
Neuronale Netze leicht gemacht (Teil 31): Evolutionäre Algorithmen

Inhalt
- Einführung
- 1. Grundlegende Prinzipien der Algorithmenkonstruktion
- 2. Implementierung mit MQL5
- 3. Tests
- Schlussfolgerung
- Referenzen
- Programme, die im diesem Artikel verwendet werden
Einführung
Wir untersuchen weiterhin Nicht-Gradienten-Methoden zur Optimierung von Modellen. Der Hauptvorteil dieser Optimierungsmethoden ist die Möglichkeit, Modelle zu optimieren, die mit Gradientenmethoden nicht optimiert werden können. Dies sind die Aufgaben, bei denen es nicht möglich ist, die Ableitung der Modellfunktion zu bestimmen, oder deren Berechnung durch einige Faktoren erschwert wird. Im vorangegangenen Artikel haben wir uns mit dem genetischen Optimierungsalgorithmus vertraut gemacht. Das Ideal dieses Algorithmus ist den Naturwissenschaften entlehnt. Jedes Modellgewicht wird durch ein eigenes Gen im Genom des Modells repräsentiert. Der Optimierungsprozess evaluiert eine bestimmte Population von Modellen, die nach dem Zufallsprinzip initialisiert werden. Die Population hat eine endliche „Lebensdauer“. Am Ende der Epoche wählt der Algorithmus die „besten“ Vertreter der Population aus, aus denen die „Nachkommen“ für die nächste Epoche hervorgehen. Für jedes Individuum (Modell in der neuen Population) wird nach dem Zufallsprinzip ein „Elternpaar“ ausgewählt. Auch die „Elterngene“ werden zufällig vererbt.
1. Grundlegende Prinzipien der Algorithmenkonstruktion
Wie Sie sehen können, gibt es in dem zuvor betrachteten genetischen Optimierungsalgorithmus eine Menge Zufälligkeiten. Wir wählen gezielt die besten Vertreter aus jeder Population aus, während der größte Teil der Population eliminiert wird. Während der vollständigen Iteration der gesamten Population in jeder Epoche führen wir also eine Menge „nutzloser“ Arbeit aus. Darüber hinaus hängt die Entwicklung der Modellpopulation von Epoche zu Epoche in die von uns gewünschte Richtung weitgehend vom Faktor Zufall ab. Nichts garantiert eine zielgerichtete Bewegung zum Ziel.
Erinnern wir uns an die Methode des Gradientenabstiegs, so haben wir uns bei jeder Iteration zielgerichtet in Richtung des Anti-Gradienten bewegt. Auf diese Weise haben wir den Modellfehler minimiert. Und das Modell bewegte sich in die gewünschte Richtung. Um die Methode des Gradientenabstiegs anwenden zu können, müssen wir natürlich die Ableitung der Funktion bei jeder Iteration analytisch bestimmen.
Was ist, wenn wir eine solche Möglichkeit nicht haben? Können wir diese beiden Ansätze irgendwie kombinieren?
Erinnern wir uns zunächst an die geometrische Bedeutung der Ableitung einer Funktion. Die Ableitung einer Funktion charakterisiert die Änderungsrate des Funktionswertes an einem bestimmten Punkt. Sie ist definiert als der Grenzwert des Verhältnisses zwischen der Änderung des Funktionswerts und der Änderung seines Arguments, wenn die Änderung des Arguments gegen 0 tendiert. Vorausgesetzt, es gibt eine solche Grenze.
Dies bedeutet, dass wir neben der analytischen Ableitung auch deren Näherung experimentell ermitteln können. Um die Ableitung einer Funktion nach einem Argument x experimentell zu bestimmen, müssen wir den Wert des Parameters x unter sonst gleichen Bedingungen leicht verändern und den Wert der Funktion berechnen. Das Verhältnis zwischen der Änderung des Funktionswerts und der Änderung des Arguments ergibt den ungefähren Wert der Ableitung.
Da es sich bei unseren Modellen um nichtlineare Modelle handelt, empfiehlt es sich, die folgenden zwei Operationen für jedes Argument durchzuführen, um eine bessere Definition der Ableitung auf experimentellem Wege zu erhalten. Im ersten Fall addieren wir einen Wert und im zweiten Fall subtrahieren wir denselben Wert. Der Mittelwert aus zwei Operationen ergibt eine genauere Annäherung an den Wert der Funktionsableitung in Bezug auf das analysierte Argument an einem bestimmten Punkt.
Dieser Ansatz wird häufig verwendet, wenn es darum geht, die Korrektheit der Ergebnisse eines abgeleiteten Modells zu bewerten. Auch evolutionäre Algorithmen machen sich diese Eigenschaft zunutze. Der Grundgedanke der evolutionären Optimierungsstrategien besteht darin, experimentell ermittelte Gradienten zu verwenden, um die Richtung für die Optimierung der Modellparameter zu bestimmen.
Das Hauptproblem bei der Verwendung experimenteller Gradienten ist jedoch die Notwendigkeit, eine große Anzahl von Operationen durchzuführen. Um zum Beispiel den Einfluss eines Parameters auf das Modellergebnis zu bestimmen, müssen wir 3 Vorwärtsdurchläufe für das Modell mit denselben Quelldaten durchführen. Dementsprechend wird bei allen Modellparametern die Zahl der Iterationen um das Dreifache erhöht.
Das ist nicht gut, also müssen wir etwas dagegen tun.
Wir können zum Beispiel nicht nur einen, sondern zwei Parameter ändern. Aber wie kann man in diesem Fall den Einfluss jedes einzelnen von ihnen bestimmen, wie man die ausgewählten Parameter ändert - synchron oder nicht? Was ist, wenn der Einfluss der gewählten Parameter auf das Ergebnis nicht gleich ist und sie mit unterschiedlicher Intensität verändert werden sollen?
Nun, wir könnten sagen, dass die Prozesse, die innerhalb des Modells ablaufen, für uns nicht wichtig sind. Wir brauchen ein Modell, das unseren Anforderungen entspricht. Das mag nicht optimal sein. Das Konzept der Optimalität ist jedenfalls die größtmögliche Erfüllung aller gestellten Anforderungen.
In diesem Fall können wir das Modell und den Satz seiner Parameter als ein Ganzes betrachten. Wir können einen Algorithmus verwenden und alle Parameter des Modells auf einmal ändern. Der Algorithmus für die Änderung der Parameter kann beliebig sein, zum Beispiel eine Zufallsverteilung.
Wir werden die Auswirkungen der Änderungen auf die einzige verfügbare Art und Weise bewerten — indem wir das Modell an der Trainingsstichprobe testen. Wenn der neue Satz von Parametern das vorherige Ergebnis verbessert hat, akzeptieren wir ihn. Wenn das Ergebnis schlechter geworden ist, verwerfen wir es und kehren zum vorherigen Parametersatz zurück. Wieder und wieder wiederholen wir die Schleife für neue Parameter.
Sieht das nicht nach einem genetischen Algorithmus aus? Aber wo bleibt die oben erwähnte Schätzung des experimentellen Gradienten?
Nähern wir uns dem genetischen Algorithmus. Wir werden wieder die gesamte Population von Modellen verwenden, deren Wirksamkeit anhand einer begrenzten Trainingsmenge getestet wird. Im Gegensatz zum genetischen Algorithmus, bei dem jedes Modell eine Art Individuum ist, das nach dem Zufallsprinzip erstellt wird, verwenden wir in diesem Fall für alle Werte die Parameter, die in der Nähe der Werte liegen. Wir nehmen ein Modell und fügen seinen Parametern ein zufälliges Rauschen hinzu. Die Verwendung von Zufallsrauschen führt zu einer Population, in der es kein einziges identisches Modell geben wird. Eine geringe Menge an Rauschen ermöglicht es uns, die Ergebnisse aller Modelle im gleichen Unterraum mit einer geringen Abweichung zu erhalten. Dies bedeutet, dass die Ergebnisse der Modelle vergleichbar sein werden.
![]()
wobei w' die Parameter des Modells in der Population sind
w sind Parameter des Quellenmodells
ɛ ist ein zufälliges Rauschen.
Um die Effizienz der einzelnen Modelle aus der Population zu bewerten, können wir eine Verlustfunktion oder ein Belohnungssystem verwenden. Die Wahl hängt weitgehend von dem Problem ab, das zu lösen ist. Außerdem berücksichtigen wir die Optimierungspolitik. Wir minimieren die Verlustfunktion und maximieren die Gesamtbelohnung. Im praktischen Teil dieses Artikels werden wir die Gesamtbelohnung maximieren, ähnlich dem Prozess, den wir bei der Lösung des Problems des verstärkten Lernens implementiert haben.
Nachdem wir die Leistung der neuen Population anhand der Trainingsstichprobe getestet haben, müssen wir bestimmen, wie die Parameter des ursprünglichen Modells optimiert werden können. Wenn wir die Mathematik anwenden, können wir versuchen, den Einfluss der einzelnen Parameter auf das Ergebnis irgendwie zu bestimmen. Dabei werden wir eine Reihe von Annahmen zugrunde legen. Aber wir haben uns vorhin darauf geeinigt, das Modell als Ganzes zu betrachten. Das bedeutet, dass die gesamte Menge des Rauschens, die in jedes einzelne Populationsmodell eingefügt wird, durch die Gesamtbelohnung geschätzt werden kann, die beim Testen der Wirksamkeit des Modells auf der Trainingsmenge erhalten wird. Daher addieren wir zu den Parametern des ursprünglichen Modells den gewichteten Durchschnitt des entsprechenden Parameterrauschens aus allen Modellen der Grundgesamtheit. Das Rauschen wird mit der Gesamtbelohnung gewichtet. Und natürlich wird der resultierende gewichtete Durchschnitt mit dem Lernkoeffizienten des Modells multipliziert. Die Formel für die Aktualisierung der Parameter ist unten dargestellt. Wie Sie sehen können, ist diese Formel der Formel für die Aktualisierung der Gewichte bei der Verwendung des Gradientenabstiegs sehr ähnlich.
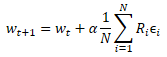
Dieser evolutionäre Optimierungsalgorithmus wurde vom OpenAI-Team im September 2017 in dem Artikel „Strategies as a Scalable Alternative to Reinforcement Learning“ vorgeschlagen. In diesem Artikel wird der vorgeschlagene Algorithmus als Alternative zu den zuvor untersuchten Q-Learning- und Policy-Gradient-Methoden besprochen. Der vorgeschlagene Algorithmus zeigt eine gute Durchführbarkeit und Produktivität. Es zeigt auch Toleranz für die Häufigkeit von Handlungen und verzögerte Belohnungen. Darüber hinaus ermöglicht die von den Autoren vorgeschlagene Methode zur Skalierung des Algorithmus eine Steigerung der Problemlösungsgeschwindigkeit in nahezu linearer Abhängigkeit, indem zusätzliche Rechenressourcen genutzt werden. So gelang es ihnen beispielsweise, mit mehr als tausend Parallelrechnern ein dreidimensionales Gehproblem eines Humanoiden in nur 10 Minuten zu lösen. Aber wir werden das Problem der Skalierung in unserem Artikel nicht berücksichtigen.
2. Implementierung mittels MQL5
Wir haben uns mit den theoretischen Aspekten der Algorithmen befasst und kommen nun zum praktischen Teil, in dem wir die Implementierung des vorgeschlagenen Algorithmus mit MQL5 betrachten. Bitte beachten Sie, dass der Algorithmus, den wir implementieren werden, nicht 100%ig original ist. Es wird einige Änderungen geben, obwohl das gesamte Konzept des Algorithmus beibehalten wird. Die Autoren schlugen insbesondere vor, einen „gierigen“ (greedy) Algorithmus für die Auswahl einer Aktion zu verwenden. Wir werden jedoch einen probabilistischen Algorithmus verwenden, wenn wir eine Aktion auswählen. Außerdem haben wir, ähnlich wie beim genetischen Algorithmus, Mutationsparameter hinzugefügt. Der ursprüngliche Algorithmus verwendete keine Mutation.
Um den Algorithmus zu implementieren, erstellen wir eine neue neuronale Netzwerkklasse CNetEvolution, die wir von dem Modell des genetischen Algorithmus ableiten. Die Ableitung geschieht privat. Daher müssen wir alle verwendeten Methoden außer Kraft setzen. Auf den ersten Blick wäre es bei der öffentlichen Ableitung nicht nötig, einige Methoden neu zu definieren, die wir einfach auf Methoden der Elternklasse umleiten werden. Aber eine nicht-öffentliche Ableitung blockiert den Zugriff auf nicht verwendete Methoden. Dies ist vor allem beim Überladen von Methoden nützlich. Der Nutzer wird die überladenen Methoden der übergeordneten Klassen nicht sehen, sodass wir unnötige Verwirrung vermeiden.
class CNetEvolution : protected CNetGenetic { protected: virtual bool GetWeights(uint layer) override; public: CNetEvolution() {}; ~CNetEvolution() {}; //--- virtual bool Create(CArrayObj *Description, uint population_size) override; virtual bool SetPopulationSize(uint size) override; virtual bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) override; virtual bool Rewards(CArrayFloat *rewards) override; virtual bool NextGeneration(float mutation, float &average, float &mamximum); virtual bool Load(string file_name, uint population_size, bool common = true) override; virtual bool Save(string file_name, bool common = true); //--- virtual bool GetLayerOutput(uint layer, CBufferFloat *&result) override; virtual void getResults(CBufferFloat *&resultVals); };
Wir deklarieren keine neuen Instanzen der Klasse im Körper der neuen Klasse. Außerdem deklarieren wir keine internen Variablen. Wir werden nur Objekte und Variablen von übergeordneten Klassen verwenden. Daher bleiben sowohl der Konstruktor als auch der Destruktor der Klasse leer.
Bitte beachten Sie, dass wir vor dem Hinzufügen des Rauschens keine Objekte zur Speicherung der Gewichte des ursprünglichen Modells erstellen. Auch dies ist eine Abweichung vom ursprünglichen Algorithmus. Wir werden jedoch bei der Implementierung des Algorithmus auf dieses Problem zurückkommen.
Als Nächstes folgt die Methode Create, mit der eine Population von Modellen erstellt wird. Die Methode erhält als Parameter ein dynamisches Array mit der Beschreibung eines Modells und der Populationsgröße, ähnlich wie bei den Methoden der Elternklasse. Die Hauptfunktionalität wird mit Methoden der übergeordneten Klasse implementiert. Hier müssen wir nur die Klasse aufrufen und die erhaltenen Parameter übergeben.
Da in der Methode der Klasse CNetGenetic::Create der genetischen Algorithmus implementiert ist, haben wir eine Population von Modellen mit einer Architektur und zufälligen Gewichten erstellt. Jetzt müssen wir eine ähnliche Population schaffen. Aber die Parameter unserer Modelle sollten nahe beieinander liegen. Um sie einander anzunähern, rufen wir die Methode NextGeneration auf, die wir etwas später besprechen werden.
Vergessen wir nicht, die Ergebnisse der Ausführung der Operation zu überprüfen. Am Ende der Methode geben wir das logische Ergebnis der Operationen zurück.
bool CNetEvolution::Create(CArrayObj *Description, uint population_size) { if(!CNetGenetic::Create(Description, population_size)) return false; float average, maximum; return NextGeneration(0,average, maximum); }
Ich habe bereits die Methode NextGeneration erwähnt. Werfen wir einen Blick auf ihren Algorithmus. Die Funktionsweise dieser Methode ist ähnlich wie die der gleichnamigen Methode der Elternklasse. Die Anforderungen an den Algorithmus sind jedoch mit einigen Besonderheiten verbunden.
In den Parametern erhält die Methode die Mutationswahrscheinlichkeit und zwei Variablen, in die wir die durchschnittliche und die maximale Belohnung schreiben werden.
Wir speichern im Methodenrumpf die erforderlichen Belohnungswerte und begrenzen den Höchstwert der Mutation. Wir begrenzen die maximale Mutationsgrenze, weil wir ein trainiertes Modell erhalten müssen. Wenn die Mutationswerte hoch sind, werden bei jeder Iteration zufällige Modellparameter erzeugt, unabhängig von den erzielten Ergebnissen. Infolgedessen wird die Population ständig aus zufälligen, untrainierten Modellen bestehen.
bool CNetEvolution::NextGeneration(float mutation, float &average, float &maximum) { maximum = v_Rewards.Max(); average = v_Rewards.Mean(); mutation = MathMin(mutation, MaxMutation);
Als Nächstes wollen wir die Grundlage für die Aktualisierung der Modellgewichte schaffen. Wie im theoretischen Teil dieses Artikels erörtert, ist ein Maß für die Gewichtung der Rauschgröße bei der Aktualisierung von Parametern die Gesamtbelohnung eines einzelnen Modells in der Trainingsmenge. Je nach Belohnungspolitik kann die Gesamtbelohnung jedoch entweder positiv oder negativ ausfallen. Mit hoher Wahrscheinlichkeit wird es zu einer Situation kommen, in der die Gesamtbelohnungen aller Mitglieder der Population das gleiche Vorzeichen haben. D.h. sie werden alle entweder positiv oder negativ sein.
Nicht alle Einflüsse des Rauschens zu den Modellparametern haben eine positive oder negative Wirkung. In diesem Fall wird der positive Einfluss einiger Komponenten durch den negativen Einfluss anderer überdeckt. Im besten Fall verlangsamt er unseren Fortschritt in die richtige Richtung. Im schlimmsten Fall kann dies dazu führen, dass das Modell in die entgegengesetzte Richtung trainiert wird. Um den Einfluss dieses Effekts zu minimieren, schreiben wir die Differenz zwischen der Gesamtbelohnung eines bestimmten Modells und der durchschnittlichen Gesamtbelohnung der gesamten Population in den v_Probability-Vektor der Wahrscheinlichkeiten.
Dieser Schritt ist mit der Annahme verbunden, dass das hinzugefügte Rauschen normalverteilt ist. Das bedeutet, dass die Gesamtbelohnung des ursprünglichen Modells ungefähr in der Mitte der Gesamtverteilung der Gesamtbelohnungen der Bevölkerung liegt. Sobald die Differenz berechnet ist, erhalten die Modelle, deren Gesamtbelohnung unter dem Durchschnittswert liegt, eine negative Wahrscheinlichkeit. Je kleiner die Gesamtbelohnung des Modells ist, desto negativer ist seine Wahrscheinlichkeit. Ebenso erhalten die Modelle mit der höchsten Gesamtbelohnung auch die höchste positive Wahrscheinlichkeit. Was ist der praktische Nutzen davon? Wenn das hinzugefügte Rauschen eine positive Wirkung hat, verschiebt sich das Gewicht durch Multiplikation mit einer positiven Wahrscheinlichkeit in die gleiche Richtung. So fördern wir die Modellbildung in die gewünschte Richtung. Wenn das hinzugefügte Rauschen eine negative Auswirkung hat, dann ändern wir durch die Multiplikation mit einer negativen Wahrscheinlichkeit die Richtung der Gewichtsverschiebung von negativ zu positiv. Dadurch wird auch das Modelltraining auf die Maximierung der Gesamtbelohnung ausgerichtet.
Anschließend werden die Modellparameter gemäß dem ursprünglichen Algorithmus anhand des gewichteten Durchschnitts des Rauschens korrigiert. Daher normalisieren wir auch den Vektor der erhaltenen Wahrscheinlichkeiten, damit die Summe der absoluten Werte aller Vektorelemente gleich 1 ist.
v_Probability = v_Rewards - v_Rewards.Mean(); float Sum = MathAbs(v_Probability).Sum(); if(Sum == 0) v_Probability[0] = 1; else v_Probability = v_Probability / Sum;
Nach der Bestimmung der Modellaktualisierungskoeffizienten, die wir in den Vektorv_Probability geschrieben haben, fahren wir mit der Schleifeniteration durch die Modellebenen fort. Die Parameter der neuen Population werden im Hauptteil dieser Schleife gebildet.
Im Schleifenkörper erhalten wir zunächst einen Zeiger auf ein dynamisches Array der aktuellen Ebenenobjekte. Wir überprüfen sofort die Gültigkeit des empfangenen Zeigers. Wir überprüfen auch die Größe des dynamischen Arrays. Sie muss der angegebenen Populationsgröße entsprechen. Wenn die Populationsgröße nicht ausreicht, rufen wir die Methode CreatePopulation auf, um zusätzliche Modelle zu erstellen. Hier verwenden wir die Methode der Elternklasse ohne Änderungen.
for(int l = 1; l < layers.Total(); l++) { CLayer *layer = layers.At(l); if(!layer) return false; if(layer.Total() < (int)i_PopulationSize) if(!CreatePopulation()) return false;
Danach rufen wir die Methode GetWeights auf, die die aktualisierten Parameter der aktuellen Ebene des Modells erstellt. Die Parameter werden in den Matrizen m_Weights und m_WeightsConv angelegt. Wir werden den Algorithmus der Methode später besprechen.
if(!GetWeights(l)) return false;
Nachdem wir die Modellparameter aktualisiert haben, können wir mit der Population beginnen. Zu diesem Zweck erstellen wir eine verschachtelte Schleife, deren Anzahl der Iterationen der Größe der Population entspricht.
Im Hauptteil der Schleife erhalten wir einen Zeiger auf das Objekt des aktuellen Neurons der zu analysierenden neuronalen Schicht. Wir überprüfen sofort die Gültigkeit des empfangenen Zeigers. Hier erhält man auch einen Zeiger auf das Gewichtsmatrixobjekt.
for(uint i = 0; i < i_PopulationSize; i++) { CNeuronBaseOCL* neuron = layer.At(i); if(!neuron) return false; CBufferFloat* weights = neuron.getWeights();
Wenn der empfangene Gewichtsmatrixzeiger gültig ist, beginnen wir mit der Arbeit mit dieser Matrix. Hier erstellen wir eine weitere verschachtelte Schleife, die über die Elemente der Gewichtsmatrix iteriert.
Im Schleifenkörper wird zunächst die Wahrscheinlichkeit der Verwendung einer Mutation geprüft und gegebenenfalls eine Zufallszahl erzeugt. Wenn die generierte Zufallszahl kleiner ist als die Mutationswahrscheinlichkeit, wird ein zufälliger Gewichtskoeffizient in das aktuelle Element der Matrix geschrieben. Danach wird mit der nächsten Iteration der Schleife fortgefahren. Ein ähnlicher Ansatz wurde für den genetischen Algorithmus verwendet.
if(!!weights) { for(int w = 0; w < weights.Total(); w++) { if(mutation > 0) { int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(mutation > random) { if(!weights.Update(w, GenerateWeight((uint)m_Weights.Cols()))) { Print("Error updating the weights"); return false; } continue; } }
Wenn das aktuelle Gewicht aktualisiert werden soll, wird zunächst sein aktueller Wert überprüft. Gegebenenfalls sollte eine ungültige Zahl durch ein Zufallsgewicht ersetzt werden.
if(!MathIsValidNumber(m_Weights[0, w])) { if(!weights.Update(w, GenerateWeight((uint)m_Weights.Cols()))) { Print("Error updating the weights"); return false; } continue; }
Am Ende der Iteration der verschachtelten Schleife wird das Rauschen zum aktuellen Gewicht addiert.
if(!weights.Update(w, m_Weights[0, w] + GenerateWeight((uint)m_Weights.Cols()))) { Print("Error updating the weights"); return false; } } weights.BufferWrite(); }
Nach dem Hinzufügen von Rauschen zu allen Elementen der Gewichtsmatrix des aktuellen Elements der Population werden die aktualisierten Parameter dem Kontextspeicher OpenCL übertragen.
Gegebenenfalls wiederholen wir die oben beschriebenen Iterationen für die Gewichtsmatrix der Faltungsschicht.
if(neuron.Type() != defNeuronConvOCL) continue; CNeuronConvOCL* temp = neuron; weights = temp.GetWeightsConv(); for(int w = 0; w < weights.Total(); w++) { if(mutation > 0) { int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(mutation > random) { if(!weights.Update(w, GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error updating the weights"); return false; } continue; } } if(!MathIsValidNumber(m_WeightsConv[0, w])) { if(!weights.Update(w, GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error updating the weights"); return false; } continue; } if(!weights.Update(w, m_WeightsConv[0, w] + GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error updating the weights"); return false; } } weights.BufferWrite(); } }
Die Iterationen werden für alle Elemente der Sequenz wiederholt.
Am Ende der Methode setzen wir den Gesamtbelohnungsakkumulationsvektor zurück und beenden die Methode.
v_Rewards.Fill(0); //--- return true; }
Entsprechend der Reihenfolge der Methoden besprechen wir nun die Methode GetWeights, die von der vorherigen Methode aufgerufen wurde. Sie dient dazu, die Parameter des zu optimierenden Modells zu aktualisieren. Die übergeordnete genetische Algorithmusklasse CNetGenetic verfügte über eine gleichnamige Methode, die zum Herunterladen der Parameter einer neuronalen Schicht aller Populationsmodelle verwendet wurde. Die sich daraus ergebende Matrix wurde dann zur Erstellung einer neuen Population verwendet. Diesmal verwenden wir die gleiche Logik, nur der Inhalt ändert sich leicht entsprechend dem verwendeten Optimierungsalgorithmus.
Die Methode erhält als Parameter den Index der neuronalen Schicht, für die eine Parametermatrix erstellt werden muss. Im Methodenrumpf überprüfen wir die Verfügbarkeit des gebildeten Vektors mit den Wahrscheinlichkeiten der Verwendung von Populationsrepräsentanten bei der Aktualisierung der Modellparameter. Aufruf der gleichnamigen Methode der übergeordneten Klasse. Vergessen wir nicht, die Ausführung von Vorgängen zu kontrollieren.
bool CNetEvolution::GetWeights(uint layer) { if(v_Probability.Sum() == 0) return false; if(!CNetGenetic::GetWeights(layer)) return false;
Sobald die Operationen der übergeordneten Klassenmethode abgeschlossen sind, erwarten wir, dass die Matrizen m_Weights und m_WeightsConv die Gewichte der analysierten neuronalen Schicht für alle Populationsmodelle enthalten.
Beachten Sie, dass die Matrizen Gewichte enthalten. Um die Modellparameter zu aktualisieren, benötigen wir jedoch die Werte des hinzugefügten Rauschens und die Parameter des ursprünglichen Modells.
Ähnlich verfahren wir bei der Anpassung von Belohnungen. Wir wissen, dass Rauschen normalverteilt ist. Jeder Parameter der Populationsmodelle ist die Summe aus dem entsprechenden Parameter des ursprünglichen Modells und dem Rauschen. Wir gehen davon aus, dass die Parameter des ursprünglichen Modells in der Mitte der Verteilung der entsprechenden Parameter der Populationsmodelle liegen. Wir können also den Vektor der Mittelwerte der entsprechenden Populationsparameter verwenden.
if(m_Weights.Cols() > 0) { vectorf mean = m_Weights.Mean(0);
Durch Subtraktion des Vektors der Mittelwerte von der Parametermatrix der Populationsmodelle lässt sich die erforderliche Matrix des hinzugefügten Rauschens ermitteln.
matrixf temp = matrixf::Zeros(1, m_Weights.Cols()); if(!temp.Row(mean, 0)) return false; temp = (matrixf::Ones(m_Weights.Rows(), 1)).MatMul(temp); m_Weights = m_Weights - temp;
Wenn wir den gleichen Ansatz verwenden, um das hinzugefügte Rauschen und die Wahrscheinlichkeiten seiner Verwendung bei der Aktualisierung der Modellgewichte zu bestimmen, erhalten wir vergleichbare Werte. Als Nächstes können wir die obige Formel zur Aktualisierung der Modellparameter verwenden. Danach müssen wir nur noch die erhaltenen Werte in die entsprechende Matrix übertragen.
mean = mean + m_Weights.Transpose().MatMul(v_Probability) * lr; if(!m_Weights.Resize(1, m_Weights.Cols())) return false; if(!m_Weights.Row(mean, 0)) return false; }
Gegebenenfalls wiederholen wir die Vorgänge für die zweite Matrix.
if(m_WeightsConv.Cols() > 0) { vectorf mean = m_WeightsConv.Mean(0); matrixf temp = matrixf::Zeros(1, m_WeightsConv.Cols()); if(!temp.Row(mean, 0)) return false; temp = (matrixf::Ones(m_WeightsConv.Rows(), 1)).MatMul(temp); m_WeightsConv = m_WeightsConv - temp; mean = mean + m_WeightsConv.Transpose().MatMul(v_Probability) * lr; if(!m_WeightsConv.Resize(1, m_WeightsConv.Cols())) return false; if(!m_WeightsConv.Row(mean, 0)) return false; } //--- return true; }
Der vollständige Code aller Methoden und Klassen ist in der Anlage unten zu finden.
Wir haben die Algorithmen der Methoden besprochen, die zur Implementierung des evolutionären Algorithmus modifiziert wurden. Um die Funktionsweise der Klasse zu vervollständigen, müssen wir noch Methoden außer Kraft setzen, um den Thread zu den entsprechenden Methoden der übergeordneten Klasse umzuleiten. Bitte beachten Sie, dass dies eine notwendige Maßnahme für die nicht-öffentliche Vererbung ist.
bool CNetEvolution::SetPopulationSize(uint size) { return CNetGenetic::SetPopulationSize(size); } bool CNetEvolution::feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNetGenetic::feedForward(inputVals, window, tem); } bool CNetEvolution::Rewards(CArrayFloat *rewards) { if(!CNetGenetic::Rewards(rewards)) return false; //--- v_Probability = v_Rewards - v_Rewards.Mean(); v_Probability = v_Probability / MathAbs(v_Probability).Sum(); //--- return true; } bool CNetEvolution::GetLayerOutput(uint layer, CBufferFloat *&result) { return CNet::GetLayerOutput(layer, result); } void CNetEvolution::getResults(CBufferFloat *&resultVals) { CNetGenetic::getResults(resultVals); }
Um die Klasse zu beenden, sollten wir die Methoden für die Arbeit mit Dateien überschreiben. Zunächst einmal müssen wir uns für eine Methode zur Speicherung des Modells entscheiden. Sie haben vielleicht bemerkt, dass wir das Modell nicht separat mit aktualisierten Parametern gespeichert haben. Wir haben nur die Parameter aktualisiert, um eine neue Population zu bilden. Aber um das trainierte Modell zu retten, müssen wir nur eines auswählen. Logischerweise sollte das Modell mit dem besten Ergebnis gespeichert werden. Wir haben die entsprechende Methode bereits in den Methoden der übergeordneten Klasse. Wir werden den Fluss der Operationen dorthin umlenken.
bool CNetEvolution::Save(string file_name, bool common = true) { return CNetGenetic::SaveModel(file_name, -1, common); }
Wir haben entschieden, wie wir das Modell retten wollen. Kommen wir nun zur Methode des Ladens des vortrainierten Modells. Die Situation ist ähnlich, aber es gibt einen kleinen Unterschied. Während des Trainingsprozesses speichern wir nicht die gesamte Population, sondern nur das Modell mit den besten Ergebnissen. Dementsprechend müssen wir nach dem Laden eines solchen Modells eine Population mit einer bestimmten Größe erstellen. Diese Möglichkeit ist in der Lademethode der Elternklasse implementiert. Diese Methode erzeugt jedoch eine Population von Modellen mit absolut zufälligen Parametern. Wir müssen jedoch eine Population eines Modells mit Rauschen erstellen. Daher rufen wir zunächst die Datenlademethode der übergeordneten Klasse model auf — sie wird die Funktionsweise und die Population in der erforderlichen Größe erstellen. Dann setzen wir den Vektor der Gesamtbelohnungen zurück und rufen die zuvor besprochenen Methode NextGeneration auf, die eine neue Population mit den erforderlichen Merkmalen erzeugt.
bool CNetEvolution::Load(string file_name, uint population_size, bool common = true) { if(!CNetGenetic::Load(file_name, population_size, common)) return false; v_Rewards.Fill(0); float average, maximum; if(!NextGeneration(0, average, maximum)) return false; //--- return true; }
Bitte beachten Sie einen Punkt, der noch nicht geklärt ist. Wie wird unsere neue Methode zur Erzeugung von Populationen das geladene Modell von den mit Zufallsgewichten gefüllten Modellen trennen? Die Lösung ist ganz einfach. In der Methode der Elternklasse wird das geladene Modell in die Grundgesamtheit mit dem Index „0“ eingefügt. Es werden Modelle mit Zufallsparametern hinzugefügt. Um die Wahrscheinlichkeit der Verwendung des zusätzlichen Rauschens zu bestimmen, verwenden wir den Vektor der Gesamtbelohnungen der Modelle. Diese Methode wurde zuvor zurückgesetzt, bevor die Methode zur Erzeugung einer neuen Population aufgerufen wurde. Daher erhalten wir im Körper der Methode NextGeneration bei der Bestimmung der Wahrscheinlichkeiten auch einen Vektor mit Nullwerten. Die Summe der Vektorwerte ist 0. In diesem Fall wird die 100%ige Wahrscheinlichkeit ermittelt, dass nur das Modell mit dem Index 0 (aus der Datei geladen) als Parametergrundlage für die neuen Populationsmodelle verwendet wird. Die Wahrscheinlichkeit der Verwendung der Parameter von Zufallsmodellen ist 0. Die neue Population wird also anhand des aus einer Datei hochgeladenen Modells erstellt.
bool CNetEvolution::NextGeneration(float mutation, float &average, float &maximum) { ............. ............. ............. v_Probability = v_Rewards - v_Rewards.Mean(); float Sum = MathAbs(v_Probability).Sum(); if(Sum == 0) v_Probability[0] = 1; else v_Probability = v_Probability / Sum; ............. ............. ............. }
Wir haben den Algorithmus für alle Methoden der neuen Klasse CNetEvolution besprochen. Jetzt können wir mit dem Modelltraining beginnen. Dies wird im nächsten Abschnitt dieses Artikels geschehen.
3. Tests
Um das Modell zu trainieren, habe ich den EA Evolution.mq5 erstellt, der auf dem EA basiert, den wir im vorherigen Artikel verwendet haben. Die EA-Parameter und Einstellungen haben sich nicht geändert. Durch einfaches Ändern der Objektklasse im Trainingsmodell des genetischen Algorithmus EA können wir mit Hilfe des evolutionären Algorithmus neue Modelle trainieren.
Ich werde ein wenig darauf eingehen, wie ein neues Modell erstellt wird. Wenn Sie sich erinnern, habe ich nach der Erstellung einer Transfer-Learning-Lösung in Teil 7 und 8 beschlossen, die Modellarchitektur nicht im EA-Code zu spezifizieren. Dies ermöglicht Experimente mit verschiedenen Modellen, ohne dass Änderungen am EA-Code vorgenommen werden müssen.
Um ein neues Modell zu erstellen, führen wir NetCreator aus, den wir zuvor erstellt haben. Wir verwenden die linke Seite des Tools nicht und laden keine vortrainierten Modelle, da wir ein völlig neues Modell erstellen.
Wir wissen, dass wir im Trainingsprozess 12 Beschreibungsparameter für jede Kerze in das Modell eingeben. Wir planen auch, historische Daten von 20 Kerzen zu analysieren. Dementsprechend wird die Größe der ersten Datenschicht 240 Neuronen (12 * 20) betragen. Als Eingabedatenschicht verwenden wir eine vollständig verbundene neuronale Schicht ohne Aktivierungsfunktion. Wir geben die Parameter der ersten Schicht im mittleren Teil des Werkzeugs an und drücken die Schaltfläche „ADD LAYER“ (Schicht hinzufügen). Als Ergebnis dieser Operation erscheint die Beschreibung der ersten neuronalen Schicht im rechten Block des Werkzeugs.

Als Nächstes folgt der Prozess der Erstellung der Modellarchitektur. Sie möchten zum Beispiel, dass das Modell die Muster von 3 nebeneinander liegenden Kerzen analysiert. Dazu fügen wir eine Faltungsschicht (convolutional layer) mit einer Analysefenstergröße von 36 Neuronen (12 * 3) hinzu und stellen den Verschiebungsschritt des Analysefensters auf 12 Neuronen ein, was der Anzahl der Elemente entspricht, die einen Kerzenständer beschreiben. Um dem Modell Handlungsspielraum zu geben, erstellen wir 12 Filter für die Musteranalyse. Als Aktivierungsfunktion habe ich eine hyperbolische Tangente verwendet, die eine logische Trennung von Auf- und Abwärtsmustern ermöglicht. Die Ausgabe der neuronalen Schicht wird innerhalb des Bereichs der Aktivierungsfunktion normalisiert.

Die erstellte Faltungsschicht liefert zunächst eine Sequenz aller Elemente eines Filters und dann eines anderen Filters. Dies kann mit einer Matrix verglichen werden, in der jede Zeile einem separaten Filter entspricht, während die Zeilenelemente die Ergebnisse der Filteroperationen für die gesamte Quelldatenfolge darstellen.
Als Nächstes müssen wir die Ergebnisse der Filter der zuvor erstellten Faltungsschicht analysieren. Wir werden eine Kaskade von 3 Faltungsschichten aufbauen, von denen jede die Ergebnisse der vorherigen Faltungsschicht analysiert. Alle drei Schichten weisen die gleichen Merkmale auf. Sie werden 2 benachbarte Neuronen in 1-Neuronen-Schritten analysieren. In jeder Schicht werden zwei Filter für die Analyse verwendet.

Wie man sieht, wächst der Ergebnisvektor aufgrund der kleinen Schrittweite des analysierten Datenfensters und der Verwendung mehrerer Filter von Schicht zu Schicht an. In der Regel werden Unterabtastungsschichten zur Dimensionalitätsreduktion verwendet. Sie bilden entweder einen Mittelwert aus den Ausgangswerten der Filter oder nehmen den höchsten Wert. Ich habe sie nicht verwendet und versucht, so viele nützliche Informationen wie möglich zu speichern.
Faltungsschichten führen eine Art anfänglicher Datenvorbereitung durch, indem sie einige Muster in den Daten definieren. Je mehr Faltungsschichten, desto komplexere Muster kann das Modell finden. Vermeiden Sie jedoch die Erstellung extrem tiefer Modelle, da dies den Lernprozess erschwert. Es trifft zu, dass die nicht-gradientenbasierten Modelloptimierungsmethoden die Probleme des explodierenden und verblassenden Gradienten vermeiden. Aber brauchen wir wirklich tiefe Netze, um unsere Probleme zu lösen? Experimentieren Sie mit verschiedenen Optionen und ermitteln Sie, wie sich eine Erweiterung des Modells auf das Endergebnis auswirkt. Sie werden feststellen, dass das Hinzufügen neuer Ebenen das Ergebnis nicht mehr verändert. Für die Optimierung des Modells werden jedoch zusätzliche Ressourcen benötigt.
Die Ergebnisse der neuronalen Faltungsschichten werden mit einem vollständig verknüpften Perzeptron aus 3 Schichten mit jeweils 500 Neuronen verarbeitet. Auch hier habe ich den hyperbolischen Tangens als Aktivierungsfunktion verwendet. Ich schlage vor, Sie probieren aus, wie verschiedene Aktivierungsfunktionen funktionieren, und vergleichen das Ergebnis.

Am Ausgang des Modells wollen wir eine Wahrscheinlichkeitsverteilung von drei Aktionen erhalten: kaufen, verkaufen, warten. Zu diesem Zweck erstellen wir eine weitere voll verknüpfte Schicht mit 3 Neuronen. Dieses Mal verwenden wir keine Aktivierungsfunktion.

Übertragen wir das Ergebnis mit Hilfe der SoftMax-Schicht in den Bereich der Wahrscheinlichkeiten.

Damit ist die Erstellung eines neuen Modells abgeschlossen. Das Einzige, was noch zu tun ist, ist, sie unter dem Namen der Datei zu speichern, auf die sich unser EA beziehen wird. Die Funktion zum Speichern des Modells wird durch Anklicken von „SAVE MODEL“ gestartet.

Das Modell wurde anhand der historischen Daten der letzten zwei Jahre trainiert. Der Prozess der Modellbildung wurde bereits in früheren Artikeln beschrieben. Ich werde hier nicht näher auf sie eingehen.
Merkwürdigerweise zeigte die Grafik der Gesamtfehlerdynamik während der Modelloptimierung eine abrupte Dynamik.

Nach der Optimierung wurde das Modell mit dem Strategietester getestet. Um das Modell zu testen, habe ich den EA Evolution-test.mq5 verwendet, der eine exakte Kopie des EA aus mehreren früheren Artikeln ist. Die Änderungen betrafen nur den Dateinamen des geladenen Modells. Der vollständige Code des EAs befindet sich im Anhang.
Der EA wurde für den Zeitraum der letzten 2 Wochen getestet, der nicht in der Trainingsstichprobe enthalten war. Das bedeutet, dass der EA unter realitätsnahen Bedingungen getestet wurde. Die Testergebnisse haben die Tragfähigkeit des vorgeschlagenen Ansatzes gezeigt. Das nachstehende Schaubild zeigt die zunehmende Dynamik des Gleichgewichts. Insgesamt wurden während des Testzeitraums 107 Abschlüsse getätigt. Davon waren fast 55 % rentabel. Das Verhältnis von gewinnbringenden zu verlustbringenden Geschäften liegt nahe bei 1:1, aber der durchschnittliche Gewinn liegt um 43 % höher als der durchschnittliche Verlust. Daraus ergibt sich ein Gewinnfaktor (Profit Factor) von 1,69. Der Erholungsfaktor (Recovery Factor) erricht 3,39.


Schlussfolgerung
In diesem Artikel haben wir uns mit einer weiteren nichtgradientenbasierten Optimierungsmethode vertraut gemacht — dem evolutionären Algorithmus. Wir haben eine Klasse zur Implementierung dieses Algorithmus erstellt. Die Wirksamkeit des besprochenen Algorithmus wird durch die Modelloptimierung und durch die Prüfung der Optimierungsergebnisse im Strategietester bestätigt. Die Testergebnisse haben gezeigt, dass der EA in der Lage ist, einen Gewinn zu erzielen. Es ist jedoch zu beachten, dass die Tests in einem kurzen Zeitintervall durchgeführt wurden. Daher können wir nicht sicher sein, dass die EA langfristig Gewinne erzielen kann.
Das Modell und der EA aus dem Artikel dienen lediglich der Demonstration der Technologie. Vor der Verwendung auf echten Konten sind zusätzliche Einstellungen und Optimierungen erforderlich.
Referenzen
- Neuronale Netze leicht gemacht (Teil 26): Reinforcement-Learning
- Neuronale Netze leicht gemacht (Teil 27): Tiefes Q-Learning (DQN)
- Neuronale Netze leicht gemacht (Teil 28): Policy Gradient Algorithmus
- Neuronale Netze leicht gemacht (Teil 29): Advantage Actor Critic Algorithm
- Natural Evolution Strategies
- Evolution Strategies as a Scalable Alternative to Reinforcement Learning
- Neuronale Netze leicht gemacht (Teil 23): Aufbau eines Tools für Transfer-Learning
- Neuronale Netze leicht gemacht (Teil 24): Verbesserung des Instruments für Transfer-Learning
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Evolution.mq5 | EA | EA zur Optimierung des Modells |
| 2 | NetEvolution.mqh | Klassenbibliothek | Bibliothek zur Organisation des evolutionären Algorithmus |
| 3 | Evolution-test.mq5 | EA | Ein Expert Advisor zum Testen des Modells im Strategy Tester |
| 4 | NeuroNet.mqh | Klassenbibliothek | Bibliothek zur Erstellung neuronaler Netzmodelle |
| 5 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek zur Erstellung neuronaler Netzwerkmodelle |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/11619
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 31): Der Zukunft entgegen (IV)
Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 31): Der Zukunft entgegen (IV)
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Gestatten Sie mir zunächst, Dmitriy für diese informative Serie zu danken.
Kann mir bitte jemand helfen, diesen Fehler zu verstehen
10:40:19.206 Core 1 2019.01.01 00:00:00 USDJPY#_PERIOD_H1_Evolution.nnw
10:40:19.206 Core 1 Tester gestoppt, weil OnInit einen Nicht-Null-Code zurückgibt 1
10:40:19.207 Kern 1 Verbindung unterbrochen
10:40:19.207 Kern 1 Verbindung geschlossen
Lieber Dmitriy ,
ich möchte mich bei Ihnen für Ihre Arbeit bedanken, sie ist sehr wertvoll!
Ich würde gerne jemanden um Hilfe bitten. Wenn ich versuche, den Evolution-test-mq5 EA zu backtesten, erhalte ich einen Fehler, der bereits oben erwähnt wurde: Der Tester wurde gestoppt, weil OnInit einen Nicht-Null-Code 1 zurückgibt.
Ich habe die .nnw-Datei in das Agent-Verzeichnis (C:\Users\...\MetaQuotes\Tester\D0E8209G77C3CF47AD8BA550E52FF078\Agent-127.0.0.1-3000\MQL5\Files) verschoben, aber das hat nicht geholfen.
Der Teil des Codes, der den Fehler zurückgibt, ist in der Abbildung unten zu sehen (genau wie der in einem Kommentar oben).
Kann mir jemand einen Ratschlag geben, bitte?
Ich danke Ihnen
Ich habe die .nnw-Datei in das Agent-Verzeichnis (C:\Users\...\MetaQuotes\Tester\D0E8209G77C3CF47AD8BA550E52FF078\Agent-127.0.0.1-3000\MQL5\Files) verschoben, aber das hat nicht geholfen.
Der Teil des Codes, der den Fehler zurückgibt, ist in der Abbildung unten zu sehen (genau wie der in einem Kommentar oben).
Kann mir jemand einen Rat geben, bitte?
Dankeschön
Hallo!
Sie müssen die .nnw-Datei in das Verzeichnis "..\Common\Files" verschieben.
Hallo Dmitriy,
danke für deine schnelle Antwort. Ich habe die Dateien in diesen Ordner verschoben, aber leider lief der EA auch nicht gut. Stattdessen bekam ich eine Fehlermeldung:
2023.02.22 18:17:24.577 2018.02.01 00:00:00 OpenCL kernel create failed. Fehlercode=5107
2023.02.22 18:17:24.577 2018.02.01 00:00:00 Fehler beim Erstellen des Kernels: 5107
2023.02.22 18:17:24.608 Testerwurde gestoppt, weil OnInit einen Nicht-Null-Code 1 zurückgibt
Ich habe es versucht, ich von 5 bis 10 gesetzt, und ich habe versucht, ein. Gleicher Fehler:
2022.10.22 01:42:08.768 Evolution (EURUSD,H1) Fehler der Ausführung Kernel SoftMax FeedForward: 5109
Mir ist etwas aufgefallen, vielleicht deswegen: beim Speichern eines Modells erscheint auf der linken Seite des Fensters folgende Aufschrift: "Fehler beim Laden des Modells, Datei auswählen, Fehler-ID: 5004". Vielleicht wirkt sich das irgendwie aus.
Außerdem: die erstellte Datei sollte 16 Megabyte wiegen! Es ist ungewöhnlich, solche Größen in mql zu sehen.
UPD
Ich habe es auf meinem Laptop versucht, es will auch nicht unterrichten:
2022.10.22 13:07:36.028 Evolution (EURUSD,H1) EURUSD_PERIOD_H1_Evolution.nnw
2022.10.22 13:07:36.028 Evolution (EURUSD,H1) OpenCL: GPU device 'Intel(R) UHD Graphics' selected
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 9 nicht gelöschte Objekte übrig
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 1 Objekt vom Typ CLayer übrig
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 1 Objekt vom Typ CNeuronBaseOCL übrig
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 7 Objekte des Typs CBufferFloat verlassen
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 2688 Bytes an ausgelaufenem Speicher
Im Protokoll:
2022.10.22 13:07:34.716 Experten Experte Evolution (EURUSD,H1) erfolgreich geladen
2022.10.22 13:07:37.568 Experten Initialisierung von Evolution (EURUSD,H1) mit Code 1 fehlgeschlagen
2022.10.22 13:07:37.580 Experten Experte Evolution (EURUSD,H1) entfernt