
Desenvolvendo um EA multimoeda (Parte 21): Preparação para um experimento importante e otimização do código
Introdução
Na parte anterior, começamos a organizar o pipeline de reotimização automática, que permite obter um novo EA final considerando os dados de preço acumulados. No entanto, a automação completa ainda não foi alcançada, já que precisamos tomar decisões difíceis sobre como implementar as últimas etapas. Elas são difíceis porque, se escolhermos o caminho errado, teremos que refazer muitas coisas. Por isso, é muito desejável economizar esforços e tentar fazer a escolha certa. E nada ajuda tanto na hora de tomar decisões complicadas quanto... adiá-las! Especialmente quando podemos nos dar a esse luxo.
No entanto, adiar também pode ser feito de diferentes formas. Em vez de simplesmente adiar a decisão, vamos tentar mudar o foco para outra tarefa que, embora pareça servir apenas como distração, pode realmente ajudar na resolução do problema. Mesmo que não nos dê a resposta definitiva sobre o melhor caminho a seguir, ao menos pode aumentar a motivação para decidir.
Uma questão interessante
Muitas discussões sobre o uso da otimização de parâmetros giram em torno da questão de por quanto tempo é possível usar os parâmetros obtidos para operar em um período futuro, mantendo os principais indicadores de lucratividade e rebaixamento dentro dos níveis estabelecidos. E será que isso é de fato possível?
Embora seja comum a visão de que não se deve acreditar na repetição futura dos resultados do teste e de que, na prática, tudo depende apenas da sorte até o momento em que a estratégia "quebra". Praticamente todos os desenvolvedores de estratégias de trading gostariam de acreditar no contrário. Caso contrário, perde-se o sentido de investir uma enorme quantidade de tempo e esforço no desenvolvimento e nos testes.
Já foram feitas várias tentativas de aumentar a confiança de que, após escolher bons parâmetros, a estratégia poderá continuar funcionando com sucesso por algum tempo. Existem artigos publicados que, de uma forma ou de outra, abordam a questão do ajuste periódico automático dos melhores parâmetros para EAs operacionais. Dentre eles, vale destacar o EA Validate de @fxsaber, criado para a realização de um experimento bastante interessante.
Esse instrumento permite pegar um EA qualquer (em análise) e, escolhendo um certo período de tempo (por exemplo, 3 anos), executar o seguinte processo: o EA em análise será otimizado em um determinado intervalo (por exemplo, 2 meses) e, em seguida, com as melhores configurações, será executado no testador de estratégias em um período de, digamos, duas semanas. Ao final de cada período de duas semanas, o EA em análise será novamente otimizado nos dois meses anteriores e depois voltará a operar por mais duas semanas. Isso continuará até que seja alcançado o fim do intervalo escolhido de 3 anos.
Ao final, será gerado um relatório de negociação mostrando como o EA analisado teria operado ao longo dos três anos, caso tivesse sido periodicamente reotimizado e executado com parâmetros atualizados. É claro que os intervalos de tempo mencionados podem ser escolhidos conforme a necessidade. Se algum EA conseguir apresentar resultados aceitáveis com esse tipo de reotimização, isso será um forte indício de seu maior potencial de uso em operações reais.
Entretanto, esse instrumento tem uma limitação importante: o EA em análise deve possuir parâmetros de entrada abertos para que a otimização seja possível. Se considerarmos, por exemplo, os nossos EAs finais, obtidos nas etapas anteriores por meio da união de muitos exemplares individuais, veremos que eles não possuem parâmetros de entrada que permitam influenciar a lógica de abertura de posições. Parâmetros de gestão de capital e de gerenciamento de risco não serão considerados, já que a otimização desses parâmetros, embora possível, é pouco significativa. Afinal, é óbvio que, se aumentarmos o tamanho das posições abertas, o resultado do teste mostrará um lucro maior em comparação com o obtido anteriormente com um tamanho de posição menor.
Portanto, vamos tentar implementar algo semelhante, mas que seja aplicável aos EAs que estamos desenvolvendo.
Definindo o caminho
De modo geral, precisamos de um script para preencher o banco de dados com projetos praticamente idênticos. A única diferença entre eles será a data de início e término do período de otimização. A composição das etapas, os trabalhos de cada etapa e as tarefas dentro dos trabalhos podem ser completamente iguais. Por isso, podemos, por enquanto, criar um EA auxiliar com poucos parâmetros de entrada, entre os quais estarão a data de início e a duração do período de otimização. Ao executá-lo em modo de otimização com variação das datas de início, conseguiremos preencher o banco de dados com projetos semelhantes. Ainda não está claro quais outros parâmetros fazem sentido expor como entrada; vamos decidir isso ao longo do desenvolvimento.
A execução completa de todas as tarefas de otimização, mesmo dentro de um único projeto, pode levar bastante tempo. E se não for apenas um, mas dez ou mais projetos, então estamos falando de tarefas bastante longas. Por isso, faz sentido verificar se existe alguma forma de acelerar o trabalho dos nossos EAs de etapas. Para identificar os gargalos que precisam ser corrigidos, usaremos o profiler que faz parte do MetaEditor.
Em seguida, precisamos decidir como simular o trabalho a partir de várias linhas de inicialização obtidas (cada projeto, ao concluir suas tarefas, gerará uma linha de inicialização do EA final). Muito provavelmente, será necessário criar um novo EA de teste, especialmente projetado para esse tipo de operação. Mas isso provavelmente ficará para o próximo artigo.
Vamos começar primeiro com a otimização do código dos EAs de teste e, só depois disso, passaremos à criação do script de preenchimento do banco de dados.
Otimização do código
Antes de nos aprofundarmos na implementação da tarefa principal, verificaremos se há possibilidade de acelerar o funcionamento do código dos EAs que participam da reotimização automática. Para identificar possíveis gargalos, analisaremos o EA final da parte anterior. Nele, foram combinados 32 exemplares de estratégias de trading individuais (2 símbolos x 1 timeframe x 16 exemplares = 32). Isso, é claro, é muito menos do que a quantidade total prevista de exemplares no EA final, mas, durante a otimização, a grande maioria das execuções utilizará apenas um exemplar (na primeira etapa) ou não mais que 16 exemplares (na segunda etapa). Portanto, esse EA de teste é suficiente para o nosso propósito.
Executemos o EA no modo de profilagem com dados históricos. Ao iniciar nesse modo, é compilada automaticamente uma versão especial do EA para profilagem e ela é executada no testador de estratégias. Vamos citar a descrição do uso da profilagem do manual:
Para a profilagem é utilizado o método "Sampling". O profiler faz pausas na execução do programa MQL (~10 000 vezes por segundo) e coleta estatísticas de quantas vezes cada pausa ocorreu em determinada parte do código. Além disso, são analisadas as pilhas de chamadas para determinar a "contribuição" de cada função no tempo total de execução do código.
Sampling é um método leve e preciso. Diferente de outros, ele não faz nenhuma alteração no código analisado que possa afetar a velocidade de sua execução.
O relatório de profilagem é apresentado na forma de funções ou linhas do programa, para cada uma das quais estão disponíveis dois indicadores:
- Atividade total da CPU [%] — número total de vezes em que a função apareceu na pilha de chamadas.
- Atividade própria da CPU [%] — número de pausas que ocorreram diretamente dentro da função em questão. Esse contador é o mais importante para identificar os gargalos, já que, estatisticamente, as paradas acontecem com mais frequência nos trechos do programa que exigem maior tempo de processamento.
Para cada indicador, é exibido tanto o valor absoluto quanto a porcentagem em relação ao total.
Aqui está o que obtivemos após a conclusão do passe:
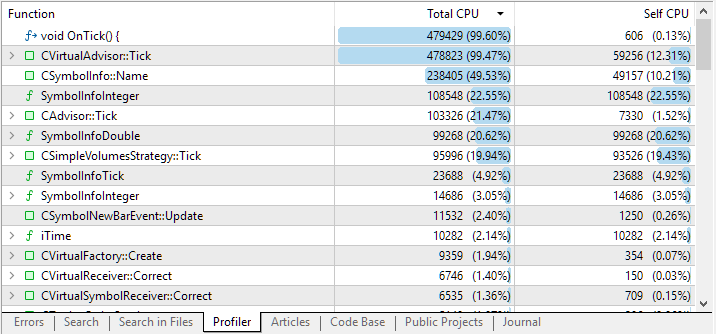
Fig. 1. Resultados da profilagem do código do EA de teste
Por padrão, na lista de resultados da profilagem são mostradas as funções maiores, localizadas nos níveis superiores. Mas, ao clicar sobre a linha com o nome de uma função, podemos visualizar uma lista aninhada de funções chamadas a partir dela. Isso permite identificar com maior precisão quais trechos de código consumiram mais tempo de processamento.
Nas duas primeiras linhas vimos, como esperado, o manipulador OnTick() e o manipulador chamado a partir dele CVirtualAdvisor::Tick(). De fato, além da inicialização, a maior parte do tempo do EA é gasta processando os ticks recebidos. Mas a terceira e a quarta linhas dos resultados já levantam questões mais sérias.
Por que estão ocorrendo tantas chamadas ao método de seleção do símbolo atual? Por que tanto tempo está sendo gasto na obtenção de algumas propriedades inteiras do símbolo? Vamos investigar.
Expandindo a linha correspondente à chamada do método CSymbolInfo::Name(string name), podemos verificar que praticamente todo o tempo gasto está associado à sua chamada dentro da função de verificação da necessidade de fechamento de uma posição virtual.
//+------------------------------------------------------------------+ //| Check the need to close by SL, TP or EX | //+------------------------------------------------------------------+ bool CVirtualOrder::CheckClose() { if(IsMarketOrder()) { // If this is a market virtual position, s_symbolInfo.Name(m_symbol); // Select the desired symbol s_symbolInfo.RefreshRates(); // Update information about current prices // ... } return false; }
Esse código foi escrito há bastante tempo. Naquele momento, o que importava era garantir que as posições virtuais abertas fossem corretamente traduzidas em posições reais. O fechamento de uma posição virtual deveria resultar no fechamento imediato (ou quase imediato) de um certo volume de posições reais. Por isso, essa verificação precisava ser feita a cada tick e para cada posição virtual aberta.
Para garantir independência, fornecemos a cada objeto da classe CVirtualOrder sua própria instância de um objeto da classe CSymbolInfo, por meio do qual solicitávamos todas as informações necessárias sobre preços e especificações do instrumento de trading (símbolo). Assim, para 16 exemplares de estratégias de trading, cada um usando três posições virtuais, o array de posições virtuais teria 16*3 = 48 elementos. Se o EA possuir várias centenas de exemplares de estratégias de trading, e ainda utilizar um número maior de posições virtuais, a quantidade de chamadas ao método de seleção de símbolo aumentará muitas vezes. Mas será que isso realmente é necessário?
Quando realmente precisamos chamar o método de seleção do nome do símbolo? Somente se o símbolo da posição virtual tiver mudado. Se ele não mudou desde o tick anterior, então não faz sentido chamar esse método. E a troca de símbolo só pode ocorrer quando é aberta uma posição virtual que ou nunca havia sido aberta antes, ou havia sido aberta em outro símbolo. Isso acontece claramente não a cada tick, mas muito, muito mais raramente. Além disso, na estratégia-modelo usada aqui nunca ocorre a troca de símbolo para uma mesma posição virtual, já que cada exemplar da estratégia de trading trabalha apenas com um único símbolo, que será o mesmo para todas as posições virtuais desse exemplar.
Nesse caso, podemos mover os objetos da classe CSymbolInfo para o nível do exemplar da estratégia de trading, mas isso ainda pode ser redundante, pois diferentes exemplares da estratégia podem usar o mesmo símbolo. Por isso, vamos movê-los ainda mais para cima — para o nível global. Nesse nível, basta termos tantos objetos da classe CSymbolInfo quanto forem os símbolos diferentes utilizados no EA. Cada objeto CSymbolInfo será criado somente quando o EA precisar acessar as propriedades de um novo símbolo. Uma vez criado, o objeto ficará permanentemente associado a esse símbolo.
Inspirados por esse exemplo do manual, vamos criar nossa própria classe CSymbolsMonitor. Diferente do exemplo, não vamos criar uma nova classe que, apesar de ser escrita de forma mais elegante, acabaria repetindo a funcionalidade já existente na classe padrão da biblioteca. A nossa terá o papel de um contêiner para múltiplos objetos da classe CSymbolInfo e garantirá que cada símbolo utilizado tenha seu próprio objeto informativo dessa classe.
Para garantir o acesso a ela a partir de qualquer lugar do código, vamos mais uma vez utilizar o padrão de projeto Singleton na implementação. A base da classe será formada pelo array m_symbols[] para armazenar ponteiros para objetos da classe CSymbolInfo.
//+---------------------------------------------------------------------+ //| Class for obtaining information about trading instruments (symbols) | //+---------------------------------------------------------------------+ class CSymbolsMonitor { protected: // Static pointer to a single class instance static CSymbolsMonitor *s_instance; // Array of information objects for different symbols CSymbolInfo *m_symbols[]; //--- Private methods CSymbolsMonitor() {} // Closed constructor public: ~CSymbolsMonitor(); // Destructor //--- Static methods static CSymbolsMonitor *Instance(); // Singleton - creating and getting a single instance // Tick handling for objects of different symbols void Tick(); // Operator for getting an object with information about a specific symbol CSymbolInfo* operator[](const string &symbol); }; // Initializing a static pointer to a single class instance CSymbolsMonitor *CSymbolsMonitor::s_instance = NULL;
A implementação do método estático de criação da única instância da classe repete as versões que já encontramos anteriormente. E no destrutor incluiremos um laço para remover os objetos informativos criados.
//+------------------------------------------------------------------+ //| Singleton - creating and getting a single instance | //+------------------------------------------------------------------+ CSymbolsMonitor* CSymbolsMonitor::Instance() { if(!s_instance) { s_instance = new CSymbolsMonitor(); } return s_instance; } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CSymbolsMonitor::~CSymbolsMonitor() { // Delete all created information objects for symbols FOREACH(m_symbols, if(!!m_symbols[i]) delete m_symbols[i]); }
O método público de processamento de tick será responsável por atualizar periodicamente as informações sobre a especificação dos símbolos e as cotações. A especificação, possivelmente, não se altera ao longo do tempo, mas, por precaução, vamos prever sua atualização uma vez por dia. Já as cotações serão atualizadas a cada minuto, pois utilizamos o modo de operação do EA apenas na abertura de barras de um minuto (para melhor repetibilidade dos resultados de simulação no modo 1 minute OHLC e no modo de todos os ticks com base em ticks reais).
//+------------------------------------------------------------------+ //| Handle a tick for the array of virtual orders (positions) | //+------------------------------------------------------------------+ void CSymbolsMonitor::Tick() { // Update quotes every minute and specification once a day FOREACH(m_symbols, { if(IsNewBar(m_symbols[i].Name(), PERIOD_D1)) { m_symbols[i].Refresh(); } if(IsNewBar(m_symbols[i].Name(), PERIOD_M1)) { m_symbols[i].RefreshRates(); } }); }
Por fim, adicionaremos o operador de indexação sobrecarregado para obter o ponteiro do objeto correspondente ao símbolo solicitado. É nesse operador que ocorrerá a criação automática de novos objetos informativos para símbolos que ainda não tenham sido acessados por meio dele.
//+-------------------------------------------------------------------------+ //| Operator for getting an object with information about a specific symbol | //+-------------------------------------------------------------------------+ CSymbolInfo* CSymbolsMonitor::operator[](const string &name) { // Search for the information object for the given symbol in the array int i; SEARCH(m_symbols, m_symbols[i].Name() == name, i); // If found, return it if(i != -1) { return m_symbols[i]; } else { // Otherwise, create a new information object CSymbolInfo *s = new CSymbolInfo(); // Select the desired symbol for it if(s.Name(name)) { // If the selection is successful, update the quotes s.RefreshRates(); // Add to the array of information objects and return it APPEND(m_symbols, s); return s; } else { PrintFormat(__FUNCTION__" | ERROR: can't create symbol with name [%s]", name); } } return NULL; }
O código desenvolvido será salvo no arquivo SymbolsMonitor.mqh na pasta atual. Agora chega a vez do código que fará uso da classe criada.
Modificação em CVirtualAdvisor
Nesse classe já temos alguns objetos que existem em instância única e desempenham tarefas específicas: o receptor dos volumes de posições virtuais, o gerenciador de risco e a interface de notificação ao usuário. A eles será adicionado também o objeto monitor de símbolos. Mais precisamente, criaremos um campo de classe que armazenará o ponteiro para o objeto do monitor de símbolos:
class CVirtualAdvisor : public CAdvisor { protected: CSymbolsMonitor *m_symbols; // Symbol monitor object CVirtualReceiver *m_receiver; // Receiver object that brings positions to the market CVirtualInterface *m_interface; // Interface object to show the status to the user CVirtualRiskManager *m_riskManager; // Risk manager object ... public: ... };
A criação do objeto monitor de símbolos será iniciada na chamada do construtor, por meio da chamada ao método estático CSymbolsMonitor::Instance(), de forma análoga aos outros objetos mencionados. E no destrutor, adicionaremos a remoção desse objeto.
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(string p_params) { ... // If there are no read errors, if(IsValid()) { // Create a strategy group CREATE(CVirtualStrategyGroup, p_group, groupParams); // Initialize the symbol monitor with a static symbol monitor m_symbols = CSymbolsMonitor::Instance(); // Initialize the receiver with the static receiver m_receiver = CVirtualReceiver::Instance(p_magic); // Initialize the interface with the static interface m_interface = CVirtualInterface::Instance(p_magic); ... } } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ void CVirtualAdvisor::~CVirtualAdvisor() { if(!!m_symbols) delete m_symbols; // Remove the symbol monitor if(!!m_receiver) delete m_receiver; // Remove the recipient if(!!m_interface) delete m_interface; // Remove the interface if(!!m_riskManager) delete m_riskManager; // Remove risk manager DestroyNewBar(); // Remove the new bar tracking objects }
No manipulador de novo tick, incluiremos a chamada ao método Tick() do monitor de símbolos. É nele que ocorrerá a atualização das cotações de todos os símbolos usados no EA:
//+------------------------------------------------------------------+ //| OnTick event handler | //+------------------------------------------------------------------+ void CVirtualAdvisor::Tick(void) { // Define a new bar for all required symbols and timeframes bool isNewBar = UpdateNewBar(); // If there is no new bar anywhere, and we only work on new bars, then exit if(!isNewBar && m_useOnlyNewBar) { return; } // Symbol monitor updates quotes m_symbols.Tick(); // Receiver handles virtual positions m_receiver.Tick(); // Start handling in strategies CAdvisor::Tick(); // Risk manager handles virtual positions m_riskManager.Tick(); // Adjusting market volumes m_receiver.Correct(); // Save status Save(); // Render the interface m_interface.Redraw(); }
Aproveitando a oportunidade, adicionaremos também a esse classe, com foco no futuro, o manipulador do evento ChartEvent. Por enquanto, nele será chamada apenas a função de mesmo nome no objeto da interface m_interface, que neste estágio ainda não executa nenhuma ação.
As alterações feitas serão salvas no arquivo VirtualAdvisor.mqh na pasta atual.
Modificação em CVirtualOrder
Como já mencionado, a obtenção de informações sobre os símbolos é feita no classe de posições virtuais. Portanto, começaremos as mudanças por ele e, antes de tudo, adicionaremos aos campos da classe os ponteiros para o monitor (classe CSymbolsMonitor) e para o objeto informativo do símbolo (classe CSymbolInfo):
class CVirtualOrder { private: //--- Static fields static ulong s_count; // Counter of all created CVirtualOrder objects CSymbolInfo *m_symbolInfo; // Object for getting symbol properties //--- Related recipient objects and strategies CSymbolsMonitor *m_symbols; CVirtualReceiver *m_receiver; CVirtualStrategy *m_strategy; ... }
A adição desses ponteiros aos campos da classe implica que eles devem receber ponteiros para objetos criados em algum lugar. E, se esses objetos forem criados dentro dos métodos dos objetos dessa classe, será necessário também garantir sua correta exclusão.
Adicionamos no construtor a inicialização do ponteiro para o monitor de símbolos e a limpeza do ponteiro para o objeto informativo do símbolo. Para obter o ponteiro para o monitor de símbolos, chamamos o método estático CSymbolsMonitor::Instance(). A criação da única instância do monitor (caso ainda não exista) será realizada dentro dele. No destrutor, incluímos a exclusão do objeto informativo, caso ele tenha sido criado e ainda não tenha sido removido:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualOrder::CVirtualOrder(CVirtualStrategy *p_strategy) : // Initialization list m_id(++s_count), // New ID = object counter + 1 ... m_point(0) { PrintFormat(__FUNCTION__ + "#%d | CREATED VirtualOrder", m_id); m_symbolInfo = NULL; m_symbols = CSymbolsMonitor::Instance(); } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CVirtualOrder::~CVirtualOrder() { if(!!m_symbolInfo) delete m_symbolInfo; }
Não adicionamos ao construtor a obtenção do ponteiro para o objeto informativo do símbolo m_symbolInfo pelo motivo de que, no momento da chamada do construtor, nem sempre é possível saber exatamente qual símbolo será utilizado nessa posição virtual. Isso só fica claro durante a abertura da posição virtual, ou seja, na chamada do método CVirtualOrder::Open(). É nele que incluímos a inicialização do ponteiro para o objeto informativo do símbolo:
//+------------------------------------------------------------------+ //| Open a virtual position (order) | //+------------------------------------------------------------------+ bool CVirtualOrder::Open(string symbol, // Symbol ENUM_ORDER_TYPE type, // Type (BUY or SELL) double lot, // Volume double price = 0, // Open price double sl = 0, // StopLoss level (price or points) double tp = 0, // TakeProfit level (price or points) string comment = "", // Comment datetime expiration = 0, // Expiration time bool inPoints = false // Are the SL and TP levels set in points? ) { if(IsOpen()) { // If the position is already open, then do nothing PrintFormat(__FUNCTION__ "#%d | ERROR: Order is opened already!", m_id); return false; } // Get a pointer to the information object for the desired symbol from the symbol monitor m_symbolInfo = m_symbols[symbol]; if(!!m_symbolInfo) { // Actions to open ... return true; } else { ... return false; } }
Agora, como a atualização das informações das cotações dos símbolos é responsabilidade do monitor de símbolos, dentro da classe CVirtualOrder podemos remover todas as chamadas aos métodos Name() e RefreshRates() do objeto informativo de propriedades do símbolo m_symbolInfo. Ao abrir uma posição virtual, em m_symbolInfo ficará armazenado o ponteiro para o objeto já associado ao símbolo correto. Já durante o acompanhamento de uma posição virtual anteriormente aberta, nesse mesmo tick o método RefreshRates() já terá sido chamado uma vez — feito pelo monitor de símbolos para todos os símbolos no método CSymbolsMonitor::Tick().
Vamos realizar a profilagem novamente. O cenário melhorou, mas ainda assim as chamadas à função SymbolInfoDouble() representam 9%. Uma rápida análise mostrou que essas chamadas servem apenas para obter o valor do spread. No entanto, podemos substituir essa operação pelo cálculo da diferença de preços (Ask — Bid), que já foram obtidos na chamada ao método RefreshRates() e, portanto, não exigem chamadas adicionais à função SymbolInfoDouble().
Além disso, foram feitas algumas alterações adicionais nessa classe, que não estão diretamente ligadas ao aumento de desempenho e não são essenciais para a estratégia-modelo em questão:
- no manipulador CVirtualStrategy::OnOpen() e CVirtualStrategy::OnClose() adicionamos a passagem do objeto atual;
- incluímos o cálculo do lucro das posições virtuais fechadas;
- adicionamos getters e setters para os níveis de StopLoss e TakeProfit;
- atribuímos um ticket único no momento da abertura de uma posição virtual.
É possível que essa biblioteca passe por uma reformulação mais profunda. Por isso, não vamos nos alongar na descrição dessas mudanças.
As alterações feitas serão salvas no arquivo VirtualOrder.mqh na pasta atual.
Modificação da estratégia
Para usar o monitor de símbolos, foi necessário fazer pequenos ajustes também na classe da estratégia de trading. Primeiro, assim como na classe de posições virtuais, fizemos com que o membro de classe m_symbolInfo passasse a armazenar agora um ponteiro para o objeto em vez do próprio objeto:
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { protected: ... CSymbolInfo *m_symbolInfo; // Object for getting information about the symbol properties ... public: ... };
E adicionamos sua inicialização no construtor:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { ... // Register the event handler for a new bar on the minimum timeframe //IsNewBar(m_symbol, PERIOD_M1); m_symbolInfo = CSymbolsMonitor::Instance()[m_symbol]; ... }
A inscrição do manipulador do evento de novo barra foi comentada, já que agora ele será registrado no monitor de símbolos.
Em segundo lugar, removemos a atualização dos preços atuais do código da estratégia (nos métodos de verificação do sinal de abertura e da própria abertura de posições), pois isso também já é responsabilidade do monitor de símbolos.
As alterações feitas foram salvas no arquivo SimpleVolumesStrategy.mqh na pasta atual.
Verificação de correção
Compararemos os resultados do teste do EA em análise em um mesmo intervalo de tempo antes e depois das alterações relacionadas à adição do monitor de símbolos.
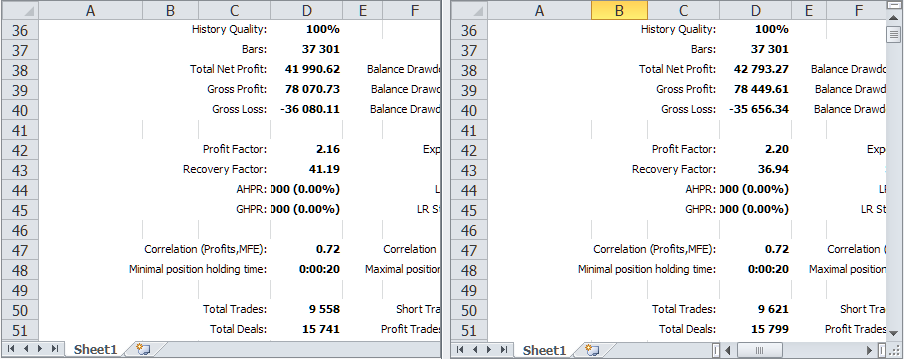
Fig. 2 Comparação dos resultados do teste da versão anterior e da versão atual com monitor de símbolos
Como pode ser visto, eles em geral coincidem, mas existem pequenas diferenças. Vamos apresentá-las em forma de tabela para maior clareza.
| Versão | Lucro | Rebaixamento | Lucro normalizado |
|---|---|---|---|
| Versão anterior | 41 990.62 | 1 019.49 (0.10 %) | 6 867.78 |
| Versão atual | 42 793.27 | 1 158.38 (0.11 %) | 6 159.87 |
Se compararmos as primeiras operações nos relatórios, é possível notar que, na versão anterior, há aberturas adicionais de posições que não existem na atual e vice-versa. Isso provavelmente está relacionado ao fato de que, ao executar o testador no símbolo EURGBP, um novo barra para EURGBP ocorre no momento mm:00, enquanto para outro símbolo, como GBPUSD, ele pode ocorrer tanto em mm:00 quanto em mm:20.
Para eliminar esse efeito, adicionamos uma verificação extra de ocorrência de novo barra na estratégia:
//+------------------------------------------------------------------+ //| "Tick" event handler function | //+------------------------------------------------------------------+ void CSimpleVolumesStrategy::Tick() override { if(IsNewBar(m_symbol, PERIOD_M1)) { // If their number is less than allowed if(m_ordersTotal < m_maxCountOfOrders) { // Get an open signal int signal = SignalForOpen(); if(signal == 1 /* || m_ordersTotal < 1 */) { // If there is a buy signal, then OpenBuyOrder(); // open the BUY_STOP order } else if(signal == -1) { // If there is a sell signal, then OpenSellOrder(); // open the SELL_STOP order } } } }
Após essa modificação, os resultados só melhoraram. A versão atual mostrou o lucro normalizado mais alto:
| Versão | Lucro | Rebaixamento | Lucro normalizado |
|---|---|---|---|
| Versão anterior | 46 565.39 | 1 079.93 (0.11 %) | 7 189.77 |
| Versão atual | 47 897.30 | 1 051.37 (0.10 %) | 7 596.31 |
Portanto, manteremos as alterações feitas e seguiremos para a criação do script de preenchimento do banco de dados.
Preenchimento do banco de dados com projetos
Na verdade, criaremos não um script, mas um EA, embora ele se comporte como um script. Todo o trabalho será feito na função de inicialização, após a qual, no primeiro tick, o EA será descarregado. Essa implementação permitirá executá-lo tanto em um gráfico quanto no otimizador, caso queiramos realizar múltiplas execuções com parâmetros variando dentro dos limites estabelecidos.
Como essa é a primeira implementação, não vamos nos preocupar demais antecipando qual conjunto de parâmetros de entrada será mais conveniente, mas sim tentar criar um protótipo funcional mínimo. Eis a lista de parâmetros que resultou:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Database" sinput string fileName_ = "article.16373.db.sqlite"; // - Main database file input group "::: Project parameters" sinput string projectName_ = "SimpleVolumes"; // - Name sinput string projectVersion_ = "1.20"; // - Version sinput string symbols_ = "GBPUSD;EURUSD;EURGBP"; // - Symbols sinput string timeframes_ = "H1;M30;M15"; // - Timeframes input datetime fromDate_ = D'2018-01-01'; // - Start date input datetime toDate_ = D'2023-01-01'; // - End date
Com o nome e a versão do projeto tudo é óbvio, em seguida temos dois parâmetros nos quais passaremos listas de símbolos e timeframes separados por ponto e vírgula. Eles serão usados para gerar os exemplares individuais da estratégia de trading. Para cada símbolo serão utilizados todos os timeframes, um após o outro. Assim, se definirmos como padrão três símbolos e três timeframes, isso levará à criação de nove exemplares individuais.
Cada exemplar individual deve passar pelo primeiro estágio de otimização, no qual são selecionadas as melhores combinações de parâmetros especificamente para ele. Mais precisamente, no processo de otimização testamos muitas combinações, das quais podemos depois escolher algumas "boas".
Essa escolha será feita já no segundo estágio de otimização. Como resultado, teremos um grupo de vários exemplares "bons", operando em um determinado símbolo e timeframe. Após repetir o segundo estágio para todas as combinações símbolo–timeframe, teremos nove grupos de exemplares individuais, um para cada combinação.
No terceiro estágio, vamos unir esses nove grupos, obtendo e salvando na biblioteca uma linha de inicialização, a partir da qual será possível criar um EA que inclua todos os exemplares individuais dessas combinações.
Vale lembrar que o código responsável pela execução sequencial de todos os estágios mencionados já foi escrito e pode funcionar, desde que as "instruções" necessárias sejam formadas no banco de dados. Até agora, nós as adicionávamos manualmente ao banco. Agora queremos transferir essa rotina para o EA-script que estamos desenvolvendo.
Os dois últimos parâmetros desse EA permitem definir a data de início e de término do intervalo de otimização. Eles serão usados para simular a realização periódica de reotimização e verificar por quanto tempo, após cada reotimização, o EA final conseguirá operar com os mesmos resultados obtidos no intervalo de otimização.
Levando tudo isso em conta, o código da função de inicialização pode ser aproximadamente assim:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the database DB::Connect(fileName_); // Create a project CreateProject(projectName_, projectVersion_, StringFormat("%s - %s", TimeToString(fromDate_, TIME_DATE), TimeToString(toDate_, TIME_DATE) ) ); // Create project stages CreateStages(); // Creating jobs and tasks CreateJobs(); // Queueing the project for execution QueueProject(); // Close the database DB::Close(); // Successful initialization return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Tick handling | //+------------------------------------------------------------------+ void OnTick() { // Since all work is done in OnInit(), delete the EA ExpertRemove(); }
Ou seja, criamos sequencialmente um registro na tabela de projetos, depois adicionamos os estágios na tabela de estágios do projeto e, em seguida, preenchemos as tabelas de trabalhos e tarefas de cada trabalho. Por fim, definimos o status do projeto como Queued, ou seja, colocado na fila para execução. Graças aos gatilhos no banco de dados, todos os estágios, trabalhos e tarefas do projeto também mudarão para o status Queued.
Vejamos agora o código das funções criadas com mais detalhes. A mais simples delas é a de criação do projeto. Ela contém apenas uma consulta SQL para inserir os dados e salvar o identificador do registro recém-criado na variável global id_project:
//+------------------------------------------------------------------+ //| Create a project | //+------------------------------------------------------------------+ void CreateProject(string name, string ver, string desc = "") { string query = StringFormat("INSERT INTO projects " " VALUES (NULL,'%s','%s','%s',NULL,'Done') RETURNING rowid;", name, ver, desc); PrintFormat(__FUNCTION__" | %s", query); id_project = DB::Insert(query); }
Como descrição do projeto, formamos uma string composta pela data de início e término do intervalo de otimização. Isso permitirá distinguir entre si os projetos de uma mesma versão da estratégia de trading.
Um pouco mais extensa será a função de criação dos estágios: nela já é necessário executar três consultas SQL para criar três estágios. Claro que pode haver mais estágios, mas por enquanto vamos nos limitar apenas aos três que foram mencionados anteriormente. Após a criação de cada estágio, também salvamos seus identificadores nas variáveis globais id_stage1, id_stage2, id_stage3.
//+------------------------------------------------------------------+ //| Create three stages | //+------------------------------------------------------------------+ void CreateStages() { // Stage 1 - single instance optimization string query1 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%s," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project "NULL", // id_parent_stage "First", // name "SimpleVolumesStage1.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query1); id_stage1 = DB::Insert(query1); // Stage 2 - selection of a good group of single specimens string query2 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage1, // id_parent_stage "Second", // name "SimpleVolumesStage2.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query2); id_stage2 = DB::Insert(query2); // Stage 3 - saving the initialization string of the final EA to the library string query3 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage2, // id_parent_stage "Save to library", // name "SimpleVolumesStage3.ex5", // expert "GBPUSD", // symbol "H1", // period 0, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query3); id_stage3 = DB::Insert(query3); }
Para cada estágio, definimos seu nome, o identificador do estágio-pai e o nome do EA para o estágio. Os demais campos da tabela de estágios serão, em sua maioria, iguais para diferentes estágios: intervalo de otimização, depósito inicial e assim por diante.
O trabalho principal recai sobre a função de criação de trabalhos e tarefas CreateJobs(). Cada trabalho corresponderá a uma combinação de símbolo e timeframe. Por isso, inicialmente criamos arrays para todos os símbolos e timeframes usados, que estão listados nos parâmetros de entrada. Para os timeframes, adicionamos a função StringToTimeframe(), que converte o nome do timeframe de string para o valor do tipo ENUM_TIMEFRAMES.
// Array of symbols for strategies string symbols[]; StringSplit(symbols_, ';', symbols); // Array of timeframes for strategies ENUM_TIMEFRAMES timeframes[]; string sTimeframes[]; StringSplit(timeframes_, ';', sTimeframes); FOREACH(sTimeframes, APPEND(timeframes, StringToTimeframe(sTimeframes[i])));
Em seguida, em um laço duplo, percorremos todas as combinações de símbolos e timeframes e criamos três tarefas de otimização com critério personalizado para cada uma delas.
// Stage 1 FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the first stage string params = StringFormat(paramsTemplate1, ""); // Request to create the first stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage1, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs1, id_job); // Create three tasks for this job for(int i = 0; i < 3; i++) { query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } } });
Esse número de tarefas se deve, por um lado, à necessidade de acumular pelo menos 10 a 20 mil passes de otimização em uma única combinação e, por outro lado, à necessidade de evitar que o tempo de otimização se torne excessivo. O critério personalizado foi escolhido para todas as três tarefas porque, em diferentes execuções, o algoritmo genético para essa estratégia de trading quase sempre converge para combinações de parâmetros diferentes. Portanto, não há necessidade de usar critérios distintos em cada execução, já que, de qualquer forma, obtemos uma variedade suficientemente rica de boas combinações de parâmetros para o exemplar individual da estratégia.
No futuro, poderemos expor no EA-script a cantidad de tarefas y os critérios de otimização a serem usados, mas, por enquanto, eles estão apenas fixados no código.
Para cada trabalho do primeiro estágio, utilizamos o mesmo template de parâmetros de otimização, definido na variável global paramsTemplate1:
// Template of optimization parameters at the first stage string paramsTemplate1 = "; === Open signal parameters\n" "signalPeriod_=212||12||40||240||Y\n" "signalDeviation_=0.1||0.1||0.1||2.0||Y\n" "signaAddlDeviation_=0.8||0.1||0.1||2.0||Y\n" "; === Pending order parameters\n" "openDistance_=10||0||10||250||Y\n" "stopLevel_=16000||200.0||200.0||20000.0||Y\n" "takeLevel_=240||100||10||2000.0||Y\n" "ordersExpiration_=22000||1000||1000||60000||Y\n" "; === Capital management parameters\n" "maxCountOfOrders_=3||3||1||30||N\n";
Os identificadores dos trabalhos criados são salvos no array id_jobs1, para serem usados posteriormente na criação dos trabalhos do segundo estágio.
Para a criação dos trabalhos do segundo estágio também utilizamos um template definido na variável global paramsTemplate2, mas nele já existe uma parte variável:
// Template of optimization parameters for the second stage string paramsTemplate2 = "idParentJob_=%s\n" "useClusters_=false||false||0||true||N\n" "minCustomOntester_=500.0||0.0||0.000000||0.000000||N\n" "minTrades_=40||40||1||400||N\n" "minSharpeRatio_=0.7||0.7||0.070000||7.000000||N\n" "count_=8||8||1||80||N\n";
O valor que vem após "idParentJob_=" representa o identificador do trabalho do primeiro estágio que utiliza uma determinada combinação de símbolo e timeframe. Antes da criação dos trabalhos do primeiro estágio esses valores são desconhecidos, portanto eles serão inseridos nesse template diretamente a partir do array id_jobs1, no momento da criação de cada trabalho do segundo estágio.
O parâmetro count_ nesse template está definido como 8, ou seja, vamos formar grupos de oito exemplares individuais da estratégia de trading. Nosso EA do segundo estágio permite definir nesse parâmetro valores de 1 a 16. Escolhemos o valor 8 pelos mesmos motivos que definimos a quantidade de tarefas para um trabalho no primeiro estágio — não é pouco demais, mas também não é excessivo. No futuro, esse valor também poderá ser exposto como parâmetro de entrada do script.
// Stage 2 int k = 0; FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the second stage string params = StringFormat(paramsTemplate2, IntegerToString(id_jobs1[k])); // Request to create a second stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage2, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs2, id_job); k++; // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } });
No segundo estágio, para cada trabalho criamos apenas uma tarefa de otimização, já que em um único ciclo conseguimos selecionar grupos suficientemente bons de exemplares individuais da estratégia de trading. O critério de otimização, assim como antes, será o critério personalizado.
Os identificadores dos trabalhos criados também são salvos no array id_jobs2, embora por enquanto não tenhamos precisado deles. Talvez eles sejam úteis ao adicionar novos estágios, por isso optamos por mantê-los.
No terceiro estágio, o template de parâmetros contém apenas o nome do grupo final, sob o qual ele será adicionado à biblioteca:
// Template of optimization parameters at the third stage string paramsTemplate3 = "groupName_=%s\n" "passes_=";
Formamos o nome do grupo final a partir do nome e da versão do projeto e da data de término do intervalo de otimização, e o inserimos no template usado para a criação do trabalho do terceiro estágio. Como nesse estágio reunimos os resultados de todos os anteriores, será criada apenas uma única tarefa para um único trabalho.
// Stage 3 // Use the optimization parameters template for the third stage string params = StringFormat(paramsTemplate3, projectName_ + "_v." + projectVersion_ + "_" + TimeToString(toDate_, TIME_DATE)); // // Request to create a third stage job string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage3, "GBPUSD", "D1", params); ulong id_job = DB::Insert(query); // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 0); DB::Execute(query);
Depois disso, resta apenas alterar o status do projeto para que ele seja colocado na fila de execução:
//+------------------------------------------------------------------+ //| Queueing the project for execution | //+------------------------------------------------------------------+ void QueueProject() { string query = StringFormat("UPDATE projects SET status='Queued' WHERE id_project=%d;", id_project); DB::Execute(query); }
As alterações realizadas foram salvas no novo arquivo CreateProject.mq5 na pasta atual.
E mais um detalhe. Já podemos considerar que o esquema do banco de dados será definitivo, portanto, podemos integrá-lo à biblioteca. Para isso, criamos o arquivo db.schema.sql com o esquema do banco de dados na forma de um conjunto de comandos SQL e o conectamos como recurso no arquivo Database.mqh:
// Import sql file for creating DB structure #resource "db.schema.sql" as string dbSchema
Além disso, alteramos um pouco a lógica do método Connect(): caso o banco de dados com o nome especificado não exista, ele será automaticamente criado utilizando os comandos SQL carregados do arquivo incluído como recurso. Ao mesmo tempo, removemos o método ExecuteFile(), já que ele não é mais utilizado em nenhum lugar.
Finalmente chegamos ao ponto em que podemos tentar executar o código desenvolvido.
Preenchimento do banco de dados
Não vamos gerar muitos projetos de imediato, mas nos limitaremos a apenas quatro. Para isso, basta arrastar o EA-script escrito para qualquer gráfico quatro vezes, configurando os parâmetros necessários em cada execução. Todos os parâmetros, exceto a data de término, permanecerão com os valores padrão. Já a data final será modificada, adicionando a cada vez um mês extra ao intervalo de teste.
Como resultado, obteremos algo semelhante a este conteúdo no banco de dados. Na tabela de projetos haverá quatro projetos:
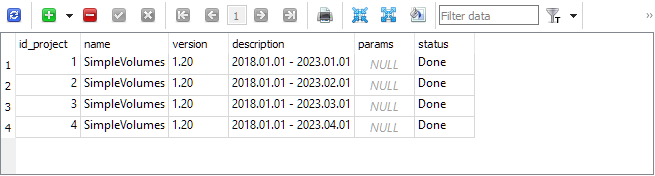
Na tabela de estágios, foram criados quatro estágios para cada projeto. Um estágio adicional chamado "Single tester pass" é automaticamente criado quando um projeto é iniciado e é usado quando desejamos executar um único passe do testador de estratégias fora do pipeline de reotimização automática:
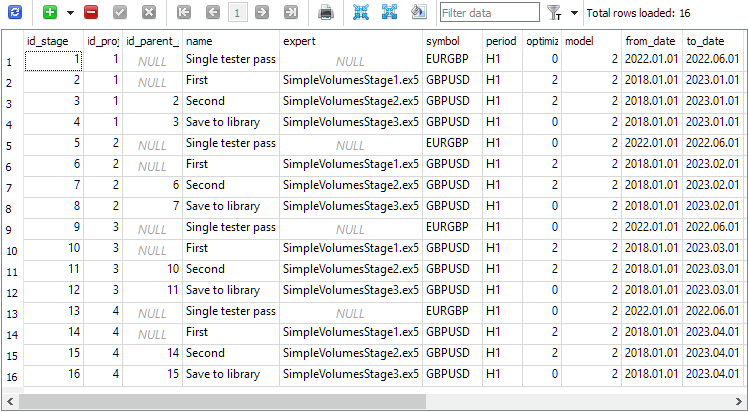
Na tabela de trabalhos foram adicionados os trabalhos correspondentes:
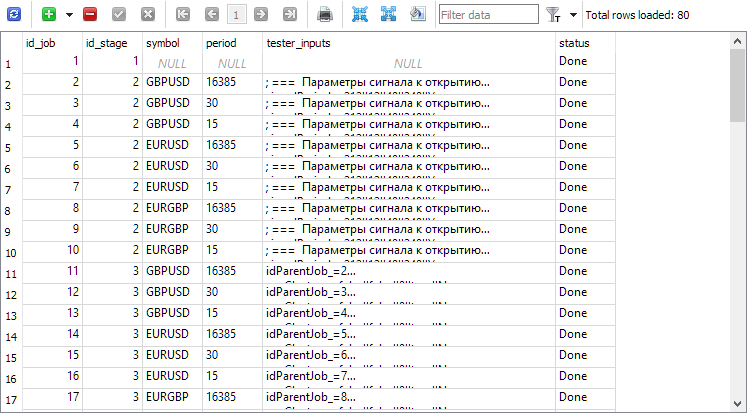
Após a execução dos projetos, o resultado foi obtido em aproximadamente quatro dias. Claro, não é um tempo tão curto, mesmo considerando os esforços de otimização de desempenho. Mas também não é tão longo a ponto de ser inviável. Podemos vê-lo na tabela da biblioteca de grupos strategy_groups:

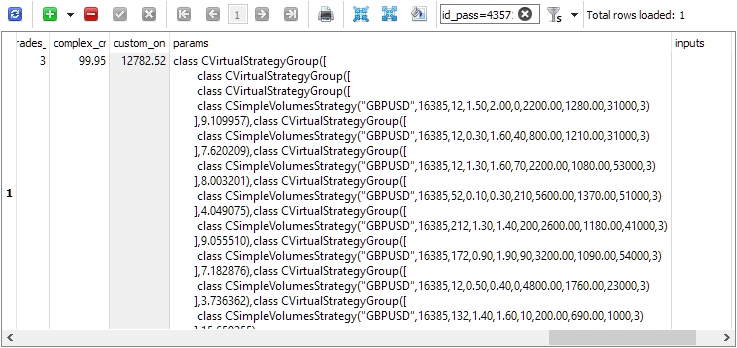
Pelo identificador do passe id_pass, é possível consultar a linha de inicialização na tabela de passes passes, por exemplo:
Ou podemos passar o identificador do passe como parâmetro de entrada para o EA do terceiro estágio SimpleVolumesStage3.ex5 e executá-lo no testador no intervalo de tempo desejado:
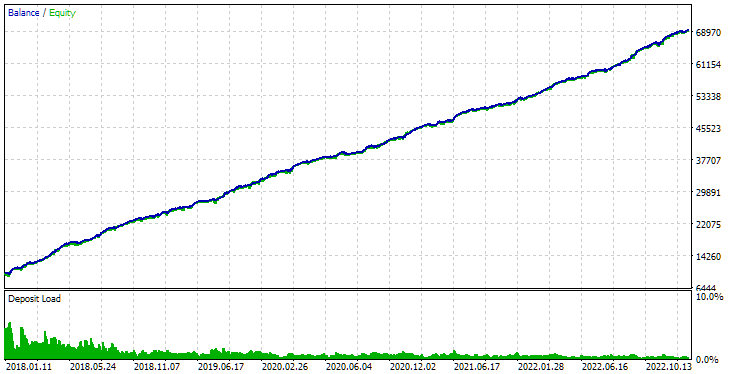
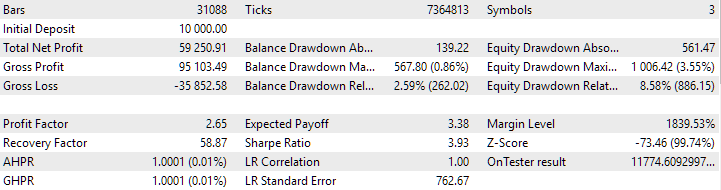
Fig. 3. Resultados da aprovação do Expert Advisor SimpleVolumesStage3.ex5 com id_pass=876663 no intervalo 2018.01.01 - 2023.01.01.01
Por enquanto, vamos parar por aqui e analisar os resultados em mais detalhes nos próximos artigos.
Considerações finais
Assim, conseguimos criar a possibilidade de gerar automaticamente tarefas para a execução do pipeline de reotimização automática, composto por três estágios. Por enquanto, trata-se apenas de um rascunho, que permitirá identificar as direções mais promissoras para o desenvolvimento futuro. Questões sobre a implementação da união ou substituição automática das linhas de inicialização dos EAs finais ao término dos estágios do pipeline para cada projeto ainda permanecem em aberto.
Mas uma coisa já pode ser afirmada com certeza. A ordem escolhida para a execução das tarefas de otimização no pipeline não é muito eficiente. Atualmente, precisamos aguardar a conclusão completa de todos os trabalhos do primeiro estágio para só então iniciar o segundo. E, da mesma forma, o terceiro estágio não começa antes que todos os trabalhos do segundo tenham terminado. Se planejamos de alguma forma implementar uma substituição "a quente" das linhas de inicialização do EA final, que continuará operando em conta real em paralelo à otimização em andamento, então seria possível realizar essas atualizações em blocos menores, porém mais frequentes. Talvez isso permita melhorar os resultados, mas, por enquanto, trata-se apenas de uma hipótese que precisa ser verificada.
Também vale ressaltar que o EA-script desenvolvido foi projetado especificamente para criar projetos de otimização da estratégia-modelo em estudo. Para outra estratégia, será necessário realizar pequenas alterações no código-fonte. No mínimo, será preciso modificar o template da string de parâmetros de entrada do primeiro estágio de otimização. Ainda não levamos esses templates para os parâmetros de entrada, já que defini-los diretamente por lá não seria prático. Contudo, provavelmente desenvolveremos algum formato de descrição da tarefa de criação do projeto, que o EA-script poderá carregar a partir de um arquivo. Mas isso ficará para a próxima vez.
Obrigado pela atenção, até a próxima!
Aviso importante
Todos os resultados apresentados neste artigo e em todos os artigos anteriores da série são baseados exclusivamente em dados de testes históricos e não garantem nenhum tipo de lucro no futuro. O trabalho realizado neste projeto tem caráter de pesquisa. Todos os resultados publicados podem ser utilizados por qualquer pessoa, por sua conta e risco.
Conteúdo do arquivo
| # | Nome | Versão | Descrição | Últimas alterações |
|---|---|---|---|---|
| MQL5/Experts/Article.16373 | ||||
| 1 | Advisor.mqh | 1.04 | Classe base do EA | Parte 10 |
| 2 | ClusteringStage1.py | 1.01 | Programa de clusterização dos resultados do primeiro estágio de otimização | Parte 20 |
| 3 | CreateProject.mq5 | 1.00 | EA-script de criação de projeto com estágios, trabalhos e tarefas de otimização. | Parte 21 |
| 4 | Database.mqh | 1.09 | Classe para trabalhar com banco de dados | Parte 21 |
| 5 | db.schema.sql | 1.05 | Esquema do banco de dados | Parte 20 |
| 6 | ExpertHistory.mqh | 1.00 | Classe para exportar histórico de operações para arquivo | Parte 16 |
| 7 | ExportedGroupsLibrary.mqh | — | Arquivo gerado com a enumeração dos nomes dos grupos de estratégias e o array de suas linhas de inicialização | Parte 17 |
| 8 | Factorable.mqh | 1.02 | Classe base de objetos criados a partir de string | Parte 19 |
| 9 | GroupsLibrary.mqh | 1.01 | Classe para trabalhar com a biblioteca de grupos de estratégias selecionadas | Parte 18 |
| 10 | HistoryReceiverExpert.mq5 | 1.00 | EA de reprodução do histórico de operações com gerenciador de risco | Parte 16 |
| 11 | HistoryStrategy.mqh | 1.00 | Classe da estratégia de trading de reprodução do histórico de operações | Parte 16 |
| 12 | Interface.mqh | 1.00 | Classe base de visualização de vários objetos | Parte 4 |
| 13 | LibraryExport.mq5 | 1.01 | EA que salva em arquivo ExportedGroupsLibrary.mqh as linhas de inicialização dos passes selecionados da biblioteca | Parte 18 |
| 14 | Macros.mqh | 1.02 | Macros úteis para operações com arrays | Parte 16 |
| 15 | Money.mqh | 1.01 | Classe base de gestão de capital | Parte 12 |
| 16 | NewBarEvent.mqh | 1.00 | Classe de detecção de novo barra para um símbolo específico | Parte 8 |
| 17 | Optimization.mq5 | 1.03 | EA que gerencia a execução de tarefas de otimização | Parte 19 |
| 18 | Optimizer.mqh | 1.01 | Classe do gerenciador de reotimização automática de projetos | Parte 20 |
| 19 | OptimizerTask.mqh | 1.01 | Classe da tarefa de otimização | Parte 20 |
| 20 | Receiver.mqh | 1.04 | Classe base de tradução de volumes abertos em posições de mercado | Parte 12 |
| 21 | SimpleHistoryReceiverExpert.mq5 | 1.00 | EA simplificado de reprodução do histórico de operações | Parte 16 |
| 22 | SimpleVolumesExpert.mq5 | 1.20 | EA para operação paralela de vários grupos de estratégias-modelo. Os parâmetros serão obtidos da biblioteca de grupos integrada. | Parte 17 |
| 23 | SimpleVolumesStage1.mq5 | 1.18 | EA de otimização de um exemplar individual da estratégia de trading (Estágio 1) | Parte 19 |
| 24 | SimpleVolumesStage2.mq5 | 1.02 | EA de otimização de grupo de exemplares da estratégia de trading (Estágio 2) | Parte 19 |
| 25 | SimpleVolumesStage3.mq5 | 1.02 | EA que salva o grupo normalizado de estratégias formado na biblioteca de grupos com o nome definido. | Parte 20 |
| 26 | SimpleVolumesStrategy.mqh | 1.10 | Classe da estratégia de trading com uso de volumes em ticks | Parte 21 |
| 27 | Strategy.mqh | 1.04 | Classe base da estratégia de trading | Parte 10 |
| 28 | SymbolsMonitor.mqh | 1.00 | Classe de obtenção de informações sobre instrumentos de trading (símbolos) | Parte 21 |
| 29 | TesterHandler.mqh | 1.05 | Classe para manipulação de eventos de otimização | Parte 19 |
| 30 | VirtualAdvisor.mqh | 1.08 | Classe do EA que trabalha com posições virtuais (ordens) | Parte 21 |
| 31 | VirtualChartOrder.mqh | 1.01 | Classe de posição virtual gráfica | Parte 18 |
| 32 | VirtualFactory.mqh | 1.04 | Classe fábrica de objetos | Parte 16 |
| 33 | VirtualHistoryAdvisor.mqh | 1.00 | Classe do EA de reprodução do histórico de operações | Parte 16 |
| 34 | VirtualInterface.mqh | 1.00 | Classe da interface gráfica do EA | Parte 4 |
| 35 | VirtualOrder.mqh | 1.08 | Classe de ordens e posições virtuais | Parte 21 |
| 36 | VirtualReceiver.mqh | 1.03 | Classe de tradução de volumes abertos em posições de mercado (receptor) | Parte 12 |
| 37 | VirtualRiskManager.mqh | 1.02 | Classe de gestão de risco (risk manager) | Parte 15 |
| 38 | VirtualStrategy.mqh | 1.05 | Classe da estratégia de trading com posições virtuais | Parte 15 |
| 39 | VirtualStrategyGroup.mqh | 1.00 | Classe de grupo de estratégias de trading ou grupos de estratégias de trading | Parte 11 |
| 40 | VirtualSymbolReceiver.mqh | 1.00 | Classe do receptor por símbolo | Parte 3 |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16373
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
O artigo Developing a Multicurrency Expert Advisor (Parte 21) foi publicado: Preparando-se para um experimento importante e otimizando o código:
Autor: Yuriy Bykov
Infelizmente, nemtudo é tão simples quantogostaríamos . Para poder iniciar o Expert Advisor doterceiro estágio, é necessárioespecificar osIDs dos passes obtidos como resultado dosestágiosanteriores dopipeline deotimização . Comoobtê-los está descrito nos artigos.
Entendido. No entanto, já que você se esforçou tanto para descrever seu trabalho de maneira mais simples, seria ótimo se você pudesse criar um tutorial em vídeo para ensinar a operação/otimização do conjunto de EAs que você está criando. Muito obrigado
Entendi. No entanto, já que você se esforçou tanto para descrever seu trabalho de maneira mais simples, seria ótimo se você pudesse criar um tutorial em vídeo para ensinar a operação/otimização do conjunto de EAs que você está criando. Muito obrigado
Olá, obrigado pela sugestão. Não posso prometer que conseguirei gravar vídeos para artigos, mas pensarei em como e de que forma posso fazer um vídeo que ajude os leitores dos artigos.
Olá, obrigado pela sugestão. Não posso prometer que realmente conseguirei gravar vídeos para artigos, mas pensarei em como e de que forma posso fazer um vídeo que ajude os leitores dos artigos.
Obrigado. Um vídeo bem simples, com duração de alguns segundos, será suficiente. Como o teste e a otimização da estratégia no MT5 são mais complexos do que no MT4, as pessoas que estão fazendo a transição às vezes acham difícil. Tudo o que você pode fazer é mostrar as configurações exatas que usa para obter os resultados que publica nos artigos.
HI Download Last Part Files (21) Como posso usar esse conselheiro? Você pode me ajudar, por favor?