Quantisierung beim maschinellen Lernen (Teil 1): Theorie, Beispielcode, Analyse der Implementierung in CatBoost

Einführung
Der Artikel befasst sich mit der theoretischen Anwendung der Quantisierung bei der Konstruktion von Baummodellen Es werden keine komplexen mathematischen Gleichungen verwendet. Beim Verfassen des Artikels habe ich festgestellt, dass es in den wissenschaftlichen Werken verschiedener Autoren keine einheitliche Terminologie gibt, sodass ich die Terminologie wählen werde, die meiner Meinung nach die Bedeutung am besten wiedergibt. Außerdem werde ich in den Fragen, die von anderen Forschern nicht behandelt werden, meine eigenen Begriffe verwenden. In diesem Artikel werden Begriffe und Konzepte verwendet, die ich zuvor in dem Artikel „Der Algorithmus CatBoost von Yandex für das maschinelle Lernen, Kenntnisse von Python- oder R sind nicht erforderlich“ beschrieben habe. Daher empfehle ich Ihnen, sich vor der Lektüre des vorliegenden Artikels mit ihm vertraut zu machen.
In diesem Artikel wird nicht auf die Möglichkeit eingegangen, die Quantisierung auf trainierte neuronale Netze anzuwenden, um deren Größe zu verringern, da ich derzeit keine persönlichen Erfahrungen auf diesem Gebiet habe.
Das können Sie erwarten:
- Der erste Teil des Artikels enthält einführendes theoretisches Material über die Quantisierung, das für das Verständnis der Ziele und des Wesens des Prozesses nützlich sein wird.
- Im zweiten Teil des Artikels wird die einheitliche Quantisierungsmethode am Beispiel des MQL5-Codes erläutert.
- Im dritten Teil des Artikels werde ich die Implementierung des Quantisierungsprozesses am Beispiel von CatBoost betrachten.
1. Standardanwendungen
Was also ist Quantisierung und warum wird sie verwendet? Lassen Sie es uns herausfinden!
Lassen Sie uns zunächst ein wenig über die Daten sprechen. Um also Modelle zu erstellen (zu trainieren), benötigen wir Daten, die gewissenhaft in der Tabelle gesammelt werden. Die Quelle solcher Daten kann jede Information sein, die das (vom Modell ermittelte) Ziel erklären kann, z. B. ein Handelssignal. Die Datenquellen werden unterschiedlich bezeichnet - Prädiktoren, Merkmale, Attribute oder Faktoren. Die Häufigkeit des Auftretens einer Datenzeile wird durch das Auftreten einer vergleichbaren Prozessbeobachtung des Phänomens bestimmt, über das Informationen gesammelt werden und das mit Hilfe des maschinellen Lernens untersucht werden soll. Die Gesamtheit der gewonnenen Daten wird als Stichprobe bezeichnet.
Eine Stichprobe kann repräsentativ sein - das heißt, die in ihr aufgezeichneten Beobachtungen beschreiben den gesamten Prozess des untersuchten Phänomens - oder sie kann nicht repräsentativ sein, wenn sie so viele Daten enthält, wie gesammelt werden konnten, was nur eine teilweise Beschreibung des Prozesses des untersuchten Phänomens ermöglicht. Wenn wir uns mit Finanzmärkten beschäftigen, haben wir es in der Regel mit nicht repräsentativen Stichproben zu tun, da alles, was passieren könnte, noch nicht geschehen ist. Aus diesem Grund wissen wir nicht, wie sich das Finanzinstrument bei neuen (bisher nicht eingetretenen) Ereignissen verhalten wird. Doch jeder kennt die Weisheit „Geschichte wiederholt sich“. Auf diese Beobachtung stützt sich der algorithmische Händler bei seinen Recherchen, in der Hoffnung, dass unter den neuen Ereignissen auch solche sind, die den vorherigen ähnlich sind und deren Ergebnis mit der ermittelten Wahrscheinlichkeit übereinstimmt.
Die numerischen Indikatoren der Prädiktoren können je nach ihrem logischen Inhalt (gemäß der Messskala) sein:
- Binär - bestätigen oder widerlegen das Vorhandensein eines bestimmten Attributs des beobachteten Phänomens.
- Quantitativ (metrische Skala) - beschreibt ein Phänomen mit einer Art Messindikator, z. B. Geschwindigkeit, Koordinaten von etwas, eine Größe, die verstrichene Zeit seit Beginn eines Ereignisses und viele andere Eigenschaften, die gemessen werden können, einschließlich deren Ableitungen.
- Kategorisch (Nominalskala) - Signale über verschiedene beobachtbare Objekte oder Phänomene, die in einer logischen Gruppe enthalten sind, in der Regel als ganze Zahl ausgedrückt. Zum Beispiel die Wochentage, die Richtung des Preistrends, die Seriennummer des Unterstützungs- oder Widerstandsniveaus.
- Rang (Ordinalskala) - charakterisiert den Grad der Überlegenheit oder Ordnung einer Sache. Sie werden nur selten einer eigenen Gruppe zugeordnet, da sie je nach Kontext und Logik auch anderen Arten von Indikatoren zugeordnet werden können. Dazu gehören zum Beispiel die Reihenfolge der Aktionen, das Ergebnis eines Experiments in Form einer Bewertung des Ergebnisses im Vergleich zu anderen ähnlichen Experimenten.
Die Stichprobe enthält also verschiedene Prädiktoren mit ihren eigenen numerischen Indikatoren, und diese Daten beschreiben in ihrer Gesamtheit das beobachtete Phänomen, dessen Merkmale oder Art in der Zielfunktion (im Folgenden als Zielfunktion bezeichnet) beschrieben werden. Die Zielfunktion in der Stichprobe kann entweder ein numerischer Indikator oder ein kategorischer Indikator sein. Im weiteren Verlauf des Textes werde ich eine kategoriale und in größerem Maße eine binäre Zielfunktion betrachten.
Wikipedia bietet folgende Definition:
Die Quantisierung ist in der digitalen Signalverarbeitung eine Abbildung, die bei der Digitalisierung von Analogsignalen und zur Komprimierung von Bildern und Videos verwendet wird. Die dabei entstehende Abweichung wird Quantisierungsabweichung genannt. Eine elektronische Komponente oder eine Funktion, die diese Abbildung eines Wertes oder eines Signals ausführt, heißt Quantisierer. Der Signalwert kann je nach Kodierungsmethode entweder auf den nächstliegenden Pegel oder auf den niedrigeren bzw. höheren der nächstliegenden Pegel gerundet werden. Diese Quantisierung wird als skalar bezeichnet. Es gibt auch die Vektorquantisierung — die Aufteilung des Raums der möglichen Werte einer Vektorgröße in eine endliche Anzahl von Regionen und die Ersetzung dieser Werte durch die Kennung einer dieser Regionen.
Mir gefällt die kürzere Definition:
Die Datenquantisierung ist eine Methode zur Komprimierung (Kodierung) von Beobachtungsinformationen mit einem akzeptablen Verlust an Genauigkeit in der Messskala. Die Komprimierung (Kodierung) impliziert die Diskretion von Objekten, was deren Gleichartigkeit und Homogenität oder einfach Ähnlichkeit voraussetzt. Das Ähnlichkeitskriterium kann je nach dem gewählten Algorithmus und der darin enthaltenen Logik unterschiedlich sein.
Die Datenquantisierung wird überall eingesetzt, insbesondere bei der Umwandlung eines analogen in ein digitales Signal sowie bei der anschließenden Komprimierung des digitalen Signals. Beispielsweise können die von der Kameramatrix empfangenen Daten als Rohdatei aufgezeichnet und dann sofort (oder später auf einem Computer) in ein jpg-Format oder ein anderes geeignetes Datenspeicherformat komprimiert werden.
Betrachtet man die grafische Darstellung der Daten in Form von Kerzen oder Balken im MetaTrader 5-Terminal, so sieht man bereits das Ergebnis der Arbeit der Quantisierung der Ticks auf der von uns gewählten Zeitskala. Die Quantisierung eines kontinuierlichen Datenstroms über die Zeit wird gewöhnlich als Abtastung (oder Diskretisierung) bezeichnet.
Unter Stichprobenbildung versteht man in der Regel die Erfassung von Beobachtungsmerkmalen mit einer bestimmten Häufigkeit über einen bestimmten Zeitraum. Wenn wir jedoch davon ausgehen, dass dies die Häufigkeit ist, mit der Daten in einer Stichprobe erhoben werden, dann sollte die Definition wie folgt angepasst werden: „Sampling ist der Prozess der Aufzeichnung von Beobachtungsmerkmalen, deren Häufigkeit durch eine bestimmte Funktion während ihrer Schwellenwertaktivierung bestimmt wird“. Unter einer Funktion ist hier jeder Algorithmus zu verstehen, der gemäß seiner eigenen Logik ein Signal zum Empfang von Daten gibt. Im MetaTrader 5 sehen wir zum Beispiel genau diesen Ansatz, denn an handelsfreien Tagen wird der Schlusskurs nicht als ein über die Zeit andauernder Prozess wiederholt, sondern es gibt einfach keine Informationen auf dem Chart, d.h. die Abtastrate sinkt auf Null.
Ein einfaches Beispiel für einen Quantisierungsalgorithmus ist die Erstellung eines Histogramms. Der Algorithmus für diese Methode ist recht einfach:
- Ermittle Maximum und Minimum des Indikators (in unserem Fall des Prädiktors).
- Berechne die Differenz zwischen dem Maximum und Minimum des Indikators.
- Teile das sich ergebende Delta aus Punkt 2 durch eine ganze Zahl, z. B. zehn, oder, je nach Anzahl der Beobachtungen (wie von Karl Pearson empfohlen). Ermittle den Teilungsschritt in den ursprünglichen Maßeinheiten, der die Ablesung der neuen Messskala sein wird.
- Jetzt müssen wir unsere eigene Skala mit unseren eigenen Abteilungen aufbauen. Dies geschieht einfach durch Multiplikation des Schrittes mit der laufenden Nummer der Ablesung.
- Anschließend wird jeder Beobachtungswert dem Bereich einer neuen Messskala zugeordnet, und die Anzahl der Beobachtungen in jedem Bereich wird separat summiert.
Das Ergebnis des Algorithmus ist das in Abbildung 1 dargestellte Histogramm.
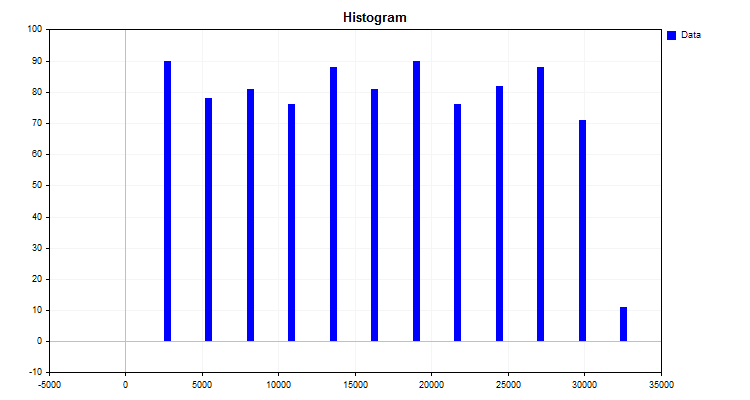
Abbildung 1
Das Histogramm zeigt, wie die Daten nach der neuen Messskala verteilt sind. Anhand des Erscheinungsbildes der Verteilung kann man mit Hilfe der deskriptiven Statistik auf die Art der Verteilungsdichte schließen, was für die Wahl einer endlichen Quantisierungsmethode nützlich sein kann. Über die Verteilungsdichte können Sie in den folgenden Artikeln lesen:
- Kernel-Dichte-Schätzung der unbekannten Wahrscheinlichkeitsdichtefunktion;
- Statistische Verteilungen in MQL5 - das Beste aus R herausholen und es schneller machen;
- Statistische Schätzungen.
Was wir also durch die Erstellung eines Histogramms erhalten haben:
- Ebenen (Cutoffs) oder Grenzen, die die Daten in Gruppen unterteilen. Ein Satz von Ebenen wird als Quantengitter oder Wörterbuch bezeichnet - auf diesen Ebenen erfolgt die Kodierung der Daten, was ihre Gruppierung und Komprimierung gewährleistet. Die Grenzen können nach verschiedenen, in den Quantisierungsalgorithmus eingebetteten Regeln festgelegt werden. Die Ebenen (Cutoffs) bilden eine neue Skala zur Messung von Beobachtungsindikatoren. Ich bin es gewohnt, den Bereich zwischen zwei Niveaus als „Quantensegment“ zu bezeichnen, obwohl sich in den Werken anderer Autoren andere Bezeichnungen finden — „Intervall“, „Bereich“ oder „Quantisierungsschritt“;
- Die Zugehörigkeit der einzelnen Beobachtungswerte (Indikatoren) zu einer bestimmten Gruppe (Histogrammspalte). Bei der Quantisierung handelt es sich um die Arbeit eines Kompressionsalgorithmus, dessen Wesen darin besteht, die ursprünglichen Daten in dem Moment in komprimierte Daten umzuwandeln, in dem der Beobachtungswert einem bestimmten Bereich des Quantengitters zugewiesen wird. Das Ergebnis der Komprimierung können verschiedene numerische Transformationen des Variablenwerts sein. Zwei Optionen kommen am häufigsten vor: die erste ist die Transformation, bei der einer Variablen ein Rang (Index) entsprechend der Zahl des Bereichs zwischen den Werten der Cutoffs (Grenzen) zugewiesen wird, in den die Zahl fällt, und die zweite Option ist die Zuweisung eines Niveauskalenwerts zu der Variablen, z. B. wenn der numerische Wert einer Beobachtung in den Bereich zwischen 1,2 und 1,4 fällt, dann wird der richtige Wert zugewiesen - 1,4. Um die zweite Option zu nutzen, müssen wir jedoch Grenzen festlegen, über die die Daten nicht hinausgehen, während die erste Option es Ihnen erlaubt, mit beliebigen Werten außerhalb der Grenzen der Quantentabelle zu arbeiten. Bei der zweiten Option könnte eine gute Lösung darin bestehen, die Hinzufügung von Ebenen (Rändern/Grenzen) in einem beträchtlichen Abstand zu erzwingen, sodass Fehler in Form von Spitzen oder fehlenden Daten dort platziert werden können.
- Die Fähigkeit, jeden Zahlenwert mit Verlust an Genauigkeit wiederherzustellen (Dequantisierung), was auf folgende Weise geschehen kann:
- - Entlang der Mitte des Intervalls, das dem Index der Zahl entspricht.
- - Durch den linken oder rechten Pegelwert (Begrenzung/Abschneidung/Rand) des Intervalls, meistens den rechten. Da die Grenzen in der Quantisierungstabelle in der Regel für das erste und das letzte Intervall nicht definiert sind, können wir den durchschnittlichen Bereich der Intervalle oder den ersten und den letzten Wert der Intervallbreite verwenden, um sie zu bestimmen.
Je nach Aufgabe und Anwendungsgebiet der Quantisierung hat man es mit unterschiedlichen Bezeichnungen der Variablen und der Schreibweise der Gleichungen zu tun, was das Verständnis des Wesens des Algorithmus erschwert, da der Autor, der sie beschreibt, Kenntnisse aus dem spezifischen Anwendungsgebiet des Algorithmus voraussetzt. Das Wesen der verschiedenen Algorithmen besteht darin, dass sie unterschiedliche Niveaus (Cutoffs) konstruieren. Ich schlage daher vor, sie nach einer Reihe von Kriterien zu klassifizieren.
Quantisierung mit konstantem Intervall:
- Einteilung in feste Intervalle nach einer dem Pearson-Histogramm ähnlichen Methode;
- Umrechnung zur Verringerung der Ziffern einer Zahl.
Variable Intervallquantisierung:
- Kumulierung eines festen Prozentsatzes von Beobachtungen für jedes Intervall.
- Verwendung eines festen Wertes für die Fläche unter der Kurve einer theoretischen oder approximativen Verteilung.
- Verwendung einer bestimmten Funktion, die den Quantisierungsschritt in Abhängigkeit vom Koeffizienten ändert. Dabei handelt es sich oft um Funktionen, die den Abstand zum Rand oder zur Mitte hin vergrößern.
- Verwendung von Gewichtungskoeffizienten, die das Intervall in Abhängigkeit von der Dichte der Werte beeinflussen.
- Iterative Methoden (einschließlich adaptiver Methoden). Die Informationen über die Datenstruktur werden verwendet, um die Grenzen zu konfigurieren, und es werden Maßnahmen ergriffen, um den Fehler zu verringern.
- Andere Methoden.
Quantisierung mit einem empirisch ermittelten Intervall:
- Zahlenfolgen;
- Kenntnisse über die Art der Beobachtung, die es ermöglichen, Indikatoren mit ähnlicher Bedeutung zu gruppieren;
- Manuelle Markierung.
Die Verringerung des Quantisierungsfehlers in der gewählten Metrik kann ein iterativer Prozess sein, oder sie kann einmalig anhand einer vorgegebenen Gleichung berechnet werden. Zur Bewertung des Ergebnisses ist es zweckmäßig, den durchschnittlichen Prozentsatz der Fehlerspanne in Bezug auf den gesamten Bereich der Zahlen zu verwenden, die den Wert des Prädiktors in der Stichprobe annehmen.
2. Implementierung eines Quantisierungsalgorithmus in MQL5
Zuvor haben wir uns ein einfaches Beispiel für die Funktionsweise der Quantisierung angesehen, bei dem jedoch einer der Schritte fehlt, die häufig bei der Quantisierung verwendet werden, nämlich die Neuaufteilung der nach einigen Berechnungen erhaltenen Skala, um den Durchschnittswert des Intervalls zu finden, der oft als Schwerpunkt bezeichnet wird. Das Intervall für die Quantisierung wird schließlich durch die Hälfte des Abstands zwischen den Grenzen zweier nahe beieinander liegender Zentroide bestimmt.
Betrachten wir eine schrittweise Quantisierung von reellen Zahlen wie double, die 8 Bytes im Speicher belegen, in den gesamten Datentyp uchar, der nur 8 Bits belegt:
- 1. Suche nach dem Maximum und Minimum in den Eingabedaten:
- 1.1. Ermittele der Höchst- und Mindestwerte - Max- und Min-Variable im Array arr_In_Data.
- 2. Berechne die Fenstergröße zwischen den Intervallen:
- 2.1. Ermittele die Differenz zwischen dem Maximum und dem Minimum und speichere sie in der Variablen Delta.
- 2.2. Ermittele die Größe eines Fensters Delta/nQ, wobei nQ die Anzahl der Separatoren (Ränder) ist, und speichere das Ergebnis in der Variablen Interval_Size.
- 3. Durchführen von Quantisierung und Fehlerberechnung:
- 3.1. Verschiebe den Mindestwerts der Eingangsdaten auf Null arr_In_Data-Min.
- 3.2. Teile das Ergebnis von Punkt 3.1 durch die Anzahl der Intervalle von Interval_Size, die um eins größer ist als die Anzahl der Separatoren.
- 3.3. Nun sollten wir die Funktion „round“, die die Zahl auf die nächste ganze Zahl rundet, auf das in 3.2 erhaltene Ergebnis anwenden. Das Ergebnis wird in dem Array arr_Output_Q_Interval gespeichert.
- 3.4. Multipliziere den Wert aus dem Array arr_Output_Q_Interval mit Interval_Size und addiere das Minimum. Jetzt haben wir den umgewandelten (quantisierten) Wert der Zahl, den wir in dem Array arr_Output_Q_Data speichern werden.
- 3.5. Berechne den Fehler als kumulierte Summe. Dazu wird die absolute Differenz zwischen dem Originalwert und dem durch die Quantisierung erhaltenen Wert durch den Bereich geteilt. Teile die resultierende Summe durch die Anzahl der Elemente im Array arr_In_Data.
- 4. Speichere die Separatoren (Ränder) in das Array arr_Output_Q_Book:
- 4.1. Für das erste Intervall nehmen wir eine Änderung vor - wir fügen die Hälfte der Größe des Intervalls (Interval_Size) zum Mindestwert (Min) hinzu.
- 4.2. Nachfolgende Intervalle werden berechnet, indem der Intervallwert zu dem Wert des Arrays arr_Output_Q_Book des vorherigen Schritts addiert wird.
Nachfolgend finden Sie ein Beispiel für einen Funktionscode mit der Beschreibung von Variablen und Arrays.
/+---------------------------------------------------------------------------------+ //|Quantization of transformation (encoding) type to a given integer bitness //+---------------------------------------------------------------------------------+ double Q_Bit( double &arr_Input_Data[],//Quantization data array int &arr_Output_Q_Interval[],//Outgoing array with intervals containing data double &arr_Output_Q_Data[],//Outgoing array with restored values of the original data float &arr_Output_Q_Book[],//Outgoing array - "Book with boundaries" or "Quantization table" int N_Intervals=2,//Number of intervals the original data should be divided (quantized) into bool Use_Max_Min=false,//Use/do not use incoming maximum and minimum values double Min_arr=0.0,//Maximum value double Max_arr=100.0//Minimum value ) { if(N_Intervals<2)return -1;//There may be at least two intervals, in this case, there is one separator //---0. Initialize the variables and copy the arr_Input_Data array double arr_In_Data[]; double Max=0.0;//Maximum double Min=0.0;//Minimum int Index_Max=0;//Maximum index in the array int Index_Min=0;//Minimum index in the array double Delta=0.0;//Difference between maximum and minimum int nQ=0;//Number of separators (borders) double Interval_Size=0.0;//Interval size int Size_arr_In_Data=0;//arr_In_Data array size double Summ_Error=0.0;//To calculate error/data loss nQ=N_Intervals-1;//Number of separators Size_arr_In_Data=ArrayCopy(arr_In_Data,arr_Input_Data,0,0,WHOLE_ARRAY); ArrayResize(arr_Output_Q_Interval,Size_arr_In_Data); ArrayResize(arr_Output_Q_Data,Size_arr_In_Data); ArrayResize(arr_Output_Q_Book,nQ); //---1. Finding the maximum and minimum in the input data if(Use_Max_Min==false)//If enforced array limits are not used { Index_Max=ArrayMaximum(arr_In_Data,0,WHOLE_ARRAY); Index_Min=ArrayMinimum(arr_In_Data,0,WHOLE_ARRAY); Max=arr_In_Data[Index_Max]; Min=arr_In_Data[Index_Min]; } else//Otherwise enforce the maximum and minimum { Max=Max_arr; Min=Min_arr; } //---2. Calculate the window size between intervals Delta=Max-Min;//Difference between maximum and minimum Interval_Size=Delta/nQ;//Size of one window //---3. Perform quantization and error calculation for(int i=0; i<Size_arr_In_Data; i++) { arr_Output_Q_Interval[i]=(int)round((arr_In_Data[i]-Min)/Interval_Size); arr_Output_Q_Data[i]=arr_Output_Q_Interval[i]*Interval_Size+Min; Summ_Error=Summ_Error+(MathAbs(arr_Output_Q_Data[i]-arr_In_Data[i]))/Delta; } //---4. Save separators (borders) into the array for(int i=0; i<nQ; i++) { switch(i) { case 0: arr_Output_Q_Book[i]=float(Min+Interval_Size*0.5); break; default: arr_Output_Q_Book[i]=float(arr_Output_Q_Book[i-1]+Interval_Size); break; } } return Summ_Error=Summ_Error/(double)Size_arr_In_Data*100.0; }
Praktische Anwendung der Datenquantisierung:
- Verringerung des Speicherbedarfs für die Speicherung und Verarbeitung von Daten. Dieser Effekt wird dadurch erreicht, dass es ausreicht, nur den Index des Quantensegments zu speichern, in das der numerische Wert der Indikatornummer fällt. In diesem Fall ist es sinnvoll, den Datentyp von real double oder float auf ganzzahlige Typen wie int oder sogar uchar zu ändern.
- Beschleunigung der Berechnungen. Erreicht wird dies durch die Arbeit mit ganzen Zahlen und die Verringerung der Menge der verwendeten Zahlen, wodurch sich die Anzahl der Zyklen in den Algorithmen verringert.
- Rauschunterdrückung. Die Qualität der Quelldaten kann Rauschen in Form von Messfehlern enthalten, sowohl in Form von primären Datenverlusten des Brokers als auch in Form von Verzögerungen, Rundungen und Messfehlern. Durch die Quantisierung wird der Indikator im Bereich des Quantensegments gemittelt, wodurch dieses Rauschen geglättet wird und das Modell sich nicht darauf konzentrieren kann.
- Ausgleich für das Fehlen von Nahbeobachtungswerten. Manchmal ist ein Prädiktorwert aufgrund eines Mangels an Beobachtungen sehr selten und kann nicht als Spike betrachtet werden. Die Quantisierung kann solchen Beobachtungen einen ausreichenden Wertebereich verleihen, um das Modell für neue Daten, die nicht in der Stichprobe enthalten waren, nutzbar zu machen.
- Kampf gegen den Fluch der Dimensionalität. Durch die Verringerung der Anzahl möglicher Kombinationen wird das Raster der möglichen Koordinaten der Messräume verkleinert, was die Ausbildung beschleunigt und verbessert.
Anhand von zwei Beispielen wurden zwei wichtige Quantisierungsstrategien vorgestellt:
- Strategie der Datenannäherung.
- Strategie der Datenaggregation.
Die erste Art von Strategie eignet sich am besten für metrische Skalen, die Indikatoren messen, deren Verteilung der Merkmalswerte einer kontinuierlichen Verteilung nahe kommt. Theoretisch gilt: Je mehr Intervalle den Wertebereich trennen, desto besser, da der Fehler in der Streuung des rekonstruierten Wertes über den gesamten Bereich der Zahlenreihe kleiner ist. Dieser Typ eignet sich gut für die Wiederherstellung mathematischer Funktionen.
Die zweite Art von Strategie zielt auf die Gruppierung von Daten ab. Man kann sich vorstellen, dass verallgemeinerte kategoriale Werte von Merkmalen erstellt werden, und hier ist die Aufgabe, die Grenzen richtig zu schätzen, viel schwieriger. Meiner Erfahrung nach müssen wir sicherstellen, dass mindestens 5 % der Beobachtungen aus der Stichprobe in das Intervall fallen.
Es ist anzumerken, dass die Merkmale, die bereits eine kategorische Bedeutung haben, ohne jegliche Konventionen, sehr sorgfältig quantifiziert werden sollten, indem nur die wirklich ähnlichen Merkmale kombiniert werden. Außerdem bedeutet Ähnlichkeit hier die Ähnlichkeit der Stichprobe, wenn sie in Teilstichproben unterteilt wird.
Dem Artikel ist das Skript „Q_Trans“ beigefügt, das als Beispiel für den Quantisierungsprozess dient. Die Daten für die Quantisierung werden nach dem Zufallsprinzip erzeugt. Das Skript enthält die folgenden Hauptfunktionen:
- „Q_Bit“ - zur Quantisierung der Umwandlungsart (Kodierung) auf eine bestimmte ganzzahlige Bittiefe.
- „Book_to_cifra“ - der Decoder stellt den ungefähren Wert einer Zahl aus der Quantisierungstabelle wieder her, ein Array mit Indizes ist erforderlich.
- „Book_to_cifra_v2“ - der Decoder stellt den ungefähren Wert einer Zahl aus der Quantisierungstabelle wieder her, ein Array mit Indizes ist nicht erforderlich.
- „Q_Random“ - zur Quantisierung mit zufälligen Grenzen.
Das Skript enthält die folgenden Einstellungen:
- Die Anzahl der Intervalle, in die die Originaldaten unterteilt (quantisiert) werden sollen;
- Initialisierungsnummer für den Zufallszahlengenerator;
- Charts speichern;
- Verzeichnis zum Speichern von Diagrammen;
- Breite des Charts;
- Höhe des Charts;
- Schriftgröße.
Beschreibung der Arbeitsschritte des Skripts:
- Es wird eine Stichprobe nach dem Zufallsprinzip gezogen.
-
Das Chart des Handelsinstruments zeigt ein Histogramm, das wie in diesem Artikel beschrieben erstellt wurde (Abbildung 1), sowie das Chart mit den Werten des generierten Prädiktors in chronologischer Reihenfolge und geteilt durch die nach der Quantisierung erhaltenen Grenzen (Abbildung 2). Wenn „Save charts“ (Charts speichern) „true“ ist, werden die Diagramme im Verzeichnis mit den nutzerdefinierten Terminaldateien „Files\Q_Trans\Grafics“ gespeichert.
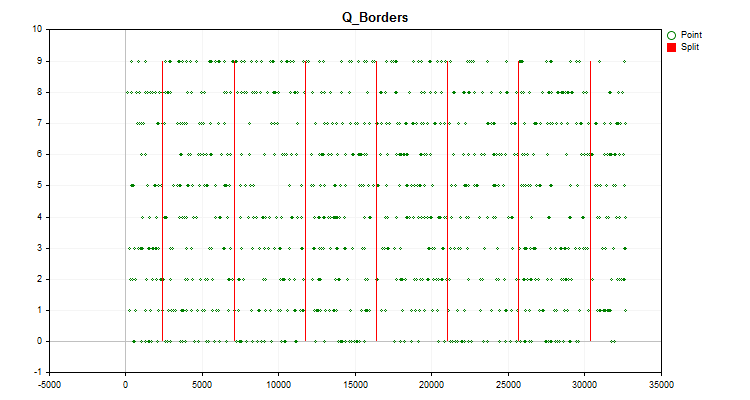 Abbildung 2.
Abbildung 2. - Mit der Funktion Q_Bit wird die Quantisierung durchgeführt und der Fehler in Form eines Offsets des rekonstruierten Wertes relativ zum gesamten Bereich der Abtastwerte berechnet.
- Mit der Funktion Book_to_cifra wird eine Dequantisierung entlang des Schwerpunkts durchgeführt und der Fehler in Form eines Offsets des rekonstruierten Wertes berechnet.
- Die Funktion Book_to_cifra wird verwendet, um die Dequantisierung entlang des rechten Randes durchzuführen und den Fehler in Form eines Offsets des rekonstruierten Wertes zu berechnen.
- Die Funktion Book_to_cifra_v2 wird verwendet, um eine Dequantisierung entlang des Schwerpunkts durchzuführen und den Fehler in Form eines Offsets des rekonstruierten Werts zu berechnen.
- Mit der Funktion Q_Random werden 1000 Versuche unternommen, um die besten Intervalle für die Aufteilung des Prädiktors zu finden.
- Mit der Funktion Book_to_cifra wird eine Dequantisierung entlang des Schwerpunkts unter Verwendung eines zufällig ermittelten besten Gitters durchgeführt und der Fehler in Form eines Offsets des rekonstruierten Werts berechnet.
Wenn wir das Skript mit den Standardeinstellungen ausführen, sehen wir im Experts-Terminalprotokoll in der Spalte „Message“ die folgenden Informationen
Average data recovery error size = 3.52% of full range when using 8 intervals Average error size via quantum table for centroid conversion (Book_to_cifra) = 1145.62263 Average error size via quantum table for right boundary conversion (Book_to_cifra) = 2513.41952 Average error size via quantum table for centroid transformation (Book_to_cifra_v2) = 1145.62263 Average error size via quantum table for centroid transformation (Q_Random) = 1030.79216
Interessant ist, dass die Zufallsmethode für die Auswahl der Grenzen sogar bessere Ergebnisse als die zuvor betrachtete Methode (basierend auf einer gleichmäßigen Quantisierung) zeigt.
3. Quantisierungen mit CatBoost
CatBoost, über das ich bereits in meinem Artikel „Der Algorithmus CatBoost von Yandex für das maschinelle Lernen, Kenntnisse von Python- oder R sind nicht erforderlich“ geschrieben habe, verwendet Quantisierung für die Datenvorverarbeitung, was den Betrieb des Gradient-Boosting-Algorithmus erheblich beschleunigen kann. Wie bisher werde ich die Konsolenversion von CatBoost verwenden, da sie keine Installation zusätzlicher Software erfordert, wenn sie auf dem Hauptprozessor des Computers arbeitet.
Wir benötigen die folgenden Einstellungen:
1. Quantisierungsmethode (Division) – Schlüssel "--feature-border-type":
- Median
- Uniform
- UniformAndQuantiles
- MaxLogSum
- MinEntropie
- GreedyLogSum
2. Anzahl der Separatoren von 1 bis 65535 - Schlüssel "--border-count"
3. Speichern von Quantisierungstabellen in der angegebenen Datei - Schlüssel "--output-borders-file"
4. Laden von Quantisierungstabellen aus der angegebenen Datei - Schlüssel "--input-borders-file"
Wenn wir die oben beschriebenen Schlüssel nicht angeben, werden die folgenden Einstellungen für die Erstellung der in diesem Artikel verwendeten Modelle verwendet:
- Für die Berechnung auf der CPU ist die Quantisierungsmethode „GreedyLogSum“, die Anzahl der Separatoren ist „254“;
- Für GPU-Berechnungen ist die Quantisierungsmethode „GreedyLogSum“, die Anzahl der Separatoren ist „128“.
Schauen wir uns an, wie man diese Schlüssel registriert:
Richten wir die Quantisierung ein, indem wir die Methode „Uniform“ und die Anzahl der Separatoren auf 30 einstellen, und speichern die Quantisierungstabelle in der Datei Quant_CB.csv:
catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description Test_CB_Setup_0_000000000 --has-header --delimiter ; --train-dir ..\Rezultat --feature-border-type Uniform --border-count 30 --output-borders-file Quant_CB.csv
Wir laden die Quantisierungstabelle aus der Datei Quant_CB.csv und trainieren das Modell:
catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description Test_CB_Setup_0_000000000 --has-header --delimiter ; --train-dir ..\Rezultat --input-borders-file Quant_CB.csv
Sie finden den Abschnitt über die Quantisierungseinstellungen in der Anleitung des Entwicklers hier.
Sehen wir uns an, wie sich die Quantisierungsmethoden bei der Anwendung auf bestimmte Daten unterscheiden. Nachfolgend finden Sie die Diagramme in Form von gif-Dateien. Jedes neue Bild ist die nächste Methode. Die Anzahl der Separatoren beträgt 16.
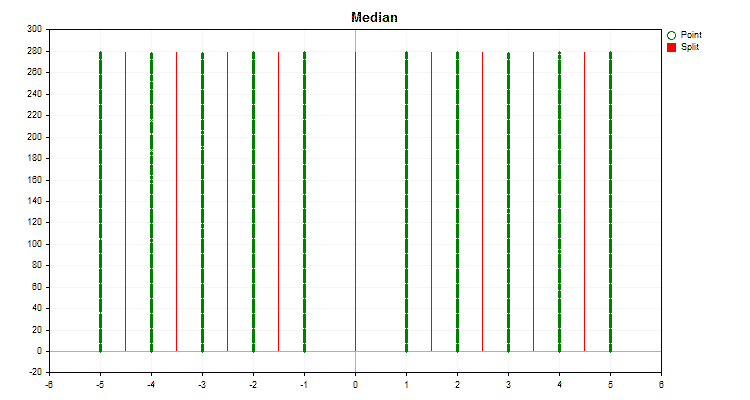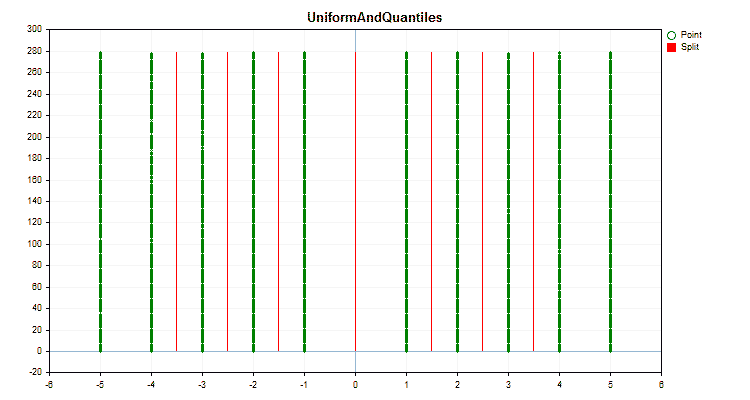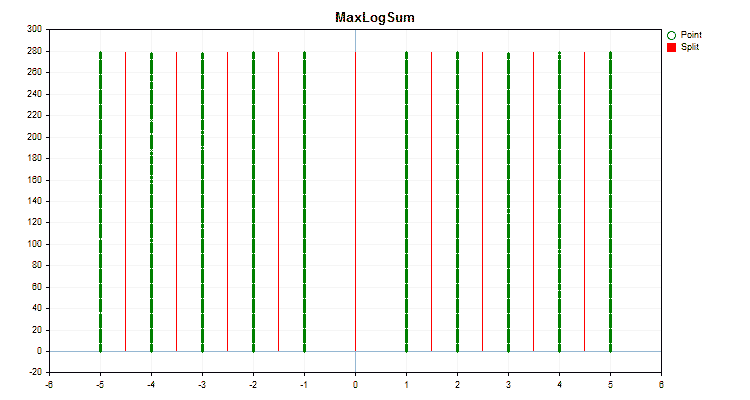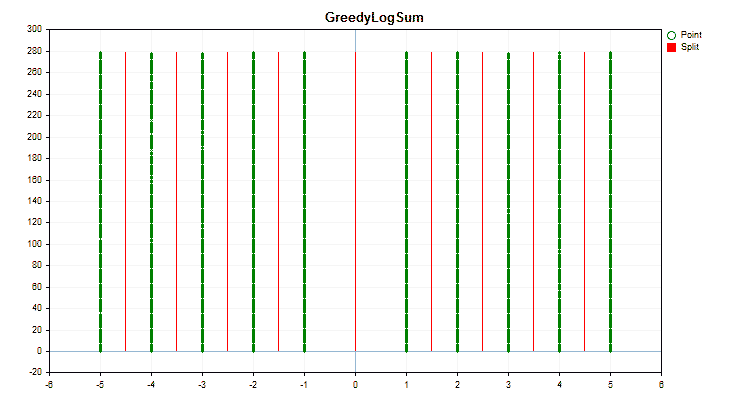
Abbildung 2 „Datendiagramm für den kategorialen Prädiktor“
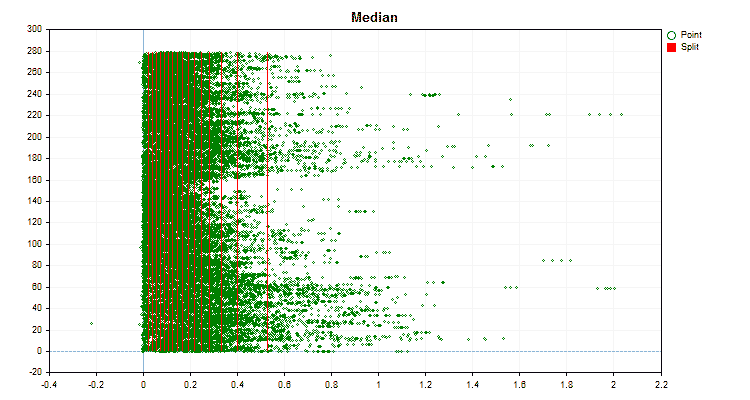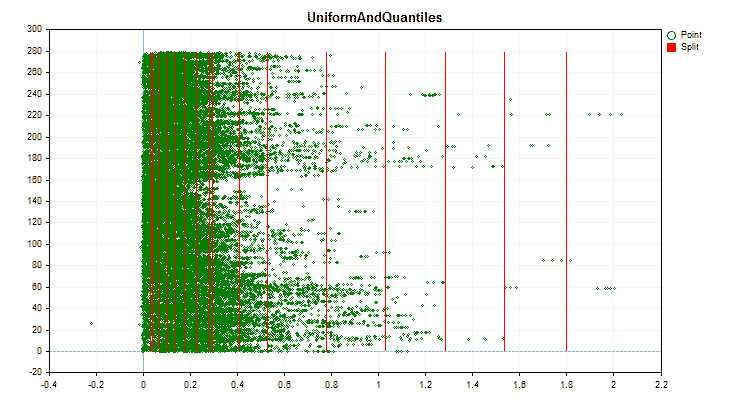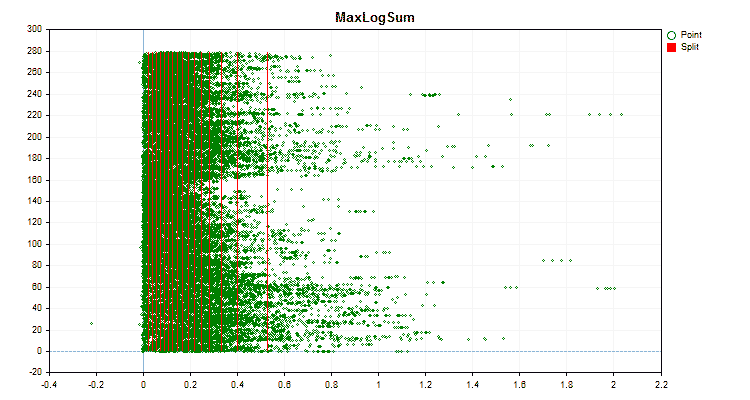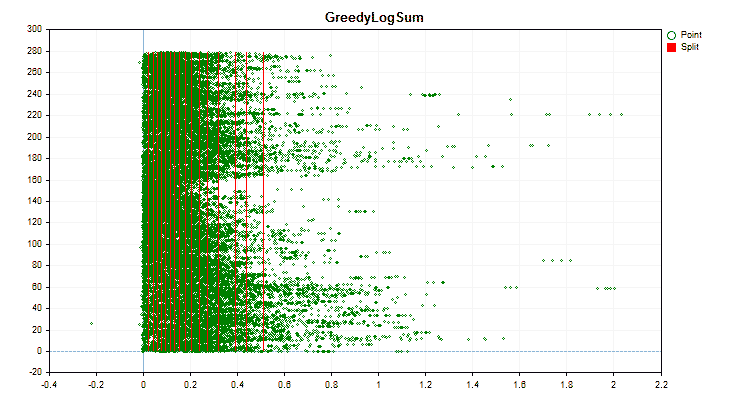
Abbildung 3 „Datendiagramm für den Prädiktor mit in den linken Bereich verschobenen Werten“
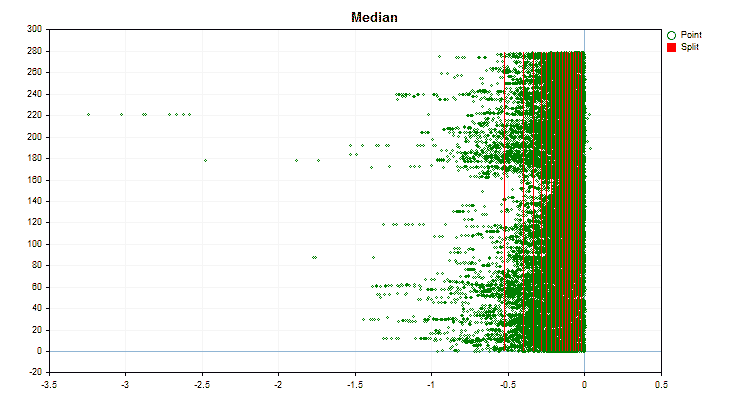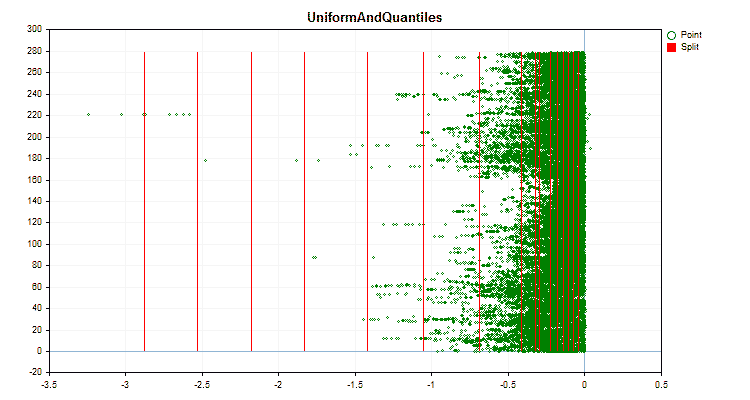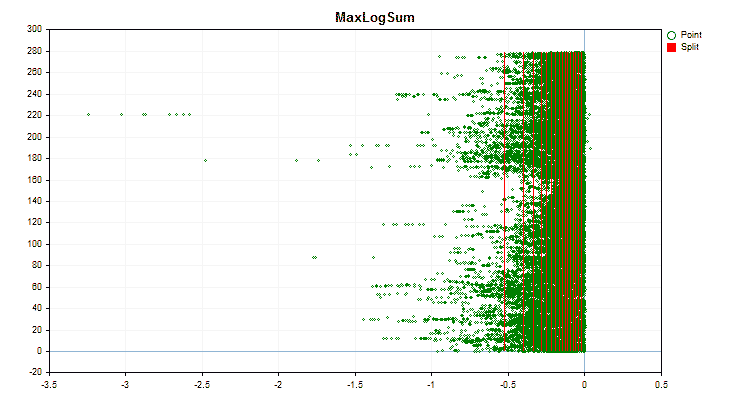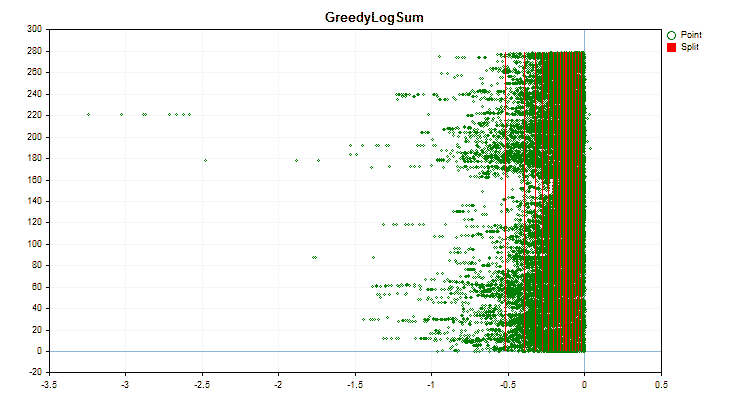
Abbildung 4 „Datendiagramm für den Prädiktor mit in den rechten Bereich verschobenen Werten“
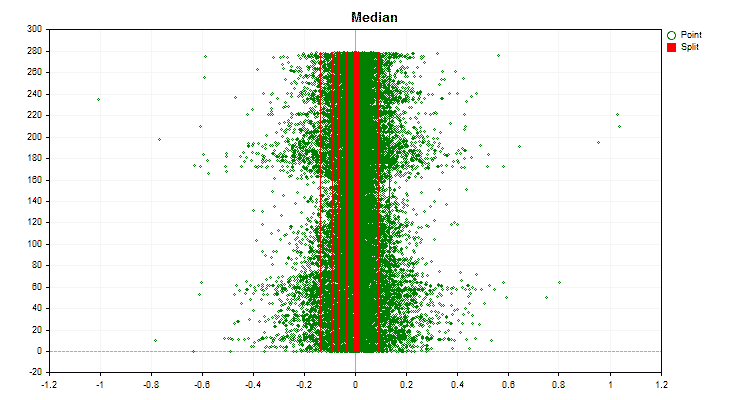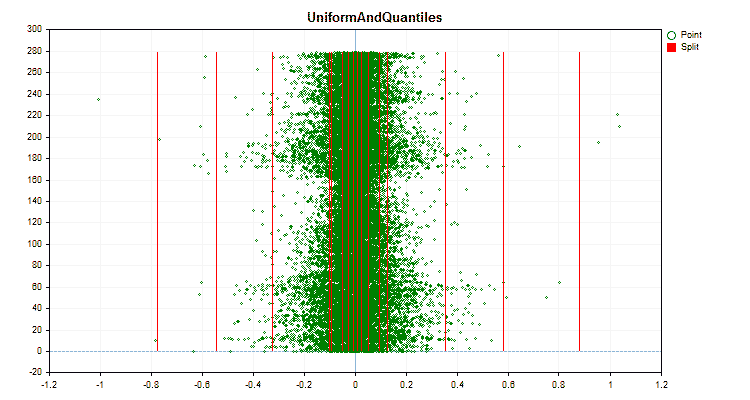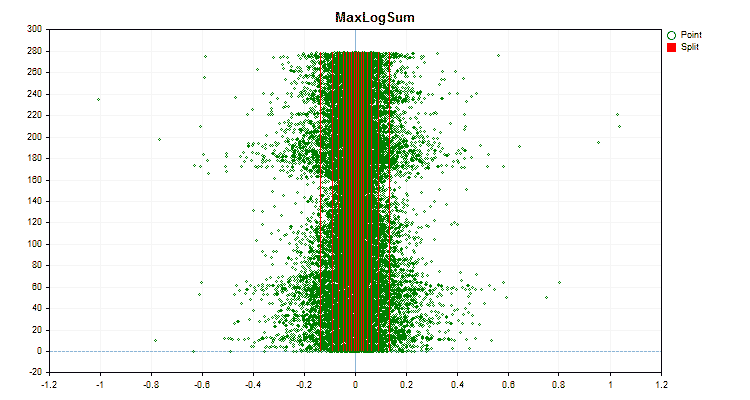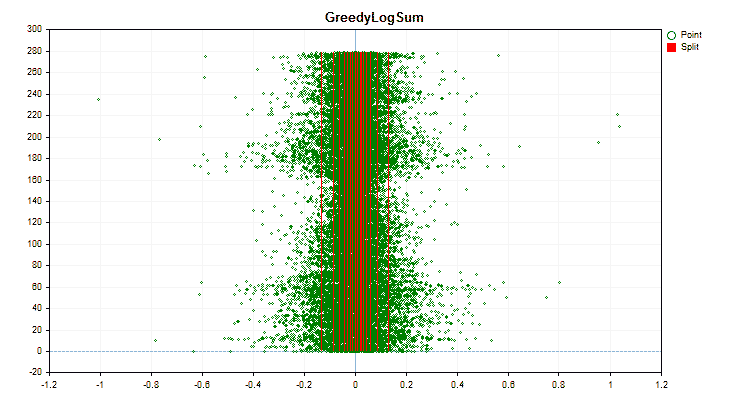
Abbildung 5 „Datendiagramm für den Prädiktor mit Werten im zentralen Bereich“
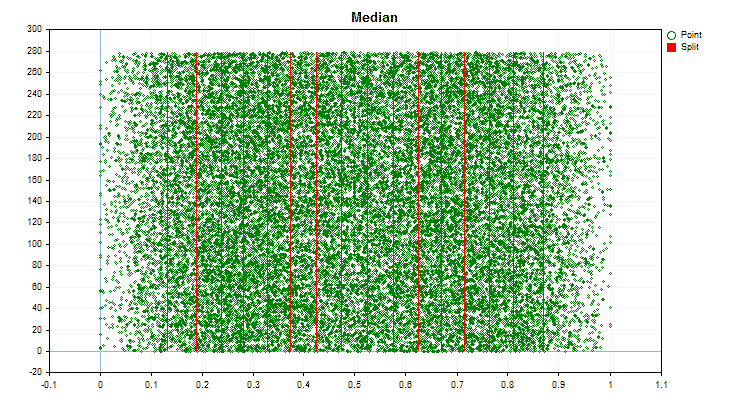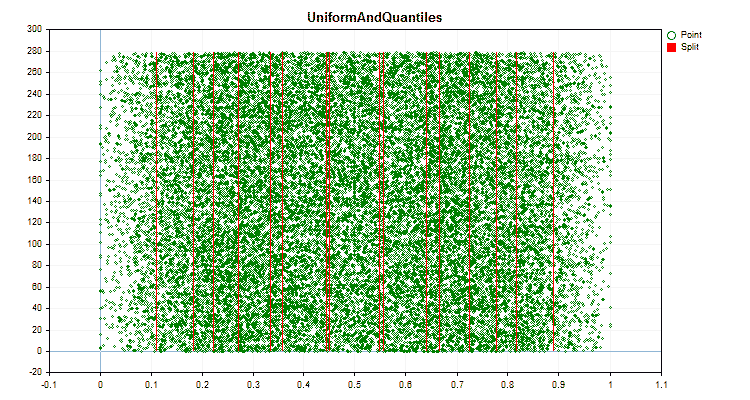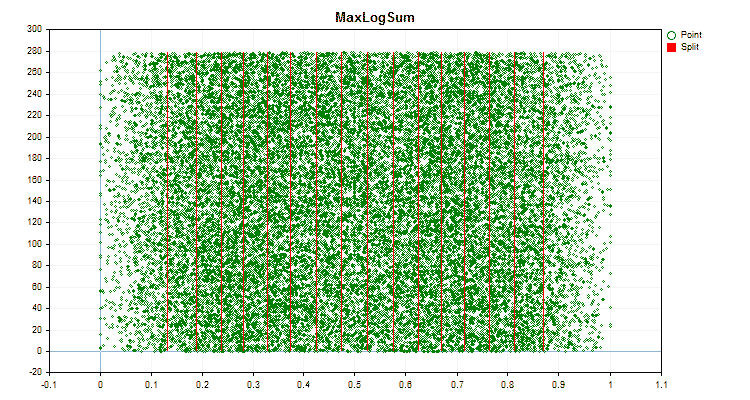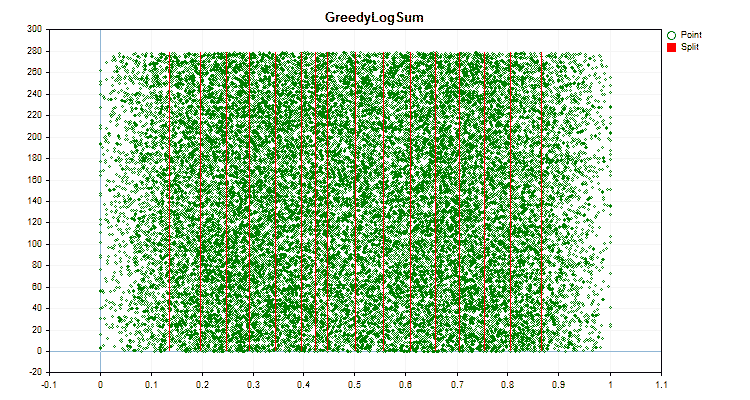
Abbildung 6 „Datendiagramm für den Prädiktor mit gleichmäßiger Verteilung der Werte“
Wenn wir uns die Struktur der Datei mit der Quantisierungstabelle ansehen (in unserem Fall Quant_CB.csv), sehen wir zwei Spalten und viele Zeilen. Die erste Spalte enthält die Seriennummer des Prädiktors, der beim Training des Modells verwendet werden soll, während die zweite Spalte das Trennzeichen (Grenze/Ebene) enthält. Die Anzahl der Zeilen entspricht der kumulativen Summe der Begrenzungszeichen, und die Zahl in der ersten Spalte ändert sich, nachdem alle Begrenzungszeichen aufgelistet worden sind.
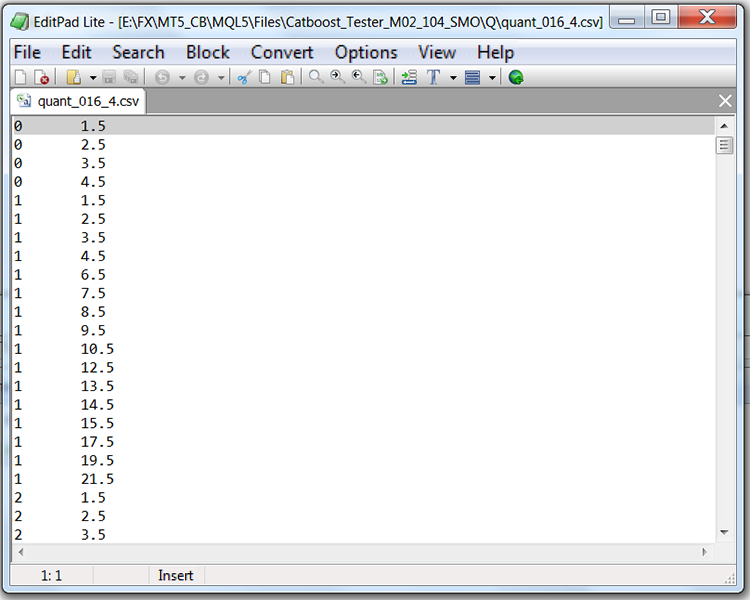
Tabelle 1 „Inhalt der gespeicherten CatBoost-Datei mit Separatoren“
Schlussfolgerung
In diesem Artikel haben wir uns mit dem Konzept der Quantisierung vertraut gemacht, die Gewinnung quantisierter Prädiktorenwerte anhand des MQL5-Codes als Beispiel analysiert und die Implementierung der Quantisierung in CatBoost untersucht.
Wenn Sie terminologische oder sachliche Fehler in diesem Artikel entdeckt haben, können Sie mich gerne kontaktieren.
Im nächsten Artikel werden wir herausfinden, wie man Quantentabellen für einen bestimmten Prädiktor auswählt und ein Experiment durchführen, um die Durchführbarkeit dieser Auswahl zu bewerten.
| # | Anwendung | Beschreibung |
|---|---|---|
| 1 | Q_Trans.mq5 | Skript mit einem Beispiel für eine gleichmäßige Quantisierung einer Zufallsstichprobe. |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13219
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wo wird dies behauptet? Scheint das Wort "Quantisierung" die Erwartungen in die Irre zu führen und zu verzerren?
Danke für den Artikel, interessant!
Sehr aufgeregt über sie!
Sehr interessanter Artikel!
Ich danke Ihnen!
Kann ich Sie als Freund hinzufügen? Ich bin neu in ML. Ich versuche, Modelle zu kodieren und sie in ONNX zu speichern, aber ich erhalte Pflaumenunsinn oder nur eine elementare Erinnerung an historische Daten(
Ich habe Sie hinzugefügt, obwohl mir jeder schreiben kann - es gibt keine Programmbeschränkung.