Статьи об анализе данных и статистике в MQL5
Статьи на темы математических моделей и законов вероятности заинтересуют многих трейдеров. Ведь математика положена в основу технических индикаторов, а знание статистики необходимо для анализа результатов торговли и разработки стратегий.
Читайте о нечеткой логике, цифровых фильтрах, рыночном профиле, картах Кохонена, нейронном газе и многих других инструментах, которые могут использованы для торговли.
Новая статья

Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь

MetaTrader 5 и экономический календарь MQL5: как превратить новости в воспроизводимую торговую систему
В статье системно изложен подход к новостной торговле в MetaTrader 5 на базе встроенного экономического календаря: структура данных, функции API, правила синхронизации времени и фильтрация событий. Описаны методы кэширования и инкрементального обновления без перегрузки сервера. Приведён рабочий механизм экспорта истории в ресурс .EX5 для детерминированного тестирования тем же алгоритмом.

Статистический арбитраж на основе коинтегрированных акций (Часть 10): Обнаружение структурных разрывов
В данной статье представлен тест Чоу для выявления структурных разрывов в зависимостях между парами переменных, а также применение метода кумулятивной суммы квадратов (CUSUM) для мониторинга и раннего выявления структурных разрывов. В статье объявление о партнерстве между Nvidia и Intel и заявление правительства США о введении внешнеторговых пошлин приводятся в качестве примеров, иллюстрирующих, соответственно, инверсию наклона и сдвиг пересечения. Предоставляются скрипты на Python для всех тестов.

Интеграция MQL5 с пакетами обработки данных (Часть 5): Адаптивное обучение и гибкость
В этой части основное внимание уделяется созданию гибкой, адаптивной торговой модели, обученной на исторических данных XAUUSD. Мы подготовим ее к экспорту в ONNX и потенциальной интеграции в системы реальной торговли.

Статистический арбитраж на основе коинтегрированных акций (Часть 9): Бэктестирование обновлений весов портфеля
В данной статье описывается использование файлов CSV для тестирования на исторических данных обновлений весов портфеля в стратегии, основанной на возврате к среднему значению и использующей статистический арбитраж на основе коинтегрированных акций. Это включает в себя как заполнение базы данных результатами сравнения собственных векторов в скользящих окнах (RWEC), так и сравнение отчетов по бэктесту. В то же время в статье подробно описывается роль каждого параметра RWEC и его влияние на общий результат бэктеста, а также показывается, как сравнение относительного просадки может помочь нам в дальнейшей оптимизации этих параметров.

Статистический арбитраж на основе коинтегрированных акций (Часть 8): Сравнение собственных векторов на скользящих окнах для ребалансировки портфеля
В этой статье предлагается использовать сравнение собственных векторов со скользящим окном для ранней диагностики дисбаланса и ребалансировки портфеля в рамках стратегии статистического арбитража, основанной на возврате к среднему (mean-reversion) и коинтегрированных акциях. Данный метод противопоставляется традиционной валидации с помощью ADF-теста на внутривыборочных и вневыборочных данных (IS/OOS), показывая, что сдвиги собственных векторов могут сигнализировать о необходимости ребалансировки даже в тех случаях, когда IS/OOS ADF всё ещё указывает на стационарность спреда. Хотя этот метод предназначен в первую очередь для мониторинга торговли в реальном времени, в статье делается вывод, что сравнение собственных векторов также может быть интегрировано в систему скоринга — хотя его реальный вклад в эффективность стратегии ещё предстоит проверить.

Алгоритм оптимизации грифов — Buzzard Optimization Algorithm (BUZOA)
BUZOA — популяционный метаэвристический алгоритм, в котором каждый агент на каждой итерации случайно выбирает одну из трёх тактик охоты: узкий поиск вокруг личного рекорда, классический PSO-шаг к лидеру стаи или полную телепортацию в случайную точку пространства. В статье разбирается реализация алгоритма на MQL5, показывается найденная в оригинальной формулировке ошибка знака коэффициента и приводятся результаты бенчмарка на стандартном тестовом стенде.
Разработка инструментария для анализа Price Action (Часть 35): Обучение и развертывание прогнозных моделей
Исторические данные – вовсе не "мусор", а основа любого надежного рыночного анализа. В этой статье мы шаг за шагом пройдем путь от сбора истории до ее использования для обучения прогностической модели, а затем – до развертывания этой модели для прогнозирования цен в реальном времени. Давайте разберемся, как это сделать.

Статистический арбитраж на основе коинтегрированных акций (Часть 7): Система оценки 2
В данной статье описываются два дополнительных критерия оценки, используемых при отборе корзин акций для торговли в стратегиях возврата к среднему, а точнее — в статистическом арбитраже на основе коинтеграции. Данная статья дополняет предыдущую публикацию, в которой были представлены показатели ликвидности и силы векторов коинтеграции, а также стратегические критерии — временной интервал и период ретроспективы, — за счет включения показателей стабильности векторов коинтеграции и времени возврата к среднему значению (полупериод). В статье приведены результаты бэктеста с применением новых фильтров с комментариями, а также предоставлены файлы, необходимые для его воспроизведения.

Моделирование рынка: Первые шаги на SQL в MQL5 (I)
В сегодняшней статье мы начнём изучать использование SQL в коде MQL5. Мы также рассмотрим, как можно создать базу данных. Или, точнее, как создать файл базы данных в SQLite, используя ресурсы или процедуры, включенные в язык MQL5. Мы также увидим, как создать таблицу, а затем как установить связь между таблицами с помощью первичного и внешнего ключей. Всё это, опять же, с использованием MQL5. Мы увидим, как легко создать код, который в будущем можно будет перенести в другие реализации SQL, используя класс, помогающий скрыть созданную реализацию. И, что самое важное, мы увидим, что в разные моменты мы можем столкнуться с риском того, что при использовании SQL что-то пойдет не так. Это происходит так, потому что в коде MQL5 SQL-код всегда будет помещаться внутри строки.

Популяционные алгоритмы оптимизации: строим защиту от читеров
Проведён повторный прогон алгоритмов на обновлённых функциях и предложен метод быстрой проверки их «честности». Составной тест объединяет пять разных ландшафтов и исключает выигрыш за счёт геометрии отдельных задач, позволяя быстро оценить реальную поисковую способность алгоритма. Прилагается скрипт для предварительной валидации алгоритмов перед применением к оптимизации торговых стратегий.

Как создать и оптимизировать торговую систему на основе циклов (Detrended Price Oscillator — DPO)
В этой статье объясняется, как спроектировать и оптимизировать торговую систему с использованием индикатора «Бестрендовый ценовой осциллятор» (Detrended Price Oscillator, DPO) на MQL5. В ней описывается основная логика индикатора, демонстрирующая, как он определяет краткосрочные циклы, отфильтровывая долгосрочные тенденции. С помощью серии пошаговых примеров и простых стратегий читатели узнают, как его кодировать, определять сигналы входа и выхода, а также проводить тестирование на истории. Наконец, в статье представлены практические методы оптимизации для повышения эффективности и адаптации системы к изменчивым рыночным условиям.
Разработка инструментария для анализа Price Action (Часть 32): Модуль распознавания свечных паттернов на Python (II) – Распознавание с помощью Ta-Lib
В этой статье мы перешли от ручной реализации распознавания свечных паттернов на Python к использованию TA-Lib – библиотеки, распознающей более шестидесяти различных паттернов. Эти формации дают ценную информацию о возможных разворотах рынка и продолжении тренда. Читайте дальше, чтобы узнать больше.

Использование регрессии Ренко-баров с корректировкой ошибок
В статье показан регрессионный подход к прогнозированию Ренко-баров с помощью CatBoost: модель оценивает логарифмическую доходность следующего бара и неопределённость прогноза. Разобран каскад residual-моделей с OOF-валидацией через TimeSeriesSplit, shrinkage и общим early stopping, а также условная коррекция смещения. На EURUSD D1 получено снижение OOF-MAE и около 65% точности по направлению. Приведён рабочий скрипт для MetaTrader 5, формирующий сигнал, размер позиции, SL и TP в единицах кирпича.

Статистический арбитраж на основе коинтегрированных акций (Часть 6): Система оценки
В данной статье мы предлагаем систему оценки стратегий возврата к среднему значению, основанную на статистическом арбитраже коинтегрированных акций. В статье предлагаются критерии, которые варьируются от ликвидности и транзакционных издержек до количества рангов коинтеграции и времени возврата к среднему значению, при этом учитываются стратегические критерии — частота данных (временной интервал) и период обратного обзора для тестов на коинтеграцию, которые оцениваются до того, как будет сформирован итоговый оценочный балл (rank_score). Предоставляются файлы, необходимые для воспроизведения бэктеста, а также приводятся комментарии к его результатам.

Моделирование рынка (Часть 23): Первые шаги на SQL (VI)
В этой статье мы рассмотрим, как выполнить визуализацию и, следовательно, поймем, как структурирована база данных. Это было сделано с помощью анализа внутренней структуры базы данных. Хотя подобные вещи могут показаться излишними, они вполне оправданы, если мы действительно намерены стать администраторами баз данных. Да, есть люди, которые зарабатывают на жизнь, поддерживая и создавая базы данных.

Создание прибыльной торговой системы (Часть 2): Тонкости управления размером позиции
Даже при использовании системы с положительными ожиданиями, на успех или неудачу может повлиять размер позиции. Это ключевой аспект управления рисками — преобразование статистических преимуществ в реальные результаты при одновременной защите вашего капитала.

Статистический арбитраж на основе коинтегрированных акций (Часть 5): Отбор активов
В данной статье предлагается процесс отбора активов для стратегии торговли на основе статистического арбитража с использованием коинтегрированных акций. Система начинается с обычной фильтрации по экономическим факторам, таким как сектор активов и отрасль, и заканчивается составлением перечня критериев для системы оценки. Для каждого статистического теста, использованного в скрининге, был разработан соответствующий класс на языке Python: Коэффициент корреляции Пирсона, коинтеграция Энгл-Грейнджера, коинтеграция Йохансена и стационарность по ADF/KPSS. Эти классы Python сопровождаются личным комментарием автора об использовании ИИ-помощников в разработке программного обеспечения.

Алготрейдинг без рутины: быстрый анализ сделок в MetaTrader 5 с SQLite
В статье представлен минимальный рабочий набор для ведения торгового журнала в MQL5 на SQLite: схема таблиц сделок, сигналов и событий, индексы, подготовленные запросы и транзакции, а также типовые аналитические SQL-запросы. Показана интеграция с панелью статистики в MetaTrader 5 и работа с базой через MetaEditor. Подход позволяет автоматизировать журнал, ускорить расчеты и проводить анализ без усложнения кода эксперта.

Моделирование рынка (Часть 24): Первые шаги на SQL (VII)
В предыдущей статье мы завершили необходимое введение в тему SQL. И то, что мы хотели показать и объяснить о SQL, на мой взгляд, мы разъяснили должным образом. Так было сделано для того, чтобы каждый, кто придет посмотреть на строящуюся систему репликации/моделирования, мог хотя бы получить представление о том, что там может происходить. Дело в том, что нет смысла программировать вещи, с которыми SQL справляется идеально.

Разработка инструментария для анализа Price Action (Часть 31): Модуль распознавания свечных паттернов на Python (I) – ручное распознавание
Свечные паттерны лежат в основе торговли Price Action и дают ценные сигналы о возможном развороте рынка или продолжении тренда. Представьте надежный инструмент, который постоянно отслеживает каждый новый бар, выявляет ключевые формации, такие как паттерны поглощения, молоты, доджи и звезды, и сразу уведомляет вас, когда обнаруживает значимый торговый сетап. Именно такой функционал мы и разработали. Независимо от того, новичок вы или опытный трейдер, эта система выдает оповещения в реальном времени о свечных паттернах, позволяя открывать сделки увереннее и эффективнее. Читайте дальше, чтобы узнать, как это работает и как может улучшить вашу торговую стратегию.

Как организовать ИИ-хедж-фонд в MetaTrader 5
В статье разобрана архитектура совета из 15 ИИ-агентов: десять аналитиков и четыре риск-офицера голосуют в трёх параллельных фазах, итог фиксирует Председатель. Для восьми валютных пар используются изолированные контексты с отдельными репутациями. Динамический порог голосов зависит от дневных целей PnL. Expert Advisor работает только по сигналу SL и TP, что позволяет оценить качество решений без дополнительной механики.

Неопределённость как модель (Часть 5): Основы регрессии
Практическое введение в регрессионные модели временных рядов: регрессия на константу и парная регрессия при детерминированном, экзогенном и эндогенном регрессорах. Описаны ключевые шаги диагностики, включая анализ остатков и проверку гипотез, необходимые для обоснованных торговых решений. Приложены MQL5‑скрипты для MetaTrader 5, реализующие тесты и графики на реальных данных.

Тестовые чемпионы против реальных задач оптимизации
Мы анализируем, почему рейтинги могут быть завышены из‑за совпадения траекторий алгоритмов с диагоналями бенчмарков, и дополняем методику тестирования требованием удалять глобальный экстремум от диагоналей. Обновляем Forest и Megacity, проводим RAW‑верификацию и калибровку через VerifyExtremes.mq5. Падение результатов HHO и DOAm служит практическим индикатором ложных лидеров.

Статистический арбитраж с использованием коинтегрированных акций (Часть 4): Обновление параметров модели в реальном времени
В данной статье описывается простой, но комплексный алгоритм статистического арбитража для торговли корзиной коинтегрированных акций. В него входит полнофункциональный скрипт на языке Python для загрузки и хранения данных; тесты на корреляцию, коинтеграцию и стационарность, а также пример реализации сервиса Metatrader 5 для обновления базы данных и соответствующий советник. Здесь приведены некоторые проектные решения для справки и в целях содействия воспроизведению эксперимента.

Торговые инструменты MQL5 (Часть 21): Добавление темы в стиле киберпанк в графики регрессии
В этой статье мы улучшаем инструмент построения графиков регрессии в MQL5, добавляя режим темы киберпанка с неоновым свечением, анимацией и голографическими рамками для иммерсивной визуализации. Мы интегрируем переключение тем, динамические фоны со звездами, светящимися контурами и неоновыми точками / линиями, сохраняя при этом совместимость со стандартным режимом. Эта двухтематическая система придает парному анализу футуристическую эстетику, поддерживая обновления и взаимодействия в режиме реального времени для получения полезных торговых выводов.

Разработка инструментария для анализа Price Action (Часть 30): Советник CCI Zero Line
Будущее – за автоматизацией анализа движения цен. В этой статье мы используем индикатор Dual CCI (Commodity Channel Index – индекс товарного канала), стратегию пересечения нулевой линии (Zero Line Crossover), EMA и анализ движения цены, чтобы разработать инструмент, который генерирует торговые сигналы и задает уровни стоп-лосса и тейк-профита с помощью ATR. Прочитайте эту статью, чтобы узнать наш подход к разработке советника CCI Zero Line.

Разработка инструментария для анализа Price Action (Часть 29): Советник "Boom and Crash Interceptor"
Узнайте, как советник Boom & Crash Interceptor превращает ваши графики в проактивную систему оповещений, выявляющую взрывные движения с помощью быстрого анализа скорости, проверки всплесков волатильности, подтверждения тренда и фильтров пивот-зон. Четкие зеленые стрелки "Boom" и красные "Crash" помогают быстрее принимать решения: этот инструмент отсекает рыночный шум и позволяет эффективнее использовать ценовые всплески. Давайте разберем, как это работает и почему этот инструмент может стать вашим следующим важным преимуществом в торговле.

Python + MetaTrader 5: быстрый исследовательский контур для данных, признаков и прототипов
Статья показывает, как интеграция Python и MetaTrader 5 объединяет исследовательскую гибкость и торговое исполнение в едином рабочем процессе. Python используется для анализа данных, отбора признаков и обучения модели, а MetaTrader 5 — для тестирования и автоматизации торговли. Такой подход упрощает перенос решений в практику, повышает воспроизводимость и делает разработку торговых систем более быстрой и структурированной.

Статистический арбитраж на коинтегрированных акциях (Часть 3): Настройка базы данных
В данной статье представлен пример реализации сервиса на MQL5 для обновления вновь созданной базы данных, используемой в качестве источника для анализа данных и для торговли корзиной коинтегрированных акций. Подробно объясняется логика проектирования базы данных, а также приводится описание структуры данных (data dictionary) для справки. Предоставлены скрипты на MQL5 и Python для создания базы данных, инициализации её схемы и загрузки рыночных данных.

Торговые инструменты на MQL5 (Часть 20): Построение графиков на Canvas с использованием статистической корреляции и регрессионного анализа
В этой статье мы создаем графический инструмент на основе Canvas в MQL5 для статистического корреляционного и линейного регрессионного анализа между двумя символами с возможностью перетаскивания и изменения размера. Мы включили ALGLIB для регрессионных расчетов, динамические метки тиков, точки данных и панель статистики, отображающую наклон, пересечение, корреляцию и R-квадрат. Эта интерактивная визуализация помогает лучше понять суть парной торговли, поддерживая настраиваемые темы, границы и обновление новых баров в режиме реального времени

Разработка инструментария для анализа Price Action (Часть 27): Инструмент выявления снятия ликвидности с MA-фильтром
Понимание тонких механизмов, стоящих за движением цены, может дать вам серьезное преимущество. Одно из таких явлений – снятие ликвидности, то есть целенаправленный прием, который крупные трейдеры, особенно институциональные участники, используют, чтобы провести цену через ключевые уровни поддержки или сопротивления. Эти уровни часто совпадают со скоплениями стоп-лоссов розничных трейдеров, создавая зоны ликвидности, которые крупные игроки могут использовать для входа в крупные позиции или выхода из них с минимальным проскальзыванием.

Внедрение в MQL5 практических модулей из других языков (Часть 06): Операции файлового ввода-вывода в MQL5, как в Python
В этой статье показано, как упростить сложные операции MQL5 с файлами, создав интерфейс в стиле Python для удобного чтения и записи. В ней объясняется, как воссоздать интуитивно понятные шаблоны работы с файлами в Python с помощью пользовательских функций и классов. В результате получился более ясный и надежный подход к файловому вводу-выводу в языке MQL5.

Самооптимизирующиеся советники на MQL5 (Часть 12): Построение линейных классификаторов с использованием факторизации матриц
В данной статье рассматривается важная роль факторизации матриц в алгоритмической торговле, в частности в приложениях MQL5. От регрессионных моделей до многоклассовых классификаторов — мы рассмотрим практические примеры, демонстрирующие, насколько легко эти методы можно интегрировать с помощью встроенных функций MQL5. Независимо от того, занимаетесь ли вы прогнозированием направления движения цен или моделированием поведения индикаторов, данное руководство заложит прочную основу для создания интеллектуальных торговых систем с использованием матричных методов.

Создание самооптимизирующихся советников на MQL5 (Часть 11): Введение в основы линейной алгебры
В ходе этого обсуждения мы заложим основу для использования мощных инструментов линейной алгебры, реализованных в API матриц и векторов MQL5. Чтобы умело использовать этот API, нам необходимо хорошо понимать принципы линейной алгебры, лежащие в основе эффективного применения этих методов. Цель этой статьи — дать читателю интуитивное представление о некоторых из наиболее важных правил линейной алгебры, которые нам, как алгоритмическим трейдерам в MQL5, необходимы для начала работы с этой мощной библиотекой.

Статистический арбитраж на коинтегрированных акциях (Часть 2): Советник, тестирование и оптимизация
В данной статье представлен пример реализации советника для торговли корзиной из четырёх акций компаний, котирующихся на Nasdaq. Сначала акции были отфильтрованы на основе тестов на корреляцию Пирсона. Затем для отфильтрованной группы была проведена проверка на коинтеграцию с помощью тестов Йохансена. Наконец, стационарность коинтегрированного спреда проверялась с помощью тестов ADF и KPSS. Здесь мы рассмотрим некоторые замечания по поводу этого процесса, а также результаты бэктестов после небольшой оптимизации.
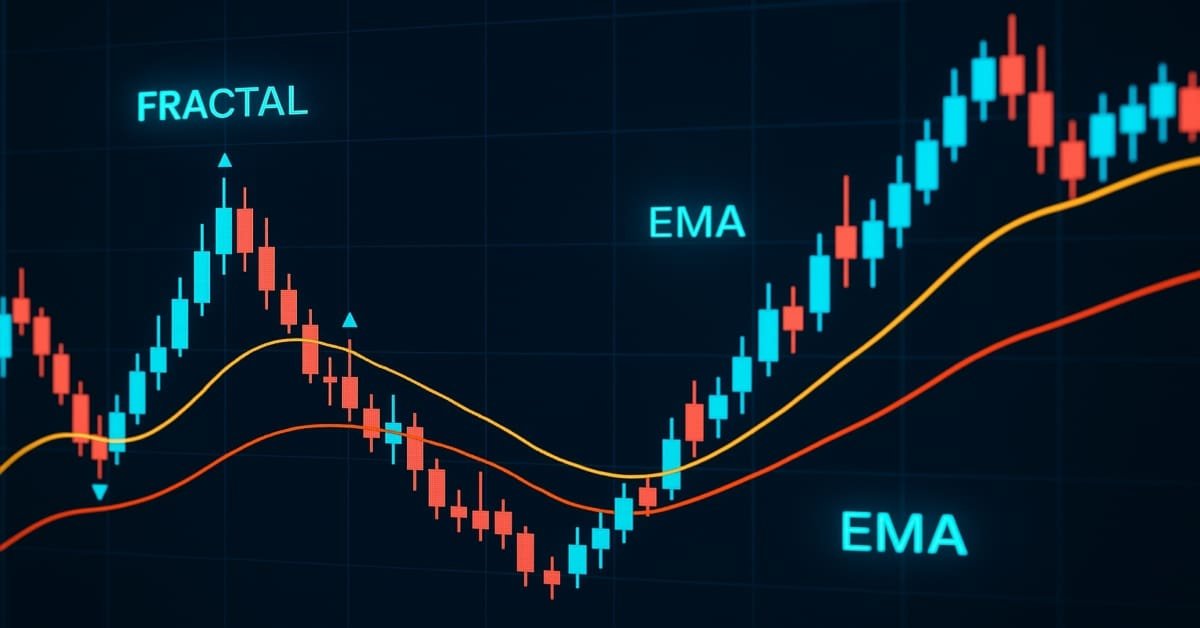
Разработка инструментария для анализа Price Action (Часть 25): Пробой фракталов по двум EMA
Анализ Price Action – это фундаментальный подход к выявлению прибыльных сетапов. Однако вручную отслеживать движение цены и паттерны бывает сложно и долго. Для решения этой задачи мы разрабатываем инструменты, которые автоматически анализируют Price Action и подают своевременные сигналы при обнаружении потенциальных возможностей. В этой статье представлен надежный инструмент, который использует пробои фракталов в сочетании с EMA 14 и EMA 200 для генерации надежных торговых сигналов, помогая трейдерам принимать более обоснованные решения.

Внедрение в MQL5 практических модулей из других языков (Часть 05): Модуль Logging из Python — ведите логи профессионально
Интеграция модуля Logging языка Python с языком MQL5 предоставляет трейдерам систематический подход к ведению логов, упрощая процесс мониторинга, отладки и документирования торговой деятельности. В этой статье описывается процесс адаптации, предлагая трейдерам мощный инструмент для поддержания четкости и организованности в процессе разработки программного обеспечения для трейдинга.

Нелинейные признаки OHLC из эллиптических кривых
В статье рассматривается проекция дневных свечей EURUSD на эллиптическую кривую secp256k1 и извлечение 96 признаков (EC+TA) для прогноза направления следующей свечи в CatBoost. Показаны маппинг цен на кривую и конвейер обучения на 2000 барах D1; полная модель достигает AUC на тесте 0,6508, вклад EC-признаков — 60,6%. Материалы пригодны для воспроизведения в Python/MetaTrader 5.

Гипотеза случайности: поиск скрытых паттернов в ценовых рядах
В статье описан тест гипотезы случайности для котировок на основе статистики хи-квадрат, построенной по частотам перекрывающихся s-цепочек. Показано, как формировать дискретные состояния и сравнивать наблюдаемые и ожидаемые частоты, чтобы обнаруживать марковскую память в приращениях цены. Подход помогает отделить структурные зависимости от шума и формализовать проверку торговых гипотез.

Торговые инструменты на MQL5 (Часть 16): Улучшенное сглаживание методом суперсэмплинга (SSAA) и рендеринг в высоком разрешении
Мы добавляем сглаживание на основе суперсэмплинга и рендеринг высокого разрешения на панель Canvas на MQL5, а затем понижаем дискретизацию до целевого размера. В статье реализованы закругленные прямоугольные заливки и границы, закругленные треугольные стрелки и пользовательская полоса прокрутки с темой оформления для статистических и текстовых панелей. Эти инструменты помогут вам создать более плавные и разборчивые компоненты пользовательского интерфейса в MetaTrader 5.