
开发多币种 EA 交易 (第 11 部分):自动化优化(第一步)
概述
在上一篇文章中,我们为轻松利用优化获得的结果来构建一个具有多个交易策略实例协同工作的现成 EA 奠定了基础。现在我们不必在代码或 EA 输入中手动输入所有使用的实例的参数。我们只需要将初始化字符串以某种格式保存到文件中,或者将其作为文本插入到源代码中,这样 EA 就可以使用它。
到目前为止,初始化字符串已经手动生成。现在,终于到了根据获得的优化结果开始实现 EA 初始化字符串的自动生成的时候了。最有可能的是,在本文的范围内,我们不会有一个完全自动化的解决方案,但至少我们会在预期的方向上取得重大进展。
设定任务
总的来说,我们的目标可以表述如下:我们希望获得一个在终端中运行的 EA,并使用一个交易策略实例在多个交易品种和时间框架内执行 EA 优化。假设这些交易品种为 EURGBP、EURUSD 和 GBPUSD,而时间框架是 H1、M30 和 M15。我们需要能够从存储在数据库中的每次优化过程的结果中选择与特定交易品种和时间框架相关的结果(以及稍后与其他一些测试参数组合相关的结果)。
我们将根据不同的标准,从一个交易品种时间框架组合的每组结果中选出一些最佳结果。我们将所有选定的实例放入一个实例组中(目前如此)。然后我们需要确定组乘数。将来会有一个单独的 EA 来执行此操作,但是现在我们可以手动执行此操作。
我们根据所选的组和乘数生成最终 EA 中要使用的初始化字符串。
概念
让我们介绍几个额外的概念以供进一步使用:
- 通用 EA 是一个 EA 交易,它接收初始化字符串,使其准备好在交易账户上工作。我们可以让它从输入参数中指定的名称的文件中读取初始化字符串,或者通过项目名称和版本从数据库中获取它。
- 优化 EA 是一个负责执行所有操作以优化项目的 EA。在图表上运行时,它将在数据库中搜索有关必要的优化操作的信息并按顺序执行它们。其工作的最终结果将是为通用 EA 保存的初始化字符串。
- 阶段 EA 是直接在测试器中优化的 EA。根据实现的阶段数量,将有几个这样的 EA。优化 EA 将启动这些 EA 进行优化并跟踪其完成情况。
在本文中,我们将限制在一个阶段优化单个交易策略实例的参数。第二阶段将涉及将几个最佳实例合并为一组并对其进行规范化。我们现在将手动执行此操作。
作为一个通用 EA,我们将制作一个可以自行构建初始化字符串的 EA,从数据库中选择有关交易策略好的示例的信息。
数据库中必要的优化操作的信息应该以方便的形式存储。我们应该能够相对轻松地创建这种信息。我们暂时先不考虑这些信息如何进入数据库的问题。我们稍后可以实现一个用户友好的界面。目前主要做的是了解这些信息的结构并在数据库中为其创建相应的表结构。
让我们从识别更一般的实体开始,然后逐渐转向更简单的实体。最后,我们应该来到之前创建的实体,它代表有关单个测试器通过的信息。
项目
项目(Project)实体位于顶层,这是一个复合实体:一个项目将包含多个阶段。阶段(Stage)实体将在下面探讨。项目以名称和版本为特征,它可能还包含一些描述。一个项目可以有几种状态:“已创建(created)”、“已排队运行(queued for run)”、“正在运行(running)”和“已完成(completed)”。将项目执行结果获得的通用 EA 的初始化字符串存储在此实体中也是合乎逻辑的。
为了方便在 MQL5 程序中使用来自数据库的信息,我们将来会实现一个简单的 ORM,也就是说,我们将在 MQL5 中创建代表我们将存储在数据库中的所有实体的类。
“项目”实体的类对象将在数据库中存储以下内容:
- id_project – 项目 ID。
- name – 通用 EA 中用于搜索初始化字符串的项目名称。
- version – 要定义的项目版本,例如,通过交易策略实例的版本。
- description – 项目描述,包含一些重要细节的任意文本。它可能为空。
- params – 项目完成时要填充的通用 EA 初始化字符串。它的初值为空。
- status – 项目状态(Created - 已创建、Queued - 已排队、Processing - 正在处理、Done - 已完成)。最初,项目创建时状态为“Created”。
字段列表以后可能会扩展。
当项目准备好运行时,它将移至“Queued”状态。目前,我们将手动进行此转换。我们的优化 EA 将搜索具有此状态的项目并将其移至 “Processing”状态。
在任何阶段开始和完成时,我们都会检查是否需要更新项目状态。如果第一阶段已经开始,项目将进入”Processing”状态。当最后一个阶段完成后,项目就进入”Done”状态。此时,params 字段值将被填充,以便我们收到一个初始化字符串,该字符串可以在项目完成时传递给通用 EA。
阶段
正如前面提到的,每个项目的实现都分为几个阶段。阶段的主要特征是将在此阶段框架内启动 EA,以便在测试器中进行优化(阶段 EA)。阶段中还将设置测试间隔。此间隔对于此阶段执行的所有优化都是相同的。我们还应该提供有关优化的其他信息(初始存款、分时报价模拟模式等)的存储。
一个阶段可以有一个指定的父阶段(或前一个阶段)。在这种情况下,只有在父阶段完成后,该阶段的执行才会开始。
此类的对象将在数据库中存储以下内容:
- id_stage – 阶段 ID。
- id_project – 该阶段所属的项目ID。
- id_parent_stage – 父(前一个)阶段 ID。
- name – 阶段名称。
- expert – 在此阶段启动优化的 EA 的名称。
- from_date – 优化期开始日期。
- to_date – 优化期结束日期。
- forward_date – 优化前向期开始日期。它可能为空,这样的话就不使用前向模式。
- 其他具有优化参数的字段 (初始存款、分时报价模拟模式等),在大多数情况下将具有不需要更改的默认值
- status – 阶段状态,有三种可能的值:Queued,Processing,Done。最初,创建一个具有 Queued 状态的阶段。
每个阶段又由一项或多项作业(job)组成。当第一个作业开始时,该阶段进入 Processing 状态。当所有作业完成后,该阶段进入 Done 状态。
作业
每个阶段的实现由其中包含的所有作业的顺序执行组成。作业的主要特征是 EA 的交易品种、时间框架和输入参数,这些在包含这项作业的阶段进行了优化。
此类的对象将在数据库中存储以下内容:
- id_job – 作业 ID。
- id_stage – 作业所属阶段的 ID。
- symbol – 测试交易品种(交易工具)。
- period – 测试时间框架。
- tester_inputs – EA 优化输入参数的设置。
- status – 作业状态(Queued、Processing 或 Done)。最初,创建的作业处于 Queued 状态。
每项作业将包含一个或多个优化任务。当第一个优化任务开始时,作业进入 Processing 状态。当所有优化任务完成后,作业进入 Done 状态。
优化任务
每个任务的执行都是由其所包含的所有任务的顺序执行组成的。问题的主要特征是优化标准。测试器的其余设置将由作业任务继承。
此类型的对象将在数据库中存储以下内容:
- id_task – 任务 ID。
- id_job – 作业 ID,作业在该 ID 内执行。
- optimization_criterion – 针对给定任务的优化标准。
- start_date – 优化任务开始时间。
- finish_date – 优化任务结束时间。
- status – 优化任务状态(Queued、Processing、Done)。最初,创建一个具有 Queued 状态的优化任务。
每个任务将包含几个优化通过。当第一次优化通过开始时,优化任务进入 Processing 状态。当所有优化通过完成后,优化任务进入 Done 状态。
优化通过
我们已经在之前的一篇文章中探讨过这个问题,其中我们在策略测试器中添加了在优化期间自动保存所有通过结果的功能。现在我们将添加一个新字段,其中包含执行此通过的任务 ID。
此类型的对象将在数据库中存储以下内容:
- id_pass – 通过 ID。
- id_task – 执行通过的任务的 ID。
- 通过结果字段 – 通过的所有可用统计数据的字段组(通过编号、交易编号、利润因子等)。
- params – 包含通过中使用的策略实例参数的初始化字符串。
- inputs – 通过输入参数值。
- pass_date – 通过结束时间。
与之前的实现相比,我们改变了每次通过中使用的策略参数的存储信息的组成。更一般地说,我们需要存储有关一组策略的信息。因此,我们将使包含一个策略的策略组也保存为单个策略。
通行将没有状态字段,因为仅在通行完成后才会将条目添加到表中,而不是在通行开始之前。因此,只要有入口,就意味着通过已经完成。
由于我们的数据库已经大大丰富了其结构,我们将对负责创建和使用数据库的程序代码进行修改。
创建和管理数据库
在开发过程中,我们将不得不反复重新创建结构更新过的数据库。因此,我们将制作一个简单的辅助脚本,它将执行单一操作 - 重新创建数据库并用必要的初始数据填充它。我们稍后将考虑将初始数据填充到空数据库中。
#include "Database.mqh" int OnStart() { DB::Open(); // Open the database // Execute requests for table creation and filling initial data DB::Create(); DB::Close(); // Close the database return INIT_SUCCEEDED; }
将代码保存在当前文件夹的 CleanDatabase.mq5 文件中。
以前,CDatabase::Create() 表创建方法包含了一个字符串数组,其中包含重新创建一个表的 SQL 查询。现在我们有了更多的表,因此将 SQL 查询直接存储在源代码中就变得不方便了。我们将所有 SQL 请求的文本重新定位到一个单独的文件中,然后从该文件加载它们并在 Create() 方法内执行。
为此,我们需要一个方法,根据文件名称读取文件中的所有请求并执行它们:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: ... // Make a request to the database from the file static bool ExecuteFile(string p_fileName); }; ... //+------------------------------------------------------------------+ //| Making a request to the database from the file | //+------------------------------------------------------------------+ bool CDatabase::ExecuteFile(string p_fileName) { // Array for reading characters from the file uchar bytes[]; // Number of characters read long len = 0; // If the file exists in the data folder, then if(FileIsExist(p_fileName)) { // load it from there len = FileLoad(p_fileName, bytes); } else if(FileIsExist(p_fileName, FILE_COMMON)) { // otherwise, if it is in the common data folder, load it from there len = FileLoad(p_fileName, bytes, FILE_COMMON); } else { PrintFormat(__FUNCTION__" | ERROR: File %s is not exists", p_fileName); } // If the file has been loaded, then if(len > 0) { // Convert the array to a query string string query = CharArrayToString(bytes); // Return the query execution result return Execute(query); } return false; }
现在让我们对 Create() 方法进行一些修改。包含数据库结构和初始数据的文件将有一个固定的名称:数据库名称加上 .schema.sql 字符串:
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create() { string schemaFileName = s_fileName + ".schema.sql"; bool res = ExecuteFile(schemaFileName); if(res) { PrintFormat(__FUNCTION__" | Database successfully created from %s", schemaFileName); } }
现在我们可以使用任何 SQLite 数据库环境来创建其中的所有表并用初始数据填充它们。之后,我们可以将生成的数据库作为一组 SQL 查询导出到文件中,并在我们的 MQL5 程序中使用该文件。
在此阶段我们需要对 CDatabase 类进行的最后一个更改与执行请求的新需求有关,不仅包括插入数据,还包括从表中获取数据。将来,所有负责获取数据的代码都应该分布在与数据库中存储的各个实体一起工作的单独类中。但在我们完成这些类之前,我们将不得不采用临时的解决办法。
使用 MQL5 提供的工具读取数据比增加数据更为复杂。为了获取请求结果行,我们需要在 MQL5 中创建一个新的数据类型(结构),用于获取此特定请求的数据。然后我们需要发送请求并获取结果句柄。使用这个句柄,我们可以在循环中从请求结果中一次接收一个字符串,并将其放入先前创建好的相同结构的变量中。
因此,在 CDababase 类中,编写一个通用方法来读取从表中获取数据的任意请求的结果并不容易实现。因此,我们还是把它交给更高级别吧。为此,我们只需要向更高级别提供存储在 s_db 字段中的数据库连接句柄:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: static int Id(); // Database connection handle ... }; ... //+------------------------------------------------------------------+ //| Database connection handle | //+------------------------------------------------------------------+ int CDatabase::Id() { return s_db; }
将得到的代码保存在当前文件夹的 Database.mqh 文件中。
优化 EA
现在我们可以开始创建优化 EA 了。首先,我们需要与 fxsaber 的测试器一起工作的库,或者更确切地说是这个包含文件:
#include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132
我们的优化 EA 将根据计时器定期执行主要工作。因此,我们将创建一个计时器并立即在初始化函数中启动其处理函数进行执行。由于优化任务通常需要几十分钟,因此每五秒触发一次计时器似乎就足够了:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create the timer and start its handler EventSetTimer(5); OnTimer(); return(INIT_SUCCEEDED); }
在计时器处理程序中,我们将检查测试器当前是否正在使用。如果确实没有在使用,那么我们需要执行操作来完成当前任务(如果有的话)。之后,从数据库获取下一个任务的优化 ID 和输入参数,并通过调用 StartTask() 函数启动它:
//+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { PrintFormat(__FUNCTION__" | Current Task ID = %d", currentTaskId); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the tester is not in use if (MTTESTER::IsReady()) { // If the current task is not empty, if(currentTaskId) { // Complete the current task FinishTask(currentTaskId); } // Get the number of tasks in the queue totalTasks = TotalTasks(); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task currentTaskId = GetNextTask(currentSetting); // Launch the current task StartTask(currentTaskId, currentSetting); Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, currentTaskId)); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
在任务启动函数中,使用 MTTESTER 类方法将输入参数加载到测试器中,并以优化模式启动测试器。另外,更新数据库中的信息,保存当前任务的开始时间及其状态:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", taskId, setting); // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Open(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
从数据库接收下一个任务的函数也相当简单。本质上,我们在其中安排一个 SQL 查询的执行并接收其结果。请注意,此函数返回下一个任务的 ID 作为结果,并将包含优化输入的字符串写入作为引用参数传递给函数的 setting 变量:
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.from_date," " s.to_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status = 'Queued'" " ORDER BY s.id_stage, j.id_job LIMIT 1;"; // Open the database DB::Open(); if(DB::IsOpen()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; string from_date; string to_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=Articles\\2024-04-15.14741\\%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=2\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=0\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d||0||0||0||N\r\n" "%s\r\n", row.expert, row.symbol, row.period, row.from_date, row.to_date, row.optimization_criterion, row.id_task, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
为了简单起见,一些优化输入参数的值直接在代码中指定。例如,存款10,000美元,杠杆1:200,USD 币别等等将始终被使用。稍后,如果需要,也可以从数据库中获取这些参数的值。
TotalTasks() 函数代码返回队列中的任务数,与上一个函数的代码非常相似,因此我们在此不再提供。
将生成的代码保存在当前文件夹的 Optimization.mq5 文件中。现在我们需要对先前创建的文件进行一些小的修改,以获得最低限度的自给自足系统。
СVirtualStrategy 和 СimpleVolumesStrategy
在这些类中,我们将删除设置策略标准化余额值的能力,并使其初始值始终等于 10,000。现在,仅当策略包含在具有给定规范化因子的组中时,它才会改变。即使我们想运行该策略的一个实例,我们也必须将其单独添加到组中。
因此让我们在 CVirtualStrategy 类对象构造函数中设置一个新值:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualStrategy::CVirtualStrategy() : m_fittedBalance(10000), m_fixedLot(0.01), m_ordersTotal(0) {}
现在从 CSimpleVolumesStrategy 类构造函数中的初始化字符串中删除最后一个参数:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { // Save the initialization string m_params = p_params; // Read the parameters from the initialization string m_symbol = ReadString(p_params); m_timeframe = (ENUM_TIMEFRAMES) ReadLong(p_params); m_signalPeriod = (int) ReadLong(p_params); m_signalDeviation = ReadDouble(p_params); m_signaAddlDeviation = ReadDouble(p_params); m_openDistance = (int) ReadLong(p_params); m_stopLevel = ReadDouble(p_params); m_takeLevel = ReadDouble(p_params); m_ordersExpiration = (int) ReadLong(p_params); m_maxCountOfOrders = (int) ReadLong(p_params); m_fittedBalance = ReadDouble(p_params); // If there are no read errors, if(IsValid()) { ... } }
将实现的修改保存到当前文件夹中的 VirtualStrategy.mqh 和 CSimpleVolumesStrategy.mqh 文件中。
СVirtualStrategyGroup
在这个类中,我们添加了一个新方法,它使用不同的标准化因子替换值返回当前组的初始化字符串。该值仅在测试程序完成运行后才能确定,因此我们无法立即创建具有正确乘数的组。基本上,我们只需将作为参数传递的数字替换到右括号之前的初始化字符串中:
//+------------------------------------------------------------------+ //| Class of trading strategies group(s) | //+------------------------------------------------------------------+ class CVirtualStrategyGroup : public CFactorable { ... public: ... string ToStringNorm(double p_scale); }; ... //+------------------------------------------------------------------+ //| Convert an object to a string with normalization | //+------------------------------------------------------------------+ string CVirtualStrategyGroup::ToStringNorm(double p_scale) { return StringFormat("%s([%s],%f)", typename(this), ReadArrayString(m_params), p_scale); }保存对当前文件夹中的 VirtualStrategyGroup.mqh 文件所做的更改。
CTesterHandler
在用于存储优化过程结果的类中,添加 s_idTask 静态属性,我们将为其分配当前优化任务 ID。在处理传入数据帧的方法中,我们将其添加到传递给 SQL 查询的值集中,以将结果保存到数据库:
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { ... public: ... static ulong s_idTask; }; ... ulong CTesterHandler::s_idTask = 0; ... //+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Open(); ... // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { ... // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s');", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); ... }
将获得的代码保存到当前文件夹下的 TesterHandler.mqh 文件中。
СVirtualAdvisor
最后,到了最后一处修改的时候了。在 EA 类中,我们将添加在给定优化过程中在 EA 中使用的策略或一组策略的自动标准化。为此,我们从 EA 初始化字符串中重新创建所用策略的组,然后使用另一个仅根据当前传递结果计算出的标准化乘数来形成该组的初始化字符串:
//+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Re-create the group of used strategies for subsequent normalization CVirtualStrategyGroup* group = NEW(ReadObject(m_params)); // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, // Normalized profit group.ToStringNorm(coeff) // Normalized group initialization string ); delete group; return fittedProfit; }
将更改保存在当前文件夹的 VirtualAdvisor.mqh 文件中。
优化开始
一切准备就绪,可以开始优化了。在数据库中,我们总共创建了 81 个任务 (3 个交易品种 * 3 个时间框架 * 9 个标准)。首先,我们选择了仅 5 个月的短优化期间和少数可能的优化参数组合,因为我们更感兴趣的是自动测试的性能,而不是以工作策略实例输入组合的形式找到的结果本身。经过几次测试运行并纠正了小缺陷后,我们得到了我们想要的结果。passes 表填充了通过结果,其中包含具有单个策略实例的标准化组的填充初始化字符串。
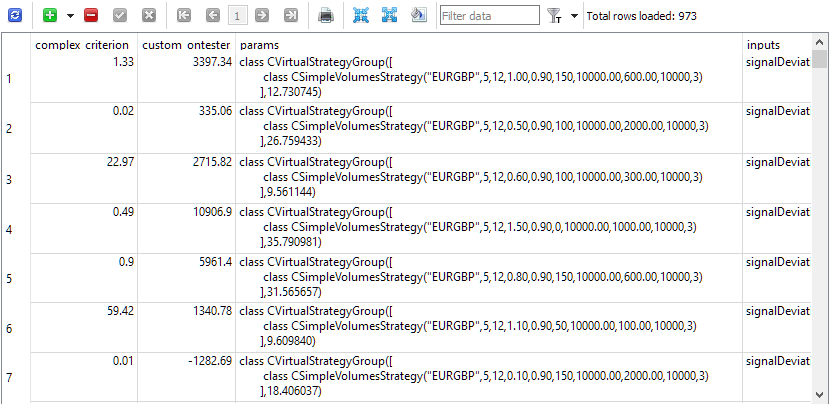
图 1.“Passes”显示通过结果
一旦该结构证明了其价值,我们就可以赋予它更复杂的任务。让我们在更长的时间间隔内使用更多的参数组合来运行相同的 81 个任务。在这种情况下,我们将不得不等待一段时间:20个代理执行一项优化任务大约需要一个小时。所以,如果我们昼夜不停地工作的话,大约需要3天时间才能完成所有任务。
之后,我们会从收到的数千个通过中手动选出最佳通过,并形成相应的 SQL 查询来选择这些通过。目前,选择仅基于夏普比率是否超过 5。接下来我们将创建一个新的 EA,它将在此阶段充当通用 EA 的角色。其主要部分是初始化函数。在此函数中,我们从数据库中提取选定最佳通过的参数,并基于它们为 EA 形成初始化字符串并创建它。
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency sinput double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input int count_ = 1000; // - Number of strategies in the group input group "::: Other parameters" sinput ulong magic_ = 27183; // - Magic input bool useOnlyNewBars_ = true; // - Work only at bar opening CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); string query = StringFormat( "SELECT DISTINCT p.custom_ontester, p.params, j.id_job " " FROM passes p JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE p.custom_ontester > 0 AND " " trades > 20 AND " " p.sharpe_ratio > 5" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC LIMIT %d;", count_); DB::Open(); int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return 0; } struct Row { double custom_ontester; string params; int id_job; } row; string strategiesParams = ""; while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
为了进行优化,我们选择了包含整整两年的间隔:2021 年和 2022 年。让我们看一下这个期间内的通用 EA 结果。为了将最大回撤与 10% 相匹配,我们将为 scale_multiplier 选择一个合适的值。通用 EA 在期间中的测试结果如下:
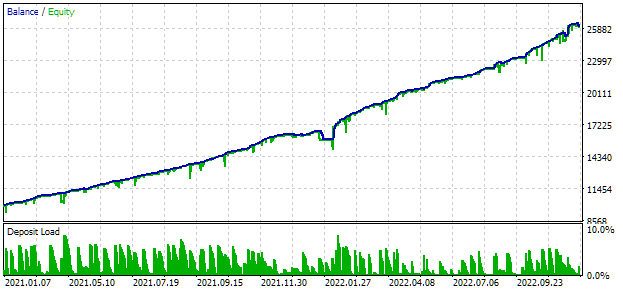
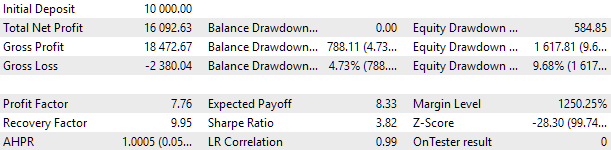
图 2.2021-2022 年通用 EA 测试结果 (scale_ = 2)
大约有一千个策略实例参与了 EA 的操作。这些结果应该被视为中间结果,因为我们还没有采取许多之前讨论过的旨在改善结果的行动。尤其是 EURUSD 策略的实例数量明显高于 EURGBP,这也是多币种优势尚未得到充分发挥的原因。因此,我们希望仍然有一定的提高潜力。我将在接下来的文章中致力于实现这一潜力。
结论
我们向着预定目标又迈出了重要一步。我们已经获得了自动优化不同交易品种、时间框架和其他参数的交易策略实例的能力。现在我们不必跟踪一个正在运行的优化过程的结束以便改变参数并运行下一个优化过程。
将所有结果保存在数据库中使我们不必担心优化 EA 可能重新启动。如果由于某种原因,优化 EA 操作被中断,那么在下次启动时它将从队列中的下一个任务开始恢复。我们还对优化过程中的所有测试通过有完整的了解。
然而,对于进一步工作仍有很大的空间。我们尚未实现更新阶段和项目状态。目前,我们只有更新任务状态。对于由多个阶段组成的项目的优化也尚未探讨。如果需要数据聚类等,如何最好地实现数据阶段的中间处理也不清楚。我将尝试在后续文章中涵盖所有这些内容。
感谢您的关注!期待很快与您见面!
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/14741
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
 在MQL5中创建交互式图形用户界面(第1部分):制作面板
在MQL5中创建交互式图形用户界面(第1部分):制作面板
是的,我自己也没想到会这么简单。起初我在学习 Validate 时,还以为要在它的基础上自己写一些东西,但后来我意识到,我可以用一个更简单的实现。
再次感谢你提供这么棒的库!
你好,尤里、
我正在尝试复制第 11 部分。 我用 CleanDatabase 创建了一个 SQL,在 User\Roaming\AppData 中创建了它......然而,当我尝试使用优化器时,我收到了错误:您或任何人能否提供一个简单的启动参考?
另外,我在终端和 MetaEditor 上使用了 /portable 开关,所有 MQL 安装都位于 C:\"Forex Program Files",这会导致任何问题吗?
在我开发MQ4和测试EA的过程中,我为我有兴趣测试的所有货币对创建了目录。我使用 JOIN 命令将每个测试目录的适当子目录重定向到我的公共目录,用于启动程序和接收报价数据,以确保所有独立测试使用相同的数据和可执行文件。 此外,每个测试为每次运行编写 CVS 文件,我使用文件函数的一个版本从每个文件目录读取 CVS 文件,并将它们合并到一个公共 CVS 文件中。 如果您对使用 CVS 文件代替 SQL 访问感兴趣,请告诉我。
在此期间,我将下载第 20 部分,并在示例中蒙混过关。
科达角