
Die Grenzen des maschinellen Lernens überwinden (Teil 8): Nichtparametrische Strategieauswahl

In unserer vorherigen Diskussion über die automatische Strategieauswahl haben wir zwei Ansätze zur Identifizierung von Handelsstrategien aus einer Liste von Kandidaten untersucht. Die erste war eine White-Box-Methode mit Matrixfaktorisierung – einfach, transparent und intuitiv. Heute widmen wir uns dem zweiten Ansatz, der komplexeren Blackbox-Lösung.
Es ist nach wie vor eine große Herausforderung, rentable Strategien zu finden. Dieser Artikel konzentriert sich auf die Verbesserung der Konfiguration und Einrichtung von Blackbox-Modellen. Zuvor haben wir ein statistisches Modell entwickelt, das den erwarteten Gewinn jeder Strategie vorhersagen kann und uns zu potenziell profitablen Strategien führt. Dies ist zwar ein berechtigtes Ziel, aber eine einfachere Alternative wäre es, die Strategie zu ermitteln, die unser Blackbox-Modell am effektivsten erlernen kann – die Auswahl des Ziels, bei dem es „am besten“ abschneidet. Dies stellt jedoch eine große Herausforderung dar.
Der Vergleich der Modellleistung zwischen verschiedenen Regressionszielen ist nicht ganz einfach. Im Gegensatz zu Klassifizierungsaufgaben – bei denen Messgrößen wie Genauigkeit oder Präzision Vergleiche erleichtern – befasst sich die Regression mit realwertigen Zielen wie zukünftigen Erträgen, und gängige Messgrößen wie der RMSE können in die Irre führen. Die Herausforderung besteht darin, dass gängige euklidische Streuungsmetriken skalenabhängig sind, was bedeutet, dass Indikatoren wie Stochastik- und gleitende Durchschnittswerte nicht direkt vergleichbar sind. Abgesehen von diesem Problem bietet das klassische überwachte Lernen hier wenig Anhaltspunkte.
An dieser Stelle wird die gegenseitige Information (MI) wertvoll. MI hat Eigenschaften, die es für den Vergleich von Regressionszielen gut geeignet machen – es ist nichtparametrisch, einheitenlos und bei Null verankert, was uns einen aussagekräftigen Referenzpunkt gibt. Kurz gesagt, bei der Auswahl zwischen mehreren zu modellierenden Zielen empfehlen wir, dasjenige zu wählen, das den MI maximiert.
MI misst die Abhängigkeit zwischen zwei Variablen. In unserem Zusammenhang wollen wir Modellvorhersagen, die auf reale Zieländerungen reagieren. Im ersten Artikel dieser Serie haben wir gezeigt, dass der RMSE durch Modelle, die die durchschnittliche Rendite vorhersagen, verfälscht werden kann. Leser, die unsere frühere Diskussion über Belohnungs-Hacking noch nicht gelesen haben, finden hier einen hilfreichen Link. Kurz gesagt, die MI ist robuster und weniger anfällig für solche Manipulationen, was sie zu einer weitaus zuverlässigeren Lösung für die Ermittlung des informativsten Regressionsziels macht, wenn mehrere Regressionsziele zur Auswahl stehen.
Abrufen der benötigten Daten
Wiederkehrende Leser werden dieses Skript erkennen – es ist dasselbe, das wir in der ersten Version dieser Diskussion verwendet haben. Wir haben sie hier aufgenommen, damit neue Leser sie leichter finden. Das Skript holt die OHLC-Marktdaten zusammen mit gleitenden Durchschnitten, RSI- und Stochastik-Indikatoren. //+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define RSI_PERIOD 15 //--- RSI Period #define STOCH_K 5 //--- Stochastich K Period #define STOCH_D 3 //--- Stochastich D Period #define STOCH_SLOWING 3 //--- Stochastic slowing #define STOCH_MODE MODE_EMA //--- Stochastic mode #define STOCH_PRICE STO_LOWHIGH //--- Stochastic price feeds #define HORIZON 5 //--- Forecast horizon //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle,rsi_handle,stoch_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[],rsi_reading[],sto_reading_main[],sto_reading_signal[]; //--- File name string file_name = Symbol() + " Market Data As Series Indicators.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); rsi_handle = iRSI(_Symbol,PERIOD_CURRENT,RSI_PERIOD,PRICE_CLOSE); stoch_handle = iStochastic(_Symbol,PERIOD_CURRENT,STOCH_K,STOCH_D,STOCH_SLOWING,STOCH_MODE,STOCH_PRICE); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); CopyBuffer(rsi_handle,0,0,fetch,rsi_reading); ArraySetAsSeries(rsi_reading,true); CopyBuffer(stoch_handle,0,0,fetch,sto_reading_main); ArraySetAsSeries(sto_reading_main,true); CopyBuffer(stoch_handle,0,0,fetch,sto_reading_signal); ArraySetAsSeries(sto_reading_signal,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle, //--- Time "Time", //--- OHLC "Open", "High", "Low", "Close", //--- MA OHLC "MA O", "MA H", "MA L", "MA C", //--- RSI "RSI", //--- Stochastic Oscilator "Stoch Main", "Stoch Signal" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], ma_reading[i], //--- RSI rsi_reading[i], //--- Stochastic Oscilator sto_reading_main[i], sto_reading_signal[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_PERIOD #undef MA_TYPE //+------------------------------------------------------------------+
Erste Schritte in Python
Sobald die Daten abgerufen sind, beginnen wir mit unserer Analyse in Python. Wir beginnen mit dem Import der Standard-Python-Bibliotheken, die zum Einlesen unserer Daten verwendet werden.#Import the standard libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Als Nächstes legen wir fest, wie weit in die Zukunft wir prognostizieren wollen.
HORIZON = 10
Lassen Sie uns nun die Daten lesen.
data = pd.read_csv("../EURUSD Market Data As Series Indicators.csv")
Wir fügen dem Datensatz Kennzeichnungen hinzu. Wie in der verlinkten Diskussion über Belohnungs-Hacking erwähnt, kann die Kennzeichnung Ihrer Daten als Änderung einer Variablen zu Problemen führen, da die beste Vorhersage oft die durchschnittliche Änderung im Trainingssatz ist. Wie die Leser später in diesem Artikel sehen werden, haben wir jedoch festgestellt, dass das Erlernen der Veränderung des stochastischen Hauptindikators trotz der durch die Differenzierung des Ziels verursachten Probleme möglich und profitabel ist.
data['Price Target'] = data['Close'].shift(-HORIZON) - data['Close'] data['MA C Target'] = data['MA C'].shift(-HORIZON) - data['MA C'] data['Stoch Target'] = data['Stoch Main'].shift(-HORIZON) - data['Stoch Main'] data['RSI Target'] = data['RSI'].shift(-HORIZON) - data['RSI']
Um die Basiswahrheit zu ermitteln, kennzeichnen wir unsere Ziele auch im Stil einer binären Klassifizierung. Zunächst werden alle Etiketten auf 0 initialisiert.
data['Price Target 2'] = 0 data['MA C Target 2'] = 0 data['Stoch Target 2'] = 0 data['RSI Target 2'] = 0
Dann setzen wir die Kennzeichen auf 1, wenn der tatsächliche Zielwert gestiegen ist.
data.loc[data['Close'].shift(-HORIZON) > data['Close'],'Price Target 2'] = 1 data.loc[data['MA C'].shift(-HORIZON) > data['MA C'],'MA C Target 2'] = 1 data.loc[data['Stoch Main'].shift(-HORIZON) > data['Stoch Main'],'Stoch Target 2'] = 1 data.loc[data['RSI'].shift(-HORIZON) > data['RSI'],'RSI Target 2'] = 1
Dann überspringen wir alle Zeiträume, die sich mit dem geplanten Backtest-Zeitraum überschneiden. Für diese Diskussion lassen wir die letzten 3 Jahre der historischen Daten weg und bewahren sie für die Modellbewertung auf.
#Drop the last 3 years of historical data data = data.iloc[:-(365*3),:] test = data.iloc[-(365*3):,:]
Trennen wir die Ein- und Ausgänge.
X = data.iloc[:,1:12] y = data.iloc[:,12:-4] y_classif = data.iloc[:,-4:] X_test = test.iloc[:,1:12] y_test = test.iloc[:,12:-4] y_classif_test = test.iloc[:,-4:]
Wir laden die Abhängigkeiten für maschinelles Lernen.
import onnx from sklearn.linear_model import Ridge from sklearn.ensemble import AdaBoostClassifier from sklearn.neural_network import MLPRegressor from skl2onnx.convert import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.model_selection import RandomizedSearchCV,TimeSeriesSplit,cross_val_score from sklearn.metrics import root_mean_squared_error from sklearn.feature_selection import mutual_info_regression
Wie bei den meisten unserer Diskussionen über sorgfältige Modellierung verwenden wir eine Kreuzvalidierung der Zeitreihen, um zuverlässige Erkenntnisse zu gewinnen.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Wirt definieren eine Methode, die eine neue Instanz eines identischen Modells zurückgibt.
def get_model(): return(Ridge(alpha=1e-3))
Wir passen ein Modell für jedes verfügbare Ziel an.
#Control model model_a = get_model() #Close Moving Average model model_b = get_model() #Stoch model model_c = get_model() #RSI model model_d = get_model() model_a.fit(X,y.iloc[:,0]) model_b.fit(X,y.iloc[:,1]) model_c.fit(X,y.iloc[:,2]) model_d.fit(X,y.iloc[:,3])
Nun zeichnen wir die Vorhersagen jedes Modells für den Testsatz auf – aber wir passen das Modell nicht mit den Testdaten an!
preds_a = model_a.predict(X_test) preds_b = model_b.predict(X_test) preds_c = model_c.predict(X_test) preds_d = model_d.predict(X_test)
Wir beginnen mit der Untersuchung der Leistung des Modells, das versucht, Preisänderungen direkt vorherzusagen. Den Lesern, die schon einmal hier waren, dürfte das Folgende bekannt vorkommen. Die x-Achse zeigt die vom Modell vorhergesagten Werte, und die y-Achse zeigt die Häufigkeit dieser Vorhersagen. Die drei gestrichelten Linien im Diagramm stellen den durchschnittlichen Zielwert (mittlere Linie) und die extremsten Werte dar, die in der Trainingsgruppe beobachtet wurden (äußere Linien). Die rote Linie stellt die Häufigkeit der realen Renditen im Testsatz dar, während die schwarze Linie die Modellvorhersagen zeigt. Wie wir sehen können, gruppiert das Modell seine Vorhersagen um den durchschnittlichen Zielwert, den es im Trainingssatz gelernt hat, und erfasst nicht die gesamte Bandbreite der realen Marktbewegungen.
Beachten Sie, dass der MI-Wert zusammen mit dem RMSE-Wert aufgezeichnet wird. Im Titel des Diagramms zur Kernel-Dichte-Schätzung wird nur der MI-Wert angezeigt. Das Preismodell erreichte einen MI von 0,04233. Es sei daran erinnert, dass MI-Werte nahe 0 unerwünscht sind – sie zeigen an, dass die Vorhersagen des Modells unabhängig von realen Marktwechselkursen sind.
score_1 = mutual_info_regression(y_test.iloc[:,[0]],preds_a) score_1_rmse = root_mean_squared_error(y_test.iloc[:,[0]],preds_a) s = 'Forecasting Price Directly Mutual Information: ' + str(score_1[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,0],color='red') sns.kdeplot(preds_a,color='black') plt.axvline(y.iloc[:,0].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,0].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,0].min(),color='black',linestyle=':') plt.legend(['Actual Exchange Rate','Forecasted Exchange Rate']) plt.grid()
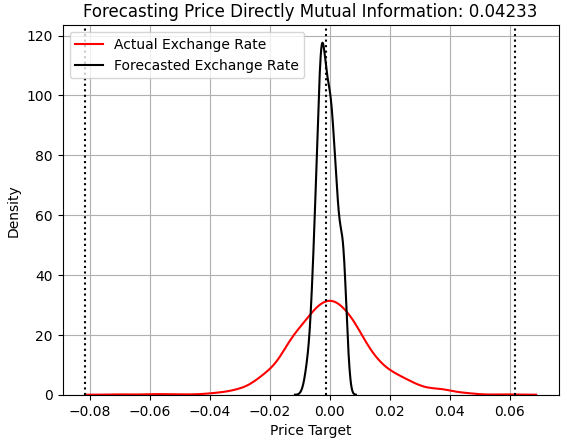
Abbildung 1: Visualisierung der Vorhersagen unseres Modells im Vergleich zu den realen Wechselkursen, die bei der Preisprognose außerhalb der Stichprobe beobachtet wurden
Im Streudiagramm wird das Problem noch deutlicher. Die Vorhersagen des Modells (in schwarz) liegen in der Mitte der realen Wechselkurse (in rot). Dies ist das Problem des Belohnungs-Hackings, das wir bereits vorgestellt haben. Traditionelle „Best Practices“ würden den RMSE begünstigen und somit die Verwendung dieses Modells im Live-Handel fördern. Aber wie wir sehen werden, fängt MI dieses Problem schnell auf und bietet eine robustere Leistungsmessung.
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,0],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_a,color='black') plt.legend(['Actual Exchange Rate','Forecasted Exchange Rate']) plt.xlabel('Historical Time Epochs') plt.ylabel('EURUSD Exchange Rate') plt.title(s) plt.grid()

Abbildung 2: Unser erstes Modell zeigt ein geiziges Verhalten, das unerwünscht ist
Betrachten wir nun die Leistung eines statistischen Modells, das lernt, Veränderungen im Indikator des gleitenden Durchschnitts zu erwarten. In unseren Diagrammen wird durchgängig die gleiche Darstellungsweise verwendet, sodass wir schnell feststellen können, dass dieses Modell die Breite des Ziels immer noch nicht erfasst, obwohl sich sein MI-Wert um mehr als 100 % von 0,04 auf 0,1 erhöht hat. Aus der KDE-Darstellung in Abbildung 3 geht jedoch nicht hervor, warum sich der MI-Wert verbessert hat.
score_2 = mutual_info_regression(y_test.iloc[:,[1]],preds_b) score_2_rmse = root_mean_squared_error(y_test.iloc[:,[1]],preds_b) s = 'Forecasting Moving Average Directly Mutual Information: ' + str(score_2[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,1],color='red') sns.kdeplot(preds_b,color='black') plt.axvline(y.iloc[:,1].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,1].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,1].min(),color='black',linestyle=':') plt.legend(['Actual Moving Average','Forecasted Moving Average']) plt.grid()
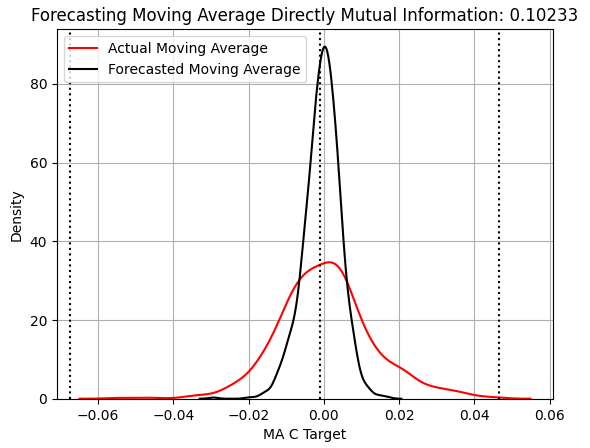
Abbildung 3: Veranschaulichung der Fähigkeit zur Vorhersage von Änderungen des Indikators „Gleitender Durchschnitt schließen“.
Die Verbesserung wird deutlich, wenn wir ein Streudiagramm der Vorhersagen des Modells außerhalb der Stichprobe betrachten. Was einst eine dünne schwarze Linie war, die auf den beobachteten Wechselkursen zentriert war, hat sich nun zu einer breiteren Verteilung ausgeweitet, was eine erhöhte Empfindlichkeit gegenüber Veränderungen auf dem EURUSD-Markt zeigt. Das Modell ist immer noch nicht akzeptabel, aber es ist ein Schritt in die richtige Richtung.
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,1],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_b,color='black') plt.legend(['Actual Moving Average','Forecasted Moving Average']) plt.xlabel('Historical Time Epochs') plt.ylabel('EURUSD Moving Average') plt.title(s) plt.grid()
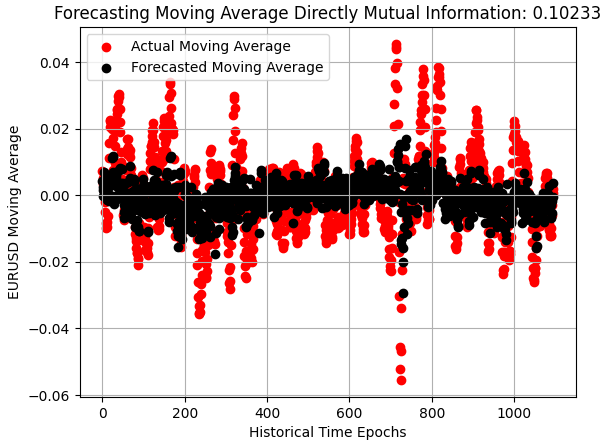
Abbildung 4: Unser Modell hat sich erheblich verbessert und beginnt, die Volatilität des Marktes zu erfassen
Bei der Bewertung des Modells zur Vorhersage des stochastischen Indikators zeigen sich wesentliche Verbesserungen. Noch bevor wir den dramatischen Anstieg der MI berücksichtigen, können wir sehen, dass wir endlich ein Modell erstellt haben, das sich nicht an den Mittelwert anlehnt. Dieses Modell ist das einzige in unserer Diskussion, das der Verteilung der Testbeobachtungen einigermaßen ähnelt und die Breite des Marktes besser abbildet als die vorherigen Modelle.
score_3 = mutual_info_regression(y_test.iloc[:,[2]],preds_c) score_3_rmse = root_mean_squared_error(y_test.iloc[:,[2]],preds_c) s = 'Forecasting EURUSD Stochastic Directly MI: ' + str(score_3[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,2],color='red') sns.kdeplot(preds_c,color='black') plt.axvline(y.iloc[:,2].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,2].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,2].min(),color='black',linestyle=':') plt.legend(['Actual Stochastic','Forecasted Stochastic']) plt.grid()
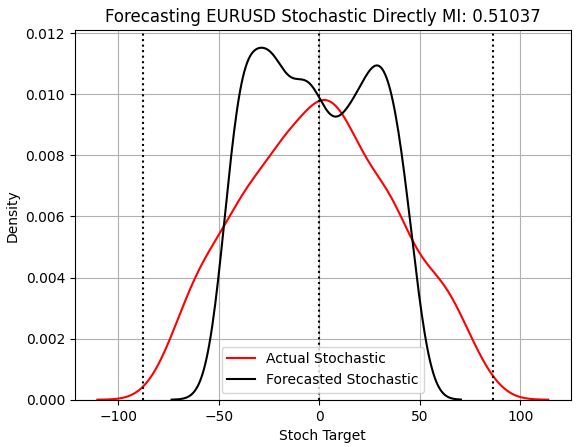
Abbildung 5: Unser Modell liefert endlich Ergebnisse, die symmetrisch zu den wahren Beobachtungen sind, die wir beim Training nicht berücksichtigt haben
Betrachtet man die Streuung der Ergebnisse, wird der Grund für den dramatischen Anstieg der MI deutlich. Das stochastische Modell schneidet außerhalb der Stichprobe beeindruckend ab und erfasst nahezu die tatsächliche Volatilität des Marktes. Vergleicht man dieses Streudiagramm mit Abbildung 1, so wird deutlich, warum sich MI hervorragend für die automatische Auswahl von Regressionszielen eignet.
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,2],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_c,color='black') plt.ylabel('Growth in The Stochastic Main Indicator') plt.xlabel('Historical Time Epochs') plt.title(s) plt.grid()

Abbildung 6: Visualisierung unserer Fähigkeit, Veränderungen im Stochastik-Oszillator zu erfassen
Als Nächstes betrachten wir die Vorhersage des RSI und der damit verbundenen Veränderungen. Leider ist der RSI, wie unten gezeigt, ebenso schwierig zu prognostizieren wie die gleitenden Durchschnittsindikatoren und bringt den MI-Score wieder auf den Stand von früher zurück. Das Modell erfasst auch nicht die tatsächliche Breite des Marktes, obwohl sich die RSI-Änderungen in der Testgruppe natürlich um 0 herum gruppieren. Allerdings überschätzt das Modell diesen Anteil, was zu einer suboptimalen Leistung führen kann.
score_4 = mutual_info_regression(y_test.iloc[:,[3]],preds_d) score_4_rmse = root_mean_squared_error(y_test.iloc[:,[3]],preds_d) s = 'Forecasting EURUSD RSI Directly MI: ' + str(score_4[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,3],color='red') sns.kdeplot(preds_d,color='black') plt.axvline(y.iloc[:,3].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,3].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,3].min(),color='black',linestyle=':') plt.grid() plt.legend(['Actual RSI','Forecasted RSI'])
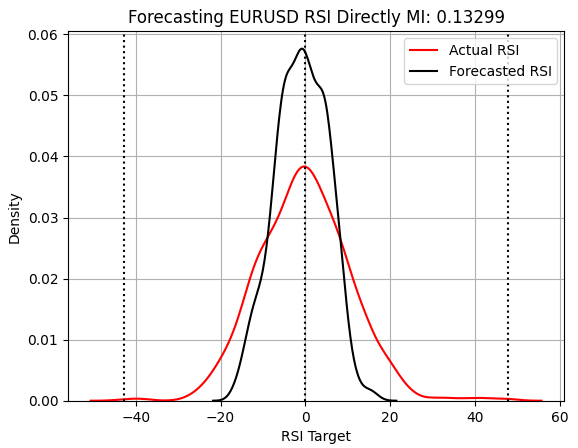
Abbildung 7: Unsere RSI-Strategie scheint die Anzahl der Vorhersagen, die sich um den Wert 0 gruppieren, zu überschätzen.
Wenn wir schließlich die Streuung der RSI-Prognose untersuchen, können wir feststellen, dass dieses Modell zwar besser ist als das Modell, mit dem wir begonnen haben – es verläuft nicht nur entlang der Mitte der Beobachtungen – aber die Marktdynamik immer noch nicht so gut erfasst wie das Modell des stochastischen Oszillators.
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,3],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_d,color='black') plt.legend(['Actual RSI','Forecasted RSI']) plt.xlabel('Historical Time Epochs') plt.ylabel('EURUSD Moving Average') plt.title('Visualizing Our Ability To Forecast Change in EURUSD Moving Average') plt.grid()
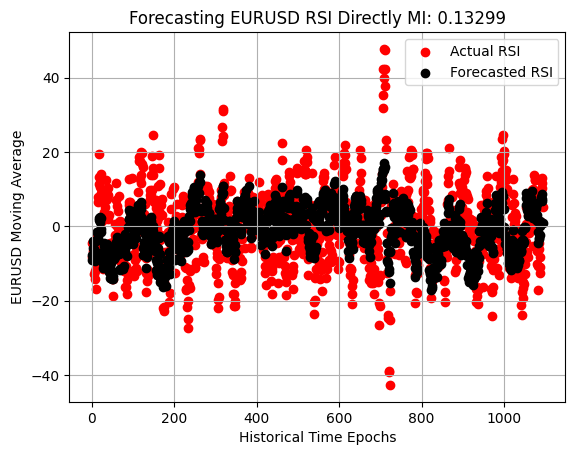
Abbildung 8: Unsere Strategie lernte besser, Veränderungen im RSI zu erwarten, als Veränderungen im Preis direkt.
Nach allem, was wir gesehen haben, sollte klar sein, dass das Modell, das lernt, Veränderungen im stochastischen Oszillator vorherzusagen, am besten abschneidet, auch außerhalb der Stichprobe. Wir konnten dies anhand der Streudiagramme visuell erkennen. Nach der Erstellung eines Balkendiagramms der MI-Bewertungen für jedes Ziel ist nun ein klarer Gewinner zu erkennen. Aber der Leser sollte wissen, dass wir hier beim Kern des Problems angelangt sind, das dieser Artikel behandelt. Wir haben die MI-Werte für jedes Modell dargestellt, aber auch die RMSE-Werte aufgezeichnet. Was passiert, wenn wir stattdessen den RMSE darstellen?
mi_scores = [score_1,score_2,score_3,score_4] rmse_scores = [score_1_rmse,score_2_rmse,score_3_rmse,score_4_rmse] sns.barplot(mi_scores,color='black') plt.ylabel('Mutual Information Score') plt.xlabel('Target') plt.title('Mutual Information Score') plt.xticks([0,1,2,3],['Price','Moving Average','Stochastic','RSI'])
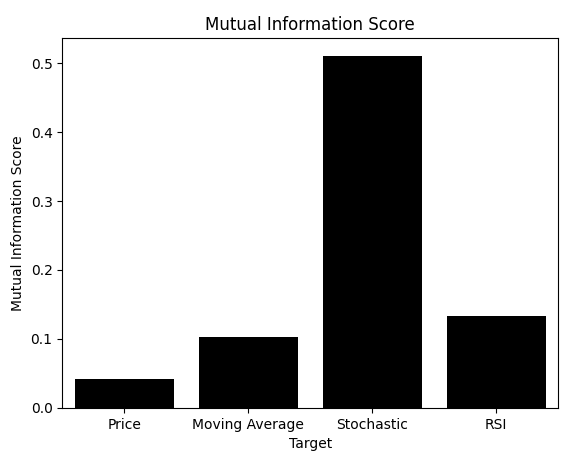
Abbildung 9: Die gegenseitige Information identifiziert korrekt das geeignete Ziel für die Modellierung, da sie nicht von der Größe der Daten abhängig ist.
Wie gezeigt, sagt der RMSE – die Kennzahl, auf die sich viele Praktiker verlassen – etwas ganz anderes aus. Denken Sie daran, dass RMSE und MI unterschiedlich interpretiert werden. Bei der Verwendung von MI wollen wir Modelle, die die Punktzahl maximieren. Beim RMSE geht es darum, die Punktzahl zu minimieren. Leider führte der RMSE dazu, dass wir uns für die Modelle „Preis“ oder „Gleitender Durchschnitt“ entschieden, obwohl wir visuell bestätigten, dass sie suboptimal waren.
Würden Sie angesichts der Informationen, die Sie bisher gelesen haben, dem RMSE oder dem MI als Leitfaden vertrauen? Einigen Lesern dürfte das Problem jetzt klar sein. Für diejenigen, die noch unsicher sind, führen wir einen weiteren Test durch, um die Schwäche des RMSE aufzuzeigen.
sns.barplot(rmse_scores,color='black') plt.xticks([0,1,2,3],['Price','Moving Average','Stochastic','RSI']) plt.title('RMSE Score ') plt.ylabel('Root Mean Squared Error') plt.xlabel('Target')
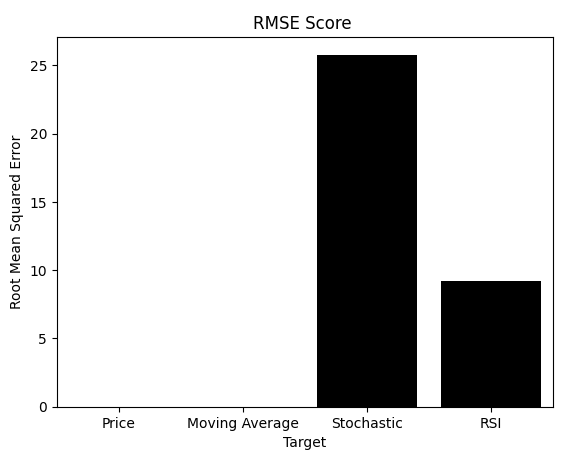
Abbildung 10: Der RMSE könnte uns fälschlicherweise zu der Annahme verleiten, dass das Modell, das den stochastischen Oszillator lernt, eine schlechte Leistung erbringt.
Wir definieren erneut eine Methode, um ein neues Klassifizierungsmodell zu erstellen, und vergleichen dessen Genauigkeit bei der Klassifizierung von binären Änderungen in jedem Ziel. Wie zuvor erstellen wir vier identische Kopien desselben Modells und messen die Kreuzvalidierungsgenauigkeit an der Trainingsmenge. Wir verfolgten auch die Genauigkeit, die jedes Modell erreichen würde, wenn es einfach die Mehrheitsklasse in seinem Trainingssatz vorhersagen würde – eine weitere Form von Belohnungshacking, auf die man achten sollte. Wenn wir diese Ergebnisse grafisch darstellen, wird deutlich, dass das stochastische Modell am besten abschneidet, genau wie MI es zuvor deutlich gezeigt hat. Die rote Linie in der Grafik zeigt die höchste Genauigkeit, die ein Modell durch Belohnungs-Hacking erreichen kann, was bestätigt, dass die Leistung des stochastischen Modells legitimerweise signifikant ist.
def get_model(): return(AdaBoostClassifier()) #Control model model_a = get_model() #Close Moving Average model model_b = get_model() #Stoch model model_c = get_model() #RSI model model_d = get_model() score = [] score.append(np.mean(cross_val_score(model_a,X,y_classif.iloc[:,0],cv=tscv,scoring='accuracy',n_jobs=-1))) score.append(np.mean(cross_val_score(model_b,X,y_classif.iloc[:,1],cv=tscv,scoring='accuracy',n_jobs=-1))) score.append(np.mean(cross_val_score(model_c,X,y_classif.iloc[:,2],cv=tscv,scoring='accuracy',n_jobs=-1))) score.append(np.mean(cross_val_score(model_d,X,y_classif.iloc[:,3],cv=tscv,scoring='accuracy',n_jobs=-1))) h1 = y_classif.loc[y_classif['Price Target 2'] == 1].shape[0] / y_classif.shape[0] h2 = y_classif.loc[y_classif['MA C Target 2'] == 1].shape[0] / y_classif.shape[0] h3 = y_classif.loc[y_classif['Stoch Target 2'] == 1].shape[0] / y_classif.shape[0] h4 = y_classif.loc[y_classif['RSI Target 2'] == 1].shape[0] / y_classif.shape[0] reward_hacking = [h1,h2,h3,h4] sns.barplot(score,color='black') plt.xticks([0,1,2,3],['Price','MA','Stochastic','RSI']) plt.ylabel('Accuracy Score 100%') plt.xlabel('Potential Target') plt.axhline(np.max(reward_hacking),color='red',linestyle=':') plt.title('Our Accuracy Changes Depending On The Target')
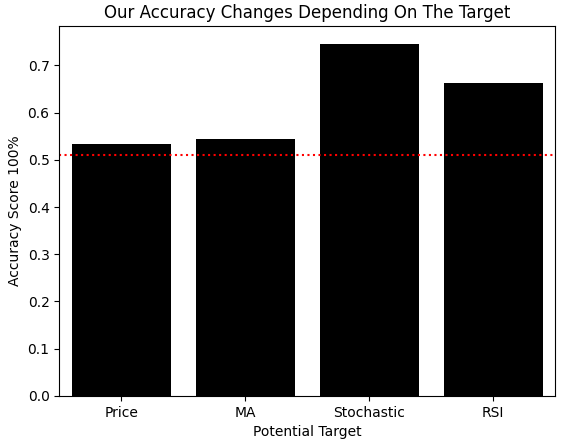
Abbildung 11: Auch wenn wir unser Problem als Klassifizierungsaufgabe formulieren, kommen wir zu demselben Ergebnis
Nachdem wir nun die Strategie ermittelt haben, die unser Blackbox-Modell am besten lernt, können wir die Handelsregeln direkt aus den Daten ableiten. Wenn zum Beispiel ein Anstieg des Stochastik-Oszillators vorhergesagt wird, sollten wir dann kaufen oder verkaufen? Eine Möglichkeit, diese Frage zu beantworten, besteht darin, die durchschnittliche Rendite aller Fälle zu untersuchen, in denen die Stochastik den Wert 1 hatte. In unserem Fall lag dieser Durchschnitt bei 0,0052, was bedeutet, dass es sinnvoll ist, Kaufpositionen einzugehen, wenn ein Anstieg des Oszillators erwartet wird.
data.loc[data['Stoch Target 2']==1,'Price Target'].mean()
0.005242425488180883
Natürlich ist keine Strategie perfekt – es gab Fälle, in denen der Preis trotz eines positiven Kennzeichens fiel.
data.loc[data['Stoch Target 2']==1,'Price Target'].min()
-0.06370000000000009
Der Wert dieser Übung liegt jedoch darin, dass der Leser anhand von Daten und nicht intuitiv beurteilen kann, ob die Strategie mit seinem Risikoprofil übereinstimmt. Wenn man berechnet, wie oft sich der Kurs und der Stochastik-Oszillator gemeinsam bewegten, stellt man fest, dass sie in 71 % der Fälle übereinstimmten. Dieser Vorlauf gibt uns weiteres Vertrauen in diese Strategie.
print('Price And The Stochastic Rise Together: ',((data.loc[(data['Stoch Target 2']==1 ) & (data['Price Target 2']==1),:].shape[0] / data.loc[data['Price Target 2'] == 1].shape[0])) * 100,'% of the time')
Der Preis und die Stochastik steigen gemeinsam an: 70.94972067039106 % der Zeit
Wenn selbst einfache Modelle erkennen können, dass der stochastische Oszillator leichter zu erlernen ist, dann sollte ein flexibleres Modell wie ein tiefes neuronales Netzwerk, das richtig konfiguriert ist, diese Beziehung noch besser erfassen. Wir werden dies untersuchen, indem wir eine randomisierte Suche über die Hyperparameter des neuronalen Netzes durchführen. Zunächst werden alle möglichen zu bewertenden Eingabewerte aufgelistet.
dist = {
'max_iter':[10,50,100,500,1000,5000,10000,50000,100000],
'activation':['tanh','relu','identity','logistic'],
'alpha':[10e0,10e-1,10e-2,10e-3,10e-4,10-5,10e-6],
'solver':['lbfgs','adam','sgd'],
'learning_rate':['constant','invscaling','adaptive'],
'hidden_layer_sizes':[(11,1),(11,22,33,44,33,22,11,5),(11,4,40,20,2),(11,11),(11,11,11),(11,11,11,11),(11,22,33,44),(11,22,55,22,11),(11,100,11),(11,5,2,5,11),(11,3,9,18,9,3)]
} Dann definieren wir feste Konstanten, die während des Trainings unverändert bleiben.
#Define the model model = MLPRegressor(shuffle=False,early_stopping=False,random_state=0,verbose=True) #Initialize the randomized search object rscv = RandomizedSearchCV(model,dist,random_state=0,n_iter=40,scoring='neg_mean_squared_error',cv=tscv,n_jobs=-1,refit=True) #Perform the search res = rscv.fit(X,y_classif['Stoch Target 2']) res.best_estimator_
Nach der Auswahl des besten Modells durch die Zufallssuche können wir es in das ONNX-Format (Open Neural Network Exchange) exportieren. ONNX ist ein weit verbreiteter offener Standard, der Modelle portabel und rahmenunabhängig macht. Wir beginnen mit der Definition der vom Modell erwarteten Eingabe- und Ausgabeformen.
initial_types = [('float_input',FloatTensorType([1,X.shape[1]]))] final_types = [('float_output',FloatTensorType([1,1]))]
Als Nächstes wird das ONNX-Modell in seine Prototypform umgewandelt, die als Zwischendarstellung dient, bevor es mit der ONNX-Speicherfunktion auf der Festplatte gespeichert wird.
onnx_proto = convert_sklearn(model=res.best_estimator_,initial_types=initial_types,final_types=final_types,target_opset=12) onnx.save(onnx_proto,'Unsupervised Strategy Selection Stochastic MLP.onnx')
Aufbau unserer Anwendung in MQL5
Wenn das Modell fertig ist, können wir mit dem Aufbau unserer Handelsanwendung beginnen. Wir beginnen mit dem Laden des ONNX-Modells und der Festlegung von Systemkonstanten, um konsistente Indikatorberechnungen bei Datenabruf und Strategieauswahl zu gewährleisten.//+------------------------------------------------------------------+
//| Automatic Strategy Selection.mq5 |
//| Gamuchirai Ndawana |
//| https://www.mql5.com/en/users/gamuchiraindawa |
//+------------------------------------------------------------------+
#property copyright "Gamuchirai Ndawana"
#property link "https://www.mql5.com/en/users/gamuchiraindawa"
#property version "1.00"
//+------------------------------------------------------------------+
//| System resources |
//+------------------------------------------------------------------+
#resource "\\Files\\Unsupervised Strategy Selection Stochastic MLP.onnx" as const uchar onnx_buffer[]; Als Nächstes definieren wir Systemkonstanten, um sicherzustellen, dass die Berechnung unserer technischen Indikatoren sowohl mit dem Skript zum Abrufen der Daten als auch mit den Indikatorberechnungen aus unserer früheren Diskussion über die automatische Strategieauswahl übereinstimmt.
//+------------------------------------------------------------------+ //| System definiyions | //+------------------------------------------------------------------+ #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average #define RSI_PERIOD 15 //--- RSI Period #define STOCH_K 5 //--- Stochastich K Period #define STOCH_D 3 //--- Stochastich D Period #define STOCH_SLOWING 3 //--- Stochastic slowing #define STOCH_MODE MODE_EMA //--- Stochastic mode #define STOCH_PRICE STO_LOWHIGH //--- Stochastic price feeds #define TOTAL_STRATEGIES 4 //--- Total strategies we have to choose from #define ONNX_INPUTS 11 //--- Total inputs needed by our ONNX model #define ONNX_OUTPUTS 1 //--- Total outputs needed by our ONNX modelWir werden auch die Handelsbibliothek benötigen, um unser Marktengagement zu verwalten.
//+------------------------------------------------------------------+
//| System libraries |
//+------------------------------------------------------------------+
#include <Trade\Trade.mqh>
CTrade Trade; Eine Handvoll globaler Variablen wird benötigt, um die Zeit, die Indikatorwerte und unsere Modellvorhersagen zu verfolgen.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_c_handle,ma_o_handle,ma_h_handle,ma_l_handle,rsi_handle,stoch_handle,atr_handle; double ma_c_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[],rsi_reading[],sto_reading_main[],sto_reading_signal[],atr_reading[]; long onnx_model; vectorf onnx_features,onnx_targets; MqlDateTime ts,tc; MqlTick current_tick;
Wir können nun unser ONNX-Modell initialisieren, indem wir es mit der Methode OnnxCreateFromBuffer aus dem ONNX-Puffer erstellen. Anschließend definieren und testen wir die Eingabe- und Ausgabedimensionen und führen eine abschließende Prüfung durch, um sicherzustellen, dass das Modell solide ist. Wenn alle Tests bestanden sind, werden die Zeiterfassung und die erforderlichen technischen Indikatoren initialisiert.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Prepare the model's inputs and outputs onnx_features = vectorf::Zeros(ONNX_INPUTS); onnx_targets = vectorf::Zeros(ONNX_OUTPUTS); //--- Create the ONNX model onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DATA_TYPE_FLOAT); //--- Define the I/O shape ulong input_shape[] = {1,ONNX_INPUTS}; ulong output_shape[] = {ONNX_OUTPUTS,1}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Print("Failed to define ONNX input shape"); return(INIT_FAILED); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Print("Failed to define ONNX output shape"); return(INIT_FAILED); } //--- Check if the model is valid if(onnx_model == INVALID_HANDLE) { Print("Failed to create our ONNX model from buffer"); return(INIT_FAILED); } //--- Setup the time TimeLocal(tc); TimeLocal(ts); //---Setup our technical indicators ma_c_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); atr_handle = iATR(_Symbol,PERIOD_CURRENT,14); rsi_handle = iRSI(_Symbol,PERIOD_CURRENT,RSI_PERIOD,PRICE_CLOSE); stoch_handle = iStochastic(_Symbol,PERIOD_CURRENT,STOCH_K,STOCH_D,STOCH_SLOWING,STOCH_MODE,STOCH_PRICE); //--- return(INIT_SUCCEEDED); }
Wenn die Anwendung nicht mehr verwendet wird, geben wir die dem ONNX-Modell und den technischen Indikatoren zugewiesenen Ressourcen frei.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- OnnxRelease(onnx_model); IndicatorRelease(ma_c_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(ma_h_handle); IndicatorRelease(ma_l_handle); IndicatorRelease(rsi_handle); IndicatorRelease(stoch_handle); IndicatorRelease(atr_handle); }
Immer wenn wir neue Kursniveaus erhalten, prüfen wir zunächst, ob sich eine neue Tageskerze gebildet hat, und aktualisieren dann die Uhrzeit und alle technischen Indikatorenwerte. Jede Modelleingabe wird dann in einen Float umgewandelt, um die Kompatibilität mit dem ONNX-Modell zu gewährleisten, bevor eine Vorhersage erstellt wird. Die Vorhersage wird mit unseren Markteintrittsbedingungen verglichen, um die geeignete Position zu bestimmen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- TimeLocal(ts); if(ts.day != tc.day) { //--- Update the time TimeLocal(tc); //--- Update Our indicator readings CopyBuffer(ma_c_handle,0,0,1,ma_c_reading); CopyBuffer(ma_o_handle,0,0,1,ma_o_reading); CopyBuffer(ma_h_handle,0,0,1,ma_h_reading); CopyBuffer(ma_l_handle,0,0,1,ma_l_reading); CopyBuffer(rsi_handle,0,0,1,rsi_reading); CopyBuffer(stoch_handle,0,0,1,sto_reading_main); CopyBuffer(stoch_handle,0,0,1,sto_reading_signal); CopyBuffer(atr_handle,0,0,1,atr_reading); //--- Set our model inputs onnx_features[0] = (float) iOpen(Symbol(),PERIOD_CURRENT,0); onnx_features[1] = (float) iHigh(Symbol(),PERIOD_CURRENT,0); onnx_features[2] = (float) iLow(Symbol(),PERIOD_CURRENT,0); onnx_features[3] = (float) iClose(Symbol(),PERIOD_CURRENT,0); onnx_features[4] = (float) ma_o_reading[0]; onnx_features[5] = (float) ma_h_reading[0]; onnx_features[6] = (float) ma_l_reading[0]; onnx_features[7] = (float) ma_c_reading[0]; onnx_features[8] = (float) rsi_reading[0]; onnx_features[9] = (float) sto_reading_main[0]; onnx_features[10] = (float) sto_reading_signal[0]; //--- Copy Market Data double close = iClose(Symbol(),PERIOD_CURRENT,0); SymbolInfoTick(Symbol(),current_tick); //--- Place a position if(PositionsTotal() ==0) { if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,onnx_features,onnx_targets)) { Comment("Onnx Model Prediction: \n",onnx_targets); //--- Store our result if(LongConditions()) Buy(); else if(ShortConditions()) Sell(); } else { Print("No trading oppurtunities expected."); } } } } //+------------------------------------------------------------------+
Die Bedingungen für den Markteintritt sind in eigenen Methoden festgelegt. Wenn die ONNX-Prognose den Wert von 0,5 überschreitet, wird ein Anstieg des stochastischen Oszillators erwartet. Wenn der Oszillator über 50 liegt und weiter steigt, gehen wir eine Kaufposition ein. Liegt der Oszillator unter der klassischen 30er-Marke, gehen wir ebenfalls Kaufpositionen ein. Wenn wir schließlich eine Engulfing-Aufwärtskerze beobachten, ist dies die letzte Bedingung, um zu kaufen. Das Gegenteil ist der Fall bei Verkaufseröffnungen.
//+------------------------------------------------------------------+ //| The market conditions we require to open short positions | //+------------------------------------------------------------------+ bool ShortConditions(void) { return(((onnx_targets[0] < 0.5) && (sto_reading_main[0]<50)) || (sto_reading_main[0]<80) || (iHigh(Symbol(),PERIOD_CURRENT,1) > iHigh(Symbol(),PERIOD_CURRENT,2) && iLow(Symbol(),PERIOD_CURRENT,1) > iLow(Symbol(),PERIOD_CURRENT,2) && iOpen(Symbol(),PERIOD_CURRENT,1)<iOpen(Symbol(),PERIOD_CURRENT,2))); } //+------------------------------------------------------------------+ //| The market conditions we require to open long positions | //+------------------------------------------------------------------+ bool LongConditions(void) { return(((onnx_targets[0] > 0.5) && (sto_reading_main[0]>50)) || (sto_reading_main[0]>30) || (iHigh(Symbol(),PERIOD_CURRENT,1) > iHigh(Symbol(),PERIOD_CURRENT,2) && iLow(Symbol(),PERIOD_CURRENT,1) > iLow(Symbol(),PERIOD_CURRENT,2) && iOpen(Symbol(),PERIOD_CURRENT,1)>iOpen(Symbol(),PERIOD_CURRENT,2))); }
Bei der Platzierung von Kauf- und Verkaufspositionen verwenden wir für jeden Einstieg die gleiche Losgröße und setzen Take-Profit- und Stop-Loss-Niveaus in gleichen Abständen.
//+------------------------------------------------------------------+ //| Enter a long position | //+------------------------------------------------------------------+ void Buy(void) { Trade.Buy(0.01,Symbol(),current_tick.ask,current_tick.ask-(1.5*atr_reading[0]),current_tick.ask+(1.5*atr_reading[0])); } //+------------------------------------------------------------------+ //| Enter a short position | //+------------------------------------------------------------------+ void Sell(void) { Trade.Sell(0.01,Symbol(),current_tick.bid,current_tick.bid+(1.5*atr_reading[0]),current_tick.bid-(1.5*atr_reading[0])); } //+------------------------------------------------------------------+
Schließlich werden am Ende jeder Anwendung alle Systemkonstanten zurückgesetzt.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_PERIOD #undef MA_TYPE #undef RSI_PERIOD #undef STOCH_K #undef STOCH_D #undef STOCH_SLOWING #undef STOCH_MODE #undef STOCH_PRICE #undef TOTAL_STRATEGIES #undef ONNX_INPUTS #undef ONNX_OUTPUTS //+------------------------------------------------------------------+
Nachdem die Einrichtung unserer Anwendung abgeschlossen ist, wählen wir nun das 3-Jahres-Backtest-Fenster aus, das wir vorhin aus unserem Modelltraining herausgehalten haben. Der Backtest erstreckt sich von Januar 2022 bis weit über Januar 2025 hinaus.
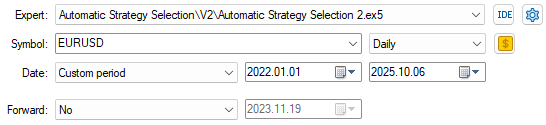
Abbildung 12: Auswahl des Backtest-Fensters zur Bewertung unserer Strategie über
Die Modellierung auf der Grundlage echter Ticks mit zufälligen Verzögerungseinstellungen ermöglicht eine zuverlässige Nachbildung der realen Marktbedingungen.
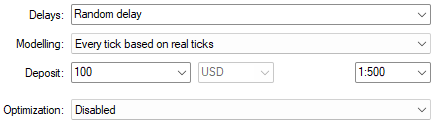
Abbildung 13: Wählen Sie die richtigen Backtest-Bedingungen, um realistische Erwartungen zu lernen
Die von unserer überarbeiteten Blackbox-Lösung erstellte Kapitalkurve zeigt einen starken Aufwärtstrend, der die Gesundheit der Strategie belegt. Wir beobachten auch Phasen, in denen die Strategie herausgefordert wurde, aber wir sind ermutigt zu sehen, dass sie sich von jedem Rückschlag mit Widerstandsfähigkeit erholte.
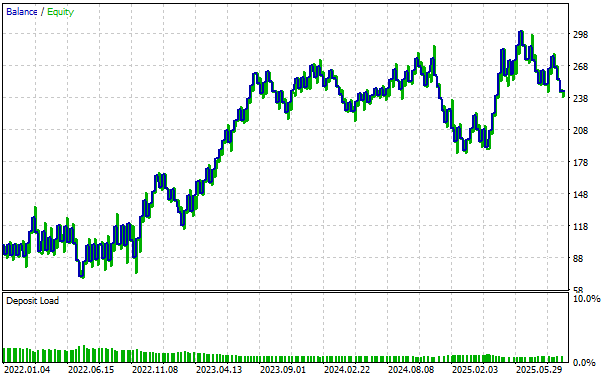
Abbildung 14: Die Visualisierung der Kapitalkurve, die wir durch unsere sorgfältig überarbeitete Handelsstrategie erhalten haben, gibt uns Vertrauen in die von uns vorgenommenen Änderungen
Wenn wir schließlich die detaillierten Statistiken unserer Strategie analysieren, stellen wir eine deutliche Verbesserung im Vergleich zu unserem ersten Versuch fest, alle möglichen Strategien zu modellieren. Unsere Strategie war gewinnbringend, mit einem starken Aufschwung und Gewinnfaktor.
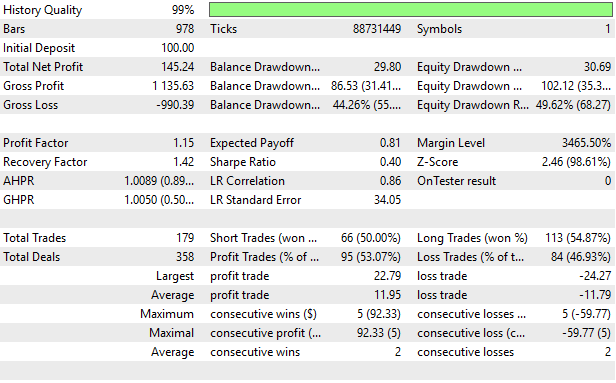
Abbildung 15: Visualisierung der detaillierten Ergebnisse unserer verbesserten Blackbox-Lösung
Schlussfolgerung
Wir sind nun am Ende unserer Diskussion angelangt. In diesem Artikel wurde dem Leser sorgfältig demonstriert, wie man eine Blackbox-Lösung so konfiguriert, dass sie automatisch gute Strategien erkennt. In unserer vorangegangenen Diskussion haben wir versucht, alle möglichen Strategien zu modellieren und dann nur Signale von der Strategie zu nehmen, von der wir annahmen, dass sie am profitabelsten sein würde, was einen Gewinn von 38,58 $ während dieses Backtests ergab. In dieser Diskussion haben wir vorgeschlagen, wie die gegenseitige Information genutzt werden kann, um schnell die beste Strategie für unseren statistischen Schätzer zu identifizieren, um den Gewinn auf $145,24 über den gleichen Backtest-Zeitraum zu verbessern, wobei alle anderen Variablen, wie Positionsgröße und Handelsvolumen, konstant gehalten werden.
Unsere vorgeschlagene Lösung hat heute unsere Sharpe Ratio von ursprünglich 0,13 auf 0,4 verbessert. In diesem Artikel hat der Leser gelernt, wie er seine Blackbox-Lösung mit Hilfe der besprochenen numerischen Techniken sorgfältig konfigurieren kann, und vor allem, wie er die blinden Flecken herkömmlicher „Best Practices“ vermeiden kann, wie z. B. das übermäßige Vertrauen auf den RMSE für die Kreuzvalidierung von Regressionsmodellen und seine Tendenz, mittelmäßiges Verhalten in Modellen zu belohnen.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/20317
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.