
Возможности Мастера MQL5, которые вам нужно знать (Часть 55): SAC с приоритетным воспроизведением опыта
Растущая сложность моделей нейронных сетей обусловлена нашей способностью обрабатывать огромные объемы данных. Традиционное машинное обучение неэффективно, в то время как нейронные сети, примером которых являются такие платформы, как DeepSeek, Grok и ChatGPT, предлагают мощные решения.
Однако обучение этих моделей сопряжено с трудностями, особенно при ограниченном объеме исторических данных. Переобучение является серьезной проблемой, поскольку существует риск того, что модели будут изучать шум вместо значимых закономерностей. Традиционное обучение часто отдает приоритет минимизации функций потерь, что может привести к плохому обобщению.
Обучение с подкреплением (reinforcement learning, RL) решает эту проблему, балансируя между эксплуатацией (оптимизацией весов) и исследованием (тестированием альтернатив). Такие методы, как приоритетное воспроизведение опыта (Prioritized Experience Replay, PER), повышают эффективность обучения, смягчая проблемы нехватки данных, возникающие в таких областях, как торговля, где ежемесячные экономические данные ограничены.
Ключевые моменты при обучении с подкреплением включают разработку эффективной функции вознаграждения, выбор правильного алгоритма и выбор между методами, основанными на значениях (например, Q-Learning, DQN), и методами, основанными на политике (например, PPO, TRPO). Подходы актер-критик (например, A3C, SAC) обеспечивают баланс между стабильностью и эффективностью. Методы, соответствующие политике (PPO, A3C), обеспечивают стабильное обучение, в то время как методы вне политики (DQN, SAC) максимизируют эффективность данных.
Адаптивность RL делает его ценным дополнением к конвейерам машинного обучения, дополняя традиционные подходы. При обучении сложных моделей с ограниченными данными приоритет обновления веса над минимизацией потерь способствует лучшему обобщению и надежности.
Приоритетное воспроизведение опыта
Буферы приоритетного воспроизведения опыта (PER) и типичные буферы воспроизведения (для случайной выборки) используются в RL с алгоритмами, не соответствующими политике, такими как DQN и SAC, поскольку они позволяют хранить и осуществлять выборку прошлого опыта. PER отличается от типичного буфера воспроизведения тем, как ранжируются и выбираются прошлые события.
При использовании типичного буфера воспроизведения выборка событий осуществляется равномерно и случайным образом, что означает, что любой прошлый опыт имеет равную вероятность быть выбранным независимо от его важности или значимости для процесса обучения. При использовании PER прошлый опыт отбирается на основе его "приоритета". Это свойство часто количественно оценивается величиной ошибки временной разницы (Temporal Difference Error). Эта ошибка служит показателем потенциала обучения. Каждому опыту присваивается значение этой ошибки, и опыт с высокими значениями выбирается чаще. Такая приоритизация может быть реализована с использованием пропорционального или рангового подхода.
Типичные буферы воспроизведения также не вносят и не используют никаких смещений. PER использует, и это может несправедливо исказить процесс обучения, поэтому, чтобы это исправить, PER использует веса выборки важности для корректировки воздействия каждого выбранного опыта. Таким образом, типичные буферы воспроизведения более эффективны с точки зрения выборки, поскольку они выполняют гораздо меньше действий в фоновом режиме по сравнению с PER. С другой стороны, PER обеспечивает более целенаправленное и конструктивное обучение, чего не могут дать обычные буферы.
Само собой разумеется, что реализация PER будет более сложной, чем реализация типичного буфера воспроизведения. PER требует дополнительного класса для поддержания очереди приоритетов, часто называемой "деревом сумм" (sum-tree). Такая структура данных позволяет более эффективно осуществлять выборку впечатлений на основе их приоритета. PER, как правило, приводит к более быстрой конвергенции и лучшей производительности, поскольку фокусируется на событиях, которые являются более информативными или сложными для агента.
Реализация в модели
Наш класс PER в Python использует инициализацию, которая проверяет параметры его конструктора, в частности параметр режима. Я могу ошибаться, но мне кажется, что это невозможно сделать "из коробки" с помощью C/MQL5. Объявим функцию __init__ следующим образом:
def __init__(self, capacity, alpha=0.6, beta=0.4, beta_increment=0.001, mode='proportional'): self.capacity = capacity self.alpha = alpha self.beta = beta self.beta_increment = beta_increment self.mode = mode if mode == 'proportional': self.tree = SumTree(capacity) elif mode == 'rank': self.priorities = [] self.data = [] else: raise ValueError("Invalid mode. Choose 'proportional' or 'rank'.")
При объявлении класса одной из важных функций, которую он должен включать, является метод добавления опыта в буфер. Реализация в коде:
def add(self, error, sample): p = self._get_priority(error) if self.mode == 'proportional': self.tree.add(p, sample) elif self.mode == 'rank': heapq.heappush(self.priorities, -p) if len(self.data) < self.capacity: self.data.append(sample) else: heapq.heappop(self.priorities) heapq.heappush(self.data, sample)
Обратите внимание, что при этом добавлении опыта режим выборки является ключевым, поскольку если мы выбираем опыт на основе доли ошибки, мы просто добавляем его в дерево суммы, но если мы выбираем на основе ранжирования величины ошибки, мы используем импортированный модуль heapq, который обновляем с помощью этого образца, как указано выше. Поэтому в пропорциональной выборке используется класс дерева сумм, а не ранг. Реализация в коде:
class SumTree: def __init__(self, capacity): self.capacity = capacity self.tree = np.zeros(2 * capacity - 1) self.data = np.zeros(capacity, dtype=object) self.write = 0 self.n_entries = 0 def _propagate(self, idx, change): parent = (idx - 1) // 2 self.tree[parent] += change if parent != 0: self._propagate(parent, change) def _retrieve(self, idx, s): left = 2 * idx + 1 right = left + 1 if left >= len(self.tree): return idx if s <= self.tree[left]: return self._retrieve(left, s) else: return self._retrieve(right, s - self.tree[left]) def total(self): return self.tree[0] def add(self, p, data): idx = self.write + self.capacity - 1 self.data[self.write] = data self.update(idx, p) self.write += 1 if self.write >= self.capacity: self.write = 0 if self.n_entries < self.capacity: self.n_entries += 1 def update(self, idx, p): change = p - self.tree[idx] self.tree[idx] = p self._propagate(idx, change) def get(self, s): idx = self._retrieve(0, s) data_idx = idx - self.capacity + 1 return (idx, self.tree[idx], self.data[data_idx])
После определения этого ключевого класса другим его важным компонентом становится сама функция выборки, которая является частью класса PER.
def sample(self, batch_size): batch = [] idxs = [] segment = self.tree.total() / batch_size if self.mode == 'proportional' else len(self.data) / batch_size priorities = [] self.beta = np.min([1., self.beta + self.beta_increment]) for i in range(batch_size): a = segment * i b = segment * (i + 1) if self.mode == 'proportional': s = random.uniform(a, b) (idx, p, data) = self.tree.get(s) priorities.append(p) batch.append(data) idxs.append(idx) elif self.mode == 'rank': idx = random.randint(0, len(self.data) - 1) priorities.append(-self.priorities[idx]) batch.append(self.data[idx]) idxs.append(idx) sampling_probabilities = np.array(priorities) / self.tree.total() if self.mode == 'proportional' else np.array(priorities) / sum(self.priorities) is_weights = np.power(len(self.data) * sampling_probabilities, -self.beta) is_weights /= is_weights.max() return batch, idxs, is_weights
И снова ключевым фактором является способ выборки — пропорциональный или ранговый. Эти два подхода назначают приоритеты каждому опыту, учитывая ошибку TD, с небольшим различием. Величина ошибки TD и ранг ошибки TD. Ошибка TD фактически представляет собой разницу между полученным на выходе результатом и фактическим или целевым значением. Она никогда не используется в исходном виде для оценки опыта, а преобразуется в приоритетное значение, как показано в этом листинге:
def _get_priority(self, error): return (error + 1e-5) ** self.alpha
Это приоритетное значение, величина (для пропорциональной выборки) или ранг (для ранговой выборки) которого используются при выборе опыта для обучения модели. Метод PER был представлен Шолом (Shaul) и соавторами в 2015 году. Более приоритетные события проверяются чаще, что повышает эффективность выборки и скорость обучения в среде RL. Приоритеты обновляются после обучения. Весовые коэффициенты выборки по значимости используются для коррекции смещения, возникающего из-за неравномерной выборки на основе приоритетов. Это указано в примере функции класса PER выше. Давайте подробнее рассмотрим эти два способа выборки.
Пропорциональная приоритизация
Как упоминалось выше, приоритеты прямо пропорциональны ошибке временной разницы (∣δ∣). Таким образом, приоритет для опыта i будет вычислен как:
pi=∣δi∣+ϵ
где ϵ, больше нуля, — это малая константа, которая гарантирует, что все события не будут иметь нулевой приоритет. Вероятность выборки для данного опыта, таким образом, будет равна:
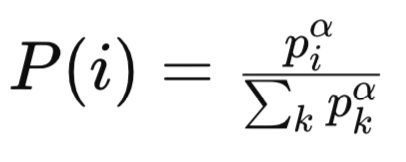
где:
-
pi - приоритет i-го опыта в буфере воспроизведения. Приоритет обычно основан на величине ошибки временной разницы (TD) для данного опыта. Опыт с большими ошибками TD считается более важным и получают более высокие приоритеты.
-
α - гиперпараметр, который контролирует степень приоритетности. Когда ( α = 0 ), все впечатления выбираются равномерно (без приоритетов). При ( α = 1 ) выборка полностью основана на приоритетах.
-
Сигма/сумма всех k приоритетов — это нормализующий член, который гарантирует, что сумма вероятностей равна 1. Он суммирует приоритеты всех событий в буфере воспроизведения, возведенные в степень ( α).
-
P(i) - вероятность выборки (i)-го опыта. Она пропорциональна приоритету опыта (Piα), нормализованному по сумме всех приоритетов, возведенных в степень ( α).
Затем можно использовать дерево сумм или структуру данных аналогичной формы для эффективной выборки событий I, пропорциональных piα. Распределение выборки с пропорциональным распределением приоритетов является непрерывным и напрямую связано с величиной ошибок TD. Опыт с высокими ошибками TD, как правило, имеет значительно более высокий приоритет, что приводит к распределению с тяжелым хвостом.
Это может привести к тому, что часть опыта будет подвергаться слишком частой выборке (что является серьезной проблемой, если его ошибки TD являются выбросами), а другая будет подвергаться выборке редко, поскольку ее ошибки невелики. Чувствительность к ошибкам обучения может различаться в зависимости от задач на этапах обучения, но существует уязвимость пропорционального установления приоритетов для выбросов в ошибках TD, поскольку большие значения могут доминировать в распределении выборки.
Например, рассмотрим сценарий, в котором один опыт имел разрыв между выходом и целевым значением 1000, а другие имели этот показатель 1; очевидно, что это большое значение будет часто непропорционально выбираться. Эта особенность может привести к переобучению зашумленным или выпадающим данным, особенно в средах данных с высокой дисперсией вознаграждений или Q-значений. Возможной мерой смягчения этого недостатка может быть ограничение или нормализация ошибки TD. Например:
pi=min(∣δi∣,δmax)+ϵ
где по сути приоритет опыта устанавливается на минимум между его собственной ошибкой TD и самой высокой ошибкой TD всех опытов в выбранном сегменте плюс небольшое ненулевое значение, эпсилон. Сложности, связанные с операционным временем при работе с деревом сумм, очевидны при вычислении приоритета для каждого опыта, поскольку они достигают O(1) на опыт. Выборка и обновление приоритетов выполняются за O(log n) на операцию, где n — размер буфера. Благодаря отсутствию дополнительных затрат на сортировку и ранжирование, обновления становятся эффективными с вычислительной точки зрения.
Пропорциональное назначение приоритетов (Proportional Prioritization, PP) может способствовать нестабильному обучению в случаях, когда ошибки TD значительно различаются на разных этапах обучения, поскольку распределение выборки будет быстро меняться. Оно также чувствительно к гиперпараметрам, поэтому выбор значений альфы и эпсилона необходимо делать осторожно, чтобы сбалансировать исследование и эксплуатацию. PP может сходиться быстрее для задач с "хорошо себя ведущими" ошибками, что свидетельствует о ценности обучения, но оно неизбежно будет испытывать трудности в шумных и нестационарных средах.
PP подходит для задач, в которых ошибки TD являются допустимыми и напрямую указывают на потенциал/ценность обучения. Оно очень эффективно в средах с низким уровнем шума и стабильными значениями Q, где ошибки TD прямо пропорциональны важному опыту. Примерами этого являются игры Atari со стабильной структурой вознаграждения и задачи непрерывного контроля с плавными функциями ценности.
Весовые коэффициенты значимости выборки PP, как правило, варьируются из-за распределения выборки с тяжелыми хвостами. Опыты с низкими приоритетными весами имеют низкие значения P(i) (т.е. вероятность выборочного опыта i), что приводит к большим весам wi (корректировочные веса, предназначенные для коррекции смещения). Такие настройки могут привести к непреднамеренным последствиям в виде усиления градиентов и дестабилизации обучения. Это означает, что бета-коэффициент также необходимо тщательно настраивать, чтобы найти баланс между коррекцией смещения и стабильностью.
Подводя итог, можно сказать, что PP подходит, когда ошибки TD являются допустимыми и коррелируют с обучающей ценностью, среда данных имеет низкий уровень шума и стабильные Q-значения, а вычислительная эффективность имеет решающее значение, поэтому расходы на сортировку и ранжирование неприемлемы. Тонкая настройка гиперпараметров альфа, бета и эпсилон может помочь в обработке выбросов и управлении нестабильностью.
Приоритизация на основе ранга
В этом режиме приоритеты основываются на значениях индексов рангов ошибок TD в отсортированном списке ошибок TD. Ранг опыта i устанавливается путем сортировки всех опытов по величине ошибки временной разницы в порядке убывания. Почему в порядке убывания? Потому что интуитивно такой список интерпретируется как важность опыта. Чем выше опыт в списке, тем он важнее. Во-вторых, с точки зрения вычислений имеет смысл располагать наиболее часто используемые опыты в нижних индексах кучи, поскольку алгоритму не нужно проходить по всей куче, чтобы добраться до опытов, предназначенных для выполнения большей части обучения. Приоритет опыта i обычно вычисляется как:
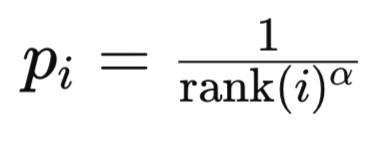
где:
- rank(i) — ранг i-го опыта.
- alpha — гиперпараметр, контролирующий силу приоритизации.
Вероятность выборки для опыта использует формулу, похожую на ту, которую мы уже рассмотрели выше при пропорциональной расстановке приоритетов.
При ранговой приоритизации (RP) распределение выборки является дискретным и основано на рангах. Это, как правило, делает его менее чувствительным к абсолютным ошибкам шкалы TD. Опыт выбирается на основе своего ранга, а не величины ошибки. Это приводит к более равномерному распределению при выборке, учитывая, что разница в приоритетах между впечатлениями почти "стандартизирована", поскольку она контролируется соответствующим рейтингом опыта (т. е. е. 1/1, ½, ⅓, и т.д.). Кроме того, RP менее склонна к переобучению выбросам, поскольку наивысший назначенный приоритет для любого опыта зафиксирован на уровне 1/1 независимо от величины его ошибки TD. Однако эта надежность снижается из-за недостаточной выборки данных с очень высокими ошибками TD, если функция приоритета, основанная на ранге, затухает слишком быстро.
Однако, помимо риска недостаточной выборки ключевого опыта, основным недостатком RP остается вычислительная сложность. Сортировка всего буфера для определения рангов представляет собой операционную вычислительную сложность величиной O(nlogn) для всего буфера размером n. На практике эту сортировку можно избежать, поддерживая отсортированную структуру данных (такую как двоичное дерево поиска или куча) для ошибок TD, но обновления по-прежнему требуют O(logn) операционных вычислений за один опыт. Выборка и обновление по-прежнему выполняются на уровне O(logn), как и при использовании пропорциональной выборки. Подводя итог, можно сказать, что RP имеет значительно более высокие вычислительные затраты по сравнению с PP.
При обучении RP более стабильна, поскольку распределение выборки менее чувствительно к изменениям величин ошибок TD. Она также имеет тенденцию обеспечивать согласованные вероятности выборки с течением времени, поскольку ранги относительны и меньше подвержены влиянию шума и выбросов. Она может сходиться медленнее для задач, где абсолютные ошибки TD имеют решающее значение/являются весьма информативными для процесса обучения, поскольку она не так агрессивно отдает приоритет ошибкам высокой величины. Ее также немного легче настраивать (корректировать гиперпараметры), поскольку функция приоритета на основе ранга менее чувствительна к масштабу.
RP подходит для ситуаций с недостаточным вознаграждением или для задач, предполагающих отсроченное вознаграждение или высокую дисперсию вознаграждения. RP является предпочтительным режимом, если стабильность и сбалансированная выборка имеют решающее значение, даже если сходимость может быть медленной.
Как PP, так и RP вносят смещение, учитывая их неравномерные методы выборки, как уже упоминалось и было показано в методе выборки в приведенном выше источнике. Основная формула:
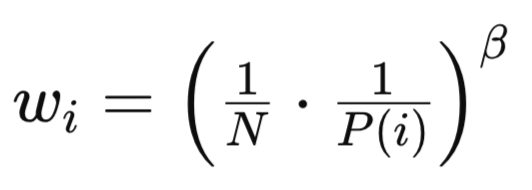
где:
- N — общее количество опыта в буфере воспроизведения.
- P(i) — вероятность выборки i-го опыта.
- бета (β∈[0,1]) — гиперпараметр, который контролирует силу коррекции выборки важности.
Несмотря на схожесть формул, веса RP и PP различаются по ключевым аспектам. Для RP веса выборки важности более равномерны, поскольку распределение менее асимметрично. Такая меньшая дисперсия значений wi приводит к более стабильному обучению и меньшей чувствительности к бета-коэффициенту. Кроме того, коррекцию смещения легче осуществлять, поскольку распределение на основе рангов по своей сути более сбалансировано.
Тестирование класса сигнала
Если мы используем указанный выше код и изменим код модели SAC из последней статьи, используя PER вместо типичного/простого буфера воспроизведения, мы сможем обучить модель и экспортировать сеть с ее весами в виде файла ONNX. Мы рассмотрели, как можно управлять экспортом здесь. Подробности об экспорте ONNX-модели из python можно найти здесь. Модели ONNX используются MQL5 путем их встраивания в качестве ресурсов при компиляции.
На стороне MQL5 в IDE наш пользовательский класс сигнала, который, строго говоря, ничем не отличается от того, что мы рассматривали в предыдущей статье о SAC, должен быть собран с помощью Мастера MQL5. Подробности можно найти здесь и здесь. Тестовые прогоны на USDJPY на дневном таймфрейме за 2023 год без перекрестной валидации дают нам следующие результаты:


Однако в дальнейшем перекрестная проверка с использованием моделей в Python может быть реализована очень эффективно, так что, возможно, я начну включать ее в свои статьи в будущем. Однако, как всегда, прошлые результаты не гарантируют будущих результатов, и читателю всегда предлагается проявить дополнительную осмотрительность, прежде чем принять решение об использовании или развертывании любой из систем, представленных здесь.
Заключение
Мы вновь рассмотрели случай обучения с подкреплением, а также попытались ответить на вопрос, почему в современных условиях сложных моделей и ограниченных исторических тестовых данных крайне важно поставить процесс получения подходящих весовых коэффициентов сети выше теоретических оценок функций с низкими потерями. Процесс имеет значение. Мы выделили альтернативный буфер воспроизведения для обучения с подкреплением, буфер воспроизведения приоритетного опыта как буфер, который не только сохраняет под рукой недавний опыт для выборки при обучении, но и делает выборки из этого буфера пропорционально тому, насколько релевантно или насколько много сети необходимо обучиться на основе выбранного опыта.
| Файл | Описание |
|---|---|
| wz_55.mq5 | Собранный в Мастере советник с заголовком, показывающим используемые файлы |
| SignlWZ_55.mqh | Файл класса пользовательских сигналов |
| USDJPY.onnx | Файл сети ONNX |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/17254
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования