
开发多币种 EA 交易(第 20 部分):整理自动项目优化阶段的输送机(一)
概述
在本系列文章中,我们尝试创建一个自动优化系统,该系统允许在没有人为干预的情况下找到一种交易策略的参数的良好组合。然后,这些组合将组合成一个最终的 EA。第 9 部分和第 11 部分更详细地阐述了目标。这种搜索过程本身将由一个 EA(优化 EA)控制,在其操作过程中需要保存的所有数据都设置在主数据库中。
在数据库中,我们有表来存储有关几类对象的信息。有些类具有状态字段,可以从一组固定的值(“Queued”(排队)、“Process”(处理)、“Done”(完成))中获取值,但并非所有类都使用此字段。更准确地说,目前它仅用于优化任务(task)。我们的优化 EA 在任务表(task)中搜索排队任务以选择下一个要运行的任务。每个任务完成后,其在数据库中的状态将更改为“Done”。
让我们尝试不仅对任务,而且对所有其他类别的对象(作业、阶段、项目)实现状态自动更新,并安排所有必要阶段的自动执行,直到获得最终的 EA,该 EA 可以独立工作,而无需连接到数据库。
规划路径
首先,我们将仔细研究数据库中具有状态的所有对象类,并制定更改状态的明确规则。如果可以做到这一点,那么我们可以将这些规则实现为对来自优化 EA 或阶段 EA 的其他 SQL 查询的调用。或者,可以将它们实现为数据库中的触发器,当某些数据更改事件发生时,这些触发器会被激活。
接下来,我们需要就确定任务完成顺序的方法达成一致。这在以前不是什么大问题,因为在开发过程中,我们每次都会在一个新的数据库上进行训练,并按照必须完成的顺序添加项目阶段、工作和任务。但是,当转移到在数据库中存储多个项目的信息,甚至自动添加新项目时,将不再可能依赖这种确定任务优先级顺序的方法。所以,让我们花点时间讨论这个问题。
为了测试整个输送机的运行情况,自动优化项目的所有任务都将依次执行,我们需要自动化更多的操作。在此之前,我们手动执行它们。例如,在完成第二阶段的优化后,我们有机会选择最佳组用于最终的 EA。我们通过手动运行第三阶段 EA 来执行此操作,即在自动优化输送机之外。为了设置此 EA 的启动参数,我们还使用与 MQL5 相关的第三方数据库访问接口手动选择了第二阶段通过的 ID,以获得最佳结果。我们也会尝试对此采取一些措施。
因此,在做出更改后,我们希望最终制作一个完全完成的输送机,用于执行自动优化阶段,以获得最终的 EA。在此过程中,我们将考虑与提高工作效率有关的其他一些问题。例如,对于不同的交易策略,EA 的第二阶段和后续阶段似乎是相同的。让我们检查一下这是否属实。我们还将了解哪种方式更方便 —— 创建不同的小型项目,还是在大型项目中创建更多阶段或产品。
更改状态的规则
让我们首先制定改变状态的规则。您可能还记得,我们的数据库包含有关具有状态字段( status )的以下对象的信息:
- 项目。组合 projects 表中存储的一个或多个阶段;
- 阶段。组合一个或多个作业,存储在 stages 表中;
- 作业。组合一个或多个任务,存储在 jobs 表中;
- 任务。通常组合多个测试过程,存储在 tasks 表中。
这四个对象类的可能状态值是相同的,可以是以下之一:
- Queued。该对象已排队等待处理;
- Process。对象正在被处理;
- Done。对象处理已完成或尚未开始。
让我们描述一下根据项目自动优化输送机的正常周期更改数据库中对象状态的规则。当项目排队等待优化时,周期就开始了,即它被分配了 Queued 状态。
当项目状态变为 Queued 时:
- 将此项目所有阶段的状态设置为 Queued。
当阶段状态变为 Queued 时:
- 将此阶段中所有作业的状态设置为 Queued。
当作业状态变为 Queued 时:
- 将此作业的所有任务的状态设置为 Queued。
当任务状态变为 Queued 时:
- 清除开始和结束日期。
因此,将项目状态更改为 Queued 将导致该项目的所有阶段、工作和任务的状态级联更新为 Queued。所有这些对象都将保持这种状态,直到 Optimization.ex5 EA 启动。
启动后,必须找到至少一个处于 Queued 状态的任务。稍后,我们将考虑具有多个任务的排序顺序。任务状态变为 Process。这将导致以下操作:
当任务状态变为 Process 时:
- 将开始日期设置为当前时间;
- 删除任务框架内先前执行的所有通过;
- 将与该任务相关的作业状态设置为 Process。
当作业状态变为 Process 时:
- 将与该作业相关的阶段的状态设置为 Process。
当阶段状态变为 Process 时:
- 将与此阶段相关的项目状态设置为 Process。
在此之后,任务将在项目阶段的框架内按顺序执行。只有在完成下一个任务后,才能进行进一步的状态更改。此时,任务状态变为 Done,并可能导致此状态级联至更高级别的对象。
当任务状态变为 Done 时:
- 将结束日期设置为当前时间;
- 我们获得了该作业中所有 Queued 任务的列表,该任务在该列表中执行。如果没有,那么我们将与该任务相关的工作的状态设置为 Done。
当作业状态变为 Done 时:
- 获取正在执行该作业的阶段中所有 Queued 作业的列表。如果没有,那么我们将与该作业相关的阶段的状态设置为 Done。
当阶段状态变为 Done 时:
- 我们获得了项目中包含的所有 Queued 阶段的列表,该阶段正在其中执行。如果没有,那么我们将与此阶段相关的项目状态设置为 Done。
因此,当最后一个阶段的最后一个工作的最后一个任务完成时,项目本身将转入完成状态。
现在所有规则都已制定,我们可以继续在数据库中创建实现这些操作的触发器。
创建触发器
让我们从处理项目状态更改为 Queued 的触发器开始。以下是一种可能的实现方式:
CREATE TRIGGER upd_project_status_queued AFTER UPDATE OF status ON projects WHEN NEW.status = 'Queued' BEGIN UPDATE stages SET status = 'Queued' WHERE id_project = NEW.id_project; END;
完成后,项目阶段的状态也将更改为 Queued。因此,我们应该为阶段、作业和任务启动相应的触发器:
CREATE TRIGGER upd_stage_status_queued
AFTER UPDATE
ON stages
WHEN NEW.status = 'Queued' AND
OLD.status <> NEW.status
BEGIN
UPDATE jobs
SET status = 'Queued'
WHERE id_stage = NEW.id_stage;
END;
CREATE TRIGGER upd_job_status_queued
AFTER UPDATE OF status
ON jobs
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET status = 'Queued'
WHERE id_job = NEW.id_job;
END;
CREATE TRIGGER upd_task_status_queued
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET start_date = NULL,
finish_date = NULL
WHERE id_task = NEW.id_task;
END;
任务启动将由以下触发器处理,该触发器设置任务开始日期,清除上次启动任务的传递数据,并将作业状态更新为 Process:
CREATE TRIGGER upd_task_status_process
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Process'
BEGIN
UPDATE tasks
SET start_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
DELETE FROM passes
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = 'Process'
WHERE id_job = NEW.id_job;
END;
接下来,执行此作业的阶段和项目状态将级联到 Process:
CREATE TRIGGER upd_job_status_process AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Process' BEGIN UPDATE stages SET status = 'Process' WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_process AFTER UPDATE OF status ON stages WHEN NEW.status = 'Process' BEGIN UPDATE projects SET status = 'Process' WHERE id_project = NEW.id_project; END;
在任务状态更新为 Done 时激活的触发器中,即当任务完成时,我们更新任务完成日期,然后(取决于当前任务作业中队列中是否存在其他要执行的任务)我们将作业状态更新为 Process 或 Done:
CREATE TRIGGER upd_task_status_done
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Done'
BEGIN
UPDATE tasks
SET finish_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = (
SELECT CASE WHEN (
SELECT COUNT( * )
FROM tasks t
WHERE t.status = 'Queued' AND
t.id_job = NEW.id_job
)
= 0 THEN 'Done' ELSE 'Process' END
)
WHERE id_job = NEW.id_job;
END;
让我们对阶段和项目状态做同样的事情:
CREATE TRIGGER upd_job_status_done AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Done' BEGIN UPDATE stages SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM jobs j WHERE j.status = 'Queued' AND j.id_stage = NEW.id_stage ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_done AFTER UPDATE OF status ON stages WHEN NEW.status = 'Done' BEGIN UPDATE projects SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM stages s WHERE s.status = 'Queued' AND s.name <> 'Single tester pass' AND s.id_project = NEW.id_project ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_project = NEW.id_project; END;
当将此状态设置为项目本身时,我们还将提供将所有项目对象转移到 Done 状态的功能。我们没有将此场景包含在上述规则列表中,因为它不是自动优化正常过程中的强制操作。在此触发器中,我们将所有未执行或正在进行的任务的状态设置为 Done,这将导致为所有项目作业和阶段设置相同的状态:
CREATE TRIGGER upd_project_status_done AFTER UPDATE OF status ON projects WHEN NEW.status = 'Done' BEGIN UPDATE tasks SET status = 'Done' WHERE id_task IN ( SELECT t.id_task FROM tasks t JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage JOIN projects p ON p.id_project = s.id_project WHERE p.id_project = NEW.id_project AND t.status <> 'Done' ); END;
创建所有这些触发器后,让我们弄清楚如何确定任务执行顺序。
输送机
到目前为止,我们只处理了数据库中的一个项目,所以让我们从确定这种情况下任务顺序的规则开始。一旦我们了解了如何确定一个项目的任务顺序,我们就可以考虑同时启动的几个项目的任务的顺序。
显然,与同一作业相关且仅在优化标准上不同的优化任务可以以任何顺序执行:在不同标准上顺序启动遗传优化不会使用之前优化的信息。使用不同的优化标准来增加所发现的良好参数组合的多样性。已经观察到,尽管标准不同,但具有相同尝试输入范围的遗传优化会收敛到不同的组合。
因此,不需要向 tasks 表添加任何排序字段。我们可以使用一个作业的任务添加到数据库的顺序,即按 id_task 对它们进行排序。
如果一个作业中只有一个任务,则执行顺序将取决于作业的执行顺序。这些工作旨在将任务分组,或者更准确地说,将任务划分为不同的交易品种和时间框架组合。如果我们考虑一个例子,我们有三个交易品种(EURGBP、EURUSD、GBPUSD)、两个时间框架(H1、M30)和两个阶段(Stage1、Stage2),那么我们可以选择两种可能的订单:
- 按交易品种和时间框架分组:
- EURGBP H1 Stage1
- EURGBP H1 Stage2
- EURGBP M30 Stage1
- EURGBP M30 Stage2
- EURUSD H1 Stage1
- EURUSD H1 Stage2
- EURUSD M30 Stage1
- EURUSD M30 Stage2
- GBPUSD H1 Stage1
- GBPUSD H1 Stage2
- GBPUSD M30 Stage1
- GBPUSD M30 Stage2
- 按阶段分组:
- Stage1 EURGBP H1
- Stage1 EURGBP M30
- Stage1 EURUSD H1
- Stage1 EURUSD M30
- Stage1 GBPUSD H1
- Stage1 GBPUSD M30
- Stage2 EURGBP H1
- Stage2 EURGBP M30
- Stage2 EURUSD H1
- Stage2 EURUSD M30
- Stage2 GBPUSD H1
- Stage2 GBPUSD M30
采用第一种分组方法(按交易品种和时间框架),每次完成第二阶段后,我们就能收到一些准备就绪的东西,也就是最终的 EA。它将包括针对那些已经通过两个优化阶段的交易品种和时间框架的交易策略的单套副本。
采用第二种分组方法(按阶段),只有当第一阶段的所有工作和至少一项第二阶段的工作完成后,最终的 EA 才能出现。
对于仅使用相同交易品种和时间框架的先前步骤的结果的作业,两种方法之间没有区别。但如果我们稍微展望一下,就会发现还会有另一个阶段,其中不同交易品种和时间框架的第二阶段的结果将会合并在一起。我们尚未将其实现为自动优化阶段,但我们已经为其准备了一个阶段 EA,甚至启动了它,尽管是手动的。对于这个阶段,第一种分组方法并不合适,所以我们将使用第二种方法。
值得注意的是,如果我们仍然想使用第一种方法,那么也许为每种交易品种和时间框架的组合创建多个项目就足够了。但就目前而言,好处似乎还不清楚。
因此,如果我们在一个阶段内有多个作业,那么它们的执行顺序可以是任意的,对于不同阶段的作业,顺序将由阶段的优先级顺序决定。换句话说,与任务的情况一样,不需要向 jobs 表添加任何排序字段。我们可以使用一个阶段的作业添加到数据库的顺序,即按 id_job 对它们进行排序。
为了确定阶段的顺序,我们还可以使用阶段表( stages )中已有的数据。我最开始已经在这个表中添加了父阶段字段( id_parent_stage ),但是到现在还没有用到。事实上,当表中只有两行代表两个阶段时,按照正确的顺序创建它们并不困难 —— 首先是第一阶段的一行,然后是第二阶段的一行。当它们的数量更多,并且出现了其他项目的阶段时,手动维护正确的顺序变得更加困难。
因此,让我们借此机会构建一个执行阶段的层次结构,其中每个阶段在其父阶段完成后执行。至少有一个阶段不应有父级,以便在层次结构中占据最高位置。让我们编写一个测试 SQL 查询,它将结合来自 tasks、jobs 和 stages 表的数据并显示当前阶段的所有任务。我们将把所有字段添加到此查询的列列表中,以便我们可以看到最完整的信息。
SELECT t.id_task,
t.optimization_criterion,
t.status AS task_status,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs,
j.status AS job_status,
s.id_stage,
s.name AS stage,
s.expert AS stage_expert,
s.status AS stage_status,
ps.name AS parent_stage,
ps.status AS parent_stage_status,
p.id_project,
p.status AS project_status
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
LEFT JOIN
stages ps ON ps.id_stage = s.id_parent_stage
JOIN
projects p ON p.id_project = s.id_project
WHERE t.id_task > 0 AND
t.status IN ('Queued', 'Process') AND
(ps.id_stage IS NULL OR
ps.status = 'Done')
ORDER BY j.id_stage,
j.symbol,
j.period,
t.status,
t.id_task;

图1.启动一个任务后获取当前阶段任务的查询结果
稍后,我们将减少使用类似查询查找另一个任务时显示的列数。与此同时,让我们确保正确接收下一阶段(及其作业和任务)。图 1 所示的结果对应的是 id_task=3 的任务启动的时间。这是属于 id_job=10 的任务,它是 id_stage=10 的一部分。该阶段称为“First”,属于 id_project=1 的项目,并且没有父阶段(parent_stage=NULL)。我们可以看到,有一个正在运行的任务会导致正在执行该作业的作业和项目都出现 Process 状态。但是 id_job=5 的另一个作业仍然处于 Queued 状态,因为尚未启动任何作业任务。
现在让我们尝试完成第一个任务(只需将表中的状态字段设置为 Done)并查看相同查询的结果:

图 2.正在运行的任务完成后,获取当前阶段任务的查询结果
如您所见,已完成的任务已从此列表中消失,顶行现在被另一个任务占用,接下来可以启动该任务。到目前为止,一切都是正确的。现在让我们启动并完成此列表中的前两个任务,并启动 id_task = 7 的第三个任务进行执行:

图 3.完成第一个作业的任务并开始下一个任务后,获取当前阶段任务的查询结果
现在 id_job=5 的作业已经收到了 Process 状态。接下来,我们将运行并完成现在显示在上一个查询结果中的三个任务。它们将会从查询结果中逐一消失。最后一个完成后,再次运行查询,得到以下内容:

图 4.第一阶段所有任务完成后,查询当前阶段任务的结果
现在查询结果包含了后面几个阶段相关的作业的任务, id_stage=2 是第一阶段结果的聚类,id_stage=3 是第二阶段,对第一阶段得到的好的交易策略示例进行分组。此阶段不使用聚类,因此可以在第一阶段之后立即运行。因此,它出现在这个列表上并不是一个错误。两个阶段都有一个名为 First 的父阶段,该阶段现在处于 Done 状态。
我们来模拟一下前两个任务的启动和完成,再看一下查询结果:

图 5.所有聚类阶段任务完成后获取任务的查询结果
结果的顶行预计由第二阶段的两个任务(名为 “Second”)占据,但最后两行现在包含带有聚类的第二阶段任务(名为 “Second with clustering”)。它们的出现有点出乎意料,但与可接受的顺序并不矛盾。事实上,如果我们已经完成了聚类阶段,那么我们也可以启动将使用聚类结果的阶段。查询结果中显示的两个步骤彼此独立,因此可以按任何顺序执行。
让我们再次运行并完成每个任务,每次选择结果中的前一个。每次状态更改后收到的任务列表都按预期运行,作业和阶段的状态正确更改。最后一个任务完成后,查询结果为空,因为所有阶段的所有作业的所有分配任务均已完成,项目转入 Done 状态。
我们将此查询集成到优化 EA 中。
优化 EA 的修改
我们需要对获取下一个优化器任务的 ID 的方法进行更改,其中已经有一个执行此任务的 SQL 查询。让我们采用上面开发的查询并从中删除多余的字段,只留下 id_task 。我们还可以用 j.id_job 替换按几个作业表字段( j.symbol 、 j.period )排序,因为每个作业在这两个字段中只有一个值。最后,我们将对返回的行数添加限制。我们只需要得到一行。
现在 GetNextTaskId() 方法如下所示:
//+------------------------------------------------------------------+ //| Get the ID of the next optimization task from the queue | //+------------------------------------------------------------------+ ulong COptimizer::GetNextTaskId() { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT t.id_task" " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " LEFT JOIN " " stages ps ON ps.id_stage = s.id_parent_stage " " JOIN " " projects p ON p.id_project = s.id_project " " WHERE t.id_task > 0 AND " " t.status IN ('Queued', 'Process') AND " " (ps.id_stage IS NULL OR " " ps.status = 'Done') " " ORDER BY j.id_stage, " " j.id_job, " " t.status, " " t.id_task" " LIMIT 1;"; // ... here we get the query result return res; }
既然我们已经决定使用此文件,那么让我们在此过程中进行另一个更改:从获取队列中任务数量的方法中删除通过方法参数传递状态。事实上,我们从不使用这种方法来获取具有排队和进程状态的任务数量,这些任务数量将单独使用,而不是作为总和使用。因此,让我们修改 TotalTasks() 方法中的 SQL 查询,以便它始终返回具有这两种状态的任务总数,并删除该方法的 status 输入参数:
//+------------------------------------------------------------------+ //| Get the number of tasks with the specified status | //+------------------------------------------------------------------+ int COptimizer::TotalTasks() { // Result int res = 0; // Request to get the number of tasks with the specified status string query = "SELECT COUNT(*)" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Process') " " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // ... here we get the query result return res; }
我们将更改保存到当前文件夹的 Optimizer.mqh 文件。
除了这些修改之外,我们还需要在几个文件中将旧的状态名称 “Processing” 替换为 “Process”,因为我们上面同意使用它。
提供获取有关启动 Python 程序的任务执行过程中可能发生的错误的一些信息的能力也是有用的。现在,当这样的程序异常终止时,优化 EA 只会停留在等待任务完成的阶段,或者更确切地说,等待有关此事件的信息出现在数据库中。如果程序以错误结束,则无法更新数据库中的任务状态。因此,输送机现阶段将无法进一步移动。
到目前为止,克服这一障碍的唯一方法是使用任务中指定的参数手动重新运行 Python 程序,分析错误原因,消除错误,然后重新运行程序。
SimpleVolumesStage3.mq5 的修改
接下来,我们计划实现第三阶段的自动化,对于第二阶段的每项作业(所使用的交易品种和时间框架不同),我们选择最佳通过以纳入最终的 EA。
到目前为止,第 3 阶段 EA 一直将第 2 阶段通过 ID 列表作为输入,我们必须以某种方式手动从数据库中选择这些 ID。除此之外,该 EA 仅执行创建、回撤评估以及将一组通过保存到库中。最终的EA没有出现在启动第三阶段 EA 的结果中,因为有必要执行许多其他操作。我们稍后会回到这些操作的自动化,但现在让我们着手修改第三阶段 EA。
有不同的方法可用于自动选择通过 ID。
例如,从第二阶段的一项工作框架内获得的所有通过结果中,我们可以根据标准化年平均利润指标选择最佳的一个。一次这样的传递反过来将是一组 16 个单一交易策略实例的结果。那么最终的 EA 会包含一组多组单一策略的实例。如果我们采用三个交易品种和两个时间框架,那么在第二阶段我们有 6 项作业。然后,在第三阶段,我们将获得一个包含 6 * 16 = 96 份单一策略的组。这个方法是最容易实现的。
更复杂的选择方法的一个例子是:对于每个第二阶段的工作,我们采取一些最佳的通过,并从所有选定的通过中尝试不同的组合。这与我们在第二阶段所做的非常相似,只是现在我们将不从 16 个单独实例中招募一个小组,而是从 6 个组中招募一个,并且在六个组中的第一个中,我们将选择第一个作业中最好的通过之一,在第二组中,我们将选择第二个作业中最好的通过之一,依此类推。这种方法更复杂,但不可能提前说它会显著改善结果。
因此,我们将首先实现更简单的方法,并将复杂实现推迟到以后。
在这个阶段,我们将不再需要优化 EA 参数。现在这将是一次单次通过。为此,我们需要在数据库的阶段设置中指定适当的参数:优化列应为 0。

图 6.阶段表的内容
在 EA 代码中,我们将优化任务 ID 添加到输入中,以便该 EA 可以在输送机中启动,同时将通过结果正确保存到数据库:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "database911.sqlite"; // - File with the main database input group "::: Selection for the group" input string passes_ = ""; // - Comma-separated pass IDs input group "::: Saving to library" input string groupName_ = ""; // - Group name (if empty - no saving)
可以删除 passes_ 参数,但为了以防万一,我现在将保留它。让我们编写一个 SQL 查询,获取第二阶段作业的最佳通过 ID 列表。如果 passes_ 参数为空,我们将采用最佳通过的 ID。如果 passes_ 参数传递了一些特定的ID,那么我们就会应用它们。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); CTesterHandler::TesterInit(idTask_, fileName_); // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the connection to the main database is established, if(DB::Connect(fileName_)) { // Form a request to receive passes with the specified IDs string query = (passes_ == "" ? StringFormat("SELECT DISTINCT FIRST_VALUE(p.params) OVER (PARTITION BY p.id_task ORDER BY custom_ontester DESC) AS params " " FROM passes p " " WHERE p.id_task IN (" " SELECT pt.id_task " " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " JOIN " " jobs pj ON pj.id_stage = s.id_parent_stage " " JOIN " " tasks pt ON pt.id_job = pj.id_job " " WHERE t.id_task = %d " " ) ", idTask_) : StringFormat("SELECT params" " FROM passes " " WHERE id_pass IN (%s);", passes_) ); Print(query); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Structure for reading results struct Row { string params; } row; // For all query result strings, concatenate initialization rows while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // ... // Successful initialization return(INIT_SUCCEEDED); }
将所做的更改保存到当前文件夹中的 SimpleVolumesStage3.mq5 文件。
这样就完成了第三阶段 EA 的修改。我们将数据库中的项目移至 Queued 状态并启动优化 EA。
优化输送机结果
尽管我们还没有实现所有计划的阶段,但我们现在已经有了一个工具,可以自动提供几乎准备好的最终 EA。完成第三阶段后,我们在参数库( strategy_groups表)中有两个条目:

第一个是第二阶段的最佳组被组合在一起而没有进行聚类的通过的 ID。第二个是组合了第二阶段具有聚类的最佳组的通过的 ID。因此,我们可以从 passes 表中获取这些通过 ID 的初始化字符串,并查看这两种组合的结果。
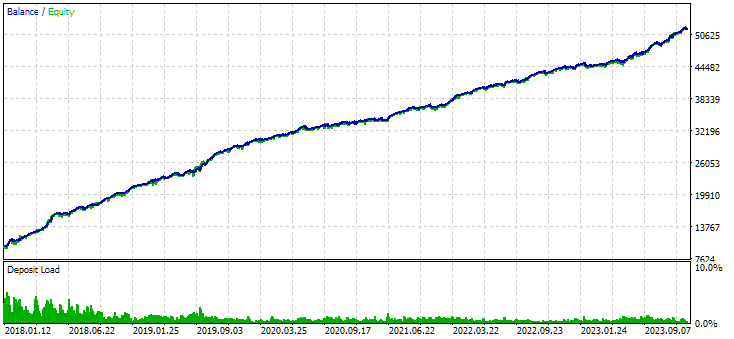
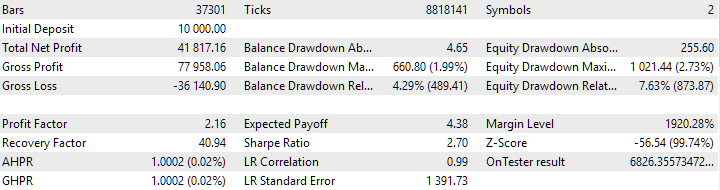
图 7.未使用聚类获得的实例组合结果
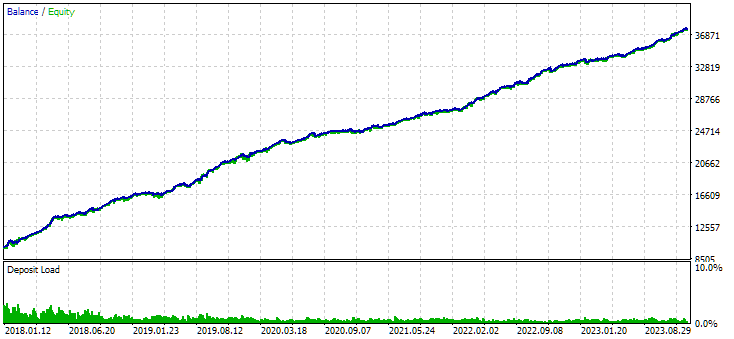
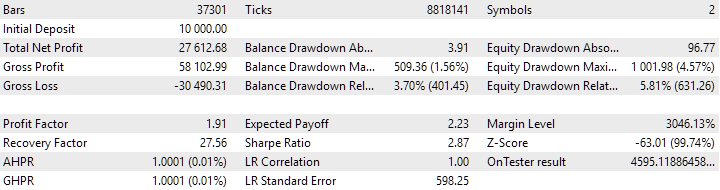
图 8.使用聚类获得的组合实例组的结果
没有聚类的变量显示出更高的利润。然而,具有聚类的变体具有更高的夏普比率和更好的线性。但我们目前不会详细分析这些结果,因为它们还不是最终结果。
下一步是添加组装最终 EA 的阶段。我们需要导出库以获取数据文件夹中的 ExportedGroupsLibrary.mqh 包含文件。然后我们应该将这个文件复制到工作文件夹。此操作可以使用 Python 程序或 DLL 中的系统复制函数执行。在最后阶段,我们只需要编译最终的 EA,并使用新的 EA 版本启动终端。
所有这些都需要大量的时间来实现,因此我们将在下一篇文章中继续对其进行描述。
结论
那么,让我们看看我们得到了什么。我们已经安排了自动优化输送机第一阶段的自动执行,实现了它们的正确操作。例如,我们可以查看中间结果并决定放弃聚类步骤。或者,相反,保留它并删除不进行聚类的选项。
拥有这样一个工具将有助于我们在未来进行实验,并尝试回答难题。例如,假设我们在第一阶段对不同范围的输入参数进行优化。哪种方式更好?是将它们单独组合,还是用相同的交易品种和时间框架组合在一起?
通过在输送机上添加阶段,我们可以实现日益复杂的 EA 的逐步组装。
最后,我们可以通过进行适当的实验来考虑部分再优化甚至连续再优化的问题。这里的重新优化意味着在不同的时间间隔内重复优化。下次再详细讨论。
感谢您的关注!期待很快与您见面!
重要警告
本文和本系列之前的所有文章中的所有结果仅基于历史测试数据,并不保证未来会有任何利润。该项目中的工作具有研究性质。所有已发表的结果都可以由任何人使用,风险自负。
存档内容
| # | 名称 | 版本 | 描述 | 最近修改 |
|---|---|---|---|---|
| MQL5/Experts/Article.16134 | ||||
| 1 | Advisor.mqh | 1.04 | EA 基类 | 第 10 部分 |
| 2 | ClusteringStage1.py | 1.01 | 对第一阶段优化结果进行聚类的程序 | 第 20 部分 |
| 3 | Database.mqh | 1.07 | 处理数据库的类 | 第 19 部分 |
| 4 | database.sqlite.schema.sql | 1.05 | 数据库结构 | 第 20 部分 |
| 5 | ExpertHistory.mqh | 1.00 | 用于将交易历史导出到文件的类 | 第 16 部分 |
| 6 | ExportedGroupsLibrary.mqh | — | 生成的文件列出了策略组名称及其初始化字符串数组 | 第 17 部分 |
| 7 | Factorable.mqh | 1.02 | 从字符串创建的对象的基类 | 第 19 部分 |
| 8 | GroupsLibrary.mqh | 1.01 | 用于处理选定策略组库的类 | 第 18 部分 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | 用于与风险管理器回放交易历史的 EA | 第 16 部分 |
| 10 | HistoryStrategy.mqh | 1.00 | 用于回放交易历史的交易策略类 | 第 16 部分 |
| 11 | Interface.mqh | 1.00 | 可视化各种对象的基类 | 第 4 部分 |
| 12 | LibraryExport.mq5 | 1.01 | EA 将库中选定通过的初始化字符串保存到 ExportedGroupsLibrary.mqh 文件 | 第 18 部分 |
| 13 | Macros.mqh | 1.02 | 用于数组操作的有用的宏 | 第 16 部分 |
| 14 | Money.mqh | 1.01 | 资金管理基类 | 第 12 部分 |
| 15 | NewBarEvent.mqh | 1.00 | 用于定义特定交易品种的新柱形的类 | 第 8 部分 |
| 16 | Optimization.mq5 | 1.03 | EA 管理优化任务的启动 | 第 19 部分 |
| 17 | Optimizer.mqh | 1.01 | 项目自动优化管理器类 | 第 20 部分 |
| 18 | OptimizerTask.mqh | 1.01 | 优化任务类 | 第 20 部分 |
| 19 | Receiver.mqh | 1.04 | 将未平仓交易量转换为市场仓位的基类 | 第 12 部分 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | 简化的EA,用于回放交易历史 | 第 16 部分 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | 用于多组模型策略并行运行的 EA。参数将从内置组库中获取。 | 第 17 部分 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | 交易策略单实例优化EA(第一阶段) | 第 19 部分 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | 交易策略实例组优化EA(第二阶段) | 第 19 部分 |
| 24 | SimpleVolumesStage3.mq5 | 1.02 | 将生成的标准化策略组保存到具有给定名称的组库中的 EA。 | 第 20 部分 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | 使用分时交易量的交易策略类 | 第 15 部分 |
| 26 | Strategy.mqh | 1.04 | 交易策略基类 | 第 10 部分 |
| 27 | TesterHandler.mqh | 1.05 | 优化事件处理类 | 第 19 部分 |
| 28 | VirtualAdvisor.mqh | 1.07 | 处理虚拟仓位(订单)的 EA 类 | 第 18 部分 |
| 29 | VirtualChartOrder.mqh | 1.01 | 图形虚拟仓位类 | 第 18 部分 |
| 30 | VirtualFactory.mqh | 1.04 | 对象工厂类 | 第 16 部分 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | 交易历史回放 EA 类 | 第 16 部分 |
| 32 | VirtualInterface.mqh | 1.00 | EA GUI 类 | 第 4 部分 |
| 33 | VirtualOrder.mqh | 1.07 | 虚拟订单和仓位类 | 第 19 部分 |
| 34 | VirtualReceiver.mqh | 1.03 | 将未平仓交易量转换为市场仓位的类(接收方) | 第 12 部分 |
| 35 | VirtualRiskManager.mqh | 1.02 | 风险管理类(风险管理器) | 第 15 部分 |
| 36 | VirtualStrategy.mqh | 1.05 | 具有虚拟仓位的交易策略类 | 第 15 部分 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | 交易策略组类 | 第 11 部分 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | 交易品种接收器类 | 第 3 部分 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/16134
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
你好,尤里
我用谷歌翻译找到了第 20 部分。 谷歌 "谷歌翻译",并将其放在浏览器的新标签页上。 它会在搜索栏最右侧放置一个图标。 加载母语页面,然后按图标选择文章语言和要翻译成的语言。 很快,我就找到了第 20 部分!它做得并不完美,但翻译 99% 是有用的。
我将您的 Archive Source 载入 Excel,并添加了几列进行排序,以安排内容。除了在 Excel 中排序外,电子表格 还可以直接导入 OutLook 数据库。
我在确定建立 SQL 数据库的起始文章时遇到了问题。 我试着运行 Simple Volume Stage 1,得到的结果是一条平线,这表明我可能需要回溯并创建另一个 SQL 数据库。 如果能有一个表,列出执行必要程序的顺序,对建立一个工作系统会非常有帮助。也许你可以把它添加到存档源表中。
另一个微小的要求是在包含文件规格时使用 <> 选项,而不是""。 我将您的系统分别保存在我的专家目录和包含目录中,#include <!!!!MultiCurrency/VirtualAdvisor.mqh>,因此这一更改将使添加子目录规范/变得更容易。
感谢您的意见
科达角
您好。
关于项目、阶段、工程和任务信息的数据库初始填充,您可以参见第 13、18 和 19 部分。这不是主要话题,所以您需要的信息会在文章末尾的某个地方。例如,在第 18 部分:
或第 19 部分:
您也可以等待下一篇文章,其中将专门讨论借助辅助脚本对数据库进行初始填充的问题。
改用 include 文件夹存储 库文件 也在计划之中,但目前还未实现。
非常感谢
你好,尤里、
您提交下一篇文章了吗?