
Нейросети — это просто (Часть 65): Дистанционно-взвешенное обучение с учителем (DWSL)

Введение
Методы клонирования поведения, во многом основанные на принципах обучения с учителем, демонстрируют довольно хорошие результаты. Но их главной проблемой остается поиск идеальных примеров для подражания, которые порой очень трудно собрать. В свою очередь, методы обучения с подкреплением способны работать с неоптимальными исходными данными. При этом находить субоптимальные политики для достижения поставленной цели. Однако, при поиске оптимальной политики мы часто сталкиваемся с проблемой оптимизации, которая более остро проявляется в высоко размерных и стохастических средах.
Для преодоления разрыва между двумя указанными подходами был предложен метод Distance Weighted Supervised Learning (DWSL), представленный в статье "Distance Weighted Supervised Learning for Offline Interaction Data". Это алгоритм контролируемого офлайн обучения целенаправленной политики. И, теоретически, сходится к оптимальной политике с минимальной границей доходности на уровне траекторий из обучающей выборки. Практические примеры авторов демонстрируют превосходство предложенного метода над алгоритмами имитационного обучения и обучения с подкреплением. Предлагаю поближе познакомиться с данным DWSL алгоритмом. И на практике оценить его сильные и слабые стороны в решении наших задач.
1. Алгоритм DWSL
Авторы метода Distance Weighted Supervised Learning ставили перед собой цель получить алгоритм, способный использовать максимально возможный набор данных для обучения. И в этой парадигме предполагается, что Агент действует в детерминированном Марковском процессе принятия решений с:
- пространством состояний S;
- пространством действий A;
- детерминированной динамикой переходов St+1 = F(St,At), где St+1 — это новое состояние окружающей среды после выполнения действия At в состоянии St;
- пространством целей G;
- разреженной функцией вознаграждения, обусловленной на достижение цели R(S,A,G);
- коэффициентом дисконтирования γ.
Пространство целей G является подпространством пространства состояний S с функцией зависимости целей G = φ(St), которая часто идентична φ(St) = St+n. Целью алгоритма является обучение политики обусловленной на достижение цели π(A|S,G). Которая обладает мастерством в изученной среде и способна достигать поставленной цели, а после оставаться в ней. Для получения желаемого результата мы максимизируем дисконтированный доход от функции вознаграждения R(S,A,G) при условии достижения цели G из распределения целей p(G).
Хотя такая постановка задачи отличается от рассмотренных ранее, у нее сильные связи с двумя общими постановками проблем: проблемой стохастического кратчайшего пути и GCRL.
Авторы метода обращают внимание, что работы в области GCRL предполагают наличие траекторий с размеченными подцелями. Данные подцели заданы намерением политики, что предоставляет модели информацию о распределении целей p(G) во время тестирования. Что ограничивает данные для извлечения знаний при офлайн обучении GCRL. Причина в том, что многие источники офлайн данных не содержат меток целей (подцелей) вместе с каждой траекторией. Более того, цели могут быть трудными для получения.
С целью изучения более широкого набора офлайн данных, авторы метода рассматривают более общую ситуацию. Которая не предполагает доступ к истинной динамике окружающей среды, меткам вознаграждений или распределению целей на стадиях тестирования и эксплуатации. На этапе обучения используется только набор траекторий из состояний и действий произвольного уровня оптимальности. Распределение p(G) принимается за распределение целей, вызванных применением функции зависимости φ(St) ко всем состояниям в наборе данных. Предполагается, что для большинства практических наборов данных цели вокруг распределения данных, вероятно, близки к целям для интересующих нас задач. Метод DWSL может использовать любую разреженную функцию вознаграждения, которую можно вычислить только из имеющихся последовательностей состояний и действий, но практические изыскания авторов метода демонстрируют хорошие результаты при простом подсчете количества итераций для достижения поставленной цели.
Интуитивно, при использовании указанной функции вознаграждения лучшая стратегия достижения цели G из текущего состояния S является использование пути с минимальным количеством временных шагов (кратчайший путь). Однако траектории в обучающем наборе данных не обязательно следуют кратчайшим путям. В результате методы клонирования поведения могут проявлять неоптимальное поведение.
Для решения этой проблемы DWSL оценивает расстояния с помощью обучения с учителем, оценивает обученные модели в пределах распределения данных обучающей выборки. Модель изучает все распределение попарных расстояний между состояниями в обучающей выборке. И использует это распределение для оценки минимального расстояния до цели, содержащейся в наборе данных каждого состояния. А затем учит политику следовать этим путям. Ниже представлена авторская визуализация метода DWSL.

Между любыми двумя состояний Si и Sj на одной траектории при i < j существует как минимум один путь из "j - i" временных шагов. Используя это свойство мы генерируем размеченный набор данных, который содержит все попарные расстояния между состояниями и целями в обучающем наборе данных. Для каждой пары "Состояние—Цель", выбранной из нового распределения, мы моделируем дискретное распределение по числу временных шагов k от текущего состояния до цели, как показано на самом левом рисунке 1. Это позволяет нам получить параметризованную оценку распределения методом максимального правдоподобия на размеченном наборе данных:
![]()
На практике распределение моделируется как дискретный классификатор по возможным расстояниям. Кратчайший путь между исходным и целевым состояниями, содержащийся в размеченном наборе данных, определяется по минимальному количеству временных шагов k. Однако из-за того, что распределение изучается с использованием аппроксимации функций, оценка минимального расстояния вероятно будет использовать ошибки моделирования. Для минимизации указанной ошибки авторы метода предлагают вычислять LogSumExp по распределению расстояний, чтобы получить мягкую оценку минимального расстояния:
![]()
Обратите внимание, в представленной формуле расстояние умножается на "-1", чтобы получить оценку минимума вместо максимума. Здесь α является гиперпараметром температуры. При α стремящемся к "0", значение функции d(s, g) приближается к минимальному расстоянию k.
После изучения оценок минимального расстояния мы хотим использовать известные пути, который исходят их каждого состояния. Предположим, что Агент находится в состоянии S и необходимо достичь цели G. В исходном состоянии Агент может совершить одно из двух действий (A1 или A2), которые приводят в состояния S1 и S2, соответственно. Мы предпочтем совершить первое действие, если оно является началом пути до цели с минимальным количеством шагов (меньшая оцененная дистанция до цели). Следовательно, мы хотим взвешивать вероятность различных действий их оценками расстояния до цели (справа на рисунке выше). Однако наивное взвешивание действий таким образом приведет к более крупному весу для всех точек данных, близких к цели, так как любое состояние, далекое от цели, естественным образом будет иметь большее расстояние. Вместо этого мы взвешиваем вероятность действий в соответствии с их сокращением оцененного расстояния до цели, которое авторы метода назвали Преимуществом. Что позволяет сформировать новую цель обучения модели:
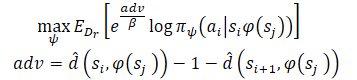
Авторы метода используют возведение в степень Преимуществ для того, чтобы обеспечить положительное значение всех весов.
2. Реализация средствами MQL5
После ознакомления с теоретическими аспектами метода Distance Weighted Supervised Learning мы переходим к практической части нашей статьи, в которой мы создадим свой вариант его реализации средствами MQL5. Как всегда, мы постараемся объединить предложенный алгоритм с накопленными нами ранее знаниями. И воспроизвести свое восприятие предложенных подходов. Согласен, что данный подход в какой-то мере отдаляет нас от авторского алгоритма и не является его точным воспроизведением. Следовательно, все слабые стороны, которые могут быть выявлены в процессе тестирования, относятся только к данной реализации.
Сразу скажу, что в авторской статье представлены эксперименты по управлению роботов-манипуляторов. В подобных условиях постановка цели имеет главенствующую роль в достижении положительного результата. Более того, она ясна в каждом отдельном случае. В своей же реализации я делаю акцент на максимизации доходности робота за обучаемый период. И для упрощения модели было принято решение об отказе постановки подцели на каждом шаге. Что в свою очередь позволяет нам не обучать модель постановки целей.
Кроме того, в данной работе мы будем обучать модель с использованием подходов Актер-Критик. И в качестве донора воспользуемся моделью стохастического маргинального Актер-Критика (SMAC). Однако мы его дополним и другими наработками. В частности, мы добавим механизм взвешивания траекторий из CWBC. Но обо всем по порядку. И начинаем мы работу с описания архитектуры моделей.
2.1. Архитектура моделей
Как всегда, архитектура обучаемых моделей представлена в методе CreateDescriptions. В параметрах методу мы будем передавать указатели на динамические массивы описания архитектуры 3 моделей:
- Актер
- Критик
- Случайный кодировщик.
Здесь надо напомнить, алгоритм SMAC предусматривает обучения стохастического кодировщика латентного состояния, который ранее мы включили в архитектуру Актера с возможностью использования Критиком. В данной реализации мы сохранили это решение.
В теле метода мы проверяем полученные указатели и, при необходимости, создаем новые экземпляры объектов.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; }
На вход Актера мы подаем исторические данные ценового движения и показателей индикаторов, что и отражается в размере его слоя исходных данных.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
На вход модели мы подаем сырые данные без предварительной обработки. Поэтому, за слоем исходных данных мы используем слой пакетной нормализации данных. Который приводит полученные сырые данные из различных источников в сопоставимый вид.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
После чего мы пробуем выявить устойчивые паттерны в данных с использование сверточных слоёв. А для получения вероятностного представления отнесения исходных данных к устойчивым паттернам мы используем функцию SoftMax.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
Обратите внимание, что поиск устойчивых паттернов мы осуществляем в разрезе каждой отдельно взятой свечи исторических данных.
Результаты поиска паттернов анализируются 2 полносвязными слоями.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
К полученным данным мы добавляем описание состояния счета.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
И генерируем стохастическое латентное состояние, предусмотренное методом SMAC.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Далее идет блок принятия решений из 2 полносвязных слоёв.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
А на выходе Актера мы ставим блок вариационного автоэнкодера для придания стохастичности политике. Размер слоя результатов соответствует размерности вектора действий Агента.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Архитектура Критика была перенесена без изменений. На вход модели подается латентное представление состояния окружающей среды из скрытого слоя Актера. И полученные данные не требуют приведения в сопоставимый вид. Следовательно, в данной модели мы не будем использовать слой пакетной нормализации.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
К латентному представлению мы добавляем действия Актера.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
Конкатенированные данные анализируются блоком принятия решений из 3 полносвязных слоев. Размер последнего слоя соответствует размеру вектора декомпозированного вознаграждения.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
В завершении метода CreateDescriptions мы добавим описание архитектуры случайного Кодировщика. Забегая немного вперед, скажу, что Кодировщик мы будем использовать в рамках процесса определения расстояния между состояниями окружающей среды. Для описания отдельно взятого состояния окружающей среды мы используем 2 вектора:
- исторических данных движения цены и показателей индикаторов;
- состояния счета и открытых позиций.
Конкатенированный вектор этих 2 сущностей мы и будем подавать на вход Кодировщика.
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
Модель Кодировщика не обучается. А следовательно, использование слоя пакетной нормализации не даст требуемого результата. Поэтому для приведения данных в какой-то сопоставимый вид мы воспользуемся полносвязным слоем. После чего нормализуем данные с помощью слоя SoftMax.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = HistoryBars * BarDescr; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = HistoryBars; descr.step = BarDescr; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
Далее идет блок сверточных слоев, который так же закрывается слоем SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count * prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
На выходе Кодировщика мы используем полносвязный слой, который возвращаем эмбединг анализируемого состояния окружающей среды.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- return true; }
2.2 Подготовка вспомогательных методов
После описания архитектуры используемых моделей мы переходим к работе над реализацией алгоритма обучения моделей. Но перед реализацией непосредственного процесса обучения надо сказать о пару слов о методах, которые реализуют отдельные блоки общего алгоритма.
Прежде всего, мы будем использовать взвешивание и приоритезацию траекторий, которая была рассмотрена в рамках метода CWBC. Для этого мы перенесем методы GetProbTrajectories и SampleTrajectory. Их алгоритм был подробно описан в предыдущей статье и мы не будем сейчас на нем останавливаться.
Для обучения Актера и Критиков мы будем использовать вознаграждения и действия, взвешенные с использованием подходов метода DWSL. С целью исключения повторных операций, вычисление целевых векторов для обоих моделей мы объединим в рамках одного метода GetTargets. А для возможности передачи 2 векторов в рамках одной операции мы создадим структуру.
struct STarget { vector<float> rewards; vector<float> actions; };
Таким образом, метод GetTargets получает в параметрах:
- перцентиль для определения количества ближайших анализируемых состояний из обучающей выборки;
- эмбединг анализируемого состояния;
- матрицу эмбедингов состояний в обучающей выборке;
- матрицу вознаграждений из обучающей выборки;
- матрицу действий Агента из обучающей выборки.
Последние 3 матрицы корреспондируются между собой.
По результатам работы метод возвращает структуру их 2 целевых векторов.
STarget GetTargets(int percentile, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards, matrix<float> &actions ) { STarget result;
В теле метода мы объявляем структуру результатов и сразу проверяем соответствие размеров эмбедингов анализируемого состояния и в матрице состояний из обучающей выборки.
if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
Далее мы определим расстояние между анализируемым состоянием и состояниями из обучающей выборки. Для определения мягкого расстояния мы используем LogSumExp, предложенный авторами метода DWSL.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * percentile / 100); matrix<float> temp = matrix<float>::Zeros(states, size); for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha=temp.Max(); vector<float> dist = MathLog(MathExp(temp/(-alpha)).Sum(1))*(-alpha);
После чего мы создадим локальные матрицы вознаграждений, действий и эмбедеинга. В которые перенесем данные о наиболее близких состояниях.
vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_rewards = matrix<float>::Zeros(k, NRewards); matrix<float> k_actions = matrix<float>::Zeros(k, NActions); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S; float max = dist.Percentile(percentile); float min = dist.Min(); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_rewards.Row(rewards.Row(i), cur); k_actions.Row(actions.Row(i), cur); k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
Чтобы получить вектор целевого вознаграждения для обучения нам предстоит взвесить матрицу отобранных вознаграждений по расстоянию от анализируемого состояния. Но здесь следует обратить внимание, что минимальное расстояние даст нам минимальный вес соответствующего вознаграждения. Однако это противоречит общей логике: наиболее актуальное значение оказывает минимальное влияние на конечный результат. Но это легко исправить. Достаточно умножить вектор расстояний на "-1". А функция SoftMax переведет полученные значения в плоскость вероятностей. Теперь нам достаточно умножить полученный вектор вероятностей на собранную матрицу вознаграждений наиболее близких состояний.
vector<float> sf; (min_dist*(-1)).Activation(sf, AF_SOFTMAX); result.rewards = sf.MatMul(k_rewards);
Тут же мы добавить ядерные нормы для стимулирования Актера к исследованию.
k_embedding.SVD(U, V, S); result.rewards[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result.rewards[NRewards - 1] = EntropyLatentState(Actor);
Далее нам предстоит сформировать целевой вектор действий. На это раз мы будем взвешивать действия по их преимуществующему вознаграждению. Аналогично вектору расстояний мы рассчитаем вектор вознаграждений с использованием функции LogSumExp.
vector<float> act_sf; alpha=MathAbs(k_rewards).Max(); dist = MathLog(MathExp(k_rewards/(-alpha)).Sum(1))*(-alpha);
На это раз максимальное вознаграждение должно оказывать максимальное влияние и нам нет необходимости переворачивать значения. Достаточно просто перевести вознаграждения в область вероятностных значений с помощью функции SoftMax. После чего, полученный вектор умножаем на матрицу действий. Полученный результат записываем в структуру. И возвращаем оба вектора целевых значений вызывающей программе.
На этом мы завершаем подготовительную работу и переходим к реализации основного алгоритма.
2.3 Советник сбора данных для обучения
Следующим этапом мы переходим к программе сбора данных для офлайн обучения моделей. Как и ранее, данная задача будет реализована в советнике "...\DWSL\Research.mq5". Мы не будем полностью рассматривать весь код данного советника. Большинство его методов кочуют без изменений из одной статье в следующую. И были уже не раз рассмотрены в предыдущих статьях. Остановимся лишь на ключевых особенностях. И первым мы рассмотри метод обработки тиков OnTick, в теле которого реализован основной алгоритм.
В начале метода мы проверяем наступление события открытия нового бара и, при необходимости, загружаем исторические данные ценового движения и показателей анализируемых индикаторов.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Из полученных данных формируем буфер исходных данных.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
И буфер состояния счета.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance)); double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Собранные данные передаем в модель Актера и вызываем метод прямого прохода. При этом не забываем контролировать процесс выполнения операций.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
В результате прямого прохода модель Актера генерирует вектор действий, который мы дешифруем. Здесь мы лишь убираем объем встречных операций, который не генерирует профит. В отличии от других ранее рассмотренных работ мы не добавляем шум к полученному вектору для исследования окружающей среды. Стохастическая политика Актера совместно со стохастичностью латентного состояния уже генерируют достаточный разброс действий для исследования ближайшего окружения пространства действий.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Далее мы сверяем существующую позицию с прогнозом Актера и, при необходимости, совершаем торговые операции. Сначала для длинных позиций.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
А затем повторяем операции для коротких позиций.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
В завершении операций метода нам остается лишь собрать обратную связь от окружающей среды и передать данные в буфер воспроизведения опыта.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove(); }
На этом процесс сбора данных можно считать реализованным. Но работу над данным советником нельзя считать завершенной. В рамках реализации метода DWSL хочется обратить внимание на одну деталь. В теоретической части данной статьи мы уже говорили, что метод DWSL сходится к оптимальной политике с минимальной границей доходности на уровне траекторий из обучающей выборки. И конечно, в поиске оптимальной траектории нам бы хотелось как можно выше поднять планку минимальной границы доходности. С этой целью мы внесем изменения в процесс добавления новых траекторий в буфер воспроизведения опыта. После первичного заполнения буфера мы будем постепенно заменять проходы с минимальной доходностью на более прибыльные. Данный процесс реализован в методе OnTesterPass, в котором обрабатывается событие завершения прохода в тестере стратегий.
В теле метода мы сначала инициализируем локальные переменные. И сразу создаем цикл опроса фреймов проходов.
void OnTesterPass() { //--- ulong pass; string name; long id; double value; STrajectory array[]; while(FrameNext(pass, name, id, value, array)) {
В теле цикла мы проверяем соответствие фрейма текущей программе.
int total = ArraySize(Buffer); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue;
После чего идет разветвление процесса в зависимости от заполненности буфера воспроизведения опыта. Если буфер уже заполнен до максимального заданного размера, то мы осуществляем в буфере поиск прохода с минимальной доходностью. Это может быть максимальный убыток или минимальная прибыль.
if(total >= MaxReplayBuffer) { for(int a = 0; a < id; a++) { float min = FLT_MAX; int min_tr = 0; for(int i = 0; i < total; i++) { float prof = Buffer[i].States[Buffer[i].Total - 1].account[1]; if(prof < min) { min = MathMin(prof, min); min_tr = i; } }
Далее мы сравниваем полученное значение с доходностью последнего прохода. И если она выше, то мы просто записываем данные нового прохода вместо найденного минимального. В противном случае переходи к следующему проходу.
float prof = array[a].States[array[a].Total - 1].account[1]; if(min <= prof) { Buffer[min_tr] = array[a]; PrintFormat("Replace %.2f to %.2f -> bars %d", min, prof, array[a].Total); } } }
В случае же, когда буфер еще не заполнен мы просто добавляем новый проход без излишних контрольных операций.
else { if(ArrayResize(Buffer, total + (int)id, 10) < 0) return; ArrayCopy(Buffer, array, total, 0, (int)id); } } }
Мы эксплуатируем следующий приоритет операций:
- Максимальное заполнение буфера воспроизведения опыта для предоставления обучаемым моделям наиболее полной информации об окружающей среде.
- После заполнения буфера воспроизведения опыта отбор наиболее прибыльных проходов для построения оптимальной стратегии.
А полный кодом советника и всех его методов представлен во вложении. Там же вы сможете нейти и код советника тестирования моделей "...\DWSL\Test.mq5". Он имеет аналогичный алгоритм метода обработки тиков, но предназначен для одиночного прогона в тестере стратегий. И мы опустим его рассмотрение в рамках данной статьи.
2.4 Советник обучения моделей
Процесс обучения моделей организован в советнике "...\DWSL\Study.mq5". Мы также не будем останавливаться на детальном рассмотрении всех его методов. Разберем лишь метод Train, в котором организован основной алгоритм обучения моделей.
В теле метода мы определяем размер буфера воспроизведения опыта и сохраняем в локальную переменную состояния счетчика тиков для отслеживания времени, затраченного на операции.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Далее мы в цикле осуществляем проход по всем траекториям для подсчета общего количества состояний в буфере воспроизведения опыта. Что даст нам возможность подготовить матрицы достаточных размеров для записи эмбедингов состояний, а также соответствующих вознаграждений и действий Агента. Использование указанных матриц мы уже встречали в методе GetTargets.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
Следующим этапом мы приступаем к заполнению данных матриц. Для этого организовываем систему циклов с полным перебором всех состояний из буфера воспроизведения опыта. В теле данной системы циклов мы собираем описание каждого отдельного состояния в единый буфер данных.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
И прямым проходом кодировщика генерируем его эмбединг.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp);
Полученный вектор сохраняем в матрице эмбединга состояний state_embedding.
if(!state_embedding.Row(temp, state)) continue;
А в матрицах вознаграждений (rewards) и действий Агента (actions) сохраним соответствующие данные из буфера воспроизведения опыта.
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue;
Обратите внимание, что в матрицу вознаграждений мы добавляем лишь Преимущества за переход в следующее состояние. Кроме того, при возникновении какой-либо ошибки мы не завершаем полностью работу программы. а только переходим к следующему состоянию. Таким образом мы не завершаем весь процесс обучения, а лишь немного уменьшаем базу для сравнения.
Затем мы увеличиваем счетчик сохраненных эмбедингов. И перед переходом к следующей итерации нашей системы циклов мы информируем пользователя о ходе процесса кодирования состояний.
state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
После завершения процесса кодирования мы уменьшаем наши матрицы до фактического количества заполненных данных.
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
}
Следующим этапом мы подготовим локальные переменные и организуем приоритезацию траекторий. Сам процесс расчета вероятностей выбора траекторий вынесен в отдельный метод GetProbTrajectories, алгоритм которого был представлен в предыдущей статье.
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
На этом мы завершаем этап подготовки данных и переходим к алгоритму непосредственного обучения моделей, который организован так же организован в цикле. Количество итераций цикла обучения моделей указывается во внешних параметрах советника.
В теле цикла мы сначала сэмплируем траекторию с учетом рассчитанных выше вероятностей. Процесс вынесен в метод SampleTrajectory, алгоритм которого так же был представлен в предыдущей статье. А затем сэмплируем состояние на выбранной траектории.
vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Далее я организовал разветвления процесс в зависимости от прошедших итераций обучения. Я исключаю оценку последующего состояния целевыми моделями на начальном этапе, так как оценка состояниями необученными моделями абсолютно случайна и может направить процесс обучения в ложном направлении. В свою очередь, оценка последующего состояния моделями с достаточным уровнем точности позволит нам оценить ожидаемую в будущем доходность от используемой на данном шаге политики. И тем самым приоритезировать действия с учетом последующих выгод.
В этом блоке мы заполняем буфер исходных данных описанием последующего состояния окружающей среды.
State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
И генерируем действия Агента с учетом обновленной политики.
if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
После чего оцениваем полученное действие 2 моделями целевых Критиков.
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Для расчета ожидаемого вознаграждения мы используем минимальную оценку.
TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward[NRewards - 1] = EntropyLatentState(Actor); target_reward *= DiscFactor; }
На следующем этапе мы переходим к процессу обучения моделей Критиков. Обучение данных моделей осуществляется на состояниях и действиях из буфера воспроизведения опыта.
Вначале мы копируем описания текущего состояния окружающей среды в буфер исходных данных.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
А затем формируем буфер описания состояния счета.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Собранные данные позволяют нам осуществить прямой проход Актера.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Обратите внимание, что перед обучением Критиков мы осуществляем прямой проход Актера. Хотя в процессе обучения мы будем использовать действия из буфера воспроизведения опыта. Это связано с использованием латентного состояния Актера в качестве исходных данных Критиков.
Далее мы заполняем буфер действий из обучающей базы данных и вызываем методы прямого прохода наших Критиков.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
А вот в качестве целевых значений для обучения моделей мы будем использовать взвешенные вознаграждения. Для их получения мы сначала добавим в буфер текущего состояния окружающей среды описание состояния счета и сгенерируем эмбединг анализируемого состояния.
if(!State.AddArray(GetPointer(Account)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
Имеющегося на данном этапе набора данных нам достаточно для вызова выше рассмотренного метода GetTargets, который вернет нам вектора взвешенных вознаграждений и действий.
target = GetTargets(Percent, temp, state_embedding, rewards, actions);
При наличии целевых данных мы можем провести обратный проход моделей Критиков, но предварительно скорректируем градиент ошибки с помощью метода CAGrad.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Следующим этапом мы обновляем мы обновляем политику Актера. Прямой проход модели мы уже осуществили ранее. Взвешенный вектор целевых действий мы также уже получили. Следовательно, у нас есть все необходимые данные для осуществления обратного прохода в режиме обучения с учителем.
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Как можно заметить, при формировании вектора целевых действий Актера мы использовали Преимущества действий, извлеченные непосредственно из буфера воспроизведения опыта. Следовательно, обученные модели Критиков не использовались. Здесь надо понимать, что вне зависимости от используемой политики Актера, его влияние на движение рынка минимально. И переоценка Преимущества с помощью аппроксимированного Критика может только исказить данные на ошибку моделирования. И в такой парадигме обучение моделей Критика может показаться излишними операциями. Но все же мы хотим учитывать влияние изученной политик на ожидаемую в будущем доходность. С этой целью мы выбираем Критика, который в результате обучения демонстрирует минимальную ошибку, и оцениваем им действия Актера, сгенерированные новой политикой. Градиент отклонения полученной оценки от взвешенной мы передаем Актеру для оптимизации параметров.
CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
Стоит отметить, что указанные операции выполняются только при достаточной уверенности в адекватности оценки действий Критиком. Для регулирования этого процесса мы ввели дополнительный внешний параметр MaxErrorActorStudy, который определяет максимальную погрешность оценки Критиком для включения указанного процесса.
После завершения процесса обучения моделей мы скопируем параметры обученных моделей Критиков в целевые модели. Здесь также надо отметить, что на начальном этапе до включения процесса оценки последующих состояний мы полностью переносим параметры обучаемых моделей в целевые. А при использовании механизма оценки последующих состояний включается мягкое копирование параметров.
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
На этом завершаются операции одной итерации обучения моделей. И нам остается проинформировать пользователя о ходе процесса обучения моделей и перейти к следующей итерации.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После выполнения всех итераций цикла обучения моделей мы очищаем поле комментариев на графике инструмента. Информируем пользователя о результатах обучения и инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем практическую часть нашей статьи. А с полным кодом всех программ, используемых в данной работе, вы можете ознакомиться во вложении. А мы переходим к тестированию проделанной работы.
3. Тестирование
Выше была проведена объемная работа по реализацию нашего видения метода DWSL средствами MQL5. Должен признаться, что у нас получился некий конгломерат из целого ряда ранее рассмотренных методов. Что является довольно большим экспериментом. А эффективность нашего решения можно проверить на исторических данных. К чему мы и приступаем.
Как всегда, для обучения моделей использовались исторические данные за первые 7 месяцем 2023 года инструмента EURUSD тайм-фрейм H1. Сбор данных для обучения моделей осуществлялся в тестере стратегий MetaTrader 5 в режиме полной оптимизации параметров. На первом этапе мы собираем 500 случайных траекторий. Благодаря нашей оптимизации алгоритма метода OnTesterPass мы можем прогнать немного больше проходов. А в буфер воспроизведения опыта будут отобраны наиболее прибыльные.
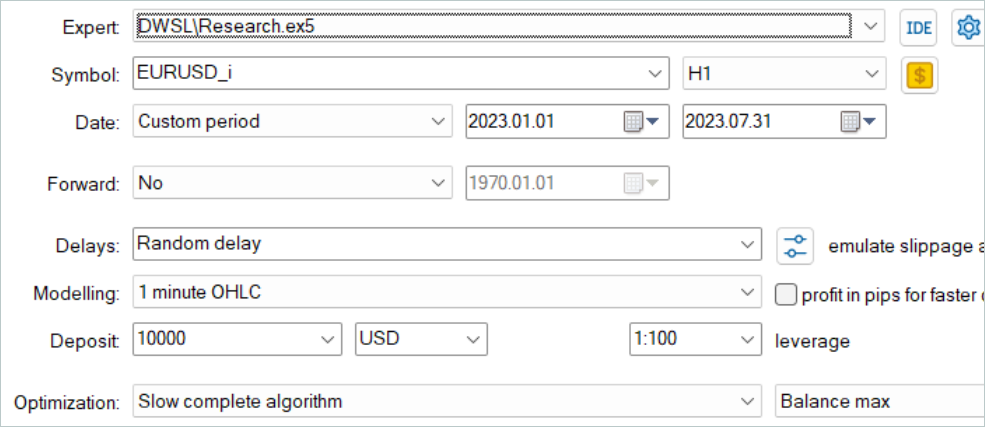
Здесь сразу надо сказать, что не следует стремиться получить прибыльные проходы случайных политик. На данном этапе это довольно случайный процесс. И как мы уже видели ранее, вероятность получения полностью прибыльного прохода случайной политикой на всем интервале близка к "0". К нашему счастью, метод DWSL способен работать с исходными данными любого качества.
После сбора базы обучающих данных мы осуществляем первый запуск нашего советника обучения моделей.
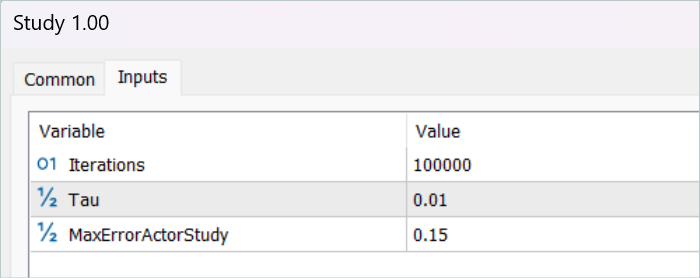
Должен сказать, что на данном этапе я не получил полностью прибыльную стратегию. И во многом это связано с низкой доходностью проходов из обучающей выборке. Но надо отметить, что повторный запуск советника взаимодействия с окружающей средой уже после первого цикла обучения дал траектории с заметно большей доходностью. Даже появился один, возможно случайный, проход с прибылью за весь период обучения. Что в целом демонстрирует результативность метода и надежу на достижения лучших результатов.
И после нескольких итераций сбора траекторий и обучения мне удалось получить модель, способную устойчиво генерировать прибыль. Полученная модель была протестирована на исторических данных Августа 2023 года, которые не входили в обучающую выборку. Но так как они следовали непосредственно за обучающем периоде позволяет нам сделать предположение о сопоставимости данных.


По результатам тестирования модель смогла получить прибыль, достигнув профит фактор на уровне 1.3. График баланса демонстрирует довольно стремительный рост в первой половине месяца. И далее мы наблюдаем его колебания в довольно узком диапазоне. К положительным результатам тестирования можно отнести:
- более 50% прибыльных позиций
- максимальная прибыльная сделка почти в 4 раза превышает максимальный убыток, а средняя прибыльная сделка почти на четверть превышает средний убыток
- наличие сделок в обоих направлениях (60% коротких и 40% длинных). При этом почти 55% коротких и 46% длинных позиций было закрыто с прибылью
- максимальная прибыльная серия превышает максимальную убыточную как по количеству сделок, так и по сумме.
Полученные результаты в целом создают положительное впечатление.
Заключение
В данной статье мы познакомились с ещё одним интересным методом обучения моделей Distance Weighted Supervised Learning. Благодаря использованию подхода взвешенной оценки имеющихся данных он позволяет в офлайн режиме оптимизировать собранные не оптимальные траектории и обучать довольно интересные политики. Которые в последующем демонстрируют не плохие результаты.
Эффективность рассмотренного метода подтверждается нашими практическими результатами. В процессе обучения была получена политика, способная обобщать изученный материал на новые данные. И, как следствие, прибыльный график баланса во время тестирования.
Однако, еще раз хочу напомнить, что все программы, представленные в статье, предназначены только для демонстрации подходов и не оптимизированы для использования в реальной торговле.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mq5 | Советник | Советник обучения агента |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования