Artikel über das Programmieren in MQL5
Lernen Sie die Sprache von Handelsstrategien MQL5 nach den hier veröffentlichten Artikeln, die meisten von denen Sie - die Mitglieder der Community - geschrieben haben. Alle Artikel sind in drei Kategorien aufgeteilt, damit man eine Antwort auf unterschiedliche Fragen des Programmierens schnell finden könnte: "Integration", "Tester", "Handelsstrategien" und vieles mehr.
Verfolgen Sie neue Veröffentlichungen und diskutieren Sie über diese im Forum!
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Neuronale Netze leicht gemacht (Teil 24): Verbesserung des Instruments für Transfer Learning
Im vorigen Artikel haben wir ein Tool zum Erstellen und Bearbeiten der Architektur neuronaler Netze entwickelt. Heute werden wir die Arbeit an diesem Instrument fortsetzen. Wir werden versuchen, sie nutzerfreundlicher zu gestalten. Dies mag ein Schritt weg von unserem Thema sein. Aber ist es nicht so, dass ein gut organisierter Arbeitsplatz eine wichtige Rolle bei der Erreichung dieses Ziels spielt?

Frequenzbereichsdarstellungen von Zeitreihen: Das Leistungsspektrum
In diesem Artikel erörtern wir Methoden zur Analyse von Zeitreihen im Frequenzbereich. Hervorhebung des Nutzens der Untersuchung der Leistungsspektren von Zeitreihen bei der Erstellung von Vorhersagemodellen. In diesem Artikel werden wir einige der nützlichen Perspektiven erörtern, die sich aus der Analyse von Zeitreihen im Frequenzbereich unter Verwendung der diskreten Fourier-Transformation (dft) ergeben.

GUI: Tipps und Tricks zur Erstellung Ihrer eigenen Grafikbibliothek in MQL
Wir gehen die Grundlagen von GUI-Bibliotheken durch, damit Sie verstehen, wie sie funktionieren, oder sogar anfangen können, Ihre eigenen zu erstellen.

Einführung in MQL5 (Teil 4): Strukturen, Klassen und Zeitfunktionen beherrschen
Enthüllen wir die Geheimnisse der MQL5-Programmierung in unserem neuesten Artikel! Vertiefen wir uns in die Grundlagen von Strukturen, Klassen und Zeitfunktionen und machen uns mit der Programmierung vertraut. Egal, ob Sie Anfänger oder erfahrener Entwickler sind, unser Leitfaden vereinfacht komplexe Konzepte und bietet wertvolle Einblicke für die Beherrschung von MQL5. Verbessern Sie Ihre Programmierkenntnisse und bleiben Sie in der Welt des algorithmischen Handels an der Spitze!

Entwicklung eines Replay-Systems — Marktsimulation (Teil 12): Die Geburt des SIMULATORS (II)
Die Entwicklung eines Simulators kann viel interessanter sein, als es scheint. Heute gehen wir ein paar Schritte weiter in diese Richtung, denn die Dinge werden immer interessanter.

Datenwissenschaft und maschinelles Lernen (Teil 16): Ein frischer Blick auf die Entscheidungsbäume
Tauchen wir ein in die komplizierte Welt der Entscheidungsbäume in der neuesten Folge unserer Serie über Datenwissenschaft und maschinelles Lernen. Dieser Artikel ist auf Händler zugeschnitten, die nach strategischen Einsichten suchen, und dient als umfassende Zusammenfassung, die die wichtige Rolle von Entscheidungsbäumen bei der Analyse von Markttrends beleuchtet. Wir erforschen die Wurzeln und Äste dieser algorithmischen Bäume und erschließen Sie deren Potenzial zur Verbesserung Ihrer Handelsentscheidungen. Erleben Sie mit uns eine erfrischende Perspektive auf Entscheidungsbäume und entdecken Sie, wie sie Ihnen bei der Navigation durch die Komplexität der Finanzmärkte behilflich sein können.
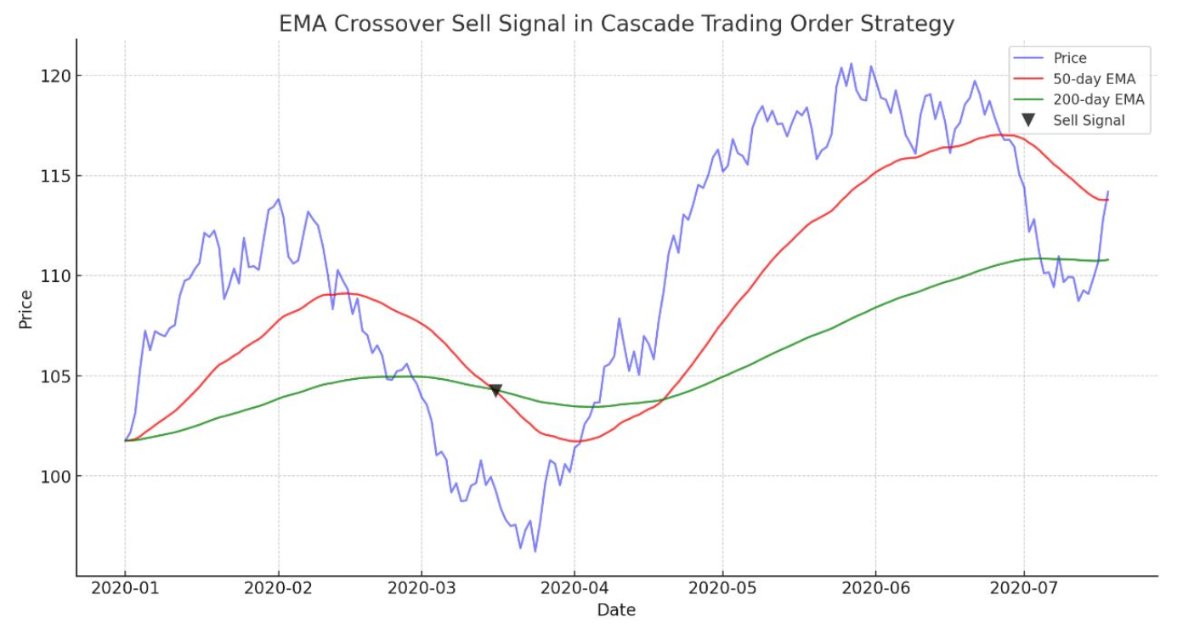
Handelsstrategie kaskadierender Aufträge basierend auf EMA Crossovers für MetaTrader 5
Der Artikel demonstriert einen automatisierten Algorithmus, der auf dem Kreuzen von EMAs für MetaTrader 5 basiert. Detaillierte Informationen zu allen Aspekten der Demonstration eines Expert Advisors in MQL5 und dem Testen in MetaTrader 5 - von der Analyse des Preisbereichsverhaltens bis zum Risikomanagement.

Neuronale Netze leicht gemacht (Teil 18): Assoziationsregeln
Als Fortsetzung dieser Artikelserie betrachten wir eine andere Art von Problemen innerhalb der Methoden des unüberwachten Lernens: die Ermittlung von Assoziationsregeln. Dieser Problemtyp wurde zuerst im Einzelhandel, insbesondere in Supermärkten, zur Analyse von Warenkörben eingesetzt. In diesem Artikel werden wir über die Anwendbarkeit solcher Algorithmen im Handel sprechen.

Kategorientheorie in MQL5 (Teil 23): Ein anderer Blick auf den doppelten exponentiellen gleitenden Durchschnitt
In diesem Artikel setzen wir unser Thema vom letzten Mal fort, indem wir uns mit alltäglichen Handelsindikatoren befassen, die wir in einem „neuen“ Licht betrachten. Wir befassen uns in diesem Beitrag mit der horizontalen Zusammensetzung natürlicher Transformationen, und der beste Indikator dafür, der das soeben behandelte Thema noch erweitert, ist der doppelte exponentielle gleitende Durchschnitt (DEMA).

Neuronale Netze leicht gemacht (Teil 66): Explorationsprobleme beim Offline-Lernen
Modelle werden offline mit Daten aus einem vorbereiteten Trainingsdatensatz trainiert. Dies bietet zwar gewisse Vorteile, hat aber den Nachteil, dass die Informationen über die Umgebung stark auf die Größe des Trainingsdatensatzes komprimiert werden. Das wiederum schränkt die Möglichkeiten der Erkundung ein. In diesem Artikel wird eine Methode vorgestellt, die es ermöglicht, einen Trainingsdatensatz mit möglichst unterschiedlichen Daten zu füllen.

Algorithmen zur Optimierung mit Populationen: der Algorithmus Simulated Annealing (SA). Teil I
Der Algorithmus des Simulated Annealing ist eine Metaheuristik, die vom Metallglühprozess inspiriert ist. In diesem Artikel führen wir eine gründliche Analyse des Algorithmus durch und räumen mit einer Reihe von weit verbreiteten Überzeugungen und Mythen rund um diese weithin bekannte Optimierungsmethode auf. Der zweite Teil des Artikels befasst sich mit dem nutzerdefinierten Algorithmus Simulated Isotropic Annealing (SIA).

Integrieren Sie Ihr eigenes LLM in Ihren EA (Teil 3): Training Ihres eigenen LLM mit CPU
Angesichts der rasanten Entwicklung der künstlichen Intelligenz sind Sprachmodelle (language models, LLMs) heute ein wichtiger Bestandteil der künstlichen Intelligenz, sodass wir darüber nachdenken sollten, wie wir leistungsstarke LLMs in unseren algorithmischen Handel integrieren können. Für die meisten Menschen ist es schwierig, diese leistungsstarken Modelle auf ihre Bedürfnisse abzustimmen, sie lokal einzusetzen und sie dann auf den algorithmischen Handel anzuwenden. In dieser Artikelserie werden wir Schritt für Schritt vorgehen, um dieses Ziel zu erreichen.

Neuronale Netze leicht gemacht (Teil 72): Entwicklungsvorhersage in verrauschten Umgebungen
Die Qualität der Vorhersage zukünftiger Zustände spielt eine wichtige Rolle bei der Methode des Goal-Conditioned Predictive Coding, die wir im vorherigen Artikel besprochen haben. In diesem Artikel möchte ich Ihnen einen Algorithmus vorstellen, der die Vorhersagequalität in stochastischen Umgebungen, wie z. B. den Finanzmärkten, erheblich verbessern kann.

Risikomanager für den manuellen Handel
In diesem Artikel wird detailliert beschrieben, wie man eine Risikomanager-Klasse für den manuellen Handel von Grund auf schreibt. Diese Klasse kann auch als Basisklasse für die Vererbung durch algorithmische Händler verwendet werden, die automatisierte Programme einsetzen.

DoEasy. Steuerung (Teil 23): Verbesserung der WinForms-Objekte TabControl und SplitContainer
In diesem Artikel werde ich neue Mausereignisse relativ zu den Grenzen der Arbeitsbereiche von WinForms-Objekten hinzufügen und einige Mängel in der Funktionsweise der TabControl- und SplitContainer-Steuerelemente beheben.
Automatisieren von Handelsstrategien in MQL5 (Teil 4): Aufbau eines mehrstufigen Zone Recovery Systems
In diesem Artikel entwickeln wir ein mehrstufiges Zone Recovery System in MQL5, das den RSI zur Erzeugung von Handelssignalen nutzt. Jede Signalinstanz wird dynamisch zu einer Array-Struktur hinzugefügt, sodass das System mehrere Signale gleichzeitig innerhalb der Zonenwiederherstellungslogik verwalten kann. Mit diesem Ansatz zeigen wir, wie man komplexe Handelsverwaltungsszenarien effektiv handhabt und gleichzeitig einen skalierbaren und robusten Codeentwurf beibehält.

Entwicklung eines Qualitätsfaktors für Expert Advisors
In diesem Artikel sehen wir uns an, wie Sie eine Qualitätsbewertung entwickeln, die Ihr Expert Advisor im Strategietester anzeigen kann. Wir werden uns zwei bekannte Berechnungsmethoden ansehen – Van Tharp und Sunny Harris.

Algorithmen zur Optimierung mit Populationen: Der Algorithmus Simulated Isotropic Annealing (SIA). Teil II
Der erste Teil war dem bekannten und beliebten Algorithmus des Simulated Annealing gewidmet. Wir haben ihre Vor- und Nachteile gründlich abgewogen. Der zweite Teil des Artikels ist der radikalen Umgestaltung des Algorithmus gewidmet, die ihn zu einem neuen Optimierungsalgorithmus macht, dem Simulated Isotropic Annealing (SIA).

Neuronale Netze leicht gemacht (Teil 47): Kontinuierlicher Aktionsraum
In diesem Artikel erweitern wir das Aufgabenspektrum unseres Agenten. Der Ausbildungsprozess wird einige Aspekte des Geld- und Risikomanagements umfassen, die ein wesentlicher Bestandteil jeder Handelsstrategie sind.

Kategorientheorie in MQL5 (Teil 18): Natürliches Quadrat (Naturality Square)
In diesem Artikel setzen wir unsere Reihe zur Kategorientheorie fort, indem wir natürliche Transformationen, eine der wichtigsten Säulen des Fachs, vorstellen. Wir befassen uns mit der scheinbar komplexen Definition und gehen dann auf Beispiele und Anwendungen dieser Serie ein: Volatilitätsprognosen.

Neuronale Netze leicht gemacht (Teil 63): Unüberwachtes Pretraining für Decision Transformer (PDT)
Wir setzen die Diskussion über die Familie der Entscheidungstransformationsmethoden fort. In einem früheren Artikel haben wir bereits festgestellt, dass das Training des Transformators, der der Architektur dieser Methoden zugrunde liegt, eine ziemlich komplexe Aufgabe ist und einen großen gekennzeichneten Datensatz für das Training erfordert. In diesem Artikel wird ein Algorithmus zur Verwendung von ungekennzeichneten Trajektorien für das vorläufige Modelltraining vorgestellt.

Parafrac-Oszillator: Kombination von Parabel- und Fraktalindikator
Wir werden untersuchen, wie der Parabolic SAR und der Fractal-Indikator kombiniert werden können, um einen neuen oszillatorbasierten Indikator zu schaffen. Durch die Integration der einzigartigen Stärken beider Instrumente können Händler eine raffiniertere und effektivere Handelsstrategie entwickeln.
DoEasy. Steuerung (Teil 19): Verschieben der Registerkarten in TabControl, Ereignisse im WinForms-Objekt
In diesem Artikel werde ich die Funktionsweise zum Verschieben (scrolling) von Registerkartenüberschriften in TabControl mithilfe von Scroll-Schaltflächen erstellen. Die Funktionalität ist dazu gedacht, Tabulator-Kopfzeilen in einer einzigen Zeile auf beiden Seiten des Steuerelements zu platzieren.
Neuronale Netze leicht gemacht (Teil 56): Nuklearnorm als Antrieb für die Erkundung nutzen
Die Untersuchung der Umgebung beim Verstärkungslernen ist ein dringendes Problem. Wir haben uns bereits mit einigen Ansätzen beschäftigt. In diesem Artikel werden wir uns eine weitere Methode ansehen, die auf der Maximierung der Nuklearnorm beruht. Es ermöglicht den Agenten, Umgebungszustände mit einem hohen Maß an Neuartigkeit und Vielfalt zu erkennen.

Aufbau eines Modells von Kerzen, Trend und Nebenbedingungen (Teil 1): Für EAs und technische Indikatoren
Dieser Artikel richtet sich an Anfänger und Profi-MQL5-Entwickler. Es stellt einen Code zur Verfügung, um signalgenerierende Indikatoren zu definieren und auf Trends in höheren Zeitrahmen zu beschränken. Auf diese Weise können Händler ihre Strategien verbessern, indem sie eine breitere Marktperspektive einbeziehen, was zu potenziell robusteren und zuverlässigeren Handelssignalen führt.

Entwicklung eines Replay-Systems — Marktsimulation (Teil 08): Sperren des Indikators
In diesem Artikel werden wir uns ansehen, wie man den Indikator sperren kann, indem man einfach die Sprache MQL5 verwendet, und zwar auf eine sehr interessante und erstaunliche Weise.
Algorithmen zur Optimierung mit Populationen: Spiralförmige Dynamische Optimization (SDO) Algorithmus
In diesem Artikel wird ein Optimierungsalgorithmus vorgestellt, der auf den Mustern der Konstruktion spiralförmiger Trajektorien in der Natur, wie z. B. bei Muschelschalen, basiert - der Algorithmus der spiralförmigen dynamischen Optimierung (SDO). Ich habe den von den Autoren vorgeschlagenen Algorithmus gründlich überarbeitet und verändert. Der Artikel befasst sich mit der Notwendigkeit dieser Änderungen.

Kausalschluss in den Problemen bei Zeitreihenklassifizierungen
In diesem Artikel werden wir uns mit der Theorie des Kausalschlusses unter Verwendung von maschinellem Lernen sowie mit der Implementierung des nutzerdefinierten Ansatzes in Python befassen. Kausalschlüsse und kausales Denken haben ihre Wurzeln in der Philosophie und Psychologie und spielen eine wichtige Rolle für unser Verständnis der Realität.
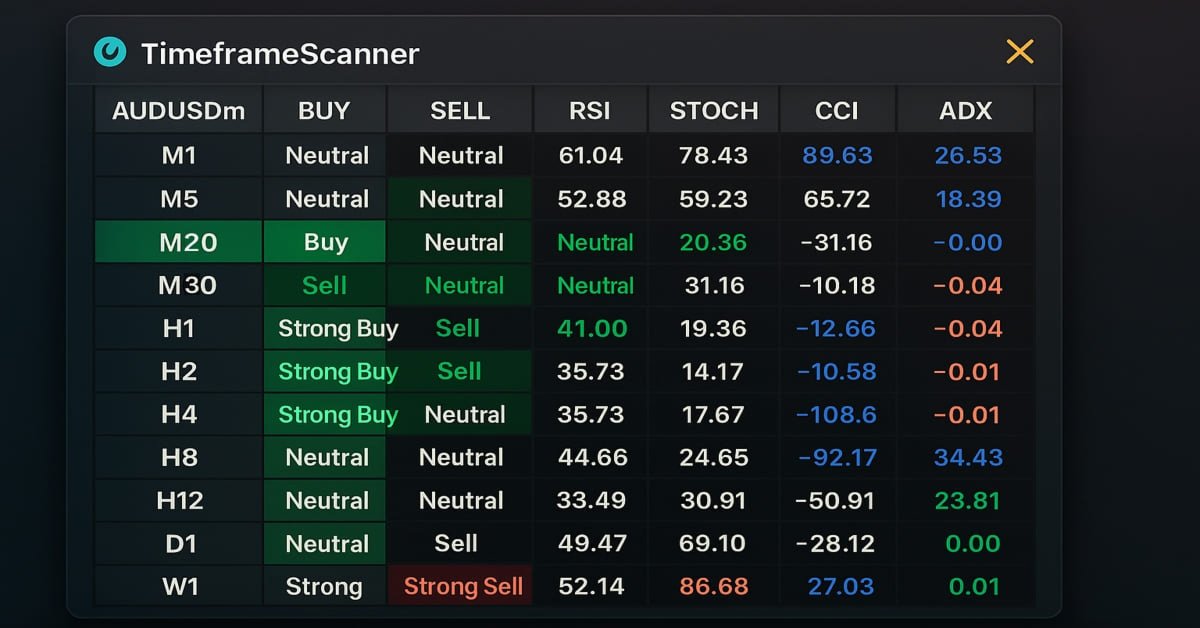
MQL5-Handelswerkzeuge (Teil 3): Aufbau eines Multi-Timeframe Scanner Dashboards für den strategischen Handel
In diesem Artikel bauen wir ein Multi-Timeframe-Scanner-Dashboard in MQL5, um Handelssignale in Echtzeit anzuzeigen. Wir planen eine interaktive Gitterschnittstelle, implementieren Signalberechnungen mit mehreren Indikatoren und fügen eine Schaltfläche zum Schließen hinzu. Der Artikel schließt mit Backtests und strategischen Handelsvorteilen

Algorithmen zur Optimierung mit Populationen Optimierung gemäß einer bakteriellen Nahrungssuche (BFO)
Die Strategie der Nahrungssuche des Bakteriums E. coli inspirierte die Wissenschaftler zur Entwicklung des BFO-Optimierungsalgorithmus. Der Algorithmus enthält originelle Ideen und vielversprechende Optimierungsansätze und ist es wert, weiter untersucht zu werden.

Neuronale Netze leicht gemacht (Teil 41): Hierarchische Modelle
Der Artikel beschreibt hierarchische Trainingsmodelle, die einen effektiven Ansatz für die Lösung komplexer maschineller Lernprobleme bieten. Hierarchische Modelle bestehen aus mehreren Ebenen, von denen jede für verschiedene Aspekte der Aufgabe zuständig ist.

Entwicklung eines Expertenberaters für mehrere Währungen (Teil 6): Automatisieren der Auswahl einer Instanzgruppe
Nach der Optimierung der Handelsstrategie erhalten wir eine Reihe von Parametern. Wir können sie verwenden, um mehrere Instanzen von Handelsstrategien zu erstellen, die in einem EA kombiniert werden. Früher haben wir das manuell gemacht. Hier werden wir versuchen, diesen Prozess zu automatisieren.
Analyse mehrerer Symbole mit Python und MQL5 (Teil II): Hauptkomponentenanalyse zur Portfolio-Optimierung
Das Management des Risikos eines Handelskontos ist für alle Händler eine Herausforderung. Wie können wir Handelsanwendungen entwickeln, die dynamisch hohe, mittlere und niedrige Risikomodi für verschiedene Symbole in MetaTrader 5 erlernen? Durch den Einsatz der PCA erhalten wir eine bessere Kontrolle über die Portfoliovarianz. Ich werde zeigen, wie man Anwendungen erstellt, die diese drei Risikomodi aus den Marktdaten des MetaTrader 5 lernen.
DoEasy. Steuerung (Teil 17): Beschneiden unsichtbarer Objektteile, Hilfspfeiltasten WinForms-Objekte
In diesem Artikel werde ich die Funktionalität zum Ausblenden von Objektabschnitten, die sich außerhalb ihrer Container befinden, erstellen. Außerdem werde ich zusätzliche Pfeiltastenobjekte erstellen, die als Teil anderer WinForms-Objekte verwendet werden können.

Datenkennzeichnung für die Zeitreihenanalyse (Teil 3):Beispiel für die Verwendung von Datenkennzeichnungen
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung (labeling) von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!

Entwurfsmuster in der Softwareentwicklung und MQL5 (Teil 3): Verhaltensmuster 1
Ein neuer Artikel aus der Reihe der Artikel über Entwurfmuster. Wir werden einen Blick auf einen seiner Typen werfen, nämlich den Verhaltensmuster, um zu verstehen, wie wir Kommunikationsmethoden zwischen erstellten Objekten effektiv aufbauen können. Durch die Vervollständigung dieser Verhaltensmuster werden wir in der Lage sein zu verstehen, wie wir eine wiederverwendbare, erweiterbare und getestete Software erstellen und aufbauen können.

Algorithmen zur Populationsoptimierung
Dies ist ein einführender Artikel über die Klassifizierung von Optimierungsalgorithmen (OA). In dem Artikel wird versucht, einen Prüfstand (eine Reihe von Funktionen) zu erstellen, der zum Vergleich von OAs und vielleicht zur Ermittlung des universellsten Algorithmus unter allen bekannten Algorithmen verwendet werden soll.

Neuronale Netze leicht gemacht (Teil 36): Relationales Verstärkungslernen
In den Verstärkungslernmodellen, die wir im vorherigen Artikel besprochen haben, haben wir verschiedene Varianten von Faltungsnetzwerken verwendet, die in der Lage sind, verschiedene Objekte in den Originaldaten zu identifizieren. Der Hauptvorteil von Faltungsnetzen ist die Fähigkeit, Objekte unabhängig von ihrer Position zu erkennen. Gleichzeitig sind Faltungsnetzwerke nicht immer leistungsfähig, wenn es zu verschiedenen Verformungen von Objekten und Rauschen kommt. Dies sind die Probleme, die das relationale Modell lösen kann.

Erfahren Sie, wie Sie ein Handelssystem anhand des Relative Vigor Index entwickeln können
Ein neuer Artikel in unserer Serie darüber, wie man ein Handelssystem anhand eines beliebten technischen Indikators entwickelt. In diesem Artikel werden wir lernen, wie man das mit Hilfe des Relativen Vigot-Index-Indikators tun kann.

Messen der Information von Indikatoren
Maschinelles Lernen hat sich zu einer beliebten Methode für die Strategieentwicklung entwickelt. Während die Maximierung der Rentabilität und der Vorhersagegenauigkeit stärker in den Vordergrund gerückt wurde, wurde der Bedeutung der Verarbeitung der Daten, die zur Erstellung von Vorhersagemodellen verwendet werden, nicht viel Aufmerksamkeit geschenkt. In diesem Artikel befassen wir uns mit der Verwendung des Konzepts der Entropie zur Bewertung der Eignung von Indikatoren für die Erstellung von Prognosemodellen, wie sie in dem Buch Testing and Tuning Market Trading Systems von Timothy Masters dokumentiert sind.