
Методика рыночного позиционирования по VGT на базе тау Кендалла и дистанционной корреляции
Введение
Поиск конкурентного преимущества на рынках редко бывает прямым. Зачастую это похоже на поиски чёрного кота в тёмной комнате… в то время как этот кот постоянно строит козни, чтобы обнулить ваш баланс на счёте. Сегодня нас заваливают не только «новостями» и медийным шумом, но и множеством графических сетапов, напичканных индикаторами, каждый из которых якобы восполняет недостающее звено в торговой вселенной. Однако критический анализ всегда показывает, что наши проблемы заключаются не в нехватке инструментов, а в понимании того, какие инструменты действительно выполняют работу, а какие потребляют ресурсы процессора или лишь создают видимость надежности.
Один из способов, которым пользователи MetaTrader, как правило, пренебрегают, когда дело доходит до преодоления шума, - это полностью выйти за рамки обычной валютной песочницы. Эта платформа - не просто рабочая лошадка для обмена валюты. В зависимости от своего брокера, вы можете торговать акциями, биржевыми инвестиционными фондами (ETF), сырьевыми товарами, индексами и широким спектром нетрадиционных активов. Для некоторых трейдеров такие активы открывают возможности там, где рыночная толпа не так плотна. В качестве наглядного примера можно привести высокореактивные ETF, такие как VGT.
VGT, который обладает почти лазерной ориентацией на компании mega-cap tech, ведет себя не так, как валютная пара. Валютные пары, за исключением выходных и очень редких случаев, демонстрируют стабильные цены без существенных гэп‑апов или гэп‑даунов. Недавно, 6 октября этого года, у нас был гэп-даун по JPY, но это произошло в выходные и после того, как в Японии сменился премьер-министр. На рынке форекс такие разрывы случаются, но из-за огромного количества доступной ликвидности они являются скорее исключением, чем нормой. Если же перейти к VGT, и если посмотреть на его ценовой график, то даже на дневном таймфрейме ценовые разрывы будут в значительной степени нормой. Эти разрывы могут отпугнуть некоторых трейдеров, предпочитающих работать в высоколиквидных условиях, но они также могут предоставить им возможность увеличить свое преимущество, что, в некотором смысле, и представляет собой MT5.
Возможность экспериментировать с различными типами активов, используя схожие наборы инструментов для различных типов активов - вот некоторые из преимуществ данного решения. Однако обратная сторона этого заключается в том, что загроможденный график или, в нашем случае, советник, использующий слишком много инструментов, могут стать еще более опасными при работе с активами, подверженными колебаниям, такими как VGT. Избыточные или чрезмерно коррелированные индикаторы не только шепчут ложь, потому что есть унисон, они выкрикивают ее. Это может исказить точки входа и привести к уверенности, основанной на дублирующихся посылках, а не на действительно независимой информации. Хотя торговая система регистрировала бы совпадение трех индикаторов, в реальности часто было бы три градусника, измеряющих одну и ту же температуру.
Чтобы избежать подобных упущений, нам необходим четкий, основанный на данных подход к оценке этих показателей, чтобы количественно оценить вклад каждого индикатора. В каком-то смысле это и есть суть задачи данной статьи и нескольких подобных ей, которые мы рассматриваем по каждому активу отдельно. Однако в данной работе мы используем индикаторы тау Кендалла и дистанционная корреляция для измерения независимости индикаторов. Помимо статистики, мы разберем сигнальный паттерн каждого индикатора и постараемся подобрать подходящее сочетание из выигрышной пары индикаторов для комбинаций паттернов, которые дают наилучшие результаты. Вкратце, речь идет не о добавлении дополнительных инструментов или внедрении новых причудливых индикаторов, а скорее о том, чтобы понять их достаточно хорошо, чтобы действительно создать преимущество, и продемонстрировать, как MT5 может служить испытательным полигоном для этого.Что такое VGT
Vanguard Information Technology ETF, часто сокращаемый как VGT, является крупным инвестиционным фондом в технологическом секторе, который выполняет функции фонда, предназначенного для отслеживания динамики индекса MSCI US Investable Market Information Technology 25/50. Это тщательно подобранная ‘ракета’, состоящая из крупнейших и наиболее влиятельных имен в области технологий, с включением нескольких небольших и средних компаний для демонстрации потенциального роста. Если взглянуть на его холдинги в любой момент времени, можно заметить, что крупнейшую долю в портфеле составляют такие компании, как Microsoft, Apple, Google, Amazon, Nvidia и другие.
Коллективное поведение этих холдингов с крупной капитализацией часто создает гравитационное притяжение, которое служит основным двигателем траектории всего ETF. Однако под ними также находятся акции полупроводников, программной инфраструктуры, IT-услуг и облачной инфраструктуры, которые выступают в качестве движущих сил общего тренда ETF. Будучи небольшими по величине, они, как правило, оказывают огромное влияние всякий раз, когда настроение меняется в сторону риска.
В отличие от более диверсифицированных ETF, которые часто распределяют технологические активы по различным секторам, VGT отличается явной концентрированностью. Этот ETF не размывает инвестиционную ставку, а, наоборот, концентрирует ее. Следствием этого является то, что он имеет тенденцию быстро перемещаться в любом направлении. Иными словами, всякий раз, когда NASDAQ чихает, VGT либо подхватывает простуду, либо растет, как будто обнаружил новую мощную вакцину. По сути, с точки зрения настройки VGT, волатильность - это не ошибка, а скорее премия, которую платят за потенциальную опережающую доходность. Как однажды сказал Уоррен Баффет (Warren Buffett), диверсификация - враг эффективности.
Начатая в 2004 году траектория роста VGT стала практически отражением самой цифровой революции. Начиная с зарождения web-2.0 и заканчивая индустриальным расцветом искусственного интеллекта, VGT, по сути, развивалась параллельно с каждой важной технологической вехой. Его минимальный коэффициент расходов также обеспечивает структурное преимущество, которое позволяет направлять большую часть прибыли от акционерного капитала инвестору, а не в казну управляющего фондом.
С учетом сказанного, все больше растет понимание того, что торговля VGT в первую очередь связана не с бычьим или медвежьим трендом, а скорее с тем, чтобы правильно улавливать ротации внутри внутренней ‘погодной системы’ технологического сектора. Поведение VGT, как правило, меняется в зависимости от сезона, квартала, а также макроциклов. Это подводит нас к следующему разделу, посвященному тому, на что следует обратить внимание в 2026 году, поскольку эта тема не только представляется актуальной, но, возможно, и критически важной.
Текущие перспективы VGT
Сезонность на фондовых рынках - это не волшебство и не выдумка трейдеров, а скорее ритм, порожденный привычками крупных игроков, таких как институты, финансовыми циклами, а также психологией некоторых инвесторов. Кроме того, лишь немногие отрасли в большей степени, чем технологии, способны выявить сезонные изменения. С этой целью фонд Vanguard Information Technology ETF часто танцевал в этом ритме как часы, особенно в конце года.
Исторически сложилось так, что четвертый квартал, в котором мы находимся, был наиболее сильным сезонным периодом для VGT. Это часто был период, когда технологии опережали рынок в целом благодаря трем повторяющимся темам.
- Во-первых, зачастую имеется импульс, создаваемый отчетами о прибыли, который обычно улучшает настроения.
- Во-вторых, ближе к концу года в VGT проводится перебалансировка, в рамках которой руководство «стрижет» отстающих и делает ставку на лидеров рынка.
- Наконец, расходы, связанные с праздниками, особенно на оборудование, полупроводники, а также цифровые услуги, в связи с которыми бум спроса способствует увеличению ожидаемых доходов.
Известно также, что это событие совпадает с ралли Санта-Клауса - периодом, когда акции растут в течение последних 5 торговых дней декабря, а также первых двух дней января. В случае с такими технологически сложными инструментами, как VGT, этот бычий импульс часто формируется на ранней стадии, поскольку фонды, стремящиеся к высокой эффективности, в поисках достойных годовых показателей запрыгивают в этот восходящий импульс. Однако в последние годы начинает вырисовываться тенденция, согласно которой не все акции демонстрируют одинаково позитивный настрой.
Январский эффект, который обычно преподносится как подарок для акций с малой капитализацией, оказывает давление на VGT, поскольку все больше и больше инвесторов уходят из mega‑cap tech в отстающие секторы. Кроме того, существует также зарождающаяся фаза переваривания отчетности, когда завышенные оценки, как правило, становятся ‘похмельем’ реальности. В прошлом, 2024 году, именно эта фаза ослабила "ИИ-манию"; в 2025 году, когда мы приближаемся к 2026 году, опасения по поводу перерасхода средств на ИИ могут сохраниться, особенно если этот ажиотаж превысит фундаментальные показатели.
Если мы посмотрим на это с точки зрения независимости от волатильности, то в начале четвертого квартала VGT обычно демонстрирует сжатые диапазоны, за которыми к концу года следует фаза расширения. Это, как правило, подходящая среда для торговых систем, использующих адаптивные индикаторы, которые используются для определения случаев, когда спокойные фазы рынка переходят в активные. Для выбора подходящей пары индикаторов мы начнем с пула из 5 пар. Исходя из этого, мы определим наилучшую пару, сопоставив ее с динамикой цен VGT за последние 5 лет. Позвольте сначала представить вам пары индикаторов. За этим последует сопоставление сигнальных паттернов для выбранных индикаторов. Поэтому в этой статье мы используем следующий тематический подход, описанный в приведенной ниже блок-схеме.

Используемые индикаторы
Выбор подходящих инструментов для анализа высокодоходных ETF, таких как VGT, заключается не столько в том, чтобы перегрузить ценовой график как можно большим количеством сложных функций, сколько в точной настройке инструментария. Нам необходимо определить пары индикаторов, которые не мешают друг другу, а скорее действуют как команда. Они должны быть способны дополнять слепые зоны друг друга. Следующие 5 пар индикаторов-кандидатов, которые мы рассматриваем, демонстрируют уникальное поведение по отношению к рынкам. К ним относятся волатильность, импульс, сила тренда, а также истощение. Краткая схема нашей методологии в выборе этих индикаторов может быть представлена следующим образом;

Наша задача состоит в том, чтобы определить, в какой степени эти индикаторные пары способны работать сами по себе или независимо друг от друга, а затем, вооружившись этой информацией, сделать вывод о том, насколько они могут обеспечить согласованную торговую логику. Именно здесь вступят в действие два наших алгоритма, которые мы упоминаем в названии и резюме статьи - тау Кендалла и дистанционная корреляция. А пока давайте сначала посмотрим на этих «бойцов».
Первая пара, которую мы рассмотрим: ADX (Average Directional Movement Index), разработанный Дж. Уэллсом Уайлдером (J. Welles Wilder) и MFI (Индекс рыночной фасилитации), разработанный Биллом Вильямсом (Bill Williams). Как видно из предоставленной ссылки на сайт MetaTrader, индикатор ADX количественно оценивает силу тренда, а не его направление. Он работает хорошо, когда есть ясность в направлении, текущие рыночные движения сильны, а импульс очевиден. С другой стороны, его парный аналог, MFI, больше внимания уделяет тому, как цена взаимодействует с объемом, измеряя ‘легкость’, с которой цена движется на рынке. Вместе они формируют цельную картину. ADX сообщает о том, насколько сильной является данная ценовая волна, в то время как MFI оценивает, сколько усилий прилагают рынки, чтобы реализовать это движение. В контексте резких скачков волатильности VGT эта комбинация может разделять где энергия накапливается, а где иссякает.
Вторая пара индикаторов-кандидатов - это фрактальная адаптивная скользящая средняя, известная как FrAMA, а также Полосы Боллинджера. FrAMA - это скользящая средняя, предназначенная для изменения своей чувствительности к рынку в зависимости от преобладающего ценового движения, в то время как индикатор «Полосы Боллинджера» обозначает границы волатильности вокруг цены. В сочетании эти два фактора создают дуэт волатильности, при котором FrAMA постоянно внутренне адаптируется к обстоятельствам тренда, в то время как Полосы Боллинджера устанавливает внешние границы волатильности. Когда между ними наблюдается совпадение, это часто означает, что цена переходит от роста к сокращению. Это может оказаться бесценным для торговли на свингах VGT, когда вы сталкиваетесь с периодами ротации базовых акций.
Наша следующая пара-кандидат - это RSI и фрактал Билла Уильямса. RSI, как хорошо известно, отслеживает внутренний ценовой импульс - насколько цена изменилась относительно произвольного/фиксированного диапазона. С другой стороны, фрактал предназначен для определения небольших "точек разворота" или точек, в которых цена капитулирует/меняет направление движения. Таким образом, это сочетание служит инструментом для «охотников за обратным движением», где RSI сигнализирует о росте условий перекупленности или перепроданности, а фрактал отмечает точки, где цена ‘решительно’ готовится к развороту. Это также может сработать для VGT, если мы попытаемся использовать колебания в конце квартала или избежать ложных прорывов.
Следующая пара индикаторов-кандидатов - это ATR и процентный диапазон Уильямса (Williams Percent Range). Индекс ATR, как хорошо известно, измеряет величину волатильности. Процентный диапазон Уильямса показывает, насколько цена находится в пределах недавнего диапазона, или что можно считать более эмоционально честным аналогом RSI, смотрите формулы. Таким образом, объединение этих двух индикаторов позволяет определить ‘масштаб поля боя’, а также ‘местонахождение войск в данный момент’. Когда на рынке наблюдается тренд, процентный диапазон Уильямса стремится к выравниванию вблизи крайних значений, в то время как показатель ATR резко возрастает. Это может служить ранним предупреждением о возможном формировании следующей волны волатильности.
Последней рассматриваемой парой индикаторов является Gator Oscillator и Индикатор стандартного отклонения. Индикатор Gator является ответвлением индикатора Alligator и предназначен для обозначения схождения и расхождения между скользящими средними. По сути, это равносильно указанию на то, когда рынок ‘кусается’, а не ‘спит’, как утверждал Билл Уильямс, его автор. Когда он сочетается со стандартным отклонением, мы получаем необработанные статистические данные о дисперсии. Всякий раз, когда Gator просыпается и формируется тренд, но стандартное отклонение остается в состоянии сжатия, это часто называют сжатой пружиной. Когда оба они расширяются, это подтверждает фазу волатильности, когда VGT будет совершать свои самые большие движения.
Каждая из наших пяти пар дает четкое представление о поведении VGT, однако таких интуитивных ожиданий редко бывает достаточно, когда мы хотим активно торговать этим ETF. Нам нужно иметь возможность определить, насколько независим каждый из этих индикаторов, чтобы избежать двойного учета одного и того же поведения рынка под разными названиями. Вот почему в нашем анализе участвуют двое ‘судей’: Тау Кендалла и дистанционная корреляция Прежде чем внимательно рассмотреть их математику, начнем с рассмотрения их определений на ‘простом языке’, чтобы по мере продвижения лучше понять логику каждого.
Тау Кендалла простыми словами
Проще говоря, это ‘рукопожатие на основе ранжирования’ между двумя наборами данных. Поэтому при сравнении двух наборов данных ключевой вопрос заключается не в том, близки ли их значения, а в том, изменяются ли они в одном и том же порядке? Для иллюстрации рассмотрим ситуацию, когда вы и ваш партнер по трейдингу оцениваете по рангу дни, когда вы торговали на VGT. Вы ранжируете их по изменению цены, а он выбирает в качестве индикатора силу сигнала. Если выяснится, что вы оба согласны с тем, какие дни были сильными, а какие - слабыми, несмотря на то, что ваши фактические показатели различаются, ваши ранги будут конкордантными. Если рейтинги каким-либо образом расходятся, то они будут называться дискордантными.
Алгоритм тау Кендалла подсчитывает, сколько раз совпадают и не совпадают данные при сравнении пар наборов данных. Оценка лежит в диапазоне от -1,0 до +1,0, где первое означает полное несоответствие, а второе — полное соответствие. Нулевое значение означало бы отсутствие взаимосвязи между двумя сравниваемыми наборами данных или полную независимость.
Это имеет значение не только для VGT, но и для торговли в целом, учитывая, что индикаторы редко движутся линейно. Гэп-ап по RSI редко совпадает с движением ADX, а сжатие полос Боллинджера не отражает наклон FrAMA. Поэтому тау Кендалла помогает отфильтровать этот ‘шум’, сосредоточившись исключительно на относительной направленности индикатора.
По-другому это можно было бы рассматривать как форму корреляции без ‘драмы’. Такой способ измерения не фокусируется на величине отдельных волн индикаторов, а лишь на том, происходят ли они синхронно. Ниже приведена дедуктивная аналогия. Предположим, что ситуация такова, что индекс относительной силы (RSI) VGT указывает на восходящий импульс, а фрактал показывает, что разворот пока не предвидится. Если тау Кендалла между этими двумя индикаторами низкий или отрицательный, это означает, что эти два индикатора расходятся в ранжировании. Это может означать, что когда один из них рано реагирует на изменение цены, у другого индикация будет более запаздывающей, и наоборот.
Определение тау Кендалла
Разобравшись с интуитивным смыслом, давайте приоткроем завесу тайны над гайками и болтами и рассмотрим, как они работают под капотом. Учитывая две переменные X и Y - например, в качестве двух значений индикатора из набора ценовых данных VGT, - тау Кендалла мог бы количественно определить степень порядковой связи между ними. Это предполагает оценку всех возможных пар между этими наблюдениями и их классификацию как конкордантных (значение больше 0) или дискордантных (значение отрицательное). С этой целью пара наблюдений (Xi, Yi) и (Xj, Yj) считается конкордантной, если они изменяются в одном и том же направлении таким образом, что:
![]()
Однако она может быть дискордантной, когда:
![]()
Коэффициент тау Кендалла определяется следующим образом:
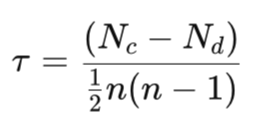
Где:
- Nc - количество конкордантных пар
- Nd - величина дискорданта
- n — общее количество наблюдений
В этой формуле знаменатель обозначает общее количество уникальных наблюдаемых пар. На практике показатель тау измеряет степень согласованности рангового порядка между значениями двух индикаторов. Значение +1 означает полное совпадение, или, как это еще называют, монотонно возрастающую зависимость. Значение, равное минимально возможному значению -1, означает идеальную обратную зависимость, которую также можно назвать монотонно убывающей зависимостью. Нулевое значение или любой показатель, близкий к нему, означает отсутствие корреляции.
При проведении анализа рынка это измерение, как правило, является выдающимся, поскольку для него не требуется каких-либо параметров. Это также не предполагает, что данные имеют нормальное распределение или даже ведут себя линейно. Эти свойства, возможно, делают его менее восприимчивым к выбросам и нелинейному масштабированию - обычным явлениям при работе с данными, полученными на основе индикаторов, особенно для таких инструментов с повышенным уровнем шума, как ETF. Таким образом, при рассмотрении всех индикаторных пар ADX-MFI, ATR-Williams R и т.д., тау служит для определения того, имеют ли сигналы обоих индикаторов тенденцию одинаково ранжировать ценовое действие или нет.
Чем ближе тау к нулю, для наших целей это будет зеленым флагом. Это происходит потому, что отсутствие какой бы то ни было корреляции, скорее всего, означает, что пара дополняет друг друга. Когда значение тау высокое или сильно отрицательное, это означает, что два значения индикаторов из цен VGT имеют значительную корреляцию, что подразумевает уровень дублирования или что оба индикатора отображают одну и ту же информацию под разными названиями индикаторов. Таким образом, именно так работает наш первый фильтр и ‘Судья’, тау Кендалла, помогающий устранить дублирующую логику среди индикаторов. Второй фильтр, который у нас есть, - это дистанционная корреляция, и, как и в случае с тау Кендалла, мы сначала представим его в терминах непрофессионала.
Изучение дистанционной корреляции
Если тау Кендалла говорит о сравнении рангов, то можно понимать дистанционную корреляцию как сравнение фигур. Он не только спрашивает, указывают ли эти индикаторные проекции в одном направлении, но и пытается количественно определить ритм или способ, которым они согласуются или расходятся. Оба алгоритма схожи в том, что они пытаются измерить, однако индикатор дистанционная корреляция немного изменен, чтобы получить дополнительную информацию между сравниваемыми наборами данных. Вот аналогия, которая могла бы прояснить этот вопрос. Рассмотрим сценарий, в котором два трейдера отслеживают ценовое движение VGT, и каждый из них имеет дело с определенным индикатором. Предположим, что первый трейдер читает ADX и сосредоточен на силе тренда, в то время как второй реагирует на сжатие волатильности, скажем, с помощью полос Боллинджера, даже на цепочку сигналов, когда в сочетании с ценовым действием оба индикатора сигнализируют, скажем, о покупке, это единодушное согласие обязательно произойдет в разной степени или нелинейно. Традиционные алгоритмы корреляции, такие как функция Пирсона или даже тау Кендалла, неизбежно пропускают эти "запутанные" детали этой зависимости.
Дистанционная корреляция, однако, немного более специфична в плане отслеживания вспомогательной информации в сравниваемых значениях индикаторов. Этот индикатор не отслеживает, насколько линейны, квадратичны или хаотичны значения двух индикаторов, а, используя ‘автокорреляционный подход’, стремится количественно оценить, в какой степени изменения значений одной переменной соответствуют изменениям значений другой переменной. Данный алгоритм ориентирован на паттерны изменений, а не на исходные значения или ранги.
Определение дистанционной корреляции
Формально, дистанционная корреляция отражает любую форму статистической зависимости, будь то монотонная, линейная, квадратичная или какая-либо другая. Учитывая два вектора значений индикатора VGT, дистанционная ковариация определяется на основе попарного расстояния между всеми наблюдаемыми значениями индикатора в каждом наборе векторных данных. Иными словами, мы отслеживаем геометрию одного вектора данных по отношению к геометрии другого. Расчет этого показателя состоит из четырех этапов. Сначала мы определяем попарные расстояния. Если задан набор данных из n наблюдений ((X1,Y1), (X2,Y2), … (Xn,Yn)), то все попарные евклидовы расстояния между значениями X можно получить из:
![]()
Аналогичным образом, расстояния между значениями Y можно получить из:
![]()
Затем вторым этапом является вычисление двойного центра, а также матриц расстояний. Мы получаем их путем вычитания средних значений по строкам и столбцам, прежде чем суммировать их обратно к общему среднему значению. Эти расстояния символически относительны, в отличие от абсолютных.

Этот этап также важен для обеспечения того, чтобы измерение было пропорциональным и не искажалось масштабом средних различий. Третий шаг, после того как мы суммируем расстояния, заключается в вычислении ковариации двух наборов данных и дисперсии каждого отдельного набора данных.

Таким образом, заключительный четвертый этап, после того как вы будете вооружены ковариацией наборов данных и индивидуальной дисперсией каждого набора данных, заключается в получении дистанционной корреляции следующим образом:

Диапазон значений составляет от 0 до 1, где 1 означает полную зависимость, а 0 - статистическую независимость.
Это довольно сложная задача, потому что, в отличие от тау Кендалла, который специализируется на ранжировании, дистанционная корреляция определяет, насколько структурно связаны два набора данных, признак, позволяющий отслеживать наборы данных независимо от того, связаны ли они линейно или квадратично. При выборе пары индикаторов для VGT индикаторы импульса, полосы волатильности и фрактальные графики обычно взаимосвязаны неочевидным образом, что означает, что тех, кто выполняет выбор на основе визуального контроля, легко ввести в заблуждение скрытыми зависимостями. Таким образом, в то время как тау Кендалла отфильтровывает зависимость от ранга, дистанционная корреляция позволяет выявить более глубокие структурные связи.
Если оба алгоритма сходятся во мнении, что значения индикаторов некоррелированы, мы можем считать, что эта пара представляет собой различную или взаимодополняющую сигнальную логику для торговой системы. Определив логику нашего алгоритма, давайте теперь рассмотрим, как реализовать его в среде, где это можно сделать достаточно эффективно, то есть в Python.
Оценка взаимодополняемости
Для достижения этой цели мы используем процесс на Python, который начинается с получения в качестве входных данных ценовых данных из модуля Python на MetaTrader 5. Мы входим в учетную запись MetaTrader 5 с данными о цене VGT ETF, а затем переходим к определению нашего тестового окна для загрузки исторических данных за последние 5 лет. Мы делаем это на дневном таймфрейме. Для каждого индикатора мы предварительно запрограммировали до 10 сигнальных паттернов, которые можно использовать по одному за раз в зависимости от настроек использования. Таким образом, первым шагом в оценке взаимодополняемости является выбор одного репрезентативного признака для каждого индикатора, его выравнивание, а затем вычисление единицы минус тау, а также единицы минус дистанционная корреляция. Мы используем единицу минус, потому что эти значения обратно пропорциональны нашей целевой величине. Код этих алгоритмов на языке Python выглядит следующим образом:
def fast_pair_summary(modA, prA, dfA, modB, prB, dfB, col_idx=0): featsA = _feature_matrix(modA, prA, dfA, col_idx) featsB = _feature_matrix(modB, prB, dfB, col_idx) tau_vals, dcor_vals = [], [] for x in featsA: if x is None: continue for y in featsB: if y is None: continue xa, ya = _align_last_equal(np.asarray(x), np.asarray(y)) if len(xa) < 5: continue tau, _ = kendalltau(xa, ya) if tau is None or np.isnan(tau): continue tau_vals.append(abs(tau)) dcor_vals.append(_distance_correlation(xa, ya)) if not tau_vals or not dcor_vals: return np.nan mean_abs_tau = np.mean(tau_vals) mean_dcor = np.mean(dcor_vals) independence = 1.0 - 0.5 * (mean_abs_tau + mean_dcor) return independence
def _distance_correlation(x, y): """Raw distance correlation (0..1). Works with 1D arrays of same length.""" # ensure 1D float arrays x = np.asarray(x, dtype=float).reshape(-1, 1) y = np.asarray(y, dtype=float).reshape(-1, 1) # pairwise Euclidean distances a = np.sqrt((x - x.T) ** 2) b = np.sqrt((y - y.T) ** 2) # double-center each distance matrix A = a - a.mean(axis=0)[None, :] - a.mean(axis=1)[:, None] + a.mean() B = b - b.mean(axis=0)[None, :] - b.mean(axis=1)[:, None] + b.mean() # distance covariance/variances dcov = np.sqrt(np.mean(A * B)) dvar_x = np.sqrt(np.mean(A * A)) dvar_y = np.sqrt(np.mean(B * B)) denom = np.sqrt(dvar_x * dvar_y) + 1e-12 return float(dcov / denom)
Когда это будет сделано, мы объединим два значения в единый показатель независимости. Поскольку у каждого индикатора есть 10 паттернов, а нам нужно выбрать один из этих десяти для использования при разработке взаимодополняемости. Мы не выбираем паттерны индикаторных сигналов для использования произвольно. Поэтому и предпринимается, казалось бы, ‘утомительный’, но необходимый процесс использования шаблонной сетки для подсчета очков размером 10 x 10. Для каждого пересечения этих паттернов в клетках мы вычисляем значение тау и дистанционную корреляцию, чтобы получить более широкое представление обо всех возможных комбинациях, где находится истинная синергия. Эту пару можно представить в виде нижней/верхней половины треугольников, образующих эту крестообразную таблицу.
Для каждой пары индикаторов мы составляем таблицу 10 x 10, содержащую взвешенные значения тау Кендалла и дистанционной корреляции. Наибольшее значение в перекрестной таблице после инверсии с единицей (1 минус взвешенное значение, учитывая обратную зависимость) может представлять собой пару индикаторов. Показатель, к которому мы приходим для каждой пары показателей, можно принять за ‘Оценку независимости’. Для наших пяти пар индикаторов эти показатели следующие:
| Индикатор 1 | Индикатор 2 | Оценка независимости |
|---|---|---|
| ADX Wilder | Bill Williams MFI (Индекс рыночной фасилитации Билла Уильямса) | 0.968 |
| Gator Oscillator | Стандартное отклонение | 0.961 |
| FrAMA | Полосы Боллинджера | 0.939 |
| RSI | Фракталы Билла Вильямса | 0.918 |
| ATR | Williams R | 0.902 |
Сопряжение сигнальных паттернов
Поскольку мы определили ADX и Bill Williams как подходящую независимую и в то же время синергетическую пару индикаторов, продолжим анализ, рассматривая сигнальные паттерны, на которых основан каждый из них. Оба индикатора имеют по 10 сигнальных паттернов и при их использовании нам нужно применять по одной паре за раз. Один паттерн ADX сопоставляется с другим паттерном MFI. Поскольку у нас есть по 10 паттернов для каждого индикатора, возникает вопрос, какой сигнальный паттерн с чем должен сочетаться, чтобы мы добились оптимальных результатов. Методологию, которую мы используем для надлежащего сочетания различных паттернов ADX и MFI, можно обобщить с помощью приведенной ниже блок-схемы:

Чтобы ответить на этот вопрос, мы получаем ценовые прогнозы индикатора и сравниваем их с фактическим движением цены при формировании показателя, известного как F1. Python отлично подходит для формирования таких оценок и отчетов, особенно после обучения нейронных сетей, но поскольку в нашем случае мы не проводим какого-либо обучения, а считываем прогнозы индикаторов на основе их необработанных входных параметров или параметров по умолчанию, он эффективно выполняет функцию проверки или тестового запуска.
Итак, нас снова интересуют прогнозы индикаторов в сочетании, поэтому мы рассматриваем перекрестную таблицу оценок F1 для каждой пары паттернов и применяем байесовский алгоритм UCB к среднему значению F1 и неопределенности, продолжая выборку наилучших показателей. Каждый индикатор содержит 10 уникальных сигнальных паттернов как для направленного, так и для волатильного рыночного режима. Этот байесовский оптимизатор рассматривает все 100 возможных пар, анализируя их как ‘отдельный рычаг (arm) в модели многорукого бандита’. Оценки F1, представленные в этой сводной таблице, становятся показателем вознаграждения, оценивая не только точность, но и согласованность результатов сделок в исследуемом пространстве VGT. Реализация в python выглядит следующим образом:
# ------------------------------------------------------------- # Dirichlet posterior score sampling per pair (for Bayesian UCB) # ------------------------------------------------------------- def _sample_score_from_dirichlet(C, weights, rng, alpha_prior=1.0, K=200): wa, wbull, wbear = weights C = C.astype(float) tot = int(C.sum()) if tot == 0: return np.zeros(K, dtype=float) draws = np.empty(K, dtype=float) alpha = alpha_prior + C.ravel() for k in range(K): p = rng.dirichlet(alpha) # probs over 9 cells # expected counts under p (or sample multinomial for more noise) # Here we treat p as a table, compute score metrics from p directly: P = p.reshape(3,3) acc = np.trace(P) pred_bull = P[:,2].sum(); bullP = (P[2,2]/pred_bull) if pred_bull>0 else 0.0 pred_bear = P[:,0].sum(); bearP = (P[0,0]/pred_bear) if pred_bear>0 else 0.0 draws[k] = wa*acc + wbull*bullP + wbear*bearP return draws
# ============================================================= # 5) Bayesian UCB assignment: S_ucb = mu + β*std from posterior draws # ============================================================= def select_pairs_bayesian_ucb(counts, weights=(0.2,0.4,0.4), K=300, beta=1.0, alpha_prior=1.0, rng=None): if rng is None: rng = np.random.default_rng() S_mu = np.zeros((10,10), dtype=float) S_sd = np.zeros((10,10), dtype=float) for i in range(10): for j in range(10): samp = _sample_score_from_dirichlet(counts[i,j], weights, rng, alpha_prior, K) S_mu[i,j] = samp.mean() S_sd[i,j] = samp.std(ddof=1) S_ucb = S_mu + beta * S_sd r, c = linear_sum_assignment(-S_ucb) pairs = [(int(i+1), int(j+1)) for i, j in zip(r, c)] return pairs, S_mu, S_sd, S_ucb
В результате этого процесса мы получаем 10 пар сигнальных паттернов на ADX и MFI.
| Ранг | Паттерн ADX | Паттерн MFI | Средний показатель F1 | Показатель UCB |
|---|---|---|---|---|
| 1 | A3 | M5 | 0.86 | 0.88 |
| 2 | A9 | M8 | 0.81 | 0.85 |
| 3 | A6 | M7 | 0.76 | 0.84 |
| 4 | A7 | M6 | 0.80 | 0.83 |
| 5 | A2 | M9 | 0.74 | 0.81 |
| 6 | A4 | M10 | 0.73 | 0.80 |
| 7 | A8 | M1 | 0.72 | 0.79 |
| 8 | A5 | M3 | 0.70 | 0.78 |
| 9 | A1 | M2 | 0.71 | 0.77 |
| 10 | A10 | M4 | 0.73 | 0.76 |
Код нашего сигнального паттерна на Python выглядит следующим образом:
# 1. ADX rises above 25 while +DI crosses above −DI -> bullish ignition. def feature_adx_1(df): adx = _col(df, 'ADX', 'adx', 'Adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') feature = np.zeros((len(df), 2), dtype=int) # bullish: ADX rises above 25 and +DI crosses above -DI (cross up on current bar) cond_bull = (adx > 25) & (pdi.shift(1) <= mdi.shift(1)) & (pdi > mdi) # bearish: ADX rises above 25 and -DI crosses above +DI cond_bear = (adx > 25) & (mdi.shift(1) <= pdi.shift(1)) & (mdi > pdi) # print(' adx > 25 ',adx > 25) # print(' pdi.shift(1) <= mdi.shift(1) ',pdi.shift(1) <= mdi.shift(1)) # print(' pdi > mdi ',pdi > mdi) # print(' cond_bull ',cond_bull) # print(' cond_bear ',cond_bear) feature[:, 0] = cond_bull.astype(int) feature[:, 1] = cond_bear.astype(int) feature[:2, :] = 0 return feature # 2. ADX making higher highs while price makes higher highs -> confirmed bullish momentum. def feature_adx_2(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close', 'PRICE', 'price', 'ClosePrice') feature = np.zeros((len(df), 2), dtype=int) # ADX higher highs over last 2 bars and price higher highs adx_hh = (adx > adx.shift(1)) & (adx.shift(1) > adx.shift(2)) price_hh = (close > close.shift(1)) & (close.shift(1) > close.shift(2)) feature[:, 0] = (adx_hh & price_hh).astype(int) # ADX higher highs but price makes lower highs -> bearish divergence (topping) price_lh = (close < close.shift(1)) & (close.shift(1) < close.shift(2)) feature[:, 1] = (adx_hh & price_lh).astype(int) feature[:3, :] = 0 return feature # 3. ADX climbing from below 20 to above 30 during sideways range -> breakout confirm. def feature_adx_3(df): adx = _col(df, 'ADX', 'adx') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # define sideways range: low volatility measured by small ATR proxy (high-low small) range_width = (high - low).rolling(10, min_periods=1).mean() sideways = range_width < (range_width.rolling(50, min_periods=1).median()) # crude # ADX climbs from below 20 to above 30 within recent window climbed = (adx > 30) & (adx.shift(5) < 20) # bullish breakout: close breaks above recent 10-bar high while climbed & sideways breakout_up = climbed & sideways & (close > close.rolling(10).max().shift(1)) breakout_down = climbed & sideways & (close < close.rolling(10).min().shift(1)) feature[:, 0] = breakout_up.astype(int) feature[:, 1] = breakout_down.astype(int) feature[:10, :] = 0 return feature # 4. +DI forms W while ADX rises -> momentum recovery; inverse for -DI M pattern. def feature_adx_4(df): adx = _col(df, 'ADX', 'adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') feature = np.zeros((len(df), 2), dtype=int) # detect simple W pattern on +DI: low in middle between two higher peaks w_plus = (pdi.shift(2) > pdi.shift(1)) & (pdi.shift(1) < pdi) & (pdi.shift(2) > pdi) m_minus = (mdi.shift(2) < mdi.shift(1)) & (mdi.shift(1) > mdi) & (mdi.shift(2) < mdi) # M-like top on -DI adx_rising = (adx > adx.shift(1)) & (adx.shift(1) > adx.shift(2)) feature[:, 0] = (w_plus & adx_rising).astype(int) feature[:, 1] = (m_minus & adx_rising).astype(int) feature[:3, :] = 0 return feature # 5. ADX falls after a long uptrend while price stalls -> trend exhaustion. def feature_adx_5(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # "long uptrend" measured as close rising for a while (10 bars) uptrend = (close > close.shift(1)) & (close.shift(1) > close.shift(2)) uptrend_long = close > close.shift(10) # price higher than 10 bars ago -> crude uptrend # ADX falling: current ADX below its 5-bar SMA and lower than previous adx_falling = (adx < adx.rolling(5, min_periods=1).mean()) & (adx < adx.shift(1)) # bull exhaustion: long uptrend + adx_falling + price stalls (small change) price_stall = (abs(close - close.shift(1)) / close.shift(1)) < 0.0025 # <0.25% change -> stall feature[:, 0] = (uptrend_long & adx_falling & price_stall).astype(int) # bear exhaustion: symmetric for downtrend downtrend_long = close < close.shift(10) feature[:, 1] = (downtrend_long & adx_falling & price_stall).astype(int) feature[:11, :] = 0 return feature # 6. ADX slope rising with widening +DI–−DI gap -> momentum expansion long def feature_adx_6(df): adx = _col(df, 'ADX', 'adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') feature = np.zeros((len(df), 2), dtype=int) adx_slope = adx - adx.shift(3) # 3-bar slope proxy gap = pdi - mdi gap_change = gap - gap.shift(3) # long expansion: ADX slope positive and gap widening in favor of +DI cond_long = (adx_slope > 0) & (gap_change > 0) & (gap > 0) # short expansion: ADX slope positive and gap widening in favor of -DI cond_short = (adx_slope > 0) & (gap_change < 0) & (gap < 0) feature[:, 0] = cond_long.astype(int) feature[:, 1] = cond_short.astype(int) feature[:4, :] = 0 return feature # 7. ADX divergence: price higher high, ADX lower high -> hidden weakness def feature_adx_7(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # Price higher high over last 2 bars but ADX lower high price_higher_high = (close > close.shift(1)) & (close.shift(1) > close.shift(2)) adx_lower_high = (adx < adx.shift(1)) & (adx.shift(1) < adx.shift(2)) feature[:, 0] = (price_higher_high & adx_lower_high).astype(int) # Price lower low but ADX higher low -> weak bearish continuation price_lower_low = (close < close.shift(1)) & (close.shift(1) < close.shift(2)) adx_higher_low = (adx > adx.shift(1)) & (adx.shift(1) > adx.shift(2)) feature[:, 1] = (price_lower_low & adx_higher_low).astype(int) feature[:3, :] = 0 return feature # 8. ADX makes W base while price forms W -> bullish reversal; M top -> bearish reversal. def feature_adx_8(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # W base detection (ADX): low in middle between two higher values adx_w = (adx.shift(2) > adx.shift(1)) & (adx.shift(1) < adx) & (adx.shift(2) > adx) price_w = (close.shift(2) > close.shift(1)) & (close.shift(1) < close) & (close.shift(2) > close) feature[:, 0] = (adx_w & price_w).astype(int) # M top detection: mirror of W (two peaks with lower middle) adx_m = (adx.shift(2) < adx.shift(1)) & (adx.shift(1) > adx) & (adx.shift(2) < adx) price_m = (close.shift(2) < close.shift(1)) & (close.shift(1) > close) & (close.shift(2) < close) feature[:, 1] = (adx_m & price_m).astype(int) feature[:3, :] = 0 return feature # 9. ADX slope flattening near 20 with price consolidating -> breakout signals (top/bottom). def feature_adx_9(df): adx = _col(df, 'ADX', 'adx') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) # flattening near 20: ADX within +/-2 of 20 and small recent slope near_20 = (adx.between(18, 22)) flat_slope = (abs(adx - adx.shift(5)) < 2) # consolidation: price within narrow band of recent 10 bars band = high.rolling(10, min_periods=1).max() - low.rolling(10, min_periods=1).min() narrow = band < (band.rolling(50, min_periods=1).median()) # breakout up: price breaks above previous 10-bar high breakout_up = near_20 & flat_slope & narrow & (close > close.rolling(10).max().shift(1)) # breakout down: price breaks below previous 10-bar low breakout_down = near_20 & flat_slope & narrow & (close < close.rolling(10).min().shift(1)) feature[:, 0] = breakout_up.astype(int) feature[:, 1] = breakout_down.astype(int) feature[:11, :] = 0 return feature # 10. ADX falls sharply while DI lines stay wide -> temporary pullback in trend. def feature_adx_10(df): adx = _col(df, 'ADX', 'adx') pdi = _col(df, '+DI', 'PLUS_DI', 'PDI', 'plus_di') mdi = _col(df, '-DI', 'MINUS_DI', 'MDI', 'minus_di') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # ADX falls sharply: current ADX much lower than 5-bar ago adx_drop = (adx < adx.shift(5) * 0.8) # >20% drop over 5 bars # DI lines stay wide: absolute gap still large (> threshold) gap = abs(pdi - mdi) wide_gap = gap > gap.rolling(20, min_periods=1).mean() # gap wider than its 20-bar mean # bullish context (initial trend was bullish): +DI > -DI bull_context = pdi > mdi bear_context = mdi > pdi # bullish temporary pullback: adx_drop & wide_gap & bull_context -> buy on continuation after pullback feature[:, 0] = (adx_drop & wide_gap & bull_context).astype(int) feature[:, 1] = (adx_drop & wide_gap & bear_context).astype(int) feature[:6, :] = 0 return feature
# 1. MFI and volume both rise -> genuine buying strength. Mirror: MFI+volume rise while price fails -> topping clue. def feature_mfi_1(df): mfi = _col(df, 'MFI_BW', 'MFI', 'mfi', 'MarketFacilitationIndex') try: vol = _col(df, 'Volume', 'tick_volume', 'VOL') except KeyError: vol = pd.Series(0, index=df.index) close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) mfi_up = (mfi > mfi.shift(1)) vol_up = (vol > vol.shift(1)) price_fail = (close <= close.shift(1)) # price not confirming feature[:, 0] = (mfi_up & vol_up & (close > close.shift(1))).astype(int) feature[:, 1] = (mfi_up & vol_up & price_fail).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 2. MFI spikes with green bar after compression -> momentum expansion up. Mirror downward. def feature_mfi_2(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) # compression = low volatility (small range) vs longer history range10 = (high - low).rolling(10, min_periods=1).mean() med_range = range10.rolling(100, min_periods=1).median().replace(0, np.nan) compressed = range10 < (0.6 * med_range) # spike = large jump in MFI relative to recent mfi_spike = (mfi > mfi.rolling(5, min_periods=1).mean() + 1.5 * mfi.rolling(5, min_periods=1).std()) green_bar = close > close.shift(1) brown_bar = close < close.shift(1) feature[:, 0] = (compressed.shift(1) & mfi_spike & green_bar).astype(int) feature[:, 1] = (compressed.shift(1) & mfi_spike & brown_bar).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 3. MFI increases while price stabilizes -> silent accumulation. Mirror: MFI decreases while price stabilizes -> silent distribution. def feature_mfi_3(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) mfi_up = (mfi > mfi.shift(1)) mfi_down = (mfi < mfi.shift(1)) # price stabilizes = small average absolute returns over short window price_change = (abs(close - close.shift(1)) / close.shift(1).replace(0, np.nan)).rolling(5, min_periods=1).mean() stable = price_change < 0.0025 # ~0.25% avg move feature[:, 0] = (mfi_up & stable).astype(int) feature[:, 1] = (mfi_down & stable).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 4. MFI higher low while price retests support -> hidden bullish divergence. Mirror bearish. def feature_mfi_4(df): mfi = _col(df, 'MFI', 'mfi') low = _col(df, 'Low', 'low') high = _col(df, 'High', 'high') feature = np.zeros((len(df), 2), dtype=int) price_retest_support = (low < low.shift(1)) & (low.shift(1) <= low.shift(2)) # recent retest/probe mfi_hl = (mfi > mfi.shift(1)) & (mfi.shift(1) > mfi.shift(2)) price_retest_resist = (high > high.shift(1)) & (high.shift(1) >= high.shift(2)) mfi_lh = (mfi < mfi.shift(1)) & (mfi.shift(1) < mfi.shift(2)) feature[:, 0] = (price_retest_support & mfi_hl).astype(int) feature[:, 1] = (price_retest_resist & mfi_lh).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 5. W-shaped MFI under price base -> reversal setup. M-shaped above price top -> topping structure. def feature_mfi_5(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # W detection on MFI (4-bar pattern): dip between two higher pivots w_mfi = (mfi.shift(3) < mfi.shift(2)) & (mfi.shift(2) < mfi.shift(1)) & (mfi.shift(1) < mfi) # require that MFI values are under price base (close relatively flat or above) price_base = close > close.rolling(10, min_periods=1).mean() # M detection on MFI: peak between two lower pivots m_mfi = (mfi.shift(3) > mfi.shift(2)) & (mfi.shift(2) > mfi.shift(1)) & (mfi.shift(1) > mfi) feature[:, 0] = (w_mfi & price_base).astype(int) feature[:, 1] = (m_mfi & (~price_base)).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 6. MFI and volume decouple -> stealth accumulation/distribution. def feature_mfi_6(df): mfi = _col(df, 'MFI', 'mfi') try: vol = _col(df, 'Volume', 'volume', 'VOL') except KeyError: vol = pd.Series(np.nan, index=df.index) close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) mfi_up = (mfi > mfi.shift(1)) mfi_down = (mfi < mfi.shift(1)) vol_down = (vol < vol.shift(1)) vol_up = (vol > vol.shift(1)) # stealth accumulation: MFI up while volume down feature[:, 0] = (mfi_up & vol_down).astype(int) # distribution bias: MFI down while volume up feature[:, 1] = (mfi_down & vol_up).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 7. MFI bar color shift from brown to green -> fresh burst. Mirror green->brown -> exhaustion. def feature_mfi_7(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') feature = np.zeros((len(df), 2), dtype=int) # Interpret "green" as close > prev close and mfi rising; "brown" as falling mfi_rise = (mfi > mfi.shift(1)) mfi_fall = (mfi < mfi.shift(1)) green_bar = (close > close.shift(1)) & mfi_rise brown_bar = (close < close.shift(1)) & mfi_fall feature[:, 0] = (brown_bar.shift(1) & green_bar).astype(int) feature[:, 1] = (green_bar.shift(1) & brown_bar).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 8. MFI bottoms and climbs while volatility increases -> uptrend resumption. Mirror peak & decline -> downtrend resumption. def feature_mfi_8(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) # volatility proxy atr_like = (high - low).rolling(14, min_periods=1).mean() vol_up = atr_like > atr_like.shift(3) # bottom and climb: mfi rises from local trough mfi_bottom = (mfi.shift(2) > mfi.shift(1)) & (mfi.shift(1) < mfi) # trough at shift(1) mfi_peak = (mfi.shift(2) < mfi.shift(1)) & (mfi.shift(1) > mfi) feature[:, 0] = (mfi_bottom.shift(1) & (mfi > mfi.shift(1)) & vol_up).astype(int) feature[:, 1] = (mfi_peak.shift(1) & (mfi < mfi.shift(1)) & vol_up).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 9. MFI breaks above prior swing -> energy expansion. Mirror break below -> collapse. def feature_mfi_9(df): mfi = _col(df, 'MFI', 'mfi') feature = np.zeros((len(df), 2), dtype=int) # prior swing high/low of MFI (10-bar) prior_high = mfi.rolling(10, min_periods=1).max().shift(1) prior_low = mfi.rolling(10, min_periods=1).min().shift(1) break_up = (mfi > prior_high) break_down = (mfi < prior_low) feature[:, 0] = break_up.astype(int) feature[:, 1] = break_down.astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature # 10. Rising MFI slope with narrowing candle bodies -> hidden demand absorption. Mirror supply absorption. def feature_mfi_10(df): mfi = _col(df, 'MFI', 'mfi') close = _col(df, 'Close', 'close') high = _col(df, 'High', 'high') low = _col(df, 'Low', 'low') feature = np.zeros((len(df), 2), dtype=int) mfi_slope = mfi - mfi.shift(3) rising_slope = mfi_slope > mfi_slope.shift(1) falling_slope = mfi_slope < mfi_slope.shift(1) # narrowing candle bodies = average body size shrinking body = (abs(close - close.shift(1))).rolling(7, min_periods=1).mean() body_shrink = body < body.shift(3) feature[:, 0] = (rising_slope & body_shrink).astype(int) feature[:, 1] = (falling_slope & body_shrink).astype(int) feature[0, :] = 0 feature[1, :] = 0 return feature
Мы кодируем их в рекомендованном выше формате парных сопоставлений на MQL5 следующим образом.
//+------------------------------------------------------------------+ //| Check for Pattern 0. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_0(ENUM_POSITION_TYPE T) { int _i_max = -1, _i_min = -1; if(T == POSITION_TYPE_BUY) { return(Hi(X()) - Lo(X()) > High(X()) - Low(X()) && ADX(X()) > 30 && ADX(X() + 5) < 20 && Close(X()) > m_close.MaxValue(X(), m_past, _i_max) && MFI(X() + 1) < MFI(X()) && MFI(X() + 2) < MFI(X() + 1) && MFI(X() + 3) < MFI(X() + 2) && Close(X()) > Cl(X())); } else if(T == POSITION_TYPE_SELL) { return(Hi(X()) - Lo(X()) > High(X()) - Low(X()) && ADX(X()) > 30 && ADX(X() + 5) < 20 && Close(X()) < m_close.MinValue(X(), m_past, _i_min) && MFI(X() + 1) > MFI(X()) && MFI(X() + 2) > MFI(X() + 1) && MFI(X() + 3) > MFI(X() + 2) && Close(X()) < Cl(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 1. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_1(ENUM_POSITION_TYPE T) { int _i_max = -1, _i_min = -1; m_close.Refresh(-1); vector _mf; m_mfi.Refresh(-1); _mf.CopyIndicatorBuffer(m_mfi.Handle(), 0, 0, m_past); if(T == POSITION_TYPE_BUY) { return(ADX(X()) >= 18.0 && ADX(X()) <= 22.0 && fabs(ADX(X()) - ADX(X() + 5)) < 2.0 && Hi(X()) - Lo(X()) < High(X()) - Low(X()) && Close(X()) > m_close.MaxValue(X(), m_past, _i_max) && Hi(X()) - Lo(X()) < Hi(X() + m_past) - Lo(X() + m_past) && MFI(X() + 1) < MFI(X()) && LocalMin(_mf, X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) >= 18.0 && ADX(X()) <= 22.0 && fabs(ADX(X()) - ADX(X() + 5)) < 2.0 && Hi(X()) - Lo(X()) < High(X()) - Low(X()) && Close(X()) < m_close.MinValue(X(), m_past, _i_min) && Hi(X()) - Lo(X()) < Hi(X() + m_past) - Lo(X() + m_past) && MFI(X() + 1) > MFI(X()) && LocalMax(_mf, X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 2. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_2(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) - ADX(X() + m_past) > 0.0 && ADXPlus(X()) - ADXMinus(X()) > 0.0 && ADXPlus(X()) - ADXMinus(X()) > ADXPlus(X() + m_past) - ADXMinus(X() + m_past) && Close(X()) > Close(X() + 1) && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) - ADX(X() + m_past) > 0.0 && ADXPlus(X()) - ADXMinus(X()) < 0.0 && ADXPlus(X()) - ADXMinus(X()) < ADXPlus(X() + m_past) - ADXMinus(X() + m_past) && Close(X()) < Close(X() + 1) && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 3. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_3(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(Close(X()) > Close(X() + 1) && Close(X() + 1) > Close(X() + 2) && ADX(X()) < ADX(X() + 1) && ADX(X() + 1) < ADX(X() + 2) && Volumes(X() + 1) > Volumes(X()) && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(Close(X()) < Close(X() + 1) && Close(X() + 1) < Close(X() + 2) && ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Volumes(X() + 1) < Volumes(X()) && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 4. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_4(ENUM_POSITION_TYPE T) { vector _mf; m_mfi.Refresh(-1); _mf.CopyIndicatorBuffer(m_mfi.Handle(), 0, 0, m_past); if(T == POSITION_TYPE_BUY) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) > Close(X() + 1) && Close(X() + 1) > Close(X() + 2) && MFI(X()) > LocalMax(_mf, X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) < Close(X() + 1) && Close(X() + 1) < Close(X() + 2) && MFI(X()) < LocalMin(_mf, X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 5. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_5(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && ADXPlus(X() + 2) > ADXPlus(X() + 1) && ADXPlus(X() + 1) < ADXPlus(X()) && ADXPlus(X() + 2) > ADXPlus(X()) && Volumes(X() + 1) > Volumes(X()) && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && ADXMinus(X() + 2) < ADXMinus(X() + 1) && ADXMinus(X() + 1) > ADXMinus(X()) && ADXMinus(X() + 2) < ADXMinus(X()) && Volumes(X() + 1) < Volumes(X()) && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 6. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_6(ENUM_POSITION_TYPE T) { vector _ad, _cl; m_adx.Refresh(-1); m_close.Refresh(-1); _ad.CopyIndicatorBuffer(m_adx.Handle(), 0, 0, fmax(5,m_past)); _cl.CopyRates(m_symbol.Name(), m_period, 8, 0, fmax(5, m_past)); if(T == POSITION_TYPE_BUY) { return(IsW(_ad) && IsW(_cl) && MFI(X()) > MFI(X() + 1) && Volumes(X()) > Volumes(X() + 1) && Close(X()) < Close(X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(IsM(_ad) && IsM(_cl) && MFI(X()) > MFI(X() + 1) && Volumes(X()) > Volumes(X() + 1) && Close(X()) > Close(X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 7. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_7(ENUM_POSITION_TYPE T) { int _i_max = -1, _i_min = -1; m_close.Refresh(-1); m_adx.Refresh(-1); if(T == POSITION_TYPE_BUY) { return(Close(X()) >= m_close.MaxValue(X(), m_past, _i_max) && ADX(X()) <= m_adx.MinValue(0, X(), m_past, _i_min) && fabs(Close(X()) - Close(X() + 1))/fmax(m_symbol.Point(),Close(X() + 1)) <= 0.0025 && MFI(X() + 1) < MFI(X())); } else if(T == POSITION_TYPE_SELL) { return(Close(X()) <= m_close.MinValue(X(), m_past, _i_max) && ADX(X()) <= m_adx.MinValue(0, X(), m_past, _i_min) && fabs(Close(X()) - Close(X() + 1))/fmax(m_symbol.Point(),Close(X() + 1)) <= 0.0025 && MFI(X() + 1) > MFI(X())); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 8. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_8(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) > 25.0 && ADXMinus(X() + 1) >= ADXPlus(X() + 1) && ADXMinus(X()) < ADXPlus(X() + m_past) && Hi(X()) - Lo(X()) < 0.6*(Hi(X() + m_past) - Lo(X() + m_past)) && MFI(X()) - MFI(X() + 1) >= 1.5*MFI(X()) && Close(X()) > Close(X() + 1)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > 25.0 && ADXMinus(X() + 1) <= ADXPlus(X() + 1) && ADXMinus(X()) > ADXPlus(X() + m_past) && Hi(X()) - Lo(X()) < 0.6*(Hi(X() + m_past) - Lo(X() + m_past)) && MFI(X()) - MFI(X() + 1) >= 1.5*MFI(X()) && Close(X()) < Close(X() + 1)); } return(false); } //+------------------------------------------------------------------+ //| Check for Pattern 9. | //+------------------------------------------------------------------+ bool CSignalADX_MFI::IsPattern_9(ENUM_POSITION_TYPE T) { if(T == POSITION_TYPE_BUY) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) > Close(X() + 1) && Close(X() + 1) > Close(X() + 2) && MFI(X()) > MFI(X() + 1) && Low(X()) < Low(X() + 1) && Low(X() + 1) <= Low(X() + 2)); } else if(T == POSITION_TYPE_SELL) { return(ADX(X()) > ADX(X() + 1) && ADX(X() + 1) > ADX(X() + 2) && Close(X()) < Close(X() + 1) && Close(X() + 1) < Close(X() + 2) && MFI(X()) < MFI(X() + 1) && High(X()) > High(X() + 1) && High(X() + 1) >= High(X() + 2)); } return(false); }
Использование нами пользовательского формата классов сигналов для представления торговой логики имеет ряд преимуществ. Новые читатели могут ознакомиться с введением здесь. Я также упоминал об этом в прошлых статьях, но, по сути, мы можем очень быстро тестировать идеи, в то же время допуская их комбинирование с другими системами аналогичного формата, т.е. с пользовательскими сигналами для разработки гибридных систем.
Заключение
В этой статье мы изложили формальный и статистически обоснованный подход к торговле ETF VGT, который напрямую решает нашу изначальную проблему с зашумленными, переполненными графиками и перекрывающимися индикаторами. Начав с уточнения сезонного поведения VGT в окне от IV квартала к I кварталу, мы смогли представить его волатильность, а также динамику тренда как предсказуемый контекст со сниженной неопределенностью. На этом фоне мы продемонстрировали, как тау Кендалла и дистанционная корреляция могут быть полезны при оценке пар индикаторов не по рекомендациям Reddit или социальных сетей, а благодаря количественной независимости, и это гарантирует, что сигнал каждого индикатора действительно подтверждает сигналы других, а у нас меньше двойственности.
Из анализа рассмотренного нами пула индикаторных пар следует, что ADX и Индекс MFI Билла Уильямса в наибольшей степени дополняли друг друга для ETF VGT. Я утверждаю, что этот процесс должен быть специфичен для конкретного торгового инструмента, однако все еще можно найти индикаторные пары, которые могли бы гораздо лучше переноситься между разными активами, хотя я утверждаю, что это скорее исключение, чем норма. Мы завершаем анализ оценкой по F1 для прогнозирования возможности комбинирования паттернов выигрышных индикаторов. Применив байесовскую процедуру UCB, мы смогли определить десять наиболее выраженных сигнальных паттернов нашей выигрышной пары индикаторов ADX-MFI и запрограммировали их в MQL5 для использования и дальнейшего тестирования непосредственно в MetaTrader. Первоначально этот метод предназначен для использования в качестве советника, собранного с помощью мастера, однако, поскольку код этого класса сигналов прилагается, более опытные программисты могут легко адаптировать его для универсального применения.| название | описание |
|---|---|
| EMC-1.mq5 | Скомпилированный советник, в заголовке которого указаны использованные файлы |
| SignalEMC-1.mq5 | Файл пользовательского класса сигнала, необходимый мастеру mql5 для сборки советника |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/20271
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования