
Redes neurais de maneira fácil (Parte 33): regressão quantílica em aprendizado Q distribuído,

Conteúdo
- Introdução
- 1. Regressão quantílica
- 2. Implementação usando MQL5
- 3. Teste
- Considerações finais
- Referências
- Programas utilizados no artigo
Introdução
No artigo anterior, apresentamos o aprendizado Q distribuído, que permite aprender a distribuição de probabilidade da recompensa prevista. Aprendemos como prever a probabilidade de receber a recompensa esperada em um intervalo específico de valores. No entanto, é importante notar que o número desses intervalos e a distribuição dos valores de recompensa são hiperparâmetros do modelo. Portanto, para selecionar os parâmetros ideais, é necessário ter conhecimento especializado sobre a distribuição dos valores de recompensa e realizar uma série de testes para selecionar os hiperparâmetros mais adequados.
É importante ressaltar que a abordagem que adotamos, dividindo todo o intervalo de valores possíveis em intervalos iguais, tem suas desvantagens. Para prever a probabilidade de receber uma recompensa em cada um desses intervalos para cada ação, identificamos um neurônio. Na prática, muitas vezes nos deparamos com situações em que a probabilidade de receber uma recompensa em um grande número de intervalos é igual a zero, o que significa que estamos utilizando nossos recursos de forma ineficiente. Seria possível combinar alguns desses intervalos para reduzir o número de operações realizadas e acelerar o treinamento e operação do modelo. Por outro lado, em algumas situações, a probabilidade de receber recompensas em outros intervalos é bastante alta, o que nos leva a querer dividir ainda mais esse intervalo para obter uma imagem mais precisa. Infelizmente, nossa abordagem atual não nos permite criar intervalos de tamanhos diferentes. Para contornar essas limitações, podemos utilizar o algoritmo de regressão quantil proposto em outubro de 2017 no artigo "Distributional Reinforcement Learning with Quantile Regression", que nos permite prever não apenas a probabilidade da recompensa em um intervalo específico, mas também a distribuição da recompensa ao longo de todo o intervalo de valores possíveis.
1. Regressão quantílica
A regressão quantílica é uma técnica que modela a relação entre a distribuição das variáveis independentes e certos quantis da variável alvo.
Quando se discute o uso de regressão quantílica em aprendizado Q distribuído, é importante mencionar que o algoritmo proposto aborda a estimação da distribuição de probabilidade da recompensa esperada. Ao contrário do método anterior de dividir a gama de possíveis valores de recompensa em seções, o novo algoritmo divide o conjunto de recompensas recebidas em vários quantis igualmente prováveis. Isso nos permite obter uma visão mais completa da distribuição da recompensa, e possibilita uma estimativa mais precisa dos valores extremos da distribuição.
O número de quantis analisados é um hiperparâmetro importante na abordagem de regressão quantílica aplicada ao aprendizado Q distribuído. Entretanto, não restringimos a gama de possíveis valores de recompensa, diferentemente da abordagem anterior de dividir em seções. Em vez disso, nosso modelo é treinado para prever os valores medianos dos quantis. Como utilizamos quantis equiprováveis, não teremos quantis com probabilidade zero de receber uma recompensa, além de identificarmos áreas com maior acúmulo de recompensas, as quais serão divididas em quantis menores, proporcionando uma imagem mais precisa da distribuição de probabilidade da recompensa esperada. Além disso, essa abordagem permite identificar variações nas áreas de baixa ou alta densidade de recompensas, que podem ser afetadas pelo estado do ambiente.
Apesar de estarmos lidando com aprendizado Q distribuído, o processo de otimização ainda é baseado na equação de Bellman.

Porém, ao invés de definirmos apenas um valor, precisamos agora definir a distribuição inteira de probabilidade de recompensas. Mas, em essência, a tarefa permanece a mesma. Vamos agora entender melhor essa tarefa.
Conforme mencionado anteriormente, dividimos toda a distribuição de recompensas do conjunto de treinamento em N quantis equiprováveis. Cada quantil representa o nível que a variável aleatória analisada não ultrapassa com uma dada probabilidade. Esses quantis são igualmente espaçados, cobrindo toda a amostra de treinamento.
Na prática, temos um conjunto de amostras de treinamento, e a probabilidade de obter qualquer um desses elementos é "1". Simplesmente não pode haver outro. Afinal, pegamos elementos do conjunto de treinamento.
Ao dividir a amostra de treinamento em N quantis equiprováveis, o primeiro passo é dividir a amostra em N partes iguais, cada uma contendo o mesmo número de elementos. E a probabilidade de escolher um elemento de uma das amostras é 1/N.
Em seguida, cada quantil é definido por dois parâmetros: a probabilidade de selecionar um elemento e o limite superior dos valores de seus elementos. É importante ressaltar que os quantis devem ser classificados em ordem crescente com o acúmulo de probabilidades, ou seja, o limite superior dos valores de cada quantil subsequente é maior que o anterior. Além disso, a probabilidade de um quantil inclui a probabilidade de quantis anteriores. Por exemplo, se uma distribuição tiver um quantil de 0,2 com nível 15, significa que o valor de 20% dos elementos da distribuição não excede 15. No entanto, o passo das probabilidades e o nível dos valores máximos dos quantis podem não ser proporcionais e podem depender da distribuição específica.
O algoritmo em questão consiste em dividir a população em quantis com um passo de probabilidade fixo, e em vez de limites superiores, o modelo é treinado para prever os valores medianos dos quantis.
Para treinar o modelo, é necessário definir os valores alvo. Quando existe um conjunto completo de elementos de uma determinada população, podemos facilmente encontrar o valor médio.
Na prática, não temos um conjunto completo de elementos da população. As recompensas são recebidas do ambiente somente após realizar uma ação e passar para um novo estado. É importante destacar que alterar o algoritmo de treinamento do modelo não afeta o processo de interação com o ambiente. No processo original de aprendizado Q, o modelo é treinado para prever a recompensa média esperada, o que é alcançado mudando iterativamente os resultados do modelo para atingir os indicadores-alvo com um pequeno coeficiente de aprendizado. Durante o processo de aprendizagem, o resultado do modelo é constantemente afetado por uma força de viés em direção ao valor alvo atual. O valor médio é alcançado quando as forças multidirecionais se equilibram, como mostra a figura.

Podemos aplicar uma abordagem semelhante para resolver os problemas do algoritmo em questão. No entanto, há uma particularidade a ser considerada. Esse algoritmo permite encontrar o valor médio de toda a população, que corresponde a um quantil de 0,5. Se aplicarmos esse algoritmo em sua forma mais pura, obteremos os mesmos valores em todos os neurônios da camada de resultados do nosso modelo. Todos eles funcionarão de forma síncrona, como um único neurônio. Entretanto, o objetivo é obter a verdadeira distribuição de valores sobre os quantis analisados.
Para entender a natureza do quantil, consideremos um quantil de 0,25, que corresponde a um quarto da população analisada. Se ignorarmos a distância entre os valores dos elementos, para cada elemento dentro do quantil deve haver três elementos fora do quantil no conjunto total. Nesse sentido, para obter o equilíbrio no ponto 0,25 do quantil, a força para diminuir o valor deve ser três vezes maior do que a força para aumentar o valor do quantil.
Para encontrar o valor de cada quantil, podemos adicionar um fator de correção na equação de Bellman que leve em conta o nível do quantil e a direção do desvio. O fator de correção depende da característica probabilística do quantil,
![]()
que é denotada por τ.
Durante o processo de aprendizagem, utilizamos todas as heurísticas do aprendizado Q clássico, como reprodução de experiência e Target Net.
2. Implementação usando MQL5
Depois de considerar os aspectos teóricos do algoritmo, passamos para a parte prática deste artigo. E veremos uma implementação do algoritmo usando MQL5. No processo de implementação do algoritmo, não criamos novas arquiteturas de camada neural. Em vez disso, efetuamos o processo em uma classe separada chamada CQRDQN. Isso nos permite simplificar o uso do método em Expert Advisors e proteger o usuário de alguns detalhes de implementação. A estrutura da nova classe é mostrada abaixo.
class CQRDQN : protected CNet { private: uint iCountBackProp; protected: uint iNumbers; uint iActions; uint iUpdateTarget; matrix<float> mTaus; //--- CNet cTargetNet; public: /** Constructor */ CQRDQN(void); CQRDQN(CArrayObj *Description) { Create(Description, iActions); } bool Create(CArrayObj *Description, uint actions); /** Destructor */~CQRDQN(void); bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNet::feedForward(inputVals, window, tem); } bool backProp(CBufferFloat *targetVals, float discount, CArrayFloat *nextState, int window = 1, bool tem = true); void getResults(CBufferFloat *&resultVals); int getAction(void); int getSample(void); float getRecentAverageError() { return recentAverageError; } bool Save(string file_name, datetime time, bool common = true) { return CNet::Save(file_name, getRecentAverageError(), (float)iActions, 0, time, common); } virtual bool Save(const int file_handle); virtual bool Load(string file_name, datetime &time, bool common = true); virtual bool Load(const int file_handle); //--- virtual int Type(void) const { return defQRDQN; } virtual bool TrainMode(bool flag) { return CNet::TrainMode(flag); } virtual bool GetLayerOutput(uint layer, CBufferFloat *&result) { return CNet::GetLayerOutput(layer, result); } //--- virtual void SetUpdateTarget(uint batch) { iUpdateTarget = batch; } virtual bool UpdateTarget(string file_name); //--- virtual bool SetActions(uint actions); };
Criamos uma nova classe que herdará a funcionalidade da classe responsável por organizar o trabalho de nossos modelos de rede neural CNet. Isso permitirá a construção de um novo algoritmo específico para trabalhar com esse modelo.
Para armazenar os principais parâmetros do nosso algoritmo, criaremos as seguintes variáveis:
- iNumbers — número de neurônios na sequência que descreve a distribuição de uma ação;
- iActions — número de ações possíveis;
- iUpdateTarget — frequência de atualização dos parâmetros do modelo Target Net;
- mTaus — matriz para registrar características probabilísticas de quantis;
- cTargetNet — ponteiro para um objeto Target Net.
É importante notar que vamos anotar na matriz mTaus os valores medianos das probabilidades de cada quantil.
No construtor da classe, definimos os valores iniciais das variáveis especificadas.
CQRDQN::CQRDQN() : iNumbers(31), iActions(2), iUpdateTarget(1000) { mTaus = matrix<float>::Ones(1, iNumbers) / iNumbers; mTaus[0, 0] /= 2; mTaus = mTaus.CumSum(0); cTargetNet.Create(NULL); Create(NULL, iActions); }
Como na própria classe de elaboração do modelo da rede neural CNet, além do construtor sem parâmetros, criaremos uma sobrecarga de método indicando a arquitetura do modelo que está sendo criado.
CQRDQN(CArrayObj *Description) { Create(Description, iActions); }
Vamos criar o modelo diretamente no método Create. Nos parâmetros, este método recebe um ponteiro para um array que descreve a arquitetura do modelo criado e a quantidade de ações possíveis do agente.
bool CQRDQN::Create(CArrayObj *Description, uint actions) { if(actions <= 0 || !CNet::Create(Description)) return false;
Dentro do método, primeiramente verificamos se o parâmetro que especifica o número de ações do agente está correto e, em seguida, chamamos o método correspondente na classe pai. Esse método organiza todos os controles necessários relacionados ao objeto de descrição da arquitetura do modelo criado e constrói o processo de criação de um novo modelo. Neste ponto, verificamos apenas a lógica da execução das operações da classe pai.
Uma vez que o novo modelo é criado com sucesso, extraímos a camada de resultados do modelo criado. Com base nas informações sobre o tamanho dessa camada e o número de ações possíveis do agente, preenchemos a matriz de características probabilísticas dos quantis mTaus. O número de linhas nesta matriz é igual ao tamanho da distribuição de probabilidade da recompensa de uma ação. E como as probabilidades de cada quantil são definidas antes do início do treinamento para serem as mesmas para todas as ações possíveis do agente com um passo fixo igual, usaremos uma matriz vetorial com uma linha. Optamos por usar uma matriz em vez de um vetor, visando o futuro desenvolvimento do modelo com a possível incorporação de uma maior variabilidade nas distribuições de probabilidade para as ações.
int last_layer = Description.Total() - 1; CLayer *layer = layers.At(last_layer); if(!layer) return false; CNeuronBaseOCL *neuron = layer.At(0); if(!neuron) return false; iActions = actions; iNumbers = neuron.Neurons() / actions; mTaus = matrix<float>::Ones(1, iNumbers) / iNumbers; mTaus[0, 0] /= 2; mTaus = mTaus.CumSum(0); cTargetNet.Create(NULL); //--- return true; }
Observe que, no estágio inicial, redefinimos Target Net. Essa abordagem é usada para evitar o treinamento de um novo modelo em variáveis absolutamente aleatórias de um modelo não treinado.
Para realizar a propagação, usaremos totalmente um método semelhante da classe pai.
bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNet::feedForward(inputVals, window, tem); }
No método backProp, precisamos lidar com alguns desafios. Como você deve se lembrar, a reação do ambiente a cada ação do nosso agente é uma recompensa. No processo de aprendizado Q clássico, definimos uma política de recompensa e, como as ações possíveis do agente são mutuamente exclusivas e opostas, podemos determinar a recompensa da ação oposta pela recompensa do ambiente por uma ação. Isso nos permite, em cada iteração da retropropagação, fornecer valores-alvo para todas as ações possíveis, tornando o processo de aprendizagem mais estável e rápido. No entanto, no processo de aprendizado Q distribuído, lidamos com todo um vetor de valores-alvo para cada ação. Em um artigo anterior, desenvolvemos um novo processo para criar um tensor de valores-alvo do modelo no EA de treinamento do modelo e um novo bloco para decodificar os resultados do modelo antes de executar uma ação no EA para verificar o desempenho do modelo treinado.
Com a criação de uma nova classe de organização de processos, podemos agora ocultar todo esse processo do usuário e tornar seu trabalho com o modelo mais simples e compreensível. Isso é semelhante ao trabalho com o modelo de aprendizado Q clássico, em que o ambiente retorna apenas um valor de recompensa discreto por ação e todo o processo de conversão dessa recompensa discreta em um vetor de distribuição para cada ação é efetuado no corpo do método de retropropagação.
Além disso, uma vantagem adicional do uso dessa nova classe é a ocultação do Target Net, usado pelo aprendizado Q para prever recompensas futuras. Anteriormente, o usuário precisava trabalhar com dois modelos, mas agora podemos encapsular todo o trabalho da Target Net dentro dos métodos da nossa classe, facilitando o trabalho do usuário. No entanto, isso exigiu a alteração dos parâmetros do método de retropropagação. Para garantir a correta execução do processo de retropropagação, além dos valores-alvo, o usuário também deve fornecer um novo estado do sistema.
Dentro do método de retropropagação, primeiro verificamos se o ponteiro recebido para o vetor de valores-alvo é correto e garantimos que o tamanho do vetor resultante seja igual ao número de ações possíveis do agente.
bool CQRDQN::backProp(CBufferFloat *targetVals, float discount, CArrayFloat *nextState=NULL, int window = 1, bool tem = true) { //--- if(!targetVals) return false; vectorf target; if(!targetVals.GetData(target) || target.Size() != iActions) return false;
Em seguida, verificamos a exatidão do ponteiro para o vetor que descreve o novo estado do sistema. E, se necessário, rodamos a propagação Target Net. Depois disso, determinamos a recompensa máxima possível e ajustamos a remuneração recebida do meio ambiente para rendimentos futuros, levando em consideração o fator de desconto.
if(!!nextState) { if(!cTargetNet.feedForward(nextState, window, tem)) return false; vectorf temp; cTargetNet.getResults(targetVals); if(!targetVals.GetData(temp)) return false; matrixf q = matrixf::Zeros(1, temp.Size()); if(!q.Row(temp, 0) || !q.Reshape(iActions, iNumbers)) return false; temp = q.Mean(0); target = target + discount * temp.Max(); }
Usaremos a seguinte fórmula para atualizar os parâmetros do modelo.
![]()
No entanto, é importante destacar que ao implementar a fórmula acima neste método, não utilizamos o coeficiente de aprendizado. Aqui está um pequeno truque. No corpo deste método, por mais estranho que pareça, não atualizamos diretamente os parâmetros do modelo. Em vez disso, criamos um vetor de resultados-alvo para o nosso modelo. A atualização direta dos parâmetros do modelo será realizada no método de classe pai com o mesmo nome. Nesse método, passamos o tensor completo dos resultados-alvo do modelo e, em seguida, levamos em consideração o coeficiente de aprendizado ao atualizar os parâmetros do modelo.
Nesta fase, já temos uma recompensa do ambiente, considerando possíveis benefícios futuros. Para criar um vetor de valores-alvo, precisamos apenas dos resultados mais recentes da propagação de nosso modelo. Vamos armazená-los na matriz local Q.
vectorf quantils; getResults(targetVals); if(!targetVals.GetData(quantils)) return false; matrixf Q = matrixf::Zeros(1, quantils.Size()); if(!Q.Row(quantils, 0) || !Q.Reshape(iActions, iNumbers)) return false;
Agora, podemos criar o buffer de valores-alvo necessário para o nosso modelo. Para isso, usamos um loop para gerar a criação de um vetor de valores-alvo de níveis de quantis para cada ação individual possível do agente. É importante notar que o uso de operações matriciais e vetoriais requer alguns truques e mudanças na abordagem ao construir algoritmos, mas também permite reduzir o uso de loops e aumentar a velocidade de execução do programa.
Nesse caso, o uso de operações vetoriais nos permite abandonar o sistema de loops aninhados, no qual teríamos que iterar sobre todas as ações e todos os elementos da distribuição para cada ação possível do agente. Em vez disso, usamos apenas uma iteração das ações possíveis do agente. O número de iterações será dezenas de vezes menor do que o número de iterações do loop excluído de elementos da distribuição de probabilidade. No entanto, o preço disso foi a rejeição do operador condicional. Não podemos simplesmente comparar dois elementos de vetores para escolher uma ação dependendo do resultado da comparação.
Portanto, precisamos realizar ambas as ramificações das operações para todos os elementos dos vetores. Para não distorcer o resultado esperado das operações, criamos dois vetores de diferenças entre a recompensa recebida do ambiente e o resultado da última propagação. Em seguida, definimos valores negativos como zero em um vetor e, no segundo, definimos valores positivos como zero. Depois de multiplicar os vetores obtidos pelos correspondentes coeficientes de ajuste da força de influência sobre o valor médio do quantil, obtemos os valores corretivos desejados. A soma dos vetores recebidos e os últimos resultados da propagação nos darão os valores-alvo necessários para a retropropagação do nosso modelo.
for(uint a = 0; a < iActions; a++) { vectorf q = Q.Row(a); vectorf dp = q - target[a], dn = dp; if(!dp.Clip(0, FLT_MAX) || !dn.Clip(-FLT_MAX, 0)) return false; dp = (mTaus.Row(0) - 1) * dp; dn = mTaus.Row(0) * dn * (-1); if(!Q.Row(dp + dn + q, a)) return false; } if(!targetVals.AssignArray(Q)) return false;
Depois que todas as iterações do loop forem concluídas, atualizamos os valores do buffer de valores-alvo.
Em seguida, fazemos um pequeno trabalho auxiliar quanto ao modelo Target Net. Implementamos um contador de iterações para a retropropagação. E quando o laço for concluído, atualizamos o modelo Target Net.
if(iCountBackProp >= iUpdateTarget) { #ifdef FileName if(UpdateTarget(FileName + ".nnw")) #else if(UpdateTarget("QRDQN.upd")) #endif iCountBackProp = 0; } else iCountBackProp++;
É importante prestar atenção às macro substituições no operador de comparação quando o laço de retropropagação for concluído. Assim como na atualização do modelo Target Net, não copiamos diretamente os parâmetros de um modelo para outro. Em vez disso, usamos o mecanismo de salvar e restaurar o modelo a partir de um arquivo. Para implementar essa iteração, precisamos de um nome de arquivo exclusivo.
Em todos os meus modelos, uso a macro substituição FileName para gerar um nome de arquivo exclusivo, dependendo do Expert Advisor, instrumento e período gráfico utilizado. Essa macro substituição é atribuída diretamente no Expert Advisor. A macro substituição implementada aqui nos permite verificar o propósito da macro substituição para gerar um nome de arquivo no Expert Advisor. E se houver um propósito, usamos essa macro substituição para salvar e restaurar arquivos. Caso contrário, o nome de arquivo padrão será usado.
#define FileName Symb.Name()+"_"+EnumToString(TimeFrame)+"_"+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
No final do nosso método, chamamos o método de retorno da classe pai e passamos o tensor de resultados-alvo preparado como parâmetros para ele. E retornaremos o resultado lógico da execução das operações do método da classe pai para o programa de chamada.
return CNet::backProp(targetVals);
}
Assim, ocultamos do usuário o uso de um modelo de distribuição de probabilidade durante a retropropagação, e o ambiente retorna apenas uma recompensa discreta para cada ação. Agora, a chamada do método de retropropagação é semelhante ao aprendizado Q clássico, mas evitamos que o usuário tenha que controlar o segundo modelo Target Net, o que aumenta a usabilidade do nosso modelo. No entanto, a questão da propagação ainda precisa ser resolvida.
Conforme mencionado anteriormente, ao executar a propagação, usamos o método da classe pai, que não interfere nas operações de propagação, uma vez que ele retorna apenas o resultado lógico da operação. No entanto, ao tentar obter os resultados da propagação, há uma lacuna entre esses resultados e os valores-alvo da retropropagação. Por isso, precisamos redefinir o método de obtenção dos resultados da propagação para torná-los comparáveis com os resultados desejados da retropropagação.
É importante destacar que usamos quantis equiprováveis por uma razão. Podemos facilmente obter o valor médio de toda a distribuição gerada para cada ação possível do agente e usá-lo como a recompensa esperada. Graças às operações de matriz, conseguimos construir o algoritmo do método completamente sem o uso de laços.
No início do método, chamamos o método de classe pai de mesmo nome, que implementa todos os controles e operações necessárias para copiar os resultados da propagação para o buffer de dados. Em seguida, transferimos os dados recebidos para a matriz, que é reformatada em uma matriz tabular com o número de linhas igual ao número de ações possíveis do agente. Cada linha é um vetor da distribuição de probabilidade da recompensa esperada para cada ação individual do agente. Em seguida, usamos a função matricial Mean para determinar os valores médios para todas as ações possíveis do agente. Transferimos o resultado para o buffer de dados e o devolvemos ao programa chamador.
void CQRDQN::getResults(CBufferFloat *&resultVals) { CNet::getResults(resultVals); if(!resultVals) return; vectorf temp; if(!resultVals.GetData(temp)) { delete resultVals; return; } matrixf q; if(!q.Init(1, temp.Size()) || !q.Row(temp, 0) || !q.Reshape(iActions, iNumbers)) { delete resultVals; return; } //--- if(!resultVals.AssignArray(q.Mean(1))) { delete resultVals; return; } //--- }
É possível que haja perplexidade e questionamentos sobre por que fizemos tudo isso se acabamos voltando ao valor médio, que o aprendizado Q original ensina. A probabilidade da média da amostra não é igual à média das probabilidades das subamostras da mesma população. O aprendizado Q original ensina a probabilidade da média da amostra. Enquanto o aprendizado Q distribuído calcula vários médias para cada quantil. E então tiramos a média desses valores probabilísticos.
O aprendizado Q distribuído aprende vários meios para cada quantil, o que torna o processo de treinamento do modelo mais estável e menos tendencioso. Os autores do método apresentam os resultados do treinamento de modelos em 57 jogos Atari em comparação com outros algoritmos, demonstrando que o resultado médio é quase 4 vezes maior do que o resultado do aprendizado Q original (DQN). Abaixo está uma tabela de resultados do artigo original [6]
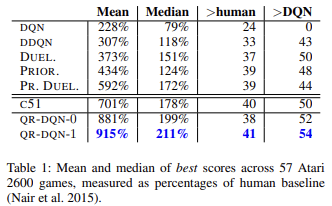
Podemos melhorar ainda mais a usabilidade do nosso modelo com a criação de uma nova classe. Antes, para cada Expert Advisor de teste do modelo de aprendizado por reforço, precisávamos criar vários métodos para escolher a ação com base nos resultados da propagação do modelo treinado. Com a nova classe, podemos criar métodos que realizam essa funcionalidade de forma mais organizada. Para selecionar a ação com a maior recompensa esperada de forma gananciosa, podemos criar um método chamado getAction. Seu algoritmo é simples e utiliza o método getResults da propagação anterior. Basta selecionar o elemento com o valor máximo no buffer de resultados obtido.
int CQRDQN::getAction(void) { CBufferFloat *temp; getResults(temp); if(!temp) return -1; //--- return temp.Maximum(0, temp.Total()); }
A estratégia ɛ-gananciosa de escolha de ação não foi implementada, já que ela é utilizada durante o treinamento do modelo para aumentar o nível de aprendizado do ambiente. Nossa política de recompensas permite ao usuário optar por não usar essa estratégia, já que, durante o processo de aprendizado, fornecemos objetivos para todas as ações possíveis do agente simultaneamente.
O segundo método que criaremos é o getSample, que será responsável por selecionar aleatoriamente uma ação da distribuição de probabilidade, onde uma recompensa maior terá uma probabilidade maior de ser escolhida. Para evitar cópias desnecessárias de dados entre matrizes e buffers, parcialmente repetiremos o algoritmo do método getResults.
int CQRDQN::getSample(void) { CBufferFloat* resultVals; CNet::getResults(resultVals); if(!resultVals) return -1; vectorf temp; if(!resultVals.GetData(temp)) { delete resultVals; return -1; } delete resultVals; matrixf q; if(!q.Init(1, temp.Size()) || !q.Row(temp, 0) || !q.Reshape(iActions, iNumbers)) { delete resultVals; return -1; }
Depois disso, normalizamos os resultados da propagação usando a função SoftMax. Estas serão as probabilidades de escolha das ações do agente.
if(!q.Mean(1).Activation(temp, AF_SOFTMAX)) return -1; temp = temp.CumSum();
Coletamos o vetor de totais cumulativos de probabilidades e realizamos a amostragem do vetor resultante da distribuição de probabilidade.
int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(random >= 1) return (int)temp.Size() - 1; for(int i = 0; i < (int)temp.Size(); i++) if(random <= temp[i] && temp[i] > 0) return i; //--- return -1; }
O resultado da amostragem será retornado ao programa chamador.
Falamos sobre vários métodos para o treinamento do nosso modelo, incluindo propagação e retropropagação, bem como métodos para obter os resultados do modelo. Entretanto, ainda falta responder algumas questões, incluindo como atualizar o modelo Target Net. Embora esse método tenha sido mencionado na nossa discussão sobre retropropagação, ele é chamado por um método diferente da classe. Apesar de protegermos o usuário da necessidade de monitorar o status do Target Net, decidimos tornar o método UpdateTarget público para permitir que o usuário tenha total controle do processo de atualização, se assim desejar.
O algoritmo do método UpdateTarget é simples. Primeiramente, chamamos o método save do objeto atual para salvar os dados do modelo treinado. Em seguida, invocamos o método de recuperação de dados do Target Net, controlando o processo de execução das operações. Após uma atualização bem-sucedida do modelo Target Net, zeramos o contador de iterações da retropropagação. Embora tenhamos protegido o usuário da necessidade de monitorar o status do Target Net, decidimos tornar o método público para dar-lhe a liberdade de escolha e o controle total sobre o processo, se desejar.
bool CQRDQN::UpdateTarget(string file_name) { if(!Save(file_name, 0, false)) return false; float error, undefine, forecast; datetime time; if(!cTargetNet.Load(file_name, error, undefine, forecast, time, false)) return false; iCountBackProp = 0; //--- return true; }
Você precisa estar ciente das diferenças entre as classes de objetos que estamos usando. Estamos trabalhando com a nova classe CQRDQN, enquanto Target Net é uma instância da classe pai CNet. O fato é que usamos apenas a funcionalidade de propagação do Target Net, que não foi modificada em nossa classe. Não há problemas em usar a classe pai. No entanto, se usarmos uma instância da classe CQRDQN para Target Net, podemos acabar criando recursivamente um novo objeto Target Net interno. Esse processo recorrente pode causar erros críticos. Portanto, esse detalhe aparentemente insignificante pode ter consequências significativas para o funcionamento de todo o programa.
Neste texto, abordamos a principal funcionalidade da classe CQRDQN, que implementa o algoritmo de regressão quantílica em aprendizado Q distribuído (QR-DQN). Esse método foi apresentado em outubro de 2017 no artigo intitulado "Distributional Reinforcement Learning with Quantile Regression".
A classe também inclui métodos para salvar (Save) e restaurar (Load) o modelo. As mudanças realizadas nesses métodos não são tão complicadas e podem ser encontradas no anexo. Agora, é hora de testar a nova classe.
3. Teste
Começamos a testar o trabalho de uma nova classe treinando o modelo. Para o treinamento, criamos o Expert Advisor "QRDQN-learning.mq5" com base no EA de aprendizado Q original "Q-learning.mq5". Alteramos a classe do modelo treinado neste EA e removemos a declaração de instância do modelo Target Net.
CSymbolInfo Symb;
MqlRates Rates[];
CQRDQN StudyNet;
CBufferFloat *TempData;
CiRSI RSI;
CiCCI CCI;
CiATR ATR;
CiMACD MACD; No método de inicialização do Expert Advisor, carregamos o modelo de um arquivo criado anteriormente e forçamos o modo de aprendizagem de todas as camadas neurais. Determinamos a profundidade do histórico analisado pelo tamanho da camada de dados de origem e damos ao modelo o tamanho da área de ações admissíveis. Especificamos também o período de atualização para o Target Net, embora tenhamos escolhido um valor superestimado, pois pretendemos gerenciar o processo de atualização dos modelos manualmente.
int OnInit() { //--- ......... ......... //--- if(!StudyNet.Load(FileName + ".nnw", dtStudied, false)) return INIT_FAILED; if(!StudyNet.TrainMode(true)) return INIT_FAILED; //--- if(!StudyNet.GetLayerOutput(0, TempData)) return INIT_FAILED; HistoryBars = TempData.Total() / 12; if(!StudyNet.SetActions(Actions)) return INIT_PARAMETERS_INCORRECT; StudyNet.SetUpdateTarget(1000000); //--- ........ //--- return(INIT_SUCCEEDED); }
A função Train é responsável pelo processo de treinamento do modelo.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
Nessa função, definimos o período de treinamento e carregamos os dados históricos, o que é mantido igual na versão original.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Em seguida, realizamos um sistema de loops aninhados para o treinamento do modelo. O loop externo faz a contagem regressiva das épocas de treinamento para atualizar o modelo Target Net.
int total = bars - (int)HistoryBars - 240; bool use_target = false; //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int i = 0; uint ticks = GetTickCount(); int count = 0; int total_max = 0;
Em um loop aninhado, realizamos a propagação e a retropropagação. Aqui preparamos primeiro os dados históricos para descrever dois estados subsequentes do sistema. Um será usado para propagação do modelo de treinamento. O segundo será Target Net.
for(int batch = 0; batch < (Batch * UpdateTarget); batch++) { i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * total + 240); State1.Clear(); State2.Clear(); int r = i + (int)HistoryBars; if(r > bars) continue; for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State1.Add((float)Rates[bar_t].close - open) || !State1.Add((float)Rates[bar_t].high - open) || !State1.Add((float)Rates[bar_t].low - open) || !State1.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State1.Add(sTime.hour) || !State1.Add(sTime.day_of_week) || !State1.Add(sTime.mon) || !State1.Add(rsi) || !State1.Add(cci) || !State1.Add(atr) || !State1.Add(macd) || !State1.Add(sign)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!use_target) continue; //--- bar_t --; open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); rsi = (float)RSI.Main(bar_t); cci = (float)CCI.Main(bar_t); atr = (float)ATR.Main(bar_t); macd = (float)MACD.Main(bar_t); sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State2.Add((float)Rates[bar_t].close - open) || !State2.Add((float)Rates[bar_t].high - open) || !State2.Add((float)Rates[bar_t].low - open) || !State2.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State2.Add(sTime.hour) || !State2.Add(sTime.day_of_week) || !State2.Add(sTime.mon) || !State2.Add(rsi) || !State2.Add(cci) || !State2.Add(atr) || !State2.Add(macd) || !State2.Add(sign)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
E realizamos uma propagação do modelo treinado.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } if(State1.Total() < (int)HistoryBars * 12 || (use_target && State2.Total() < (int)HistoryBars * 12)) continue; if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return;
Depois disso, formamos um pacote de recompensas para todas as ações possíveis do agente e chamamos o método de retropropagação do modelo principal.
Rewards.BufferInit(Actions, 0); double reward = Rates[i].close - Rates[i].open; if(reward >= 0) { if(!Rewards.Update(0, (float)(2 * reward))) return; if(!Rewards.Update(1, (float)(-5 * reward))) return; if(!Rewards.Update(2, (float) - reward)) return; } else { if(!Rewards.Update(0, (float)(5 * reward))) return; if(!Rewards.Update(1, (float)(-2 * reward))) return; if(!Rewards.Update(2, (float)reward)) return; }
Observe que, de acordo com o método de retropropagação substituído, nos parâmetros do método, passamos não apenas o buffer de recompensa, mas também o estado atual subsequente. Além disso, removemos o bloco de trabalho com o Target Net e ajustamos a recompensa pelo rendimento esperado dos estados futuros.
if(!StudyNet.backProp(GetPointer(Rewards), DiscountFactor, (use_target ? GetPointer(State2) : NULL), 12, true)) return;
E exibimos informações sobre o andamento do processo no gráfico do instrumento.
if(GetTickCount() - ticks > 500) { Comment(StringFormat("%.2f%%", batch * 100.0 / (double)(Batch * UpdateTarget))); ticks = GetTickCount(); } }
Com o fim das operações de loop aninhadas, verificamos o erro do modelo atual. Caso este erro seja menor que o erro mínimo registrado até o momento, salvamos o estado atual do modelo e atualizamos o Target Net.
if(StudyNet.getRecentAverageError() <= min_loss) { if(!StudyNet.UpdateTarget(FileName + ".nnw")) continue; use_target = true; min_loss = StudyNet.getRecentAverageError(); } PrintFormat("Iteration %d, loss %.8f", iter, StudyNet.getRecentAverageError()); } Comment(""); //--- PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); }
Com essas operações, finalizamos o loop externo e a função de aprendizado como um todo. O código restante do EA foi transferido sem alterações. O código completo de todas as classes e programas pode ser encontrado no anexo.
Para o treinamento, utilizou-se uma ferramenta chamada NetCreator para criar um modelo que reproduzisse a arquitetura do modelo treinado no artigo anterior. A única diferença foi a remoção da última camada de normalização SoftMax, para que a área de resultados do modelo pudesse replicar quaisquer políticas de recompensa utilizadas.
Como sempre, o modelo foi treinado usando dados históricos do EURUSD, período H1. Dados históricos dos últimos 2 anos foram usados como amostra de treinamento.
O modelo treinado foi testado no testador de estratégia por meio do EA "QRDQN-learning-test.mq", o qual foi criado com base em Expert Advisors semelhantes de artigos anteriores. O código do EA não sofreu grandes alterações e pode ser encontrado na íntegra no anexo.
Os resultados do teste foram satisfatórios, demonstrando a capacidade do modelo em gerar lucro em um curto período de tempo de 2 semanas, com mais da metade das operações de negociação encerradas em lucro. O lucro médio por negociação foi quase duas vezes maior do que a perda média.


Considerações finais
Neste artigo, apresentamos um método promissor de aprendizado por reforço e implementamos sua classe correspondente. Treinamos o modelo e testamos seu desempenho no testador de estratégia. Os resultados obtidos sugerem que é possível utilizar o algoritmo de regressão quantílica em aprendizado Q distribuído para resolver problemas reais de mercado.
É importante lembrar que os programas apresentados aqui são apenas para fins de demonstração e que para utilizá-los em negociações reais, é necessário um refinamento e testes abrangentes.
Referências
- Redes neurais de maneira fácil (Parte 26): aprendizado por reforço
- Redes neurais de maneira fácil (Parte 27): aprendizado Q profundo (DQN)
- Redes neurais de maneira fácil (Parte 28): algoritmo de gradiente de política
- Redes neurais de maneira fácil (Parte 32): Aprendizado Q distribuído
- A Distributional Perspective on Reinforcement Learning
- Distributional Reinforcement Learning with Quantile Regression
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | QRDQN-learning.mq5 | EA | EA para otimização de modelos |
| 2 | QRDQN-learning-test.mq5 | EA | EA para prova do modelo no testador de estratégia |
| 3 | QRDQN.mqh | Biblioteca de classes | Classe de organização do modelo QR-DQN |
| 4 | NeuroNet.mqh | Biblioteca de classes | Biblioteca para preparar modelos de redes neurais |
| 5 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL para manusear modelos de redes neurais |
| 6 | NetCreator.mq5 | EA | Ferramenta para construção de modelos |
| 7 | NetCreatotPanel.mqh | Biblioteca de classes | Biblioteca da classe para criação da ferramenta |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/11752
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Guia Prático MQL5 — Serviços
Guia Prático MQL5 — Serviços
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Olá,
obrigado por seu trabalho árduo, agradeço seu tempo e esforço.
Tive que pegar o VAE do artigo nº 22 quando tentei compilar o QRDQN.
Mas estou encontrando este erro,
'MathRandomNormal' - identificador não declarado VAE.mqh 92 8
Suponho que a biblioteca VAE do artigo 22 esteja desatualizada?
Olá,
obrigado por seu trabalho árduo, agradeço seu tempo e esforço.
Tive que pegar o VAE do artigo nº 22 quando tentei compilar o QRDQN.
mas estou encontrando esse erro,
'MathRandomNormal' - identificador não declarado VAE.mqh 92 8
Suponho que a biblioteca VAE no número 22 esteja desatualizada?
Olá, você pode carregar os arquivos atualizados deste artigo https://www.mql5.com/pt/articles/11619
Olá, você pode carregar os arquivos atualizados deste artigo https://www.mql5.com/en/articles/11619
Obrigado por sua resposta,
Fiz isso e o erro foi corrigido, mas apareceram mais dois.
um
'Create' - expressão do tipo 'void' é ilegal QRDQN.mqh 85 30
2
''AssignArray' - nenhuma das sobrecargas pode ser aplicada à chamada de função QRDQN.mqh 149 19