
Developing a multi-currency Expert Advisor (Part 21): Preparing for an important experiment and optimizing the code
Introduction
In the previous part, we started working on putting in order the automatic optimization conveyor, which allows us to obtain a new final EA taking into account the accumulated price data. However, we have not yet reached full automation, as difficult decisions still need to be made about how best to implement the final stages. They are difficult because if we make the wrong choice, we will have to redo a lot. Therefore, I really want to save my efforts and try to make the right choice. And nothing helps in making difficult decisions as much as... postponing them! Especially if we can afford it.
But we can postpone them in different ways. Instead of simply delaying the moment of choice, let's try to switch to another task that will seem to allow us to get distracted, but in fact its solution can at least help increase the motivation to make a choice if not work out the right path.
Interesting question
The stumbling block in many debates about the use of parameter optimization is the question of how long the obtained parameters can be used for trading in the future period while maintaining the profitability and drawdown at the specified levels. And is it even possible to do this?
Although there is a popular point of view that one cannot trust the repeatability of testing results in the future, and it is only a matter of luck when the strategy "breaks down". Probably almost all developers of trading strategies really want to believe this, otherwise the point of putting in a huge amount of effort into development and testing is lost.
Attempts to increase confidence that, by selecting good parameters, the strategy will be able to work successfully for some time have already been made repeatedly. There are articles that, in one way or another, consider the topic of periodic automatic selection of the best EA parameters. Validate EA by @fxsaber deserves a separate mention since it is precisely intended for conducting a very interesting experiment.
This tool allows us to take an arbitrary EA (the one being studied) and, having selected a certain period of time (for example, 3 years), launch the following process: the EA being studied will be optimized over a certain period (for example, 2 months), after which, using the best settings, trade in the strategy tester over a period of, say, two weeks. At the end of each two-week period, the EA being studied will again optimize for the previous two months and trade again for another two weeks. This will continue until the end of the selected 3 year interval is reached.
The end result will be a trading report showing how the EA under study would have traded over the course of all three years if it had really been periodically re-optimized and launched with updated parameters. It is clear that you can arbitrarily choose the mentioned time intervals at your own discretion. If any EA can show acceptable results with such re-optimization, then this will indicate its increased potential for use in real trading.
However, this tool has a significant limitation - the EA being studied must have open input parameters to perform optimization. If we take, for example, our final EAs obtained in the previous parts by combining many single instances, they do not have inputs that would allow them to influence the trading logic of opening positions. We will not take into account the parameters of money and risk management, since their optimization, although possible, is rather meaningless. After all, it is clear that if we increase the size of the opened positions, the result of the pass will show a greater profit, compared to what was previously obtained as a result of the pass with a smaller position size.
Therefore, let's try to implement something similar, but applicable to our developed EAs.
Mapping out the path
In general, we need a script to fill the database with almost identical projects. The main difference will be only in the start and end dates of the optimization period. The composition of stages, stage works and tasks within the work may be completely identical. Therefore, for now, you can make a service EA with a small number of inputs, including the start date and duration of the optimization period. By running it in optimization mode with a search for start dates, we can fill the database with similar projects. It is not yet clear what other parameters make sense to include in the inputs; we will decide on them as development progresses.
Completely running all optimization tasks, even within a single project, can take a long time. If there is not one such project that needs to be completed, but a dozen or more, then we are talking about rather time-consuming tasks. Therefore, it makes sense to see if it is possible to somehow speed up the work of stage EAs. To detect bottlenecks that need to be fixed, we will use the profiler included with MetaEditor.
Next we need to decide how to simulate the work from several obtained initialization strings (each project, after completing its tasks, will provide one initialization string of the final EA). Most likely, we will need to create a new testing EA specifically designed for this type of work. But I will probably put this off until the next article.
Let's first start by optimizing the code of the test EAs. After that, we will start creating a script for filling the database.
Code optimization
Before we dive into the implementation of the main task, let's see if there is any way to speed up the code of the EAs involved in auto optimization. To detect possible bottlenecks, let's take the final EA from the previous part for research. It combines 32 instances of single trading strategies (2 symbols * 1 timeframe * 16 instances = 32). This is, of course, much less than the expected total number of instances in the final EA, but during optimization, the absolute majority of our passes will use either one instance (at the first stage) or no more than 16 instances (at the second stage). Therefore, such a test subject EA will suit us perfectly.
Let's launch the EA in profiling mode on historical data. When running in this mode, a special version of the EA for profiling will be automatically compiled and launched in the strategy tester. Let's quote the description of using profiling from the Reference:
The Sampling method is used for profiling. The profiler pauses the operation of an MQL program (~10 000 times per second) and collects statistics on how many times a pause occurred in a particular code part. This includes analyzing call stacks to determine the "contribution" of each function to the total code execution time.
Sampling is a lightweight and accurate method. Unlike other methods, sampling does not make any changes to the analyzed code, which could affect its running speed.
The profiling report is presented as functions or program lines, for each of which there are two indicators available:
- Total CPU [unit,%] — how many times the function appeared in the call stack.
- Self CPU [unit of measurement,%] — the number of "pauses" which occurred directly within the specified function. This variable is crucial in identifying bottlenecks: according to statistics, pauses occur more often where more processor time is required.
The value is displayed as an absolute quantity and as a percentage of the total quantity.
This is what we have after completing the pass:
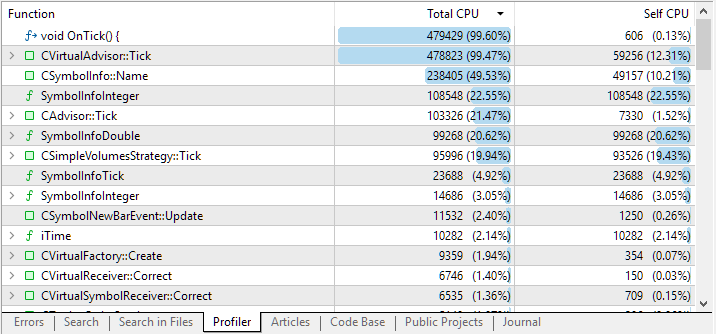
Fig. 1. Results of profiling the code of the studied EA
By default, the profiling results list shows large functions located at the top levels. But by clicking on the string with the function name, we can see a nested list of functions that were called from this one. This allows us to more accurately determine which sections of code took up the most CPU time.
In the first two strings, we expectedly saw the OnTick() handler, as well as the CVirtualAdvisor::Tick() handler called from it. Indeed, in addition to initialization, the EA spends most of its time handling incoming ticks. But the third and fourth strings of results raise reasonable questions.
Why do we have so many calls to the current symbol select method? Why is so much time spent on getting some integer properties of the symbol? Let's figure it out.
By expanding the string corresponding to the CSymbolInfo::Name(string name) method call, we can track that almost all the time is spent calling it from the function of checking the need to close the virtual position.
//+------------------------------------------------------------------+ //| Check the need to close by SL, TP or EX | //+------------------------------------------------------------------+ bool CVirtualOrder::CheckClose() { if(IsMarketOrder()) { // If this is a market virtual position, s_symbolInfo.Name(m_symbol); // Select the desired symbol s_symbolInfo.RefreshRates(); // Update information about current prices // ... } return false; }
This code was written quite a long time ago. At that moment, it was important to us that open virtual positions were correctly translated into real positions. Closing a virtual position was supposed to result in an immediate (or almost immediate) closure of some volume of real positions. Therefore, this check should be performed on every tick and for every open virtual position.
For self-sufficiency, we provided each CVirtualOrder class object with its CSymbolInfo class object instance, through which we requested all the necessary information about prices and specifications of the required trading instrument (symbol). Thus, for 16 instances of trading strategies using three virtual positions each, there will be 16*3 = 48 of them in the array of virtual positions. If the EA contains several hundred instances of trading strategies, and also uses a larger number of virtual positions, then the number of calls to the symbol selection method will increase many times over. But is it necessary?
When do we really need to call the symbol name selector method? Only if the virtual position symbol has changed. If it has not changed since the previous tick, then calling this symbol method is useless. The symbol can only change when opening a virtual position that either has not been opened before or was opened for a different symbol. This clearly does not happen on every tick, but much, much less frequently. Moreover, in the model strategy used, there is never a change of symbol for one virtual position, since one instance of the trading strategy works with a single symbol, which will be the symbol for all virtual positions of this instance of the strategy.
Then you can send the CSymbolInfo class objects to the trading strategy instance level, but this may also be redundant, since different trading strategy instances may use the same symbol. Therefore, we will take them even higher - to the global level. At this level, we only need to have the number of instances of the CSymbolInfo class objects equal to the number of different symbols used in the EA. Each CSymbolInfo instance will be created only when the EA needs to access the properties of a new symbol. Once created, a copy will be permanently assigned to a specific symbol.
Inspired by the following example from the book, we will create our own class CSymbolsMonitor. Unlike the example, we will not create a new class, which, although written much more neatly, will essentially repeat the functionality of an existing class in the standard library. Our class will act as a container for several objects of the CSymbolInfo class and ensure that a separate information object of the class is created for each symbol used.
To make it accessible from anywhere in the code, we will again use the Singleton design pattern in the implementation. The base of the class is formed by the m_symbols[] array storing the pointers to the CSymbolInfo class objects.
//+--------------------------------------------------------------------+ //| Class for obtaining information about trading instruments (symbols)| //+--------------------------------------------------------------------+ class CSymbolsMonitor { protected: // Static pointer to a single class instance static CSymbolsMonitor *s_instance; // Array of information objects for different symbols CSymbolInfo *m_symbols[]; //--- Private methods CSymbolsMonitor() {} // Closed constructor public: ~CSymbolsMonitor(); // Destructor //--- Static methods static CSymbolsMonitor *Instance(); // Singleton - creating and getting a single instance // Tick handling for objects of different symbols void Tick(); // Operator for getting an object with information about a specific symbol CSymbolInfo* operator[](const string &symbol); }; // Initializing a static pointer to a single class instance CSymbolsMonitor *CSymbolsMonitor::s_instance = NULL;
The implementation of the static method for creating a single instance of a class is similar to the implementations that have already been encountered earlier. The destructor will contain a loop for deleting created information objects.
//+------------------------------------------------------------------+ //| Singleton - creating and getting a single instance | //+------------------------------------------------------------------+ CSymbolsMonitor* CSymbolsMonitor::Instance() { if(!s_instance) { s_instance = new CSymbolsMonitor(); } return s_instance; } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CSymbolsMonitor::~CSymbolsMonitor() { // Delete all created information objects for symbols FOREACH(m_symbols, if(!!m_symbols[i]) delete m_symbols[i]); }
The public tick handling method will provide periodic updates of symbol specification and quote information. The specification may not change at all over time, but just in case, we will provide for its update once a day. We will update quotes every minute, since we use the EA's operating mode only for opening minute bars (for better repeatability of modeling results in the 1 minute OHLC mode and the every tick mode based on real ticks).
//+------------------------------------------------------------------+ //| Handle a tick for the array of virtual orders (positions) | //+------------------------------------------------------------------+ void CSymbolsMonitor::Tick() { // Update quotes every minute and specification once a day FOREACH(m_symbols, { if(IsNewBar(m_symbols[i].Name(), PERIOD_D1)) { m_symbols[i].Refresh(); } if(IsNewBar(m_symbols[i].Name(), PERIOD_M1)) { m_symbols[i].RefreshRates(); } }); }
Finally, we add an overloaded indexing operator to get a pointer to the desired object given a symbol name. It is in this operator that the automatic creation of new information objects for symbols that have not previously been accessed through this operator will occur.
//+-------------------------------------------------------------------------+ //| Operator for getting an object with information about a specific symbol | //+-------------------------------------------------------------------------+ CSymbolInfo* CSymbolsMonitor::operator[](const string &name) { // Search for the information object for the given symbol in the array int i; SEARCH(m_symbols, m_symbols[i].Name() == name, i); // If found, return it if(i != -1) { return m_symbols[i]; } else { // Otherwise, create a new information object CSymbolInfo *s = new CSymbolInfo(); // Select the desired symbol for it if(s.Name(name)) { // If the selection is successful, update the quotes s.RefreshRates(); // Add to the array of information objects and return it APPEND(m_symbols, s); return s; } else { PrintFormat(__FUNCTION__" | ERROR: can't create symbol with name [%s]", name); } } return NULL; }
Save the received code in the SymbolsMonitor.mqh file of the current folder. Now comes the turn of the code that will use the created class.
CVirtualAdvisor modification
In this class, we already have several objects that exist in a single copy and perform some specific tasks: a receiver of virtual position volumes, a risk manager, and a user information interface. Let's add a symbol monitor object to them. More precisely, we will create a class field that will store a pointer to the symbol monitor object:
class CVirtualAdvisor : public CAdvisor { protected: CSymbolsMonitor *m_symbols; // Symbol monitor object CVirtualReceiver *m_receiver; // Receiver object that brings positions to the market CVirtualInterface *m_interface; // Interface object to show the status to the user CVirtualRiskManager *m_riskManager; // Risk manager object ... public: ... };
The creation of the symbol monitor object will be initiated when the constructor is called by calling the CSymbolsMonitor::Instance() static method similar to other objects mentioned earlier. We will add the deletion of this object in the destructor.
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(string p_params) { ... // If there are no read errors, if(IsValid()) { // Create a strategy group CREATE(CVirtualStrategyGroup, p_group, groupParams); // Initialize the symbol monitor with a static symbol monitor m_symbols = CSymbolsMonitor::Instance(); // Initialize the receiver with the static receiver m_receiver = CVirtualReceiver::Instance(p_magic); // Initialize the interface with the static interface m_interface = CVirtualInterface::Instance(p_magic); ... } } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ void CVirtualAdvisor::~CVirtualAdvisor() { if(!!m_symbols) delete m_symbols; // Remove the symbol monitor if(!!m_receiver) delete m_receiver; // Remove the recipient if(!!m_interface) delete m_interface; // Remove the interface if(!!m_riskManager) delete m_riskManager; // Remove risk manager DestroyNewBar(); // Remove the new bar tracking objects }
Add calling the Tick() method to the new tick handler in order to monitor symbols. It is here that the quotes of all symbols used in the EA will be updated:
//+------------------------------------------------------------------+ //| OnTick event handler | //+------------------------------------------------------------------+ void CVirtualAdvisor::Tick(void) { // Define a new bar for all required symbols and timeframes bool isNewBar = UpdateNewBar(); // If there is no new bar anywhere, and we only work on new bars, then exit if(!isNewBar && m_useOnlyNewBar) { return; } // Symbol monitor updates quotes m_symbols.Tick(); // Receiver handles virtual positions m_receiver.Tick(); // Start handling in strategies CAdvisor::Tick(); // Risk manager handles virtual positions m_riskManager.Tick(); // Adjusting market volumes m_receiver.Correct(); // Save status Save(); // Render the interface m_interface.Redraw(); }
Taking this opportunity, let's add the ChartEvent event handler to this class with an eye to the future. For now, the same-name method of the m_interface interface object will be called in it. It does nothing at this stage.
Save the changes made to the VirtualAdvisor.mqh file in the current folder.
CVirtualOrder modification
As already mentioned, obtaining information about symbols is performed in the class of virtual positions. Therefore, let's start making changes from this class, and first of all, let's add pointers to the monitor (CSymbolsMonitor class) and the information object for a symbol (CSymbolInfo class):
class CVirtualOrder { private: //--- Static fields static ulong s_count; // Counter of all created CVirtualOrder objects CSymbolInfo *m_symbolInfo; // Object for getting symbol properties //--- Related recipient objects and strategies CSymbolsMonitor *m_symbols; CVirtualReceiver *m_receiver; CVirtualStrategy *m_strategy; ... }
Adding pointers to the composition of class fields implies that they should be assigned pointers to some created objects. And if these objects are created inside the methods of objects of this class, then it is necessary to take care of their correct deletion.
Let's add the initialization of the pointer to the symbol monitor and the clearing of the pointer to the symbol information object. Call the CSymbolsMonitor::Instance() static method to get the pointer to the symbol monitor. The creation of a single monitor object (if it does not exist) will occur inside it. In the destructor, add the deletion of the information object if it was created and has not yet been deleted:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualOrder::CVirtualOrder(CVirtualStrategy *p_strategy) : // Initialization list m_id(++s_count), // New ID = object counter + 1 ... m_point(0) { PrintFormat(__FUNCTION__ + "#%d | CREATED VirtualOrder", m_id); m_symbolInfo = NULL; m_symbols = CSymbolsMonitor::Instance(); } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CVirtualOrder::~CVirtualOrder() { if(!!m_symbolInfo) delete m_symbolInfo; }
I did not add receiving the pointer to the m_symbolInfo info object to the constructor since at the moment of calling the constructor it may not always be known exactly which symbol will be used in this virtual position. This becomes clear only when opening a virtual position, that is, when calling the CVirtualOrder::Open() method. We will add the initialization of the pointer to the symbol information object to it:
//+------------------------------------------------------------------+ //| Open a virtual position (order) | //+------------------------------------------------------------------+ bool CVirtualOrder::Open(string symbol, // Symbol ENUM_ORDER_TYPE type, // Type (BUY or SELL) double lot, // Volume double price = 0, // Open price double sl = 0, // StopLoss level (price or points) double tp = 0, // TakeProfit level (price or points) string comment = "", // Comment datetime expiration = 0, // Expiration time bool inPoints = false // Are the SL and TP levels set in points? ) { if(IsOpen()) { // If the position is already open, then do nothing PrintFormat(__FUNCTION__ "#%d | ERROR: Order is opened already!", m_id); return false; } // Get a pointer to the information object for the desired symbol from the symbol monitor m_symbolInfo = m_symbols[symbol]; if(!!m_symbolInfo) { // Actions to open ... return true; } else { ... return false; } }
Now, since the symbol monitor is responsible for updating the symbol quotes information, we are now able to free the CVirtualOrder class from all calls of the Name() and RefreshRates() methods for the m_symbolInfo information object of symbol properties. When opening a virtual position in m_symbolInfo, we will save the pointer to the object the required symbol has already been selected for. When accompanying a previously opened virtual position, the RefreshRates() method was already called once on this tick — this was done by the symbol monitor for all of them in the CSymbolsMonitor::Tick() method.
Let's do the profiling again. The picture has changed for the better, but calling the SymbolInfoDouble() function still occupies 9%. A quick search revealed that these calls are needed to obtain the spread value. But we can replace this operation with calculating the difference in prices (Ask — Bid), which have already been obtained when calling the RefreshRates() method and do not require additional SymbolInfoDouble() function calls.
Additionally, changes were made to this class that were not directly related to increasing the speed of operation and were not necessary for the model strategy under consideration:
- added passing the current object to the CVirtualStrategy::OnOpen() and CVirtualStrategy::OnClose() handlers;
- added calculation of profits from closed virtual positions;
- added getters and setters for StopLoss and TakeProfit levels;
- added a unique ticket assigned when opening a virtual position.
Perhaps, this library is in for a more radical overhaul. Therefore, we will not dwell on the description of these changes.
Save the changes made in the VirtualOrder.mqh file in the current folder.
Strategy modification
To use the symbol monitor, we needed to make some minor edits to the trading strategy class as well. First, as in the class for virtual positions, we made it so that a member of the m_symbolInfo class now stores a pointer to the object instead of the object itself:
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { protected: ... CSymbolInfo *m_symbolInfo; // Object for getting information about the symbol properties ... public: ... };
And added its initialization in the constructor:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { ... // Register the event handler for a new bar on the minimum timeframe //IsNewBar(m_symbol, PERIOD_M1); m_symbolInfo = CSymbolsMonitor::Instance()[m_symbol]; ... }
We commented out the registration of the new bar event handler, since it will now be registered in the symbol monitor.
Secondly, we removed the update of the current prices from the strategy code (in the methods for checking the signal for opening and the opening of positions itself), since the symbol monitor also takes care of this.
Let's save the changes made to the SimpleVolumesStrategy.mqh file in the current folder.
Validity check
Let's compare the results of testing the EA under study on the same time interval before and after making changes related to the addition of the symbol monitor.
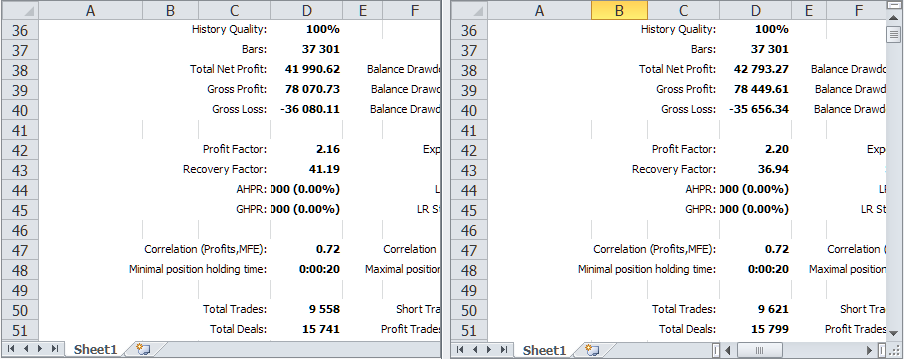
Fig. 2. Comparing test results of the previous version and the current one with the symbol monitor
As we can see, they are generally the same, but there are some minor differences. Let's show them in the form of a table for clarity.
| Version | Profit | Drawdown | Normalized profit |
|---|---|---|---|
| Previous version | 41 990.62 | 1 019.49 (0.10%) | 6 867.78 |
| Current version | 42 793.27 | 1 158.38 (0.11%) | 6 159.87 |
If we compare the first trades in the reports, we can see that the previous version features additional positions that are not present in the current one and vice versa. Most likely, this is due to the fact that when the tester is launched on the EURGBP symbol, a new bar for EURGBP occurs at mm:00, and for another symbol, for example GBPUSD, it can occur either at mm:00 or mm:20.
To eliminate this effect, we will add an additional check for the occurrence of a new bar to the strategy:
//+------------------------------------------------------------------+ //| "Tick" event handler function | //+------------------------------------------------------------------+ void CSimpleVolumesStrategy::Tick() override { if(IsNewBar(m_symbol, PERIOD_M1)) { // If their number is less than allowed if(m_ordersTotal < m_maxCountOfOrders) { // Get an open signal int signal = SignalForOpen(); if(signal == 1 /* || m_ordersTotal < 1 */) { // If there is a buy signal, then OpenBuyOrder(); // open the BUY_STOP order } else if(signal == -1) { // If there is a sell signal, then OpenSellOrder(); // open the SELL_STOP order } } } }
After this modification, the results only improved. The current version showed the highest normalized profit:
| Version | Profit | Drawdown | Normalized profit |
|---|---|---|---|
| Previous version | 46 565.39 | 1 079.93 (0.11%) | 7 189.77 |
| Current version | 47 897.30 | 1 051.37 (0.10%) | 7 596.31 |
So let's leave the changes made and move on to creating a database filling script.
Filling the database with projects
We will not create a script, but an EA, but it will behave like a script. All work will be performed in the initialization function, after which the EA will be unloaded on the first tick. This implementation will allow us to run it both on the chart and in the optimizer, if we want to get multiple runs with parameters changing within the specified limits.
Since this is the first implementation, we will not think too much in advance about which set of inputs will be more convenient, but we will try to make just a minimal working prototype. Here is the list of parameters we ended up with:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Database" sinput string fileName_ = "article.16373.db.sqlite"; // - Main database file input group "::: Project parameters" sinput string projectName_ = "SimpleVolumes"; // - Name sinput string projectVersion_ = "1.20"; // - Version sinput string symbols_ = "GBPUSD;EURUSD;EURGBP"; // - Symbols sinput string timeframes_ = "H1;M30;M15"; // - Timeframes input datetime fromDate_ = D'2018-01-01'; // - Start date input datetime toDate_ = D'2023-01-01'; // - End date
The name and version of the project are obvious, then there are two parameters, in which we will pass lists of symbols and timeframes, separated by semicolons. They will be used to obtain single instances of the trading strategy. For each symbol, all timeframes will be taken in turn. So if we specified three symbols and three timeframes in the default values, this would result in nine single instances being created.
Each single instance must go through a first stage of optimization, where the best combinations of parameters are selected specifically for it. More precisely, during the optimization we might try many combinations, from which we can then select a certain number of "good" ones.
This choice will already be made at the second stage of optimization. As a result, we will have a group of several "good" instances working on a certain symbol and timeframe. After repeating the second step for all symbol-timeframe combinations, we will have nine groups of single instances for each combination.
During the third step, we will combine these nine groups, obtaining and storing in the library an initialization string, which can be used to create an EA that includes all single instances from these groups.
Let us recall that the code responsible for the sequential execution of all the above stages has already been written and can work if the necessary "instructions" are generated in the database. Before this, we added them to the database manually. Now we want to transfer this routine procedure to the developed EA script.
The remaining two parameters of this EA allow us to set the start and end dates of the optimization interval. We will use them to simulate periodic re-optimization and see how long after re-optimization the final EA will trade with the same results as in the optimization interval.
With that said, the initialization function code might look something like this:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the database DB::Connect(fileName_); // Create a project CreateProject(projectName_, projectVersion_, StringFormat("%s - %s", TimeToString(fromDate_, TIME_DATE), TimeToString(toDate_, TIME_DATE) ) ); // Create project stages CreateStages(); // Creating jobs and tasks CreateJobs(); // Queueing the project for execution QueueProject(); // Close the database DB::Close(); // Successful initialization return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Tick handling | //+------------------------------------------------------------------+ void OnTick() { // Since all work is done in OnInit(), delete the EA ExpertRemove(); }
That is, we sequentially create an entry in the project table, then add stages to the project stage table, and then fill in the work and task tables for each job. At the end, we set the project status to Queued. Thanks to triggers in the database, all stages, jobs and tasks of the project will also move to the Queued status.
Let's now look at the code from the created functions in more detail. The simplest of them is to create a project. It contains one SQL query to insert data and store the ID of the newly created record in the id_project global variable:
//+------------------------------------------------------------------+ //| Create a project | //+------------------------------------------------------------------+ void CreateProject(string name, string ver, string desc = "") { string query = StringFormat("INSERT INTO projects " " VALUES (NULL,'%s','%s','%s',NULL,'Done') RETURNING rowid;", name, ver, desc); PrintFormat(__FUNCTION__" | %s", query); id_project = DB::Insert(query); }
As a project description, we form a string from the start and end dates of the optimization interval. This will allow us to distinguish between projects for the same version of the trading strategy.
The function for creating stages will be a little longer: it will require three SQL queries to create three stages. Of course, there may be more stages, but for now we will limit ourselves to only the three that were mentioned a little earlier. After creating each stage, we also store their IDs in the id_stage1, id_stage2 and id_stage3 global variables.
//+------------------------------------------------------------------+ //| Create three stages | //+------------------------------------------------------------------+ void CreateStages() { // Stage 1 - single instance optimization string query1 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%s," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project "NULL", // id_parent_stage "First", // name "SimpleVolumesStage1.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query1); id_stage1 = DB::Insert(query1); // Stage 2 - selection of a good group of single specimens string query2 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage1, // id_parent_stage "Second", // name "SimpleVolumesStage2.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query2); id_stage2 = DB::Insert(query2); // Stage 3 - saving the initialization string of the final EA to the library string query3 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage2, // id_parent_stage "Save to library", // name "SimpleVolumesStage3.ex5", // expert "GBPUSD", // symbol "H1", // period 0, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query3); id_stage3 = DB::Insert(query3); }
For each stage we specify its name, the ID of the parent stage and the name of the EA for the stage. The remaining fields in the stage table will be mostly the same for different stages: optimization interval, initial deposit, and so on.
The main work falls on the function of creating jobs and tasks CreateJobs(). Each job will be related to one combination of symbol and timeframe. So, first we create arrays for all used symbols and timeframes listed in the inputs. For timeframes, I have added the StringToTimeframe() function, which converts the timeframe name from a string to a value of the ENUM_TIMEFRAMES type.
// Array of symbols for strategies string symbols[]; StringSplit(symbols_, ';', symbols); // Array of timeframes for strategies ENUM_TIMEFRAMES timeframes[]; string sTimeframes[]; StringSplit(timeframes_, ';', sTimeframes); FOREACH(sTimeframes, APPEND(timeframes, StringToTimeframe(sTimeframes[i])));
Then, in a double loop, we go through all combinations of symbols and timeframes and create three optimization tasks with a custom criterion.
// Stage 1 FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the first stage string params = StringFormat(paramsTemplate1, ""); // Request to create the first stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage1, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs1, id_job); // Create three tasks for this job for(int i = 0; i < 3; i++) { query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } } });
This number of tasks is determined, on the one hand, by the fact that we have accumulated at least 10-20 thousand passes during optimization on one combination, and on the other hand, there would not be so many of them that the time taken by optimization would be too long. The custom criterion for all three tasks is chosen because, with different runs, the genetic algorithm for this trading strategy almost always converges to different combinations of parameters. Therefore, there is no need to use different criteria for different runs, we already have a fairly rich choice of different good combinations of parameters for a single instance of the strategy.
In the future, the number of tasks and the optimization criteria used can be included in the script parameters, but now they are simply hard-coded in the code.
For each job of the first stage, we use the same optimization parameter template, which is specified in the paramsTemplate1 global variable :
// Template of optimization parameters at the first stage string paramsTemplate1 = "; === Open signal parameters\n" "signalPeriod_=212||12||40||240||Y\n" "signalDeviation_=0.1||0.1||0.1||2.0||Y\n" "signaAddlDeviation_=0.8||0.1||0.1||2.0||Y\n" "; === Pending order parameters\n" "openDistance_=10||0||10||250||Y\n" "stopLevel_=16000||200.0||200.0||20000.0||Y\n" "takeLevel_=240||100||10||2000.0||Y\n" "ordersExpiration_=22000||1000||1000||60000||Y\n" "; === Capital management parameters\n" "maxCountOfOrders_=3||3||1||30||N\n";
Save the IDs of the added jobs to the id_jobs1 array for use in creating the second stage jobs.
To create the second stage works, the template specified in the paramsTemplate2 global variable is also used, but it already has a variable part:
// Template of optimization parameters for the second stage string paramsTemplate2 = "idParentJob_=%s\n" "useClusters_=false||false||0||true||N\n" "minCustomOntester_=500.0||0.0||0.000000||0.000000||N\n" "minTrades_=40||40||1||400||N\n" "minSharpeRatio_=0.7||0.7||0.070000||7.000000||N\n" "count_=8||8||1||80||N\n";
The value that comes after "idParentJob_=" is the ID of the first stage job that uses a specific symbol and timeframe combination. Before the creation of the first stage jobs, these values are unknown, so they will be substituted into this template immediately before the creation of each second stage job from the id_jobs1 array.
The count_ parameter in this template is equal to 8, that is, we will collect groups of eight single instances of trading strategies. Our second stage EA allows us to set a value from 1 to 16 in this parameter. I chose the value 8 for the same reasons as the number of tasks for one job in the first stage - not too few and not too much. I might move it into the script inputs later.
// Stage 2 int k = 0; FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the second stage string params = StringFormat(paramsTemplate2, IntegerToString(id_jobs1[k])); // Request to create a second stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage2, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs2, id_job); k++; // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } });
At the second stage, we create only one optimization task for a single job, since in one optimization loop we select quite good groups of single instances of the trading strategy. We will use a user criterion as an optimization one.
We also save the IDs of the added jobs to the id_jobs2 array (we did not need them in the end). These IDs may be useful when adding stages, so we will not remove them.
At the third stage, the parameter template contains only the name of the final group, under which it will be added to the library:
// Template of optimization parameters at the third stage string paramsTemplate3 = "groupName_=%s\n" "passes_=";
We form the name of the final group from the name and version of the project, as well as from the end date of the optimization interval and substitute it into the template used to create the work of the third stage. Since at the third stage we sort of collect together the results of all the previous stages, then only one job and its task are created:
// Stage 3 // Use the optimization parameters template for the third stage string params = StringFormat(paramsTemplate3, projectName_ + "_v." + projectVersion_ + "_" + TimeToString(toDate_, TIME_DATE)); // // Request to create a third stage job string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage3, "GBPUSD", "D1", params); ulong id_job = DB::Insert(query); // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 0); DB::Execute(query);
After this, all that remains is to change the project status so that it is queued for execution:
//+------------------------------------------------------------------+ //| Queueing the project for execution | //+------------------------------------------------------------------+ void QueueProject() { string query = StringFormat("UPDATE projects SET status='Queued' WHERE id_project=%d;", id_project); DB::Execute(query); }
Save the changes made to the CreateProject.mq5 new file in the current folder.
There is one more thing. It is probably safe to assume that the database structure will be permanent, so it can be integrated into the library. To fulfill this task, we created the db.schema.sql file with the database structure as a set of SQL commands and connected it as a resource to Database.mqh:
// Import sql file for creating DB structure #resource "db.schema.sql" as string dbSchema
We also slightly changed the logic of the Connect() method - if there is no database with the specified name, it will be automatically created using SQL commands from a file loaded as a resource. At the same time, we got rid of the ExecuteFile() method, since it is no longer used anywhere.
Finally, we have come to the point where we can try to run the implemented code.
Filling the database
We will not generate many projects at once, but will limit ourselves to only four. To do this, we will simply place the EA-script on any chart four times, setting the necessary parameters each time. Let the values of all parameters except the end date remain equal to the default values. We will change the end date by adding an additional month to the test interval every time.
As a result, we get approximately the following database content. The project table features four projects:
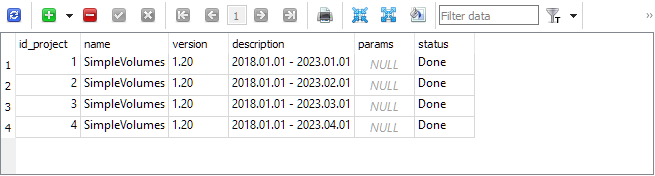
The stage table has four stages per each project. An additional stage named "Single tester pass" is created automatically when creating the project and used when we want to launch a single strategy tester pass outside of the auto optimization conveyor:
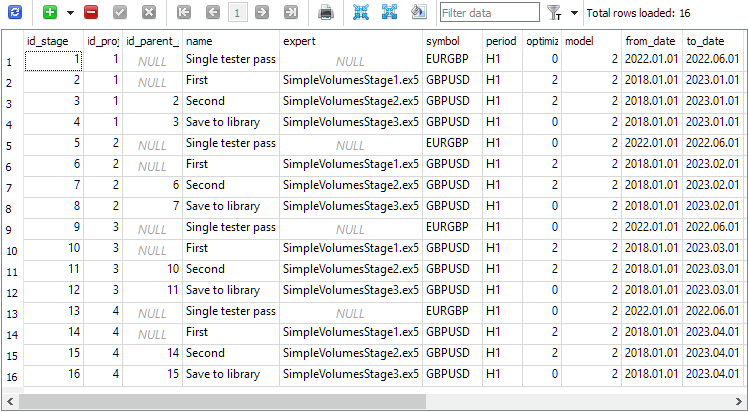
The corresponding jobs have been added to the job table:
After the projects were launched for execution, the result was obtained in approximately four days. This is certainly not such a small amount of time, despite efforts to optimize performance. But not so big either so that it cannot be allocated. We can see it in the strategy_groups group library table:

Check id_pass to see the initialization string in the passes table, for example:
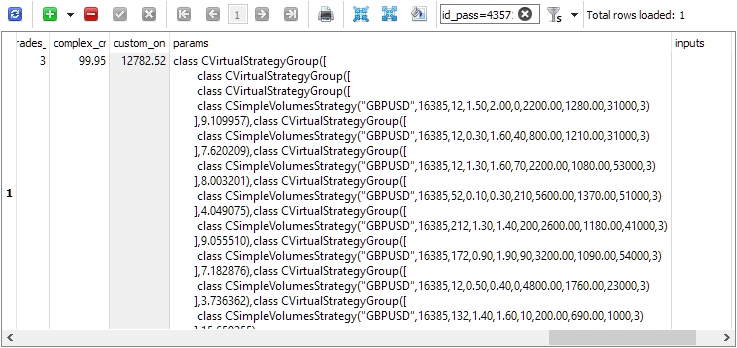
Or we can substitute the pass ID as an input of the SimpleVolumesStage3.ex5 third stage EA and run it in the tester at the selected time interval:
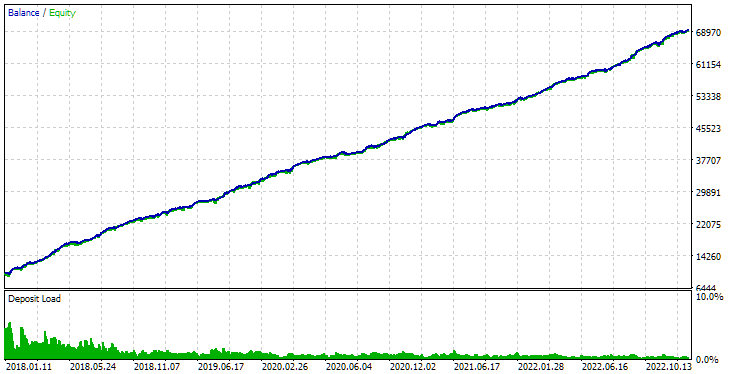
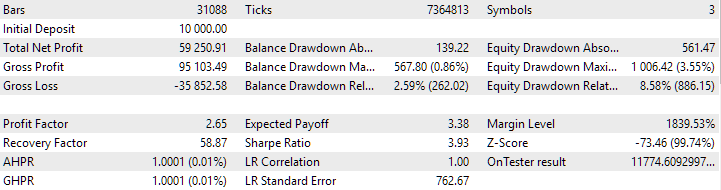
Fig. 3. SimpleVolumesStage3.ex5 EA pass results with id_pass=876663 in the interval 2018.01.01 - 2023.01.01
We will stop here for now and conduct a more detailed analysis of the results obtained in the coming articles.
Conclusion
So, we got the ability to automatically create tasks to launch the auto optimization conveyor, which includes three stages. This is still nothing more than a draft that will allow us to identify preferred directions for further development. The issues of implementing auto merging or replacing the initialization strings of the final EAs upon completion of the conveyor stages for each project remain open.
But one thing can already be said for sure. The chosen order of execution of optimization tasks in the conveyor is not very good. Now we have to wait for the full completion of all the work of the first stage in order to begin the second. And in the same way, the third stage will not begin until all the work of the second stage is completed. If we plan to somehow implement a "hot" replacement of the initialization strings of the final EA, which continuously works on the account in parallel with the optimization being carried out, then we can make these updates smaller, but more frequent. This may improve the results, but it is still only a hypothesis that needs to be tested.
It is also worth noting that the developed EA-script is focused on creating optimization projects only for the considered model trading strategy. Another strategy will require some minor changes to the source code. At a minimum, you will have to change the template of the input parameter string for the first stage of optimization. We have not yet moved these templates into inputs, since it is inconvenient to set them there directly. However, further on, we will probably develop some format for describing the task for creating a project, which the script EA will upload from a file.
Thank you for your attention! See you soon!
Important warning
All results presented in this article and all previous articles in the series are based only on historical testing data and are not a guarantee of any profit in the future. The work within this project is of a research nature. All published results can be used by anyone at their own risk.
Archive contents
| # | Name | Version | Description | Recent changes |
|---|---|---|---|---|
| MQL5/Experts/Article.16373 | ||||
| 1 | Advisor.mqh | 1.04 | EA base class | Part 10 |
| 2 | ClusteringStage1.py | 1.01 | Program for clustering the results of the first stage of optimization | Part 20 |
| 3 | CreateProject.mq5 | 1.00 | EA script for creating a project with stages, jobs and optimization tasks. | Part 21 |
| 4 | Database.mqh | 1.09 | Class for handling the database | Part 21 |
| 5 | db.schema.sql | 1.05 | Database structure | Part 20 |
| 6 | ExpertHistory.mqh | 1.00 | Class for exporting trade history to file | Part 16 |
| 7 | ExportedGroupsLibrary.mqh | — | Generated file listing strategy group names and the array of their initialization strings | Part 17 |
| 8 | Factorable.mqh | 1.02 | Base class of objects created from a string | Part 19 |
| 9 | GroupsLibrary.mqh | 1.01 | Class for working with a library of selected strategy groups | Part 18 |
| 10 | HistoryReceiverExpert.mq5 | 1.00 | EA for replaying the history of deals with the risk manager | Part 16 |
| 11 | HistoryStrategy.mqh | 1.00 | Class of the trading strategy for replaying the history of deals | Part 16 |
| 12 | Interface.mqh | 1.00 | Basic class for visualizing various objects | Part 4 |
| 13 | LibraryExport.mq5 | 1.01 | EA that saves initialization strings of selected passes from the library to the ExportedGroupsLibrary.mqh file | Part 18 |
| 14 | Macros.mqh | 1.02 | Useful macros for array operations | Part 16 |
| 15 | Money.mqh | 1.01 | Basic money management class | Part 12 |
| 16 | NewBarEvent.mqh | 1.00 | Class for defining a new bar for a specific symbol | Part 8 |
| 17 | Optimization.mq5 | 1.03 | EA managing the launch of optimization tasks | Part 19 |
| 18 | Optimizer.mqh | 1.01 | Class for the project auto optimization manager | Part 20 |
| 19 | OptimizerTask.mqh | 1.01 | Optimization task class | Part 20 |
| 20 | Receiver.mqh | 1.04 | Base class for converting open volumes into market positions | Part 12 |
| 21 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Simplified EA for replaying the history of deals | Part 16 |
| 22 | SimpleVolumesExpert.mq5 | 1.20 | EA for parallel operation of several groups of model strategies. The parameters will be taken from the built-in group library. | Part 17 |
| 23 | SimpleVolumesStage1.mq5 | 1.18 | Trading strategy single instance optimization EA (stage 1) | Part 19 |
| 24 | SimpleVolumesStage2.mq5 | 1.02 | Trading strategies instances group optimization EA (stage 2) | Part 19 |
| 25 | SimpleVolumesStage3.mq5 | 1.02 | The EA that saves a generated standardized group of strategies to a library of groups with a given name. | Part 20 |
| 26 | SimpleVolumesStrategy.mqh | 1.10 | Class of trading strategy using tick volumes | Part 21 |
| 27 | Strategy.mqh | 1.04 | Trading strategy base class | Part 10 |
| 28 | SymbolsMonitor.mqh | 1.00 | Class for obtaining information about trading instruments (symbols) | Part 21 |
| 29 | TesterHandler.mqh | 1.05 | Optimization event handling class | Part 19 |
| 30 | VirtualAdvisor.mqh | 1.08 | Class of the EA handling virtual positions (orders) | Part 21 |
| 31 | VirtualChartOrder.mqh | 1.01 | Graphical virtual position class | Part 18 |
| 32 | VirtualFactory.mqh | 1.04 | Object factory class | Part 16 |
| 33 | VirtualHistoryAdvisor.mqh | 1.00 | Trade history replay EA class | Part 16 |
| 34 | VirtualInterface.mqh | 1.00 | EA GUI class | Part 4 |
| 35 | VirtualOrder.mqh | 1.08 | Class of virtual orders and positions | Part 21 |
| 36 | VirtualReceiver.mqh | 1.03 | Class for converting open volumes to market positions (receiver) | Part 12 |
| 37 | VirtualRiskManager.mqh | 1.02 | Risk management class (risk manager) | Part 15 |
| 38 | VirtualStrategy.mqh | 1.05 | Class of a trading strategy with virtual positions | Part 15 |
| 39 | VirtualStrategyGroup.mqh | 1.00 | Class of trading strategies group(s) | Part 11 |
| 40 | VirtualSymbolReceiver.mqh | 1.00 | Symbol receiver class | Part 3 |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/16373
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
The article Developing a Multicurrency Expert Advisor (Part 21) has been published: Preparing for an important experiment and optimising the code:
Author: Yuriy Bykov
Unfortunately, everything is not as simple as we would like. To be able tolaunch the Expert Advisor of the third stage, it is necessary to specify theIDs of the passes obtained as a result ofthe previous stages of the optimization pipeline. How to get them is described in the articles.
Understood. However, since you have taken so much of efforts to describe your work in a simpler manner, it will be even great if you could create a video tutorial to teach the operation/optimisation of the set of EAs you are creating. Thanks
Understood. However, since you have taken so much of efforts to describe your work in a simpler manner, it will be even great if you could create a video tutorial to teach the operation/optimisation of the set of EAs you are creating. Thanks
Hi, thanks for the suggestion. I can't promise that I'll actually be able to record videos for articles, but I'll think about how and in what form I can make a video that helps readers of articles.
Hi, thanks for the suggestion. I can't promise that I'll actually be able to record videos for articles, but I'll think about how and in what form I can make a video that helps readers of articles.
Thank you. A very simple one lasting a few seconds will be sufficient. Since strategy testing and optimisation in MT5 is more complex than what used to be in MT4, people who are transitioning find it difficult sometimes. All you can do is showing the exact settings you use in getting those results which you are posting in the articles.
HI Download Last Part Files (21) How I Can User This Advisor Can u Help me please