
Marktpositionierungskodex für den VGT mit Kendall’schen Tau und Distanzkorrelation
Einführung
Die Suche nach einem Vorteil auf den Märkten ist selten direkt. Oft kommt es einem vor, als würde man in einem dunklen Raum nach einer vermissten Katze suchen … während diese Katze ständig darauf aus ist, Ihr Kontoguthaben zu vernichten. Heutzutage werden wir nicht nur mit „Nachrichten“ und Medienlärm überschwemmt, sondern auch mit so vielen Chart-Setups, die alle mit Indikatoren vollgestopft sind, von denen jeder angeblich ein fehlendes Glied im Handelsuniversum darstellt. Bei kritischer Betrachtung stellt sich jedoch immer heraus, dass unsere Probleme nicht darauf zurückzuführen sind, dass wir nicht wissen, was wir verwenden sollen, sondern vielmehr darauf, dass wir nicht wissen, welche Tools wirklich die Arbeit erledigen und welche nur CPU-Zyklen verbrauchen oder Vertrauenspunkte sammeln.
Eine Methode, die von MetaTrader-Nutzern oft vernachlässigt wird, wenn es darum geht, das Rauschen zu unterdrücken, besteht darin, die typische FX-Sandbox komplett zu verlassen. Diese Plattform ist nicht nur ein Arbeitstier in Sachen Währung. Je nach Broker kann man mit Aktien, börsengehandelten Fonds, Rohstoffen, Indizes und einer Vielzahl von nicht-traditionellen Anlagen handeln. Für einige Händler bieten diese Vermögenswerte oft Chancen in einem Bereich, in dem man argumentieren könnte, dass die „Marktschreier“ nicht „Ellbogen an Ellbogen“ stehen. Ein Beispiel, das dies verdeutlicht, sind hoch reaktive ETFs wie der VGT.
Der VGT, der sich fast ausschließlich auf Mega-Cap-Technologien konzentriert, verhält sich nicht wie ein Devisenpaar. Außer an Wochenenden oder bei sehr seltenen Gelegenheiten zeigen die Währungspaare kontinuierliche Kurse ohne größere Aufwärts- oder Abwärtslücken. Vor kurzem, am 6. Oktober dieses Jahres, gab es eine Kurslücke im JPY, aber das war über das Wochenende und nachdem Japan einen neuen Premierminister bekommen hatte. Im Devisenhandel kommen diese Lücken vor, aber aufgrund der enormen Menge an verfügbarer Liquidität sind sie eher die Ausnahme als die Regel. Wenn man sich das Kurschart des VGT anschaut, sind Kurslücken selbst auf dem täglichen Zeitrahmen so ziemlich die Norm. Diese Lücken können einige Händler abhalten, die es vorziehen, in hochliquiden Umgebungen zu handeln, aber sie können auch Gelegenheiten bieten, sich einen Vorteil zu verschaffen, was MT5 in gewissem Sinne bietet.
Die Möglichkeit, mit verschiedenen Arten von Vermögenswerten zu experimentieren und ähnliche Toolkits für verschiedene Arten von Vermögenswerten zu verwenden, sind einige der Vorteile dieser Lösung. Die Kehrseite der Medaille ist jedoch, dass ein unübersichtliches Chart oder, wie in unserem Fall, ein Expert Advisor, der sich auf zu viele Tools stützt, noch gefährlicher werden kann, wenn es um unruhige Vermögenswerte wie den VGT geht. Redundante oder übermäßig korrelierte Indikatoren flüstern nicht nur Lügen, sie schreien sie sogar heraus, denn es herrscht Einigkeit. Dies kann Einträge verzerren und zu Verurteilungen führen, die auf doppelten Thesen statt auf wirklich unabhängigen Informationen beruhen. Während das Handelssystem drei übereinstimmende Indikatoren registriert, sind es in der Realität oft drei Thermometer, die alle das gleiche Fieber messen.
Um diese Versäumnisse zu vermeiden, brauchen wir einen sauberen, datengestützten Ansatz für die Bewertung dieser Indikatoren, der quantifiziert, was jeder einzelne von ihnen leisten kann oder zu leisten imstande ist. Das ist in gewissem Sinne der Kern der Aufgabe dieses Artikels und einiger ähnlicher Artikel, die wir auf der Basis von einzelnen Vermögenswerten verfolgen. Für diesen Beitrag verwenden wir jedoch das Kendall’sche Tau und Distanz-Korrelation um die Unabhängigkeit der Indikatoren zu messen. Über die Statistiken hinaus werden wir die Signalmuster der einzelnen Indikatoren aufschlüsseln und versuchen, ein geeignetes Paar von Indikatoren für die Musterkombinationen zu finden, die die beste Performance liefern. Kurz gesagt, es geht nicht darum, weitere Tools hinzuzufügen oder neue, ausgefallene Indikatoren einzuführen – vielmehr geht es uns darum, sie gut genug zu verstehen, um tatsächlich einen Vorteil zu schaffen, und zu zeigen, wie MT5 als Testfeld für genau das dienen kann.Was ist VGT
Der Vanguard Information Technology ETF, oft abgekürzt als VGT, ist ein wichtiger Bestandteil des Tech-Sektors. Er dient als Fonds, der die Performance des MSCI US Investable Market Information Technology 25/50 Index nachbildet. Es handelt sich um eine eng zusammengesetzte „Rakete“ aus den größten und einflussreichsten Namen der Technologiebranche, die auch einige kleine und mittelgroße Unternehmen für ein potenzielles Wachstumsengagement enthält. Wenn Sie einen Blick auf seine Beteiligungen werfen, werden Sie die üblichen Verdächtigen wie Microsoft, Apple, Google, Amazon, Nvidia usw. als die wichtigsten prozentualen Beteiligungen erkennen.
Das kollektive Verhalten dieser Large-Cap-Bestände übt oft eine Anziehungskraft aus, die als Hauptmotor für die Entwicklung des gesamten ETF dient. Darunter befinden sich jedoch auch Aktien aus den Bereichen Halbleiter, Software-Infrastruktur, IT-Dienstleistungen und Cloud-Infrastruktur, die als Impulsgeber für den Gesamttrend der ETFs fungieren – auch wenn sie vom Umfang her klein sind, haben sie in der Regel einen großen Einfluss, wenn die Stimmung auf „risk-on“ umschlägt.
Im Gegensatz zu diversifizierteren börsengehandelten Fonds, die das Engagement im Technologiesektor oft über verschiedene Sektoren streuen, ist der VGT unverschämt konzentriert. Dieser ETF verwässert die Verurteilung nicht, sondern verengt sie vielmehr. Dies hat zur Folge, dass sie sich schnell in die eine oder andere Richtung bewegen kann. Anders ausgedrückt: Wann immer der NASDAQ niest, bekommt der VGT entweder eine Erkältung oder erholt sich, als hätte er einen neuen starken Impfstoff entdeckt. So wie der VGT aufgebaut ist, ist Volatilität kein Fehler, sondern eher eine Prämie, die man für eine potenzielle Outperformance zahlt. Wie Warren Buffett einmal sagte, ist Diversifizierung der Feind der Performance.
Seit seiner Gründung im Jahr 2004 ist der Wachstumskurs des VGT fast ein Spiegelbild der digitalen Revolution selbst. Angefangen bei den Anfängen des Web 2.0 bis hin zu den industriellen Anfängen der KI hat sich der VGT im Grunde mit jedem wichtigen technologischen Meilenstein weiterentwickelt. Seine extrem niedrige Kostenquote bietet auch einen strukturellen Vorteil, der es ermöglicht, dass der Großteil der Aktiengewinne dem Anleger und nicht den Kassen des Fondsmanagers zufließt.
In diesem Zusammenhang setzt sich zunehmend die Erkenntnis durch, dass es beim Handel mit dem VGT nicht in erster Linie darum geht, zu kaufen oder zu verkaufen, sondern vielmehr um das Timing von Rotationen innerhalb des internen „Wettersystems“ des Technologiesektors. Das Verhalten des VGT variiert über die Jahreszeiten, die Quartale und die Makrozyklen hinweg. Dies führt uns zu unserem nächsten Abschnitt, in dem es darum geht, worauf wir auf dem Weg ins Jahr 2026 achten sollten, da dieses Thema nicht nur relevant, sondern wohl auch entscheidend ist.
VGT Aktueller Ausblick
Die Saisonalität bei Aktien ist keine Magie oder etwas, das sich Händler ausdenken, sondern ein Rhythmus, der sich aus den Gewohnheiten großer Akteure wie Institutionen, den Konjunkturzyklen und der Psychologie der Anleger ergibt. Darüber hinaus gibt es nur wenige Sektoren, die einen so saisonalen Fingerabdruck aufweisen wie die Technologie. Zu diesem Zweck hat der Vanguard Information Technology ETF oft wie ein Uhrwerk nach diesem Rhythmus getanzt, insbesondere zu den Jahresendterminen.
Historisch gesehen ist das vierte Quartal, in dem wir uns befinden, die Hauptjagdsaison des VGT. In diesem Zeitraum hat die Technologiebranche aufgrund von drei wiederkehrenden Themen häufig besser abgeschnitten als der breite Markt.
- Erstens gibt es oft Impulse von den Gewinnen, die die Stimmung aufhellen.
- Zweitens wird der VGT gegen Ende des Jahres umgeschichtet, wobei das Management Nachzügler ausmustert und die besten Werte aufstockt.
- Und schließlich tragen die weihnachtsbedingten Ausgaben, insbesondere für Hardware, Halbleiter und digitale Dienstleistungen, dazu bei, die Umsatzerwartungen zu steigern.
Dieser Zeitraum überschneidet sich auch mit der Weihnachtsmann-Rallye, bei der die Aktien in den letzten 5 Handelstagen des Dezembers und den ersten beiden des Januars steigen. Bei technologielastigen Instrumenten wie dem VGT nimmt dieser Aufwärtstrend oft schon früh Gestalt an, wenn Fonds, die auf der Suche nach guten Jahreszahlen sind, auf diesen Zug aufspringen. In den letzten Jahren hat sich jedoch gezeigt, dass die Entwicklung nicht für alle zugrunde liegenden Aktien gleichmäßig steigt.
Der Januar-Effekt, der normalerweise als Geschenk für Small-Cap-Aktien angepriesen wird, übt Druck auf den VGT aus, da immer mehr Anleger aus den Mega-Cap-Technologiewerten in die nachlaufenden Sektoren abwandern. Darüber hinaus gibt es auch eine Verdauungsphase nach dem Gewinn, in der die überzogenen Bewertungen einen „Kater“ der Realität bekommen. Im letzten Jahr, 2024, dämpfte diese besondere Phase die „KI-Manie“; 2025, auf dem Weg ins Jahr 2026, könnte die Besorgnis über zu hohe KI-Ausgaben anhalten, vor allem, wenn der Überschwang die Fundamentaldaten übersteigt.
Aus volatilitätsagnostischer Sicht zeigt der VGT zu Beginn des vierten Quartals in der Regel komprimierte Schwankungsbreiten, auf die zum Jahresende hin eine Expansionsphase folgt. Dies ist in der Regel ein geeignetes Terrain für Handelssysteme, die auf adaptive Indikatoren setzen, d. h. auf Indikatoren, die erkennen, wann ruhige Marktphasen in Aktion umschlagen. Um ein geeignetes Indikatorpaar auszuwählen, gehen wir von einem Pool von 5 Paaren aus. Auf dieser Grundlage werden wir das beste Paar ermitteln, wenn wir es mit der jüngsten 5-Jahres-Kursentwicklung des VGT vergleichen. Stellen wir zunächst die Indikatorpaare vor. Anschließend werden wir die Signalmuster für die ausgewählten Indikatoren miteinander verbinden. Daher verfolgen wir in diesem Artikel den folgenden thematischen Ansatz, der im nachstehenden Flussdiagramm skizziert wird.

Verwendete Indikatoren
Bei der Auswahl geeigneter Tools für die Analyse von ETFs mit hoher Dynamik, wie dem VGT, geht es weniger darum, einen Kurschart mit möglichst viel Schnickschnack vollzustopfen, sondern vielmehr darum, Präzision zu wahren. Wir müssen Indikatorenpaare finden, die sich nicht gegenseitig im Weg stehen, sondern als Team agieren. Sie sollten in der Lage sein, die blinden Flecken des jeweils anderen zu ergänzen. Die folgenden 5 Paare von Kandidatenindikatoren, die wir in Betracht ziehen, weisen alle einen einzigartigen Verhaltenswinkel gegenüber den Märkten auf. Diese reichen von Volatilität, Momentum, Trendstärke bis hin zu Erschöpfung. Ein Flussdiagramm, das unsere Methodik bei der Auswahl dieser Indikatoren zusammenfasst, könnte wie folgt dargestellt werden;

Unsere Aufgabe ist es, das Ausmaß zu messen, in dem diese Indikatorpaare in der Lage sind, eigenständig oder unabhängig zu arbeiten, und dann, einmal mit diesen Informationen ausgestattet, den Grad abzuleiten, in dem sie eine kohärente Handelslogik erzeugen können. Hier kommen unsere beiden Algorithmen ins Spiel, die wir im Titel und in der Zusammenfassung des Artikels erwähnt haben – Kendall’sches Tau und Distanzkorrelation. Schauen wir uns zunächst einmal diese Kämpfer an.
Das erste Paar, das wir in Betracht ziehen, ist der ADX-Wilder und der MFI von Bill Williams. Der ADX misst, wie aus dem gemeinsamen Link zur MetaTrader-Website hervorgeht, die Stärke eines Trends, nicht seine Richtung. Er ist gut, wenn die Richtung klar ist, die aktuellen Marktbewegungen stark sind und das Momentum sauber ist. Sein gepaartes Gegenstück, der MFI, befasst sich dagegen mehr mit der Wechselwirkung zwischen Preis und Volumen, indem er die „Leichtigkeit“ misst, mit der sich der Preis auf dem Markt bewegt. Wenn wir diese beiden miteinander verbinden, ergeben sie eine Geschichte. Der ADX gibt Aufschluss darüber, wie stark eine bestimmte Kurswelle ist, während der MFI angibt, wie viel Mühe die Märkte aufwenden, um diese Bewegung zu realisieren. Im Zusammenhang mit den Volatilitätsschüben des VGT kann diese Kombination unterscheiden, wo sich Energie ansammelt und wo sie nicht verpufft.
Das zweite Indikatorpaar, das in Frage kommt, ist der Fractal Adaptive Moving Average (FrAMA) und die Bollinger Bänder. Der FrAMA ist ein gleitender Durchschnitt, der so konzipiert ist, dass er seine Reaktionsfähigkeit auf den Markt in Abhängigkeit von der vorherrschenden Preisaktion ändert, während die Bollinger Bänder Volatilitätsumschläge um den Preis herum markieren. In Kombination bilden diese beiden ein Volatilitätsduett, bei dem sich der FrAMA intern ständig an die Trendbedingungen anpasst, während die Bollinger-Bänder die äußeren Volatilitätsgrenzen festlegen. Wenn sie übereinstimmen, deutet dies häufig darauf hin, dass der Preis von einer Expansion zu einer Kontraktion übergeht. Dies kann von unschätzbarem Wert für den Handel mit den Schwankungen des VGT sein, wenn er mit seinen zugrunde liegenden Aktienrotationsperioden konfrontiert wird.
Unser nächstes Kandidatenpaar ist der RSI und das Bill Williams Fractal. Der RSI verfolgt bekanntlich die interne Preisdynamik, d. h. wie weit sich der Preis im Verhältnis zu einer willkürlichen/festen Spanne bewegt hat. Das Fraktal hingegen soll die kleinen „Pivot-Fingerabdrücke“ oder die Punkte identifizieren, an denen der Preis kapituliert oder die Richtung wechselt. Der RSI signalisiert einen Anstieg im überkauften oder überverkauften Bereich, während das Fraktal die Punkte markiert, an denen der Kurs sich verpflichtet“, die Wende zu vollziehen. Dies kann auch für den VGT funktionieren, wenn wir versuchen, Erschütterungen am Ende des Quartals auszunutzen oder falsche Ausbrüche zu vermeiden.
Das nächste Indikatorpaar, das in Frage kommt, sind ATR und Williams Percent Range. Die ATR misst bekanntlich das Ausmaß der Volatilität. Der Williams Percent R misst, wie weit der Preis innerhalb einer aktuellen Spanne liegt, oder was man als emotional ehrlicheren Cousin des RSI ansehen könnte, siehe Formeln. Durch die Zusammenführung dieser beiden Elemente wird also erfasst, „wie groß das Schlachtfeld ist“ und „wo die Truppen gegenwärtig stationiert sind“. Wenn sich die Märkte in einem Trend befinden, neigt der Williams Percent R dazu, in der Nähe der Extreme abzuflachen, während der ATR in die Höhe schießt. Dies kann als Frühwarnung dienen, dass sich die nächste Volatilitätswelle bilden könnte.
Das letzte in Betracht kommende Indikatorpaar ist der Gator-Oszillator und der Standardabweichungsindikator. Der Gator ist ein Ableger des Alligator-Indikators und soll Konvergenz und Divergenz zwischen gleitenden Durchschnitten anzeigen. Im Wesentlichen geht es darum, aufzuzeigen, wann der Markt „beißt“ und nicht „schläft“, wie Bill Williams, der Autor des Berichts, argumentiert. In Verbindung mit der Standardabweichung ergibt sich ein statistischer Rohwert für die Streuung. Wenn der Gator aufwacht und sich ein Trend bildet, die Standardabweichung aber in der Kompression verbleibt, wird dies oft als Spiralfeder bezeichnet. Wenn sich beide ausweiten, ist das die Bestätigung einer Volatilitätsphase, in der der VGT seine größten Bewegungen machen würde.
Jedes unserer fünf Paare bietet eine bestimmte Sichtweise auf das Verhalten des VGT, aber solche intuitiven Erwartungen sind selten ausreichend, wenn wir diesen ETF aktiv handeln wollen. Wir müssen in der Lage sein, die Unabhängigkeit jedes dieser Indikatoren zu beziffern, um zu vermeiden, dass dasselbe Marktverhalten unter verschiedenen Namen doppelt gezählt wird. Aus diesem Grund werden in unserer Analyse zwei „Richter“ eingesetzt. Das Kendall’sche Tau und die Abstandskorrelation. Bevor wir ihre jeweilige Mathematik unter die Lupe nehmen, könnten wir damit beginnen, ihre „einfachen englischen“ Definitionen zu betrachten, damit die Logik der einzelnen Begriffe im weiteren Verlauf besser verstanden wird.
Das Kendall’sche Tau in Laiensprache
Einfach ausgedrückt, handelt es sich um einen „rangbasierten Handschlag“ zwischen zwei Datensätzen. Wenn man also zwei Datensätze vergleicht, stellt sich nicht die Frage, ob ihre jeweiligen Werte nahe beieinander liegen, sondern ob sie sich in derselben Reihenfolge bewegen. Um dies zu veranschaulichen, stellen Sie sich eine Situation vor, in der Sie und ein Handelskollege die gleichen Tage rangieren, an denen Sie den VGT gehandelt haben. Sie ordnen sie nach Preisveränderung ein, und er entscheidet sich für die Indikatorstärke. Wenn sich herausstellt, dass Sie beide darin übereinstimmen, welche Tage stark und welche schwach waren, obwohl Ihre tatsächlichen Größenordnungen unterschiedlich sind, wären Ihre Einstufungen übereinstimmend. Wenn die Einstufungen in irgendeiner Weise nicht übereinstimmen, werden sie als uneinheitlich bezeichnet.
Der Algorithmus des Kendall’schen Tau zählt, wie oft Übereinstimmungen und Unstimmigkeiten auftreten, wenn dieser Vergleich über die Datensatzpaarung durchgeführt wird. Die Bewertung liegt im Bereich von -1,0 bis +1,0, wobei der erste Wert eine vollkommene Unstimmigkeit bedeutet, während der zweite Wert eine vollständige Übereinstimmung darstellt. Ein Wert von Null würde bedeuten, dass es keine Beziehung zwischen den beiden verglichenen Datensätzen gibt, also eine vollkommene Unabhängigkeit.
Dies gilt nicht nur für den VGT, sondern für den Handel im Allgemeinen, da sich Indikatoren nur selten linear bewegen. Eine Lücke im RSI, die nach oben klafft, wird selten gleichmäßig mit einer ADX-Bewegung skaliert, und auch die Kompression der Bollinger-Bänder spiegelt nicht den Anstieg des FrAMA wider. Das Kendall’sche Tau hilft daher beim Herausfiltern dieses „Rauschens“, indem es sich ausschließlich auf die relative Richtungsabhängigkeit des Indikators konzentriert.
Man könnte dies auch als eine Form der Korrelation ohne „das Drama“ betrachten. Eine Form der Messung, bei der es nicht auf die Größe der einzelnen Indikatorwellen ankommt, sondern nur darauf, ob sie synchron verlaufen. Hier ist eine deduktive Analogie. Angenommen, der RSI des VGT deutet auf ein steigendes Momentum hin, während das Fraktal zeigt, dass noch keine Umkehr bevorsteht. Wenn der Wert des Kendall’schen Tau zwischen diesen beiden Indikatoren niedrig oder negativ ist, würde dies bedeuten, dass diese beiden Indikatoren in der Rangfolge nicht übereinstimmen. Dies könnte bedeuten, dass, wenn der eine früh auf die Preisentwicklung reagiert, der andere mit einer größeren Verzögerung reagiert und umgekehrt.
Die Definition des Kendall’schen Tau
Da die intuitive Bedeutung nun geklärt ist, wollen wir den Vorhang für die Schrauben und Muttern zurückziehen und uns die Funktionsweise unter der Motorhaube ansehen. Bei zwei Variablen X und Y – zum Beispiel zwei Indikatorausgaben aus dem Preisdatensatz des VGT – würde das Kendall’sche Tau das Ausmaß des ordinalen Zusammenhangs zwischen ihnen quantifizieren. Dies würde bedeuten, dass alle möglichen Paarungen zwischen diesen Beobachtungen bewertet und entweder als übereinstimmend (größer als 0) oder als nicht übereinstimmend (negativer Wert) eingestuft werden. Zu diesem Zweck ist ein Paar von Beobachtungen (Xi, Yi) und (Xj, Yj) konkordant, wenn sie sich in dieselbe Richtung ändern, sodass:
![]()
Es wäre jedoch ein Missklang, wenn:
![]()
Der Koeffizient des Kendall’schen Tau ist definiert als:
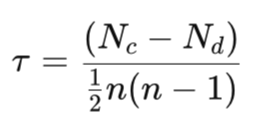
wobei:
- Nc ist die Anzahl der übereinstimmenden Paare
- Nd ist die Menge der nicht übereinstimmenden Paare
- n ist die Gesamtzahl der Beobachtungen
Bei dieser Formel soll der Nenner die Gesamtzahl der eindeutig beobachteten Paare darstellen. In der Praxis misst Tau das Ausmaß, in dem die Rangfolge der beiden Indikatorwerte übereinstimmt. Ein Wert von +1 bedeutet eine perfekte Übereinstimmung oder eine sogenannte monoton steigende Beziehung. Ein Wert beim kleinstmöglichen Wert von -1 bedeutet eine perfekte inverse Beziehung, die auch als monoton abnehmende Beziehung bezeichnet werden kann. Ein Wert von Null oder ein Wert in der Nähe davon bedeutet, dass es keine Korrelation gibt.
Bei der Marktanalyse ist diese Messung in der Regel hervorragend, da sie keine Parameter erfordert. Es wird auch nicht davon ausgegangen, dass die Daten einer Normalverteilung folgen oder sich sogar linear verhalten. Diese Eigenschaften machen ihn wohl weniger anfällig für Ausreißer und nichtlineare Skalierung – häufige Erscheinungen beim Umgang mit von Indikatoren abgeleiteten Daten, insbesondere bei verrauschten Instrumenten wie ETFs. Daher dient Tau bei der Betrachtung aller Indikatorpaare ADX-MFI, ATR-Williams R usw. dazu, festzustellen, ob beide Indikatorsignale die Tendenz haben, die Preisaktion gleich zu bewerten oder nicht.
Je näher Tau bei Null liegt, desto besser ist das für unsere Zwecke. Denn wenn keine Korrelation besteht, bedeutet dies höchstwahrscheinlich, dass das Paar komplementär ist. Wenn Tau hoch oder stark negativ ist, bedeutet dies, dass die beiden Indikatorwerte aus den VGT-Preisen eine signifikante Korrelation aufweisen, was auf ein gewisses Maß an Duplizität hindeutet oder dass beide Indikatoren dieselben Informationen unter verschiedenen Indikatorbezeichnungen erfassen. Das ist also die Funktionsweise unseres ersten Filters und „Richters“, das Kendall’sche Tau, das dazu beiträgt, sich überschneidende Logiken unter den Indikatoren herauszufiltern. Der zweite Filter, den wir haben, ist die Abstands-Korrelation, und wie beim Kendall’schen Tau werden wir ihn zunächst in Laiensprache vorstellen.
Verständnis der Abstands-Korrelation
Wenn es beim Kendall’schen Tau um den Vergleich von Rangordnungen geht, dann kann man die Distanzkorrelation als Formvergleich verstehen. Sie fragt nicht nur, ob diese Indikatorprojektionen in dieselbe Richtung weisen, sondern versucht auch, den Rhythmus oder die Art und Weise zu quantifizieren, in der sie übereinstimmen oder nicht übereinstimmen. Beide Algorithmen ähneln sich in dem, was sie zu messen versuchen, allerdings ist die Distanz-Korrelation leicht nuanciert, um einige zusätzliche Informationen zwischen den verglichenen Datensätzen zu erfassen. Hier ist eine Analogie, die dies verdeutlichen könnte. Stellen Sie sich ein Szenario vor, in dem zwei Händler die Kursentwicklung des VGT verfolgen, wobei jeder von ihnen mit einem bestimmten Indikator arbeitet. Angenommen, der erste Händler liest den ADX und konzentriert sich auf die Trendstärke, während der zweite auf die Volatilitätskompression mit den Bollinger Bändern reagiert. Selbst bei einer Reihe von Signalen, bei denen beide Indikatoren, wenn sie mit der Preisaktion gepaart sind, Kaufsignale signalisieren, ist diese einstimmige Übereinstimmung in unterschiedlichem Maße oder nicht linear zu erwarten. Herkömmliche Korrelationsalgorithmen wie die Pearson-Funktion oder sogar das Kendall’sche Tau lassen diese „unschönen“ Details dieser Beziehung zwangsläufig aus.
Die Abstands-Korrelation ist jedoch etwas spezifischer in ihrer Verfolgung der Zusatzinformationen in den verglichenen Indikatorwerten. Es wird nicht erfasst, wie linear oder quadratisch oder chaotisch die beiden Indikatorwerte sind, sondern durch die Annahme einer „Autokorrelationshaltung“ wird versucht, das Ausmaß zu beziffern, in dem Veränderungen der Werte einer Variablen mit Veränderungen der anderen Variablen korrespondieren. Dieser Algorithmus befasst sich mit Variationsmustern, nicht mit Rohwerten oder Rängen.
Definition der Abstandskorrelation
Formal erfasst die Abstandskorrelation jede Form der statistischen Abhängigkeit, ob monoton, linear, quadratisch oder anders. Bei zwei Vektoren von VGT-Indikatorwerten wird die Abstandskovarianz auf der Grundlage eines paarweisen Abstands zwischen allen beobachteten Indikatorwerten in jedem Vektordatensatz definiert. Anders ausgedrückt, wir verfolgen die Geometrie des einen Datenvektors im Verhältnis zur Geometrie des anderen. Die Berechnung ist ein vierstufiger Prozess. Zunächst berechnen wir die paarweisen Abstände. Bei einem Datensatz mit n Beobachtungen ((X1,Y1), (X2,Y2), ... (Xn,Yn)) lassen sich alle paarweisen euklidischen Abstände zwischen den X-Werten ablesen:
![]()
Und die Abstände zwischen den Y können ebenfalls ermittelt werden:
![]()
Der zweite Schritt ist dann die Berechnung des doppelten Zentrums sowie der Abstandsmatrizen. Diese erhält man durch Subtraktion der Zeilen- und Spaltenmittelwerte und anschließender Summierung zum Gesamtmittelwert. Diese Entfernungen sind symbolisch relativ und nicht absolut.

Dieser Schritt ist auch wichtig, um sicherzustellen, dass die Maßnahme verhältnismäßig ist und nicht durch die Größenordnung der Mittelwertunterschiede verzerrt wird. Der dritte Schritt, nachdem wir die Abstände summiert haben, besteht darin, die Kovarianz der beiden Datensätze und die Varianz jedes einzelnen Datensatzes zu berechnen.

Der abschließende vierte Schritt besteht daher darin, mit Hilfe der Kovarianz der Datensätze und der individuellen Varianz der einzelnen Datensätze die Distanzkorrelation wie folgt zu ermitteln:

Der Wertebereich reicht von 0 bis 1, wobei 1 eine vollständige Abhängigkeit bedeutet, während 0 für statistische Unabhängigkeit steht.
Das ist eine große Sache, denn im Gegensatz zum Kendall’schen Tau, das sich auf Rankings spezialisiert hat, bestimmt die Distanzkorrelation, wie strukturell zwei Datensätze miteinander verbunden sind, eine Eigenschaft, die es ihr ermöglicht, Datensätze unabhängig davon zu verfolgen, ob sie linear oder quadratisch miteinander verbunden sind. Bei der Auswahl eines Indikatorpaares für den VGT stehen Momentum-Indikatoren, Volatilitätsbänder und Fraktal-Darstellungen in der Regel in einer Beziehung zueinander, die nicht offensichtlich ist, was bedeutet, dass jemand, der seine Auswahl auf der Grundlage visueller Inspektionen trifft, leicht durch versteckte Abhängigkeiten getäuscht werden kann. Während das Kendall’sche Tau also die Rangabhängigkeit herausfiltert, gräbt die Distanzkorrelation tiefer und versucht, strukturelle Abhängigkeiten aufzudecken.
Wenn beide Algorithmen übereinstimmen, dass die Indikatorausgaben unkorreliert sind, können wir darauf vertrauen, dass dieses Paar eine unterschiedliche oder ergänzende Signallogik für ein Handelssystem darstellt. Nachdem wir unsere Algorithmuslogik definiert haben, wollen wir nun untersuchen, wie wir sie in einer Umgebung implementieren, in der dies recht effizient möglich ist, nämlich in Python.
Bewertung der Komplementarität
Um dies zu erreichen, verwenden wir eine Python-Pipeline, die zunächst Kursdaten vom Python-Modul des MetaTrader 5 als Input erhält. Wir melden uns bei einem MetaTrader 5-Konto mit VGT-ETF-Kursdaten an und definieren dann unser Testfenster für das Laden der historischen Daten als die letzten 5 Jahre. Wir tun dies mit dem täglichen Zeitrahmen. Wir haben jeden Indikator mit bis zu 10 Signalmustern vorcodiert, die je nach den Nutzungseinstellungen einzeln verwendet werden können. Der erste Schritt bei der Bewertung der Komplementarität besteht also darin, für jeden Indikator ein repräsentatives Merkmal auszuwählen, es abzugleichen und dann ein minus Tau sowie ein minus die Abstandskorrelation zu berechnen. Wir verwenden ein Minus, weil diese Werte in umgekehrtem Verhältnis zu unserem Ziel stehen. Die Kodierung dieser Algorithmen erfolgt in Python wie folgt:
def fast_pair_summary(modA, prA, dfA, modB, prB, dfB, col_idx=0): featsA = _feature_matrix(modA, prA, dfA, col_idx) featsB = _feature_matrix(modB, prB, dfB, col_idx) tau_vals, dcor_vals = [], [] for x in featsA: if x is None: continue for y in featsB: if y is None: continue xa, ya = _align_last_equal(np.asarray(x), np.asarray(y)) if len(xa) < 5: continue tau, _ = kendalltau(xa, ya) if tau is None or np.isnan(tau): continue tau_vals.append(abs(tau)) dcor_vals.append(_distance_correlation(xa, ya)) if not tau_vals or not dcor_vals: return np.nan mean_abs_tau = np.mean(tau_vals) mean_dcor = np.mean(dcor_vals) independence = 1.0 - 0.5 * (mean_abs_tau + mean_dcor) return independence
def _distance_correlation(x, y): """Raw distance correlation (0..1). Works with 1D arrays of same length.""" # ensure 1D float arrays x = np.asarray(x, dtype=float).reshape(-1, 1) y = np.asarray(y, dtype=float).reshape(-1, 1) # pairwise Euclidean distances a = np.sqrt((x - x.T) ** 2) b = np.sqrt((y - y.T) ** 2) # double-center each distance matrix A = a - a.mean(axis=0)[None, :] - a.mean(axis=1)[:, None] + a.mean() B = b - b.mean(axis=0)[None, :] - b.mean(axis=1)[:, None] + b.mean() # distance covariance/variances dcov = np.sqrt(np.mean(A * B)) dvar_x = np.sqrt(np.mean(A * A)) dvar_y = np.sqrt(np.mean(B * B)) denom = np.sqrt(dvar_x * dvar_y) + 1e-12 return float(dcov / denom)
Anschließend werden die beiden Werte zu einem einzigen Unabhängigkeitsscore zusammengeführt. Denn jeder Indikator hat 10 Muster, und wir müssen eines dieser zehn Muster auswählen, um die Komplementarität zu berechnen. Wir wählen nicht willkürlich Indikator-Signalmuster zur Verwendung aus. Aus diesem Grund wird der scheinbar „mühsame“, aber notwendige Prozess der Verwendung eines 10 x 10 Rasterpunktes durchgeführt. Für jeden Zellschnittpunkt dieser Muster berechnen wir den Tau-Wert und die Distanzkorrelation, um ein breiteres Bild über all diese möglichen Kombinationen zu erhalten, wo die wahre Synergie liegt. Diese Paarung kann tatsächlich als die untere/obere Hälfte der Dreiecke dargestellt werden, die diesen Kreuztisch bilden.
Für jede Indikatorpaarung wird eine 10 x 10 Kreuztabelle mit gewichtetem Kendall’schen Tau- und Distanzkorrelationswerten erstellt. Der höchste Wert in der Kreuztabelle nach der Inversion mit 1 (1 minus dem gewichteten Wert aufgrund der inversen Beziehung) kann die Indikatorpaarung darstellen. Die Metrik, die wir für jede Indikatorenkombination erhalten, kann als „Unabhängigkeitspunkte“ betrachtet werden. Für unsere fünf Indikatorenpaare lauten diese Werte wie folgt:
| Indikator 1 | Indikator 2 | Unabhängigkeitspunkte |
|---|---|---|
| ADX Wilder | Bill Williams MFI | 0.968 |
| Gator Oscillator | Standardabweichung | 0.961 |
| FrAMA | Bollinger Bänder | 0.939 |
| RSI | Bill Williams Fraktale | 0.918 |
| ATR | Williams R | 0.902 |
Paarung von Signalmustern
Da wir den ADX und Bill Williams als geeignetes unabhängiges und dennoch synergetisches Indikatorenpaar identifiziert haben, setzen wir die Analyse nun fort, indem wir sie auf die Signalmuster übertragen, auf denen beide basieren. Beide Indikatoren haben 10 Signalmuster, und bei ihrer Verwendung müssen wir jeweils ein Paar anwenden. Ein Muster des ADX wird mit einem anderen Muster des MFI abgeglichen. Da wir für jeden Indikator 10 Muster haben, stellt sich die Frage, welches Signalmuster mit welchem gekoppelt werden sollte, um eine optimale Leistung zu erzielen. Die Methodik, mit der wir die verschiedenen Muster des ADX und des MFI in geeigneter Weise miteinander verbinden, lässt sich in dem folgenden Flussdiagramm zusammenfassen:

Um diese Frage zu beantworten, ermitteln wir die Preisprognosen des Indikators und vergleichen sie mit der tatsächlichen Preisentwicklung, indem wir einen so genannten F1-Score erstellen. Python kann diese Ergebnisse und Berichte vor allem nach dem Training neuronaler Netze erstellen. Da wir in unserem Fall jedoch kein Training durchführen, sondern die Prognosen der Indikatoren auf der Grundlage ihrer Roh- oder Standard-Eingabeparameter ablesen, dient dies tatsächlich als Validierungs- oder Testlauf.
Auch hier sind wir an den Indikatorvorhersagen interessiert, wenn sie gepaart sind. Wir sehen uns also eine Kreuztabelle der F1-Werte jedes Musterpaares an und wenden den Bayes'schen Algorithmus UCB auf den Mittelwert und die Unsicherheit der F1-Werte an, während wir weiterhin Stichproben nehmen, wo die Leistung am besten ist. Jeder Indikator verfügt über 10 einzigartige Signalmuster für direktionale oder Volatilitätsmarktregimes. Dieser Bayes'sche Optimierer berücksichtigt alle 100 möglichen Paarungen, indem er sie als „ein Arm in einem mehrarmigen Banditenmodell“ behandelt. Die F1-Scores, die in dieser Kreuztabelle aufgeführt sind, werden zur Belohnungsmetrik, indem sie nicht nur die Genauigkeit, sondern auch die Konsistenz der Handelsergebnisse im gesamten VGT-Raum bewerten. Wir implementieren dies in Python wie folgt:
# ------------------------------------------------------------- # Dirichlet posterior score sampling per pair (for Bayesian UCB) # ------------------------------------------------------------- def _sample_score_from_dirichlet(C, weights, rng, alpha_prior=1.0, K=200): wa, wbull, wbear = weights C = C.astype(float) tot = int(C.sum()) if tot == 0: return np.zeros(K, dtype=float) draws = np.empty(K, dtype=float) alpha = alpha_prior + C.ravel() for k in range(K): p = rng.dirichlet(alpha) # probs over 9 cells # expected counts under p (or sample multinomial for more noise) # Here we treat p as a table, compute score metrics from p directly: P = p.reshape(3,3) acc = np.trace(P) pred_bull = P[:,2].sum(); bullP = (P[2,2]/pred_bull) if pred_bull>0 else 0.0 pred_bear = P[:,0].sum(); bearP = (P[0,0]/pred_bear) if pred_bear>0 else 0.0 draws[k] = wa*acc + wbull*bullP + wbear*bearP return draws
# ============================================================= # 5) Bayesian UCB assignment: S_ucb = mu + β*std from posterior draws # ============================================================= def select_pairs_bayesian_ucb(counts, weights=(0.2,0.4,0.4), K=300, beta=1.0, alpha_prior=1.0, rng=None): if rng is None: rng = np.random.default_rng() S_mu = np.zeros((10,10), dtype=float) S_sd = np.zeros((10,10), dtype=float) for i in range(10): for j in range(10): samp = _sample_score_from_dirichlet(counts[i,j], weights, rng, alpha_prior, K) S_mu[i,j] = samp.mean() S_sd[i,j] = samp.std(ddof=1) S_ucb = S_mu + beta * S_sd r, c = linear_sum_assignment(-S_ucb) pairs = [(int(i+1), int(j+1)) for i, j in zip(r, c)] return pairs, S_mu, S_sd, S_ucb
Dieser Prozess führt uns zu diesen 10 Signalmusterpaaren über ADX und den MFI.
| Rang | ADX-Muster | MFI-Muster | Mittlerer F1-Wert | UCB-Wert |
|---|---|---|---|---|
| 1 | A3 | M5 | 0.86 | 0.88 |
| 2 | A9 | M8 | 0.81 | 0.85 |
| 3 | A6 | M7 | 0.76 | 0.84 |
| 4 | A7 | M6 | 0.80 | 0.83 |
| 5 | A2 | M9 | 0.74 | 0.81 |
| 6 | A4 | M10 | 0.73 | 0.80 |
| 7 | A8 | M1 | 0.72 | 0.79 |
| 8 | A5 | M3 | 0.70 | 0.78 |
| 9 | A1 | M2 | 0.71 | 0.77 |
| 10 | A10 | M4 | 0.73 | 0.76 |
Unser Signalmuster-Code in Python sieht wie folgt aus:
# 1. ADX rises above 25 while +DI crosses above −DI -> bullish ignition. def feature_adx_1(df): adx = _col(df, 'ADX', 'adx', 'Adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') feature = np.zeros((len(df), 2), dtype=int) # bullish: ADX rises above 25 and +DI crosses above -DI (cross up on current bar) cond_bull = (adx > 25) & (pdi.shift(1) <= mdi.shift(1)) & (pdi > mdi) # bearish: ADX rises above 25 and -DI crosses above +DI cond_bear = (adx > 25) & (mdi.shift(1) <= pdi.shift(1)) & (mdi > pdi) # print(' adx > 25 ',adx > 25) # print(' pdi.shift(1) <= mdi.shift(1) ',pdi.shift(1) <= mdi.shift(1)) # print(' pdi > mdi ',pdi > mdi) # print(' cond_bull ',cond_bull) # print(' cond_bear ',cond_bear) feature[:, 0] = cond_bull.astype(int) feature[:, 1] = cond_bear.astype(int) feature[:2, :] = 0 return feature # 2. ADX making higher highs while price makes higher highs -> confirmed bullish momentum. def feature_adx_2(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close', 'PRICE', 'price', 'ClosePrice') feature = np.zeros((len(df), 2), dtype=int) # ADX higher highs over last 2 bars and price higher highs adx_hh = (adx > adx.shift(1)) & (adx.shift(1) > adx.shift(2)) price_hh = (close > close.shift(1)) & (close.shift(1) > close.shift(2)) feature[:, 0] = (adx_hh & price_hh).astype(int) # ADX higher highs but price makes lower highs -> bearish divergence (topping) price_lh = (close < close.shift(1)) & (close.shift(1) < close.shift(2)) feature[:, 1] = (adx_hh & price_lh).astype(int) feature[:3, :] = 0 return feature # 3. ADX climbing from below 20 to above 30 during sideways range -> breakout confirm. def feature_adx_3(df): adx = _col(df, 'ADX', 'adx') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # define sideways range: low volatility measured by small ATR proxy (high-low small) range_width = (high - low).rolling(10, min_periods=1).mean() sideways = range_width < (range_width.rolling(50, min_periods=1).median()) # crude # ADX climbs from below 20 to above 30 within recent window climbed = (adx > 30) & (adx.shift(5) < 20) # bullish breakout: close breaks above recent 10-bar high while climbed & sideways breakout_up = climbed & sideways & (close > close.rolling(10).max().shift(1)) breakout_down = climbed & sideways & (close < close.rolling(10).min().shift(1)) feature[:, 0] = breakout_up.astype(int) feature[:, 1] = breakout_down.astype(int) feature[:10, :] = 0 return feature # 4. +DI forms W while ADX rises -> momentum recovery; inverse for -DI M pattern. def feature_adx_4(df): adx = _col(df, 'ADX', 'adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') feature = np.zeros((len(df), 2), dtype=int) # detect simple W pattern on +DI: low in middle between two higher peaks w_plus = (pdi.shift(2) > pdi.shift(1)) & (pdi.shift(1) < pdi) & (pdi.shift(2) > pdi) m_minus = (mdi.shift(2) < mdi.shift(1)) & (mdi.shift(1) > mdi) & (mdi.shift(2) < mdi) # M-like top on -DI adx_rising = (adx > adx.shift(1)) & (adx.shift(1) > adx.shift(2)) feature[:, 0] = (w_plus & adx_rising).astype(int) feature[:, 1] = (m_minus & adx_rising).astype(int) feature[:3, :] = 0 return feature # 5. ADX falls after a long uptrend while price stalls -> trend exhaustion. def feature_adx_5(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # "long uptrend" measured as close rising for a while (10 bars) uptrend = (close > close.shift(1)) & (close.shift(1) > close.shift(2)) uptrend_long = close > close.shift(10) # price higher than 10 bars ago -> crude uptrend # ADX falling: current ADX below its 5-bar SMA and lower than previous adx_falling = (adx < adx.rolling(5, min_periods=1).mean()) & (adx < adx.shift(1)) # bull exhaustion: long uptrend + adx_falling + price stalls (small change) price_stall = (abs(close - close.shift(1)) / close.shift(1)) < 0.0025 # <0.25% change -> stall feature[:, 0] = (uptrend_long & adx_falling & price_stall).astype(int) # bear exhaustion: symmetric for downtrend downtrend_long = close < close.shift(10) feature[:, 1] = (downtrend_long & adx_falling & price_stall).astype(int) feature[:11, :] = 0 return feature # 6. ADX slope rising with widening +DI–−DI gap -> momentum expansion long def feature_adx_6(df): adx = _col(df, 'ADX', 'adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') feature = np.zeros((len(df), 2), dtype=int) adx_slope = adx - adx.shift(3) # 3-bar slope proxy gap = pdi - mdi gap_change = gap - gap.shift(3) # long expansion: ADX slope positive and gap widening in favor of +DI cond_long = (adx_slope > 0) & (gap_change > 0) & (gap > 0) # short expansion: ADX slope positive and gap widening in favor of -DI cond_short = (adx_slope > 0) & (gap_change < 0) & (gap < 0) feature[:, 0] = cond_long.astype(int) feature[:, 1] = cond_short.astype(int) feature[:4, :] = 0 return feature # 7. ADX divergence: price higher high, ADX lower high -> hidden weakness def feature_adx_7(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # Price higher high over last 2 bars but ADX lower high price_higher_high = (close > close.shift(1)) & (close.shift(1) > close.shift(2)) adx_lower_high = (adx < adx.shift(1)) & (adx.shift(1) < adx.shift(2)) feature[:, 0] = (price_higher_high & adx_lower_high).astype(int) # Price lower low but ADX higher low -> weak bearish continuation price_lower_low = (close < close.shift(1)) & (close.shift(1) < close.shift(2)) adx_higher_low = (adx > adx.shift(1)) & (adx.shift(1) > adx.shift(2)) feature[:, 1] = (price_lower_low & adx_higher_low).astype(int) feature[:3, :] = 0 return feature # 8. ADX makes W base while price forms W -> bullish reversal; M top -> bearish reversal. def feature_adx_8(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # W base detection (ADX): low in middle between two higher values adx_w = (adx.shift(2) > adx.shift(1)) & (adx.shift(1) < adx) & (adx.shift(2) > adx) price_w = (close.shift(2) > close.shift(1)) & (close.shift(1) < close) & (close.shift(2) > close) feature[:, 0] = (adx_w & price_w).astype(int) # M top detection: mirror of W (two peaks with lower middle) adx_m = (adx.shift(2) < adx.shift(1)) & (adx.shift(1) > adx) & (adx.shift(2) < adx) price_m = (close.shift(2) < close.shift(1)) & (close.shift(1) > close) & (close.shift(2) < close) feature[:, 1] = (adx_m & price_m).astype(int) feature[:3, :] = 0 return feature # 9. ADX slope flattening near 20 with price consolidating -> breakout signals (top/bottom). def feature_adx_9(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) # flattening near 20: ADX within +/-2 of 20 and small recent slope near_20 = (adx.between(18, 22)) flat_slope = (abs(adx - adx.shift(5)) < 2) # consolidation: price within narrow band of recent 10 bars band = high.rolling(10, min_periods=1).max() - low.rolling(10, min_periods=1).min() narrow = band < (band.rolling(50, min_periods=1).median()) # breakout up: price breaks above previous 10-bar high breakout_up = near_20 & flat_slope & narrow & (close > close.rolling(10).max().shift(1)) # breakout down: price breaks below previous 10-bar low breakout_down = near_20 & flat_slope & narrow & (close < close.rolling(10).min().shift(1)) feature[:, 0] = breakout_up.astype(int) feature[:, 1] = breakout_down.astype(int) feature[:11, :] = 0 return feature # 10. ADX falls sharply while DI lines stay wide -> temporary pullback in trend. def feature_adx_10(df): adx = _col(df, 'ADX', 'adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # ADX falls sharply: current ADX much lower than 5-bar ago adx_drop = (adx < adx.shift(5) * 0.8) # >20% drop over 5 bars # DI lines stay wide: absolute gap still large (> threshold) gap = abs(pdi - mdi) wide_gap = gap > gap.rolling(20, min_periods=1).mean() # gap wider than its 20-bar mean # bullish context (initial trend was bullish): +DI > -DI bull_context = pdi > mdi bear_context = mdi > pdi # bullish temporary pullback: adx_drop & wide_gap & bull_context -> buy on continuation after pullback feature[:, 0] = (adx_drop & wide_gap & bull_context).astype(int) feature[:, 1] = (adx_drop & wide_gap & bear_context).astype(int) feature[:6, :] = 0 return feature
# 1. MFI and volume both rise -> genuine buying strength. Mirror: MFI+volume rise while price fails -> topping clue. def feature_mfi_1(df): mfi = _col(df, 'MFI_BW', 'MFI', 'mfi', 'MarketFacilitationIndex') try: vol = _col(df, 'Volume', 'tick_volume', 'VOL') except KeyError: vol = pd.Series(0, index=df.index) close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) mfi_up = (mfi > mfi.shift(1)) vol_up = (vol > vol.shift(1)) price_fail = (close <= close.shift(1)) # price not confirming feature[:, 0] = (mfi_up & vol_up & (close > close.shift(1))).astype(int) feature[:, 1] = (mfi_up & vol_up & price_fail).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 2. MFI spikes with green bar after compression -> momentum expansion up. Mirror downward. def feature_mfi_2(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) # compression = low volatility (small range) vs longer history range10 = (high - low).rolling(10, min_periods=1).mean() med_range = range10.rolling(100, min_periods=1).median().replace(0, np.nan) compressed = range10 < (0.6 * med_range) # spike = large jump in MFI relative to recent mfi_spike = (mfi > mfi.rolling(5, min_periods=1).mean() + 1.5 * mfi.rolling(5, min_periods=1).std()) green_bar = close > close.shift(1) brown_bar = close < close.shift(1) feature[:, 0] = (compressed.shift(1) & mfi_spike & green_bar).astype(int) feature[:, 1] = (compressed.shift(1) & mfi_spike & brown_bar).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 3. MFI increases while price stabilizes -> silent accumulation. Mirror: MFI decreases while price stabilizes -> silent distribution. def feature_mfi_3(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) mfi_up = (mfi > mfi.shift(1)) mfi_down = (mfi < mfi.shift(1)) # price stabilizes = small average absolute returns over short window price_change = (abs(close - close.shift(1)) / close.shift(1).replace(0, np.nan)).rolling(5, min_periods=1).mean() stable = price_change < 0.0025 # ~0.25% avg move feature[:, 0] = (mfi_up & stable).astype(int) feature[:, 1] = (mfi_down & stable).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 4. MFI higher low while price retests support -> hidden bullish divergence. Mirror bearish. def feature_mfi_4(df): mfi = _col(df, 'MFI', 'mfi') low = _col(df, 'Low', 'low') high = _col(df, 'High', 'high') feature = np.zeros((len(df), 2), dtype=int) price_retest_support = (low < low.shift(1)) & (low.shift(1) <= low.shift(2)) # recent retest/probe mfi_hl = (mfi > mfi.shift(1)) & (mfi.shift(1) > mfi.shift(2)) price_retest_resist = (high > high.shift(1)) & (high.shift(1) >= high.shift(2)) mfi_lh = (mfi < mfi.shift(1)) & (mfi.shift(1) < mfi.shift(2)) feature[:, 0] = (price_retest_support & mfi_hl).astype(int) feature[:, 1] = (price_retest_resist & mfi_lh).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 5. W-shaped MFI under price base -> reversal setup. M-shaped above price top -> topping structure. def feature_mfi_5(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # W detection on MFI (4-bar pattern): dip between two higher pivots w_mfi = (mfi.shift(3) < mfi.shift(2)) & (mfi.shift(2) < mfi.shift(1)) & (mfi.shift(1) < mfi) # require that MFI values are under price base (close relatively flat or above) price_base = close > close.rolling(10, min_periods=1).mean() # M detection on MFI: peak between two lower pivots m_mfi = (mfi.shift(3) > mfi.shift(2)) & (mfi.shift(2) > mfi.shift(1)) & (mfi.shift(1) > mfi) feature[:, 0] = (w_mfi & price_base).astype(int) feature[:, 1] = (m_mfi & (~price_base)).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 6. MFI and volume decouple -> stealth accumulation/distribution. def feature_mfi_6(df): mfi = _col(df, 'MFI', 'mfi') try: vol = _col(df, 'Volume', 'volume', 'VOL') except KeyError: vol = pd.Series(np.nan, index=df.index) close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) mfi_up = (mfi > mfi.shift(1)) mfi_down = (mfi < mfi.shift(1)) vol_down = (vol < vol.shift(1)) vol_up = (vol > vol.shift(1)) # stealth accumulation: MFI up while volume down feature[:, 0] = (mfi_up & vol_down).astype(int) # distribution bias: MFI down while volume up feature[:, 1] = (mfi_down & vol_up).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 7. MFI bar color shift from brown to green -> fresh burst. Mirror green->brown -> exhaustion. def feature_mfi_7(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # Interpret "green" as close > prev close and mfi rising; "brown" as falling mfi_rise = (mfi > mfi.shift(1)) mfi_fall = (mfi < mfi.shift(1)) green_bar = (close > close.shift(1)) & mfi_rise brown_bar = (close < close.shift(1)) & mfi_fall feature[:, 0] = (brown_bar.shift(1) & green_bar).astype(int) feature[:, 1] = (green_bar.shift(1) & brown_bar).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 8. MFI bottoms and climbs while volatility increases -> uptrend resumption. Mirror peak & decline -> downtrend resumption. def feature_mfi_8(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) # volatility proxy atr_like = (high - low).rolling(14, min_periods=1).mean() vol_up = atr_like > atr_like.shift(3) # bottom and climb: mfi rises from local trough mfi_bottom = (mfi.shift(2) > mfi.shift(1)) & (mfi.shift(1) < mfi) # trough at shift(1) mfi_peak = (mfi.shift(2) < mfi.shift(1)) & (mfi.shift(1) > mfi) feature[:, 0] = (mfi_bottom.shift(1) & (mfi > mfi.shift(1)) & vol_up).astype(int) feature[:, 1] = (mfi_peak.shift(1) & (mfi < mfi.shift(1)) & vol_up).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 9. MFI breaks above prior swing -> energy expansion. Mirror break below -> collapse. def feature_mfi_9(df): mfi = _col(df, 'MFI', 'mfi') feature = np.zeros((len(df), 2), dtype=int) # prior swing high/low of MFI (10-bar) prior_high = mfi.rolling(10, min_periods=1).max().shift(1) prior_low = mfi.rolling(10, min_periods=1).min().shift(1) break_up = (mfi > prior_high) break_down = (mfi < prior_low) feature[:, 0] = break_up.astype(int) feature[:, 1] = break_down.astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 10. Rising MFI slope with narrowing candle bodies -> hidden demand absorption. Mirror supply absorption. def feature_mfi_10(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) mfi_slope = mfi - mfi.shift(3) rising_slope = mfi_slope > mfi_slope.shift(1) falling_slope = mfi_slope < mfi_slope.shift(1) # narrowing candle bodies = average body size shrinking body = (abs(close - close.shift(1))).rolling(7, min_periods=1).mean() body_shrink = body < body.shift(3) feature[:, 0] = (rising_slope & body_shrink).astype(int) feature[:, 1] = (falling_slope & body_shrink).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature
Wir kodieren diese in dem oben empfohlenen Paarungsformat in MQL5 wie folgt.
//+------------------------------------------------------------------+ //| Check for Pattern 0. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_0(ENUM_POSITION_TYPE T) { int _i_max = -1, _i_min = -1; if(T == POSITION_TYPE_BUY) { return(Hi(X()) - Lo(X()) > High(X()) - Low(X()) && ADX(X()) > 30 && ADX(X() + 5) < 20 && Close(X()) > m_close.MaxValue(X(), m_past, _i_max) && MFI(X() + 1) < MFI(X()) && MFI(X() + 2) < MFI(X() + 1) && MFI(X() + 3) < MFI(X() + 2) && Close(X()) > Cl(X())); } else if(T == POSITION_TYPE_SELL) { return(Hi(X()) - Lo(X()) > High(X()) - Low(X()) && ADX(X()) > 30 && ADX(X() + 5) < 20 && Close(X()) < m_close.MinValue(X(), m_past, _i_min) && MFI(X() + 1) > MFI(X()) && MFI(X() + 2) > MFI(X() + 1) && MFI(X() + 3) > MFI(X() + 2) && Close(X()) < Cl(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 1. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_1(ENUM_POSITION_TYPE T) { int _i_max = -1, _i_min = -1; m_close.Refresh(-1); vector _mf; m_mfi.Refresh(-1); _mf.CopyIndicatorBuffer(m_mfi.Handle(), 0, 0, m_past); if(T == POSITION_TYPE_BUY) { return(ADX(X()) >= 18.0 && ADX(X()) <= 22.0 && fabs(ADX(X()) - ADX(X() + 5)) < 2.0 && Hi(X()) - Lo(X()) < High(X()) - Low(X()) && Close(X()) > m_close.MaxValue(X(), m_past, _i_max) && Hi(X()) - Lo(X()) < Hi(X() + m_past) - Lo(X() + m_past) && MFI(X() + 1) < MFI(X()) && LocalMin(_mf, X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) >= 18.0 && ADX(X()) <= 22.0 && fabs(ADX(X()) - ADX(X() + 5)) < 2.0 && Hi(X()) - Lo(X()) < High(X()) - Low(X()) && Close(X()) < m_close.MinValue(X(), m_past, _i_min) && Hi(X()) - Lo(X()) < Hi(X() + m_past) - Lo(X() + m_past) && MFI(X() + 1) > MFI(X()) && LocalMax(_mf, X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 2. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_2(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) - ADX(X() + m_past) > 0.0 && ADXPlus(X()) - ADXMinus(X()) > 0.0 && ADXPlus(X()) - ADXMinus(X()) > ADXPlus(X() + m_past) - ADXMinus(X() + m_past) && Close(X()) > Close(X() + 1) && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) - ADX(X() + m_past) > 0.0 && ADXPlus(X()) - ADXMinus(X()) < 0.0 && ADXPlus(X()) - ADXMinus(X()) < ADXPlus(X() + m_past) - ADXMinus(X() + m_past) && Close(X()) < Close(X() + 1) && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 3. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_3(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(Close(X()) > Close(X() + 1) && Close(X() + 1) > Close(X() + 2) && ADX(X()) < ADX(X() + 1) && ADX(X() + 1) < ADX(X() + 2) && Volumes(X() + 1) > Volumes(X()) && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(Close(X()) < Close(X() + 1) && Close(X() + 1) < Close(X() + 2) && ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Volumes(X() + 1) < Volumes(X()) && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 4. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_4(ENUM_POSITION_TYPE T) { vector _mf; m_mfi.Refresh(-1); _mf.CopyIndicatorBuffer(m_mfi.Handle(), 0, 0, m_past); if(T == POSITION_TYPE_BUY) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) > Close(X() + 1) && Close(X() + 1) > Close(X() + 2) && MFI(X()) > LocalMax(_mf, X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) < Close(X() + 1) && Close(X() + 1) < Close(X() + 2) && MFI(X()) < LocalMin(_mf, X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 5. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_5(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && ADXPlus(X() + 2) > ADXPlus(X() + 1) && ADXPlus(X() + 1) < ADXPlus(X()) && ADXPlus(X() + 2) > ADXPlus(X()) && Volumes(X() + 1) > Volumes(X()) && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && ADXMinus(X() + 2) < ADXMinus(X() + 1) && ADXMinus(X() + 1) > ADXMinus(X()) && ADXMinus(X() + 2) < ADXMinus(X()) && Volumes(X() + 1) < Volumes(X()) && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 6. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_6(ENUM_POSITION_TYPE T) { vector _ad, _cl; m_adx.Refresh(-1); m_close.Refresh(-1); _ad.CopyIndicatorBuffer(m_adx.Handle(), 0, 0, fmax(5,m_past)); _cl.CopyRates(m_symbol.Name(), m_period, 8, 0, fmax(5, m_past)); if(T == POSITION_TYPE_BUY) { return(IsW(_ad) && IsW(_cl) && MFI(X()) > MFI(X() + 1) && Volumes(X()) > Volumes(X() + 1) && Close(X()) < Close(X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(IsM(_ad) && IsM(_cl) && MFI(X()) > MFI(X() + 1) && Volumes(X()) > Volumes(X() + 1) && Close(X()) > Close(X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 7. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_7(ENUM_POSITION_TYPE T) { int _i_max = -1, _i_min = -1; m_close.Refresh(-1); m_adx.Refresh(-1); if(T == POSITION_TYPE_BUY) { return(Close(X()) >= m_close.MaxValue(X(), m_past, _i_max) && ADX(X()) <= m_adx.MinValue(0, X(), m_past, _i_min) && fabs(Close(X()) - Close(X() + 1))/fmax(m_symbol.Point(),Close(X() + 1)) <= 0.0025 && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(Close(X()) <= m_close.MinValue(X(), m_past, _i_max) && ADX(X()) <= m_adx.MinValue(0, X(), m_past, _i_min) && fabs(Close(X()) - Close(X() + 1))/fmax(m_symbol.Point(),Close(X() + 1)) <= 0.0025 && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 8. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_8(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) > 25.0 && ADXMinus(X() + 1) >= ADXPlus(X() + 1) && ADXMinus(X()) < ADXPlus(X() + m_past) && Hi(X()) - Lo(X()) < 0.6*(Hi(X() + m_past) - Lo(X() + m_past)) && MFI(X()) - MFI(X() + 1) >= 1.5*MFI(X()) && Close(X()) > Close(X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > 25.0 && ADXMinus(X() + 1) <= ADXPlus(X() + 1) && ADXMinus(X()) > ADXPlus(X() + m_past) && Hi(X()) - Lo(X()) < 0.6*(Hi(X() + m_past) - Lo(X() + m_past)) && MFI(X()) - MFI(X() + 1) >= 1.5*MFI(X()) && Close(X()) < Close(X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 9. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_9(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) > Close(X() + 1) && Close(X() + 1) > Close(X() + 2) && MFI(X()) > MFI(X() + 1) && Low(X()) < Low(X() + 1) && Low(X() + 1) <= Low(X() + 2)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) < Close(X() + 1) && Close(X() + 1) < Close(X() + 2) && MFI(X()) < MFI(X() + 1) && High(X()) > High(X() + 1) && High(X() + 1) >= High(X() + 2)); } return(false); }
Die Verwendung eines nutzerdefinierten Signalklassenformats bei der Darstellung der Handelslogik hat eine Reihe von Vorteilen. Neue Leser können hier eine Einführung finden. Ich habe diese bereits in früheren Artikeln erwähnt, aber im Wesentlichen können wir Ideen sehr schnell testen und gleichzeitig die Kombination mit anderen ähnlich formatierten Systemen, z. B. nutzerdefinierten Signalen für die Entwicklung hybrider Systeme, ermöglichen.
Schlussfolgerung
In diesem Artikel haben wir einen formalen und statistisch fundierten Weg für den Einsatz des VGT ETF aufgezeigt, der unser Ausgangsproblem der verrauschten, überfüllten Charts und sich überschneidenden Indikatoren direkt angeht. Indem wir mit der Klärung des saisonalen Verhaltens des VGT im Zeitfenster von Q4 bis Q1 begannen, konnten wir seine Volatilität sowie die Trenddynamik in einen vorhersehbaren Kontext mit geringerer Unsicherheit einordnen. Vor diesem Hintergrund haben wir gezeigt, wie das Kendall’sche Tau und die Distanzkorrelation bei der Bewertung von Indikatorenpaaren nützlich sein können, und zwar nicht durch Reddit- oder Social-Media-Empfehlungen, sondern durch eine quantifizierte Unabhängigkeit, die sicherstellt, dass jedes Indikatorsignal das der anderen wirklich bestätigt und wir weniger Duplizität haben.
Bei der Analyse der von uns betrachteten Indikatorenpaare waren der ADX und der MFI von Bill Williams am komplementärsten für den VGT ETF. Ich vertrete die Auffassung, dass dieser Prozess handelsinstrumentenspezifisch sein sollte. Dennoch ist es möglich, Indikatorpaare zu finden, die sich viel besser über verschiedene Vermögenswerte hinweg verallgemeinern lassen, auch wenn ich behaupte, dass dies eher die Ausnahme als die Regel sein dürfte. Wir schließen die Analyse mit einem F1-Scoring für die Vorhersagefähigkeit der Musterpaare der Gewinnerindikatoren ab. Durch die Anwendung des Bayes'schen UCB-Verfahrens sind wir in der Lage, die zehn deutlichsten Signalmuster unseres Gewinner-Indikatorpaares ADX-MFI zu identifizieren und diese in MQL5 für die Verwendung und weitere Tests direkt im MetaTrader zu kodieren. Diese Methode ist ursprünglich als per Assistent erstellter Expert Advisor gedacht; da jedoch der Code für diese Signalklasse beigefügt ist, können erfahrenere Programmierer ihn problemlos universell anpassen.| Name | Beschreibung |
|---|---|
| EMC-1.mq5 | Kompilierbarer Expert Advisor, dessen Header die verwendeten Dateien anzeigt |
| SignalEMC-1.mq5 | Nutzerdefinierte Klassendatei des Signals, das vom mql5 Wizard benötigt wird, um den Expert Advisor zusammenzustellen |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/20271
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.