
ケンドールのタウ係数と距離相関を用いたVGTの市場ポジショニング分析コード
はじめに
市場で優位性を見つけるプロセスは、決して一直線ではありません。多くの場合、それは暗い部屋で黒猫を探すようなものです。しかもその猫は、こちらの口座残高を消し去ろうと常に企んでいるかのようです。現在、私たちは「ニュース」やメディアのノイズだけでなく、無数のチャートセットアップにも囲まれています。それらは大量のインジケーターで埋め尽くされ、それぞれが、取引の世界を解き明かす最後のピースであるかのように語られています。しかし、冷静に検証してみると、問題は「何を使うかが足りない」ことではありません。本当の課題は、どのツールが実際に有効に機能しており、どのツールが単にCPUサイクルを消費したり、単に心理的な安心感を与えているだけなのかを理解することです。
ノイズを切り分ける方法の一つとして、MetaTraderユーザーがあまり活用していないのが、FXという典型的なサンドボックスの外に出てみることです。このプラットフォームは単なる通貨取引ツールではありません。ブローカーによっては、株式、ETF、コモディティ、指数、その他さまざまな非伝統的資産を取引できます。トレーダーによっては、こうした資産クラスが、市場参加者が過密になっていない領域での機会を生み出すことがあります。その典型例として挙げられるのが、Vanguard Information Technology Index Fund ETF (VGT)のような価格反応が非常に速いETFです。
VGTはメガキャップのテクノロジー企業に非常に高い集中度を持っており、為替ペアとはまったく異なる値動きを見せます。為替ペアは、週末やごく稀な例外を除けば、通常は大きなギャップアップやギャップダウンがなく、連続した価格推移を示します。最近では、今年10月6日にJPYでギャップダウンがありましたが、これは週末を挟み、日本で新しい首相が誕生した直後に起きた出来事でした。FX市場ではこうしたギャップは発生しますが、膨大な流動性のおかげで例外的な現象であることが多いです。一方でVGTの価格チャートを見ると、たとえ日足チャートであっても価格ギャップはむしろ日常的に発生しています。この点は、高い流動性を好むトレーダーにとっては敬遠材料になるかもしれません。しかし同時に、それは自分のエッジを構築する機会にもなります。そしてある意味で、MT5はその実験環境を提供してくれるプラットフォームでもあります。
同じツールセットを使いながら、さまざまな資産クラスで実験できることは大きな利点です。しかしその裏側として、チャートの過度な混雑や、今回の文脈で言えばツールに依存しすぎたエキスパートアドバイザー(EA)は、VGTのような敏感な資産を扱う際にはさらに危険になる可能性があります。冗長なインジケーターや過度に相関したインジケーターは、単に誤解を生むだけではありません。互いに同じ情報を繰り返しているため、まるで声をそろえて間違った主張を叫んでいるような状態になります。その結果、エントリー判断が歪み、本来は独立した根拠であるべき判断が、重複した仮説によって裏付けられているだけという状況になりかねません。取引システム上では3つのインジケーターが一致しているように見えても、同じ体温を測っている体温計が3本並んでいるに過ぎない場合も多いのです。
こうした問題を避けるためには、データドリブンなアプローチでインジケーターを評価し、それぞれがどのような情報価値を提供できるのかを定量的に測定する必要があります。これは本記事、そして今後続く一連の記事の核心的な目的でもあります。資産ごとに同様の分析をおこない、インジケーターの組み合わせを検証していきます。本記事では特に、ケンドールの順位相関係数(タウ係数)と距離相関を用いてインジケーターの独立性を測定します。統計的な分析だけでなく、それぞれのインジケーターが持つシグナルパターンを分解し、最終的に選ばれたインジケーターのペアに対して、最もパフォーマンスの高いパターンの組み合わせを探ります。つまり本記事の目的は、新しいインジケーターを追加したり、派手なツールを紹介することではありません。重要なのは、既存のツールを十分に理解し、実際の取引エッジへとつなげることです。そして同時に、MT5がその検証のための実験場としてどのように活用できるかを示すことでもあります。VGTとは
Vanguard Information Technology ETF(一般的にVGTと略されます)は、テクノロジーセクターに特化した代表的なETFであり、MSCI US Investable Market Information Technology 25/50 Indexのパフォーマンスを追跡することを目的としたファンドです。このETFは、テクノロジー業界を代表する巨大企業を中心に構成された、非常に集中度の高いポートフォリオ。さらに、成長機会を取り込むために一部の中小型株も組み入れられています。保有銘柄を確認すると、主要な構成比率としてMicrosoft、Apple、Google、Amazon、Nvidiaといった、いわゆる「主要銘柄」が並んでいることが分かります。
これらの大型株の集合的な値動きは、ETF全体の軌道を決定づける重力のような役割を果たし、VGTの中心的な役割を果たします。一方でその下には、半導体、ソフトウェア基盤、ITサービス、クラウドインフラといった分野の銘柄も含まれています。これらは規模としては小さいものの、市場センチメントがリスクオンに切り替わる局面ではETFのトレンドを加速させる役割を果たすことがあります。
VGTは、多くの分散型ETFのように複数セクターへテクノロジー銘柄を薄く分散するタイプとは異なり、非常に高い集中度を持っています。このETFは「確信を薄める」のではなく、むしろ確信を一点に集約する構造を採っています。その結果、価格は上昇にも下落にも比較的速く動く傾向があります。言い換えれば、NASDAQ Composite Indexがくしゃみをするたびに、VGTは風邪をひくか、あるいは新しい強力なワクチンを見つけたかのように急騰する、というイメージです。 要するに、VGTにおいてボラティリティは欠陥ではなく、アウトパフォーマンスの可能性と引き換えのコストだと言えるでしょう。ウォーレン・バフェットが述べたように、「分散投資はパフォーマンスの敵である」という考え方にも通じる部分があります。
VGTは2004年に設定されましたが、その成長の軌跡は、ほぼデジタル革命そのものを反映していると言えます。Web 2.0の黎明期から始まり、現在のAI時代の産業的発展段階に至るまで、VGTは主要なテクノロジーのマイルストーンとともに複利的に成長してきました。さらに、非常に低い経費率を持つことも構造的な強みであり、株式市場のリターンの多くがファンドマネージャーではなく投資家側に還元されやすい仕組みになっています。
ただし近年では、VGTを取引することは単純に「強気か弱気か」という問題ではなく、テクノロジーセクター内部で起こるローテーションのタイミングを読むことにある、という見方が強まっています。VGTの値動きは、季節、四半期、さらにはマクロ経済サイクルによっても変化する傾向があります。この点を踏まえると、2026年に向けて何に注目すべきかというテーマは、単に関連性があるだけでなく、むしろ非常に重要な視点になってきます。次のセクションでは、この点について詳しく見ていきます。
VGTの現在の見通し
株式市場における季節性は、単なる思い込みではありません。むしろ、機関投資家の行動パターン、会計年度のサイクル、そして投資家心理といった要因から生まれる市場の周期的な傾向です。特にテクノロジーセクターは、こうした季節的な特徴が比較的はっきりと表れやすい分野の一つです。その意味で、VGTは、特に年末にかけてこのリズムに合わせて動くことが多い銘柄として知られています。
歴史的に見ても、現在私たちがいる第4四半期(Q4)は、VGTにとってパフォーマンスが高まりやすい時期となることが少なくありません。テクノロジー株が広範な市場をアウトパフォームしやすい時期であり、その背景には主に次の3つの要因があります。
- まず第一に、決算発表によるモメンタムが市場センチメントを押し上げるケースが多いことです。
- 第二に、年末に向けてETFのリバランスがおこなわれることがあります。この過程で、運用側はパフォーマンスの低い銘柄を削減し、より好調な銘柄の比率を高める傾向があります。
- そして第三に、ホリデーシーズンの消費です。特にハードウェア、半導体、デジタルサービスといった分野では需要が増えやすく、それが売上予想の上方修正につながることがあります。
こうした動きは、いわゆるサンタクロース・ラリーとも重なります。これは12月最後の5営業日と翌年1月最初の2営業日に株式市場が上昇しやすいとされる現象です。VGTのようなテクノロジー比率の高い銘柄では、この強気の動きが比較的早い段階で現れることがあります。特に、年間パフォーマンスを良く見せたいファンドが追い込みで資金を投入するため、いわば「あぶく銭」のような上昇トレンドに乗ろうとする資金が流入することがあります。しかし近年では、すべての構成銘柄が一様に強気というわけではないという傾向も見られ始めています。
たとえば、一般的に小型株に追い風とされる「1月効果」の影響により、一部の投資家が大型テック株から資金を引き上げ、出遅れセクターへローテーションする動きが見られます。こうした資金移動はVGTに一定の下押し圧力を与える可能性があります。さらに、決算発表後には「消化フェーズ」とも呼べる局面が生じることがあります。これは、過度に伸びたバリュエーションが現実的な水準へ調整される過程です。2024年には、この段階がいわゆる「AIブーム」の過熱感をある程度冷やす結果となりました。そして2025年から2026年に向かう現在、AI投資の過剰支出への懸念が引き続き議論される可能性があります。特に、市場の期待が企業の実際のファンダメンタルズを大きく上回る場合、このテーマは重要性を増すでしょう。
ボラティリティの方向性を考慮しない観点から見ると、VGTは通常、Q4初期には比較的レンジが圧縮され、その後年末に向けてボラティリティが拡大する傾向を示します。このような市場環境は、適応型インジケーターを活用する取引システムにとって適したフィールドとなります。つまり、市場が静かな状態から活発な状態へ移行するタイミングを捉えるタイプのインジケーターです。適切なインジケーターのペアを選ぶために、本記事ではまず5つの候補ペアからスタートします。そして、VGTの直近5年間の価格データに基づいて、それぞれを比較評価し、最も適した組み合わせを特定していきます。まず最初に、これらのインジケーターのペアを紹介します。その後、選ばれたインジケーターについてシグナルパターンの組み合わせを検証していきます。本記事では、以下のフローチャートに示すようなテーマ構成に沿って分析を進めていきます。

使用インジケーター
高モメンタムETF、特にVGTの分析において、重要なのはチャートをインジケーターを過剰に表示することではなく、精度を重視して道具を選ぶことです。ここで求められるのは、互いに干渉せず、むしろ補完し合えるインジケーターのペアです。それぞれの盲点をカバーし合うことができる組み合わせを見つけることが重要です。以下に紹介する5つの候補インジケーターのペアは、それぞれ市場に対して独自の視点を提供します。対象は、ボラティリティ、モメンタム、トレンドの強さ、エネルギー消耗など多岐にわたります。選定プロセスをフローチャートでまとめると以下のようになります。

私たちの目標は、これらのインジケーターのペアがどの程度独立して機能できるかを数値化することです。そしてこの情報をもとに、ペアとして一貫性のある取引ロジックを構築できるかを評価します。ここで登場するのが、記事タイトルや概要でも触れた「ケンドールのタウ係数」と「距離相関」という2つのアルゴリズムです。まずは、それぞれのインジケーター候補を見ていきましょう。
ここで検討する最初のペアは、ADX-Wilderとビル・ウィリアムズMFIです。 ADXは、MetaTraderのウェブサイトで共有されているリンクからも確認できるように、トレンドの方向性ではなくその強さを定量化する指標です。方向性が明確で、現在の市場の動きが力強く、モメンタムが整っている局面で特に効果を発揮します。一方で、MFIは価格と出来高の相互作用に注目し、市場で価格がどれだけ「容易に」動いているかを測定します。この2つを組み合わせることで、1つの物語が描かれます。ADXは価格波の強さを示し、MFIはその波を実現するために市場がどれだけのエネルギーを投入しているかを示します。VGTのボラティリティ急騰局面では、この組み合わせにより、エネルギーが蓄積されている場面と失速している場面を区別することが可能です。
次に検討するインジケーターのペアは、フラクタル適応移動平均(FrAMA, Fractal Adaptive Moving Average)とボリンジャーバンドです。FrAMAは、価格の動きに応じて反応速度を変化させる適応型移動平均であり、ボリンジャーバンドは価格の周囲にボラティリティの包絡線を示します。この2つを組み合わせることで、ボラティリティを補完的に捉える組み合わせが生まれます。FrAMAは内部的にトレンド状況に適応し続け、ボリンジャーバンドは外側のボラティリティ限界を設定します。両者が一致する場合、価格が拡張期から収縮期に移行していることを示唆することが多く、VGTの株式ローテーション期のスイングトレードにおいて非常に有用です。
次の候補ペアは、RSIとビル・ウィリアムズフラクタルです。RSIは、既によく知られている通り、価格の内部モメンタムを追跡します。任意の固定期間に対して価格がどれだけ動いたかを示す指標です。一方、フラクタルは、価格が反転する小さな「ピボットの指紋」や転換ポイントを特定するためのものです。この組み合わせは、反転を狙う取引戦略として機能します。RSIは買われ過ぎや売られ過ぎ状態の蓄積を示し、フラクタルは価格が実際に反転するポイントをマークします。VGTの四半期末の調整や偽ブレイクアウトの回避にも応用可能です。
次に検討するのはATRとウィリアムズ%R(Williams Percent Range)です。ATRはよく知られている通り、ボラティリティの大きさを測定する指標です。ウィリアムズ%は、価格が最近のレンジの中でどの位置にあるかを示す指標で、RSIのより感情的に正直な兄弟のようなものと考えることもできます。これら2つを組み合わせることで、市場のボラティリティの幅と現在の価格位置を同時に把握できます。市場がトレンド中の場合、ウィリアムズ%は極端値付近で平坦化し、ATRは急上昇する傾向があり、次のボラティリティ波の形成を示す早期警告として機能します。
最後に検討するペアは、ゲーター(Gator)オシレーターと標準偏差インジケーターです。ゲーターはアリゲーター(Alligator)インジケーターの派生で、移動平均の収束と発散を示します。本質的には、市場の「歯が噛み合っているか眠っているか」を示すものであり(ビル・ウィリアムズの考え方に基づく)、これを標準偏差と組み合わせることで、価格の分散を統計的に把握できます。ゲーターが目覚めトレンドが形成されているときに標準偏差が圧縮されていれば、「コイルばね」のようにエネルギーが蓄積されている状態と解釈されます。両方が拡張するとボラティリティ相場の確認となり、VGTが最も大きな動きをする局面を示唆します。
これら5つのペアはそれぞれ、VGTの動きを異なる角度から捉えるレンズを提供します。しかし、直感だけで取引に用いるのは十分ではありません。同じ市場挙動を別名の指標で二重カウントしないためには、各インジケーターがどれだけ独立して機能するかを数値化する必要があります。そこで、私たちは2人の「審判」、すなわちケンドールのタウ係数と距離相関を活用します。各アルゴリズムの数学的な詳細に入る前に、まずそれぞれの平易な定義を理解しておくことで、後の論理をスムーズに追えるようにします。
ケンドールのタウ係数のわかりやすい説明
簡単に言えば、これは、2つのデータセットの順位の一致度です。2つのデータセットを比較する際、個々の値がどれだけ近いかを問うのではなく、それらが同じ順序で動いているかどうかを確認します。これをイメージしやすくするために、次のような状況を考えてみましょう。あなたとトレーダー仲間が、同じ期間にVGTを取引した日をそれぞれ評価してランキングしたとします。あなたは価格変動の大きさで順位付けをし、仲間はインジケーターの強さを基準に順位をつけます。もし両者が、どの日が強く、どの日が弱かったかについて同じ順序で評価していた場合、たとえ数値の大きさが異なっていても、そのランキングは一致している(concordant)と言えます。逆に、ランキングが一致しない場合は不一致(discordant)と呼ばれます。
ケンドールのタウ係数アルゴリズムは、こうした比較をデータセット全体に対しておこない、一致と不一致が何回発生するかを数え上げます。その結果は−1.0から+1.0の範囲で表され、−1.0は完全な不一致、+1.0は完全な一致を意味します。値が0の場合は、2つのデータセットの間に関係がなく、完全に独立している状態を示します。
これはVGTに限らず、取引全般において重要な意味を持ちます。というのも、インジケーターはほとんどの場合、線形的には動かないからです。たとえば、RSIが急上昇したとしても、それがADXの動きと比例して拡大するとは限りませんし、ボリンジャーバンドの収縮がFrAMAの傾きと同じ形で反映されるわけでもありません。ケンドールのタウ係数は、こうした差異によって生まれる「ノイズ」を排除し、インジケーター同士の相対的な方向性だけに注目することで比較をおこないます。
別の言い方をすれば、これは、値の大きさではなく順位に基づく相関とも考えられます。つまり、各インジケーターの波の大きさではなく、それらが同じタイミングで起きているかどうかだけを見る測定方法です。もう少し具体的な例で考えてみましょう。VGTのRSIがモメンタムの上昇を示している一方で、フラクタルがまだ反転の兆候を示していないとします。これら2つのインジケーター間のケンドールのタウ係数が低い、あるいは負の値であれば、それは順位の観点で両者が一致していないことを意味します。つまり、一方のインジケーターが価格変動に早く反応しているのに対し、もう一方はより遅れて反応する傾向がある可能性を示唆しているのです。
ケンドールのタウ係数の定義
直感的な意味を説明したところで、ここからはもう少し踏み込んで、その内部の仕組みを見ていきます。2つの変数XとYがあるとします。例えば、これはVGTの価格データセットから得られる2つのインジケーター出力だと考えることができます。このときケンドールのタウ係数は、それらの間に存在する順位ベースの関連性の度合いを定量化します。そのためにおこなわれるのは、すべての観測値の組み合わせを評価し、それぞれを「一致」または「不一致」に分類することです。「一致」は正の関係を示し、「不一致」は負の関係を示します。具体的には、2つの観測ペア(Xᵢ, Yᵢ)と(Xⱼ, Yⱼ)が同じ方向に変化している場合、それらは「一致」とみなされます。
![]()
一方で、互いに逆方向に変化している場合には、それらは「不一致」と分類されます。
![]()
ケンドールのタウ係数は次のように定義されます。
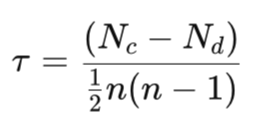
ここで
- Ncは「一致」ペアの数
- Ndは「不一致」ペアの数
- nは観測値の総数
この式において分母は、観測されたすべてのユニークなペアの総数を表します。実際には、タウは2つのインジケーターの順位付けがどれだけ一致しているかを測定しています。値が+1の場合は完全な一致、すなわち単調増加関係を意味します。反対に、最小値である−1は完全な逆相関、つまり単調減少関係を意味します。値が0、あるいはそれに近い場合は、相関関係が存在しないことを示します。
市場分析において、この測定方法は非常に有用です。その理由の一つは、追加のパラメータを必要としない点にあります。また、データが正規分布に従うことを前提としないうえ、線形関係である必要もありません。こうした特性により、外れ値や非線形スケーリングの影響を受けにくいという利点があります。これらは、特にETFのようなノイズの多い金融商品でインジケーター由来のデータを扱う際には、非常によく見られる特徴です。そのため、ADX–MFI、ATR–ウィリアムズ%Rなど、今回検討している各インジケーターのペアに対して、タウは両方のインジケーターが価格変動を同じ順位構造で捉える傾向があるかどうかを判断する役割を果たします。
今回の目的においては、タウの値が0に近いほど好ましいと考えます。なぜなら、相関がまったく存在しない、あるいは非常に弱いことは、そのペアが互いに補完的である可能性が高いことを示唆するからです。反対に、タウが高い値、あるいは強い負の値を示す場合、それはVGTの価格データから得られる2つのインジケーターが強い相関を持っていることを意味します。これはつまり、異なる名前のインジケーターでありながら、実際には同じ市場情報を重複して捉えている可能性を示しています。このようにして、ケンドールのタウ係数は私たちの最初のフィルタ、すなわち最初の「審判」として機能し、インジケーター間に存在する重複したロジックを取り除く役割を果たします。次に用いる2つ目のフィルタは距離相関です。ケンドールのタウ係数と同様に、まずはその概念を平易な言葉で説明するところから始めていきます。
距離相関の理解
ケンドールのタウ係数がランキングの比較だとすれば、距離相関はデータ構造の比較だと考えることができます。つまり、単に「これらのインジケーターの投影が同じ方向を向いているか」を問うだけではなく、それらがどのようなリズムやパターンで一致または不一致になっているのかまで定量化しようとします。両アルゴリズムは基本的に似た目的、つまりデータセット間の関係性を測定することを目指しています。しかし、距離相関はそこに少しニュアンスのある追加情報を捉えることができます。これを理解するために、次のような例を考えてみましょう。2人のトレーダーがVGTの価格動向を追跡しているとします。それぞれが異なるインジケーターを使っている状況です。たとえば、1人目のトレーダーはADXを見ており、トレンドの強さに注目しています。一方で2人目のトレーダーはボリンジャーバンドを使って、ボラティリティの収縮に反応しているとします。仮に、価格動向と組み合わせたシグナルの連続の中で、両方のインジケーターが結果的に買いシグナルを出していたとしましょう。しかし、この一致は必ずしも同じタイミングや同じ強さで起きるとは限りません。多くの場合、一致の度合いはさまざまであり、必ずしも線形的ではないのです。ところが、ピアソン相関やケンドールのタウ係数のような従来の相関アルゴリズムでは、このような関係の「非線形な関係」は見逃されてしまうことがあります。
これに対して距離相関は、比較されるインジケーター値の中に含まれる追加的な構造情報をより細かく追跡します。このアルゴリズムは、2つのインジケーターが線形なのか、二次的な関係なのか、あるいはカオス的な動きなのかといった形状そのものを評価するのではありません。むしろ、自己相関的な視点を取り入れることで、一方の変数の値が変化したとき、それがどの程度もう一方の変数の変化に対応しているかを数値化しようとします。言い換えると、このアルゴリズムが注目しているのは、生の値や順位ではなく「変動パターン」そのものなのです。
距離相関の定義
形式的に言えば、距離相関は単調関係、線形関係、二次関係、その他あらゆる形の統計的依存関係を捉えることができます。VGTのインジケーター値からなる2つのベクトルが与えられたとすると、距離共分散は、それぞれのベクトル内にあるすべての観測値のペアワイズ距離に基づいて定義されます。言い換えれば、一方のデータベクトルの幾何構造が、もう一方のデータベクトルの幾何構造とどのような関係にあるかを追跡していることになります。この計算は4つのステップで構成されます。まず最初のステップでは、ペアワイズ距離を求めます。n個の観測値からなるデータセット((X₁,Y₁),(X₂,Y₂),…,(Xₙ,Yₙ))がある場合、Xの値同士のすべてのユークリッド距離は次のように求められます。
![]()
同様に、Yの値同士の距離は次のように求められます。
![]()
次のステップでは、二重中心化をおこない、距離行列を計算します。これは、各行と各列の平均を差し引き、その後に全体平均を加えることで求められます。ここで得られる距離は、絶対的な距離というよりも相対的な距離として扱われます。

このステップは、測定値が平均値のスケール差によって歪められないようにするためにも重要です。 距離の合計を求めた後の第三のステップでは、2つのデータセット間の共分散と、それぞれのデータセットの分散を計算します。

そして第四の最終ステップでは、これまでに得られたデータセット間の共分散と各データセットの分散を用いて、距離相関を次のように計算します。

値の範囲は0から1で、1は完全な依存関係を示し、0は統計的独立を表します。
これは非常に重要な点です。というのも、ケンドールのタウ係数が順位関係の分析に特化しているのに対し、距離相関は2つのデータセットが構造的にどれだけ結び付いているかを判断するためです。この特性により、データセットが線形関係であろうと二次関係であろうと、関係性を検出することができます。VGTのインジケーターのペアを選ぶ際には、モメンタム系インジケーター、ボラティリティバンド、フラクタル系指標などが一見して分かりにくい形で互いに関連していることが多いものです。そのため、単純な視覚的判断だけで選定をおこなうと、隠れた依存関係に気付かずに誤った結論に至る可能性があります。したがって、ケンドールのタウ係数が順位依存をフィルタリングする役割を果たす一方で、距離相関はさらに深く踏み込み、構造的な依存関係を明らかにしようとします。
両方のアルゴリズムが、インジケーター出力の間に相関がないと判断した場合、そのペアは取引システムにおいて独立した、あるいは補完的なシグナルロジックを表していると信頼することができます。これでアルゴリズムのロジックを定義できたので、次はこれをどのように実装するかを見ていきます。効率的に実行する環境として、本記事ではPythonを使用します。
相補性のスコアリング
これを実現するために、まずMetaTrader 5のPythonモジュールから価格データを入力として受け取るPythonパイプラインを構築します。最初にMetaTrader 5のアカウントへログインし、VGTのETF価格データを取得します。その後、履歴データを読み込むテストウィンドウとして過去5年間を指定します。時間足は日足を使用しています。各インジケーターには、設定に応じて最大10種類のシグナルパターンがあり、実際の運用では一度に1つずつ使用します。そのため、補完性をスコアリングする最初のステップは、各インジケーターから代表的な特徴量を1つ選択し、それらを整列させたうえでケンドールのタウ係数と距離相関を計算することです。ただし、ここではタウ係数と距離相関の値そのものではなく、それぞれを1から引いた値を使用します。これは、これらの値が今回の目的である「独立性」と逆方向の関係にあるためです。これらのアルゴリズムの実装は、Pythonでは次のように記述されます。
def fast_pair_summary(modA, prA, dfA, modB, prB, dfB, col_idx=0): featsA = _feature_matrix(modA, prA, dfA, col_idx) featsB = _feature_matrix(modB, prB, dfB, col_idx) tau_vals, dcor_vals = [], [] for x in featsA: if x is None: continue for y in featsB: if y is None: continue xa, ya = _align_last_equal(np.asarray(x), np.asarray(y)) if len(xa) < 5: continue tau, _ = kendalltau(xa, ya) if tau is None or np.isnan(tau): continue tau_vals.append(abs(tau)) dcor_vals.append(_distance_correlation(xa, ya)) if not tau_vals or not dcor_vals: return np.nan mean_abs_tau = np.mean(tau_vals) mean_dcor = np.mean(dcor_vals) independence = 1.0 - 0.5 * (mean_abs_tau + mean_dcor) return independence
def _distance_correlation(x, y): """Raw distance correlation (0..1). Works with 1D arrays of same length.""" # ensure 1D float arrays x = np.asarray(x, dtype=float).reshape(-1, 1) y = np.asarray(y, dtype=float).reshape(-1, 1) # pairwise Euclidean distances a = np.sqrt((x - x.T) ** 2) b = np.sqrt((y - y.T) ** 2) # double-center each distance matrix A = a - a.mean(axis=0)[None, :] - a.mean(axis=1)[:, None] + a.mean() B = b - b.mean(axis=0)[None, :] - b.mean(axis=1)[:, None] + b.mean() # distance covariance/variances dcov = np.sqrt(np.mean(A * B)) dvar_x = np.sqrt(np.mean(A * A)) dvar_y = np.sqrt(np.mean(B * B)) denom = np.sqrt(dvar_x * dvar_y) + 1e-12 return float(dcov / denom)
計算が完了すると、これら2つの値を組み合わせて単一の独立性スコアに統合します。各インジケーターには10種類のシグナルパターンが存在するため、補完性を評価する際にはその中から1つを選択する必要があります。ただし、インジケーターのシグナルパターンを恣意的に選択することはおこないません。そのため、一見すると手間のかかる作業ではありますが、必要な手順として10 × 10のパターングリッドを用いたスコアリングを実施します。この方法では、2つのインジケーターの各パターンのすべての組み合わせを評価します。グリッド内の各セル、つまりパターン同士の交差点ごとにケンドールのタウ係数と距離相関を計算し、すべての組み合わせにおいてどこに本当のシナジーが存在するのかを網羅的に確認します。このペアリング構造は、クロス集計表の三角行列として表現することもできます。
各インジケーターのペアについて、ケンドールのタウ係数と距離相関の重み付き値を基にした10 × 10のクロス集計表を作成します。そして、このテーブルの中で「1 −(重み付き値)」という反転処理をおこなった後、最も高い値をそのインジケーターのペアの代表値として採用します。こうして得られる指標を、各インジケーターのペアの「独立性スコア」と呼びます。今回検証した5つのインジケーターのペアについて、算出されたスコアは次の通りです。
| インジケーター1 | インジケーター2 | 独立性スコア |
|---|---|---|
| ADXワイルダー | ビル・ウィリアムズMFI | 0.968 |
| ゲーターオシレーター | 標準偏差 | 0.961 |
| FrAMA | ボリンジャーバンド | 0.939 |
| RSI | ビル・ウィリアムズフラクタル | 0.918 |
| ATR | ウィリアムズR | 0.902 |
シグナルパターンのペアリング
これまでの分析により、ADXとビル・ウィリアムズMFIが、互いに独立性を保ちながらもシナジーを生み出すインジケーターのペアとして適していることが確認されました。そこで次のステップとして、両インジケーターが持つシグナルパターンに焦点を当てて分析を続けます。両インジケーターにはそれぞれ10種類のシグナルパターンがあり、実際に利用する際には一度に1つのパターン同士を組み合わせて使用する必要があります。つまり、ADXの1つのパターンをMFIの1つのパターンと組み合わせることになります。各インジケーターに10種類のパターンがあるため、問題はどのシグナルパターン同士を組み合わせれば最も良いパフォーマンスが得られるのかという点になります。ADXとMFIの各パターンを適切に組み合わせるための手法は、以下のフローチャートで示すような流れになります。

この問いに答えるために、まずインジケーターが生成する価格予測を取得し、それを実際の価格変動と比較することで、F1スコアと呼ばれる評価指標を算出します。Pythonは、特にニューラルネットワークを学習させた後の評価プロセスにおいて、こうしたスコアやレポートを生成することに長けています。ただし今回のケースではモデルの学習はおこなわず、インジケーターのデフォルトまたは生の入力パラメータから得られる予測値を直接利用しています。そのため、このプロセスは学習ではなく、一種の検証またはテストランとして機能します。
ここでも私たちが関心を持つのは、インジケーターをペアにしたときの予測性能です。そのため、各パターンの組み合わせごとのF1スコアをクロステーブル形式で集計し、その平均値と不確実性を基にUCB (Upper Confidence Bound)ベイズアルゴリズムを適用します。そして、パフォーマンスが最も良い領域を継続的にサンプリングしていきます。各インジケーターには、方向性相場またはボラティリティ相場のいずれかに対応する10種類のシグナルパターンが存在します。このベイズ最適化手法では、100通りのすべての組み合わせを、多腕バンディットモデルの「腕」として扱います。クロス集計表に集計されたF1スコアは、このモデルにおける報酬指標として機能し、単なる予測精度だけでなく、VGTのサンプル期間全体における取引結果の一貫性も評価対象となります。Pythonでの実装は次のとおりです。
# ------------------------------------------------------------- # Dirichlet posterior score sampling per pair (for Bayesian UCB) # ------------------------------------------------------------- def _sample_score_from_dirichlet(C, weights, rng, alpha_prior=1.0, K=200): wa, wbull, wbear = weights C = C.astype(float) tot = int(C.sum()) if tot == 0: return np.zeros(K, dtype=float) draws = np.empty(K, dtype=float) alpha = alpha_prior + C.ravel() for k in range(K): p = rng.dirichlet(alpha) # probs over 9 cells # expected counts under p (or sample multinomial for more noise) # Here we treat p as a table, compute score metrics from p directly: P = p.reshape(3,3) acc = np.trace(P) pred_bull = P[:,2].sum(); bullP = (P[2,2]/pred_bull) if pred_bull>0 else 0.0 pred_bear = P[:,0].sum(); bearP = (P[0,0]/pred_bear) if pred_bear>0 else 0.0 draws[k] = wa*acc + wbull*bullP + wbear*bearP return draws
# ============================================================= # 5) Bayesian UCB assignment: S_ucb = mu + β*std from posterior draws # ============================================================= def select_pairs_bayesian_ucb(counts, weights=(0.2,0.4,0.4), K=300, beta=1.0, alpha_prior=1.0, rng=None): if rng is None: rng = np.random.default_rng() S_mu = np.zeros((10,10), dtype=float) S_sd = np.zeros((10,10), dtype=float) for i in range(10): for j in range(10): samp = _sample_score_from_dirichlet(counts[i,j], weights, rng, alpha_prior, K) S_mu[i,j] = samp.mean() S_sd[i,j] = samp.std(ddof=1) S_ucb = S_mu + beta * S_sd r, c = linear_sum_assignment(-S_ucb) pairs = [(int(i+1), int(j+1)) for i, j in zip(r, c)] return pairs, S_mu, S_sd, S_ucb
このプロセスにより、ADXとMFIの間で以下の10組のシグナルパターンのペアが導き出されます。
| 順位 | ADXパターン | MFIパターン | 平均F1スコア | UCBスコア |
|---|---|---|---|---|
| 1 | A3 | M5 | 0.86 | 0.88 |
| 2 | A9 | M8 | 0.81 | 0.85 |
| 3 | A6 | M7 | 0.76 | 0.84 |
| 4 | A7 | M6 | 0.80 | 0.83 |
| 5 | A2 | M9 | 0.74 | 0.81 |
| 6 | A4 | M10 | 0.73 | 0.80 |
| 7 | A8 | M1 | 0.72 | 0.79 |
| 8 | A5 | M3 | 0.70 | 0.78 |
| 9 | A1 | M2 | 0.71 | 0.77 |
| 10 | A10 | M4 | 0.73 | 0.76 |
Pythonでのシグナルパターンコードは次のとおりです。
# 1. ADX rises above 25 while +DI crosses above −DI -> bullish ignition. def feature_adx_1(df): adx = _col(df, 'ADX', 'adx', 'Adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') feature = np.zeros((len(df), 2), dtype=int) # bullish: ADX rises above 25 and +DI crosses above -DI (cross up on current bar) cond_bull = (adx > 25) & (pdi.shift(1) <= mdi.shift(1)) & (pdi > mdi) # bearish: ADX rises above 25 and -DI crosses above +DI cond_bear = (adx > 25) & (mdi.shift(1) <= pdi.shift(1)) & (mdi > pdi) # print(' adx > 25 ',adx > 25) # print(' pdi.shift(1) <= mdi.shift(1) ',pdi.shift(1) <= mdi.shift(1)) # print(' pdi > mdi ',pdi > mdi) # print(' cond_bull ',cond_bull) # print(' cond_bear ',cond_bear) feature[:, 0] = cond_bull.astype(int) feature[:, 1] = cond_bear.astype(int) feature[:2, :] = 0 return feature # 2. ADX making higher highs while price makes higher highs -> confirmed bullish momentum. def feature_adx_2(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close', 'PRICE', 'price', 'ClosePrice') feature = np.zeros((len(df), 2), dtype=int) # ADX higher highs over last 2 bars and price higher highs adx_hh = (adx > adx.shift(1)) & (adx.shift(1) > adx.shift(2)) price_hh = (close > close.shift(1)) & (close.shift(1) > close.shift(2)) feature[:, 0] = (adx_hh & price_hh).astype(int) # ADX higher highs but price makes lower highs -> bearish divergence (topping) price_lh = (close < close.shift(1)) & (close.shift(1) < close.shift(2)) feature[:, 1] = (adx_hh & price_lh).astype(int) feature[:3, :] = 0 return feature # 3. ADX climbing from below 20 to above 30 during sideways range -> breakout confirm. def feature_adx_3(df): adx = _col(df, 'ADX', 'adx') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # define sideways range: low volatility measured by small ATR proxy (high-low small) range_width = (high - low).rolling(10, min_periods=1).mean() sideways = range_width < (range_width.rolling(50, min_periods=1).median()) # crude # ADX climbs from below 20 to above 30 within recent window climbed = (adx > 30) & (adx.shift(5) < 20) # bullish breakout: close breaks above recent 10-bar high while climbed & sideways breakout_up = climbed & sideways & (close > close.rolling(10).max().shift(1)) breakout_down = climbed & sideways & (close < close.rolling(10).min().shift(1)) feature[:, 0] = breakout_up.astype(int) feature[:, 1] = breakout_down.astype(int) feature[:10, :] = 0 return feature # 4. +DI forms W while ADX rises -> momentum recovery; inverse for -DI M pattern. def feature_adx_4(df): adx = _col(df, 'ADX', 'adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') feature = np.zeros((len(df), 2), dtype=int) # detect simple W pattern on +DI: low in middle between two higher peaks w_plus = (pdi.shift(2) > pdi.shift(1)) & (pdi.shift(1) < pdi) & (pdi.shift(2) > pdi) m_minus = (mdi.shift(2) < mdi.shift(1)) & (mdi.shift(1) > mdi) & (mdi.shift(2) < mdi) # M-like top on -DI adx_rising = (adx > adx.shift(1)) & (adx.shift(1) > adx.shift(2)) feature[:, 0] = (w_plus & adx_rising).astype(int) feature[:, 1] = (m_minus & adx_rising).astype(int) feature[:3, :] = 0 return feature # 5. ADX falls after a long uptrend while price stalls -> trend exhaustion. def feature_adx_5(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # "long uptrend" measured as close rising for a while (10 bars) uptrend = (close > close.shift(1)) & (close.shift(1) > close.shift(2)) uptrend_long = close > close.shift(10) # price higher than 10 bars ago -> crude uptrend # ADX falling: current ADX below its 5-bar SMA and lower than previous adx_falling = (adx < adx.rolling(5, min_periods=1).mean()) & (adx < adx.shift(1)) # bull exhaustion: long uptrend + adx_falling + price stalls (small change) price_stall = (abs(close - close.shift(1)) / close.shift(1)) < 0.0025 # <0.25% change -> stall feature[:, 0] = (uptrend_long & adx_falling & price_stall).astype(int) # bear exhaustion: symmetric for downtrend downtrend_long = close < close.shift(10) feature[:, 1] = (downtrend_long & adx_falling & price_stall).astype(int) feature[:11, :] = 0 return feature # 6. ADX slope rising with widening +DI–−DI gap -> momentum expansion long def feature_adx_6(df): adx = _col(df, 'ADX', 'adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') feature = np.zeros((len(df), 2), dtype=int) adx_slope = adx - adx.shift(3) # 3-bar slope proxy gap = pdi - mdi gap_change = gap - gap.shift(3) # long expansion: ADX slope positive and gap widening in favor of +DI cond_long = (adx_slope > 0) & (gap_change > 0) & (gap > 0) # short expansion: ADX slope positive and gap widening in favor of -DI cond_short = (adx_slope > 0) & (gap_change < 0) & (gap < 0) feature[:, 0] = cond_long.astype(int) feature[:, 1] = cond_short.astype(int) feature[:4, :] = 0 return feature # 7. ADX divergence: price higher high, ADX lower high -> hidden weakness def feature_adx_7(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # Price higher high over last 2 bars but ADX lower high price_higher_high = (close > close.shift(1)) & (close.shift(1) > close.shift(2)) adx_lower_high = (adx < adx.shift(1)) & (adx.shift(1) < adx.shift(2)) feature[:, 0] = (price_higher_high & adx_lower_high).astype(int) # Price lower low but ADX higher low -> weak bearish continuation price_lower_low = (close < close.shift(1)) & (close.shift(1) < close.shift(2)) adx_higher_low = (adx > adx.shift(1)) & (adx.shift(1) > adx.shift(2)) feature[:, 1] = (price_lower_low & adx_higher_low).astype(int) feature[:3, :] = 0 return feature # 8. ADX makes W base while price forms W -> bullish reversal; M top -> bearish reversal. def feature_adx_8(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # W base detection (ADX): low in middle between two higher values adx_w = (adx.shift(2) > adx.shift(1)) & (adx.shift(1) < adx) & (adx.shift(2) > adx) price_w = (close.shift(2) > close.shift(1)) & (close.shift(1) < close) & (close.shift(2) > close) feature[:, 0] = (adx_w & price_w).astype(int) # M top detection: mirror of W (two peaks with lower middle) adx_m = (adx.shift(2) < adx.shift(1)) & (adx.shift(1) > adx) & (adx.shift(2) < adx) price_m = (close.shift(2) < close.shift(1)) & (close.shift(1) > close) & (close.shift(2) < close) feature[:, 1] = (adx_m & price_m).astype(int) feature[:3, :] = 0 return feature # 9. ADX slope flattening near 20 with price consolidating -> breakout signals (top/bottom). def feature_adx_9(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) # flattening near 20: ADX within +/-2 of 20 and small recent slope near_20 = (adx.between(18, 22)) flat_slope = (abs(adx - adx.shift(5)) < 2) # consolidation: price within narrow band of recent 10 bars band = high.rolling(10, min_periods=1).max() - low.rolling(10, min_periods=1).min() narrow = band < (band.rolling(50, min_periods=1).median()) # breakout up: price breaks above previous 10-bar high breakout_up = near_20 & flat_slope & narrow & (close > close.rolling(10).max().shift(1)) # breakout down: price breaks below previous 10-bar low breakout_down = near_20 & flat_slope & narrow & (close < close.rolling(10).min().shift(1)) feature[:, 0] = breakout_up.astype(int) feature[:, 1] = breakout_down.astype(int) feature[:11, :] = 0 return feature # 10. ADX falls sharply while DI lines stay wide -> temporary pullback in trend. def feature_adx_10(df): adx = _col(df, 'ADX', 'adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # ADX falls sharply: current ADX much lower than 5-bar ago adx_drop = (adx < adx.shift(5) * 0.8) # >20% drop over 5 bars # DI lines stay wide: absolute gap still large (> threshold) gap = abs(pdi - mdi) wide_gap = gap > gap.rolling(20, min_periods=1).mean() # gap wider than its 20-bar mean # bullish context (initial trend was bullish): +DI > -DI bull_context = pdi > mdi bear_context = mdi > pdi # bullish temporary pullback: adx_drop & wide_gap & bull_context -> buy on continuation after pullback feature[:, 0] = (adx_drop & wide_gap & bull_context).astype(int) feature[:, 1] = (adx_drop & wide_gap & bear_context).astype(int) feature[:6, :] = 0 return feature
# 1. MFI and volume both rise -> genuine buying strength. Mirror: MFI+volume rise while price fails -> topping clue. def feature_mfi_1(df): mfi = _col(df, 'MFI_BW', 'MFI', 'mfi', 'MarketFacilitationIndex') try: vol = _col(df, 'Volume', 'tick_volume', 'VOL') except KeyError: vol = pd.Series(0, index=df.index) close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) mfi_up = (mfi > mfi.shift(1)) vol_up = (vol > vol.shift(1)) price_fail = (close <= close.shift(1)) # price not confirming feature[:, 0] = (mfi_up & vol_up & (close > close.shift(1))).astype(int) feature[:, 1] = (mfi_up & vol_up & price_fail).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 2. MFI spikes with green bar after compression -> momentum expansion up. Mirror downward. def feature_mfi_2(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) # compression = low volatility (small range) vs longer history range10 = (high - low).rolling(10, min_periods=1).mean() med_range = range10.rolling(100, min_periods=1).median().replace(0, np.nan) compressed = range10 < (0.6 * med_range) # spike = large jump in MFI relative to recent mfi_spike = (mfi > mfi.rolling(5, min_periods=1).mean() + 1.5 * mfi.rolling(5, min_periods=1).std()) green_bar = close > close.shift(1) brown_bar = close < close.shift(1) feature[:, 0] = (compressed.shift(1) & mfi_spike & green_bar).astype(int) feature[:, 1] = (compressed.shift(1) & mfi_spike & brown_bar).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 3. MFI increases while price stabilizes -> silent accumulation. Mirror: MFI decreases while price stabilizes -> silent distribution. def feature_mfi_3(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) mfi_up = (mfi > mfi.shift(1)) mfi_down = (mfi < mfi.shift(1)) # price stabilizes = small average absolute returns over short window price_change = (abs(close - close.shift(1)) / close.shift(1).replace(0, np.nan)).rolling(5, min_periods=1).mean() stable = price_change < 0.0025 # ~0.25% avg move feature[:, 0] = (mfi_up & stable).astype(int) feature[:, 1] = (mfi_down & stable).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 4. MFI higher low while price retests support -> hidden bullish divergence. Mirror bearish. def feature_mfi_4(df): mfi = _col(df, 'MFI', 'mfi') low = _col(df, 'Low', 'low') high = _col(df, 'High', 'high') feature = np.zeros((len(df), 2), dtype=int) price_retest_support = (low < low.shift(1)) & (low.shift(1) <= low.shift(2)) # recent retest/probe mfi_hl = (mfi > mfi.shift(1)) & (mfi.shift(1) > mfi.shift(2)) price_retest_resist = (high > high.shift(1)) & (high.shift(1) >= high.shift(2)) mfi_lh = (mfi < mfi.shift(1)) & (mfi.shift(1) < mfi.shift(2)) feature[:, 0] = (price_retest_support & mfi_hl).astype(int) feature[:, 1] = (price_retest_resist & mfi_lh).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 5. W-shaped MFI under price base -> reversal setup. M-shaped above price top -> topping structure. def feature_mfi_5(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # W detection on MFI (4-bar pattern): dip between two higher pivots w_mfi = (mfi.shift(3) < mfi.shift(2)) & (mfi.shift(2) < mfi.shift(1)) & (mfi.shift(1) < mfi) # require that MFI values are under price base (close relatively flat or above) price_base = close > close.rolling(10, min_periods=1).mean() # M detection on MFI: peak between two lower pivots m_mfi = (mfi.shift(3) > mfi.shift(2)) & (mfi.shift(2) > mfi.shift(1)) & (mfi.shift(1) > mfi) feature[:, 0] = (w_mfi & price_base).astype(int) feature[:, 1] = (m_mfi & (~price_base)).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 6. MFI and volume decouple -> stealth accumulation/distribution. def feature_mfi_6(df): mfi = _col(df, 'MFI', 'mfi') try: vol = _col(df, 'Volume', 'volume', 'VOL') except KeyError: vol = pd.Series(np.nan, index=df.index) close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) mfi_up = (mfi > mfi.shift(1)) mfi_down = (mfi < mfi.shift(1)) vol_down = (vol < vol.shift(1)) vol_up = (vol > vol.shift(1)) # stealth accumulation: MFI up while volume down feature[:, 0] = (mfi_up & vol_down).astype(int) # distribution bias: MFI down while volume up feature[:, 1] = (mfi_down & vol_up).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 7. MFI bar color shift from brown to green -> fresh burst. Mirror green->brown -> exhaustion. def feature_mfi_7(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # Interpret "green" as close > prev close and mfi rising; "brown" as falling mfi_rise = (mfi > mfi.shift(1)) mfi_fall = (mfi < mfi.shift(1)) green_bar = (close > close.shift(1)) & mfi_rise brown_bar = (close < close.shift(1)) & mfi_fall feature[:, 0] = (brown_bar.shift(1) & green_bar).astype(int) feature[:, 1] = (green_bar.shift(1) & brown_bar).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 8. MFI bottoms and climbs while volatility increases -> uptrend resumption. Mirror peak & decline -> downtrend resumption. def feature_mfi_8(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) # volatility proxy atr_like = (high - low).rolling(14, min_periods=1).mean() vol_up = atr_like > atr_like.shift(3) # bottom and climb: mfi rises from local trough mfi_bottom = (mfi.shift(2) > mfi.shift(1)) & (mfi.shift(1) < mfi) # trough at shift(1) mfi_peak = (mfi.shift(2) < mfi.shift(1)) & (mfi.shift(1) > mfi) feature[:, 0] = (mfi_bottom.shift(1) & (mfi > mfi.shift(1)) & vol_up).astype(int) feature[:, 1] = (mfi_peak.shift(1) & (mfi < mfi.shift(1)) & vol_up).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 9. MFI breaks above prior swing -> energy expansion. Mirror break below -> collapse. def feature_mfi_9(df): mfi = _col(df, 'MFI', 'mfi') feature = np.zeros((len(df), 2), dtype=int) # prior swing high/low of MFI (10-bar) prior_high = mfi.rolling(10, min_periods=1).max().shift(1) prior_low = mfi.rolling(10, min_periods=1).min().shift(1) break_up = (mfi > prior_high) break_down = (mfi < prior_low) feature[:, 0] = break_up.astype(int) feature[:, 1] = break_down.astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 10. Rising MFI slope with narrowing candle bodies -> hidden demand absorption. Mirror supply absorption. def feature_mfi_10(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) mfi_slope = mfi - mfi.shift(3) rising_slope = mfi_slope > mfi_slope.shift(1) falling_slope = mfi_slope < mfi_slope.shift(1) # narrowing candle bodies = average body size shrinking body = (abs(close - close.shift(1))).rolling(7, min_periods=1).mean() body_shrink = body < body.shift(3) feature[:, 0] = (rising_slope & body_shrink).astype(int) feature[:, 1] = (falling_slope & body_shrink).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature
これらを上記の推奨ペアリング形式でMQL5で次のように実装します。
//+------------------------------------------------------------------+ //| Check for Pattern 0. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_0(ENUM_POSITION_TYPE T) { int _i_max = -1, _i_min = -1; if(T == POSITION_TYPE_BUY) { return(Hi(X()) - Lo(X()) > High(X()) - Low(X()) && ADX(X()) > 30 && ADX(X() + 5) < 20 && Close(X()) > m_close.MaxValue(X(), m_past, _i_max) && MFI(X() + 1) < MFI(X()) && MFI(X() + 2) < MFI(X() + 1) && MFI(X() + 3) < MFI(X() + 2) && Close(X()) > Cl(X())); } else if(T == POSITION_TYPE_SELL) { return(Hi(X()) - Lo(X()) > High(X()) - Low(X()) && ADX(X()) > 30 && ADX(X() + 5) < 20 && Close(X()) < m_close.MinValue(X(), m_past, _i_min) && MFI(X() + 1) > MFI(X()) && MFI(X() + 2) > MFI(X() + 1) && MFI(X() + 3) > MFI(X() + 2) && Close(X()) < Cl(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 1. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_1(ENUM_POSITION_TYPE T) { int _i_max = -1, _i_min = -1; m_close.Refresh(-1); vector _mf; m_mfi.Refresh(-1); _mf.CopyIndicatorBuffer(m_mfi.Handle(), 0, 0, m_past); if(T == POSITION_TYPE_BUY) { return(ADX(X()) >= 18.0 && ADX(X()) <= 22.0 && fabs(ADX(X()) - ADX(X() + 5)) < 2.0 && Hi(X()) - Lo(X()) < High(X()) - Low(X()) && Close(X()) > m_close.MaxValue(X(), m_past, _i_max) && Hi(X()) - Lo(X()) < Hi(X() + m_past) - Lo(X() + m_past) && MFI(X() + 1) < MFI(X()) && LocalMin(_mf, X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) >= 18.0 && ADX(X()) <= 22.0 && fabs(ADX(X()) - ADX(X() + 5)) < 2.0 && Hi(X()) - Lo(X()) < High(X()) - Low(X()) && Close(X()) < m_close.MinValue(X(), m_past, _i_min) && Hi(X()) - Lo(X()) < Hi(X() + m_past) - Lo(X() + m_past) && MFI(X() + 1) > MFI(X()) && LocalMax(_mf, X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 2. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_2(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) - ADX(X() + m_past) > 0.0 && ADXPlus(X()) - ADXMinus(X()) > 0.0 && ADXPlus(X()) - ADXMinus(X()) > ADXPlus(X() + m_past) - ADXMinus(X() + m_past) && Close(X()) > Close(X() + 1) && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) - ADX(X() + m_past) > 0.0 && ADXPlus(X()) - ADXMinus(X()) < 0.0 && ADXPlus(X()) - ADXMinus(X()) < ADXPlus(X() + m_past) - ADXMinus(X() + m_past) && Close(X()) < Close(X() + 1) && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 3. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_3(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(Close(X()) > Close(X() + 1) && Close(X() + 1) > Close(X() + 2) && ADX(X()) < ADX(X() + 1) && ADX(X() + 1) < ADX(X() + 2) && Volumes(X() + 1) > Volumes(X()) && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(Close(X()) < Close(X() + 1) && Close(X() + 1) < Close(X() + 2) && ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Volumes(X() + 1) < Volumes(X()) && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 4. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_4(ENUM_POSITION_TYPE T) { vector _mf; m_mfi.Refresh(-1); _mf.CopyIndicatorBuffer(m_mfi.Handle(), 0, 0, m_past); if(T == POSITION_TYPE_BUY) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) > Close(X() + 1) && Close(X() + 1) > Close(X() + 2) && MFI(X()) > LocalMax(_mf, X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) < Close(X() + 1) && Close(X() + 1) < Close(X() + 2) && MFI(X()) < LocalMin(_mf, X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 5. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_5(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && ADXPlus(X() + 2) > ADXPlus(X() + 1) && ADXPlus(X() + 1) < ADXPlus(X()) && ADXPlus(X() + 2) > ADXPlus(X()) && Volumes(X() + 1) > Volumes(X()) && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && ADXMinus(X() + 2) < ADXMinus(X() + 1) && ADXMinus(X() + 1) > ADXMinus(X()) && ADXMinus(X() + 2) < ADXMinus(X()) && Volumes(X() + 1) < Volumes(X()) && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 6. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_6(ENUM_POSITION_TYPE T) { vector _ad, _cl; m_adx.Refresh(-1); m_close.Refresh(-1); _ad.CopyIndicatorBuffer(m_adx.Handle(), 0, 0, fmax(5,m_past)); _cl.CopyRates(m_symbol.Name(), m_period, 8, 0, fmax(5, m_past)); if(T == POSITION_TYPE_BUY) { return(IsW(_ad) && IsW(_cl) && MFI(X()) > MFI(X() + 1) && Volumes(X()) > Volumes(X() + 1) && Close(X()) < Close(X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(IsM(_ad) && IsM(_cl) && MFI(X()) > MFI(X() + 1) && Volumes(X()) > Volumes(X() + 1) && Close(X()) > Close(X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 7. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_7(ENUM_POSITION_TYPE T) { int _i_max = -1, _i_min = -1; m_close.Refresh(-1); m_adx.Refresh(-1); if(T == POSITION_TYPE_BUY) { return(Close(X()) >= m_close.MaxValue(X(), m_past, _i_max) && ADX(X()) <= m_adx.MinValue(0, X(), m_past, _i_min) && fabs(Close(X()) - Close(X() + 1))/fmax(m_symbol.Point(),Close(X() + 1)) <= 0.0025 && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(Close(X()) <= m_close.MinValue(X(), m_past, _i_max) && ADX(X()) <= m_adx.MinValue(0, X(), m_past, _i_min) && fabs(Close(X()) - Close(X() + 1))/fmax(m_symbol.Point(),Close(X() + 1)) <= 0.0025 && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 8. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_8(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) > 25.0 && ADXMinus(X() + 1) >= ADXPlus(X() + 1) && ADXMinus(X()) < ADXPlus(X() + m_past) && Hi(X()) - Lo(X()) < 0.6*(Hi(X() + m_past) - Lo(X() + m_past)) && MFI(X()) - MFI(X() + 1) >= 1.5*MFI(X()) && Close(X()) > Close(X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > 25.0 && ADXMinus(X() + 1) <= ADXPlus(X() + 1) && ADXMinus(X()) > ADXPlus(X() + m_past) && Hi(X()) - Lo(X()) < 0.6*(Hi(X() + m_past) - Lo(X() + m_past)) && MFI(X()) - MFI(X() + 1) >= 1.5*MFI(X()) && Close(X()) < Close(X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 9. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_9(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) > Close(X() + 1) && Close(X() + 1) > Close(X() + 2) && MFI(X()) > MFI(X() + 1) && Low(X()) < Low(X() + 1) && Low(X() + 1) <= Low(X() + 2)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) < Close(X() + 1) && Close(X() + 1) < Close(X() + 2) && MFI(X()) < MFI(X() + 1) && High(X()) > High(X() + 1) && High(X() + 1) >= High(X() + 2)); } return(false); }
取引ロジックを提示する際にカスタムシグナルクラス形式を使用することには、いくつかの利点があります。初めての読者向けの導入記事も用意されていますが、この形式についてはこれまでの過去記事でも触れてきました。要点としては、アイデアの検証を非常に迅速におこなえる点に加えて、同じ形式で作成された他のシステムと容易に組み合わせられるという点にあります。つまり、カスタムシグナルを用いることで、ハイブリッド型取引システムの開発が柔軟におこなえるようになります。
結論
本記事では、Vanguard Information Technology ETF (VGT)を対象に、ノイズの多いチャートや過密なインジケーター配置、そしてインジケーター間の情報の重複という、トレーダーが直面しがちな問題に正面から対処するための統計的かつ体系的なアプローチを提示しました。まず、VGTの第4四半期から第1四半期(Q4〜Q1)にかけての季節性を明確にすることで、その期間におけるボラティリティおよびトレンド特性を、比較的予測可能で不確実性が抑えられた市場環境として捉えることができました。この前提のもとで、ケンドールのタウ係数と距離相関を用いてインジケーターのペアを評価する方法を示しました。ここで重要なのは、RedditなどのSNSの推奨に依存するのではなく、定量的な独立性指標に基づいて評価するという点です。この方法により、各インジケーターが互いのシグナルを本当に補完しているのか、それとも単に同じ情報を別の形で表しているだけなのかを判断することができます。
検討したインジケーターのペアの中では、ADXとビル・ウィリアムズMFIの組み合わせが、VGT ETFに対して最も補完性が高いペアとして確認されました。もっとも、このようなプロセスは取引対象となる金融商品ごとに個別に実施するべきであると考えられます。もちろん、複数の資産クラスに対して広く適用できるインジケーターのペアが存在する可能性もありますが、そのようなケースは例外的である可能性が高いと言えるでしょう。最後に、選ばれたインジケーターのペアのシグナルパターンの予測能力を評価するためにF1スコアを用いた分析をおこないました。さらに、UCBベイズ手法を適用することで、ADX–MFIペアの中から最も有効な10種類のシグナルパターンを特定しました。これらのロジックはMQL5で実装されており、MetaTrader 5上で直接利用および追加テストが可能です。この手法の初期用途としては、ウィザードで構築されたエキスパートアドバイザー(EA)としての使用を想定しています。ただし、本記事にはシグナルクラスのコードも添付されているため、経験のある開発者であれば、このロジックを比較的容易に汎用的な形へ拡張・適用することも可能です。| 名前 | 説明 |
|---|---|
| EMC-1.mq5 | 使用ファイルがヘッダに示されたコンパイル済みEA |
| SignalEMC-1.mq5 | MQL5ウィザードがEAを構築するために必要なカスタムシグナルクラスファイル |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/20271
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索