[row.strategyIndex].Load(row); } } else { // Save the error and report it if necessary s_res = false; PrintFormat(__FUNCTION__" | ERROR: Execution failed in DB [adv], query:\n" "%s\n" "error code = %d", query, GetLastError()); } return s_res; }
Con esto damos por concluida la mayor parte de las modificaciones relacionadas con la transición al almacenamiento de información sobre el rendimiento del asesor final en una base de datos separada.
Una pequeña prueba
A pesar de la gran cantidad de cambios realizados, aún no hemos llegado a la fase en la que podamos probar un cambio dinámico real de la configuración del asesor experto final mientras se ejecuta. Pero ya podemos asegurarnos de que no hemos estropeado el mecanismo de inicialización del asesor experto final.
Para ello, hemos exportado un array de cadenas de inicialización de la base de datos de optimización de la forma antigua y nueva. Ahora la información sobre los cuatro grupos de estrategias está presente tanto en el archivo ExportedGroupsLibrary.mqh como en la base de datos del asesor experto, con el nombre SimpleVolumes-27183.test.db.sqlite. Vamos a compilar el archivo con el código del asesor experto final SimpleVolumesExpert.mq5.
Si fijamos así los valores de los parámetros de entrada,

entonces se usará la carga de la cadena de inicialización seleccionada desde el array interno del asesor experto final. Este array se rellenaba durante la compilación a partir de los datos ubicados en el archivo ExportedGroupsLibrary.mqh (a la antigua usanza).
Si los valores de los parámetros se especifican de este modo,

entonces la cadena de inicialización se formará según la información recibida de la base de datos del asesor experto (nuevo método).
Vamos a ejecutar el asesor experto final con el método antiguo de inicialización en un intervalo pequeño, por ejemplo, para el último mes. Obtenemos los siguientes resultados:
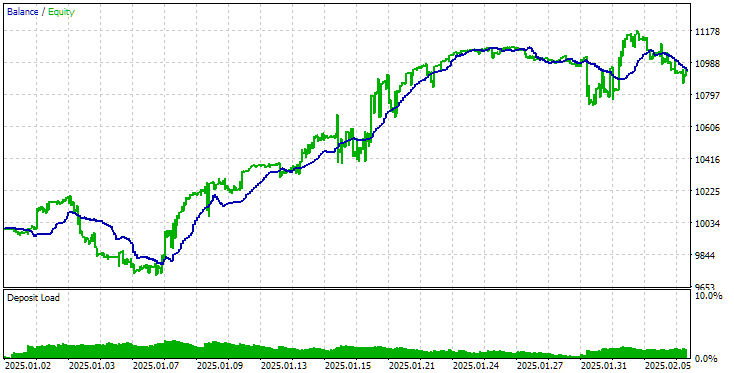
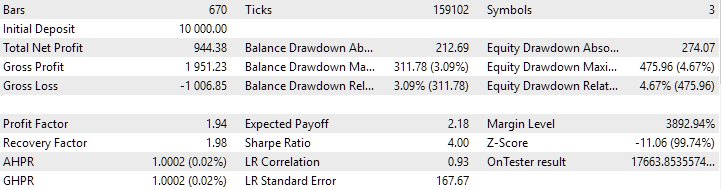
Resultados del asesor experto final con la antigua forma de cargar estrategias
Ahora vamos a ejecutar el asesor experto final con el nuevo método de inicialización en el mismo intervalo temporal. Los resultados son los siguientes:
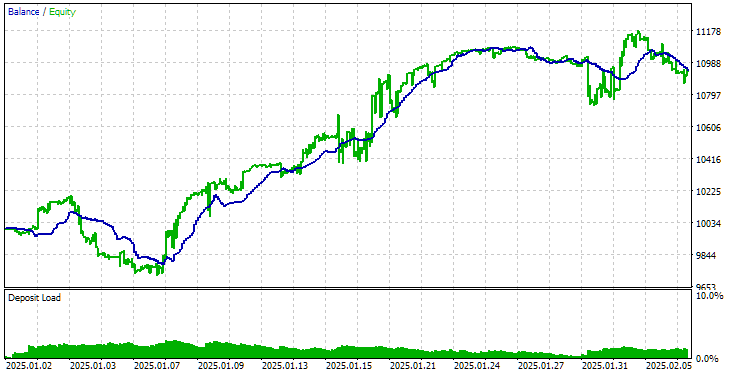
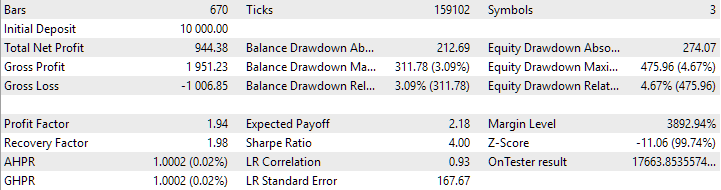
Resultados del asesor experto final con la nueva forma de cargar estrategias
Como podemos ver, los resultados obtenidos con el método antiguo y el nuevo coinciden plenamente.
Conclusión
Ha llegado el momento de resumir algunos de los resultados. La tarea que hemos emprendido ha sido un poco más difícil de lo imaginado inicialmente. Aunque todavía no hemos conseguido todos los resultados esperados, sí que hemos obtenido una solución bastante viable y adecuada para seguir probando y desarrollando. Ahora podemos ejecutar proyectos de optimización con la exportación de nuevos grupos de estrategias comerciales directamente a la base de datos usada por algún asesor experto que se ejecute en la cuenta comercial. Pero aún no hemos comprobado si este mecanismo es correcto.
Empezaremos a probarlo, como de costumbre, simulando el comportamiento deseado en un asesor experto que se ejecute en el simulador de estrategias. Si los resultados son satisfactorios allí, pasaremos a usarlo en los asesores expertos finales, que ya no funcionan en el simulador. Pero eso será en otra ocasión.
Gracias por su atención, ¡hasta pronto!
Advertencia importante:
Todos los resultados expuestos en este artículo y en todos los artículos anteriores de la serie se basan únicamente en datos de pruebas históricas y no ofrecen ninguna garantía de lograr beneficios en el futuro. El trabajo de este proyecto es de carácter exploratorio. Todos los resultados publicados pueden ser usados por cualquiera bajo su propia responsabilidad.
Contenido del archivo
| # | Nombre | Versión | Descripción | Cambios recientes |
|---|---|---|---|---|
| MQL5/Experts/Article.16452 | ||||
| 1 | Advisor.mqh | 1.04. | Clase básica del experto | Parte 10 |
| 2 | ClusteringStage1.py | 1.01 | Programa de clusterización de los resultados de la primera etapa de optimización | Parte 20 |
| 3 | CreateProject.mq5 | 1.00 | Script asesor para crear un proyecto con etapas, actividades y tareas de optimización. | Parte 21 |
| 4 | Database.mqh | 1.10 | Clase para trabajar con la base de datos | Parte 22 |
| 5 | db.adv.schema.sql | 1.00 | Esquema de la base de datos del asesor final | Parte 22 |
| 6 | db.cut.schema.sql | 1.00 | Esquema de una base de datos de optimización truncada | Parte 22 |
| 7 | db.opt.schema.sql | 1.05 | Esquema de la base de datos de optimización | Parte 22 |
| 8 | ExpertHistory.mqh | 1.00 | Clase para exportar la historia de transacciones a un archivo | Parte 16 |
| 9 | ExportedGroupsLibrary.mqh | - | Archivo generado con los nombres de los grupos de estrategias y un array con sus cadenas de inicialización | Parte 22 |
| 10 | Factorable.mqh | 1.03 | Clase básica de objetos creados a partir de una cadena (string) | Parte 22 |
| 11 | GroupsLibrary.mqh | 1.01 | Clase para trabajar con una biblioteca de grupos estratégicos seleccionados | Parte 18 |
| 12 | HistoryReceiverExpert.mq5 | 1.00 | Asesor experto para reproducir la historia de transacciones con el gestor de riesgos | Parte 16 |
| 13 | HistoryStrategy.mqh | 1.00 | Clase de estrategia comercial para reproducir la historia de transacciones | Parte 16 |
| 14 | Interface.mqh | 1.00 | Clase básica de visualización de diversos objetos | Parte 4 |
| 15 | LibraryExport.mq5 | 1.01 | Asesor que guarda las líneas de inicialización de las pasadas seleccionadas de la biblioteca en el archivo ExportedGroupsLibrary.mqh | Parte 18 |
| 16 | Macros.mqh | 1.05 | Macros útiles para operaciones con arrays | Parte 22 |
| 17 | Money.mqh | 1.01 | Clase básica de gestión de capital | Parte 12 |
| 18 | NewBarEvent.mqh | 1.00 | Clase de definición de una nueva barra para un símbolo específico | Parte 8 |
| 19 | Optimization.mq5 | 1.04. | Asesor que gestiona el inicio de las tareas de optimización | Parte 22 |
| 20 | Optimizer.mqh | 1.03 | Clase para el gestor de optimización automática de proyectos | Parte 22 |
| 21 | OptimizerTask.mqh | 1.03 | Clase para la tarea de optimización | Parte 22 |
| 22 | Receiver.mqh | 1.04. | Clase básica de transferencia de volúmenes abiertos a posiciones de mercado | Parte 12 |
| 23 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Asesor experto simplificado para reproducir la historia de transacciones | Parte 16 |
| 24 | SimpleVolumesExpert.mq5 | 1.21 | Asesor experto final para el funcionamiento en paralelo de varios grupos de estrategias modelo. Los parámetros se tomarán de la biblioteca de grupos incorporada. | Parte 22 |
| 25 | SimpleVolumesStage1.mq5 | 1.18 | Asesor experto para optimizar una única instancia de una estrategia comercial (Etapa 1) | Parte 19 |
| 26 | SimpleVolumesStage2.mq5 | 1.02 | Asesor experto para optimizar un grupo de instancias de estrategias comerciales (Etapa 2) | Parte 19 |
| 27 | SimpleVolumesStage3.mq5 | 1.03 | Asesor experto para guardar un grupo normalizado generado de estrategias en la biblioteca de grupos con el nombre indicado. | Parte 22 |
| 28 | SimpleVolumesStrategy.mqh | 1.11 | Clase de estrategia comercial con uso de volúmenes de ticks | Parte 22 |
| 29 | Storage.mqh | 1.00 | Clase de trabajo con almacenamiento Key-Value para el asesor experto final | Parte 22 |
| 30 | Strategy.mqh | 1.04. | Clase básica de estrategia comercial | Parte 10 |
| 31 | SymbolsMonitor.mqh | 1.00 | Clase de obtención de información sobre instrumentos comerciales (símbolos) | Parte 21 |
| 32 | TesterHandler.mqh | 1.06 | Clase para gestionar los eventos de optimización | Parte 22 |
| 33 | VirtualAdvisor.mqh | 1.09 | Clase de asesor experto para trabajar con posiciones (órdenes) virtuales | Parte 22 |
| 34 | VirtualChartOrder.mqh | 1.01 | Clase de posición virtual gráfica | Parte 18 |
| 35 | VirtualFactory.mqh | 1.04. | Clase de fábrica de objetos | Parte 16 |
| 36 | VirtualHistoryAdvisor.mqh | 1.00 | Clase experta para reproducir la historia de transacciones | Parte 16 |
| 37 | VirtualInterface.mqh | 1.00 | Clase de GUI del asesor | Parte 4 |
| 38 | VirtualOrder.mqh | 1.09 | Clase de órdenes y posiciones virtuales | Parte 22 |
| 39 | VirtualReceiver.mqh | 1.03 | Clase de transferencia de volúmenes abiertos a posiciones de mercado (receptor) | Parte 12 |
| 40 | VirtualRiskManager.mqh | 1.02 | Clase de gestión de riesgos (gestor de riesgos) | Parte 15 |
| 41 | VirtualStrategy.mqh | 1.08 | Clase de estrategia comercial con posiciones virtuales | Parte 22 |
| 42 | VirtualStrategyGroup.mqh | 1.00 | Clase de grupo o grupos de estrategias comerciales | Parte 11 |
| 43 | VirtualSymbolReceiver.mqh | 1.00 | Clase de receptor simbólico | Parte 3 |
| MQL5/Common/Files | Carpeta común de terminales | |||
| 44 | SimpleVolumes-27183.test.db.sqlite | - | Base de datos de expertos con cuatro grupos de estrategias añadidos | |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16452
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso