
Redes neuronales: así de sencillo (Parte 33): Regresión cuantílica en el aprendizaje Q distribuido

Contenido
- Introducción
- 1. Regresión cuantil
- 2. Aplicación usando MQL5
- 3. Simulación
- Conclusión
- Enlaces
- Programas usados en el artículo.
Introducción
En el artículo anterior, presentamos el aprendizaje Q distribuido, que nos permite analizar la distribución de probabilidad de la recompensa predicha. Asimismo, aprendimos a predecir la probabilidad de obtener la recompensa esperada dentro de un determinado rango de valores. Pero, como ya habrá observado, el número de esos rangos y la dispersión de los valores de recompensa son hiperparámetros del modelo, y en consecuencia, necesitaremos conocimientos expertos sobre la distribución de los valores de recompensa para seleccionar los parámetros óptimos, así como una serie de pruebas para seleccionarlos.
Debemos decir que el planteamiento que hemos adoptado de dividir toda la gama de valores posibles en rangos iguales también tiene sus desventajas. Para predecir la probabilidad de obtener una recompensa en cada uno de los rangos individuales para cada acción, asignaremos una neurona. En la práctica, sin embargo, resulta bastante común ver situaciones en las que la probabilidad de obtener una recompensa en un gran número de rangos es exactamente "0". Esto significará que no estamos gastando nuestros recursos de forma eficiente. Algunos rangos podrían combinarse para reducir el número de operaciones realizadas, y así acelerar el entrenamiento y el funcionamiento del modelo. Al mismo tiempo, la probabilidad de obtener recompensas en otros rangos resultará bastante elevada, y para conseguir una imagen más completa, nos gustaría desglosar dicho rango en componentes más pequeños, lo cual mejorará la precisión de la predicción de la recompensa esperada. No obstante, nuestro enfoque no permitirá rangos de diferentes tamaños. Estas deficiencias se solucionan usando el algoritmo de regresión cuantílica propuesto en octubre de 2017 en el artículo "Distributional Reinforcement Learning with Quantile Regression"
1. Regresión cuantílica
La regresión cuantílica modela la relación entre la distribución de las variables independientes y determinados cuantiles de la variable objetivo.
Comenzando a discutir el uso de la regresión cuantílica en el aprendizaje Q distribuido, el algoritmo propuesto adopta un enfoque diferente para valorar la distribución de la probabilidad de la recompensa esperada. Y si antes desglosábamos el rango de posibles valores de recompensa en diferentes secciones, en el nuevo algoritmo, descompondremos todo el conjunto de recompensas obtenidas en una serie de cuantiles igualmente probables. ¿Qué nos aportará esto?
Pues ni más ni menos que el hiperparámetro del número de cuantiles a analizar, sin limitar en este caso el abanico de posibles recompensas. En su lugar, entrenaremos nuestro modelo para predecir los valores medianos de los cuantiles, y como estamos usando cuantiles de igual probabilidad, no obtendremos cuantiles con probabilidad cero de obtener una recompensa. Además, en la zona donde los valores de recompensa se hacen más raros, obtendremos cuantiles ampliados, mientras que en las zonas de gran acumulación de recompensas, se dividirán en zonas más pequeñas. Esto nos dará una idea más completa de la distribución de probabilidad de la recompensa esperada. Además, este enfoque permitirá identificar zonas no estáticas con menor y mayor densidad de valores de recompensa, que puede variar según el estado del entorno.
No obstante, seguirá siendo el mismo aprendizaje Q, y el proceso se basará en la ecuación de optimización de Bellman.

Solo que esta vez no se nos pedirá que definamos un único valor, sino toda una distribución. Sin embargo, en esencia, la tarea seguirá siendo la misma. Vamos a echar un vistazo más de cerca a la tarea que nos ocupa.
Como ya hemos mencionado, dividiremos la distribución completa de recompensas de la muestra de entrenamiento en N cuantiles igualmente probables. Cada cuantil representará el nivel que la variable aleatoria analizada no superará con una probabilidad determinada. Los cuantiles de igual probabilidad en este caso los llamaremos cuantiles de paso fijo, cuya población total abarcará toda la muestra de entrenamiento.
En la práctica, tendremos un conjunto de muestra de entrenamiento, y la probabilidad de obtener uno de los elementos de esta muestra será "1". Sencillamente, no puede haber otra. Al fin y al cabo, estamos tomando elementos de una muestra de entrenamiento.
La partición de la muestra en N cuantiles igualmente probables implicará, en primer lugar, dividir toda la muestra de entrenamiento en N partes iguales, cada una de las cuales contendrá el mismo número de elementos. Y la probabilidad de seleccionar un elemento de una de las muestras será 1/N.
Un cuantil individual se caracterizará por 2 parámetros: la probabilidad de seleccionar un elemento y el límite superior de los valores de sus elementos. Debemos decir que una condición adicional para los cuantiles será que estén clasificados de forma ascendente con acumulación de la probabilidad. Es decir, el límite superior de los valores de cada cuantil sucesivo será superior al anterior, y la probabilidad de un cuantil incluirá la probabilidad de los cuantiles anteriores. Por ejemplo, para alguna distribución tendremos un cuantil de 0,2 con un nivel de 15. Esto significará que el valor del 20% de los elementos de toda la distribución no superará 15. No obstante, el paso de las probabilidades y los niveles de los valores cuantílicos máximos podrían no ser proporcionales y depender de una distribución concreta.
El algoritmo que estamos analizando consiste en dividir la población en cuantiles con un paso de probabilidad fijo, y en lugar de los límites superiores, entrenaremos el modelo para predecir los valores medianos de los cuantiles.
Necesitaremos valores objetivo para entrenar el modelo. Con un conjunto completo de elementos de una población, podremos hallar fácilmente el valor medio,
pero en la práctica, no dispondremos de la población completa: solo obtendremos recompensas del entorno después de realizar la acción y la transición a un nuevo estado. Como puede ver, cambiar el algoritmo de aprendizaje del modelo no influye en el proceso de interacción con el entorno. En el proceso original de aprendizaje Q, entrenábamos un modelo para predecir la recompensa media esperada, y lo conseguimos desplazando iterativamente los resultados de nuestro modelo hacia los objetivos con una pequeña curva de aprendizaje. Como podemos ver, durante el proceso de aprendizaje, el resultado de nuestro modelo se ve constantemente afectado por una fuerza de desplazamiento hacia el valor objetivo actual. Y el valor medio se alcanza en el momento en que las fuerzas dirigidas de forma opuesta se equilibran entre sí (como se muestra en la figura).

Podemos utilizar un enfoque similar para resolver los problemas del algoritmo en cuestión, pero aquí se da una circunstancia: el algoritmo anterior permite hallar el valor medio de toda la población, que es un cuantil de 0,5. Aplicándolo en su forma pura, obtendremos los mismos valores en todas las neuronas de la capa de resultados de nuestro modelo. Todas funcionarán de manera sincronizada, como una sola neurona, mientras que a nosotros nos gustaría obtener una distribución real de los valores por los cuantiles analizados.
Veamos la naturaleza del cuantil. Por ejemplo, vamos a analizar un cuantil de 0,25, que es la cuarta parte de la población analizada. Si descartamos la distancia entre los valores de los elementos, entonces por cada 1 elemento del cuantil deberemos tener 3 elementos de la población total que no entren en ese cuantil. Volviendo a nuestro ejemplo anterior, para obtener el equilibrio en el punto del cuantil de 0,25, la fuerza del valor decreciente deberá ser 3 veces la fuerza del valor creciente del cuantil.
Como consecuencia, para hallar el valor de cada cuantil concreto, solo tendremos que introducir un factor de corrección en la ecuación de Bellman, que dependerá del nivel del cuantil y de la dirección de la desviación.
![]()
donde τ será la característica probabilística del cuantil.
Para ello, durante el proceso de aprendizaje, usaremos todas las heurísticas del aprendizaje Q clásico como reproducción de la experiencia y Target Net.
2. Implementación usando MQL5
Tras considerar los aspectos teóricos del algoritmo, pasaremos a la parte práctica de este artículo, y veremos la implementación del algoritmo usando MQL5. No crearemos nuevas arquitecturas de capas neuronales en el proceso de implementación del algoritmo, no obstante, sacaremos la organización del proceso a una clase aparte, CQRDQN. Esto nos permitirá simplificar el proceso de uso del método en los asesores y proteger al usuario de algunos de los detalles de implementación. A continuación, mostraremos la estructura de la nueva clase.
class CQRDQN : protected CNet { private: uint iCountBackProp; protected: uint iNumbers; uint iActions; uint iUpdateTarget; matrix<float> mTaus; //--- CNet cTargetNet; public: /** Constructor */ CQRDQN(void); CQRDQN(CArrayObj *Description) { Create(Description, iActions); } bool Create(CArrayObj *Description, uint actions); /** Destructor */~CQRDQN(void); bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNet::feedForward(inputVals, window, tem); } bool backProp(CBufferFloat *targetVals, float discount, CArrayFloat *nextState, int window = 1, bool tem = true); void getResults(CBufferFloat *&resultVals); int getAction(void); int getSample(void); float getRecentAverageError() { return recentAverageError; } bool Save(string file_name, datetime time, bool common = true) { return CNet::Save(file_name, getRecentAverageError(), (float)iActions, 0, time, common); } virtual bool Save(const int file_handle); virtual bool Load(string file_name, datetime &time, bool common = true); virtual bool Load(const int file_handle); //--- virtual int Type(void) const { return defQRDQN; } virtual bool TrainMode(bool flag) { return CNet::TrainMode(flag); } virtual bool GetLayerOutput(uint layer, CBufferFloat *&result) { return CNet::GetLayerOutput(layer, result); } //--- virtual void SetUpdateTarget(uint batch) { iUpdateTarget = batch; } virtual bool UpdateTarget(string file_name); //--- virtual bool SetActions(uint actions); };
La nueva clase la crearemos como heredera de la clase de organización de nuestros modelos de red neuronal CNet. Esto significará que construiremos un nuevo algoritmo para trabajar con el modelo.
Asimismo, para almacenar los parámetros clave del funcionamiento de nuestro algoritmo, crearemos las variables:
- iNumbers — número de neuronas en la secuencia que describe la distribución de una acción;
- iActions — número de opciones de acción posibles;
- iUpdateTarget — frecuencia de actualización de los parámetros del modelo Target Net;
- mTaus — matriz para registrar las características probabilísticas de los cuantiles;
- cTargetNet — puntero a un objeto Target Net.
Nótese aquí que en la matriz mTaus registraremos los valores medianos de probabilidad de cada cuantil.
En el constructor de la clase, estableceremos los valores iniciales de las variables especificadas.
CQRDQN::CQRDQN() : iNumbers(31), iActions(2), iUpdateTarget(1000) { mTaus = matrix<float>::Ones(1, iNumbers) / iNumbers; mTaus[0, 0] /= 2; mTaus = mTaus.CumSum(0); cTargetNet.Create(NULL); Create(NULL, iActions); }
Como en la propia clase de organización del modelo de red neuronal CNet, además del constructor sin parámetros, crearemos una sobrecarga del método indicando la arquitectura del modelo a crear.
CQRDQN(CArrayObj *Description) { Create(Description, iActions); }
Asimismo, crearemos directamente el modelo en el método Create. En los parámetros, este método obtiene el puntero al array de descripciones de la arquitectura del modelo que estamos creando y el número de posibles acciones del agente.
bool CQRDQN::Create(CArrayObj *Description, uint actions) { if(actions <= 0 || !CNet::Create(Description)) return false;
En el cuerpo del método, comprobaremos que el parámetro de número de acciones del agente se haya especificado correctamente, y llamaremos al método homónimo de la clase padre que organizará todos los controles necesarios en relación con el objeto de descripción de la arquitectura del modelo que estamos creando y el proceso de creación del nuevo modelo en sí. Aquí solo comprobaremos el resultado lógico de la ejecución de las operaciones de la clase padre.
Tras crear con éxito un nuevo modelo, tomaremos una capa de resultados del modelo creado. A partir de la información sobre su tamaño y el número de acciones posibles del agente, rellenaremos la matriz de características probabilísticas de los cuantiles mTaus. El número de filas de esta matriz será igual al tamaño de la distribución de probabilidad de la recompensa por una acción, y como las probabilidades de cada cuantil se establecerán de forma que sean las mismas para todas las acciones posibles del agente con un paso fijo igual antes de empezar el entrenamiento, utilizaremos una matriz-vector con una fila. El uso de una matriz, en lugar de un vector, se debe al "objetivo" de un desarrollo posterior con posibles variaciones en las distribuciones probabilísticas de las acciones.
int last_layer = Description.Total() - 1; CLayer *layer = layers.At(last_layer); if(!layer) return false; CNeuronBaseOCL *neuron = layer.At(0); if(!neuron) return false; iActions = actions; iNumbers = neuron.Neurons() / actions; mTaus = matrix<float>::Ones(1, iNumbers) / iNumbers; mTaus[0, 0] /= 2; mTaus = mTaus.CumSum(0); cTargetNet.Create(NULL); //--- return true; }
Tenga en cuenta que al principio ponemos Target Net a cero. Este enfoque se usa para evitar que el nuevo modelo se entrene con variables completamente aleatorias de un modelo no entrenado.
Aprovecharemos al máximo un método similar de la clase padre para organizar las pasadas directas.
bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNet::feedForward(inputVals, window, tem); }
El método backProp, por otro lado, es algo con lo que deberemos trabajar. Recordemos que la respuesta del entorno a cada acción de nuestro agente será una recompensa. Al organizar el proceso clásico de aprendizaje Q, definiremos la política de recompensas, y como en el proceso comercial las posibles acciones del agente son mutuamente excluyentes y de naturaleza opuesta, podremos determinar a partir de la recompensa del entorno por una acción cuál sería la recompensa por la acción opuesta. Esto nos permitirá obtener los valores objetivo para todas las acciones posibles en cada iteración de la pasada inversa, lo que hará que el proceso de aprendizaje resulte más estable y rápido. Sin embargo, en el aprendizaje Q distribuido estamos tratando con un vector completo de valores objetivo para cada acción, y en el artículo anterior, construimos un nuevo proceso para crear un tensor de valores objetivo del modelo en el asesor de entrenamiento de modelos, así como un nuevo bloque para descifrar los resultados del modelo antes de realizar una acción en el asesor experto para comprobar el funcionamiento del modelo entrenado.
Ahora, al crear una nueva clase, podremos ocultar este proceso al usuario, para que su trabajo con el modelo sea más fácil y claro. Esto resulta similar a trabajar con el modelo de aprendizaje Q clásico, cuando el entorno solo retorna un valor de recompensa discreto por acción, mientras que el proceso de conversión de esta recompensa discreta en un vector de distribución para cada acción se realiza en el cuerpo del método de pasada inversa.
El uso de la nueva clase de organización de procesos tendrá otra ventaja. Como ya sabrá, el proceso de aprendizaje Q utiliza laTarget Net para predecir recompensas futuras, y antes el usuario tenía que trabajar con 2 modelos. Ahora podremos ocultar todo el trabajo con la Target Net dentro de los métodos de nuestra clase, facilitando así el trabajo del usuario. No obstante, para hacer esto, antes era necesario cambiar los parámetros del método de pasada inversa, y en este escenario, para ejecutar correctamente el proceso de pasada inversa, aparte de los valores objetivo, también esperamos que el usuario obtenga un nuevo estado del sistema.
En el cuerpo del método de pasada inversa, primero comprobamos si el puntero resultante al vector de valores objetivo es correcto, asimismo, el tamaño del vector resultante deberá ser igual al número de acciones posibles del agente.
bool CQRDQN::backProp(CBufferFloat *targetVals, float discount, CArrayFloat *nextState=NULL, int window = 1, bool tem = true) { //--- if(!targetVals) return false; vectorf target; if(!targetVals.GetData(target) || target.Size() != iActions) return false;
A continuación, comprobaremos que el puntero al nuevo vector de descripción del estado del sistema sea correcto, y, si fuera necesario, realizaremos una pasada directa de la Target Net. A continuación, determinaremos la recompensa máxima posible y ajustaremos la recompensa obtenida del entorno a los ingresos futuros, considerando el factor de descuento.
if(!!nextState) { if(!cTargetNet.feedForward(nextState, window, tem)) return false; vectorf temp; cTargetNet.getResults(targetVals); if(!targetVals.GetData(temp)) return false; matrixf q = matrixf::Zeros(1, temp.Size()); if(!q.Row(temp, 0) || !q.Reshape(iActions, iNumbers)) return false; temp = q.Mean(0); target = target + discount * temp.Max(); }
Para actualizar los parámetros del modelo, utilizaremos la fórmula:
![]()
No obstante, deberá tener en cuenta que, al aplicar la fórmula anterior en el cuerpo de este método, no utilizaremos el coeficiente de aprendizaje. Aquí se esconde una pequeña trampa. La cuestión es que en el cuerpo de este método, por extraño que parezca, no actualizaremos los parámetros del modelo, solo crearemos un vector de resultados objetivo para nuestro modelo. Los parámetros del modelo se actualizarán directamente en el método homónimo de la clase padre, al que transmitiremos el tensor completo de los resultados objetivo del modelo, y ya al actualizar los parámetros del modelo, tendremos en cuenta el coeficiente de aprendizaje.
En esta fase, ya tendremos una recompensa del entorno, considerando los posibles beneficios futuros, y para crear un vector de valores objetivo, solo nos faltarán los últimos resultados de la pasada directa de nuestro modelo. Los cargaremos en la matriz local Q.
vectorf quantils; getResults(targetVals); if(!targetVals.GetData(quantils)) return false; matrixf Q = matrixf::Zeros(1, quantils.Size()); if(!Q.Row(quantils, 0) || !Q.Reshape(iActions, iNumbers)) return false;
A continuación, podremos crear el búfer de valores objetivo necesario para nuestro modelo. Para ello utilizaremos un ciclo para generar la creación de un vector de valores objetivo de niveles cuantiles para cada posible acción individual del agente. Querríamos señalar que el uso de operaciones matriciales y vectoriales requiere algunos trucos y cambios de planteamiento a la hora de construir algoritmos, pero también reducirá el uso de ciclos. En general, esto aumentará la velocidad de ejecución del programa.
En este caso, el uso de operaciones vectoriales nos permitirá prescindir del sistema de ciclos anidados, en el que se iteran todas las acciones y todos los elementos de distribución para cada posible acción del agente. En su lugar, solo utilizaremos 1 ciclo de enumeración de las posibles acciones de los agentes, cuyo número de iteraciones será, en la mayoría de los casos, decenas de veces inferior al número de iteraciones del ciclo de enumeración de la distribución de la probabilidad excluida. Pero el precio a pagar por ello es el abandono del operador condicional. No podemos simplemente comparar 2 elementos del vector para seleccionar una acción según el resultado de la comparación,
y deberemos ejecutar ambas ramas de las operaciones para todos los elementos del vector. Para no distorsionar el resultado esperado de las operaciones, crearemos 2 vectores de diferenciación entre la recompensa obtenida del entorno y el resultado de la última pasada directa. A continuación, pondremos a cero los valores negativos de un vector y los positivos del segundo. Así, tras multiplicar los vectores derivados por los coeficientes de ajuste de potencia correspondientes para el valor medio del cuantil, obtendremos los valores de corrección deseados. La suma de los vectores resultantes y los últimos resultados de la pasada directa nos dará los valores objetivo necesarios para la pasada inversa de nuestro modelo.
for(uint a = 0; a < iActions; a++) { vectorf q = Q.Row(a); vectorf dp = q - target[a], dn = dp; if(!dp.Clip(0, FLT_MAX) || !dn.Clip(-FLT_MAX, 0)) return false; dp = (mTaus.Row(0) - 1) * dp; dn = mTaus.Row(0) * dn * (-1); if(!Q.Row(dp + dn + q, a)) return false; } if(!targetVals.AssignArray(Q)) return false;
Tras completar todas las iteraciones del ciclo, actualizaremos los valores del búfer de valores objetivo.
A continuación, realizaremos un pequeño trabajo de apoyo para organizar el modelo de Target Net. Luego implementaremos un contador para las iteraciones de los pasadas inversas, y cuando se alcance el número umbral de iteraciones, actualizaremos el modelo de Target Net.
if(iCountBackProp >= iUpdateTarget) { #ifdef FileName if(UpdateTarget(FileName + ".nnw")) #else if(UpdateTarget("QRDQN.upd")) #endif iCountBackProp = 0; } else iCountBackProp++;
Fíjese en la macrosustitución en el cuerpo del operador de comparación al alcanzar el umbral de iteraciones de la pasada inversa. Como antes, al actualizar el modelo de Target Net, no copiaremos directamente los parámetros de un modelo a otro. En su lugar, usaremos un mecanismo para guardar y restaurar el modelo desde un archivo. Para realizar esta iteración, necesitaremos un nombre de archivo.
En todos nuestros modelos, hemos utilizado la macrosustitución FileName para generar un nombre de archivo único dependiendo del asesor, el instrumento y el marco temporal utilizado. Esta macrosustitución se asignará directamente en el asesor, mientras que la macrosustitución organizada aquí nos permitirá comprobar el propósito de la macrosustitución para generar nombres de archivo en el asesor. Si esta se encuentra disponible, la utilizaremos para operaciones de guardado y recuperación de archivos. En caso contrario, usaremos el nombre de archivo por defecto.
#define FileName Symb.Name()+"_"+EnumToString(TimeFrame)+"_"+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
Al final de nuestro método, llamaremos al método de pasada inversa de la clase padre y le transmitiremos el tensor objetivo preparado en los parámetros, mientras que el resultado lógico de las operaciones del método de la clase padre se retornarán al programa que ha realizado la llamada.
return CNet::backProp(targetVals);
}
De este modo, hemos ocultado al usuario el uso del modelo con la distribución de probabilidad al realizar una pasada inversa, y el entorno solo retornará una recompensa discreta por cada acción. La llamada al método de pasada inversa ahora se realizará de la misma forma que en el aprendizaje Q clásico. Pero al hacerlo, hemos evitado que el usuario tenga que controlar el segundo modelo de Target Net, lo cual, a mi juicio, aumentará la utilidad de nuestro modelo. No obstante, la cuestión de la pasada directa seguirá abierta.
Como ya hemos indicado, para la pasada directa, se aprovechará el método de la clase padre. Esto no afectará negativamente a las operaciones de pasada directa. Al fin y al cabo, el método de pasada directa solo retornará el resultado lógico de las operaciones. La cuestión surgirá al intentar obtener los resultados de la pasada directa. Aquí, los métodos de la clase padre retornarán la distribución de probabilidad completa generada por el modelo. Entonces surgirá una laguna entre los resultados de la pasada hacia directa y los valores objetivo de la pasada inversa. Por consiguiente, deberemos redefinir el método de obtención de los resultados de la pasada directa para que estos resulten comparables a los resultados de la pasada inversa que estamos utilizando.
Aquí debemos decir que no hemos utilizado los cuantiles equiprobables porque sí. Es por ello que podremos simplemente tomar la media de toda la distribución generada para cada posible acción del agente y retornar este valor como la recompensa esperada. También en este caso, las operaciones matriciales acudirán en nuestra ayuda. Gracias a ellas hemos podido construir al completo el algoritmo del método sin utilizar ciclos.
Al principio del método, llamaremos al método homónimo de la clase padre, que implementará todos los controles y operaciones necesarios para copiar en el búfer de datos los resultados de la pasada directa. Los datos obtenidos los transferiremos a una matriz que luego reformatearemos en una matriz de tabla con un número de filas igual al número de acciones posibles del agente. Cada fila será entonces un vector de la distribución de probabilidad de la recompensa esperada para cada acción individual del agente. y entonces solo necesitaremos la función matricial Mean para determinar los valores medios de todas las acciones posibles de los agentes. Todo lo que deberemos hacer será transmitir el resultado al búfer de datos y retornarlo al programa de llamada.
void CQRDQN::getResults(CBufferFloat *&resultVals) { CNet::getResults(resultVals); if(!resultVals) return; vectorf temp; if(!resultVals.GetData(temp)) { delete resultVals; return; } matrixf q; if(!q.Init(1, temp.Size()) || !q.Row(temp, 0) || !q.Reshape(iActions, iNumbers)) { delete resultVals; return; } //--- if(!resultVals.AssignArray(q.Mean(1))) { delete resultVals; return; } //--- }
Y aquí podríamos esperar un mar de desconcierto y preguntas referentes al motivo de todo esto si regresamos a la media, que es lo que enseña el aprendizaje Q original. Sin profundizar en las matemáticas, enunciaremos una verdad que se ha demostrado con resultados prácticos: la probabilidad del valor medio de una muestra no es igual al valor medio de las probabilidades de las submuestras de la misma población. El aprendizaje Q original enseña la probabilidad del valor medio de la muestra, mientras que el aprendizaje Q distribuido aprende varias medias para cada cuantil, y ya luego nosotros tomamos la media de estas probabilidades.
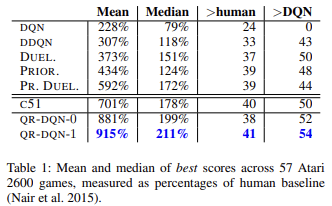
Como demuestran la literatura científica y la práctica, la regresión cuantílica se ve en general menos influida por diversos valores atípicos, y esto hace que el proceso de aprendizaje del modelo resulte más estable, y los resultados de ese aprendizaje sean menos sesgados. Los autores del método citan en su artículo los resultados del entrenamiento de modelos entrenados con 57 juegos de Atari en comparación con los logros de los modelos entrenados usando otros algoritmos. Los datos muestran que el resultado medio es casi 4 veces superior al del aprendizaje Q original (DQN). A continuación, le mostraremos la tabla de resultados del artículo original [6]
Mejoramos la usabilidad de nuestro modelo. Antes, al crear todos los asesores que probaban modelos de aprendizaje por refuerzo, creábamos varios métodos para seleccionar una acción basándonos en los resultados de una pasada directa del modelo entrenado. La creación de una nueva clase nos permitirá organizar los métodos que ejecutan esta funcionalidad. Para seleccionar de forma codiciosa la acción con la máxima recompensa esperada, crearemos el método getAction. Su algoritmo es bastante simple. Nosotros solo usaremos el método getResults descrito anteriormente para obtener los resultados de la pasada directa. En el búfer de resultados obtenido, seleccionaremos el elemento con el valor máximo.
int CQRDQN::getAction(void) { CBufferFloat *temp; getResults(temp); if(!temp) return -1; //--- return temp.Maximum(0, temp.Total()); }
No aplicamos la estrategia de selección de acciones ɛ-codiciosa, ya que se aplicará durante el entrenamiento del modelo para aumentar el aprendizaje del entorno. Nuestra política de recompensas no permite el uso de métodos semejantes. Al fin y al cabo, durante el entrenamiento, ofreceremos objetivos de referencia para todas las acciones posibles del agente a la vez.
El segundo método getSample se usará para seleccionar aleatoriamente una acción de una distribución de probabilidad en la que una gran recompensa tiene una alta probabilidad. Para evitar el copiado innecesario de datos entre matrices y búferes de datos, repetiremos parcialmente el algoritmo del método getResults.
int CQRDQN::getSample(void) { CBufferFloat* resultVals; CNet::getResults(resultVals); if(!resultVals) return -1; vectorf temp; if(!resultVals.GetData(temp)) { delete resultVals; return -1; } delete resultVals; matrixf q; if(!q.Init(1, temp.Size()) || !q.Row(temp, 0) || !q.Reshape(iActions, iNumbers)) { delete resultVals; return -1; }
A continuación, normalizaremos los resultados de la pasada directa con la función SoftMax. Estas serán las probabilidades de elección de la acción del agente.
if(!q.Mean(1).Activation(temp, AF_SOFTMAX)) return -1; temp = temp.CumSum();
Luego recopilaremos un vector de probabilidad total acumulada y realizaremos un muestreo a partir del vector de distribución de probabilidad resultante.
int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(random >= 1) return (int)temp.Size() - 1; for(int i = 0; i < (int)temp.Size(); i++) if(random <= temp[i] && temp[i] > 0) return i; //--- return -1; }
Después retornaremos el resultado del muestreo al programa que ha realizado la llamada.
Ya hemos examinado los métodos de pasada directa e inversa, así como los métodos para obtener los resultados de nuestro modelo, pero seguimos teniendo una serie de cuestiones sin resolver. Uno de ellas es el método de actualización del modelo Target Net - UpdateTarget. Nos hemos referido a este método al examinar el método de pasada inversa, aunque este método se llama desde otro método de la clase, hemos decidido hacerlo público y ofrecerle acceso al usuario. Sí, hemos evitado que el usuario tenga que controlar el estado de la Target Net, sin embargo, no hemos limitado su libertad de elección y, si lo desea, podrá tomar el control total.
El algoritmo del método es bastante sencillo: simplemente llamaremos primero al método de almacenamiento del objeto actual, y luego llamaremos al método de recuperación de datos de Target Net. Al hacerlo, controlaremos el proceso de realización de las operaciones, y después de que el modelo de la Target Net se haya actualizado correctamente, reiniciaremos el contador de iteraciones de pasada inversa.
bool CQRDQN::UpdateTarget(string file_name) { if(!Save(file_name, 0, false)) return false; float error, undefine, forecast; datetime time; if(!cTargetNet.Load(file_name, error, undefine, forecast, time, false)) return false; iCountBackProp = 0; //--- return true; }
Preste atención a la diferencia en las clases de los objetos. Estamos trabajando en la nueva clase CQRDQN, mientras que Target Net es un ejemplar de la clase padre CNet. El hecho es que solo utilizaremos la funcionalidad de la pasada directa de Target Net . Este método no se ha modificado en nuestra clase, por lo que no habrá problemas previsibles en el uso de la clase padre. Al mismo tiempo, el uso de un ejemplar de la clase CQRDQN para Target Net creará recursivamente un objeto interno Target Net del ejemplar ya nuevo, y un proceso tan recurrente puede provocar errores críticos. Por consiguiente, un detalle tan pequeño podría tener implicaciones significativas para el funcionamiento de todo el programa.
Hemos analizado la funcionalidad básica de la nueva clase CQRDQN, que implementa el algoritmo de regresión cuantílica en el aprendizaje Q distribuido (QR-DQN). El método se presentó en octubre de 2017 en el artículo "Distributional Reinforcement Learning with Quantile Regression".
En la clase también se han implementado los métodos para guardar y restaurar el modelo, Save y Load, respectivamente. Los cambios introducidos en ellas no resultan tan complicados: podrá leerlos usted mismo en el archivo adjunto. Ahora le proponemos probar la nueva clase.
3. Simulación
Empezaremos a probar el funcionamiento de la nueva clase entrenando el modelo. Para su entrenamiento, hemos creado el asesor experto "QRDQN-learning.mq5". El asesor ha sido creado sobre la base del asesor original de aprendizaje Q "Q-learning.mq5". Hemos cambiado la clase del modelo entrenado en este asesor y eliminado la declaración del ejemplar del modelo de Target Net.
CSymbolInfo Symb;
MqlRates Rates[];
CQRDQN StudyNet;
CBufferFloat *TempData;
CiRSI RSI;
CiCCI CCI;
CiATR ATR;
CiMACD MACD; En el método de inicialización del asesor, cargaremos el modelo desde un archivo creado previamente. Luego activaremos forzosamente el modo de entrenamiento en todas las capas neuronales, determinaremos la profundidad de la historia a analizar según el tamaño de la capa de datos de origen y transmitiremos al modelo el tamaño del área de acciones permitidas. También especificaremos el periodo de actualización de la Target Net. En este caso, hemos dado un valor deliberadamente alto, ya que tenemos previsto gestionar por nosotros mismos el proceso de actualización de los modelos.
int OnInit() { //--- ......... ......... //--- if(!StudyNet.Load(FileName + ".nnw", dtStudied, false)) return INIT_FAILED; if(!StudyNet.TrainMode(true)) return INIT_FAILED; //--- if(!StudyNet.GetLayerOutput(0, TempData)) return INIT_FAILED; HistoryBars = TempData.Total() / 12; if(!StudyNet.SetActions(Actions)) return INIT_PARAMETERS_INCORRECT; StudyNet.SetUpdateTarget(1000000); //--- ........ //--- return(INIT_SUCCEEDED); }
El propio proceso de entrenamiento del modelo se realizará en la función Train.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
En dicha función definiremos el periodo de entrenamiento y cargaremos los datos históricos. Este proceso se almacenará íntegramente en su diseño original.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
A continuación, organizaremos un sistema de ciclos anidados del proceso de entrenamiento del modelo. El ciclo externo contará las épocas de entrenamiento de la actualización del modelo de la Target Net.
int total = bars - (int)HistoryBars - 240; bool use_target = false; //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int i = 0; uint ticks = GetTickCount(); int count = 0; int total_max = 0;
En el ciclo anidado, repetiremos las iteraciones de la pasada directa e inversa. Aquí prepararemos primero los datos históricos para describir los dos estados posteriores del sistema. Uno se utilizará para la pasada directa del modelo entrenado, mientras que el segundo será la Target Net.
for(int batch = 0; batch < (Batch * UpdateTarget); batch++) { i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * total + 240); State1.Clear(); State2.Clear(); int r = i + (int)HistoryBars; if(r > bars) continue; for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State1.Add((float)Rates[bar_t].close - open) || !State1.Add((float)Rates[bar_t].high - open) || !State1.Add((float)Rates[bar_t].low - open) || !State1.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State1.Add(sTime.hour) || !State1.Add(sTime.day_of_week) || !State1.Add(sTime.mon) || !State1.Add(rsi) || !State1.Add(cci) || !State1.Add(atr) || !State1.Add(macd) || !State1.Add(sign)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!use_target) continue; //--- bar_t --; open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); rsi = (float)RSI.Main(bar_t); cci = (float)CCI.Main(bar_t); atr = (float)ATR.Main(bar_t); macd = (float)MACD.Main(bar_t); sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State2.Add((float)Rates[bar_t].close - open) || !State2.Add((float)Rates[bar_t].high - open) || !State2.Add((float)Rates[bar_t].low - open) || !State2.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State2.Add(sTime.hour) || !State2.Add(sTime.day_of_week) || !State2.Add(sTime.mon) || !State2.Add(rsi) || !State2.Add(cci) || !State2.Add(atr) || !State2.Add(macd) || !State2.Add(sign)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Luego realizaremos una pasada directa del modelo entrenado.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } if(State1.Total() < (int)HistoryBars * 12 || (use_target && State2.Total() < (int)HistoryBars * 12)) continue; if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return;
A continuación, generaremos un lote de recompensas para todas las acciones posibles del agente y llamaremos al método de pasada inversa del modelo principal.
Rewards.BufferInit(Actions, 0); double reward = Rates[i].close - Rates[i].open; if(reward >= 0) { if(!Rewards.Update(0, (float)(2 * reward))) return; if(!Rewards.Update(1, (float)(-5 * reward))) return; if(!Rewards.Update(2, (float) - reward)) return; } else { if(!Rewards.Update(0, (float)(5 * reward))) return; if(!Rewards.Update(1, (float)(-2 * reward))) return; if(!Rewards.Update(2, (float)reward)) return; }
Tenga en cuenta que, según el método de pasada inversa redefinido, transmitiremos no solo el búfer de recompensa, sino también el estado actual posterior en los parámetros del método. Al mismo tiempo, hemos eliminado el bloque de operaciones de la Target Net y los ajustes de recompensa por los ingresos previstos de futuros estados.
if(!StudyNet.backProp(GetPointer(Rewards), DiscountFactor, (use_target ? GetPointer(State2) : NULL), 12, true)) return;
Luego mostraremos el progreso del proceso en el gráfico del instrumento.
if(GetTickCount() - ticks > 500) { Comment(StringFormat("%.2f%%", batch * 100.0 / (double)(Batch * UpdateTarget))); ticks = GetTickCount(); } }
Con esto concluirán las operaciones del ciclo anidado. Después de completar todas sus iteraciones, comprobaremos el error actual del modelo. Una vez mejorados los resultados anteriores, mantendremos el estado actual del modelo y actualizaremos la Target Net.
if(StudyNet.getRecentAverageError() <= min_loss) { if(!StudyNet.UpdateTarget(FileName + ".nnw")) continue; use_target = true; min_loss = StudyNet.getRecentAverageError(); } PrintFormat("Iteration %d, loss %.8f", iter, StudyNet.getRecentAverageError()); } Comment(""); //--- PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); }
Así concluirán las operaciones del ciclo externo y la función de entrenamiento en su conjunto. El resto del código del asesor se ha trasladado sin cambios. Podrá familiarizarse con el código completo de todas las clases y programas en el anexo.
Para el entrenamiento, hemos creado un modelo utilizando la herramienta NetCreator. El modelo reproducirá íntegramente la arquitectura del modelo entrenado del artículo anterior. Solo hemos eliminado la última capa de normalización SoftMax para que el área de resultados del modelo pueda replicar cualquier resultado de la política de recompensa utilizada.
Como siempre, el modelo ha sido entrenado con datos históricos de EURUSD, utilizando el marco temporal H1. Como muestra de entrenamiento, hemos usado los datos históricos de los dos últimos años.
El rendimiento del modelo entrenado ha sido comprobado en el simulador de estrategias. Para ello, hemos creado el asesor "QRDQN-learning-test.mq". El asesor también se ha basado en asesores similares de artículos anteriores, y su código no ha cambiado significativamente. Encontrará el código completo en el archivo adjunto.
En el simulador de estrategias, el modelo ha mostrado capacidad para generar beneficios en un breve plazo de 2 semanas. Más de la mitad de las transacciones realizadas se han cerrado con beneficios. El beneficio medio por transacción ha sido casi el doble que la pérdida media.


Conclusión
En este artículo hemos presentado otro prometedor método de aprendizaje por refuerzo. Asimismo, hemos creado una clase para implementar el método analizado. Hemos entrenado el modelo y observado su rendimiento en el simulador de estrategias. Los resultados sugieren que resulta posible utilizar el algoritmo de regresión cuantílica en el aprendizaje Q distribuido para implementar modelos capaces de resolver problemas reales del mercado.
Una vez más, querríamos hacer hincapié en que todos los programas de este artículo pretenden simplemente mostrar la tecnología estudiada. Para utilizar los modelos y asesores en transacciones reales, antes será necesario perfeccionarlos y probarlos a fondo.
Enlaces
- Redes neuronales: así de sencillo (Parte 26): Aprendizaje por refuerzo
- Redes neuronales: así de sencillo (Parte 27): Aprendizaje Q profundo (DQN)
- Redes neuronales: así de sencillo (Parte 28): Algoritmo de gradiente de políticas
- Redes neuronales: así de sencillo (Parte 32): Aprendizaje Q distribuido
- A Distributional Perspective on Reinforcement Learning
- Distributional Reinforcement Learning with Quantile Regression
Programas usados en el artículo.
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | QRDQN-learning.mq5 | Asesor | Asesor para la optimización de modelos |
| 2 | QRDQN-learning-test.mq5 | Asesor | Asesor Experto para probar modelos en el Simulador de Estrategias |
| 3 | QRDQN.mqh | Biblioteca de clases | Clase de organización del modelo QR-DQN |
| 4 | NeuroNet.mqh | Biblioteca de clases | Biblioteca para organizar modelos de redes neuronales |
| 5 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL para organizar modelos de redes neuronales |
| 6 | NetCreator.mq5 | Asesor | Herramienta de construcción de modelos |
| 7 | NetCreatotPanel.mqh | Biblioteca de clases | Biblioteca de clases para crear una herramienta |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/11752
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola,
gracias por tu duro trabajo, aprecio tu tiempo y esfuerzo.
Tuve que agarrar VAE del artículo # 22 cuando traté de compilar QRDQN.
Pero corriendo en este error,
'MathRandomNormal' - identificador no declarado VAE.mqh 92 8
Supongo que la biblioteca VAE en # 22 es obsoleto?
Hola,
gracias por tu duro trabajo, aprecio tu tiempo y esfuerzo.
Tuve que agarrar VAE del artículo # 22 cuando traté de compilar QRDQN.
pero corriendo en este error,
'MathRandomNormal' - identificador no declarado VAE.mqh 92 8
Supongo que la biblioteca VAE en # 22 es obsoleto?
Hola, puedes cargar archivos actualizados desde este artículo https://www.mql5.com/es/articles/11619
Hola, puede cargar los archivos actualizados de este artículo https://www.mql5.com/en/articles/11619
Gracias por tu respuesta,
Hice eso y ese error se ha solucionado, pero aparecieron 2 más.
uno
'Create' - expresión de tipo 'void' es ilegal QRDQN.mqh 85 30
2
''AssignArray' - ninguna de las sobrecargas se puede aplicar a la llamada de función QRDQN.mqh 149 19