
开发多币种 EA 交易(第 24 部分):添加新策略(二)
概述
我们将继续上一篇文章中开始的工作。我们在此提醒您,在将整个项目代码拆分为库部分和项目部分之后,我们决定研究如何从 SimpleVolumes 模型交易策略过渡到另一种策略。我们需要为此做些什么?这会有多容易?毫无疑问,有必要为新的交易策略编写一个类。但随后出现了一些意想不到的复杂情况。
它们与确保库部分独立于项目部分的愿望紧密相连。如果我们决定打破这项新引入的规则,就不会有任何困难。然而,最终找到了一种既能保持代码分离又能集成新交易策略的方法。这需要对项目的库文件进行更改,虽然数量不是很大,但意义重大。
因此,我们能够编译并运行第一阶段 EA 的优化,采用一种名为 SimpleCandles 的新策略。接下来的步骤是让它与自动优化输送机一起工作。对于之前的策略,我们开发了 CreateProject.mq5 EA,它能够创建任务优化数据库,以便在输送机上执行。在 EA 参数中,我们可以指定要优化的交易工具(交易品种)和时间周期、EA 阶段的名称以及其他必要信息。如果优化数据库之前不存在,则会自动创建。
让我们看看如何让它与新的交易策略一起工作。
规划路径
我们将从分析 CreateProject.mq5 EA 代码开始主要工作。 我们的目标是识别不同项目中相同或几乎相同的代码。此代码可以分成一个库部分,必要时可以将其拆分为几个单独的文件。我们将在项目部分留下不同项目的代码部分,并描述需要对其进行哪些更改。
但首先,让我们修复一个在将测试器传递信息保存到优化数据库时发现的错误,优化用于组织周期的宏,并研究如何将新参数添加到之前开发的交易策略中。
CDatabase 中的修复
在最近的文章中,我们开始对优化项目使用相对较短的测试间隔。我们开始采用持续几个月的间隔,而不是持续 5 年或更长时间的间隔。这是因为我们的主要任务是测试自动优化输送机的运行情况,缩短间隔使我们能够显著减少单个测试通过的时间,从而缩短整体优化时间。
为了将有关传递的信息保存到优化数据库,每个测试代理(本地、远程或云)都将其作为数据帧的一部分发送到运行优化过程的终端。在该终端中,优化开始后,以特殊模式(数据帧收集模式)启动优化 EA 的另一个实例。此实例不是在测试器中启动的,而是在单独的终端图表上启动的。它将接收并保存来自测试代理的所有信息。
尽管来自测试代理的新数据帧到达事件处理程序的代码不包含异步操作,但在优化过程中,开始出现与数据库被另一个操作锁定相关的数据库插入错误消息。这种错误比较少见。然而,在数千次运行中,有几十次最终未能将结果添加到优化数据库中。
这些错误的原因似乎是越来越多的情况下,多个测试代理同时完成一次运行并向主终端中的 EA 发送数据帧。该 EA 尝试以比数据库端完成上一次插入操作更快的速度向数据库中插入新条目。
为了解决这个问题,我们将为这类错误添加一个单独的处理过程。如果错误的原因正是数据库或表被另一个操作锁定,那么我们只需要在一段时间后重复不成功的操作。如果在尝试重新插入数据一定次数后,再次出现相同的错误,则应停止尝试。
对于插入操作,我们使用 CDatabase::ExecuteTransaction() 方法,因此让我们对其进行以下更改。将请求执行尝试计数器添加到方法参数中。如果发生此类错误,则暂停随机毫秒数(0 至 50),然后使用增加的尝试计数器值调用相同的函数。
//+------------------------------------------------------------------+ //| Execute multiple DB queries in one transaction | //+------------------------------------------------------------------+ bool CDatabase::ExecuteTransaction(string &queries[], int attempt = 0) { // Open a transaction DatabaseTransactionBegin(s_db); s_res = true; // Send all execution requests FOREACH(queries, { s_res &= DatabaseExecute(s_db, queries[i]); if(!s_res) break; }); // If an error occurred in any request, then if(!s_res) { // Cancel transaction DatabaseTransactionRollback(s_db); if((_LastError == ERR_DATABASE_LOCKED || _LastError == ERR_DATABASE_BUSY) && attempt < 20) { PrintFormat(__FUNCTION__" | ERROR: ERR_DATABASE_LOCKED. Repeat Transaction in DB [%s]", s_fileName); Sleep(rand() % 50); ExecuteTransaction(queries, attempt + 1); } else { // Report it PrintFormat(__FUNCTION__" | ERROR: Transaction failed in DB [%s], error code=%d", s_fileName, _LastError); } } else { // Otherwise, confirm transaction DatabaseTransactionCommit(s_db); //PrintFormat(__FUNCTION__" | Transaction done successfully"); } return s_res; }
为了以防万一,让我们对 CDatabase::Execute() 方法进行相同的更改,以便在不使用事务的情况下执行 SQL 查询。
另一个将来对我们有用的小改动是向 CDatabase 类添加了一个静态布尔变量。它会记住在执行请求时发生的错误:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { // ... static bool s_res; // Query execution result public: static int Id(); // Database connection handle static bool Res(); // Query execution result // ... }; bool CDatabase::s_res = true;
保存对库文件夹中 Database/Database.mqh 文件所做的更改。
Macros.h 中错误的修复
让我们来谈谈一项早就应该进行的改变。您可能还记得,我们创建了 FOREACH(A, D) 宏,以简化遍历特定数组中所有值的循环头的编写:
#define FOREACH(A, D) { for(int i=0, im=ArraySize(A);i<im;i++) {D;} }
这里 A 是数组名,而 D 是循环体。这种实现有一个缺点,即在调试时无法正确跟踪循环体内代码的逐步执行。虽然很少需要,但很不方便。有一天,我在浏览文档时,看到了实现类似宏的另一种方法。该宏只指定了循环头,循环体被移到了宏之外。但是,还有一个参数指定了循环变量的名称。
在我们之前的实现中,循环变量(数组元素索引)的名称是固定的( i ),这在任何地方都没有造成任何问题。即使在需要双循环的地方,由于这些索引的范围不同,也有可能使用相同的名称。因此,新实现也获得了一个固定的索引名称。传递的唯一参数是循环中要迭代的数组的名称:
#define FOREACH(A) for(int i=0, im=ArraySize(A);i<im;i++)
要切换到新版本,有必要在使用此宏的所有地方进行更改。示例:
//+------------------------------------------------------------------+ //| OnTick event handler | //+------------------------------------------------------------------+ void CAdvisor::Tick(void) { // Call OnTick handling for all strategies //FOREACH(m_strategies, m_strategies[i].Tick();) FOREACH(m_strategies) m_strategies[i].Tick(); }
除了这个宏,我们还添加了另一个宏,用于创建循环头。在宏中, A 数组的每个元素被逐一放入 E 数组(应该事先声明)。在循环头之前,数组的第一个元素(如果存在)将被放置到此变量中。我们将使用一个名称由字母 i 和变量名 E 组成的变量作为循环变量。 在循环头的第三部分,我们递增循环变量,同时 E 变量接收 A 数组元素的值,该元素的索引递增。通过对数组元素的数量取模来获取索引,可以避免在循环的最后一次迭代中超出数组边界:
#define FOREACH_AS(A, E) if(ArraySize(A)) E=A[0]; \ for(int i##E=0, im=ArraySize(A);i##E<im;E=A[++i##E%im])
将更改保存到库文件夹中的 Utils/Macros.h 文件。
向交易策略添加参数
与几乎所有代码一样,交易策略的实现也可能会发生变化。如果这些变化涉及交易策略单个实例的输入参数组成的变化,那么不仅需要对交易策略类进行编辑,还需要对其他一些地方进行编辑。让我们看一个例子,看看需要为此做些什么。
假设我们决定在交易策略中添加最大点差参数。它的作用在于,如果在收到开仓信号时,当前点差超过此参数中设置的值,则不会开仓。
首先,我们将在第一阶段 EA 中添加一个输入参数,通过该输入参数,我们可以在运行测试器时设置此值。然后,在初始化字符串生成函数中,添加将新参数值替换到初始化字符串的操作:
//+------------------------------------------------------------------+ //| 4. Strategy inputs | //+------------------------------------------------------------------+ sinput string symbol_ = ""; // Symbol sinput ENUM_TIMEFRAMES period_ = PERIOD_CURRENT; // Timeframe for candles input group "=== Opening signal parameters" input int signalSeqLen_ = 6; // Number of unidirectional candles input int periodATR_ = 0; // ATR period (if 0, then TP/SL in points) input group "=== Pending order parameters" input double stopLevel_ = 25000; // Stop Loss (in ATR fraction or points) input double takeLevel_ = 3630; // Take Profit (in ATR fraction or points) input group "=== Money management parameters" input int maxCountOfOrders_ = 9; // Max number of simultaneously open orders input int maxSpread_ = 10; // Max acceptable spread (in points) //+------------------------------------------------------------------+ //| 5. Strategy initialization string generation function | //| from the inputs | //+------------------------------------------------------------------+ string GetStrategyParams() { return StringFormat( "class CSimpleCandlesStrategy(\"%s\",%d,%d,%d,%.3f,%.3f,%d,%d)", (symbol_ == "" ? Symbol() : symbol_), period_, signalSeqLen_, periodATR_, stopLevel_, takeLevel_, maxCountOfOrders_, maxSpread_ ); }
初始化字符串现在比以前多包含一个参数。因此,下一步的改动是为类添加一个新属性,并将构造函数中初始化字符串的值读取到该属性中:
//+------------------------------------------------------------------+ //| Trading strategy using unidirectional candlesticks | //+------------------------------------------------------------------+ class CSimpleCandlesStrategy : public CVirtualStrategy { protected: // ... //--- Money management parameters int m_maxCountOfOrders; // Max number of simultaneously open positions int m_maxSpread; // Max acceptable spread (in points) // ... }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleCandlesStrategy::CSimpleCandlesStrategy(string p_params) { // Read the parameters from the initialization string m_params = p_params; m_symbol = ReadString(p_params); m_timeframe = (ENUM_TIMEFRAMES) ReadLong(p_params); m_signalSeqLen = (int) ReadLong(p_params); m_periodATR = (int) ReadLong(p_params); m_stopLevel = ReadDouble(p_params); m_takeLevel = ReadDouble(p_params); m_maxCountOfOrders = (int) ReadLong(p_params); m_maxSpread = (int) ReadLong(p_params); // ... }
现在,新参数可以在交易策略类的方法中随意使用。根据其用途,可以将以下代码添加到仓位开立信号接收方法中。
//+------------------------------------------------------------------+ //| Signal for opening pending orders | //+------------------------------------------------------------------+ int CSimpleCandlesStrategy::SignalForOpen() { // By default, there is no signal int signal = 0; MqlRates rates[]; // Copy the quote values (candles) to the destination array. // To check the signal we need m_signalSeqLen of closed candles and the current candle, // so in total m_signalSeqLen + 1 int res = CopyRates(m_symbol, m_timeframe, 0, m_signalSeqLen + 1, rates); // If the required number of candles has been copied if(res == m_signalSeqLen + 1) { signal = 1; // buy signal // Go through all closed candles for(int i = 1; i <= m_signalSeqLen; i++) { // If at least one upward candle occurs, cancel the signal if(rates[i].open < rates[i].close ) { signal = 0; break; } } if(signal == 0) { signal = -1; // otherwise, sell signal // Go through all closed candles for(int i = 1; i <= m_signalSeqLen; i++) { // If at least one downward candle occurs, cancel the signal if(rates[i].open > rates[i].close ) { signal = 0; break; } } } } // If there is a signal, then if(signal != 0) { // If the current spread is greater than the maximum allowed, then if(rates[0].spread > m_maxSpread) { PrintFormat(__FUNCTION__" | IGNORE %s Signal, spread is too big (%d > %d)", (signal > 0 ? "BUY" : "SELL"), rates[0].spread, m_maxSpread); signal = 0; // Cancel the signal } } return signal; }
同样,我们可以在交易策略中添加其他新参数,或者删除不必要的参数。
分析 CreateProject.mq5
让我们开始分析 CreateProject.mq5 项目创建 EA 代码。在初始化函数中,我们已经将代码拆分为单独的函数。从名称上可以清楚地看出每个函数的目的:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the database DB::Connect(fileName_); // Create a project CreateProject(projectName_, projectVersion_, StringFormat("%s - %s", TimeToString(fromDate_, TIME_DATE), TimeToString(toDate_, TIME_DATE) ) ); // Create project stages CreateStages(); // Creating jobs and tasks CreateJobs(); // Queueing the project for execution QueueProject(); // Close the database DB::Close(); // Successful initialization return(INIT_SUCCEEDED); }
这种划分不太方便,因为所选函数相当繁琐,而且解决的问题也截然不同。例如,在 CreateJobs() 函数中,我们预处理输入数据,生成作业参数模板,将信息插入数据库,然后执行类似操作以在数据库中创建优化任务。如果情况反过来就好了:函数更简单,只解决一个小问题。
为了在当前实现中使用新策略,我们需要更改第一阶段参数的模板,可能还需要更改具有优化标准的任务数量。先前交易策略的第一阶段参数模板在全局变量 paramsTemplate1 中指定:
// Template of optimization parameters at the first stage string paramsTemplate1 = "; === Open signal parameters\n" "signalPeriod_=212||12||40||240||Y\n" "signalDeviation_=0.1||0.1||0.1||2.0||Y\n" "signaAddlDeviation_=0.8||0.1||0.1||2.0||Y\n" "; === Pending order parameters\n" "openDistance_=10||0||10||250||Y\n" "stopLevel_=16000||200.0||200.0||20000.0||Y\n" "takeLevel_=240||100||10||2000.0||Y\n" "ordersExpiration_=22000||1000||1000||60000||Y\n" "; === Capital management parameters\n" "maxCountOfOrders_=3||3||1||30||N\n";
幸运的是,之前所有第一阶段优化作业的情况都一样。但情况并非总是如此。例如,在新策略中,我们将交易品种值和策略应运行的时间周期都纳入了参数中。这意味着在为不同交易品种和时间周期创建的不同第一阶段优化作业中,参数模板将具有可变部分。但是,要设置它们的值,您需要深入研究任务创建函数代码的深度并对其进行更改。那样的话,就无法再把它带到库区域了。
此外,我们的优化项目创建 EA 现在会创建一个包含三个固定阶段的项目。我们在开发过程中最终确定了这套简单的阶段,尽管我们也尝试添加其他阶段(例如,参见第 18 部分和第 19 部分)。尽管其他交易策略可能并非如此,但额外的步骤并没有显示出最终结果的任何显著改善。因此,如果我们将当前代码移动到库部分,如果我们愿意,将来将无法更改阶段的组成。
因此,尽管我们希望通过一点努力来完成,但现在对这段代码进行一些认真的重构工作仍然比推迟到以后要好。让我们尝试将项目创建 EA 代码拆分成几个类。这些类将移至库部分,在项目部分,我们将使用它们来创建具有所需阶段及其内容的项目。同时,这也将作为未来显示输送机进度信息的模板。
首先,我们尝试写出最终代码可能的样子。在最终版本发布之前,这个初步版本几乎保持不变。方法调用中只添加了特定的参数组合。因此,让我们来看看优化项目创建 EA 的初始化函数的新版本是什么样的。为了避免被小细节分散注意力,这些方法的参数没有显示出来:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create an optimization project object for the given database COptimizationProject p; // Create a new project in the database p.Create(...); // Add the first stage p.AddStage(...); // Adding the first stage jobs p.AddJobs(...); // Add tasks for the first stage jobs p.AddTasks(...); // Add the second stage p.AddStage(...); // Add the second stage jobs p.AddJobs(...); // Add tasks for the second stage jobs p.AddTasks(...); // Add the third stage p.AddStage(...); // Add the third stage job p.AddJobs(...); // Add a task for the third stage job p.AddTasks(...); // Put the project in the execution queue p.Queue(); // Delete the EA ExpertRemove(); // Successful initialization return(INIT_SUCCEEDED); }
通过这种代码结构,我们可以轻松添加新阶段并灵活更改其参数。但就目前而言,我们只看到一个我们肯定需要的新类 —— COptimizationProject 优化项目类。我们来看看它的代码。
COptimizationProject 类
在开发这个类的过程中,很快就清楚了,我们需要为存储在优化数据库中的所有类型的实体提供单独的类。接下来是项目阶段的 COptimizationStage 类、项目阶段作业的 COptimizationJob 类以及每个项目阶段作业的任务的 COptimizationTask 类。
由于这些类的对象本质上是优化数据库各个表中条目的表示,因此类字段的组合将重复相应表字段的组合。除了这些字段之外,我们还将向这些类添加执行分配给它们的任务所必需的其他字段和方法。
为了简单起见,目前我们将把所创建类的所有属性和方法都设为公有的。每个类都有自己的方法来在优化数据库中创建新条目。将来,我们将添加更改现有条目和从数据库读取条目的方法,因为创建项目时不需要它。
我们将创建单独的函数,根据模板返回已填充的参数,而不是以前使用的测试器参数模板。这样,参数模板就会移到这些函数内部。这些函数将把项目指针作为参数,并能够使用它来访问要替换到模板中的所需项目信息。我们将把这些函数的声明移到项目部分,在库部分,我们只会声明一个新类型 —— 指向以下类型函数的指针:
// Create a new type - a pointer to a string generation function // for optimization job parameters (job) accepting the pointer // to the optimization project object as an argument typedef string (*TJobsTemplateFunc)(COptimizationProject*);
这样一来,我们就能够在 COptimizationProject 类中使用阶段参数生成函数了。它们目前还不存在,但将来在设计部分,我们肯定需要添加它们。
以下是该类的描述:
//+------------------------------------------------------------------+ //| Optimization project class | //+------------------------------------------------------------------+ class COptimizationProject { public: string m_fileName; // Database name // Properties stored directly in the database ulong id_project; // Project ID string name; // Name string version; // Version string description; // Description string status; // Status // Arrays of all stages, jobs and tasks COptimizationStage* m_stages[]; // Project stages COptimizationJob* m_jobs[]; // Jobs of all project stages COptimizationTask* m_tasks[]; // Tasks of all jobs of project stages // Properties for the current state of the project creation string m_symbol; // Current symbol string m_timeframe; // Current timeframe COptimizationStage* m_stage; // Last created stage (current stage) COptimizationJob* m_job; // Last created job (current job) COptimizationTask* m_task; // Last created task (current task) // Methods COptimizationProject(string p_fileName); // Constructor ~COptimizationProject(); // Destructor // Create a new project in the database COptimizationProject* COptimizationProject::Create(string p_name, string p_version = "", string p_description = "", string p_status = "Done"); void Insert(); // Insert an entry into the database void Update(); // Update an entry in the database // Add a new stage to the database COptimizationProject* AddStage(COptimizationStage* parentStage, string stageName, string stageExpertName, string stageSymbol, string stageTimeframe, int stageOptimization, int stageModel, datetime stageFromDate, datetime stageToDate, int stageForwardMode, datetime stageForwardDate, int stageDeposit = 10000, string stageCurrency = "USD", int stageProfitInPips = 0, int stageLeverage = 200, int stageExecutionMode = 0, int stageOptimizationCriterion = 7, string stageStatus = "Done"); // Add new jobs to the database for the specified symbols and timeframes COptimizationProject* AddJobs(string p_symbols, string p_timeframes, TJobsTemplateFunc p_templateFunc); COptimizationProject* AddJobs(string &p_symbols[], string &p_timeframes[], TJobsTemplateFunc p_templateFunc); // Add new tasks to the database for the specified optimization criteria COptimizationProject* AddTasks(string p_criterions); COptimizationProject* AddTasks(string &p_criterions[]); void Queue(); // Put the project in the execution queue // Convert a string name to a timeframe static ENUM_TIMEFRAMES StringToTimeframe(string s); };
首先是直接存储在优化数据库的 projects 表中的属性。接下来是所有项目阶段、工作和任务的数组,然后是项目创建的当前状态的属性。
由于此类目前只有一个任务(在优化数据库中创建一个项目),因此我们在构造函数中立即连接到所需的数据库并打开一个事务。此事务将在析构函数中完成。这时, CDatabase::s_res 静态类字段就派上用场了。它的值可用于确定在创建项目时向优化数据库插入条目时是否发生任何错误。如果没有错误,事务将被确认;否则,事务将被取消。此外,创建的动态对象的内存会在析构函数中释放。
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ COptimizationProject::COptimizationProject(string p_fileName) : m_fileName(p_fileName), id_project(0) { // Connect to the database if (DB::Connect(m_fileName)) { // Start a transaction DatabaseTransactionBegin(DB::Id()); } } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ COptimizationProject::~COptimizationProject() { // If no errors occurred, then if(DB::Res()) { // Confirm the transaction DatabaseTransactionCommit(DB::Id()); } else { // Otherwise, cancel the transaction DatabaseTransactionRollback(DB::Id()); } // Close connection to the database DB::Close(); // Delete created task, job, and stage objects FOREACH(m_tasks) { delete m_tasks[i]; } FOREACH(m_jobs) { delete m_jobs[i]; } FOREACH(m_stages) { delete m_stages[i]; } }
添加工作和任务的方法有两种变体,第一种方法是将交易品种列表、时间周期和标准列表以字符串参数的形式传递给它们,参数之间用逗号分隔。在该方法内部,这些字符串被转换为值数组,并在调用该方法的第二个版本时作为参数替换,该版本接受数组。
以下是添加工作的方法:
//+------------------------------------------------------------------+ //| Add new jobs to the database for the specified | //| symbols and timeframes in strings | //+------------------------------------------------------------------+ COptimizationProject* COptimizationProject::AddJobs(string p_symbols, string p_timeframes, TJobsTemplateFunc p_templateFunc) { // Array of symbols for strategies string symbols[]; StringReplace(p_symbols, ";", ","); StringSplit(p_symbols, ',', symbols); // Array of timeframes for strategies string timeframes[]; StringReplace(p_timeframes, ";", ","); StringSplit(p_timeframes, ',', timeframes); return AddJobs(symbols, timeframes, p_templateFunc); } //+------------------------------------------------------------------+ //| Add new jobs to the database for the specified | //| symbols and timeframes in arrays | //+------------------------------------------------------------------+ COptimizationProject* COptimizationProject::AddJobs(string &p_symbols[], string &p_timeframes[], TJobsTemplateFunc p_templateFunc) { // For each symbol FOREACH_AS(p_symbols, m_symbol) { // For each timeframe FOREACH_AS(p_timeframes, m_timeframe) { // Get the parameters for work for a given symbol and timeframe string params = p_templateFunc(&this); // Create a new job object m_job = new COptimizationJob(0, m_stage, m_symbol, m_timeframe, params); // Insert it into the optimization database m_job.Insert(); // Add it to the array of all jobs APPEND(m_jobs, m_job); // Add it to the array of current stage jobs APPEND(m_stage.jobs, m_job); } } return &this; }
第三个参数是指向用于创建阶段 EA 优化参数的函数的指针。
COptimizationStage 类
与其他类相比,该类的描述具有许多属性,但这仅仅是因为优化数据库的 stages 表中有多个字段。对于它们中的每一个,该类中都有一个对应的属性。另请注意,指向项目对象(包括此阶段)的指针和指向上一个阶段对象的指针将传递给阶段构造函数。第一阶段没有前一阶段,因此我们将在此参数中传递 NULL 。
//+------------------------------------------------------------------+ //| Optimization stage class | //+------------------------------------------------------------------+ class COptimizationStage { public: ulong id_stage; ulong id_project; ulong id_parent_stage; string name; string expert; string symbol; string period; int optimization; int model; datetime from_date; datetime to_date; int forward_mode; datetime forward_date; int deposit; string currency; int profit_in_pips; int leverage; int execution_mode; int optimization_criterion; string status; COptimizationProject* project; COptimizationStage* parent_stage; COptimizationJob* jobs[]; COptimizationStage(ulong p_idStage, COptimizationProject* p_project, COptimizationStage* parentStage, string p_name, string p_expertName, string p_symbol = "GBPUSD", string p_timeframe = "H1", int p_optimization = 0, int p_model = 0, datetime p_fromDate = 0, datetime p_toDate = 0, int p_forwardMode = 0, datetime p_forwardDate = 0, int p_deposit = 10000, string p_currency = "USD", int p_profitInPips = 0, int p_leverage = 200, int p_executionMode = 0, int p_optimizationCriterion = 7, string p_status = "Done") : id_stage(p_idStage), project(p_project), id_project(!!p_project ? p_project.id_project : 0), parent_stage(parentStage), id_parent_stage(!!parentStage ? parentStage.id_stage : 0), name(p_name), expert(p_expertName), symbol(p_symbol), period(p_timeframe), optimization(p_optimization), model(p_model), from_date(p_fromDate), to_date(p_toDate), forward_mode(p_forwardMode), forward_date(p_forwardDate), deposit(p_deposit), currency(p_currency), profit_in_pips(p_profitInPips), leverage(p_leverage), execution_mode(p_executionMode), optimization_criterion(p_optimizationCriterion), status(p_status) {} // Create a stage in the database void Insert(); }; //+------------------------------------------------------------------+ //| Create a stage in the database | //+------------------------------------------------------------------+ void COptimizationStage::Insert() { string query = StringFormat("INSERT INTO stages VALUES(" "%s," // id_stage "%I64u," // id_project "%s," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "%s," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ");", (id_stage == 0 ? "NULL" : (string) id_stage), // id_stage id_project, // id_project (id_parent_stage == 0 ? "NULL" : (string) id_parent_stage), // id_parent_stage name, // name expert, // expert symbol, // symbol period, // period optimization, // optimization model, // model TimeToString(from_date, TIME_DATE), // from_date TimeToString(to_date, TIME_DATE), // to_date forward_mode, // forward_mode (forward_mode == 4 ? "'" + TimeToString(forward_date, TIME_DATE) + "'" : "NULL"), // forward_date deposit, // deposit currency, // currency profit_in_pips, // profit_in_pips leverage, // leverage execution_mode, // execution_mode optimization_criterion, // optimization_criterion status // status ); PrintFormat(__FUNCTION__" | %s", query); id_stage = DB::Insert(query); }
在构造函数和向 stages 表中插入新条目的方法中执行的操作非常简单:记住对象属性中传递的参数值,并使用它们来形成 SQL 查询,从而将条目插入到所需的优化数据库表中。
COptimizationJob 类
该类的结构与 COptimizationStage 类完全相同。构造函数会记住参数,而 Insert() 方法会将新行插入到优化数据库的 jobs 表中。此外,在创建期间,会将指向阶段对象的指针(包括当前作业对象)传递给每个作业对象。
//+------------------------------------------------------------------+ //| Optimization job class | //+------------------------------------------------------------------+ class COptimizationJob { public: ulong id_job; // job ID ulong id_stage; // stage ID string symbol; // Symbol string timeframe; // Timeframe string params; // Optimizer operation parameters string status; // Status COptimizationStage* stage; // Stage a job belongs to COptimizationTask* tasks[]; // Array of tasks related to the job // Constructor COptimizationJob(ulong p_jobId, COptimizationStage* p_stage, string p_symbol, string p_timeframe, string p_params, string p_status = "Done"); // Create a job in the database void Insert(); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ COptimizationJob::COptimizationJob(ulong p_jobId, COptimizationStage* p_stage, string p_symbol, string p_timeframe, string p_params, string p_status = "Done") : id_job(p_jobId), stage(p_stage), id_stage(!!p_stage ? p_stage.id_stage : 0), symbol(p_symbol), timeframe(p_timeframe), params(p_params), status(p_status) {} //+------------------------------------------------------------------+ //| Create a job in the database | //+------------------------------------------------------------------+ void COptimizationJob::Insert() { // Request to create a second stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','%s');", id_stage, symbol, timeframe, params, status); id_job = DB::Insert(query); PrintFormat(__FUNCTION__" | %s -> %I64u", query, id_job); }
最后一个剩下的 COptimizationTask 类也是以同样的方式构造的,因此我不会在这里提供它的代码。
重写 CreateProject.mq5
让我们回到 CreateProject.mq5 文件,看看它的主要参数。此文件位于项目部分,因此对于每个单独的项目,我们可以在其中指定所需的默认参数值,以便在启动时不更改它们。
首先,我们指定优化数据库的名称:
input string fileName_ = "article.17328.db.sqlite"; // - Optimization database file
在下一组参数中,我们指定以逗号分隔的交易品种和时间周期,EA 优化的第一阶段和第二阶段将分别在这些交易品种和时间周期上执行:
input string symbols_ = "GBPUSD,EURUSD,EURGBP"; // - Symbols input string timeframes_ = "H1,M30"; // - Timeframes
通过此选择,对于三个交易品种和两个时间周期的每种可能组合,将创建六个作业。
接下来是选择优化期间:
input group "::: Project parameters - Optimization interval" input datetime fromDate_ = D'2022-09-01'; // - Start date input datetime toDate_ = D'2023-01-01'; // - End date
在账户参数组中,我们选择将在第三阶段使用的主要交易品种,届时 EA 将在测试器中使用多个交易品种。如果某些交易品种在周末继续交易(例如加密货币),那么它的选择就变得很重要。在这种情况下,我们需要选择这个作为主要测试用例,否则在测试运行期间,它将不会在所有周末生成测试用例。
input group "::: Project parameters - Account" input string mainSymbol_ = "GBPUSD"; // - Main symbol input int deposit_ = 10000; // - Initial deposit
在第一阶段参数组中,指定了第一阶段 EA 的名称,尽管它可以保持不变。接下来,我们指定第一阶段中每个作业将使用的优化标准。这些只是用逗号分隔的数字。数值 6 对应于用户优化标准。
input group "::: Stage 1. Search" input string stage1ExpertName_ = "Stage1.ex5"; // - Stage EA input string stage1Criterions_ = "6,6,6"; // - Optimization criteria for tasks
在这种情况下,我们三次指定了用户标准,因此每个作业将包含三个具有指定准则的优化问题。
在第二阶段参数组中,我们增加了指定第二阶段 EA 参数所有值的功能,而不仅仅是指定组中策略的名称和数量。这些参数会影响第一阶段通过结果的选择,而这些参数将用于选择第二阶段的分组。
input group "::: Stage 2. Grouping" input string stage2ExpertName_ = "Stage2.ex5"; // - Stage EA input string stage2Criterion_ = "6"; // - Optimization criterion for tasks //input bool stage2UseClusters_= false; // - Use clustering? input double stage2MinCustomOntester_ = 500; // - Min value of norm. profit input uint stage2MinTrades_ = 20; // - Min number of trades input double stage2MinSharpeRatio_ = 0.7; // - Min Sharpe ratio input uint stage2Count_ = 8; // - Number of strategies in the group
例如,如果 stage2MinTrades_ =20 ,则只有在第一阶段完成至少 20 笔交易的个人交易策略实例才能加入该组。目前 stage2UseClusters_ 参数已被注释掉,因为我们目前没有使用第二阶段结果的聚类。因此,应该将其替换为 false 。
我们还向第三阶段参数组添加了一些内容。除了第三阶段 EA 的名称(在更改项目时也不需要更改)之外,还添加了两个参数来控制最终 EA 数据库名称的形成。在最终 EA 程序中,该名称是在 CVirtualAdvisor::FileName() 函数中根据以下模板生成的:
<Project name>-<Magic>.test.db.sqlite // To run in the tester <Project name>-<Magic>.db.sqlite // To run on a trading account
因此,第三阶段 EA 使用相同的模板。<Project name>> 替换为 projectName_ ,而 <Magic> 替换为 stage3Magic_ 。stage3Tester_ 参数负责添加“.test”后缀。
input group "::: Stage 3. Result" input string stage3ExpertName_ = "Stage3.ex5"; // - Stage EA input ulong stage3Magic_ = 27183; // - Magic input bool stage3Tester_ = true; // - For the tester?
原则上,可以创建一个参数,该参数只需指示最终 EA 数据库的全名即可。完成第三阶段后,生成的数据库文件可以根据需要安全地重命名,然后再进行进一步使用。
现在我们只需要创建函数,使用给定的模板为阶段 EA 生成参数。由于我们使用了三个阶段,因此我们需要三个函数。
对于第一阶段,该函数如下所示:
// Template of optimization parameters at the first stage string paramsTemplate1(COptimizationProject *p) { string params = StringFormat( "symbol_=%s\n" "period_=%d\n" "; === Open signal parameters\n" "signalSeqLen_=4||2||1||8||Y\n" "periodATR_=21||7||2||48||Y\n" "; === Pending order parameters\n" "stopLevel_=2.34||0.01||0.01||5.0||Y\n" "takeLevel_=4.55||0.01||0.01||5.0||Y\n" "; === Capital management parameters\n" "maxCountOfOrders_=15||1||1||30||Y\n", p.m_symbol, p.StringToTimeframe(p.m_timeframe)); return params; }
它基于从策略测试器复制的第一阶段 EA 的优化参数,并设置了迭代各个输入参数的期望范围。该字符串填充有交易品种和时间周期的值,当调用此函数时,将在项目中为该交易品种和时间周期创建一个作业对象。例如,如果在某个时间段内需要使用其他输入范围进行迭代,则可以在此函数中实现此逻辑。
当迁移到另一个具有不同交易策略的项目时,应该将此函数替换为另一个为新的交易策略及其输入集编写的函数。
在第二和第三阶段,我们也在 CreateProject.mq5 文件中实现了这些函数。但是,当转移到另一个项目时,它们很可能不需要更改。但我们先别急着把它们带到库区域。让它们暂时待在这里:
// Template of optimization parameters for the second stage string paramsTemplate2(COptimizationProject *p) { // Find the parent job ID for the current job // by matching the symbol and timeframe at the current and parent stages int i; SEARCH(p.m_stage.parent_stage.jobs, (p.m_stage.parent_stage.jobs[i].symbol == p.m_symbol && p.m_stage.parent_stage.jobs[i].timeframe == p.m_timeframe), i); ulong parentJobId = p.m_stage.parent_stage.jobs[i].id_job; string params = StringFormat( "idParentJob_=%I64u\n" "useClusters_=%s\n" "minCustomOntester_=%f\n" "minTrades_=%u\n" "minSharpeRatio_=%.2f\n" "count_=%u\n", parentJobId, (string) false, //(string) stage2UseClusters_, stage2MinCustomOntester_, stage2MinTrades_, stage2MinSharpeRatio_, stage2Count_ ); return params; } // Template of optimization parameters at the third stage string paramsTemplate3(COptimizationProject *p) { string params = StringFormat( "groupName_=%s\n" "advFileName_=%s\n" "passes_=\n", StringFormat("%s_v.%s_%s", p.name, p.version, TimeToString(toDate_, TIME_DATE)), StringFormat("%s-%I64u%s.db.sqlite", p.name, stage3Magic_, (stage3Tester_ ? ".test" : ""))); return params; }
接下来是初始化函数的代码,它会完成所有工作,并在结束前将 EA 从图表中移除。现在让我们用被调用函数的参数来演示一下:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create an optimization project object for the given database COptimizationProject p(fileName_); // Create a new project in the database p.Create(projectName_, projectVersion_, StringFormat("%s - %s", TimeToString(fromDate_, TIME_DATE), TimeToString(toDate_, TIME_DATE))); // Add the first stage p.AddStage(NULL, "First", stage1ExpertName_, mainSymbol_, "H1", 2, 2, fromDate_, toDate_, 0, 0, deposit_); // Adding the first stage jobs p.AddJobs(symbols_, timeframes_, paramsTemplate1); // Add tasks for the first stage jobs p.AddTasks(stage1Criterions_); // Add the second stage p.AddStage(p.m_stages[0], "Second", stage2ExpertName_, mainSymbol_, "H1", 2, 2, fromDate_, toDate_, 0, 0, deposit_); // Add the second stage jobs p.AddJobs(symbols_, timeframes_, paramsTemplate2); // Add tasks for the second stage jobs p.AddTasks(stage2Criterion_); // Add the third stage p.AddStage(p.m_stages[1], "Save to library", stage3ExpertName_, mainSymbol_, "H1", 0, 2, fromDate_, toDate_, 0, 0, deposit_); // Add the third stage job p.AddJobs(mainSymbol_, "H1", paramsTemplate3); // Add a task for the third stage job p.AddTasks("0"); // Put the project in the execution queue p.Queue(); // Delete the EA ExpertRemove(); // Successful initialization return(INIT_SUCCEEDED); }
除非我们想要改变自动优化输送机阶段的组成,否则将这部分代码迁移到另一个项目时也不需要更改。随着时间的推移,我们也会不断改进它。例如,代码当前包含数字常量,应将其替换为命名常量以提高可读性。如果事实证明这段代码真的不需要任何更改,那么我们将把它移到库部分。
因此,用于在数据库中创建优化项目的 EA 已经准备就绪。现在我们来创建阶段 EA。
阶段 EA
我们在上一篇文章中已经实现了 Stage1.mq5 ,所以现在我们只对其进行了与向交易策略中添加新的 maxSpread_ 参数相关的更改。这些修改前面已经讨论过了。
// 1. Define a constant with the EA name #define __NAME__ "SimpleCandles" + MQLInfoString(MQL_PROGRAM_NAME) // 2. Connect the required strategy #include "Strategies/SimpleCandlesStrategy.mqh"; // 3. Connect the general part of the first stage EA from the Advisor library #include <antekov/Advisor/Experts/Stage1.mqh> //+------------------------------------------------------------------+ //| 4. Strategy inputs | //+------------------------------------------------------------------+ sinput string symbol_ = ""; // Symbol sinput ENUM_TIMEFRAMES period_ = PERIOD_CURRENT; // Timeframe for candles input group "=== Opening signal parameters" input int signalSeqLen_ = 6; // Number of unidirectional candles input int periodATR_ = 0; // ATR period (if 0, then TP/SL in points) input group "=== Pending order parameters" input double stopLevel_ = 25000; // Stop Loss (in ATR fraction or points) input double takeLevel_ = 3630; // Take Profit (in ATR fraction or points) input group "=== Money management parameters" input int maxCountOfOrders_ = 9; // Max number of simultaneously open orders input int maxSpread_ = 10; // Max acceptable spread (in points) //+------------------------------------------------------------------+ //| 5. Strategy initialization string generation function | //| from the inputs | //+------------------------------------------------------------------+ string GetStrategyParams() { return StringFormat( "class CSimpleCandlesStrategy(\"%s\",%d,%d,%d,%.3f,%.3f,%d,%d)", (symbol_ == "" ? Symbol() : symbol_), period_, signalSeqLen_, periodATR_, stopLevel_, takeLevel_, maxCountOfOrders_, maxSpread_ ); }
在第二阶段和第三阶段的 EA 中,我们只需要定义 __NAME__ 常量,使用唯一的 EA 名称,并连接所使用的交易策略文件即可。其余代码将取自相应阶段的包含库文件。以下是第二阶段 EA 的代码,可能看起来类似于Stage2.mq5:
// 1. Define a constant with the EA name #define __NAME__ "SimpleCandles" + MQLInfoString(MQL_PROGRAM_NAME) // 2. Connect the required strategy #include "Strategies/SimpleCandlesStrategy.mqh"; #include <antekov/Advisor/Experts/Stage2.mqh>
以及第三阶段 Stage3.mq5 :
// 1. Define a constant with the EA name #define __NAME__ "SimpleCandles" + MQLInfoString(MQL_PROGRAM_NAME) // 2. Connect the required strategy #include "Strategies/SimpleCandlesStrategy.mqh"; #include <antekov/Advisor/Experts/Stage3.mqh>
最终 EA
在最终 EA 中,我们只需要添加与所用策略的连接即可。这里不需要声明 __NAME__ 常量,因为在这种情况下,常量和用于生成初始化字符串的函数都将在库部分包含的文件中声明。下面的代码中,我们在注释中展示了 EA 名称和用于生成初始化字符串的函数在本例中的样子:
// 1. Define a constant with the EA name //#define __NAME__ MQLInfoString(MQL_PROGRAM_NAME) // 2. Connect the required strategy #include "Strategies/SimpleCandlesStrategy.mqh"; #include <antekov/Advisor/Experts/Expert.mqh> //+------------------------------------------------------------------+ //| Function for generating the strategy initialization string | //| from the default inputs (if no name was specified). | //| Import the initialization string from the EA database | //| by the strategy group ID | //+------------------------------------------------------------------+ //string GetStrategyParams() { //// Take the initialization string from the new library for the selected group //// (from the EA database) // string strategiesParams = CVirtualAdvisor::Import( // CVirtualAdvisor::FileName(__NAME__, magic_), // groupId_ // ); // //// If the strategy group from the library is not specified, then we interrupt the operation // if(strategiesParams == NULL && useAutoUpdate_) { // strategiesParams = ""; // } // // return strategiesParams; //}
如果我们突然想对此进行更改,那么从这段代码中删除注释并对其进行必要的编辑就足够了。
因此,在项目部分,我们将包含以下文件:
让我们编译项目部分的所有文件,以便为每个扩展名为 mq5 的文件创建一个扩展名为 ex5 的文件。
把所有东西整合起来
第一步:创建项目
将 CreateProject.ex5 EA 拖到终端中的任何图表上(此 EA 不需要在测试器中运行!)。在 EA 源代码中,我们已经尝试指定所有输入参数的当前值,因此您只需在对话框中单击“确定”即可。
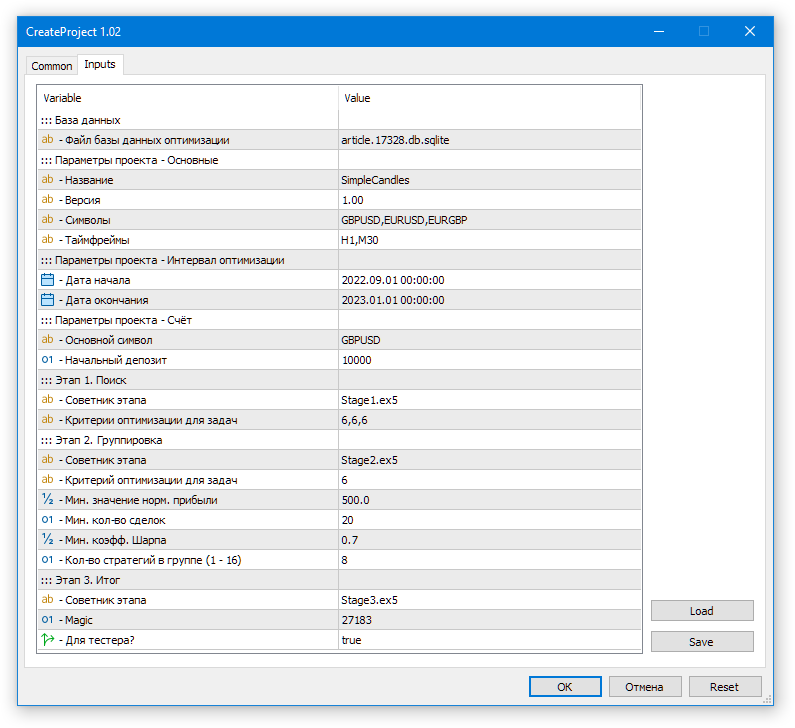
图 1.在优化数据库中启动项目创建 EA
这样,我们将得到包含优化数据库的 article.17328.db.sqlite 文件。
第二步:优化开始
将 Optimization.ex5 EA(此 EA 也不需要先在测试器中运行!)拖到任意图表上。在打开的对话框中,启用 DLL 的使用,并确保已指定正确的优化数据库名称:
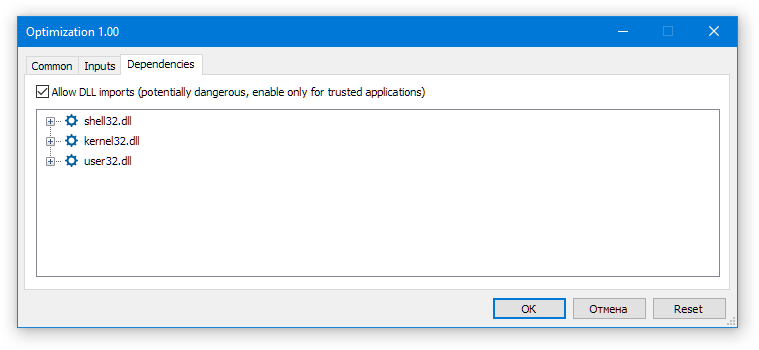
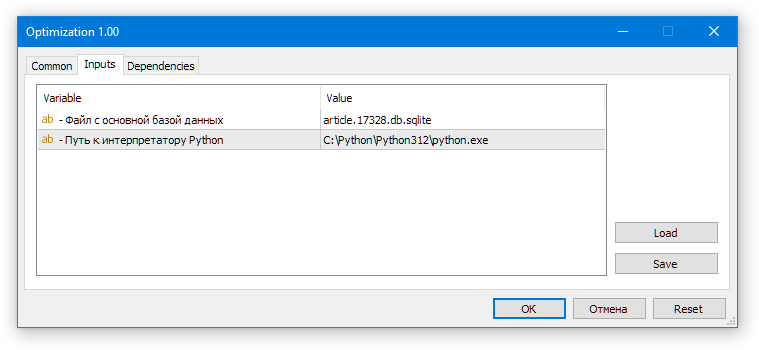
图 2.启动自动优化 EA
如果一切正常,我们应该看到类似这样的情况:在测试器中,第一阶段 EA 的优化从第一个交易品种-时间周期组合开始,而在运行 Optimization.ex5 EA的图表上,我们将看到以下内容:"Total tasks in queue: ..., Current Task ID: ...".
图 3.自动优化 EA 运行。
接下来,您需要等待一段时间,直到所有优化任务完成。如果测试间隔较长,且交易品种和时间周期数量较多,那么这段时间可能相当重要。在当前默认设置下,33 个代理的整个过程大约需要 4 个小时。
在输送机的最后一个阶段,不再进行优化,而是启动第三阶段 EA 的单次运行。因此,会创建一个包含最终 EA 数据库的文件。由于我们在创建项目时选择了项目名称“SimpleCandles”,而幻数为 27183,并且 stage3Tester_=true ,因此将在共享终端中创建一个名为 SimpleCandles-27183.test.db.sqlite 的文件。
第三步:在测试器中启动最终 EA
我们来测试一下最终 EA 在测试器中运行情况。由于其代码现在完全取自库部分,因此默认参数值也在那里定义。因此,当我们在测试器中启动 SimpleCandles.ex5 EA 而不更改输入值时,它将使用数据库中最后添加的策略组( groupId_= 0 ),并启用自动更新( useAutoUpdate_= true )( SimpleCandles-27183.test.db.sqlite ,即 SimpleCandles EA 文件名加上默认幻数 magic_= 27183 ,加上“.test”后缀,因为是在测试器中运行)。
遗憾的是,我们还没有创建任何特殊的工具来查看最终 EA 数据库中现有的策略组 ID。我们只能在任何 SQLite 编辑器中打开数据库本身,并在 strategy_groups 表中查看它们。
但是,如果只创建并运行了一个优化项目,那么最终 EA 数据库中只会出现一个 ID 为 1 的策略组。因此,从组选择的角度来看,指定 groupId_= 1或将 groupId_= 0 留空都没有什么区别。无论如何,只会加载已存在的组。如果我们再次运行同一个项目(这可以通过直接在数据库中更改项目状态来实现),或者创建另一个类似的项目并运行它,那么新的策略组将出现在最终 EA 数据库中。在这种情况下,不同的 groupId_ 参数值将使用不同的组。
自动更新启用参数( useAutoUpdate_= true )也需要我们注意。即使只有一个组,该参数也会影响最终 EA 的运行。这体现在,当启用自动更新时,只有出现日期早于当前模拟日期的策略组才能被加载以进行工作。
这意味着,如果我们使用与优化相同的时间间隔(2022.09.01 - 2023.01.01)运行最终 EA,那么我们唯一的策略组将不会被加载,因为它的形成日期是 2023.01.01。因此,我们需要在启动最终 EA 时,要么关闭自动更新( useAutoUpdate_= false ),并在输入中指定所使用的交易策略组的特定 ID( groupId_= 1) ,要么选择优化间隔结束日期之后的另一个间隔。
一般来说,在我们最终确定最终 EA 将采用哪些策略,并且尚未设定测试这些策略是否可进行定期重新优化的目标之前,可以将此参数设置为 false ,并指定正在使用的交易策略组的具体 ID。
最后一组重要参数决定了最终 EA 将使用哪个数据库名称。默认设置下,幻数与我们在创建项目时在设置中指定的幻数相同。我们还使最终 EA 文件的名称与项目名称保持一致。创建项目时, stage3Tester_ 参数值为 true ,因此最终 EA 创建的数据库文件名将是 SimpleCandles-27183.test.db.sqlite 。它与最终的 SimpleCandles.ex5 EA 将使用的内容完全一致。
让我们来看看最终 EA 在优化期间内运行的结果:
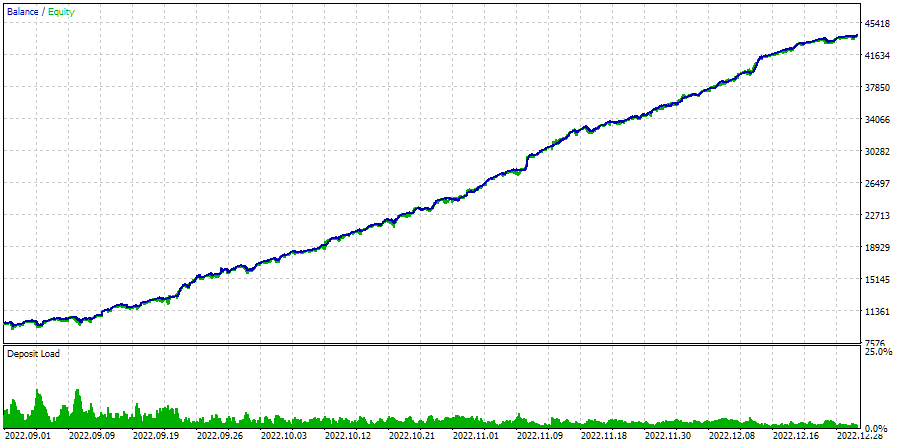
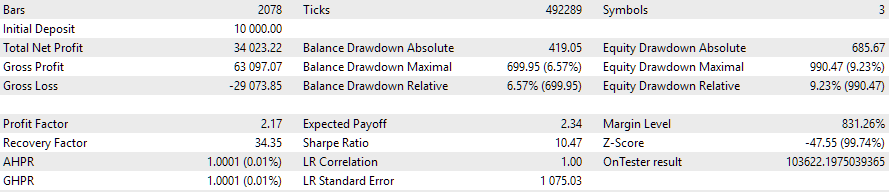
图 4.2022.09.01 - 2023.01.01 期间的自动优化 EA 操作
如果我们换个时间期间运行,结果很可能不会这么理想:
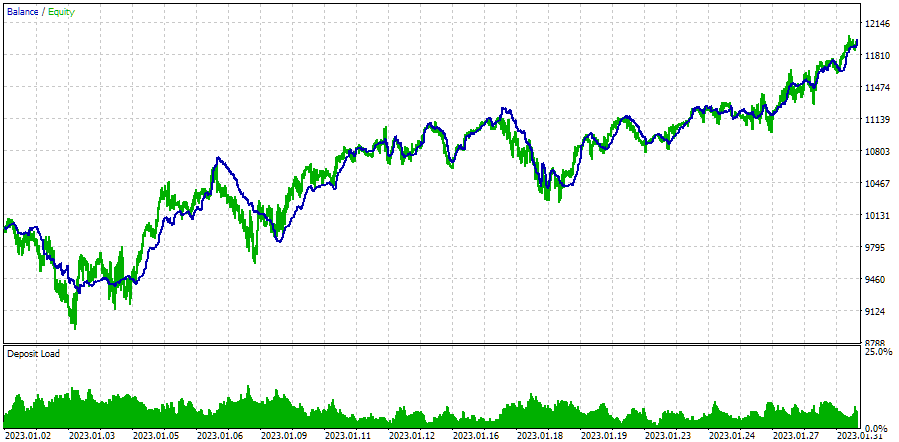
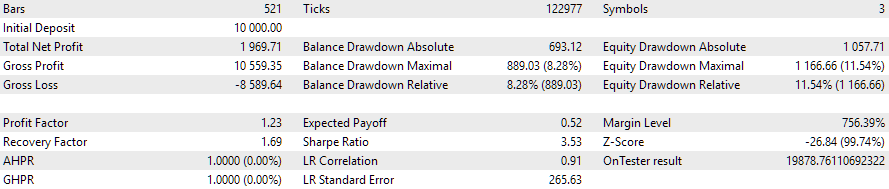
图 5.2023.01.01 - 2023.02.01 期间自动优化 EA 操作
我们以优化周期之后紧接着的一个月为期间作为示例。事实上,回撤幅度略高于预期的 10%,而标准化利润下降了约五倍。能否重新运行过去三个月的优化,从而获得 EA 在接下来的一个月中的类似行为情况?这个问题目前仍未解决。
第四步:在交易账户上启动最终 EA
要在交易账户上运行最终 EA,我们需要调整生成的数据库文件的名称。我们应该去掉文件名后的“.test”后缀。换句话说,我们只需将 SimpleCandles-27183.test.db.sqlite 重命名并复制到SimpleCandles-27183.db.sqlite 即可。它的位置保持不变 —— 在通用终端文件夹中。
将最终的 SimpleCandles.ex5 EA 拖放到任何终端图表上。在输入中,我们可能会将所有内容保留为默认值,因为我们对加载最后一组策略非常满意,而且当前日期显然会大于该组的创建日期。
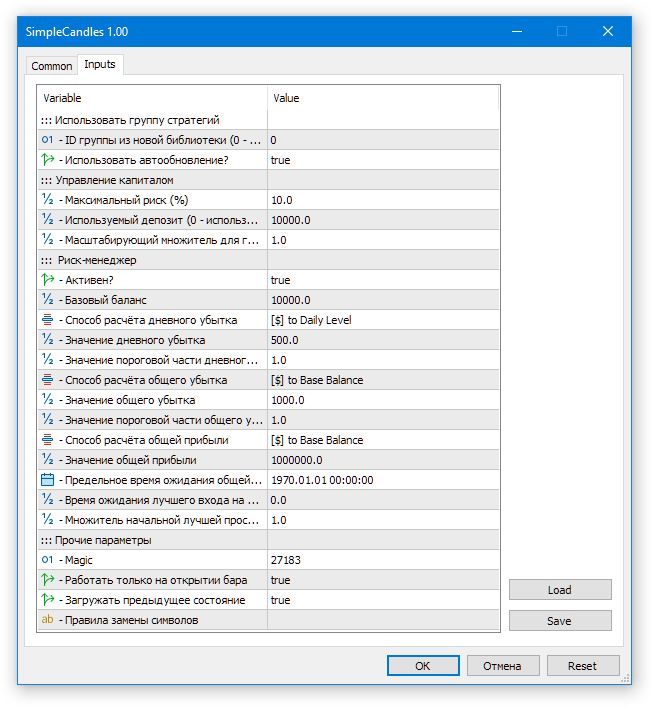
图 6.最终 EA 的默认输入参数
在撰写本文期间,最终 EA 在模拟账户上进行了大约一周的测试,结果如下:
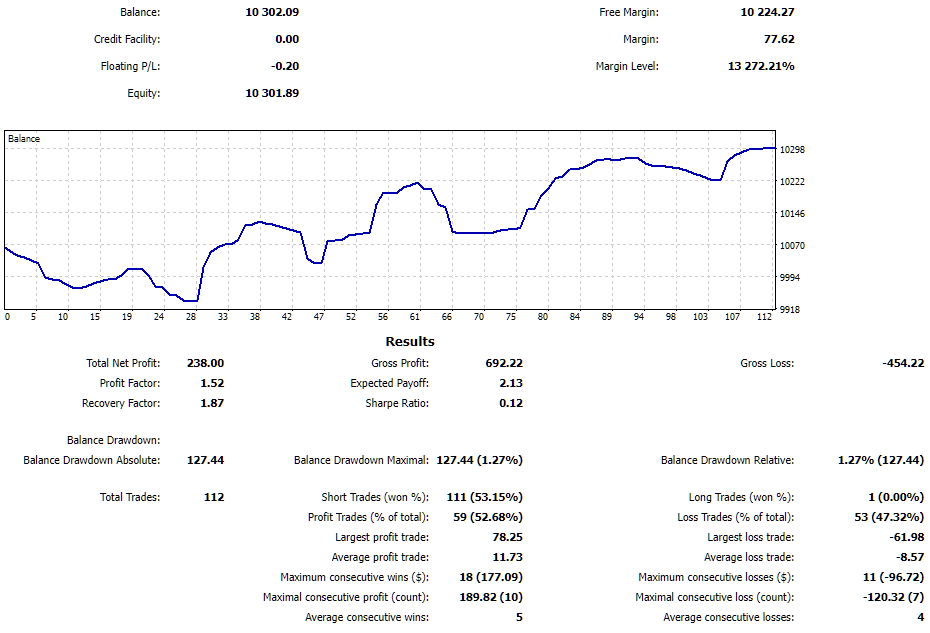
图 7.最终 EA 在交易账户上的运行结果
对 EA 来说,这周过得相当不错。回撤幅度为 1.27%,利润约为 2%。由于电脑重启,EA 重启了几次,但成功恢复了有关未平仓虚拟仓位的信息并继续运行。
结论
让我们看看有什么收获。我们终于将一个相当漫长的开发过程的结果整合成一个连贯的系统。由此产生的用于组织自动优化和测试交易策略的工具,通过跨不同交易工具的多样化,可以显著改善即使是简单交易策略的测试结果。
它还允许大幅减少需要人工干预以实现相同目标的操作数量。现在,在启动下一个优化之前,不需要跟踪另一个优化的完成情况,也不需要考虑如何保存中间优化结果,以及如何将它们集成到交易 EA 中。相反,我们可以直接专注于开发交易策略背后的逻辑。
当然,仍有许多工作要做,以改进和使这个工具更方便。一个功能齐全的 Web 界面,不仅可以管理正在运行的优化项目的创建、启动和监控,还可以管理在各种终端上运行的 EA 的操作并查看其统计数据,这仍然是一个遥远的未来。这是一项非常艰巨的任务,但回头看,今天已经或多或少得到完整解决方案的任务也是如此。
感谢您的关注!期待很快与您见面!
重要警告
本文和本系列之前的所有文章中的所有结果仅基于历史测试数据,并不保证未来会有任何利润。该项目中的工作具有研究性质。所有已发表的结果都可以由任何人使用,风险自负。
存档内容
| # | 名称 | 版本 | 描述 | 最近修改 |
|---|---|---|---|---|
| MQL5/Experts/Article.17328 | 项目工作文件夹 | |||
| 1 | CreateProject.mq5 | 1.02 | 用于创建具有阶段、作业和优化任务的项目的 EA 脚本。 | 第 25 部分 |
| 2 | Optimization.mq5 | 1.00 | 用于项目自动优化的 EA | 第 23 部分 |
| 3 | SimpleCandles.mq5 | 1.01 | 最终 EA,用于并行运行多组模型策略。参数将从内置组库中获取。 | 第 25 部分 |
| 4 | Stage1.mq5 | 1.02 | 交易策略单实例优化 EA(第一阶段) | 第 25 部分 |
| 5 | Stage2.mq5 | 1.01 | 交易策略实例组优化 EA(第二阶段) | 第 25 部分 |
| 6 | Stage3.mq5 | 1.01 | EA 将生成的标准化策略组保存到具有给定名称的 EA 数据库中。 | 第 25 部分 |
| MQL5/Experts/Article.17328/Strategies | 项目策略文件夹 | |||
| 7 | SimpleCandlesStrategy.mqh | 1.01 | SimpleCandles 交易策略类 | 第 25 部分 |
| MQL5/Include/antekov/Advisor/Base | 其他项目类所继承的基类 | |||
| 8 | Advisor.mqh | 1.04 | EA 基类 | 第 10 部分 |
| 9 | Factorable.mqh | 1.05 | 从字符串创建的对象的基类 | 第 24 部分 |
| 10 | FactorableCreator.mqh | 1.00 | 第 24 部分 | |
| 11 | Interface.mqh | 1.01 | 可视化各种对象的基类 | 第 4 部分 |
| 12 | Receiver.mqh | 1.04 | 将未平仓交易量转换为市场仓位的基类 | 第 12 部分 |
| 13 | Strategy.mqh | 1.04 | 交易策略基类 | 第 10 部分 |
| MQL5/Include/antekov/Advisor/Database | 用于处理项目 EA 使用的所有类型数据库的文件 | |||
| 14 | Database.mqh | 1.12 | 处理数据库的类 | 第 25 部分 |
| 15 | db.adv.schema.sql | 1.00 | 最终 EA 的数据库结构 | 第 22 部分 |
| 16 | db.cut.schema.sql | 1.00 | 截断优化数据库的结构 | 第 22 部分 |
| 17 | db.opt.schema.sql | 1.05 | 优化数据库结构 | 第 22 部分 |
| 18 | Storage.mqh | 1.01 | 用于处理 EA 数据库中最终 EA 的键值存储的类 | 第 23 部分 |
| MQL5/Include/antekov/Advisor/Experts | 包含不同类型已使用 EA 的公共部分的文件 | |||
| 19 | Expert.mqh | 1.22 | 最终 EA 的库文件。组参数可以从 EA 数据库中获取。 | 第 23 部分 |
| 20 | Optimization.mqh | 1.04 | 用于管理优化任务启动 EA 的库文件 | 第 23 部分 |
| 21 | Stage1.mqh | 1.19 | 单实例交易策略优化 EA(第一阶段)的库文件 | 第 23 部分 |
| 22 | Stage2.mqh | 1.04 | 用于优化一组交易策略实例的 EA 的库文件(第二阶段) | 第 23 部分 |
| 23 | Stage3.mqh | 1.04 | EA 库文件,用于将生成的标准化策略组保存到具有给定名称的 EA 数据库中。 | 第 23 部分 |
| MQL5/Include/antekov/Advisor/Optimization | 负责自动优化的类 | |||
| 24 | OptimizationJob.mqh | 1.00 | 优化项目阶段作业类 | 第 25 部分 |
| 25 | OptimizationProject.mqh | 1.00 | 优化项目类 | 第 25 部分 |
| 26 | OptimizationStage.mqh | 1.00 | 优化项目阶段类 | 第 25 部分 |
| 27 | OptimizationTask.mqh | 1.00 | 优化任务类(创建) | 第 25 部分 |
| 28 | Optimizer.mqh | 1.03 | 项目自动优化管理器类 | 第 22 部分 |
| 29 | OptimizerTask.mqh | 1.03 | 优化任务类(输送机) | 第 22 部分 |
| MQL5/Include/antekov/Advisor/Strategies | 用于演示项目如何运作的交易策略示例 | |||
| 30 | HistoryStrategy.mqh | 1.00 | 用于回放交易历史的交易策略类 | 第 16 部分 |
| 31 | SimpleVolumesStrategy.mqh | 1.11 | 使用分时交易量的交易策略类 | 第 22 部分 |
| MQL5/Include/antekov/Advisor/Utils | 辅助工具、用于代码简化的宏 | |||
| 32 | ExpertHistory.mqh | 1.00 | 用于将交易历史导出到文件的类 | 第 16 部分 |
| 33 | Macros.mqh | 1.06 | 用于数组操作的有用的宏 | 第 25 部分 |
| 34 | NewBarEvent.mqh | 1.00 | 用于定义特定交易品种的新柱形的类 | 第 8 部分 |
| 35 | SymbolsMonitor.mqh | 1.00 | 用于获取交易工具(交易品种)信息的类 | 第 21 部分 |
| MQL5/Include/antekov/Advisor/Virtual | 通过使用虚拟交易订单和头寸系统创建各种对象的类 | |||
| 36 | Money.mqh | 1.01 | 资金管理基类 | 第 12 部分 |
| 37 | TesterHandler.mqh | 1.07 | 优化事件处理类 | 第 23 部分 |
| 38 | VirtualAdvisor.mqh | 1.10 | 处理虚拟仓位(订单)的 EA 类 | 第 24 部分 |
| 39 | VirtualChartOrder.mqh | 1.01 | 图形虚拟仓位类 | 第 18 部分 |
| 40 | VirtualHistoryAdvisor.mqh | 1.00 | 交易历史回放 EA 类 | 第 16 部分 |
| 41 | VirtualInterface.mqh | 1.00 | EA GUI 类 | 第 4 部分 |
| 42 | VirtualOrder.mqh | 1.09 | 虚拟订单和仓位类 | 第 22 部分 |
| 43 | VirtualReceiver.mqh | 1.04 | 将未平仓交易量转换为市场仓位的类(接收方) | 第 23 部分 |
| 44 | VirtualRiskManager.mqh | 1.05 | 风险管理类(风险管理器) | 第 24 部分 |
| 45 | VirtualStrategy.mqh | 1.09 | 具有虚拟仓位的交易策略类 | 第 23 部分 |
| 46 | VirtualStrategyGroup.mqh | 1.03 | 交易策略组类 | 第 24 部分 |
| 47 | VirtualSymbolReceiver.mqh | 1.00 | 交易品种接收器类 | 第 3 部分 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/17328
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
首先,我想知道这是什么语言。
是韩语,不知为什么你的浏览器没有显示。
是韩文,但你的浏览器不显示。
没错。2025.07.08 从一开始,我就没有在这个主题中发布任何内容。如果你按照那个链接进入主题,就会看到一个日期不同的帖子。这可能也是我的浏览器的错,你们剩下的程序员跟不上了。
没错。在 2025.07.08 这一天,我从一开始就没有在这个主题中发布任何内容。如果你按照这个链接进入主题,就会看到一个日期不同的帖子。这可能也是我的浏览器的错,你们剩下的程序员跟不上了。
谢谢你的坚持,已经修好了。
谢谢你的坚持,已更正。
很抱歉您的坚持,我没有看到修复方法。链接仍然指向一条奇怪的信息,而这不是我写的。好吧,就算我们假设是我写的,那为什么旁边没有俄语信息呢?还是你认为如果我学不会英语,我学过韩语,我有乐趣....?
这就是用不同语言进行讨论的不同之处。
这是链接中的内容。
这是俄语翻译。
这是俄文版的文章。
那么,我想用哪种语言来写?????
这只是一个话题。如果你看看其他的主题,你会发现信息的来源都很奇怪,使用的语言都是我做梦都想不到的。
我可能反应过度了。我只发现了另外一条类似的信息,用的是英语,可能是真正的翻译。
请删除所有语言版本的上述信息,可能会得到更正。也许不会像上次那样完全.......
关于交易、自动交易系统和交易策略测试的论坛
讨论文章 "开发多币种智能交易系统(第 25 部分):插入新策略(二)"
Rashid Umarov, 2025.07.06 14:04
谢谢,我们会解决的。
我们已经解决了这个问题,但似乎还没有完全 解决。