
От новичка до эксперта: Создание анимированного советника для новостей в MQL5 (IV) - Анализ рынка локально размещенными моделями с использованием ИИ

Содержание:
- Введение
- Общие сведения
- Настройка и локальное размещение модели искусственного интеллекта
- Интеграция инструмента «Анализ искусственного интеллекта» в MQL5: Усовершенствование советника «Заголовки новостей»
- Тестирование и интеграция
- Заключение
- Основные уроки
- Содержимое вложения
Введение
В настоящем обсуждении мы рассмотрим, как использовать модели искусственного интеллекта с открытым исходным кодом для улучшения наших инструментов алгоритмической торговли, в частности, как дополнить советник «Заголовки новостей» разделом «Анализ искусственного интеллекта». Цель состоит в том, чтобы помочь новичкам найти надежную начальную точку. Кто знает? Сегодня вы можете интегрировать модель, а завтра, возможно, будете ее создавать. Но все начинается с понимания основ, заложенных теми, кто был до нас.
Мы не можем говорить о современных достижениях, не упоминая искусственный интеллект и его быстро растущее влияние на решение задач, стоящих перед человеком. Когда речь заходит об алгоритмической торговле, дискуссия становится еще более актуальной — торговля уже основана на цифрах и автоматизации, что делает искусственный интеллект естественным решением по сравнению с другими областями, которые все еще требуют отказа от ручных процессов.
Хотя модели искусственного интеллекта стали мощными инструментами в различных областях, не у всех есть ресурсы или опыт для создания собственных моделей из-за сложности разработки полнофункциональных систем. К счастью, рост числа инициатив с открытым исходным кодом позволил получить бесплатный доступ к предварительно подготовленным моделям и воспользоваться ими бесплатно. Эти предпринимаемые сообществом усилия являются практической отправной точкой для многих разработчиков и энтузиастов.
В то же время, модели премиум-класса часто обладают более широкими возможностями благодаря вложенному в них огромному труду. Тем не менее, модели с открытым исходным кодом являются ценной начальной точкой, особенно для тех, кто хочет интегрировать искусственный интеллект, не изобретая велосипед заново.
В предыдущем обсуждении мы сосредоточились на разделе «Аналитика индикаторов». Сегодня мы рассмотрим, как использовать искусственный интеллект с открытым исходным кодом для алгоритмической торговли, самостоятельно разместив квантованную языковую модель и интегрировав ее непосредственно в советник MQL5. В следующем разделе мы начнем с краткого ознакомления с ролями llama.cpp (облегченный механизм логического вывода) и 4‑разрядной модели в формате GGUF (сжатый “мозг”), затем рассмотрим загрузку и подготовку модели, настроив локальный сервер логического вывода на базе Python с помощью FastAPI и, наконец, подключив его к советнику «Заголовки новостей» для создания динамичного раздела «Анализ искусственного интеллекта».
Попутно расскажем о ключевых решениях, устранении распространенных препятствий и продемонстрируем простой дымовой тест — все это разработано для того, чтобы предоставить вам четкую, комплексную модель добавления комментариев искусственного интеллекта в реальном времени в ваш торговый процесс.
Общие сведения
Для этого проекта мы используем 64‑разрядный процессор Intel Core i7‑8550U (1,80–1,99 ГГц) с ОЗУ 8 ГБ. Учитывая эти аппаратные ограничения, нами выбрана облегченная 4‑разрядную модель GGUF, в частности, stablelm‑zephyr‑3b.Q5_K_M.gguf, чтобы обеспечить эффективную загрузку и производительность логического вывода в нашей системе. Позже я поделюсь рекомендуемыми техническими характеристиками оборудования, подходящими для проектов такого рода, а также планами обновления для поддержки более крупных и требовательных моделей искусственного интеллекта в будущем.
Прежде чем продолжим, важно ознакомиться с ключевыми компонентами и требованиями к оборудованию, необходимыми для бесперебойной работы этого проекта. В образовательных целях мы работаем со скромными техническими характеристиками, но если у вас есть доступ к более мощному оборудованию, рекомендуем вам воспользоваться им. Я также дам рекомендации по подходящим моделям и рекомендуемым техническим характеристикам для более производительных установок.
Освоение платформы Hugging Face
Hugging Face это платформа, на которой размещены тысячи предварительно подготовленных моделей машинного обучения (NLP, vision, speech и т.д.), а также наборы данных, показатели оценки и инструменты разработчика, доступные через Интернет или библиотеку huggingface_hub на Python. Это упрощает обнаружение моделей, управление версиями и управление большими файлами (Git LFS), а также предлагает как бесплатные варианты самостоятельного размещения, так и API управляемого логического вывода для масштабируемых развертываний. Благодаря полной документации, поддержке сообщества и плавной интеграции с такими фреймворками, как PyTorch и TensorFlow, Hugging Face позволяет любому пользователю быстро находить, загружать и запускать передовые модели искусственного интеллекта в своих приложениях.
Требования к оборудованию
Для 4‑разрядной модели GGUF с 3 параметрами B, работающей на llama‑cpp‑python, вам потребуется как минимум:
- ЦП: 4‑ядерный/8‑поточный процессор (например, Intel i5/i7 или AMD Ryzen 5/7) для вывода каждого токена за долю секунды.
- ОЗУ: ~6-8 ГБ свободно для загрузки квантованной модели объемом ~ 1,9 ГБ, плюс рабочая память.
- Хранилище: SSD-накопитель со свободным объемом памяти ≥3 ГБ для кэш-памяти модели (~1,9 ГБ) и экономии ресурсов операционной системы.
- Сеть: Вызовы с локального хостинга — внешняя пропускная способность не требуется.
Обновление спецификаций
- Более крупные модели: Переходите к моделям с 7 параметрами B или 13 параметрами B (квантованными), но планируйте использовать более 12 ГБ памяти и более мощные ЦПУ или графические процессоры.
- Ускорение графического процессора: Используйте графические процессоры NVIDIA с CUDA/cuBLAS и серверной частью llama‑cpp GPU или фреймворки, такие как Triton/ONNX, для ускорения в 10 раз.
- Горизонтальное масштабирование: Контейнеризация (Docker) или развертывание в кластерах Kubernetes для балансировки нагрузки на несколько модулей вывода ‑ отлично подходит для высокопроизводительных или многопользовательских установок.
- Облачное хранилище для графических/тензорных процессоров: Перейдите к экземплярам AWS/GCP/Azure (например, A10G, A100) для моделей с параметрами >13 B или SLA в реальном времени.
Требования к программному обеспечению:
В нашем рабочем процессе используется несколько взаимодополняющих оболочек и сред для оптимизации разработки и тестирования:
- Git Bash ‑ это наш инструмент для кода fetch и контроля версий ‑ используйте его для git—клонирования репозитория Hugging Face, запуска python download_model.py (как только ваш Python будет на PATH) и даже для запуска быстрых дымовых тестов, если вы предпочитаете синтаксис Bash. Мы можем использовать командную строку Windows или другие оболочки для этого же процесса.
- MSYS2 предоставляет нам полноценный уровень POSIX в Windows — как только модель будет готова, мы сможем остаться в MSYS2, чтобы запустить curl (или httpie) против http://localhost:8000/insights чтобы убедиться, что наша конечная точка FastAPI активна и возвращает JSON.
- В Anaconda Prompt мы создаем и активируем нашу среду Conda для ai‑сервера (python=3.12), устанавливаем пакеты llama‑cpp‑python, FastAPI и Uvicorn и, наконец, запускаем uvicorn server:app --reload --port 8000.
Ниже приведена блок-схема, служащая основой для процессов, которые мы рассмотрим в этом обсуждении.
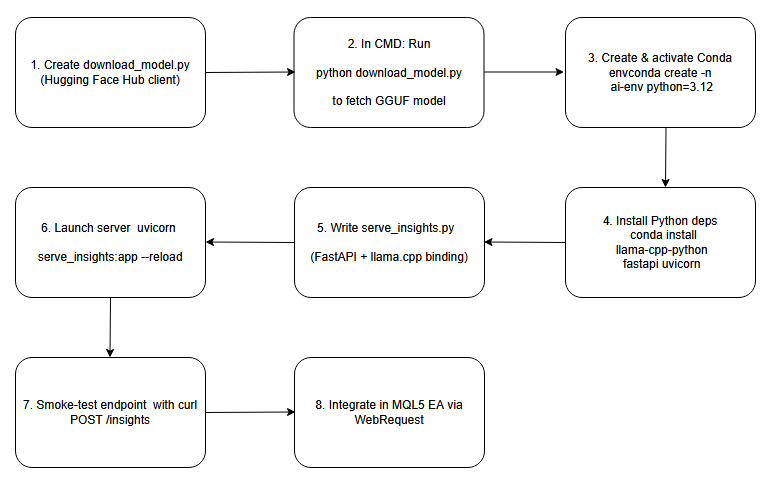
Схема последовательности операций.
Настройка и локальное размещение модели искусственного интеллекта
Шаг 1: Создаём скрипт загрузки
Для начала напишем небольшой скрипт на Python, в котором используется клиент Hugging Face Hub. В этом скрипте мы указываем имя хранилища (например, "TheBloke/stablelm‑zephyr‑3b.Q5_K_M.gguf") и вызываем hf_hub_download(), чтобы загрузить квантованный файл GGUF в наш локальный кэш. Затем, выведя возвращенный путь к файлу, мы получаем надежную, машиночитаемую ссылку на то, где сейчас находится модель на диске. Такой подход автоматизирует загрузку и гарантирует, что вы знаете точное местоположение кэша, что критически важно для настройки последующего кода логического вывода без жесткого кодирования непредсказуемых каталогов.
# download_model.py from huggingface_hub import hf_hub_download # Download the public 4-bit GGUF model; no Hugging Face account required model_path = hf_hub_download( repo_id = "TheBloke/stablelm-zephyr-3b-GGUF", filename = "stablelm-zephyr-3b.Q5_K_M.gguf", repo_type = "model" ) print("Downloaded to:", model_path)
Шаг 2: Запускаем скрипт загрузки
Затем откроем обычную командную строку Windows и перейдем в каталог, содержащий ваш скрипт загрузки (например, download_model.py). Когда исполнится python download_model.py, клиент Hugging Face подключится по протоколу HTTPS, загрузит значения GGUF в свой кэш и выведет полный путь (что-то вроде C:\Users\You\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b.Q5_K_M\…\stablelm-zephyr-3b.Q5_K_M.gguf). Просмотр этого пути подтверждает, что файл готов, и позволяет вам скопировать его непосредственно в вашу конфигурацию логического вывода.
Cmd в Windows:
python download_model.py
Путь к загруженной модели:
Адрес загрузки: C:\Users\BTA24\.cache\huggingface\hub\…\stablelm-zephyr-3b.Q5_K_M.gguf
Шаг 3: Создание и активация среды Conda
conda create -n ai-env python=3.12 -y conda activate ai-env
Шаг 4: Установим зависимости Python
При включенной среде ai-сервера используйте pip install llama-cpp-python fastapi uvicorn (или "conda install -c conda-forge llama-cpp-python", если предпочтительнее) для загрузки основных библиотек. Привязка llama-cpp-python обеспечивает высокопроизводительный механизм логического вывода C++, необходимый для загрузки и запуска вашей модели GGUF, в то время как FastAPI и Uvicorn предоставляют асинхронную веб‑платформу и сервер (соответственно) для предоставления конечных точек с целью получения аналитических данных. Вместе эти пакеты составляют основу вашей локальной службы логического вывода с использованием искусственного интеллекта.
conda install -c conda-forge llama-cpp-python fastapi uvicorn -y
Шаг 5: Пишем серверный скрипт FastAPI
В папке вашего проекта создайте новый файл (например, server.py) и импортируйте FastAPI и Llama из llama_cpp. В глобальной области создайте экземпляр класса Llama, указав путь к загруженному вами файлу GGUF. Затем определите конечную точку POST в /insights, которая принимает текст в формате JSON (содержащий строку "prompt"), вызывает llm.create() или эквивалент для генерации текста и возвращает ответ в формате JSON, содержащий поле "insight". Всего за несколько строк у вас теперь есть сервис RESTful AI, готовый получать подсказки и передавать результаты моделирования в потоковом режиме.
# serve_insights.py from fastapi import FastAPI, Request from llama_cpp import Llama MODEL_PATH = r"C:\Users\BTA24\.cache\huggingface\hub\models--TheBloke--stablelm-zephyr-3b-GGUF\snapshots\<snapshot-id>\stablelm-zephyr-3b.Q5_K_M.gguf" llm = Llama(model_path=MODEL_PATH, n_threads=4, n_ctx=512) app = FastAPI() @app.post("/insights") async def insights(req: Request): data = await req.json() prompt = data.get("prompt", "") out = llm(prompt, max_tokens=64) text = out["choices"][0]["text"].strip() return {"insight": text}
Шаг 6: Запуск сервера логического вывода
Все еще находясь в Anaconda Prompt, перейдите в каталог вашего проекта и запустите Uvicorn, указав на приложение FastAPI. Включите автоматическую перезагрузку, чтобы мгновенно отслеживать изменения в скрипте и прослушивать входящие запросы через порт 8000.
cd into the folder where server.py lives and run:
cd "C:\Users\YOUR_COMPUTER_NAME\PATH_TO_YOUR python serve insights file"
После входа запустим сервер:
uvicorn serve_insights:app --host 0.0.0.0 --port 8000 --reload
Шаг 7: Дымовой тест конечной точки
С любого терминала отправьте простой POST-запрос на адрес http://localhost:8000/insights с тестовым запросом в формате JSON. Убедитесь, что сервер отправляет в ответ действительный JSON-файл, содержащий поле "insight".
curl -X POST http://localhost:8000/insights \ -H "Content-Type: application/json" \ -d '{"prompt":"One-sentence FX signal for EUR/USD."}'
Успешный ответ будет выглядеть следующим образом:
{"insight":"Be mindful of daily open volatility…"}
Шаг 8: Интеграция в Ваш советник на MQL5
Теперь, когда сервер искусственного интеллекта запущен и проверен, пришло время вернуться к нашему советнику на MQL5 и продолжить с того места, на котором мы остановились. Интегрируем конечную точку AI‑Insights в наш советник, добавив на график специальную полосу “AI Insights” (т.е. «Анализ искусственного интеллекта»). После интеграции ваш советник будет вызывать локальную конечную точку /insights с заданным интервалом, анализировать возвращенный JSON‑файл и вводить полученный текст в тот же механизм плавной прокрутки, который вы уже используете для новостей и индикаторов. В следующем разделе шаг за шагом рассмотрим полную интеграцию кода, чтобы создать полноценный торговый инструмент, улучшенный с помощью искусственного интеллекта.
Интеграция инструмента «Анализ искусственного интеллекта» в MQL5: Усовершенствование советника «Заголовки новостей»
Предполагая, что вы ознакомились с нашей предыдущей статьей, теперь сосредоточимся только на интеграции новой функции «Анализ искусственного интеллекта» в советник. На следующих этапах я выделю и объясню каждое требуемое добавление кода, оставив остальную часть советника нетронутой, а затем предоставлю полный обновленный код советника в конце нашего обсуждения.
1. Расширение наших входных параметров.
Сначала добавляем три новых входных параметра наряду с существующими. Включаем логическое значение, чтобы по желанию включать или выключать полосу «Анализ искусственного интеллекта», строку, в которую вводим URL-адрес нашей конечной точки FastAPI (или другой ИИ), и целое число, задающее, сколько секунд должно пройти между последовательными вызовами POST. С их помощью мы можем экспериментировать в интерактивном режиме — переключать полосу движения, указывать на разные серверы или увеличивать или уменьшать скорость, не затрагивая основной код.
//--- 1) USER INPUTS ------------------------------------------------ input bool ShowAIInsights = true; input string InpAIInsightsURL = "http://127.0.0.1:8000/insights"; input int InpAIInsightsReloadSec = 60; // seconds between requests
2. Объявление общих глобальных переменных
Далее вводим глобальные переменные для хранения наших данных искусственного интеллекта и управления ими. Мы сохраняем текущий текст insight в виде одной строки и отслеживаем его смещение по горизонтали в виде целого числа, чтобы прокручивать его каждый тик. Чтобы избежать дублирования запросов, добавляем флаг, отмечающий время выполнения веб-запроса, и сохраняем временную метку нашей последней успешной выборки. Эти глобальные переменные гарантируют, что нам всегда будет что рисовать, мы точно знаем, когда отправлять следующий вызов, и предотвращаем скачки HTTP-вызовов.
//--- 3) GLOBALS ----------------------------------------------------- string latestAIInsight = "AI insights coming soon…"; int offAI; // scroll offset bool aiRequestInProgress = false; // prevent concurrent POSTs datetime lastAIInsightTime = 0; // last successful fetch time
3. Разработка FetchAIInsights()
Мы инкапсулируем всю нашу логику HTTP в единую функцию. Внутри сначала проверяем наш переключатель и время восстановления: если полоса искусственного интеллекта отключена, или если мы сделали выборку слишком недавно (или предыдущий запрос все еще не завершён), мы просто возвращаемся. В противном случае создаем минимальную полезную нагрузку в формате JSON — возможно, включая текущий символ — и запускаем WebRequest("POST"). В случае успешного исполнения извлекаем поле "insight" из ответа JSON и обновляем наш глобальный текст и временную метку. Если что-то пойдет не так, мы оставим предыдущую информацию без изменений так, чтобы наша полоса прокрутки никогда не была пустой.
void FetchAIInsights() { if(!ShowAIInsights || aiRequestInProgress) return; datetime now = TimeTradeServer(); if(now < lastAIInsightTime + InpAIInsightsReloadSec) return; aiRequestInProgress = true; string hdrs = "Content-Type: application/json\r\n"; string body = "{\"prompt\":\"Concise trading insight for " + Symbol() + "\"}"; uchar req[], resp[]; string hdr; StringToCharArray(body, req); int res = WebRequest("POST", InpAIInsightsURL, hdrs, 5000, req, resp, hdr); if(res > 0) { string js = CharArrayToString(resp,0,WHOLE_ARRAY); int p = StringFind(js, "\"insight\":"); if(p >= 0) { int start = StringFind(js, "\"", p+10) + 1; int end = StringFind(js, "\"", start); if(start>0 && end>start) latestAIInsight = StringSubstr(js, start, end-start); } lastAIInsightTime = now; } aiRequestInProgress = false; }
4. Заполнение холста в OnInit()
В нашей процедуре инициализации, после настройки всех остальных холстов, мы также создаем холст ИИ. Мы придаем ему те же размеры и полупрозрачный фон, а затем размещаем его чуть ниже существующих полос. Перед возвратом каких-либо данных, рисуем понятный заполнитель (“Скоро появятся результаты анализа с помощью искусственного интеллекта...”), чтобы диаграмма выглядела безупречно. Наконец, немедленно единоразово вызываем функцию FetchAIInsights(). Это гарантирует, что даже если мы запустим ее в середине сеанса, реальный контент появится сразу после завершения первого сетевого вызова.
int OnInit() { // … existing init … // AI Insights lane if(ShowAIInsights) { aiCanvas.CreateBitmapLabel("AiC", 0, 0, canvW, lineH, COLOR_FORMAT_ARGB_RAW); aiCanvas.TransparentLevelSet(120); offAI = canvW; SetCanvas("AiC", InpPositionTop, InpTopOffset + (InpSeparateLanes ? 8 : 5) * lineH); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); aiCanvas.Update(true); // initial fetch FetchAIInsights(); } EventSetMillisecondTimer(InpTimerMs); return INIT_SUCCEEDED; }
5. Обновление и прокрутка в OnTimer()
С каждым тиком таймера мы уже перерисовываем события, новости и индикаторы. Сразу после этого мы выполняем наши действия с использованием искусственного интеллекта: вызываем функцию FetchAIInsights() (которая автоматически отключается, если время восстановления не прошло), стираем холст ИИ, рисуем последнюю информацию с текущим смещением, уменьшаем это смещение для плавной прокрутки влево, оборачиваем ее, когда она покидает экран, и, наконец, вызываем Update(true), чтобы немедленно очистить её. В результате получается красиво прокручивающееся сообщение с использованием ИИ, которое обновляется только тогда, когда мы ему разрешаем, сочетая плавную анимацию с контролируемым использованием сети.
void OnTimer() { // … existing redraw for events/news/indicators … // fetch & draw AI lane FetchAIInsights(); if(ShowAIInsights) { aiCanvas.Erase(ARGB(120,0,0,0)); aiCanvas.TextOut(offAI, (lineH - aiCanvas.TextHeight(latestAIInsight)) / 2, latestAIInsight, XRGB(180,220,255), ALIGN_LEFT); offAI -= InpAIInsightsSpeed; if(offAI + aiCanvas.TextWidth(latestAIInsight) < -20) offAI = canvW; aiCanvas.Update(true); } }
6. Очистка в OnDeinit()
Когда наш советник загружается, мы все приводим в порядок. Мы отключаем таймер, уничтожаем и удаляем холст ИИ (только если он существует), а затем выполняем существующую очистку для других холстов, массивов событий и динамических объектов. Это гарантирует, что мы не оставим никаких следов — поэтому перезагрузка или повторное развертывание советника всегда начинается с чистого листа.
void OnDeinit(const int reason) { EventKillTimer(); // … existing cleanup … if(ShowAIInsights) { aiCanvas.Destroy(); ObjectDelete(0, "AiC"); } }
Тестирование интеграции
Теперь, когда мы завершили интеграцию, загрузим наш обновленный советник в MetaTrader 5 и понаблюдаем за его работой в режиме реального времени. Убедитесь, что сервер ИИ работает в фоновом режиме — я все еще изучаю, сможем ли мы запустить его программно из самого советника. На скриншоте ниже вы увидите закрепленную под другими полосами новую полосу «Анализ искусственного интеллекта», на которой отображается текст аналитической информации в режиме реального времени.
Вы можете легко настроить его цветовую гамму в коде; для этой демонстрации мы оставили ее по умолчанию. Вы также заметите случайные, краткие паузы в прокрутке — это следствие нашего текущего тайминга выборки, который мы скорректируем в следующих версиях. Теперь, когда функция комплексного искусственного интеллекта запущена, мы перейдем к реализации на стороне сервера, чтобы понять, как именно серверная часть обеспечивает эти возможности.

Советник «Заголовки новостей» с аналитическими данными на основе ИИ из локально размещенной модели
Этот фрагмент, приведенный ниже, был взят непосредственно из Anaconda Prompt, где Uvicorn обслуживает нашу конечную точку /insights. Просмотр этих логов говорит нам о трех вещах
- Модель успешно загружена, так что механизм логического вывода готов.
- Uvicorn запущен и прослушивает, значит, HTTP-сервер запущен.
- WebRequest нашего советника успешно поступил на сервер, запустив новый цикл логического вывода.
Ниже я запечатлел пять таких циклов вывода во время тестирования — каждый из них соответствует отдельному POST от советника. После этого фрагмента я подробно расскажу вам об одном из этих циклов, чтобы вы могли точно увидеть, что происходит за кулисами.
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 83.42 ms / 64 runs ( 1.30 ms per token, 767.19 tokens per second) llama_print_timings: prompt eval time = 1890.97 ms / 6 tokens ( 315.16 ms per token, 3.17 tokens per second) llama_print_timings: eval time = 32868.44 ms / 63 runs ( 521.72 ms per token, 1.92 tokens per second) llama_print_timings: total time = 35799.69 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 51.40 ms / 64 runs ( 0.80 ms per token, 1245.21 tokens per second) llama_print_timings: prompt eval time = 1546.64 ms / 4 tokens ( 386.66 ms per token, 2.59 tokens per second) llama_print_timings: eval time = 29878.89 ms / 63 runs ( 474.27 ms per token, 2.11 tokens per second) llama_print_timings: total time = 32815.26 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 65.92 ms / 64 runs ( 1.03 ms per token, 970.80 tokens per second) llama_print_timings: prompt eval time = 1841.83 ms / 6 tokens ( 306.97 ms per token, 3.26 tokens per second) llama_print_timings: eval time = 31295.30 ms / 63 runs ( 496.75 ms per token, 2.01 tokens per second) llama_print_timings: total time = 34146.43 ms ←[32mINFO←[0m: 127.0.0.1:52769 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 55.34 ms / 64 runs ( 0.86 ms per token, 1156.42 tokens per second) llama_print_timings: prompt eval time = 1663.61 ms / 4 tokens ( 415.90 ms per token, 2.40 tokens per second) llama_print_timings: eval time = 29311.62 ms / 63 runs ( 465.26 ms per token, 2.15 tokens per second) llama_print_timings: total time = 31952.19 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
Понимание работы модели и WebRequest внутри Anaconda Prompt:
llama_print_timings: load time = 206235.75 ms llama_print_timings: sample time = 58.01 ms / 64 runs ( 0.91 ms per token, 1103.33 tokens per second) llama_print_timings: prompt eval time = 1487.17 ms / 4 tokens ( 371.79 ms per token, 2.69 tokens per second) llama_print_timings: eval time = 29555.55 ms / 63 runs ( 469.14 ms per token, 2.13 tokens per second) llama_print_timings: total time = 31979.70 ms ←[32mINFO←[0m: 127.0.0.1:52770 - "←[1mPOST /insights HTTP/1.1←[0m" ←[32m200 OK←[0m Llama.generate: prefix-match hit
Когда ваш сервер FastAPI‐Uvicorn загружает модель GGUF, llama‑cpp сообщает, что “время загрузки” составляет около 206 секунд — это единовременные затраты на считывание и инициализацию всей квантованной сети в памяти. После этого каждый входящий HTTP POST в /insights выполняется примерно в такой последовательности:
Оценка запроса (время оценки запроса)
Здесь llama‑cpp запускает первые несколько токенов из вашего запроса через стек трансформаторов модели, чтобы “запустить” генерацию. В данном логе на 4 токена ушло в общей сложности 1,49 секунды, что составляет примерно 372 мс на каждый токен.
Генерация токена (время оценки + время выборки)
- Для каждого последующего генерируемого токена библиотека выполняет две операции:
- Оценка: вычисляет прямой проход трансформера (≈ 469 мс на токен, то есть ~2,13 токена в секунду).
- Выборка: применяет выборку nucleus/top‑k/etc для выбора следующего токена (≈ 0,91 мс на токен).
- В вашем эксперименте генерация 63 токенов заняла около 29,6 секунды для оценки плюс 58 мс для выборки всех из них.
Общая задержка (общее время)
Суммирование значений запроса, всех оценок токенов и выборки дает 31,98 секунды с момента начала вычислений моделью до получения окончательного текста.
Сразу по завершении генерации Uvicorn регистрирует что-то вроде:
INFO: 127.0.0.1:52770 - "POST /insights HTTP/1.1" 200 OK
это означает, что сервер получил WebRequest("POST", "http://127.0.0.1:8000/insights", …) от вашего советника, обработал его и вернул информацию в формате JSON со статусом 200, содержащую вашу «аналитическую информацию".
Наконец, строка указывает на то, что llama‑cpp распознал повторяющуюся последовательность токенов (префикс) в своем кэше и пропустил повторное вычисление этих уровней, что немного ускорило генерацию.
Llama.generate: prefix-match hit
Во время тестирования я заметил случайные паузы в прокрутке полосы советника. Оказалось, что вызов функции FetchAIInsights() непосредственно в цикле таймера означал, что WebRequest советника будет заблокирован в ожидании таймаута, в то время как Uvicorn выполнит всю оценку модели, генерацию токенов и выборку (около 32 секунд), прежде чем вернет JSON.
Благодаря полному отделению логики прокрутки от наших HTTP—вызовов — рисования и перемещения текста каждые 20 мс перед вызовом функции FetchAIInsights() - анимация полосы пользовательского интерфейса может продолжаться без перерыва. Тем временем на сервере выполняется логический вывод в тяжелом режиме, и только после его завершения мы обновляем latestAIInsight с новым ответом.
Заключение
В заключение, это упражнение показало, насколько расширяемым может быть MQL5 в сочетании с внешними сервисами — независимо от того, загружаете ли вы текущие события экономического календаря и заголовки из Alpha Vantage или дополняете свои графики "заметками", созданными искусственным интеллектом, из самостоятельно размещенной 4‑разрядной модели. Хотя эти аналитические материалы с использованием ИИ не заменяют данные в режиме реального времени или профессионально подготовленную торговую систему, они добавляют качественный уровень комментариев по запросу или подсказок для мозгового штурма, которые могут породить новые идеи.
Попутно мы познакомились с платформой Hugging Face и научились использовать MSYS2, Git Bash и Miniconda для извлечения моделей, настройки серверов и управления изолированными средами. Мы объединили два языка — Python для логического вывода моделей и FastAPI, а также MQL5 для интеграции с графиками, расширяя наш набор инструментов программирования и продемонстрировав, как различные экосистемы могут работать сообща. Приглашаем вас поэкспериментировать, поделиться своими отзывами в разделе комментариев.
Забегая вперед, чтобы улучшить контекст и релевантность, попробуйте ввести в свои запросы искусственного интеллекта ценовой ряд с платформы MetaTrader 5 или значения индикаторов в режиме реального времени. Можно экспериментировать с различными квантованными форматами, автоматизировать развертывание с нулевым временем простоя или распределять логический вывод по нескольким узлам. Переход на более крупную модель и модернизация оборудования позволят получить более насыщенную, подробную информацию, но даже скромные настройки могут стать мощными интерактивными помощниками в торговле. Возможности для пересечения алгоритмической торговли и автономного ИИ остаются открытыми; ваш следующий прорыв может изменить то, как трейдеры взаимодействуют с рынками.
Ознакомьтесь с прилагаемыми файлами поддержки ниже. Также я подготовил таблицу с кратким описанием каждого файла, чтобы помочь вам понять их назначение.
Основные уроки
| Урок | Описание |
|---|---|
| Изоляция среды | Используйте Conda или virtualenv для создания изолированных сред на Python, сохраняя такие зависимости, как FastAPI и llama‑cpp‑python, раздельными и воспроизводимыми. |
| Локальное кэширование | Однократно загружайте и кэшируйте большие файлы моделей GGUF с помощью клиента Hugging Face Hub, чтобы избежать повторной передачи данных по сети и ускорить запуск сервера. |
| Ограничение скорости | Установите ограничение с минимальным интервалом (например, 300 секунд) для запросов ИИ, чтобы советник не перегружал сервер, либо не создавал чрезмерной нагрузки на логический вывод. |
| Синтаксический анализ с устойчивостью к ошибкам | Включает декодирование JSON в обработку ошибок и извлекает только первый действительный объект, защищая советника от неправильных ответов или ответов с дополнительными данными. |
| Двойная буферизация холста | Использует Canvas.Update(true) после каждого цикла рисования, чтобы зафиксировать изменения, предотвратить мерцание и обеспечить плавную анимацию графика. |
| Управляемые таймером циклы | Управляет прокруткой и обновлением данных с помощью единого таймера в миллисекунды (например, 20 мс), чтобы сбалансировать плавность анимации с нагрузкой на процессор. |
| Интеграция WebRequest | Использует WebRequest MQL5 для отправки JSON на локальный сервер ИИ и получения аналитических данных, не забывая добавить URL-адрес в белый список в настройках терминала. |
| Рандомизация для разнообразия | Изменяет подсказки или случайным образом выбирает валютные пары для каждого запроса ИИ, чтобы генерировать разнообразную, неповторяющуюся аналитическую информацию о торговле. |
| Очистка ресурсов | В OnDeinit уничтожает все объекты Canvas, удаляет динамические массивы и отключает таймеры, чтобы избежать утечек памяти и потерянных объектов диаграммы. |
| Модульное проектирование | Организует код в понятные функции — ReloadEvents, FetchAlphaVantageNews, FetchAIInsights, DrawLane — для улучшения читаемости и сопровождаемости. |
| Универсальность оболочки | Использует Git Bash для Git и написания скриптов, MSYS2 для инструментов и сборок POSIX, Conda Prompt для сред Python и CMD для быстрого выполнения разовых заданий. |
| Хостинг квантованной модели | Размещает квантованную модель GGUF локально, чтобы уменьшить объем памяти и задержку вывода по сравнению со значениями с полной точностью. |
| Разделение сервера и клиента | Сохраняет высокий уровень логических выводов на сервере FastAPI/Uvicorn, позволяет советнику оставаться ненагруженным, обрабатывая только обновления пользовательского интерфейса и HTTP-запросы. |
| Раздельный рендеринг | Всегда выполняет операции прокрутки и рисования перед вызовом сетевых функций, обеспечивая оперативность пользовательского интерфейса даже при длительных запросах. |
| Разработка запросов | Создает краткие, целенаправленные запросы в формате JSON, такие как “Информация по паре EURUSD на сегодня”, чтобы свести к минимуму время на оценку запросов и сфокусировать вывод модели. |
| Стратегии формирования выборок | Настройка параметров выборки (top‑k, top‑p, температура) в вашем приложении FastAPI, чтобы сбалансировать креативность и последовательность генерируемых аналитических данных. |
| Асинхронные конечные точки | Использует асинхронные обработчики определения FastAPI, чтобы Uvicorn мог обрабатывать одновременные запросы советника без блокировки длительного логического вывода. |
| Ведение лога и наблюдаемость | Использует как советник, так и сервер с временными метками в логе и уровнями — например, llama_print_timings и EA console prints — для диагностики проблем с производительностью. |
| Показатели производительности | Предоставляет доступ к таким показателям (например, через Prometheus), как задержка запроса, количество токенов в секунду и время загрузки модели, для мониторинга и оптимизации производительности системы. |
| Резервные стратегии | Отображает сообщение “insight unavailable” (аналитическая информация недоступна) в советнике по умолчанию в случае сбоя WebRequest или сбоя сервера, поддерживая стабильность пользовательского интерфейса в условиях ошибок. |
Содержимое вложения
| Имя файла | Описание |
|---|---|
| News Headline EA.mq5 | Скрипт советника MetaTrader 5, который отображает полосы прокрутки событий экономического календаря, новости Alpha Vantage, информацию об индикаторах непосредственно на графике (RSI, Stochastics, MACD, CCI), а также замедленную полосу сигналов рынка, управляемую ИИ. |
| download_model.py | Автономный скрипт на Python, использующий клиент Hugging Face Hub для извлечения и кэширования 4‑разрядной квантованной StableLM‑Zephyr модели в формате, выводящий ее локальный путь для последующего использования при настройке сервера. |
| serve_insights.py | Приложение FastAPI, которое загружает кэшированную модель GGUF посредством llama‑cpp‑python, предоставляет конечную точку POST/ insights для приема запросов в формате JSON, выполняет логический вывод и возвращает сгенерированную информацию о рынке. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18685
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования