
Neuronale Netze leicht gemacht (Teil 44): Erlernen von Fertigkeiten mit Blick auf die Dynamik

Einführung
Bei der Lösung von Vorhersageproblemen in einem komplexen stochastischen Umfeld ist es ziemlich schwierig und oft unmöglich, ein Modell zu trainieren, das außerhalb der Trainingsmenge akzeptable Ergebnisse liefert. Gleichzeitig verbessert die Aufteilung des Problems in kleinere Teilaufgaben die Leistung des Gesamtmodells erheblich. In früheren Artikeln haben wir uns bereits mit der Konstruktion hierarchischer Modelle vertraut gemacht. Ihre Architektur ermöglicht es, die Lösung eines Problems in mehrere Teilaufgaben zu unterteilen. Jede Teilaufgabe wird mit einem eigenen, einfacheren Modell gelöst. Hier stellt sich die Frage nach dem richtigen Training von Fertigkeiten, die sich leicht am Verhalten des Modells in einem bestimmten Zustand erkennen lassen.
Im vorigen Artikel haben wir die DIAYN-Methode kennengelernt, mit der man trennbare Fertigkeiten trainieren kann. Dadurch ist es möglich, ein Modell zu erstellen, das das Verhalten des Agenten in Abhängigkeit vom aktuellen Zustand ändern kann. Wie Sie sich vielleicht erinnern, bietet der DIAYN-Algorithmus Belohnungen für unvorhersehbares Verhalten. Auf diese Weise können wir so viele verschiedene Verhaltensweisen wie möglich unterrichten. Aber es gibt auch eine andere Seite der Medaille. Solche Fertigkeiten lassen sich nur schwer vorhersagen. Dies erschwert die Planung und Verwaltung des Agenten.
In diesem Paradigma stellt sich die Frage nach dem Erlernen von Fertigkeiten, deren Verhalten leicht vorhersehbar wäre. Zugleich sind wir nicht bereit, die Vielfalt ihres Verhaltens zu opfern. Ein ähnliches Problem wird von den Autoren der 2020 vorgestellten Methode Dynamics-Aware Discovery of Skills (DADS) gelöst. Im Gegensatz zu DIAYN zielt die DADS-Methode darauf ab, Fertigkeiten zu vermitteln, die nicht nur vielfältig im Verhalten, sondern auch vorhersehbar sind.
1. Überblick über die DADS-Architektur und grundlegende Schritte
Durch die Untersuchung mehrerer individueller Verhaltensweisen und entsprechender Umweltveränderungen kann die modellprädiktive Steuerung für die Planung im Verhaltensraum statt im Aktionsraum eingesetzt werden. In diesem Zusammenhang stellt sich vor allem die Frage, wie wir solche Verhaltensweisen erreichen können, da sie zufällig und unvorhersehbar sein können. Die DADS-Methode (Dynamics-Aware Discovery of Skills) schlägt ein unüberwachtes Verstärkungslernsystem zum Erlernen von Low-Level-Fertigkeiten vor, mit dem ausdrücklichen Ziel, die modellbasierte Steuerung zu erleichtern.
Die mit DADS erlernten Fertigkeiten sind direkt auf Vorhersagbarkeit hin optimiert und bieten einen besseren Einblick, aus dem Vorhersagemodelle gelernt werden können. Ein wesentliches Merkmal von Fertigkeiten ist, dass sie vollständig durch autonomes Erkunden erworben werden. Das bedeutet, dass das Toolkit und sein Vorhersagemodell lernt, bevor die Aufgabe und die Belohnungsfunktion entworfen werden. In einer ausreichenden Umfang kann die Umwelt in vollem Umfang studiert und Fertigkeiten entwickelt werden, sich in ihr zu verhalten.
Wie bei der DIAYN-Methode verwendet der DADS-Algorithmus zwei Modelle: ein Kompetenzmodell (Agent) und einen Diskriminator (Kompetenzdynamikmodell).
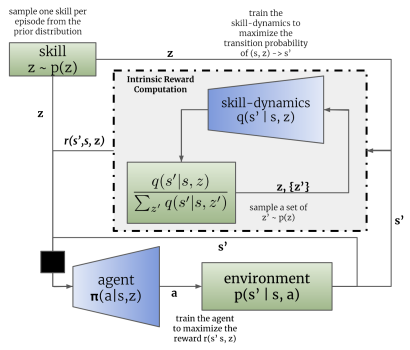
Die Modelle werden sequentiell und iterativ trainiert. Zunächst wird der Diskriminator darauf trainiert, einen zukünftigen Zustand auf der Grundlage des aktuellen Zustands und der verwendeten Fertigkeit vorherzusagen. Zu diesem Zweck werden der aktuelle Zustand und der One-Hot-Skill-Identifikationsvektor in den Input des Agentenmodells eingespeist. Der Agent erzeugt eine Aktion, die in der Umgebung ausgeführt wird. Als Ergebnis der Aktion bewegt sich der Agent in einen neuen Zustand der Umgebung.
Der Diskriminator wiederum versucht, auf der Grundlage der gleichen Ausgangsdaten einen neuen Zustand der Umgebung vorherzusagen. In diesem Fall ähnelt die Arbeit des Diskriminators der Arbeit des zuvor besprochenen Auto-Encoders. In diesem Fall stellt der Decoder jedoch nicht die ursprünglichen Daten aus dem latenten Zustand wieder her, sondern sagt den nächsten Zustand voraus. Genauso wie wir die Auto-Encoder trainiert haben, trainieren wir den Diskriminator mittels Gradientenabstieg.
Wie Sie sehen können, liegt hier der erste Unterschied zwischen den Algorithmen DIAYN und DADS. In DIAYN haben wir die Fertigkeit, die uns zu diesem Zustand gebracht hat, anhand des neuen Zustands bestimmt. Der DADS-Diskriminator hat die entgegengesetzte Funktion. Auf der Grundlage der anfänglichen Daten und der bekannten Fertigkeiten sagt er den späteren Zustand der Umgebung voraus.
Dabei ist zu beachten, dass es sich um einen iterativen Prozess handelt. Daher versuchen wir nicht, sofort die maximale Wahrscheinlichkeit zu erreichen. Gleichzeitig benötigen wir zumindest eine erste Annäherung, um den Agenten zu trainieren.
Nach der ersten Reihe von Diskriminator-Trainingsiterationen gehen wir zum Training des Agenten (Kompetenzmodell) über. Nehmen wir einmal an, dass verschiedene Pakete von Quelldaten verwendet werden, um den Diskriminator und den Agenten zu trainieren. Dies bedeutet jedoch nicht, dass es notwendig ist, separate Trainingsmuster zu erstellen. Wir teilen dieselbe Erfahrung mit dem Playback-Puffer. Nur bei jeder Iteration werden aus diesem Puffer nach dem Zufallsprinzip 2 separate Stapel von Trainingsdaten erzeugt.
Ähnlich wie bei der DIAYN-Methode wird das Fertigkeitsmodell mit Methoden des Reinforcement Learning auf der Grundlage der vom Diskriminator erzeugten Belohnung trainiert. Der Unterschied liegt, wie immer, im Detail. DADS verwendet eine andere mathematische Gleichung, um Belohnungen zu generieren. Ich werde jetzt nicht auf alle mathematischen Berechnungen und Begründungen für diesen Ansatz eingehen. Sie finden sie im Original in diesem Artikel. Ich werde nur die endgültige Belohnungsgleichung betrachten.
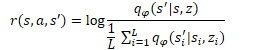
In der angegebenen Gleichung ist q(s'|s,z) die Ausgabe des Diskriminators für den Ausgangszustand der Person s und der Fertigkeit z. L bestimmt die Anzahl der Fertigkeiten. Im Zähler der Belohnungsgleichung sehen wir also den Vorhersagewert für die analysierte Fertigkeit. Der Nenner enthält den durchschnittlichen vorhergesagten Zustand für alle möglichen Fertigkeiten.
Die Verwendung einer solchen Belohnungsfunktion ermöglicht es uns, das oben gestellte Problem zu lösen. Da wir im Zähler den vorhergesagten Zustand für die aktuelle Fertigkeit verwenden, belohnen wir die Agentenaktion, die zum Erreichen des vorhergesagten Zustands führt. Dadurch wird das Verhalten der Fertigkeiten vorhersehbar.
Gleichzeitig ermöglicht die Verwendung des durchschnittlichen Zustands aller möglichen Fertigkeiten im Nenner eine stärkere Belohnung für das Verhalten der Fertigkeiten, das so weit wie möglich vom statistischen Durchschnitt abweicht.
Auf diese Weise schafft die DADS-Methode ein Gleichgewicht zwischen Vorhersehbarkeit und Vielfalt der Fertigkeiten. Auf diese Weise können Fertigkeiten vermittelt werden, die ein strukturiertes und vorhersehbares Verhalten erfordern, während gleichzeitig die Möglichkeit erhalten bleibt, die Umwelt zu erkunden.
Denken Sie daran, dass das Verhalten der Rückmeldung des Diskriminators und das Training des Fertigkeitsmodells zu einer Änderung des Verhaltens des Agenten führt. Infolgedessen unterscheidet sich sein Verhalten von den Beispielen, die im Erfahrungswiedergabepuffer gespeichert sind. Um ein optimales Ergebnis zu erzielen, verwenden wir daher einen iterativen Prozess mit sequentiellem Training des Diskriminators und des Agenten. Während des Prozesses wird das Modelltraining mehrere Male wiederholt. Darüber hinaus schlagen die Autoren der Methode vor, den Wichtigkeitskoeffizienten zu verwenden, der durch das Verhältnis der Wahrscheinlichkeit, eine Handlung mit der aktuellen Agentenpolitik auszuführen, zur Wahrscheinlichkeit, diese Handlung im Erfahrungswiedergabepuffer auszuführen, bestimmt wird. Dadurch kann dem vom Agenten festgelegten Verhalten mehr Aufmerksamkeit gewidmet werden. Gleichzeitig wird der Einfluss zufälliger Aktionen eingeebnet.
Es sei darauf hingewiesen, dass die DADS-Methode ursprünglich für das Training von Fertigkeiten und die Erstellung eines Modells der Umgebung vorgeschlagen wurde. Wie Sie sehen, können wir durch das Training einer vorhersehbaren Fertigkeit und eines Dynamikmodells, das es uns ermöglicht, einen neuen Zustand der Umgebung mit ausreichender Wahrscheinlichkeit vorherzusagen, mehrere Schritte im Voraus planen. Gleichzeitig können wir im Planungsprozess von spezifischen Maßnahmen zu einem allgemeineren Konzept von Fertigkeiten übergehen. Konkrete Maßnahmen werden vom Agenten in Übereinstimmung mit der geplanten Fertigkeit festgelegt.
In diesem Stadium beschloss ich jedoch, nicht zur langfristigen Planung überzugehen, sondern den Planer so zu schulen, dass er die Fertigkeiten für jeden einzelnen Schritt bestimmt, wie im vorherigen Artikel.
2. Implementierung mittels MQL5
Kommen wir nun zur praktischen Umsetzung des Algorithmus. Bevor wir uns direkt der Implementierung des Algorithmus zuwenden, werden wir uns für die Architektur der Modelle entscheiden.
Wie DIAYN werden wir in unserer Implementierung 3 Modelle verwenden. Dabei handelt es sich um den Agenten (Kompetenzmodell), den Diskriminator (dynamisches Modell) und den Scheduler (Planer).
Der Algorithmus sieht vor, dass der Agent die auszuführende Aktion auf der Grundlage des aktuellen Zustands und der ausgewählten Fertigkeit bestimmt. Daher sollte die Größe der Quelldatenschicht ausreichen, um einen Vektor, der den aktuellen Zustand beschreibt, und einen One-Hot-Vektor, der die ausgewählte Fertigkeit identifiziert, festzulegen.
Am Ausgang des Agenten erhalten wir einen Vektor der Wahrscheinlichkeitsverteilung des Raums der möglichen Aktionen. Wie Sie sehen können, sind die Ausgangsdaten, die Funktionalität und das Ergebnis des Agenten den entsprechenden Merkmalen des Agenten der DIAYN-Methode völlig ähnlich. In dieser Implementierung lassen wir die Agentenarchitektur unverändert. Dies wird es uns ermöglichen, die Arbeit der beiden betrachteten Methoden zur Ausbildung von Fertigkeiten in der Praxis zu vergleichen. Dies bedeutet jedoch nicht, dass keine andere Modellarchitektur verwendet werden kann.
Ich möchte Sie daran erinnern, dass wir in der Agentenarchitektur eine Batch-Normalisierungsschicht verwendet haben, um die Quelldaten in eine vergleichbare Form zu bringen.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die normalisierten Daten werden von einem Block aus 2 Faltungsschichten und Unterabtastungen verarbeitet, wodurch es möglich ist, individuelle Muster und Trends in den Quelldaten zu erkennen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die verarbeiteten Daten nach den Faltungsschichten werden an den Entscheidungsblock weitergeleitet, der voll verknüpfte Schichten und ein voll parametrisiertes Quantil-FQF-Modell enthält.
Die Verwendung des FQF als Ausgabe des Entscheidungsblocks ermöglicht es uns, genauere Vorhersagen über die Belohnungen nach der Durchführung von Aktionen zu erhalten, die nicht nur deren Durchschnittswert, sondern auch die Wahrscheinlichkeitsverteilung unter Berücksichtigung der Stochastizität der Umgebung berücksichtigen.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wie bereits erwähnt, haben wir bei dieser Umsetzung kein Umweltmodell erstellt, um Prognosen mehrere Schritte im Voraus zu erstellen. Wie zuvor werden wir in jedem Schritt die verwendete Fertigkeit festlegen. Daher haben wir auch die Architektur und die Ansätze zum Training des Schedulers unverändert gelassen. Hier verwenden wir eine Batch-Normalisierungsschicht, um die Rohdaten in eine vergleichbare Form zu bringen. Der Entscheidungsblock besteht aus vollständig verbundenen Schichten und einem FQF-Modell. Seine Ergebnisse werden mit Hilfe der SoftMax-Schicht in den Bereich der Wahrscheinlichkeitsverteilung übertragen.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Wir haben jedoch Änderungen an der Architektur des Diskriminatormodells vorgenommen. Ich möchte Sie daran erinnern, dass der DADS-Algorithmus das dynamische Modell als Unterscheidungsmerkmal verwendet. Nach dem betrachteten Algorithmus sollte er einen neuen Zustand der Umgebung auf der Grundlage des aktuellen Zustands und der ausgewählten Fertigkeit vorhersagen. Außerdem wird das Dynamikmodell in der DADS-Methode zur Vorhersage zukünftiger Zustände verwendet, wenn Pläne mehrere Schritte im Voraus erstellt werden. Aber, wie bereits erwähnt, werden wir keine langfristigen Pläne machen. Das bedeutet, dass wir bei der Vorhersage aller Indikatoren für den künftigen Zustand der Umwelt leicht abweichen können. Wie Sie wissen, besteht unsere Beschreibung des Zustands der Umwelt aus 2 großen Blöcken:
- historische Daten der Preisbewegung und Indikatoren der analysierten Indikatoren
- Indikatoren für den aktuellen Zustand des Kontos.
Der Einfluss eines einzelnen Händlers auf den Zustand des Finanzmarktes ist so unbedeutend, dass er vernachlässigt werden kann. Daher haben die Aktionen unserer Agenten keinen Einfluss auf die historischen Daten. Das bedeutet, dass wir sie bei der Ausbildung unseres Agenten von der Bildung interner Belohnungen ausschließen können. Da wir keine weitreichenden Pläne machen werden, macht eine Prognose dieser Indikatoren keinen Sinn. Um interne Belohnungen zu bilden, reicht es also aus, die Indikatoren für den zukünftigen Zustand des Kontos vorherzusagen.
Ein weiterer Punkt sollte beachtet werden. Sehen Sie sich die Gleichung für die Bildung der internen Belohnung des Agenten an. Neben dem Prognosezustand für die analysierte Fertigkeit wird auch der durchschnittliche Prognosezustand für alle möglichen Fertigkeiten verwendet. Das bedeutet, dass wir, um eine Belohnung zu bestimmen, zukünftige Zustände für alle Fertigkeiten vorhersagen müssen. Um den Prozess der Ausbildung von Modellen zu beschleunigen, wurde beschlossen, ein Mehrkopfmodell zu erstellen. Das Modell liefert Vorhersagen für alle möglichen Fertigkeiten auf der Grundlage eines einzigen Ausgangswertes.
Die Quelldatenschicht des Discriminator-Modells ist also vergleichbar mit einer ähnlichen Schicht des Scheduler-Modells und sollte ausreichen, um eine Beschreibung des Systemzustands ohne Berücksichtigung der gewählten Fertigkeit zu erfassen.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; }
Die empfangenen Ausgangsdaten werden in der Batch-Normalisierungsschicht einer ersten Verarbeitung unterzogen und an den Entscheidungsblock weitergeleitet, der aus einem vollständig verbundenen Perzeptron besteht.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; }
Für die Ausgabe des Modells wird ebenfalls eine vollständig verbundene Schicht verwendet. Seine Größe entspricht dem Produkt aus der Anzahl der zu vermittelnden Fertigkeiten und der Anzahl der Elemente, die einen Zustand des Systems beschreiben. In diesem Fall geben wir die Anzahl der Elemente der Kontostandbeschreibung an.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills*AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; }
Es ist erwähnenswert, dass wir uns im vorherigen Artikel zwar für die Verwendung relativer Werte von Indikatoren zur Beschreibung des Kontostandes entschieden haben, diese Werte jedoch nicht normalisiert zu sein scheinen. Wir können bei der Vorhersage keine einzige Aktivierungsfunktion verwenden. Daher wird für die Ausgabe des Diskriminatormodells eine neuronale Schicht ohne Aktivierungsfunktion verwendet.
Der gesamte Code zur Beschreibung der Architekturen aller verwendeten Modelle ist in der Funktion CreateDescriptions zusammengefasst, die sich in der Bibliotheksdatei „Trajectory.mqh“ befindet. Die Übertragung dieser Funktion von der EA-Datei in die Bibliotheksdatei ermöglicht es uns, eine einzige Modellarchitektur in allen Phasen des Trainings zu verwenden, und macht das manuelle Kopieren der Modellarchitekturbeschreibung zwischen EAs überflüssig.
Beim Training der Modelle und beim Testen der erzielten Ergebnisse werden wir 3 EAs verwenden, die dem Training der Modelle mit der DIAYN-Methode ähneln. Die primäre Datenerfassung EA für Trainingsmodelle „Research.mq5“ wurde vollständig und nahezu unverändert übernommen. Die Änderungen betrafen nur den Namen der Datei für die Aufzeichnung von Modellen und die oben beschriebenen architektonischen Lösungen. Den vollständigen Code des Expert Advisors finden Sie im Anhang.
Die wichtigsten Änderungen für die Implementierung des DADS-Algorithmus wurden an der Modell-Trainings-EA „Study.mq5“ vorgenommen. Dies ist zunächst die Überwachung der Übereinstimmung der Modellarchitektur mit den zuvor deklarierten Konstanten, die in der OnInit-Methode durchgeführt wird. Hier haben wir die Kontrollen an die veränderten Modellarchitekturen angepasst.
Discriminator.getResults(DiscriminatorResult); if(DiscriminatorResult.Size() != NSkills * AccountDescr) { PrintFormat("The scope of the discriminator does not match the skills count (%d <> %d)", NSkills * AccountDescr, Result.Total()); return INIT_FAILED; } Scheduler.getResults(SchedulerResult); Scheduler.SetUpdateTarget(MathMax(Iterations / 100, 500000 / SchedulerBatch)); if(SchedulerResult.Size() != NSkills) { PrintFormat("The scope of the scheduler does not match the skills count (%d <> %d)", NSkills, Result.Total()); return INIT_FAILED; } Actor.getResults(ActorResult); Actor.SetUpdateTarget(MathMax(Iterations / 100, 500000 / AgentBatch * NSkills)); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
An der Trainingsmethode für das Modell Train wurden wesentliche Änderungen vorgenommen. Zunächst werden wir uns die 2 neuen Hilfsmethoden ansehen. Die erste Methode ist GetNewState. Im Hauptteil dieser Methode werden wir den berechneten Stand der Gleichgewichtsindikatoren auf der Grundlage des vorherigen Kontostands, der geplanten Aktion und der bekannten „zukünftigen“ Kursbewegung bilden.
Beachten Sie, dass die Methode den berechneten Gleichgewichtszustand definiert, nicht den prognostizierten. Hinter dem Wortspiel verbirgt sich eine Menge Bedeutung. Die Vorhersage der Bilanzparameter erfolgt durch das Modell Dynamics (Discriminator). In der aktuellen Methode definieren wir den berechneten Saldozustand basierend auf unserem Wissen über nachfolgende Kursbewegungen aus dem Erfahrungswiedergabepuffer. Die Notwendigkeit einer solchen Berechnung ergibt sich aus der hohen Wahrscheinlichkeit einer Diskrepanz zwischen der Aktion des Agenten aus der Zwischenablage und der vom Agenten unter Berücksichtigung der verwendeten Fertigkeiten und der aktualisierten Verhaltensstrategie generierten Aktion. Die Daten aus dem Erfahrungswiedergabepuffer ermöglichen es uns, den Kontostatus und die offenen Positionen für jede Agentenaktion genau zu berechnen, ohne die Aktion im Strategietester wiederholen zu müssen. Auf diese Weise können wir die Trainingsmenge erheblich erweitern und damit die Qualität des Modelltrainings verbessern. Eine ähnliche Funktion wurde bereits im vorherigen Artikel implementiert. Das Anordnen einer separaten Methode wird durch mehrfache Aufrufe dieser Funktion während des Trainings von Modellen verursacht.
In den Parametern erhält die Methode ein dynamisches Array von Kontobeschreibungsparametern in der Entscheidungsphase, die Aktions-ID und den Wert des Gewinns/Verlusts aus der nachfolgenden Preisbewegung pro 1 Lot einer Kaufposition. Als Ergebnis der Operationen gibt diese Methode einen Vektor von Werten zurück, die den späteren Zustand des Kontos unter Berücksichtigung der angegebenen Aktion beschreiben.
Im Hauptteil der Methode erstellen wir einen Vektor zur Erfassung der Ergebnisse und übertragen die Anfangswerte in Form des Anfangszustands des Kontos in diesen Vektor.
vector<float> GetNewState(float &prev_account[], int action, double prof_1l) { vector<float> result; //--- result.Assign(prev_account);
Anschließend erfolgt eine Verzweigung in Abhängigkeit von der durchgeführten Aktion. Im Falle einer Handelsoperation, bei der eine Position eröffnet oder aufgestockt wird, berechnen wir den neuen Wert der offenen Positionen in der entsprechenden Richtung. Als Nächstes berechnen wir die Veränderung des kumulierten Gewinns/Verlusts für jede Richtung, wobei wir die Größe der offenen Position und die anschließende Kursbewegung berücksichtigen. Der Wert des kumulierten Gewinns/Verlusts auf dem Konto ist gleich der Summe der beiden oben berechneten Indikatoren. Addiert man den daraus resultierenden Wert mit dem Saldenindikator, erhält man das Kapital des Kontos.
switch(action) { case 0: result[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; case 1: result[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break;
Wenn alle offenen Positionen geschlossen sind, addieren wir einfach den Wert des aufgelaufenen Gewinns zum aktuellen Saldo. Wir übertragen den daraus resultierenden Wert in das Kapital und die freie Marge. Setzen Sie die übrigen Parameter auf Null zurück.
case 2: result[0] += result[4]; result[1] = result[0]; result[2] = result[0]; for(int i = 3; i < AccountDescr; i++) result[i] = 0; break;
Die Neuberechnung der Parameter während des Wartens (keine Aktion des Agenten) ähnelt dem Handelsvorgang des Eröffnens einer Position, mit Ausnahme der Änderungen des Volumens der offenen Positionen. Das bedeutet, dass wir nur den kumulierten Gewinn/Verlust und das Kapital für zuvor eröffnete Positionen neu berechnen.
case 3: result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; } //--- return result return result; }
Nachdem wir alle Parameter neu berechnet haben, geben wir den resultierenden Wertevektor an das aufrufende Programm zurück.
Die zweite Methode, die wir hinzufügen werden, soll dazu dienen, die Höhe der internen Belohnung für den Agenten auf der Grundlage der vorhergesagten Werte des Diskriminators, der ausgewählten Fertigkeit und des vorherigen Kontostands zu berechnen.
Man beachte, dass der Agent für eine bestimmte Handlung eine Belohnung erhält. Aber wir geben die vom Agenten gewählte Aktion nicht in den Methodenparametern an. Tatsächlich ist hier eine gewisse Diskrepanz zwischen der Prognose des Agenten und der erhaltenen Belohnung festzustellen. Es besteht nämlich die Möglichkeit, dass die vom Agenten gewählte Handlung nicht zu dem vom Diskriminator vorhergesagten Zustand führt. Im Laufe des Trainings des Agenten und des Diskriminators wird die Wahrscheinlichkeit einer solchen Lücke natürlich abnehmen. Dennoch wird sie bestehen bleiben. Gleichzeitig ist es für uns wichtig, dass die Belohnung der Handlung entspricht, die zu dem vorhergesagten Zustand führt. Andernfalls erhalten wir nicht das vorhergesagte Verhalten der Fertigkeiten. Deshalb bestimmen wir die belohnte Aktion aus 2 aufeinander folgenden Zuständen: dem aktuellen und dem voraussichtlichen für die ausgewählte Fertigkeit.
Die Funktion GetAgentReward erhält also als Parameter die ausgewählte Fertigkeit, den Ergebnisvektor des Vorwärtsdurchlaufs des Diskriminators und ein Array, das den vorherigen Gleichgewichtszustand beschreibt. Als Ergebnis der Funktionsoperation planen wir, einen Vektor mit den Belohnungen der Agenten zu erhalten.
Wir werden einige vorbereitende Arbeiten im Hauptteil der Methode durchführen müssen. Der Ergebnisvektor des Diskriminators für den Vorwärtsdurchlauf enthält Vorhersagezustände für alle möglichen Fertigkeiten. Um die Belohnung zu ermitteln, müssen wir die einzelnen Fertigkeiten isolieren und Durchschnittswerte im Zusammenhang mit den einzelnen Parametern berechnen. Matrixoperationen werden uns bei dieser Aufgabe helfen. Zunächst müssen wir den Vektor der Diskriminatorergebnisse in eine Matrix umwandeln.
Es wird eine neue Matrix mit 1 Zeile erstellt, wobei die Anzahl der Spalten der Anzahl der Elemente im Ergebnisvektor des Diskriminators entspricht. Kopieren wir nun die Werte aus dem Vektor in die Matrix. Anschließend wird die Matrix in eine rechteckige Matrix umgewandelt, bei der die Anzahl der Zeilen der Anzahl der Fertigkeiten und die Anzahl der Spalten der Größe des Vektors entspricht, der einen Zustand beschreibt. In diesem Fall ist es sehr wichtig, die Methode „Reshape“ und nicht „Resize“ zu verwenden, da die erste Methode die vorhandenen Werte in eine Matrix neuen Formats umverteilt. Bei der zweiten Variante wird nur die Anzahl der Zeilen und Spalten geändert, ohne die vorhandenen Elemente neu zu verteilen. In diesem Fall gehen einfach alle Daten außer der ersten Fertigkeit verloren. Die hinzugefügten Zeilen werden mit Zufallswerten gefüllt.
vector<float> GetAgentReward(int skill, vector<float> &discriminator, float &prev_account[]) { //--- prepare matrix<float> discriminator_matrix; discriminator_matrix.Init(1, discriminator.Size()); discriminator_matrix.Row(discriminator,0); discriminator_matrix.Reshape(NSkills, AccountDescr); vector<float> forecast = discriminator_matrix.Row(skill);
Jetzt müssen wir nur noch die Werte der entsprechenden Zeile extrahieren, um den prädiktiven Zustandsvektor der gewünschten Fertigkeit zu erhalten.
Als Nächstes müssen wir die Aktion bestimmen, für die der Agent eine Belohnung erhält. Unser wichtigster Parameter für eine Handelsoperation ist eine Positionsveränderung. Ich gebe zu, dass es hier vielleicht viele Konventionen gibt. Ihre Verwendung wird uns jedoch dabei helfen, Maßnahmen zu ermitteln, mit denen wir uns dem prognostizierten Zustand mit einer angemessenen Wahrscheinlichkeit nähern können. Das macht unser Modell überschaubar und berechenbar.
Zunächst wird die Veränderung der Position in jeder Richtung bestimmt. Wenn die Größe der offenen Positionen in beide Richtungen abnimmt, halten wir die Schließung von Positionen für sehr wahrscheinlich. Andernfalls geben wir der größten Positionsveränderung den Vorzug. Wir glauben, dass in dieser Richtung ein neues Handelsgeschäft eröffnet oder eine Ergänzung vorgenommen wurde.
Wenn die Änderungen gleich sind, warten wir einfach ab. Nach der Wahrscheinlichkeitstheorie, die Fließkommazahlen verwendet, ist dieses Ergebnis am unwahrscheinlichsten. Wir wollen also das Modell zu aktivem Handeln anregen.
//--- check action int action = 3; float buy = forecast[5] - prev_account[5]; float sell = forecast[6] - prev_account[6]; if(buy < 0 && sell < 0) action = 2; else if(buy > sell) action = 0; else if(buy < sell) action = 1;
Nachdem wir nun die belohnte Aktion definiert und die Daten für die Berechnungen vorbereitet haben, können wir direkt mit dem Ausfüllen des Belohnungsvektors beginnen.
Zunächst bilden wir einen Vektor von Nullwerten entlang der Dimension des Aktionsraums. Als Nächstes teilen wir den Vektor der vorhergesagten Werte der Fertigkeit, die uns interessiert, durch den Vektor der durchschnittlichen vorhergesagten Werte für alle Fertigkeiten. Aus dem resultierenden Vektor wird der Durchschnittswert gebildet. Wir gehen davon aus, dass die Durchführung dieser Operationen auch einen negativen Wert ergeben kann. Daher nehmen wir seinen absoluten Wert in den Logarithmus auf. Dies steht absolut nicht im Widerspruch zur primären Aufgabe, da wir die Belohnung für die untypischsten Aktionen maximieren wollen, die so weit wie möglich vom Vektor der Durchschnittswerte entfernt sind. Als alternative Lösung, die auch dazu beiträgt, die Division durch Null zu vermeiden, kann ich die Verwendung des euklidischen Abstands zwischen dem Vektor der analysierten Fertigkeit und dem Vektor der Durchschnittswerte vorschlagen. Testen wir die Qualität der Ansätze in der Praxis.
//--- calculate reward vector<float> result = vector<float>::Zeros(NActions); float mean = (forecast / discriminator_matrix.Mean(0)).Mean(); result[action] = MathLog(MathAbs(mean)); //--- return result return result; }
Setzen Sie den resultierenden Belohnungswert in das Vektorelement, das der zuvor definierten Aktion entspricht. Am Ende der Funktionsoperationen geben Sie den resultierenden Reward-Vektor an das aufrufende Programm zurück.
Nach Abschluss der Vorbereitungsarbeiten gehen wir dazu über, unsere Train-Modelle zu trainieren. Hier deklarieren wir zunächst eine Reihe lokaler Variablen und bestimmen die Anzahl der zuvor geladenen Trainingstrajektorien.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action; int skill, shift;
Als Nächstes stellen wir ein System von Zyklen für den Modellbildungsprozess auf. Ich sollte gleich sagen, dass das Modelltraining nach dem DADS-Algorithmus sequentiell und iterativ durchgeführt wird. Wir trainieren zunächst den Diskriminator (Phase 0). Dann trainieren wir den Agenten (Phase 1). Und zu guter Letzt ist da noch der Scheduler (Phase 2). Der gesamte Vorgang wird in mehreren Iterationen wiederholt. Die Anzahl der Iterationen wird in den externen Parametern des EA festgelegt. Darüber hinaus geben wir in den externen Parametern des EA die Größe des Trainingspakets für jede Phase an.
Jetzt werden wir ein System von verschachtelten Schleifen im Körper der Funktion deklarieren. Die externe Schleife bestimmt die Anzahl der Iterationen des Trainingsprozesses. Die verschachtelte Schleife bestimmt die Trainingsphase.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { for(int phase = 0; phase < 3; phase++) {
Die verschachtelte Schleife könnte durch eine Folge von Operationen ersetzt werden. Mit diesem Ansatz war es jedoch möglich, das Kopieren gängiger Operationen, wie das Laden des Ausgangszustands aus dem Wiedergabepuffer vor der direkten Weitergabe der Modelle, zu vermeiden.
Die Operationen jeder Trainingsphase wiederholen sich in der Größe des Trainingspakets, die in den externen Parametern des EA für jede Phase separat angegeben ist. Daher bestimmen wir zunächst die Größe des entsprechenden Trainingspakets. Dann erstellen wir eine weitere verschachtelte Schleife mit der gewünschten Anzahl von Wiederholungen.
int batch = 0; switch(phase) { case 0: batch = DiscriminatorBatch; break; case 1: batch = AgentBatch; break; case 2: batch = SchedulerBatch; break; default: PrintFormat("Incorrect phase %d"); batch = 0; break; } for(int batch_iter = 0; batch_iter < batch; batch_iter++) {
Als Nächstes beginnt der Prozess des direkten Trainings der Modelle. Zunächst müssen wir die Ausgangsdaten vorbereiten. Wir wählen sie nach dem Zufallsprinzip aus dem Erfahrungswiedergabepuffer aus. Hier wird ein Durchgang und ein Zustand aus diesem Durchgang zufällig ausgewählt.
int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Dann laden wir die Daten, die den aktuellen Zustand des Systems beschreiben, in den Datenpuffer.
State.AssignArray(Buffer[tr].States[i].state);
Dann konvertieren wir die Kontodaten in relative Einheiten und fügen einen Puffer hinzu.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
In diesem Stadium können wir einen direkten Durchlauf der Modelle durchführen. Bevor wir jedoch den Ablauf der Operationen in Abhängigkeit von der aktuellen Ausbildungsphase verzweigen, bereiten wir auch die Daten vor, die wir in jeder Phase der Operationen benötigen, um den geschätzten zukünftigen Zustand des Kontos zu berechnen.
bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Nachdem alle allgemeinen Vorgänge abgeschlossen sind, unterteilen wir den Operationsablauf in Abhängigkeit von der aktuellen Phase des Trainings.
Wie bereits erwähnt, beginnt der Lernprozess mit dem Training des Unterscheidungsmodells. Zunächst führen wir auf der Grundlage der zuvor aufbereiteten Quelldaten einen direkten Durchlauf durch das Modell durch und überprüfen die Korrektheit der Operationen.
switch(phase) { case 0: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Am Ausgang des Diskriminators erhalten wir einen Vektor von Vorhersagezuständen für alle untersuchten Fertigkeiten. Daher müssen wir auch Zielzustände für alle Fertigkeiten erzeugen, um Zielwerte vorzubereiten. Um dies zu erreichen, werden wir den Zyklus nach der Anzahl der untersuchten Fertigkeiten anordnen. Dann werden wir einen direkten Durchlauf unseres Agenten für jede einzelne Fertigkeit im Körper des Zyklus durchführen.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Auf der Grundlage der Ergebnisse des Vorwärtsdurchlaufs wird die Aktion des Agenten ausgewählt. Ich möchte mich speziell auf die Stichprobe der Aktionen konzentrieren. Dies wird dazu beitragen, die Aktionen der Agenten so weit wie möglich zu diversifizieren und zu einer umfassenden Untersuchung der Umwelt beizutragen.
Auf der Grundlage des Ausgangszustands des Systems, der gesampelten Aktion und der aus dem Wiedergabepuffer bekannten Erfahrung der nachfolgenden Kursbewegung berechnen wir den nächsten Zustand des Kontos und füllen den entsprechenden Block von Zieldiskriminatorwerten aus. Dann geht es weiter mit der nächsten Fertigkeit.
action = Actor.getSample(); account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); shift = skill * AccountDescr; DiscriminatorResult[shift] = (account[0] - PrevBalance) / PrevBalance; DiscriminatorResult[shift + 1] = account[1] / PrevBalance; DiscriminatorResult[shift + 2] = (account[1] - PrevEquity) / PrevEquity; DiscriminatorResult[shift + 3] = account[2] / PrevBalance; DiscriminatorResult[shift + 4] = account[4] / PrevBalance; DiscriminatorResult[shift + 5] = account[5]; DiscriminatorResult[shift + 6] = account[6]; DiscriminatorResult[shift + 7] = account[7] / PrevBalance; DiscriminatorResult[shift + 8] = account[8] / PrevBalance; }
Nach der Aufbereitung der Zieldaten führen wir einen Rückwärtsdurchlauf des Diskriminators durch.
if(!Result) { Result = new CBufferFloat(); if(!Result) { PrintFormat("Error of create buffer %d", GetLastError()); ExpertRemove(); break; } } Result.AssignArray(DiscriminatorResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
Im nächsten Block werden wir uns die Iterationen der nächsten Phase des Trainingsprozesses ansehen - das Agententraining. Ich möchte Sie daran erinnern, dass wir die Ausgangsdaten vorbereitet haben, bevor wir den Arbeitsablauf je nach Ausbildungsphase aufgeteilt haben. Dies bedeutet, dass wir bereits einen generierten Puffer mit Quelldaten haben. Daher führen wir einen Vorwärtsdurchlauf des Diskriminators durch und extrahieren die Ergebnisse der Operationen, da wir sie zur Bildung der internen Belohnung benötigen.
case 1: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Discriminator.getResults(DiscriminatorResult);
Als Nächstes organisieren wir, wie in der vorangegangenen Trainingsphase, einen zyklischen Prozess der sequentiellen Aufzählung aller Fertigkeiten für den aktuellen Zustand.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Im Hauptteil der Schleife organisieren wir die Vorwärtsbewegung des Agenten, die Bildung des Belohnungsvektors und die Rückwärtsbewegung des Modells.
reward = GetAgentReward(skill, DiscriminatorResult, Buffer[tr].States[i].account); Result.AssignArray(reward); StateSkill.AssignArray(Buffer[tr].States[i + 1].state); account = GetNewState(Buffer[tr].States[i].account, Actor.getAction(), prof_1l); shift = skill * AccountDescr; StateSkill.Add((account[0] - PrevBalance) / PrevBalance); StateSkill.Add(account[1] / PrevBalance); StateSkill.Add((account[1] - PrevEquity) / PrevEquity); StateSkill.Add(account[2] / PrevBalance); StateSkill.Add(account[4] / PrevBalance); StateSkill.Add(account[5]); StateSkill.Add(account[6]); StateSkill.Add(account[7] / PrevBalance); StateSkill.Add(account[8] / PrevBalance); if(!Actor.backProp(Result, DiscountFactor, GetPointer(StateSkill), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } } break;
Wie Sie sehen können, ist die vollständige Enumeration der Fertigkeiten etwas unvereinbar mit dem allgemeinen, zuvor verwendeten Paradigma der Verwendung von Zufallszuständen. Bei der Bestimmung der Trajektorie und des Anfangszustands bleiben wir der Stichprobe treu. Durch die vollständige Aufzählung der Fertigkeiten für einen einzelnen Staat wollen wir die Aufmerksamkeit des Modells speziell auf die Indikatoren zur Identifizierung der Fertigkeiten lenken. Schließlich sind es die Veränderungen in den Fertigkeiten, die dem Modell signalisieren sollen, die Verhaltensstrategie zu ändern.
Der nächste Schritt unserer Implementierung des DADS-Algorithmus ist das Training des Schedulers. Dieser Prozess wiederholt fast vollständig die ähnliche Funktionalität bei der Implementierung der DIAYN-Methode. Zunächst wird ein direkter Durchlauf vom Planer durchgeführt und wir erhalten eine probabilistische Verteilung der Fertigkeiten. Anders als bei der vorherigen Implementierung werden wir jedoch weder eine Stichprobe ziehen noch eine gierige Auswahl der Fertigkeiten vornehmen. Wir wissen, dass es unter realen Bedingungen keine klaren Grenzen für die Abgrenzung der einen oder anderen Strategie gibt. Diese Grenzen sind sehr unscharf. In allen Bereichen gibt es verschiedene Toleranzen und Kompromisse. Unter solchen Bedingungen reift die Entscheidung, dem Agenten die vollständige Wahrscheinlichkeitsverteilung zur Entscheidungsfindung zu übertragen.
case 2: if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Scheduler.getResults(SchedulerResult);
Ich möchte Sie darauf aufmerksam machen, dass während der Ausbildung des Agenten klar definierte Skill-IDs an ihn weitergegeben wurden. Umso interessanter wird das Experiment, dem Agenten die gesamte Wahrscheinlichkeitsverteilung zur weiteren Entscheidungsfindung zu übertragen. Schließlich gehen solche Ausgangsdaten über den Trainingssatz hinaus, was das Verhalten des Modells unvorhersehbar macht.
State.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } action = Actor.getAction();
Auf der Grundlage der Ergebnisse des Vorwärtsdurchlaufs wählen wir die Agentenaktion gierig aus. Unser Ziel ist es ja, den Planer zu trainieren, damit er die Entscheidungspolitik auf der Ebene der Fertigkeiten steuern kann. Dies ist nur möglich, wenn vorhersehbare Fertigkeiten eingesetzt werden, deren Verhalten durch eine sinnvolle und konsistente Strategie bestimmt wird.
Als Nächstes bestimmen wir den geschätzten Folgezustand der Kontobeschreibungsindikatoren und bilden auf dieser Grundlage den Modellbelohnungsvektor. Wie Sie sich vielleicht erinnern, verwenden wir die relative Veränderung des Kontostands als externe Belohnung des Modells.
account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); SchedulerResult = SchedulerResult * (account[0] / PrevBalance - 1.0); Result.AssignArray(SchedulerResult); State.AssignArray(Buffer[tr].States[i + 1].state); State.Add((account[0] - PrevBalance) / PrevBalance); State.Add(account[1] / PrevBalance); State.Add((account[1] - PrevEquity) / PrevEquity); State.Add(account[2] / PrevBalance); State.Add(account[4] / PrevBalance); State.Add(account[5]); State.Add(account[6]); State.Add(account[7] / PrevBalance); State.Add(account[8] / PrevBalance); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
Nach der Vorbereitung des Modell-Belohnungsvektors und des darauf folgenden Systemzustands führen wir einen Rückwärtsdurchlauf durch das Planermodell durch.
default: PrintFormat("Wrong phase %d", phase); break; } } } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Am Ende der Operationen im Hauptteil des Modelltrainingszyklus-Systems wird eine Meldung angezeigt, die den Nutzer über den Fortschritt des Modelltrainings informiert.
Die übrigen EA-Methoden und -Funktionen sowie der EA zum Testen des trainierten Modells wurden unverändert übernommen. Der vollständige Code aller in diesem Artikel verwendeten Programme befindet sich im Anhang im Verzeichnis MQL5\Experts\DADS.
3. Test
Die Modelle wurden auf historischen Daten für die ersten 4 Monate des Jahres 2023 auf EURUSD H1 trainiert. Die Indikatoren wurden mit Standardparametern verwendet. Wie Sie sehen können, wurden die Testparameter unverändert aus dem vorherigen Artikel übernommen. Auf diese Weise können wir die Ergebnisse von zwei Trainingsmethoden vergleichen.
Um die Leistung des trainierten Modells zu überprüfen, wurde der Test im Strategietester für den Zeitraum Mai 2023 durchgeführt. Mit anderen Worten: Der Test des trainierten Modells wurde außerhalb der Trainingszeitraumes in einem Zeitintervall von 25 % dieses Trainingszeitraumes durchgeführt.
Das Modell zeigte die Fertigkeit, mit einem Gewinnfaktor von 1,75 und einem Erholungsfaktor von 0,85 Gewinn zu erzielen. Der Anteil der gewinnbringenden Geschäfte lag bei 52,64 %. Gleichzeitig liegt der durchschnittliche Ertrag eines gewinnbringenden Geschäfts um 57,37 % über dem durchschnittlichen Verlustgeschäft (2,99 gegenüber -1,90).



Wir können auch die fast einheitliche Nutzung von Fertigkeiten feststellen. Alle Fertigkeiten wurden in den Test einbezogen.
Beim Testen des trainierten Modells erhielt der Agent nicht nur eine gierig ausgewählte Fertigkeit, sondern eine vollständige Wahrscheinlichkeitsverteilung, die vom Planer erzeugt wurde. Darüber hinaus wurde jede Agentenaktion mit Hilfe einer Gierstrategie nach der maximalen vorhergesagten Belohnung ausgewählt. Dieser Ansatz gibt dem Planer ein Höchstmaß an Kontrolle über den Betrieb des Modells und eliminiert die Stochastizität der Aktionen des Agenten, die beim Sampling möglich ist. Wie Sie sich vielleicht erinnern, haben wir auf diese Weise das Scheduler-Modell trainiert.
Es ist bemerkenswert, dass das Experiment mit der gierigen Auswahl von Fertigkeiten ähnliche Ergebnisse zeigte. Durch die gierige Wahl der Fertigkeiten konnte der Gewinnfaktor auf 1,80 erhöht werden. Der Anteil der gewinnbringenden Transaktionen stieg um 0,91 % auf 53,55 %. Auch hier ist ein Anstieg des durchschnittlich profitablen Handels auf 3,08 zu beobachten.

Schlussfolgerung
In diesem Artikel haben wir eine weitere Methode des unüberwachten Kompetenztrainings vorgestellt, die Dynamics-Aware Discovery of Skills (DADS). Mit dieser Methode kann eine Vielzahl von Fertigkeiten trainiert werden, mit denen die Umwelt effektiv erkundet werden kann. Gleichzeitig haben die mit der vorgeschlagenen Methode trainierten Fertigkeiten ein recht vorhersehbares Verhalten. Dies erleichtert das Training des Planers und erhöht die Stabilität des trainierten Modells im Allgemeinen.
Wir haben den betrachteten Algorithmus auch mit MQL5 implementiert und das konstruierte Modell getestet. Der Test lieferte ermutigende Ergebnisse, die zeigen, dass das Modell in der Lage ist, über den Trainingssatz hinaus Gewinne zu erzielen.
Alle in diesem Artikel vorgestellten und verwendeten Programme sollen jedoch nur die Funktionsweise der Ansätze demonstrieren und sind nicht für den Einsatz im realen Handel geeignet.
Liste der Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mql5 | Expert Advisor | Modelltraining EA |
| 3 | Test.mq5 | Expert Advisor | Modellversuche EA |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | FQF.mqh | Klassenbibliothek | Klassenbibliothek zur Organisation der Arbeit eines vollständig parametrisierten Modells |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/12750
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
beim Starten des Strategietesters.
Ich habe viel gesucht, muss ich die Datei selbst erstellen? und wenn ja, wo sollte ich das tun?
Ich habe viel gesucht, muss ich die Datei selbst erstellen? und wenn ja, wo sollte ich das tun?
Hallo, was ist der EA-Back-Fehler?
Zuerst müssen Sie Research.mq5 im Strategietester ausführen. Und dann führen Sie Study.mq5 im Real-Modus aus.