Artikel über das Programmieren in MQL4 und MQL5
Lernen Sie die Sprache von Handelsstrategien MQL5 nach den hier veröffentlichten Artikeln, die meisten von denen Sie - die Mitglieder der Community - geschrieben haben. Alle Artikel sind in drei Kategorien aufgeteilt, damit man eine Antwort auf unterschiedliche Fragen des Programmierens schnell finden könnte: "Integration", "Tester", "Handelsstrategien" und vieles mehr.
Verfolgen Sie neue Veröffentlichungen und diskutieren Sie über diese im Forum!
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
DoEasy. Steuerung (Teil 17): Beschneiden unsichtbarer Objektteile, Hilfspfeiltasten WinForms-Objekte
In diesem Artikel werde ich die Funktionalität zum Ausblenden von Objektabschnitten, die sich außerhalb ihrer Container befinden, erstellen. Außerdem werde ich zusätzliche Pfeiltastenobjekte erstellen, die als Teil anderer WinForms-Objekte verwendet werden können.

Neuronale Netze leicht gemacht (Teil 54): Einsatz von Random Encoder für eine effiziente Forschung (RE3)
Wann immer wir Methoden des Verstärkungslernens in Betracht ziehen, stehen wir vor dem Problem der effizienten Erkundung der Umgebung. Die Lösung dieses Problems führt häufig dazu, dass der Algorithmus komplizierter wird und zusätzliche Modelle trainiert werden müssen. In diesem Artikel werden wir einen alternativen Ansatz zur Lösung dieses Problems betrachten.
MQL5-Handelswerkzeuge (Teil 3): Aufbau eines Multi-Timeframe Scanner Dashboards für den strategischen Handel
In diesem Artikel bauen wir ein Multi-Timeframe-Scanner-Dashboard in MQL5, um Handelssignale in Echtzeit anzuzeigen. Wir planen eine interaktive Gitterschnittstelle, implementieren Signalberechnungen mit mehreren Indikatoren und fügen eine Schaltfläche zum Schließen hinzu. Der Artikel schließt mit Backtests und strategischen Handelsvorteilen

DoEasy. Steuerung (Teil 23): Verbesserung der WinForms-Objekte TabControl und SplitContainer
In diesem Artikel werde ich neue Mausereignisse relativ zu den Grenzen der Arbeitsbereiche von WinForms-Objekten hinzufügen und einige Mängel in der Funktionsweise der TabControl- und SplitContainer-Steuerelemente beheben.

Datenkennzeichnung für die Zeitreihenanalyse (Teil 3):Beispiel für die Verwendung von Datenkennzeichnungen
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung (labeling) von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!

Entwurfsmuster in der Softwareentwicklung und MQL5 (Teil 3): Verhaltensmuster 1
Ein neuer Artikel aus der Reihe der Artikel über Entwurfmuster. Wir werden einen Blick auf einen seiner Typen werfen, nämlich den Verhaltensmuster, um zu verstehen, wie wir Kommunikationsmethoden zwischen erstellten Objekten effektiv aufbauen können. Durch die Vervollständigung dieser Verhaltensmuster werden wir in der Lage sein zu verstehen, wie wir eine wiederverwendbare, erweiterbare und getestete Software erstellen und aufbauen können.
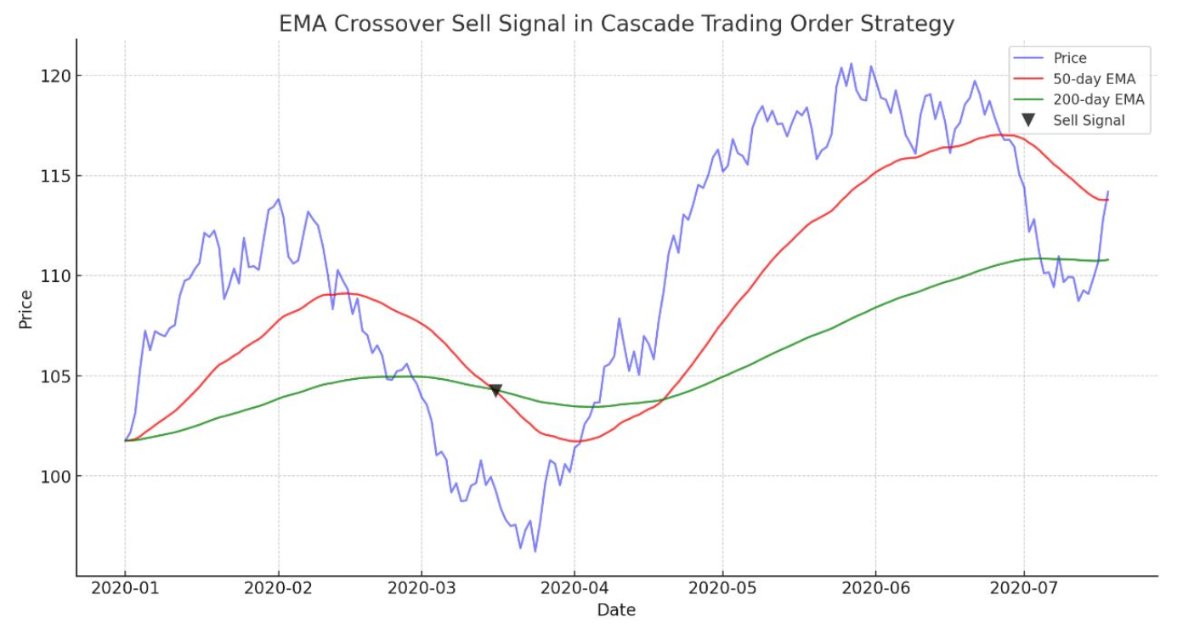
Handelsstrategie kaskadierender Aufträge basierend auf EMA Crossovers für MetaTrader 5
Der Artikel demonstriert einen automatisierten Algorithmus, der auf dem Kreuzen von EMAs für MetaTrader 5 basiert. Detaillierte Informationen zu allen Aspekten der Demonstration eines Expert Advisors in MQL5 und dem Testen in MetaTrader 5 - von der Analyse des Preisbereichsverhaltens bis zum Risikomanagement.

Erfahren Sie, wie Sie ein Handelssystem anhand des Relative Vigor Index entwickeln können
Ein neuer Artikel in unserer Serie darüber, wie man ein Handelssystem anhand eines beliebten technischen Indikators entwickelt. In diesem Artikel werden wir lernen, wie man das mit Hilfe des Relativen Vigot-Index-Indikators tun kann.
DoEasy. Steuerung (Teil 29): Das Hilfssteuerelement der ScrollBar
In diesem Artikel werde ich mit der Entwicklung des ScrollBar-Hilfssteuerelements und seiner abgeleiteten Objekte beginnen — vertikale und horizontale Bildlaufleisten. Eine Bildlaufleiste wird verwendet, um den Inhalt des Formulars zu verschieben, wenn er über den Container hinausgeht. Die Bildlaufleisten befinden sich in der Regel am unteren und rechten Rand des Formulars. Die horizontale am unteren Rand blättert den Inhalt nach links und rechts, während die vertikale nach oben und unten blättert.

Messen der Information von Indikatoren
Maschinelles Lernen hat sich zu einer beliebten Methode für die Strategieentwicklung entwickelt. Während die Maximierung der Rentabilität und der Vorhersagegenauigkeit stärker in den Vordergrund gerückt wurde, wurde der Bedeutung der Verarbeitung der Daten, die zur Erstellung von Vorhersagemodellen verwendet werden, nicht viel Aufmerksamkeit geschenkt. In diesem Artikel befassen wir uns mit der Verwendung des Konzepts der Entropie zur Bewertung der Eignung von Indikatoren für die Erstellung von Prognosemodellen, wie sie in dem Buch Testing and Tuning Market Trading Systems von Timothy Masters dokumentiert sind.

Lernen Sie, wie man ein Handelssystem mit Bill Williams' MFI entwickelt
Dies ist ein neuer Artikel in der Serie, in der wir lernen, wie man ein Handelssystem auf der Grundlage beliebter technischer Indikatoren entwickelt. Dieses Mal werden wir den Market Facilitation Index von Bill Williams (BW MFI) besprechen.

Verschaffen Sie sich einen Vorteil auf jedem Markt (Teil II): Vorhersage technischer Indikatoren
Wussten Sie, dass die Vorhersage bestimmter technischer Indikatoren genauer ist als die Vorhersage des zugrunde liegenden Preises eines gehandelten Symbols? Lernen Sie mit uns, wie Sie diese Erkenntnisse für bessere Handelsstrategien nutzen können.

Tipps von einem professionellen Programmierer (Teil III): Protokollierung. Anbindung an das Seq-Log-Sammel- und Analysesystem
Implementierung der Klasse Logger zur Vereinheitlichung und Strukturierung von Meldungen, die in das Expertenprotokoll ausgegeben werden. Anschluss an das Seq Logsammel- und Analysesystem. Online-Überwachung der Log-Meldungen.

Algorithmen zur Optimierung mit Populationen: Mikro-Künstliches Immunsystem (Mikro-AIS)
Der Artikel befasst sich mit einer Optimierungsmethode, die auf den Prinzipien des körpereigenen Immunsystems basiert - Mikro-Künstliches Immunsystem (Micro Artificial Immune System, Micro-AIS) - eine Modifikation von AIS. Micro-AIS verwendet ein einfacheres Modell des Immunsystems und einfache Informationsverarbeitungsprozesse des Immunsystems. In dem Artikel werden auch die Vor- und Nachteile von Mikro-AIS im Vergleich zu herkömmlichen AIS erörtert.

DoEasy. Steuerung (Teil 28): Balkenstile im ProgressBar-Steuerelement
In diesem Artikel werde ich Anzeigestile und Beschreibungstext für die Fortschrittsleiste des Steuerelements der ProgressBar entwickeln.

Neuronale Netze leicht gemacht (Teil 36): Relationales Verstärkungslernen
In den Verstärkungslernmodellen, die wir im vorherigen Artikel besprochen haben, haben wir verschiedene Varianten von Faltungsnetzwerken verwendet, die in der Lage sind, verschiedene Objekte in den Originaldaten zu identifizieren. Der Hauptvorteil von Faltungsnetzen ist die Fähigkeit, Objekte unabhängig von ihrer Position zu erkennen. Gleichzeitig sind Faltungsnetzwerke nicht immer leistungsfähig, wenn es zu verschiedenen Verformungen von Objekten und Rauschen kommt. Dies sind die Probleme, die das relationale Modell lösen kann.

Algorithmen zur Optimierung mit Populationen Optimierung gemäß einer bakteriellen Nahrungssuche (BFO)
Die Strategie der Nahrungssuche des Bakteriums E. coli inspirierte die Wissenschaftler zur Entwicklung des BFO-Optimierungsalgorithmus. Der Algorithmus enthält originelle Ideen und vielversprechende Optimierungsansätze und ist es wert, weiter untersucht zu werden.

Algorithmen zur Optimierung mit Populationen: Stochastische Diffusionssuche (SDS)
Der Artikel behandelt die stochastische Diffusionssuche (SDS), einen sehr leistungsfähigen und effizienten Optimierungsalgorithmus, der auf den Prinzipien des Random Walk basiert. Der Algorithmus ermöglicht es, optimale Lösungen in komplexen mehrdimensionalen Räumen zu finden, wobei er sich durch eine hohe Konvergenzgeschwindigkeit und die Fähigkeit auszeichnet, lokale Extrema zu vermeiden.

Integrieren Sie Ihr eigenes LLM in Ihren EA (Teil 3): Training Ihres eigenen LLM mit CPU
Angesichts der rasanten Entwicklung der künstlichen Intelligenz sind Sprachmodelle (language models, LLMs) heute ein wichtiger Bestandteil der künstlichen Intelligenz, sodass wir darüber nachdenken sollten, wie wir leistungsstarke LLMs in unseren algorithmischen Handel integrieren können. Für die meisten Menschen ist es schwierig, diese leistungsstarken Modelle auf ihre Bedürfnisse abzustimmen, sie lokal einzusetzen und sie dann auf den algorithmischen Handel anzuwenden. In dieser Artikelserie werden wir Schritt für Schritt vorgehen, um dieses Ziel zu erreichen.

Klassische Strategien neu interpretieren (Teil II): Bollinger-Bänder Ausbrüche
Dieser Artikel untersucht eine Handelsstrategie, die die lineare Diskriminanzanalyse (LDA) mit Bollinger-Bändern integriert und kategorische Zonenvorhersagen für strategische Markteinstiegssignale nutzt.

Entwicklung eines Replay-Systems — Marktsimulation (Teil 06): Erste Verbesserungen (I)
In diesem Artikel werden wir mit der Stabilisierung des gesamten Systems beginnen, ohne die wir möglicherweise nicht in der Lage sind, mit den nächsten Schritten fortzufahren.

Wie man MetaTrader 5 mit PostgreSQL verbindet
Dieser Artikel beschreibt vier Methoden zur Verbindung von MQL5-Code mit einer Postgres-Datenbank und bietet eine Schritt-für-Schritt-Anleitung zum Einrichten einer Entwicklungsumgebung für eine dieser Methoden, eine REST-API, unter Verwendung des Windows Subsystem For Linux (WSL). Eine Demo-Anwendung für die API wird zusammen mit dem entsprechenden MQL5-Code zum Einfügen von Daten und Abfragen der entsprechenden Tabellen sowie einem Demo-Expert Advisor zum Abrufen dieser Daten bereitgestellt.

Neuronale Netze leicht gemacht (Teil 60): Online Decision Transformer (ODT)
Die letzten beiden Artikel waren der Decision-Transformer-Methode gewidmet, die Handlungssequenzen im Rahmen eines autoregressiven Modells der gewünschten Belohnungen modelliert. In diesem Artikel werden wir uns einen weiteren Optimierungsalgorithmus für diese Methode ansehen.

DoEasy. Dienst-Funktionen (Teil 1): Preismuster
In diesem Artikel werden wir mit der Entwicklung von Methoden zur Suche nach Preismustern anhand von Zeitreihendaten beginnen. Ein Muster hat einen bestimmten Satz von Parametern, die für alle Arten von Mustern gelten. Alle Daten dieser Art werden in der Objektklasse des abstrakten Basismusters konzentriert. In diesem Artikel werden wir eine abstrakte Musterklasse und eine Pin Bar-Musterklasse erstellen.

Entwicklung eines Replay System (Teil 28): Expert Advisor Projekt — Die Klasse C_Mouse (II)
Als man begann, die ersten rechenfähigen Systeme zu entwickeln, war für alles die Mitwirkung von Ingenieuren erforderlich, die das Projekt sehr gut kennen mussten. Wir sprechen von den Anfängen der Computertechnologie, einer Zeit, in der es noch nicht einmal Terminals zum Programmieren gab. Im Laufe der Entwicklung, als immer mehr Menschen daran interessiert waren, etwas zu erschaffen, entstanden neue Ideen und Wege der Programmierung, die das frühere Wechseln der Steckverbindungen ersetzten. Zu diesem Zeitpunkt erschienen die ersten Terminals.

Implementierung des Janus-Faktors in MQL5
Gary Anderson entwickelte eine Marktanalysemethode, die auf einer Theorie beruht, die er Janus-Faktor nannte. Die Theorie beschreibt eine Reihe von Indikatoren, mit denen sich Trends aufzeigen und Marktrisiken bewerten lassen. In diesem Artikel werden wir diese Werkzeuge in mql5 implementieren.
MQL5-Assistent-Techniken, die Sie kennen sollten (Teil 26): Gleitende Durchschnitte und der Hurst-Exponent
Der Hurst-Exponent ist ein Maß dafür, wie stark eine Zeitreihe auf lange Sicht autokorreliert. Es wird davon ausgegangen, dass sie die langfristigen Eigenschaften einer Zeitreihe erfasst und daher in der Zeitreihenanalyse auch außerhalb von wirtschaftlichen/finanziellen Zeitreihen eine gewisse Bedeutung hat. Wir konzentrieren uns jedoch auf den potenziellen Nutzen für Händler, indem wir untersuchen, wie diese Metrik mit gleitenden Durchschnitten gepaart werden kann, um ein potenziell robustes Signal zu bilden.

Grafiken in der Bibliothek DoEasy (Teil 94): Bewegen und Löschen zusammengesetzter grafischer Objekte
In diesem Artikel werde ich mit der Entwicklung verschiedener Ereignisse für zusammengesetzte grafische Objekte beginnen. Teilweise werden wir auch das Verschieben und Löschen eines zusammengesetzten grafischen Objekts betrachten. In der Tat werde ich hier eine Feinabstimmung der Dinge vornehmen, die ich im vorherigen Artikel implementiert habe.

Entwicklung eines Replay-Systems — Marktsimulation (Teil 02): Erste Versuche (II)
Diesmal wollen wir einen anderen Ansatz wählen, um das 1-Minuten-Ziel zu erreichen. Diese Aufgabe ist jedoch nicht so einfach, wie man vielleicht denkt.

Integration von ML-Modellen mit dem Strategy Tester (Schlussfolgerung): Implementierung eines Regressionsmodells für die Preisvorhersage
Dieser Artikel beschreibt die Implementierung eines Regressionsmodells auf der Grundlage eines Entscheidungsbaums. Das Modell soll die Preise von Finanzanlagen vorhersagen. Wir haben die Daten bereits aufbereitet, das Modell trainiert und evaluiert, sowie angepasst und optimiert. Es ist jedoch wichtig zu beachten, dass dieses Modell nur für Studienzwecke gedacht ist und nicht im realen Handel eingesetzt werden sollte.

Entwicklung eines Replay-Systems — Marktsimulation (Teil 09): Nutzerdefinierte Ereignisse
Hier sehen wir, wie nutzerdefinierte Ereignisse ausgelöst werden und wie der Indikator den Status des Wiedergabe-/Simulationsdienstes meldet.

Neuronale Netze leicht gemacht (Teil 44): Erlernen von Fertigkeiten mit Blick auf die Dynamik
Im vorangegangenen Artikel haben wir die DIAYN-Methode vorgestellt, die einen Algorithmus zum Erlernen einer Vielzahl von Fertigkeiten (skills) bietet. Die erworbenen Fertigkeiten können für verschiedene Aufgaben genutzt werden. Aber solche Fertigkeiten können ziemlich unberechenbar sein, was ihre Anwendung schwierig machen kann. In diesem Artikel wird ein Algorithmus zum Erlernen vorhersehbarer Fertigkeiten vorgestellt.

Dekodierung von Intraday-Handelsstrategien des Opening Range Breakout
Die Strategien des Opening Range Breakout (ORB) basieren auf der Idee, dass die erste Handelsspanne, die sich kurz nach der Markteröffnung bildet, wichtige Preisniveaus widerspiegelt, bei denen sich Käufer und Verkäufer auf einen Wert einigen. Durch die Identifizierung von Ausbrüchen über oder unter einer bestimmten Spanne können Händler von der Dynamik profitieren, die oft folgt, wenn die Marktrichtung klarer wird. In diesem Artikel werden wir drei ORB-Strategien untersuchen, die von der Concretum Group übernommen wurden.

Algorithmen zur Optimierung mit Populationen: Harmonie-Suche (HS)
In diesem Artikel werde ich den leistungsstärksten Optimierungsalgorithmus untersuchen und testen - die Harmonie-Suche (HS), inspiriert durch den Prozess der Suche nach der perfekten Klangharmonie. Welcher Algorithmus ist nun der führende in unserer Bewertung?
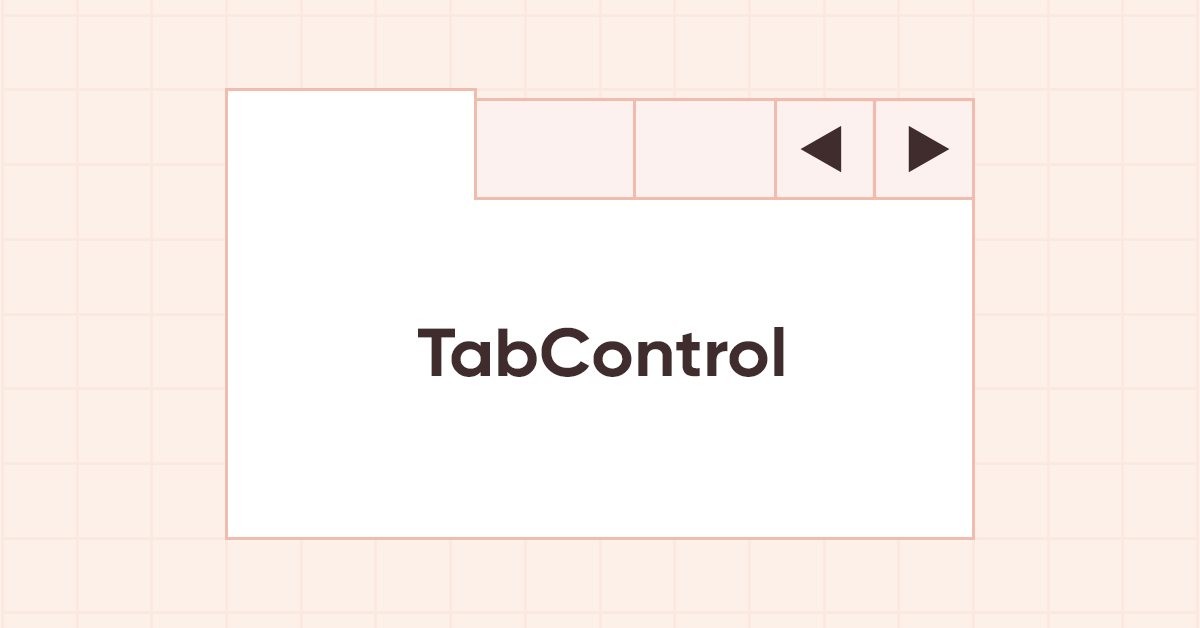
DoEasy. Steuerung (Teil 18): Funktionsweise für scrollende Registerkarten in TabControl
In diesem Artikel werde ich die Schaltflächen der Kopfzeilen-Scroll-Steuerung im TabControl WinForms-Objekt platzieren, für den Fall, dass die Kopfzeile nicht in die Größe des Steuerelements passt. Außerdem werde ich die Verschiebung der Kopfleiste beim Klicken auf die abgeschnittene Registerkartenüberschrift implementieren.

Entwicklung eines Replay System (Teil 32): Auftragssystem (I)
Von allen Dingen, die wir bisher entwickelt haben, ist dieses System, wie Sie wahrscheinlich bemerken und letztendlich zustimmen werden, das komplexeste. Nun müssen wir etwas sehr Einfaches tun: unser System soll den Betrieb eines Handelsservers simulieren. Die Notwendigkeit, die Funktionsweise des Handelsservers genau zu implementieren, scheint eine Selbstverständlichkeit zu sein. Zumindest in Worten. Aber wir müssen dies so tun, dass alles nahtlos und transparent für den Nutzer des Wiedergabe-/Simulationssystems ist.

Neuronale Netze sind einfach (Teil 59): Dichotomy of Control (DoC)
Im vorigen Artikel haben wir uns mit dem Decision Transformer vertraut gemacht. Das komplexe stochastische Umfeld des Devisenmarktes erlaubte es uns jedoch nicht, das Potenzial der vorgestellten Methode voll auszuschöpfen. In diesem Artikel werde ich einen Algorithmus vorstellen, der die Leistung von Algorithmen in stochastischen Umgebungen verbessern soll.

Entwurfsmuster in der Softwareentwicklung und MQL5 (Teil 2): Strukturelle Muster
In diesem Artikel werden wir unsere Artikel über Entwurfsmuster fortsetzen, nachdem wir gelernt haben, wie wichtig dieses Thema für uns als Entwickler ist, um erweiterbare, zuverlässige Anwendungen nicht nur mit der Programmiersprache MQL5, sondern auch mit anderen zu entwickeln. Wir werden eine andere Art von Entwurfsmustern kennenlernen, nämlich die strukturellen, um zu lernen, wie man Systeme entwirft, indem man das, was wir als Klassen haben, zur Bildung größerer Strukturen verwendet.

Datenwissenschaft und maschinelles Lernen (Teil 19): Überladen Sie Ihre AI-Modelle mit AdaBoost
AdaBoost, ein leistungsstarker Boosting-Algorithmus, der die Leistung Ihrer KI-Modelle steigert. AdaBoost, die Abkürzung für Adaptive Boosting, ist ein ausgeklügeltes Ensemble-Lernverfahren, das schwache Lerner nahtlos integriert und ihre kollektive Vorhersagestärke erhöht.

Verwendung von Optimierungsalgorithmen zur Konfiguration von EA-Parametern im laufenden Betrieb
Der Artikel behandelt die praktischen Aspekte der Verwendung von Optimierungsalgorithmen, um die besten EA-Parameter im laufenden Betrieb zu finden, sowie die Virtualisierung von Handelsoperationen und EA-Logik. Der Artikel kann als Anleitung für die Implementierung von Optimierungsalgorithmen in einen EA verwendet werden.