Kategorientheorie in MQL5 (Teil 16): Funktoren mit mehrschichtigen Perceptrons
Einführung
Diese Serie hat bisher gezeigt, wie einige grundlegende Konzepte der Kategorientheorie dargestellt und in MQL5-Code verwendet werden können, um Händlern bei der Entwicklung robusterer Handelssysteme zu helfen. Das Thema der Kategorientheorie hat viele Facetten, aber die beiden wichtigsten sind wohl Funktor (Mathematik) und die Natürliche Transformation. Indem wir uns also erneut mit Funktoren beschäftigen (wie in unseren beiden vorherigen Artikeln), heben wir eine der wichtigsten Ideen des Themas hervor.
Der Schwerpunkt dieses Artikels liegt jedoch, auch wenn wir wie im letzten Artikel an den Funktoren festhalten, auf Anwendungen zur Generierung von Einstiegs- und Ausstiegssignalen, während wir uns in der Vergangenheit nur auf die Anpassung des Trailing-Stops konzentriert haben. Dies bedeutet wiederum nicht, dass der beigefügte Code ein Gral ist, sondern eher eine Idee, die vom Leser verbessert und modifiziert werden sollte, je nachdem, wie er die Märkte sieht.
Rekapitulation: Funktoren und Graphen in MQL5
Funktoren sind eine Abbildung zwischen Kategorien, die Beziehungen nicht nur zwischen den Objekten in den beiden Kategorien, sondern auch zwischen den Morphismen dieser Kategorien erfassen. Das bedeutet, dass wir sie im Code als eine dieser beiden Zuordnungen implementiert haben, wenn wir Vorhersagen machen, weil die Zuordnung über die Objekte tatsächlich die über die Morphismen überprüft und umgekehrt.
Die Graphentheorie, das als Darstellung von miteinander verbundenen Systemen mit Pfeilen und Eckpunkten betrachtet werden kann, wurde in Artikel 11 in die Reihe aufgenommen. In unserem letzten Artikel haben wir sie jedoch anhand der von MetaQuotes über das MetaTrader 5-Terminal zur Verfügung gestellten Wirtschaftskalenderdaten veranschaulicht und eine einfache Hypothese verwendet, die 4 verschiedene Datenpunkte miteinander verbindet, die Teil einer Zeitreihe sind. Dieses Schaubild, das in dem Artikel gezeigt wurde, ist eigentlich eine Kategorie für sich.
Die Funktoren, die wir in unserem letzten Artikel betrachtet haben, bilden zwei Kategorien durch eine einfache lineare Gleichung ab. Der Code enthielt Optionen zur Skalierung auf eine quadratische Gleichung, die jedoch bei den für diesen Artikel durchgeführten Tests nicht implementiert wurden. Die Abbildung des Funktors nimmt also im Wesentlichen den Wert eines Objekts in der Domänenkategorie, multipliziert ihn mit einem Koeffizienten und fügt eine Konstante hinzu, um den Objektwert in der Codomäne zu erhalten. Sie war linear, da der Koeffizient und die Konstante praktisch die Steigung und der y-Achsenabschnitt einer einfachen linearen Gleichung waren.
Kategorientheoretische Funktoren aus Wirtschaftskalenderdaten
Die Neuformatierung der Wirtschaftskalenderdaten als Kategorie, die durch die Verwendung von Graphen erreicht wurde, war angesichts der komplexen Verflechtung der Kalenderdaten geeignet. Wie auf der Registerkarte „Kalender“ im MetaTrader 5-Terminal zu sehen ist, gibt es eine Fülle von verschiedenen Arten von Wirtschaftsdaten. Dieses Problem wurde in einem früheren Artikel hervorgehoben, in dem die Notwendigkeit, diese Daten, da sie währungsspezifisch sind, bei Handelsentscheidungen für ein Währungspaar zu kombinieren, schwierig sein kann. Für das im letzten und in diesem Artikel vorgesehene Wertpapier besteht zwar keine Notwendigkeit, die Daten zu koppeln, aber dennoch ist die Vorstellung, dass einige dieser Daten von anderen Wirtschaftsdaten abhängig sind, etwas, das in Betracht gezogen werden sollte, insbesondere angesichts der weitreichenden Bedeutung unseres Wertpapiers, des S&P 500. Um dieses Problem anzugehen, hatten wir im letzten Artikel die einfache Hypothese aufgestellt, dass der VPI-Druck vom PMI-Druck abhängt, der wiederum von den jüngsten 10-Jahres-Auktionsrenditen abhängt, die wiederum von den Einzelhandelsumsätzen beeinflusst werden. Anstatt einer Zeitreihe mit nur einem dieser Wirtschaftsdatenpunkte haben wir also eine Reihe von mehreren Punkten, die die Grundlage für die Volatilität des S&P 500 bilden.
In diesem Artikel interessieren wir uns jedoch mehr für den S&P 500, und zwar nicht nur wegen seiner Volatilität, wie es in den letzten Artikeln der Fall war, sondern wegen seiner Trends. Wir versuchen, Prognosen über seine kurzfristigen (monatlichen) Trends zu erstellen und diese Prognosen zu nutzen, um Positionen in unserem Expert Advisor zu eröffnen. Das bedeutet, dass wir uns mit der Klasse Expert Signal und nicht wie bisher mit der Klasse Expert Trailing beschäftigen werden. Die Implementierung von funktorbasierten Transformationen auf dem Graph der Wirtschaftskalenderdaten führt also zu der prognostizierten Veränderung des S&P 500. Diese Implementierung wird mit Hilfe eines mehrschichtigen Perzeptrons erreicht.
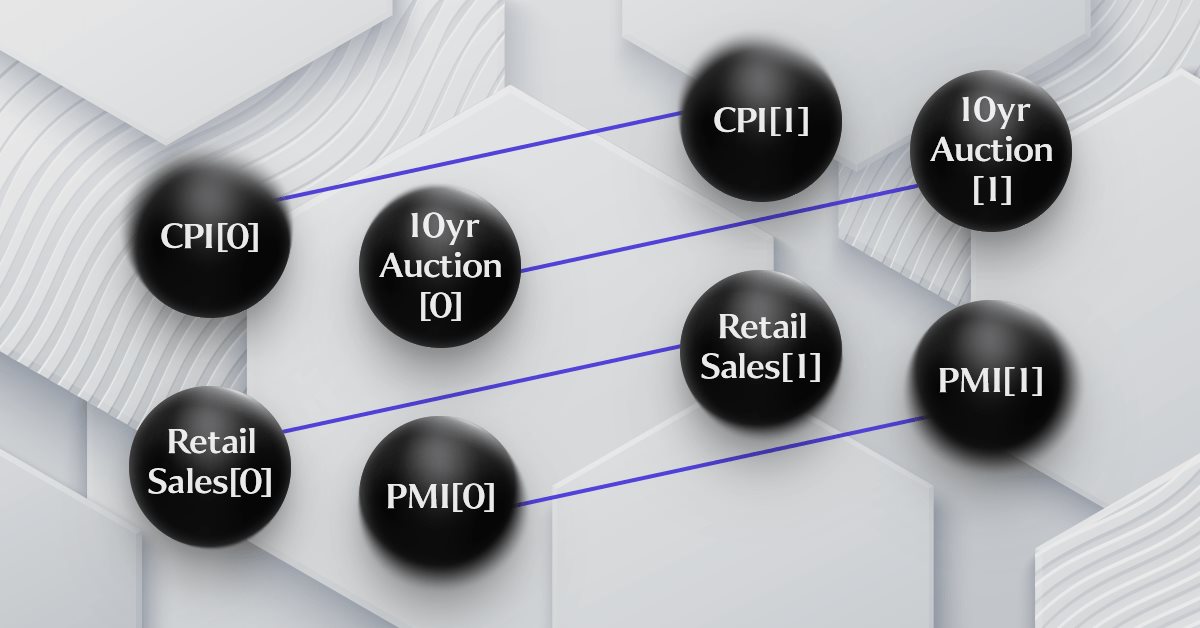
Im letzten Artikel hatten wir eine schematische Darstellung unserer einfachen Hypothese, die die vier betrachteten Wirtschaftsdaten miteinander verknüpft, allerdings war sie zu stark vereinfacht und wurde nicht als Graph von Zeitreihen dargestellt. Das nachstehende Diagramm versucht, dies zu erreichen:

Wie Sie aus dem Diagramm ersehen können, führt das Hinzufügen von Zeitreihenobjekten zu einer gewissen Komplexität, was eindeutig dafür spricht, dass es sich um ein Graph handelt. Die Hypothese, auf der dies beruht, ist umstritten, da man beispielsweise argumentieren könnte, dass der VPI ein Ergebnis der Einzelhandelsumsätze ist, die wiederum vom PMI beeinflusst werden, der wiederum von der Geldmenge, gemessen an der Entwicklung der 10-jährigen Auktion, bestimmt wird. Und so weiter. Es gibt sogar noch eine Reihe anderer Permutationen mit anderen oder mehr Wirtschaftsdaten, die vielleicht einen größeren Einfluss auf das prognostizierte Delta des S&P 500 haben würden. Die gute Nachricht ist, dass trotz all dieser möglichen Permutationen und Hypothesen der Strategietester im Terminal all diese Argumente ausräumen kann. Deshalb ist es hilfreich, wenn Sie Ihre Ideen klar in einem Format formulieren, das effizient getestet werden kann.
Zu diesem Zweck ermöglicht der MQL5-Assistent die einfache Zusammenstellung eines Expert Advisors mit wenigen Klicks, wenn man lediglich eine Signaldatei kodiert hat.
Kategorientheoretische Funktoren für S&P 500 Indexwerte
Innerhalb der Signaldatei entspricht die Darstellung der S&P 500-Indexwerte als Graph einer Kategorie, da, wie im letzten Artikel erläutert, jeder Graph-Vertex (Datenpunkt) einem Objekt entspricht und somit die Pfeile zwischen den Vertices als Morphismen betrachtet werden können. Ein Objekt kann aus einem einzigen Element bestehen, aber in diesem Fall umfasst der Datenpunkt mehr als nur den Wert, an dem wir interessiert sind, denn zu den zusätzlichen Daten, die für unsere Kategorie nicht berücksichtigt werden, gehören: das Datum, an dem die Wirtschaftsdaten veröffentlicht wurden, die Konsensprognosen für diese Daten im Vorfeld ihrer Veröffentlichung und andere Daten, die alle auf der Registerkarte „Kalender“ im MetaTrader-Terminal aufgeführt sind. Dieser Link führt zu einer Seite mit Kalenderereignistypen, und jedes Attribut der Enumeration würde auf unser Objekt zutreffen. Alle diese Daten würden dann ein Objekt oder einen so genannten Satz in der Kategorie Wirtschaftskalender bilden.
Die Verwendung von Funktoren zur Analyse und Vorverarbeitung historischer Wirtschaftskalenderdaten kann leider nur im Strategietester über einen Drittanbieter und nicht direkt von MetaQuotes' Server(n) erfolgen. Dies ist sicherlich ein Engpass, den wir durch den Export der Daten in eine CSV-Datei per Skript und das anschließende Einlesen dieser CSV-Datei im Strategietester wie in einem früheren Artikel gelöst haben. Der Unterschied besteht hier darin, dass wir dies für eine Instanz der Klasse Expert Signal und nicht für die Klasse Trailing tun. Da wir es mit zwei Funktoren zu tun haben, hat das verwendete Skript zwei Dateien geschrieben, eine mit dem Präfix „true“, was bedeutet, dass der Funktor über Objekte geht, und eine andere mit dem Präfix „false“, was bedeutet, dass er über Morphismen geht. Die entsprechenden Dateien sind am Ende des Artikels beigefügt.
Eine grafische Darstellung der transformierten Werte des S&P 500-Index wurde in einem Diagramm oben veröffentlicht.
Funktorbasierte neuronale Netzwerkarchitektur
Die Funktoren als mehrschichtige Perzeptrons (neuronale Netze) sind in diesem Artikel ein Fortschritt gegenüber den bisherigen linearen oder quadratischen Beziehungen, die wir bei der Zuordnung zwischen Kategorien und sogar Objekten innerhalb einer Kategorie verwendet haben (da eine Morphismus-Beziehung zwischen zwei Elementen auf dieselbe Weise definiert werden kann). Wie bereits betont, impliziert die Verwendung von Funktoren nicht nur eine Abbildung der Objekte in den beiden Kategorien, sondern auch ihrer jeweiligen Morphismen. Das eine kann also das andere überprüfen, d.h. wenn man die Objekte in der Codomain-Kategorie kennt, dann sind die Morphismen impliziert und umgekehrt. Das bedeutet, dass wir es mit zwei Perceptrons zwischen unseren Kategorien zu tun haben werden.
Dieser Artikel soll auch keine Fibel über das mehrschichtige Perzeptron sein, da es bereits viele Artikel gibt, nicht nur unter den auf dieser Website veröffentlichten, sondern auch im Internet im Allgemeinen, sodass der neugierige Leser eingeladen ist, seine eigenen Hintergrundrecherchen durchzuführen, wenn dies zur Klärung des hier Dargestellten beitragen kann. Die hier implementierte Netzwerkarchitektur ist zu einem großen Teil der Alglib zu verdanken, die in der IDE von MetaTrader unter dem Ordner „Include\Math“ zugänglich ist. Und so wird die Initialisierung eines Perceptrons mit der Bibliothek durchgeführt:
//+------------------------------------------------------------------+ //| Function to train Perceptron. | //+------------------------------------------------------------------+ bool CSignalCT::Train(CMultilayerPerceptron &MLP) { CMLPBase _base; CMLPTrain _train; if(!ReadPerceptron(m_training_profit)) { _base.MLPCreate1(__INPUTS,m_hidden,__OUTPUTS,MLP); m_training_profit=0.0; } else { printf(__FUNCSIG__+" read perceptron, with profit: "+DoubleToString(m_training_profit)); } ... return(false); }
Die in dieser Bibliothek verwendeten Perceptrons sind sehr einfach und bestehen aus drei Schichten. Eine Eingabeschicht, eine verborgene Schicht und eine Ausgabeschicht. Unsere wirtschaftliche Datenkategorie hat jeweils vier Datenpunkte (basierend auf unserer Hypothese), sodass die Anzahl der Eingaben in der versteckten Schicht vier beträgt. Die Anzahl der Punkte auf der versteckten Schicht ist einer der wenigen optimierbaren Parameter, aber unsere Vorgabe ist sieben. Schließlich gibt es in der Ausgabeschicht eine Ausgabe, die die prognostizierte Veränderung des S&P 500 Index darstellt. Die Kenntnis von Gewichten, Verzerrungen und Aktivierungsfunktionen ist der Schlüssel zum Verständnis der Vorwärtsfunktion von Perceptrons. Auch hier wird der Leser aufgefordert, bei Bedarf eigene Nachforschungen anzustellen.
Training des funktorbasierten neuronalen Netzes
Der Trainingsprozess auf Basis historischer Wirtschaftskalenderdaten wird mit dem Algorithmus durchgeführt. Die Kodierung hierfür wird, wie bei der Feedforward- und Backpropagation, von AlgLib-Funktionen übernommen. Wir würden eine Schulung in der Bibliothek wie folgt durchführen:
int _info=0; CMatrixDouble _xy; CMLPReport _report; TrainingLoad(m_training_stop,_xy,m_training_points,m_testing_points); // if(m_training_points>0) { _train.MLPTrainLM(MLP,_xy,m_training_points,m_decay,m_restarts,_info,_report); if(_info>0){ return(true); } }
Der wichtigste Teil ist hier das Auffüllen der XY-Matrix mit Eingabedaten aus einer csv-Datei im gemeinsamen Verzeichnis. Die Matrix holt die vier Datenpunkte, die in jeder Datenzeile als historische Daten definiert sind, immer dann ab, wenn ein neuer Balken erzeugt wird (oder bei einem Timer), und verwendet sie zum Trainieren des Netzes, um seine Gewichte und Vorspannungen zu erzeugen. Die Population der XY-Eingabematrix wird von der Funktion „TrainingLoad“ wie unten dargestellt behandelt:
//+------------------------------------------------------------------+ //| Function Get Training Points and Initialize Training Matrix. | //+------------------------------------------------------------------+ void CSignalCT::TrainingLoad(datetime Date,CMatrixDouble &XY,int &TrainingPoints,int &TestingPoints) { TrainingPoints=0; TestingPoints=0; ResetLastError(); string _file="_s_"+m_currency+"_"+m_symbol.Name()+"_"+EnumToString(m_period)+"_"+string(m_objects)+".csv"; int _handle=FileOpen(_file,FILE_SHARE_READ|FILE_ANSI|FILE_COMMON,"\n",CP_ACP); if(_handle!=INVALID_HANDLE) { string _line=""; int _line_length=0; while(!FileIsLineEnding(_handle)) { //--- find out how many characters are used for writing the line _line_length=FileReadInteger(_handle,INT_VALUE); //--- read the line _line=FileReadString(_handle,_line_length); string _values[]; ushort _separator=StringGetCharacter(",",0); if(StringSplit(_line,_separator,_values)==6) { datetime _date=StringToTime(_values[0]); _d_economic.Let(); _d_economic.Cardinality(4); //printf(__FUNCSIG__+" initializing for: "+TimeToString(Date)+" at: "+TimeToString(_date)); if(_date<Date) { TrainingPoints++; // XY.Resize(TrainingPoints,__INPUTS+__OUTPUTS); for(int i=0;i<__INPUTS;i++) { XY[TrainingPoints-1].Set(i,StringToDouble(_values[i+1])); } // XY[TrainingPoints-1].Set(__INPUTS,StringToDouble(_values[__INPUTS+1])); } else { TestingPoints++; } } } FileClose(_handle); } else { printf(__FUNCSIG__+" failed to load file. Err: "+IntegerToString(GetLastError())); } }
Der Grund, warum neuronale Netze nach dem Training funktionieren und beliebt sind, liegt in ihrer Fähigkeit, Gewichte und Verzerrungen zu entwickeln und wiederzuverwenden. In diesem Artikel wird die Speicherung dieser Gewichte und Verzerrungen durch eine nutzerdefinierte Funktion gehandhabt, die der Autor zu diesem Zeitpunkt nicht mit anderen teilen möchte. Daher wird ihr Verweis als ex5-Bibliothek in der Auflistung enthalten sein, nicht aber ihr Code.
Beim Training eines Netzes werden die Daten in der Regel vorverarbeitet, d. h. sie werden auf vergleichbare Werte normalisiert und in Trainings- und Testsätze aufgeteilt. Für unsere Zwecke trainieren wir jedoch den geladenen Historien-Datensatz bei der Initialisierung des Experten und testen ihn dann unter Verwendung eines separaten Teils der csv-Daten, dessen Trennung von den Trainingsdaten durch ein Eingabedatum definiert ist. Da unser einziger optimierbarer Parameter die Anzahl der Gewichte in der versteckten Schicht ist (von 5 bis 12), schreiben wir die trainierten Gewichte des Netzes in eine Datei im gemeinsamen Verzeichnis und am Ende jedes Optimierungsdurchgangs nur dann, wenn die Optimierungskriterien aus diesem Durchgang die der bereits geschriebenen Datei in einem früheren Durchgang übersteigen. Wenn dies gelingt und eine Datei geschrieben wird, dann werden bei der Initialisierung des Netzes im nächsten Durchgang die Anfangsgewichte aus dieser Datei geschrieben.
Backpropagation und Gradientenverfahren werden von der Funktion „MLPTrainLM“ in der Klasse „CMLPTrain“ von AlgLib behandelt.
Erzeugung von Handelssignalen mit Hilfe von Funktoren und neuronalen Netzen
Die S&P 500-Kategorie, die eine Totalordnung der Indexveränderungen ist, bildet eine Codomäne zu unseren „zwei“ Funktoren aus der Kategorie der Wirtschaftskalenderdaten. Zusammenfassend kann man sagen, dass es „zwei“ sind, weil die Objekte und Morphismen beide miteinander verbunden sind. Unser Signal für den Testzeitraum, der durch das aus der csv-Datei gelesene Eingabedatum definiert ist, wird also durch die am Ende jedes Trainings erhaltenen Gewichte erzeugt. Das Training für den diesem Artikel beigefügten Code erfolgt bei jeder Initialisierung des Experten. Im Anhang finden Sie eine Signaldatei, die wie die in früheren Artikeln angehängten Trailing-Dateien verwendet werden kann, sobald sie im MQL5-Assistenten über MetaEditor IDE zusammengestellt wurde. Wir könnten zusätzlich mit dem Timer trainieren, da jeder neue Balken eine neue Datenzeile für unsere csv-Datei liefert. Dieser Ansatz wird in dem Artikel jedoch nicht untersucht, und der Leser ist eingeladen, ihn selbst zu erforschen, da er schnell weitere auftauchende Signale aufspüren kann.
Unsere Funktion „GetOutput“ ist wie in den vergangenen Artikeln dafür verantwortlich, den Wert zu erhalten, aus dem wir unsere Handelsentscheidung ableiten. Wie aus der nachstehenden Auflistung hervorgeht, werden nicht nur die Kategorien mit aktuellen Werten aktualisiert, sondern auch die Netzwerkeingänge auf der Grundlage der aktuellen Kalenderwerte aus der csv-Datei im gemeinsamen Verzeichnis vorbereitet und in das Array „_x_inputs“ eingefügt, von wo aus das Array mit der Funktion „MLPProcess“, die Teil der Klasse „CMLPBase“ ist, an das Netzwerk weitergeleitet wird. Diese sind unten aufgeführt:
//+------------------------------------------------------------------+ //| Get Output value, forecast for next change in price bar range. | //+------------------------------------------------------------------+ double CSignalCT::GetOutput(datetime Date) { if(Date>=D'2023.07.01') { printf(__FUNCSIG__+" log profit: "+DoubleToString(m_training_profit)+", account profit: "+DoubleToString(m_account.Profit())+", equity: "+DoubleToString(m_account.Equity())+", deposit: "+DoubleToString(m_training_deposit)); if(m_training_profit<m_account.Equity()-m_training_deposit) { printf(__FUNCSIG__+" perceptron write... "); m_training_profit=m_account.Equity()-m_training_deposit; WritePerceptron(m_training_profit,_MLP); } } ... _value="";_e.Let();_e.Cardinality(1); _d_economic.Get(3,_e);_e.Get(0,_value); _x_inputs[3]=StringToDouble(_value);//printf(__FUNCSIG__+" val 4: "+_value); //forward feed?... CMLPBase _base; _base.MLPProcess(_MLP,_x_inputs,_y_inputs); _output=_y_inputs[0]; //printf(__FUNCSIG__+" output is: "+DoubleToString(_output)); return(_output); }
Es besteht auch die Möglichkeit, das Risikomanagement und die Positionsgröße in ein Handelssystem einzubeziehen, das diese Methoden verwendet, die eine Größenbestimmung in Abhängigkeit von der Größe des Signals beinhalten könnten. Dies erfordert natürlich eine Normalisierung des Signalwerts, und wie immer, wenn es um Änderungen der Positionsgröße geht, ist besondere Vorsicht geboten. Diese Änderungen würden jedoch durch die Erstellung einer nutzerdefinierten Instanz der Klasse „ExpertMoney“ erreicht, so wie wir eine nutzerdefinierte Instanz der Klasse „ExpertSignal“ zur Festlegung von Ein- und Ausstiegspunkten verwenden.
Backtesting und Leistungsbewertung
Unser Backtesting wird eine Optimierung der idealen Anzahl von Gewichten in der versteckten Schicht sein. Da diese von 5 bis 12 reichen, gibt es nur acht Möglichkeiten, und dennoch wollen wir mehrere Durchläufe mit jeder Anzahl von Gewichten durchführen, bevor wir eine ideale Anzahl auswählen. Um also mehrere Durchläufe zu ermöglichen, fügen wir einen Parameter hinzu, der sich nicht auf die Leistung des Experten auswirkt, aber optimiert werden muss und daher zusätzliche Durchläufe zum Optimierungsprozess hinzufügt, um für jede Anzahl von Gewichtungsoptionen mehrere Testläufe zu ermöglichen. Wie bereits erwähnt, werden am Ende eines jeden Durchlaufs, wenn das Testergebnis besser ist als das der zuletzt in den gemeinsamen Ordner geschriebenen Datei, die zuvor geschriebenen Gewichte ersetzt. Unser Optimierungskriterium wird der maximale Gewinn sein. Wir arbeiten mit dem monatlichen Zeitrahmen, da die Wirtschaftsdaten im Durchschnitt etwa genauso oft aktualisiert werden. Die Testläufe waren vom 2022-07-01 bis 2023-08-01 für den S&P 500 im monatlichen Zeitrahmen und unser bester Lauf für den Objekt-zu-Objekt-Funktor ergab den unten stehenden Bericht:

In ähnlicher Weise erzeugte unser Morphismus-zu-Morphismus-Funktor den folgenden Bericht:

Die Analyse der wichtigsten Kennzahlen der Berichte zum Drawdown und zum Gewinnfaktor zeigt, dass der Morphismus-zu-Morphismus-Funktor am besten abschneidet. Vielleicht lohnt es sich, sie weiterzuentwickeln? Diese Frage lässt sich nicht nur durch weitere Tests mit alternativen Wertpapieren beantworten, sondern auch durch die Verwendung unterschiedlicher Trainingsansätze bei den Testläufen, z. B. durch die Überlegung, ob das Training bei jedem neuen Balken oder vierteljährlich durchgeführt werden sollte.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass die wichtigsten Erkenntnisse aus den Tests mit Perceptrons darin bestehen, dass ein Handelssystem mit einem Signal wie dem in der Signaldatei dargestellten entwickelt werden könnte. Im Vorfeld der Entwicklung muss eine geeignete Domänenkategorie mit Daten in einem für Strategietester leicht zugänglichen Format verfügbar sein, und da sich zuverlässige Tests in der Regel über mehrere Jahre erstrecken, müssen diese Daten umfangreich sein.
Die Bedeutung der Verwendung von mehrschichtigen Perceptrons als Funktoren ist nicht nur ein Fortschritt, sondern ein Segen, der angesichts der vielen Arten und Formate, die neuronale Netze annehmen können, ein großes Potenzial hat. Der Artikel enthält Hyperlinks zur weiteren Untersuchung von Perceptrons, doch handelt es sich hierbei um ein bekanntes und dokumentiertes Thema, sodass sie nur als Anhaltspunkte dienen. Viele der bereits behandelten Konzepte wie Grenzwerte, Kolimits und universelle Eigenschaften können mit Hilfe von neuronalen Netzen formuliert werden.
Referenzen
Wikipedia, die aufgeführten Links.
Anmerkungen zu Anhängen
Kopieren Sie die Dateien „SignalCT_16_.mqh“ in den Ordner „MQL5\include\Expert\Signal\“ und die Datei „ct_16.mqh“ in den Ordner „MQL5\include\“.
Darüber hinaus sollten Sie diesen Leitfaden zur Zusammenstellung eines Expert Advisors mit dem Assistenten befolgen, da Sie sie als Teil eines Expert Advisors aufnehmen müssen. Wie im Artikel erwähnt, habe ich keinen Trailing Stop und eine feste Marge für das Money Management verwendet, die beide Teil der MQL5-Bibliothek sind. Wie immer ist das Ziel dieses Artikels nicht, Ihnen einen Gral zu präsentieren, sondern vielmehr eine Idee, die Sie an Ihre eigene Strategie anpassen können.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/13116
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.