
Neuronale Netze leicht gemacht (Teil 20): Autoencoder

Inhalt
- Einführung
- 1. Architektur der Autoencoder
- 2. Klassische Probleme, die von Autoencodern gelöst werden
- 3. Vergleich von Autoencoder mit PCA
- 4. Mögliche Anwendungen für Autoencoder im Handel
- 5. Praktische Versuche
- Schlussfolgerung
- Liste der Referenzen
- Programme, die im diesem Artikel verwendet werden
Einführung
Wir untersuchen weiterhin Methoden des unüberwachten Lernens. In früheren Artikeln haben wir bereits Clustering-, Datenkomprimierungs- und Assoziationsregel-Mining-Algorithmen analysiert. Die bisher betrachteten unüberwachten Algorithmen verwenden jedoch keine neuronalen Netze. In diesem Artikel kehren wir zum Studium neuronaler Netze zurück. Dieses Mal werden wir uns mit Autoencodern beschäftigen.
1. Architektur von Autoencoder
Bevor wir mit der Beschreibung der Autoencoder-Architektur fortfahren, werfen wir einen Blick zurück auf die Trainingsmethoden für neuronale Netze mit überwachten Lernalgorithmen. Bei der Untersuchung der Algorithmen haben wir Paare von markierten Daten verwendet, die aus dem Muster und dem Zielergebnis bestehen. Wir haben die Gewichte so optimiert, dass der Fehler zwischen dem Ergebnis der Operation des neuronalen Netzes und dem Zielwert minimiert wird.
Was kann ein neuronales Netz in diesem Fall lernen? Sie wird genau lernen, was wir von ihr erwarten. Das heißt, es wird die Merkmale finden, die das Zielergebnis beeinflussen. Allerdings gibt das Netz den Merkmalen, die sich nicht auf das Zielergebnis auswirken oder deren Wirkung unbedeutend ist, kein Gewicht. Das Modell bewegt sich also in eine recht enge, definierte Richtung. Daran ist nichts auszusetzen. Das Modell erfüllt perfekt, was wir von ihm erwarten.
Aber es gibt auch eine andere Seite der Medaille. Wir sind bereits auf das Konzept des Transfer-Lernens gestoßen, das die Verwendung eines zuvor trainierten Modells zur Lösung neuer Probleme impliziert. In diesem Fall werden nur dann gute Ergebnisse erzielt, wenn die vorherigen und neuen Zielwerte von denselben Merkmalen abhängen. Andernfalls kann die Leistung des Modells durch die fehlenden Merkmale beeinträchtigt werden, die in der vorangegangenen Trainingsphase auf Null gesetzt wurden.
Wie wirkt sich dies auf die Aufgabenlösung aus? Unsere Welt ist nicht statisch, sie verändert sich ständig. Die Markttreiber von heute können schon morgen ihren Einfluss verlieren. Der Markt wird von anderen Kräften bestimmt. Dies schränkt die Lebensdauer unseres Modells ein. Das ist ganz offensichtlich. Zum Beispiel überprüfen Händler ihre Strategien von Zeit zu Zeit. Dies wird auch durch die Rentabilität von algorithmischen Handelsrobotern bestätigt, die mit klassischen Methoden zur Beschreibung von Strategien entwickelt wurden.
Als wir begannen, neuronale Netze zu untersuchen, erwarteten wir, dass der Einsatz von künstlicher Intelligenz die Lebensdauer des Modells verlängern würde. Wenn wir von Zeit zu Zeit zusätzliche Schulungen durchführen, können wir über einen sehr langen Zeitraum hinweg Gewinne erzielen.
Um die mit der oben genannten Eigenschaft verbundenen Risiken zu minimieren, verwenden wir das Repräsentations- oder Merkmalslernen, eines der Gebiete des unüberwachten Lernens. Das Repräsentationslernen kombiniert eine Reihe von Algorithmen, die automatisch Merkmale aus Rohdaten extrahieren. Clustering- und Dimensionalitätsreduktionsalgorithmen, die wir zuvor betrachtet haben, beziehen sich ebenfalls auf Repräsentationslernen. Wir haben in diesen Algorithmen lineare Transformationen verwendet. Autoencoder ermöglichen das Studium komplexerer Formen.
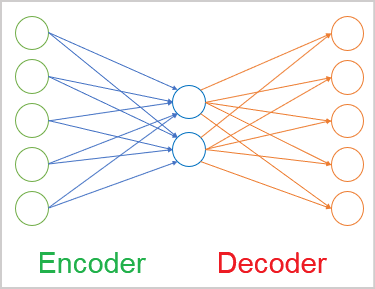
Im allgemeinen Fall ist der Autoencoder (Selbstprogrammierend) ein neuronales Netz, das aus zwei Encoder- und Decoderblöcken besteht. Die Quelldatenschicht des Encoders und die Ergebnisschicht des Decoders enthalten die gleiche Anzahl von Elementen. Dazwischen befindet sich eine verborgene Schicht, die in der Regel kleiner ist als die Quelldaten. Während des Lernprozesses bilden die Neuronen dieser Schicht einen latenten (versteckten) Zustand, der die Quelldaten in komprimierter Form beschreiben kann.
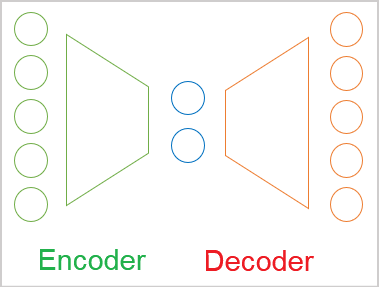
Dies ähnelt dem Datenkomprimierungsproblem, das wir mit der Methode der Hauptkomponentenanalyse gelöst haben. Es gibt jedoch Unterschiede in den Ansätzen, auf die wir später noch eingehen werden.
Wie bereits erwähnt, ist ein Autoencoder ein neuronales Netz. Es wird nach der Backpropagation-Methode trainiert. Der Trick besteht darin, dass wir, da wir nicht gekennzeichnete Daten verwenden, das Modell zunächst darauf trainieren, die Daten mithilfe eines Encoders auf die Größe des latenten Zustands zu komprimieren. Dann wird das Modell im Decoder die Daten mit minimalem Informationsverlust in den ursprünglichen Zustand zurückversetzen.
Daher trainieren wir den Autoencoder mit der bereits bekannten Backpropagation-Methode. Die Trainingsstichprobe selbst wird als Zielergebnis verwendet.
Die Architektur der neuronalen Schichten kann unterschiedlich sein. In der einfachsten Version können dies vollständig verbundene Schichten sein. Faltungsmodelle werden häufig verwendet, um Merkmale aus Bildern zu extrahieren.
Für die Arbeit mit Sequenzen können wiederkehrende Modelle und Aufmerksamkeitsalgorithmen verwendet werden. Auf all diese Einzelheiten wird in künftigen Artikeln eingegangen werden.
2. Klassische Probleme, die von Autoencodern gelöst werden
Trotz des eher untypischen Ansatzes für das Training von Autoencodern können diese bei der Lösung einer ganzen Reihe von Problemen eingesetzt werden. In erster Linie handelt es sich dabei um Datenkomprimierungs- und Vorverarbeitungsaufgaben...
Datenkomprimierungsalgorithmen lassen sich in zwei Typen unterteilen:
- Komprimierung mit Verlusten
- Komprimierung ohne Verluste
Ein Beispiel für Datenkomprimierung mit Verlusten ist die Hauptkomponentenanalyse (PCA), die wir bereits in einem früheren Artikel behandelt haben. Bei der Auswahl der Komponenten haben wir darauf geachtet, dass der Informationsverlust möglichst gering ist.
Ein Beispiel für verlustfreie Datenkompression sind verschiedene Archivierungsprogramme und Zipper. Wir wollen nicht, dass nach dem Entpacken Daten verloren gehen.
Theoretisch kann ein Autoencoder mit beliebigen Daten trainiert werden. Mit dem Kodierer können Daten komprimiert und mit dem Dekodierer können die ursprünglichen Daten wiederhergestellt werden. Dies geschieht auf der Grundlage des übergebenen latenten Status. Je nach Komplexitätsgrad des Autoencoder-Modells kann es Kompression mit und ohne Verluste geben. Natürlich erfordert die verlustfreie Datenkompression komplexere Modelle. In der Telekommunikation wird es häufig eingesetzt, um die Qualität der Datenübertragung zu verbessern und gleichzeitig den Datenverkehr zu reduzieren. Dies erhöht letztendlich den Durchsatz der verwendeten Netze.
Nach der Komprimierung folgt die Vorverarbeitung der Quelldaten. So wird beispielsweise die Datenkomprimierung mit Hilfe von Autoencodern eingesetzt, um das Problem der Dimensionalität zu lösen. Viele Methoden des maschinellen Lernens funktionieren besser und schneller mit Daten geringerer Dimension. Neuronale Netze mit einer kleineren Eingangsdimension enthalten daher weniger trainierbare Gewichte. Das bedeutet, dass sie schneller lernen und arbeiten und das Risiko einer Überanpassung geringer ist.
Eine weitere Aufgabe, die von Autoencodern gelöst wird, ist die Bereinigung der Quelldaten vom Rauschen. Es gibt zwei Ansätze, um dieses Problem zu lösen. Die erste ist, wie bei der PCA, die verlustbehaftete Datenkompression. Wir gehen jedoch davon aus, dass das Rauschen bei der Kompression verloren geht.
Der zweite Ansatz ist in der Bildverarbeitung weit verbreitet. Wir nehmen Quellbilder von guter Qualität (ohne Rauschen) und fügen verschiedene Verzerrungen (Artefakte, Rauschen usw.) hinzu. Die verzerrten Bilder werden in den Autoencoder eingespeist. Das Modell wird so trainiert, dass es eine maximale Ähnlichkeit mit dem qualitativ hochwertigen Originalbild erreicht. Bei der Auswahl von Verzerrungen sollte man jedoch besonders vorsichtig sein. Sie sollten mit natürlichem Rauschen vergleichbar sein. Andernfalls besteht eine hohe Wahrscheinlichkeit, dass das Modell unter realen Bedingungen nicht korrekt funktioniert.
Neben dem Löschendes Rauschens aus Bildern können Autoencoder auch zum Löschen oder Hinzufügen von Objekten zu Bildern verwendet werden. Nimmt man zum Beispiel zwei Bilder, die sich nur in einem Objekt unterscheiden, und gibt sie in den Encoder ein, so entspricht der Differenzvektor zwischen den latenten Zuständen der beiden Bilder dem Objekt, das nur auf einem Bild vorhanden ist. Indem wir den resultierenden Vektor zum latenten Zustand eines beliebigen anderen Bildes hinzufügen, können wir das Objekt dem Bild hinzufügen. In ähnlicher Weise können wir durch Subtraktion des Vektors vom latenten Zustand das Objekt aus dem Bild entfernen.
Separate Autoencoder-Lerntechniken ermöglichen die Trennung des latenten Zustands in Inhalt und Bildstil. Die stilbewahrende Inhaltssubstitution ermöglicht es, am Ausgang des Decoders ein neues Bild zu erhalten, das den Inhalt eines Bildes mit dem Stil eines anderen kombiniert. Die Entwicklung solcher Experimente ermöglicht den Einsatz von trainierten Autoencodern für die Bilderzeugung.
Im Allgemeinen ist das Spektrum der Aufgaben, die mit Hilfe von Autoencodern gelöst werden können, recht groß. Aber nicht alle von ihnen können im Handel angewendet werden. Zumindest sehe ich jetzt nicht, wie man die Fähigkeit zur Generierung nutzen kann. Vielleicht hat ja jemand ein paar ungewöhnliche Ideen und kann sie umsetzen.
3. Vergleich von Autoencoder mit PCA
Wie bereits erwähnt, überschneiden sich die von Autoencodern gelösten Aufgaben teilweise mit den zuvor betrachteten Algorithmen. Insbesondere Autoencoder und die Methode der Hauptkomponentenanalyse können Daten komprimieren (Dimensionalität reduzieren) und Rauschen aus den Quelldaten entfernen. Warum brauchen wir also ein weiteres Instrument, um die gleichen Probleme zu lösen? Schauen wir uns die Unterschiede zwischen den Ansätzen und ihre Leistung an.
Erinnern wir uns zunächst an die Einzelheiten des Algorithmus der Hauptkomponentenanalyse. Dies ist eine rein mathematische Methode, die auf strengen mathematischen Formeln beruht. Sie wird für die Extraktion der Hauptkomponenten verwendet. Bei Anwendung der Methode auf dieselben Ausgangsdaten erhalten wir immer die gleichen Ergebnisse. Dies ist bei Autoencodern nicht der Fall.
Ein Autoencoder ist ein neuronales Netz. Es wird mit zufälligen Werten initialisiert und iterativ mit der Methode des Gradientenabstiegs trainiert. Bei der Ausbildung werden die gleichen mathematischen Formeln verwendet. Es gibt jedoch einige Gründe dafür, dass verschiedene Trainings desselben Modells mit denselben Quelldaten zu völlig unterschiedlichen Ergebnissen führen können. Sie können eine vergleichbare Genauigkeit bieten, aber dennoch unterschiedlich sein.
Der zweite Aspekt bezieht sich auf die Art der Umwandlungen. Bei der PCA verwenden wir lineare Transformationen in Form von Matrixmultiplikation. In neuronalen Netzen verwenden wir in der Regel nichtlineare Aktivierungsfunktionen. Das bedeutet, dass die Transformationen im Autoencoder komplexer sein werden.
Nun, wir könnten die Methode der Hauptkomponentenanalyse mit einem dreischichtigen Autoencoder ohne Aktivierungsfunktion vergleichen. Aber auch in diesem Fall, selbst wenn die Anzahl der Elemente der versteckten Schicht gleich der Anzahl der Hauptkomponenten ist, ist das gleiche Ergebnis nicht garantiert. Im Gegenteil, in diesem Fall wird die PCA garantiert ein besseres Ergebnis liefern.
Außerdem wäre die Berechnung der Hauptkomponenten viel schneller als das Training des Autoencoder-Modells. Wenn Ihre Daten also eine lineare Beziehung aufweisen, ist es besser, sie mit der Hauptkomponentenanalyse zu komprimieren. Autoencoder ist für komplexere Aufgaben besser geeignet.
4. Mögliche Anwendungen für Autoencoder im Handel
Nachdem wir nun den theoretischen Teil der Autoencoder-Algorithmen betrachtet haben, wollen wir sehen, wie wir ihre Fähigkeiten in Handelsstrategien nutzen können. Die allererste mögliche Idee ist die Datenvorverarbeitung: Datenkompression und Rauschunterdrückung. Zuvor hatten wir ähnliche Experimente mit der Methode der Hauptkomponentenanalyse durchgeführt. So können wir eine vergleichende Analyse durchführen.
Es fällt mir schwer, mir vorzustellen, wie wir die generativen Fähigkeiten von Autoencodern nutzen können. Und der Wert gefälschter Charts ist fraglich. Natürlich könnten Sie versuchen, einen Autoencoder zu trainieren, um Decoderergebnisse mit einer leichten Zeitverschiebung zu erhalten. Dies unterscheidet sich jedoch nicht wesentlich von den zuvor erörterten Methoden des überwachten Lernens. In jedem Fall kann der Wert eines solchen Ansatzes nur experimentell bewertet werden.
Wir können auch versuchen, die Dynamik der Veränderungen der Marktsituation zu bewerten. Denn der Handel basiert im Allgemeinen auf der Beobachtung von Veränderungen der Marktsituation und dem Versuch, künftige Bewegungen vorherzusagen. Ich habe bereits den Ansatz beschrieben, bei dem wir mit Hilfe des latenten Zustands ein Objekt aus dem Bild hinzufügen oder entfernen können. Warum machen wir uns diese Eigenschaft nicht zunutze? Aber wir werden die Marktsituation am Decoderausgang nicht verzerren. Wir werden versuchen, die Marktdynamik auf der Grundlage des Vektors der Differenz zwischen zwei aufeinanderfolgenden latenten Zuständen zu bewerten.
Wir werden auch Transfer Learning einsetzen. An dieser Stelle setzt unser Artikel an. Die Autoencoder-Lerntechnologie kann verwendet werden, um das Modell zu trainieren und Merkmale aus den Quelldaten zu extrahieren. Dann verwenden wir nur den Encoder, fügen ihm mehrere Entscheidungsschichten hinzu und trainieren das Modell mit überwachtem Lernen, um unsere Aufgaben zu lösen. Wenn wir einen Autoencoder trainieren, enthält sein latenter Zustand alle Merkmale aus den Quelldaten. Nachdem wir also einen Encoder einmal trainiert haben, können wir ihn zur Lösung verschiedener Probleme einsetzen. Natürlich unter der Voraussetzung, dass sie dieselben Quelldaten verwenden.
Wir haben einen Pool von Aufgaben für unsere Experimente zusammengestellt. Bitte beachten Sie, dass ihr gesamter Umfang den Rahmen eines Artikels sprengen würde. Aber wir haben keine Angst vor Schwierigkeiten. Beginnen wir also mit dem praktischen Teil.
5. Praktische Versuche
Jetzt ist es Zeit für praktische Experimente. Zunächst erstellen und trainieren wir einen einfachen Autoencoder mit vollständig verbundenen Schichten. Um das Autoencoder-Modell zu erstellen, werden wir die Bibliothek der neuronalen Schichten verwenden, die wir beim Studium der überwachten Lernmethoden erstellt haben.
Bevor wir direkt mit der Erstellung des Codes beginnen, sollten wir uns überlegen, was und wie wir den Autoencoder trainieren werden. Wir haben bereits über die Encoder gesprochen und herausgefunden, dass sie die Quelldaten zurückgeben. Warum stellen wir uns also diese Frage? Eigentlich ist alles klar, wenn wir es mit homogenen Daten zu tun haben. In diesem Fall trainieren wir das Modell einfach so, dass es die Originaldaten zurückgibt. Aber unsere Originaldaten sind nicht homogen. Wir können sowohl Preisdaten als auch Indikatorwerte in das Modell einspeisen. Auch die Messwerte verschiedener Indikatoren liefern unterschiedliche Daten. Dies wurde bereits bei der Betrachtung von Algorithmen des überwachten Lernens erwähnt. In früheren Artikeln haben wir darauf geachtet, dass Daten mit unterschiedlichen Amplituden einen unterschiedlichen Einfluss auf das Modellergebnis haben. Aber jetzt wird die Sache noch komplizierter, denn in der Ergebnisschicht des Decoders müssen wir die Aktivierungsfunktion angeben. Diese Aktivierungsfunktion muss in der Lage sein, den gesamten Bereich der verschiedenen Ausgangswerte zurückzugeben.
Meine Lösung war dieselbe wie bei den Methoden des überwachten Lernens, nämlich die Normalisierung der Quelldaten. Dies kann als separater Prozess oder unter Verwendung einer Batch-Normalisierungsschicht implementiert werden.
Die erste verborgene Schicht unseres Autoencoders wird die Schicht der Stapelnormalisierung sein. Wir werden den Autoencoder so trainieren, dass der Decoder normalisierte Daten liefert. Für die Ergebnisschicht des Decoders verwenden wir den hyperbolischen Tangens als Aktivierungsfunktion. Dies ermöglicht die Normalisierung der Ergebnisse im Bereich zwischen -1 und 1.
Dies ist die theoretische Lösung. Um dies in der Praxis umzusetzen, müssen wir bei jeder Trainingsiteration des Modells Zugang zu den Ergebnissen der ersten verborgenen Schicht des Modells haben. Wir haben noch nicht in unsere Modelle hineingeschaut. Die verborgenen Zustände unserer neuronalen Netze waren schon immer eine "Black Box". Dieses Mal müssen wir sie öffnen, um den Lernprozess zu organisieren. Dazu gehen wir zu unserer CNet-Klasse, um die Operationen des neuronalen Netzes zu organisieren, und fügen die Methode GetLayerOutput hinzu, um die Werte des Ergebnispuffers einer beliebigen versteckten Schicht zu erhalten.
In den Parametern dieser neuen Methode übergeben wir die Ordnungszahl der gewünschten Schicht und einen Zeiger auf einen Puffer zum Schreiben der Ergebnisse.
Vergessen wir nicht, einen Ergebnisprüfungsblock in den Methodenkörper einzufügen. In diesem Fall wird geprüft, ob ein gültiger Modellschichtpuffer vorhanden ist. Außerdem wird geprüft, ob die angegebene Ordnungszahl der gewünschten neuronalen Schicht in den Bereich der neuronalen Schichten des Modells fällt. Bitte beachten Sie, dass dies keine Prüfung der Möglichkeit ist, fälschlicherweise eine negative Ordnungszahl für die Schicht anzugeben. Stattdessen verwenden wir eine Integer-Variable ohne Vorzeichen, um den Parameter zu erhalten. Daher ist sein Wert immer nicht-negativ. Im Kontrollblock überprüfen wir also einfach die Obergrenze der Anzahl der neuronalen Schichten im Modell.
Nach erfolgreicher Übergabe des Kontrollblocks erhalten wir einen Zeiger auf die angegebene neuronale Schicht in einer lokalen Variablen. Überprüfen Sie sofort die Gültigkeit des empfangenen Zeigers.
Im nächsten Schritt der Methode wird die Gültigkeit des in den Parametern enthaltenen Zeigers auf den Ergebnispuffer überprüft. Gegebenenfalls wird das Erstellen eines neuen Datenpuffers eingeleitet.
Danach werden die Werte des Ergebnispuffers von der entsprechenden neuronalen Schicht abgefragt. Vergessen wir nicht, das Ergebnis bei jedem Schritt zu überprüfen.
bool CNet::GetLayerOutput(uint layer, CBufferDouble *&result) { if(!layers || layers.Total() <= (int)layer) return false; CLayer *Layer = layers.At(layer); if(!Layer) return false; //--- if(!result) { result = new CBufferDouble(); if(!result) return false; } //--- CNeuronBaseOCL *temp = Layer.At(0); if(!temp || temp.getOutputVal(result) <= 0) return false; //--- return true; }
Damit sind die vorbereitenden Arbeiten abgeschlossen. Jetzt können wir mit der Erstellung unseres ersten Autoencoders beginnen. Zur Implementierung erstellen wir einen Expert Advisor und nennen ihn ae.mq5. Es wird auf dem überwachten Lernmodell EAs basieren.
Die Ausgangsdaten sind die Preisnotierungen und die Werte von vier Indikatoren: RSI, CCI, ATR und MACD. Die gleichen Daten wurden für die Prüfung aller vorherigen Modelle verwendet. Alle Indikatorparameter werden in den externen Parametern des EA angegeben. In der Funktion OnInit initialisieren wir Instanzen von Objekten für die Arbeit mit Indikatoren.
int OnInit() { //--- Symb = new CSymbolInfo(); if(CheckPointer(Symb) == POINTER_INVALID || !Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- RSI = new CiRSI(); if(CheckPointer(RSI) == POINTER_INVALID || !RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- CCI = new CiCCI(); if(CheckPointer(CCI) == POINTER_INVALID || !CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- ATR = new CiATR(); if(CheckPointer(ATR) == POINTER_INVALID || !ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- MACD = new CiMACD(); if(CheckPointer(MACD) == POINTER_INVALID || !MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED;
Als Nächstes müssen wir die Architektur des Encoders festlegen. Die Algorithmen und Prinzipien für den Aufbau neuronaler Netze stimmen vollständig mit denen überein, die wir für den Aufbau von Modellen des überwachten Lernens verwendet haben. Der einzige Unterschied besteht in der Architektur des neuronalen Netzes.
Um die Architektur des neuronalen Netzes an unser Modellinitialisierungsmodell zu übergeben, erstellen wir ein dynamisches Array von Objekten CArrayObj. Jedes Objekt in diesem Array beschreibt eine neuronale Schicht. Ihre Reihenfolge im Array entspricht der Reihenfolge der neuronalen Schichten im Modell. Um die Architektur der neuronalen Schicht zu beschreiben, werden wir speziell erstellte CLayerDescription-Objekte verwenden.
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count int batch; ///< Batch Size ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) double probability; ///< Probability of neurons shutdown, only Dropout used };
Die erste Ebene ist die Quelldatenebene, die als vollständig verbundene Ebene deklariert ist. Wir benötigen 12 Elemente, um jeden Kerze zu beschreiben. Die Schichtgröße beträgt also das 12-fache der historischen Tiefe eines Musters. Wir verwenden die Aktivierungsfunktion nicht für die Quelldatenschicht.
Net = new CNet(NULL); ResetLastError(); double temp1, temp2; if(CheckPointer(Net) == POINTER_INVALID || !Net.Load(FileName + ".nnw", dError, temp1, temp2, dtStudied, false)) { printf("%s - %d -> Error of read %s prev Net %d", __FUNCTION__, __LINE__, FileName + ".nnw", GetLastError()); CArrayObj *Topology = new CArrayObj(); if(CheckPointer(Topology) == POINTER_INVALID) return INIT_FAILED; //--- 0 CLayerDescription *desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; int prev = desc.count = (int)HistoryBars * 12; desc.type = defNeuronBaseOCL; desc.activation = None; if(!Topology.Add(desc)) return INIT_FAILED;
Sobald die Architektur der neuronalen Schicht beschrieben ist, fügen wir sie dem dynamischen Array der Modellarchitekturbeschreibung hinzu.
Die nächste Ebene ist die Ebene der Batch-Normalisierung. Wir haben bereits vor einiger Zeit darüber gesprochen, dass es notwendig ist, sie zu schaffen. Die Anzahl der Elemente in der Batch-Normalisierungsschicht ist gleich der Anzahl der Neuronen in der vorherigen Schicht. Auch hier werden wir die Aktivierungsfunktion nicht verwenden. Wir geben die Größe der Batch-Normalisierung mit 1000 Elementen und die Methode der Optimierung der trainierten Parameter an. Außerdem fügen wir die Beschreibungen einer weiteren neuronalen Schicht zu unserem dynamischen Array von Modellarchitekturbeschreibungen hinzu.
//--- 1 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = prev; desc.batch = 1000; desc.type = defNeuronBatchNormOCL; desc.activation = None; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED;
Erinnern Sie sich an den Index der Normalisierungsschicht in der Architektur unseres Autoencoders.
Als Nächstes beginnen wir mit dem Bau des Encoders des Autoencoders. Im Encoder werden wir die Größe der neuronalen Schichten schrittweise auf 2 Elemente des latenten Zustands reduzieren. Seine Architektur ähnelt einem Trichter.
Alle neuronalen Schichten des Encoders verwenden den hyperbolischen Tangens als Aktivierungsfunktion. Um den latenten Zustand zu aktivieren, habe ich das Sigmoid verwendet.
Beim Aufbau eines Autoencoders gibt es keine besonderen Anforderungen an die Anzahl der neuronalen Schichten und an die verwendete Aktivierungsfunktion. Wir wenden also die gleichen Prinzipien an, die auch bei der Konstruktion eines neuronalen Netzmodells verwendet werden. Ich schlage vor, dass Sie beim Aufbau Ihres Autoencoder-Modells mit verschiedenen Architekturen experimentieren.
//--- 2 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; prev = desc.count = (int)HistoryBars; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 3 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; prev = desc.count = prev / 2; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 4 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; prev = desc.count = prev / 2; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 5 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = 2; desc.type = defNeuronBaseOCL; desc.activation = SIGMOID; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED;
Als Nächstes wird die Architektur des Decoders beschrieben. Dieses Mal werden wir die Anzahl der Elemente in den neuronalen Schichten schrittweise erhöhen. Oft ist die Architektur des Decoders ein Spiegelbild des Encoders. Ich beschloss jedoch, die Anzahl der neuronalen Netze und der darin enthaltenen Neuronen zu ändern. Wir müssen jedoch sicherstellen, dass die Anzahl der Neuronen in der Batch-Normalisierungsschicht gleich der der Decoder-Ergebnisschicht ist.
//--- 6 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = (int) HistoryBars; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 7 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = (int) HistoryBars * 4; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 8 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = (int) HistoryBars * 12; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED;
Nachdem wir die Beschreibung der Modellarchitektur erstellt haben, können wir mit der Erstellung des neuronalen Netzes unseres Autoencoders fortfahren. Erstellen wir eine neue Instanz des neuronalen Netzwerkobjekts und übergeben wir die Beschreibung unseres Autoencoders an seinen Konstruktor.
delete Net; Net = new CNet(Topology); delete Topology; if(CheckPointer(Net) == POINTER_INVALID) return INIT_FAILED; dError = DBL_MAX; }
Bevor wir die EA-Initialisierungsfunktion abschließen, erstellen wir einen Puffer mit temporären Daten und ein Ereignis, um das Modelltraining zu starten.
TempData = new CBufferDouble(); if(CheckPointer(TempData) == POINTER_INVALID) return INIT_FAILED; //--- bEventStudy = EventChartCustom(ChartID(), 1, (long)MathMax(0, MathMin(iTime(Symb.Name(), PERIOD_CURRENT, (int)(100 * Net.recentAverageSmoothingFactor * 10)), dtStudied)), 0, "Init"); //--- return(INIT_SUCCEEDED); }
Der vollständige Code aller Methoden und Funktionen findet sich im Anhang.
Der erstellte Autoencoder muss trainiert werden. Unsere EA-Vorlage verwendet die Funktion Train, um Modelle zu trainieren. Die Funktion erhält als Parameter das Datum des Ausbildungsbeginns. Im Hauptteil der Funktion legen wir lokale Variablen an und definieren den Lernzeitraum.
void Train(datetime StartTrainBar = 0) { int count = 0; //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time); dtStudied = MathMax(StartTrainBar, st_time); ulong last_tick = 0; double prev_er = DBL_MAX; datetime bar_time = 0; bool stop = IsStopped(); CArrayDouble *loss = new CArrayDouble(); MqlDateTime sTime;
Danach laden wir die historischen Daten, um das Modell zu trainieren.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); prev_er = dError; //--- if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } RSI.Refresh(OBJ_ALL_PERIODS); CCI.Refresh(OBJ_ALL_PERIODS); ATR.Refresh(OBJ_ALL_PERIODS); MACD.Refresh(OBJ_ALL_PERIODS);
Das Modell wird in einem System von verschachtelten Schleifen trainiert. In der äußeren Schleife wird die Trainingsepoche gezählt. Die innere Schleife iteriert über die historischen Daten innerhalb der Lernepoche.
Im äußeren Schleifenkörper wird der Fehlerwert der vorherigen Trainingsepoche gespeichert. Sie wird zur Kontrolle der Lerndynamik eingesetzt. Wenn die Dynamik der Fehleränderung nach Abschluss der nächsten Lernepoche nicht signifikant ist, wird der Lernprozess unterbrochen. Außerdem müssen wir das Kennzeichen überprüfen, das anzeigt, dass der Nutzer das Programm angehalten hat. Es folgt eine verschachtelte Schleife.
int total = (int)(bars - MathMax(HistoryBars, 0)); do { //--- stop = IsStopped(); prev_er = dError; for(int it = total - 1; it >= 0 && !stop; it--) { int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total)); if((GetTickCount64() - last_tick) >= 250) { com = StringFormat("Study -> Era %d -> %.6f\n %d of %d -> %.2f%% \nError %.5f", count, prev_er, bars - it + 1, bars, (double)(bars - it + 1.0) / bars * 100, Net.getRecentAverageError()); Comment(com); last_tick = GetTickCount64(); }
Im Hauptteil der verschachtelten Schleife werden Informationen über den Lernprozess angezeigt - die Informationen erscheinen als Kommentar im Chart. Dann wird nach dem Zufallsprinzip das nächste Muster zum Trainieren des Modells bestimmt. Danach füllen wir den temporären Puffer mit historischen Daten.
TempData.Clear(); int r = i + (int)HistoryBars; if(r > bars) continue; //--- for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; double open = Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); double rsi = RSI.Main(bar_t); double cci = CCI.Main(bar_t); double atr = ATR.Main(bar_t); double macd = MACD.Main(bar_t); double sign = MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!TempData.Add(Rates[bar_t].close - open) || !TempData.Add(Rates[bar_t].high - open) || !TempData.Add(Rates[bar_t].low - open) || !TempData.Add((double)Rates[bar_t].tick_volume / 1000.0) || !TempData.Add(sTime.hour) || !TempData.Add(sTime.day_of_week) || !TempData.Add(sTime.mon) || !TempData.Add(rsi) || !TempData.Add(cci) || !TempData.Add(atr) || !TempData.Add(macd) || !TempData.Add(sign)) break; } if(TempData.Total() < (int)HistoryBars * 12) continue;
Nach dem Sammeln historischer Daten rufen wir die Feedforward-Methode des Autoencoders auf. Die gesammelten historischen Daten werden in Methodenparametern übergeben.
Net.feedForward(TempData, 12, true); TempData.Clear();
Im nächsten Schritt müssen wir die Backpropagation-Methode des Modells aufrufen. Zuvor haben wir den Puffer der Zielergebnisse in den Methodenparametern übergeben. Das Zielergebnis für den Kodierer sind nun die normalisierten Quelldaten. Dazu müssen wir zunächst die Ergebnisse der Batch-Normalisierungsschicht abrufen und sie dann an die Backpropagation-Methode des Modells weitergeben. Wie wir bereits wissen, ist der Index der Batch-Normalisierungsschicht in unserem Modell "1".
if(!Net.GetLayerOutput(1, TempData)) break; Net.backProp(TempData); stop = IsStopped(); }
Nach Beendigung der Backpropagation-Methode wird geprüft, ob die Programmausführung durch den Nutzer unterbrochen wurde, und mit der nächsten Iteration der verschachtelten Schleife fortgefahren.
Nach Abschluss einer Trainingsepoche wird das aktuelle Trainingsergebnis des Modells gespeichert. Der aktuelle Modellfehlerwert wird protokolliert, um den Nutzer zu benachrichtigen, und wird im Trainingsdynamikpuffer gespeichert.
Bevor wir eine neue Lernepoche starten, prüfen wir, ob ein weiteres Training möglich ist.
if(!stop) { dError = Net.getRecentAverageError(); Net.Save(FileName + ".nnw", dError, 0, 0, dtStudied, false); printf("Era %d -> error %.5f %%", count, dError); loss.Add(dError); count++; } } while(!(dError < 0.01 && (prev_er - dError) < 0.01) && !stop);
Nach Abschluss des Trainings speichern wir die Fehlerdynamik des gesamten Modelltrainings in einer Datei und rufen eine Funktion auf, die den Abbruch des EA erzwingt.
Comment("Write dynamic of error"); int handle = FileOpen("ae_loss.csv", FILE_WRITE | FILE_CSV | FILE_ANSI, ",", CP_UTF8); if(handle == INVALID_HANDLE) { PrintFormat("Error of open loss file: %d", GetLastError()); delete loss; return; } for(int i = 0; i < loss.Total(); i++) if(FileWrite(handle, loss.At(i)) <= 0) break; FileClose(handle); PrintFormat("The dynamics of the error change is saved to a file %s\\%s", TerminalInfoString(TERMINAL_DATA_PATH), "ae_loss.csv"); delete loss; Comment(""); ExpertRemove(); }
In der obigen Version verwende ich die Funktion ExpertRemove, um die Arbeit des EA abzuschließen, da ihr Zweck darin bestand, das Modell zu trainieren. Wenn Ihr EA andere Zwecke verfolgt, löschen wir diese Funktion aus dem Code. Optional könnten wir sie an das Ende verschieben, damit sie ausgeführt wird, nachdem Ihr EA alle zugewiesenen Aufgaben erledigt hat.
Der vollständige Code des EA und alle verwendeten Klassen sind im Anhang zu finden.
Als Nächstes können wir den erstellten EA mit echten Daten testen. Der Autoencoder wurde für EURUSD mit dem H1-Zeitrahmen unter Verwendung der Daten der letzten 15 Jahre trainiert. So wurde der Autoencoder auf einem Trainingssatz von mehr als 92.000 Mustern von 40 Kerzen trainiert. Die Dynamik des Lernfehlers ist im folgenden Diagramm dargestellt.
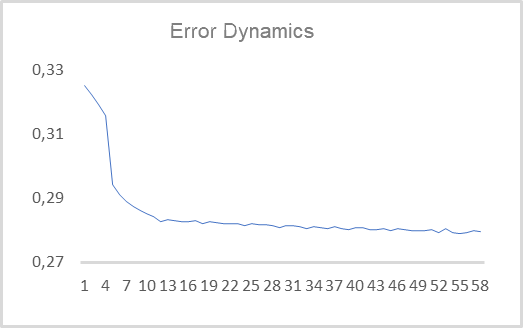
Wie man sehen kannt, sank der Wert des mittleren quadratischen Fehlers in 10 Epochen auf 0,28 und nahm dann langsam weiter ab. Das bedeutet, dass der Autoencoder in der Lage ist, Informationen aus 480 Merkmalen (40 Kerzen * 12 Merkmale pro Kerze) bis zu einem latenten Zustand mit zwei Elementen zu komprimieren, wobei 78 % der Informationen erhalten bleiben. Wie Sie sich erinnern, bleiben bei der PCA weniger als 25 % der ähnlichen Daten auf den ersten beiden Komponenten erhalten.
Ich verwende absichtlich eine Größe des latenten Zustands von 2 Elementen. Dies ermöglicht die Visualisierung und den Vergleich mit ähnlichen Darstellungen, die wir mit der Methode der Hauptkomponentenanalyse erhalten haben. Um solche Daten vorzubereiten, müssen wir den obigen EA leicht abändern. Die wichtigsten Änderungen betreffen die Modelltrainingsfunktion Train. Der Beginn der Funktion ändert sich nicht — er umfasst den Prozess der Erstellung von Übungsproben.
Gleich nach der Erstellung der Trainingsstichprobe fügen wir ein Training mit der Methode der Hauptkomponentenanalyse hinzu.
void Train(datetime StartTrainBar = 0) { //--- The process of creating a training sample has not changed //--- if(!PCA.Study(data)) { printf("Runtime error %d", GetLastError()); return; }
In der obigen EA haben wir ein System aus zwei verschachtelten Schleifen erstellt, um das Modell zu trainieren. Jetzt werden wir den Autoencoder nicht neu trainieren, sondern das zuvor trainierte Modell verwenden. Daher brauchen wir das System der verschachtelten Schleifen nicht. Wir brauchen nur eine Schleife durch die Elemente der Trainingsstichprobe. Außerdem werden wir den latenten Zustand nicht für alle 92.000 Muster sichtbar machen. Dadurch werden die Informationen schwer verständlich. Ich beschloss, nur 1000 Muster zu visualisieren. Sie können meine Experimente mit einer beliebigen Anzahl von Mustern zur Visualisierung wiederholen.
Da ich mich entschieden habe, nicht die gesamte Stichprobe zu visualisieren, werde ich ein Muster aus der Trainingsstichprobe zufällig für die Visualisierung auswählen. Wir füllen also den temporären Puffer mit den Merkmalen des ausgewählten Musters.
{
//---
stop = IsStopped();
bool add_loop = false;
for(int it = 0; i < 1000 && !stop; i++)
{
if((GetTickCount64() - last_tick) >= 250)
{
com = StringFormat("Calculation -> %d of %d -> %.2f%%", it + 1, 1000, (double)(it + 1.0) / 1000 * 100);
Comment(com);
last_tick = GetTickCount64();
}
int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total));
TempData.Clear();
int r = i + (int)HistoryBars;
if(r > bars)
continue;
//---
for(int b = 0; b < (int)HistoryBars; b++)
{
int bar_t = r - b;
double open = Rates[bar_t].open;
TimeToStruct(Rates[bar_t].time, sTime);
double rsi = RSI.Main(bar_t);
double cci = CCI.Main(bar_t);
double atr = ATR.Main(bar_t);
double macd = MACD.Main(bar_t);
double sign = MACD.Signal(bar_t);
if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE)
continue;
//---
if(!TempData.Add(Rates[bar_t].close - open) || !TempData.Add(Rates[bar_t].high - open) ||
!TempData.Add(Rates[bar_t].low - open) || !TempData.Add((double)Rates[bar_t].tick_volume / 1000.0) ||
!TempData.Add(sTime.hour) || !TempData.Add(sTime.day_of_week) || !TempData.Add(sTime.mon) ||
!TempData.Add(rsi) || !TempData.Add(cci) || !TempData.Add(atr) || !TempData.Add(macd) || !TempData.Add(sign))
break;
}
if(TempData.Total() < (int)HistoryBars * 12)
continue;
Nachdem wir Informationen über das Muster erhalten haben, rufen wir die Feed-Forward-Methode des Autoencoders auf und komprimieren die Daten mit der Methode der Hauptkomponentenanalyse. Dann erhalten wir den Wert des Ergebnispuffers des latenten Zustands des Autoencoders.
Net.feedForward(TempData, 12, true); data = PCA.ReduceM(TempData); TempData.Clear(); if(!Net.GetLayerOutput(5, TempData)) break;
Zuvor haben wir bei der Prüfung der Modelle deren Fähigkeit geprüft, die Bildung eines Fraktals vorherzusagen. Um die Muster visuell zu trennen, verwenden wir diesmal die farbliche Trennung der Muster auf dem Diagramm. Daher müssen wir angeben, zu welchem Typ das gerenderte Muster gehört. Um dies zu verstehen, müssen wir die Bildung eines Fraktals nach dem Muster überprüfen.
bool sell = (Rates[i - 1].high <= Rates[i].high && Rates[i + 1].high < Rates[i].high); bool buy = (Rates[i - 1].low >= Rates[i].low && Rates[i + 1].low > Rates[i].low); if(buy && sell) buy = sell = false;
Die empfangenen Daten werden zur weiteren Visualisierung in einer Datei gespeichert. Dann geht es weiter mit dem nächsten Muster.
FileWrite(handle, (buy ? DoubleToString(TempData.At(0)) : " "), (buy ? DoubleToString(TempData.At(1)) : " "), (sell ? DoubleToString(TempData.At(0)) : " "), (sell ? DoubleToString(TempData.At(1)) : " "), (!(buy || sell) ? DoubleToString(TempData.At(0)) : " "), (!(buy || sell) ? DoubleToString(TempData.At(1)) : " "), (buy ? DoubleToString(data[0, 0]) : " "), (buy ? DoubleToString(data[0, 1]) : " "), (sell ? DoubleToString(data[0, 0]) : " "), (sell ? DoubleToString(data[0, 1]) : " "), (!(buy || sell) ? DoubleToString(data[0, 0]) : " "), (!(buy || sell) ? DoubleToString(data[0, 1]) : " ")); stop = IsStopped(); } }
Nach allen Iterationen der Schleife löschen Sie das Kommentarfeld im Diagramm und schließen den EA.
Comment(""); ExpertRemove(); }
Der vollständige Code des EAs befindet sich im Anhang.
Als Ergebnis der Arbeit des Expert Advisors erhalten wir die Datei AE_latent.csv, die die Daten des latenten Zustands des Autoencoders und die ersten beiden Hauptkomponenten für die entsprechenden Muster enthält. Anhand der Daten aus der Datei wurden zwei Diagramme erstellt.


Wie man sehen kann, weisen die beiden vorgestellten Diagramme keine klare Einteilung der Muster in die gewünschten Gruppen auf. Die Latenzdaten des Autoencoders liegen jedoch auf beiden Achsen nahe bei 0,5. Dieses Mal haben wir das Sigmoid als Aktivierungsfunktion für die neuronale Schicht des latenten Zustands verwendet. Und die Funktion gibt immer einen Wert im Bereich von 0 bis 1 zurück. Das Zentrum der erhaltenen Verteilung liegt also nahe dem Zentrum des Wertebereichs der Funktion.
Die Datenkompression mit der Methode der Hauptkomponentenanalyse ergibt recht große Werte. Die Werte entlang der Achsen unterscheiden sich um das 6-7-fache. Der Mittelpunkt der Verteilung liegt ungefähr bei [18000, 130000]. Außerdem gibt es ausgeprägte lineare Ober- und Untergrenzen des Bereichs.
Auf der Grundlage der Analyse der vorgestellten Diagramme würde ich einen Autoencoder für die Datenvorverarbeitung wählen, bevor die Daten in das entscheidungsrelevante neuronale Netz eingespeist werden.
Schlussfolgerung
In diesem Artikel haben wir uns mit Autokodierern vertraut gemacht, die weithin zur Lösung verschiedener Probleme eingesetzt werden. Wir haben unseren ersten Autoencoder mit vollständig verbundenen Schichten entwickelt und seine Leistung mit der Hauptkomponentenanalyse verglichen. Die Testergebnisse zeigten den Vorteil der Verwendung eines Autoencoders bei der Lösung nichtlinearer Probleme. Aber das Thema Autoencoder ist recht umfangreich und passt nicht in einen Artikel. Im nächsten Artikel schlage ich vor, verschiedene Heuristiken zur Verbesserung der Effizienz von Autoencodern zu betrachten.
Ich beantworte gerne alle Ihre Fragen im Forumsthread zu diesem Artikel.
Liste der Referenzen
- Neuronale Netze leicht gemacht (Teil 14): Datenclustering
- Neuronale Netze leicht gemacht (Teil 15): Datenclustering mit MQL5
- Neuronale Netze leicht gemacht (Teil 16): Praktische Anwendung des Clustering
- Neuronale Netze leicht gemacht (Teil 17): Dimensionsreduktion.
- Neuronale Netze leicht gemacht (Teil 18): Assoziationsregeln
-
Neuronale Netze leicht gemacht (Teil 19): Assoziationsregeln mit MQL5
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | ae.mq5 | Expert Advisor | Autoencoder eines lernenden Expert Advisors |
| 2 | ae2.mq5 | EA | EA zur Vorbereitung von Daten für die Visualisierung |
| 2 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 3 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/11172
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Techniken des MQL5-Assistenten, die Sie kennen sollten (Teil 03): Shannonsche Entropie
Techniken des MQL5-Assistenten, die Sie kennen sollten (Teil 03): Shannonsche Entropie
 Matrix- und Vektoroperationen in MQL5
Matrix- und Vektoroperationen in MQL5
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Es ist einfach, aber es gibt bereits 20 Abschnitte).
Ich versuche, verschiedene Ansätze zu zeigen und unterschiedliche Nutzungsvarianten zu demonstrieren.
Und mit dem Namen "it's simple" wollte ich die Zugänglichkeit der Technologie für alle, die sie nutzen wollen, betonen.