
Торговля LLM-агента со встроенной философией топ-трейдеров

Введение: проблема предыдущей части статьи
Разработка системы из прошлой статьи столкнулась с фундаментальной и очень распространённой ловушкой: система показывает высокую точность предсказания направления цены (accuracy > 60–65% на out-of-sample), красивые метрики в независимом тесте, но при переводе прогнозов в реальные торговые действия edge либо очень маленький, либо полностью исчезает — особенно после учёта издержек и при переходе на новые рыночные режимы.
У трейдера возникает классический когнитивный диссонанс: модель угадывает правильно чаще 50%, бэктест выглядит отлично, а в реальности деньги не приходят или уходят. Почему так происходит, и как правильно переформулировать задачу, чтобы модель ориентировалась не на «угадал направление», а на реальную прибыльность сделки — главная тема этой статьи.
В первой версии система была разработана с соблюдением всех методологических требований: строгое разделение данных без look-ahead bias, использование современных архитектур LLM, встроенная философия элитных трейдеров и честное форвард-тестирование на невидимых данных. Тем не менее, даже при этих улучшениях при переходе от теоретических метрик к реальному PnL система демонстрирует систематический разрыв между предсказательной силой и торговой доходностью.
Вторая версия — это попытка частично закрыть этот разрыв через более тщательное управление качеством датасета, балансировку классов и некоторые улучшения в промптинге/парсинге. Но даже после этих доработок главная проблема остаётся — и именно её диагностике и посвящена статья. В итоге мы строим перспективную систему, которая уже показывает хороший потенциал в бэктесте, и её ждёт тщательная проверка на реальных данных.
Генерация сбалансированного датасета: критическая роль class imbalance
Качество данных является абсолютной нижней границей для производительности любой системы машинного обучения. Первая версия AGI Trader игнорировала проблему class imbalance, где количество восходящих и нисходящих паттернов в исторических данных распределено крайне неравномерно. Валютные пары демонстрируют естественный дрейф цены в зависимости от макроэкономических условий, процентных ставок и геополитических факторов, приводя к систематическому смещению в направлении тренда.
Функция generate_real_dataset_from_mt5 в новой версии адресует эту проблему через активную балансировку с целевым соотношением UP/DOWN = 1.0:
def generate_real_dataset_from_mt5(num_samples: int = 1000) -> list: """Генерация СБАЛАНСИРОВАННОГО датасета на основе реальных данных MT5""" # Счётчики для балансировки up_count = 0 down_count = 0 target_up = int(num_samples * balance_ratio / (1 + balance_ratio)) target_down = num_samples - target_up print(f"Целевое распределение:") print(f" UP: {target_up} примеров ({target_up/num_samples*100:.1f}%)") print(f" DOWN: {target_down} примеров ({target_down/num_samples*100:.1f}%)\n") dataset = [] # Загружаем данные за последние 6 месяцев end = datetime.now() start = end - timedelta(days=180) for symbol in SYMBOLS: # Собираем ВСЕ возможные точки для анализа all_candidates = [] for idx in range(LOOKBACK, len(df) - PREDICTION_HORIZON): row = df.iloc[idx] future_idx = idx + PREDICTION_HORIZON future_row = df.iloc[future_idx] actual_price_24h = future_row['close'] price_change = actual_price_24h - row['close'] direction = "UP" if price_change > 0 else "DOWN" all_candidates.append({ 'idx': idx, 'direction': direction, 'price_change': abs(price_change), 'symbol': symbol, 'row': row, 'future_row': future_row }) # Разделяем по направлениям up_candidates = [c for c in all_candidates if c['direction'] == 'UP'] down_candidates = [c for c in all_candidates if c['direction'] == 'DOWN'] # Сэмплируем с учётом баланса symbol_target = num_samples // len(SYMBOLS) symbol_up_target = int(symbol_target * balance_ratio / (1 + balance_ratio)) symbol_down_target = symbol_target - symbol_up_target selected_up = np.random.choice( len(up_candidates), size=min(symbol_up_target, len(up_candidates)), replace=False ) if len(up_candidates) > 0 else []
Алгоритм балансировки состоит из трёх этапов. Во-первых, собираются ВСЕ возможные кандидаты для включения в датасет, без предварительного отбора по направлению. Это обеспечивает полное представление доступного рыночного материала. Во-вторых, кандидаты разделяются по классам UP и DOWN. В-третьих, выполняется стратифицированная выборка независимо для каждого класса, обеспечивая целевое распределение без дублирования. При balance_ratio = 1.0 достигается идеальное распределение 50/50, что позволяет модели обучиться с равной эффективностью на обоих направлениях.
Критически важным является осознание того, что балансировка датасета не решает коренную проблему: даже идеально сбалансированный датасет обучает модель предсказывать направление движения цены, а не извлекать прибыль на торговле. Балансировка лишь гарантирует, что модель одинаково хорошо обучится обоим классам, но не трансформирует эту точность в торговое преимущество.
→ Мини-вывод раздела: class imbalance — это важный, но вторичный фактор. Основной разрыв лежит глубже — в самой постановке целевой переменной (label / objective). Мы учли это в версии 2, и система уже выглядит сбалансированной — впереди тесты на устойчивость.
Технические индикаторы как представление рыночного состояния
Система вычисляет полный набор технических индикаторов для каждого бара, определяя признаковое пространство для обучения модели. Функция calculate_features реализует следующие компоненты:
def calculate_features(df: pd.DataFrame) -> pd.DataFrame: """Расчёт технических индикаторов""" d = df.copy() d["close_prev"] = d["close"].shift(1) # ATR - мера волатильности для управления рисками tr = pd.concat([ d["high"] - d["low"], (d["high"] - d["close_prev"]).abs(), (d["low"] - d["close_prev"]).abs(), ], axis=1).max(axis=1) d["ATR"] = tr.rolling(14).mean() # RSI - индикатор импульса с периодом 14 delta = d["close"].diff() up = delta.clip(lower=0).rolling(14).mean() down = (-delta.clip(upper=0)).rolling(14).mean() rs = up / down.replace(0, np.nan) d["RSI"] = 100 - (100 / (1 + rs)) # MACD - конвергенция-дивергенция скользящих средних ema12 = d["close"].ewm(span=12, adjust=False).mean() ema26 = d["close"].ewm(span=26, adjust=False).mean() d["MACD"] = ema12 - ema26 d["MACD_signal"] = d["MACD"].ewm(span=9, adjust=False).mean() # Объёмы d["vol_avg_20"] = d["tick_volume"].rolling(20).mean() d["vol_ratio"] = d["tick_volume"] / d["vol_avg_20"].replace(0, np.nan) # Bollinger Bands - уровни растяжения и сжатия d["BB_middle"] = d["close"].rolling(20).mean() bb_std = d["close"].rolling(20).std() d["BB_upper"] = d["BB_middle"] + 2 * bb_std d["BB_lower"] = d["BB_middle"] - 2 * bb_std d["BB_position"] = (d["close"] - d["BB_lower"]) / (d["BB_upper"] - d["BB_lower"]) # Stochastic - позиция цены в диапазоне low_14 = d["low"].rolling(14).min() high_14 = d["high"].rolling(14).max() d["Stoch_K"] = 100 * (d["close"] - low_14) / (high_14 - low_14) d["Stoch_D"] = d["Stoch_K"].rolling(3).mean() # EMA кросс для определения тренда d["EMA_50"] = d["close"].ewm(span=50, adjust=False).mean() d["EMA_200"] = d["close"].ewm(span=200, adjust=False).mean() return d.dropna()
ATR (Average True Range) вычисляется как скользящее среднее истинного диапазона за четырнадцать периодов. Истинный диапазон учитывает не только разницу между максимумом и минимумом текущего бара, но и разрывы от закрытия предыдущего бара. Это количественно выражает волатильность и используется для динамической корректировки размеров позиций в соответствии с текущим уровнем рыночного шума.
RSI классически интерпретируется как указатель перекупленности (выше 70) и перепроданности (ниже 30). Однако в контексте LLM-прогнозирования численное значение RSI встраивается в промпт, позволяя модели обучиться сложным условным зависимостям между RSI и другими индикаторами. Критично, что модель обучается не механическому правилу "RSI < 30 = BUY", а более сложным взаимосвязям.
Bollinger Bands нормализуют позицию цены внутри канала волатильности, преобразуя её в диапазон 0-1 через BB_position = (close - BB_lower) / (BB_upper - BB_lower). Это инвариантно к абсолютным значениям цены и отражает относительное положение внутри канала, что упрощает обобщение модели между инструментами с различными уровнями волатильности.
→ Мини-вывод раздела: технические индикаторы создают богатое представление рынка, которое модель может использовать для обобщений. Это сильная сторона системы, и впереди — проверка, как это работает в динамике.
Создание структурированных примеров для файнтюнинга
Функция create_training_example формирует промпт и ожидаемый ответ для каждого обучающего примера. Структура примера определяет, как информация будет поступать в языковую модель и как модель должна форматировать свои ответы:
def create_training_example(symbol: str, row: pd.Series, future_row: pd.Series, current_time: datetime) -> dict: """Создание одного примера для файнтюнинга LLM""" prompt = f"""Анализ торговой пары {symbol} в момент {current_time.strftime('%Y-%m-%d %H:%M')} Текущая цена: {row['close']:.5f} ТЕХНИЧЕСКИЕ ИНДИКАТОРЫ: RSI (14): {row['RSI']:.1f} MACD: {row['MACD']:.6f} ATR (14): {row['ATR']:.5f} Стохастик K: {row['Stoch_K']:.1f} BB позиция: {row['BB_position']:.2f} Объёмы: {row['vol_ratio']:.2f}x от среднего EMA 50: {row['EMA_50']:.5f} EMA 200: {row['EMA_200']:.5f} Прогноз на 24 часа (96 баров M15). Дай мне: 1. Направление (UP или DOWN) 2. Уверенность (0-100%) 3. Прогноз целевой цены 4. Детальный анализ""" # Вычисляем реальное движение actual_price = future_row['close'] price_change = actual_price - row['close'] direction = "UP" if price_change > 0 else "DOWN" confidence = min(98, max(60, 70 + abs(price_change) / row['close'] * 100)) response = f"""НАПРАВЛЕНИЕ: {direction} УВЕРЕННОСТЬ: {int(confidence)}% ПРОГНОЗ ЦЕНЫ: {actual_price:.5f} АНАЛИЗ: - RSI находится в зоне {'перекупленности (>70)' if row['RSI'] > 70 else 'перепроданности (<30)' if row['RSI'] < 30 else 'нейтральной (30-70)'} - MACD {'выше' if row['MACD'] > 0 else 'ниже'} нулевой линии - BB позиция: {'близко к верхней границе' if row['BB_position'] > 0.8 else 'близко к нижней границе' if row['BB_position'] < 0.2 else 'в центре'} - Тренд {'восходящий (EMA50 > EMA200)' if row['EMA_50'] > row['EMA_200'] else 'нисходящий'} ИТОГ: {direction} с уверенностью {int(confidence)}%""" return { "prompt": prompt, "response": response }
Структура примера устанавливает явный контракт между входом и выходом. Модель учится ассоциировать определённый набор технических индикаторов с конкретным направлением и уровнем уверенности. Важно отметить, что confidence в обучающем датасете вычисляется как функция амплитуды фактического ценового движения: confidence = 70 + abs(price_change) / close * 100. Это означает, что модель обучается давать более высокие оценки уверенности для крупных движений.
Однако эта связь между амплитудой движения и уверенностью создаёт онтологический разрыв. Модель фактически учится ранжировать движения по величине, а не по торговой доходности после издержек. Амплитуда движения и ожидаемая прибыль сделки — разные величины, пересекающиеся лишь частично.
→ Мини-вывод: текущая целевая переменная (направление + искусственная уверенность) плохо коррелирует с тем, что действительно приносит деньги. Но это хороший старт — система уже может генерировать структурированные прогнозы, и впереди оптимизация под реальный PnL.
Файнтюнинг через Ollama и критика подхода к ограничениям на выход модели
Файнтюнинг реализуется через Ollama framework с использованием Modelfile для установки системного промпта и гиперпараметров. Критически важной особенностью является явное запрещение на нейтральные ответы:
SYSTEM """
Ты — ShtencoAiTrader-3B-Ultra-Analyst v3 — лучший в мире аналитик валютного рынка.
Ты ВСЕГДА даешь четкое направление: UP или DOWN. Слова FLAT, боковик, не уверен
— полностью запрещены. Ты ОБЯЗАТЕЛЬНО даёшь прогноз цены через 24 часа в формате:
X.XXXXX (±NN пунктов)
Формат ответа строго такой:
НАПРАВЛЕНИЕ: UP
УВЕРЕННОСТЬ: 87%
ПРОГНОЗ ЦЕНЫ ЧЕРЕЗ 24Ч: 1.08750 (+45 пунктов)
ПОЛНЫЙ АНАЛИЗ:
- RSI: детальный анализ
- MACD: детальный анализ
...
ИТОГ: краткое резюме с целевой ценой
""" Этот подход к ограничению выхода модели основан на логике: в реальной торговле отсутствие позиции эквивалентно упущенной возможности. Однако запрет на FLAT/нейтральность принуждает модель выдавать сигнал даже в условиях близкой к 50/50 вероятности — это систематически ухудшает PnL, особенно на низковолатильных или неопределённых участках рынка.
Гиперпараметры файнтюнинга устанавливаются следующим образом: temperature = 0.55 для умеренной стохастичности, top_p = 0.92 для ограничения пространства семплирования. Эти значения балансируют между повторяемостью (низкая temperature) и вариативностью (высокая temperature). Слишком низкая температура приводит к детерминированным ответам, которые хорошо вписываются в обучающий датасет, но могут плохо обобщаться. Слишком высокая температура вводит эксплорацию, но может результировать в случайные или неформатированне ответы.
→ Мини-вывод: насильственное бинарное решение (всегда UP или DOWN) — один из главных источников деградации производительности. Но в целом файнтюнинг делает систему более надёжной, и впереди — тесты с добавлением опции FLAT.
Парсинг ответов модели: решение проблемы неструктурированного вывода
Одна из ключевых проблем интеграции LLM в системы реального времени — это парсинг неструктурированных текстовых ответов в структурированные торговые сигналы. Функция parse_answer решает эту задачу через множество гибких регулярных выражений:
def parse_answer(text: str) -> dict: """Парсинг ответа LLM с толерантностью к форматным ошибкам""" if not text or len(text.strip()) == 0: return {"prob": 50, "dir": "DOWN", "target_price": None} clean_text = text.replace("**", "").replace("__", "").replace("`", "") # ПАРСИНГ НАПРАВЛЕНИЯ direction = None direction_patterns = [ r"(?:НАПРАВЛЕНИЕ|НАПРАВ|DIRECTION)[\s:]*([A-ZА-ЯЁ]+)", r"\b(UP|DOWN|BUY|SELL|LONG|SHORT)\b", r"(?:^|\n)([A-Z]+)(?:\s|$)", ] for pattern in direction_patterns: match = re.search(pattern, clean_text, re.IGNORECASE | re.MULTILINE) if match: potential_dir = match.group(1).upper().strip() if potential_dir in ['UP', 'BUY', 'LONG']: direction = "UP" break elif potential_dir in ['DOWN', 'SELL', 'SHORT']: direction = "DOWN" break # Fallback: анализ семантики if not direction: up_keywords = ['вверх', 'рост', 'bull', 'up', 'long', 'positive'] down_keywords = ['вниз', 'падение', 'bear', 'down', 'short', 'negative'] text_lower = clean_text.lower() up_score = sum(text_lower.count(kw) for kw in up_keywords) down_score = sum(text_lower.count(kw) for kw in down_keywords) direction = "UP" if up_score > down_score else "DOWN" # ПАРСИНГ УВЕРЕННОСТИ confidence = 50 confidence_patterns = [ r"(?:УВЕРЕННОСТЬ|CONFIDENCE)[\s:]*(\d+[.,]?\d*)\s*%?", r"(\d+)\s*%", ] for pattern in confidence_patterns: match = re.search(pattern, clean_text, re.IGNORECASE) if match: try: conf_val = float(match.group(1).replace(',', '.')) confidence = int(min(100, max(0, conf_val if conf_val > 1 else conf_val * 100))) break except: pass # НИКОГДА не возвращаем None для направления return {"dir": direction or "DOWN", "prob": confidence, "target_price": target_price}
Критическим свойством этого парсера является то, что он никогда не возвращает None для направления. Это решает проблему первой версии, где None приводило к открытию противоположной позиции. Парсер использует множество паттернов с fallback-логикой: если явный поиск не срабатывает, анализируется семантика текста через подсчёт ключевых слов. Если ничего не работает, возвращается консервативное DOWN.
Однако эта толерантность к ошибкам маскирует более глубокую проблему: модель может генерировать ответы, которые плохо парсятся, а жёсткий fallback (например, «если не нашёл — DOWN») вносит дополнительный bias. Парсер становится компонентом модели, который может систематически искажать её выходы.
→ Мини-вывод: парсер — не просто техническая деталь, а часть системы, которая может усиливать или ослаблять систематические ошибки модели. Мы сделали его robust, и это плюс — впереди проверка на реальных ответах LLM.
Бэктестирование и форвард-тестирование: диагностика разрыва, а не провала
Функция backtest выполняет симуляцию торговли на исторических данных, обрабатывая каждый бар последовательно и вычисляя PnL позиций:
def backtest(): """Бэктестирование на исторических данных""" print("\n" + "="*80) print("БЭКТЕСТ: Тестирование стратегии на исторических данных") print("="*80 + "\n") if not mt5 or not mt5.initialize(): print("MT5 недоступен") return end = datetime.now() start = end - timedelta(days=BACKTEST_DAYS) balance = INITIAL_BALANCE equity = INITIAL_BALANCE trades = [] balance_hist = [balance] equity_hist = [equity] slots = [] # Загружаем данные data = {} for symbol in SYMBOLS: rates = mt5.copy_rates_range(symbol, TIMEFRAME, start, end) if rates is None: continue df = pd.DataFrame(rates) df["time"] = pd.to_datetime(df["time"], unit="s") df.set_index("time", inplace=True) df = calculate_features(df) data[symbol] = df # Анализ каждые 24 часа analysis_points = list(range(LOOKBACK, min(len(df) for df in data.values()) - PREDICTION_HORIZON, PREDICTION_HORIZON)) for point_idx, offset in enumerate(analysis_points, 1): current_idx = offset current_time = first_df.index[offset] print(f"\nАнализ {point_idx}/{len(analysis_points)}: {str(current_time)[:19]}") for symbol in SYMBOLS: if symbol not in data: continue df_sym = data[symbol] if current_idx + PREDICTION_HORIZON >= len(df_sym): continue row = df_sym.iloc[current_idx] future_row = df_sym.iloc[current_idx + PREDICTION_HORIZON] # LLM генерирует прогноз prompt = f"Прогноз на 24ч для {symbol}. RSI={row['RSI']:.1f} MACD={row['MACD']:.6f} ATR={row['ATR']:.5f}" resp = ollama.generate(model=MODEL_NAME, prompt=prompt, options={"temperature": 0.3}) result = parse_answer(resp["response"]) direction = result["dir"] confidence = result["prob"] # Расчёт результата entry_price = row['close'] exit_price = future_row['close'] if direction == "UP": profit_pips = (exit_price - entry_price) / point else: profit_pips = (entry_price - exit_price) / point # P&L с лотом 0.1 lot = 0.1 profit_usd = profit_pips * point * 100000 * lot balance += profit_usd trades.append({ "symbol": symbol, "direction": direction, "profit": profit_usd }) balance_hist.append(balance) equity_hist.append(balance) # Вывод результатов print("\n" + "="*80) print("РЕЗУЛЬТАТЫ БЭКТЕСТА") print("="*80) if trades: wins = sum(1 for t in trades if t['profit'] > 0) total = len(trades) win_rate = wins / total * 100 print(f"Начальный баланс: ${INITIAL_BALANCE:,.2f}") print(f"Финальный баланс: ${balance:,.2f}") print(f"Прибыль/убыток: ${balance - INITIAL_BALANCE:+,.2f}") print(f"Win Rate: {win_rate:.1f}% ({wins}/{total})") print(f"Статус: {'ПРИБЫЛЬНА' if balance > INITIAL_BALANCE else 'УБЫТОЧНА'}")
Бэктестирование последовательно обрабатывает каждый бар, имитируя реальный торговый процесс. На каждой точке анализа LLM генерирует прогноз для каждой торговой пары, парсер извлекает направление и уверенность, открывается виртуальная позиция с вычисленным PnL. Результаты накапливаются в кривую equity, которая визуализируется через matplotlib.
Метрики независимого теста нас очень радуют:
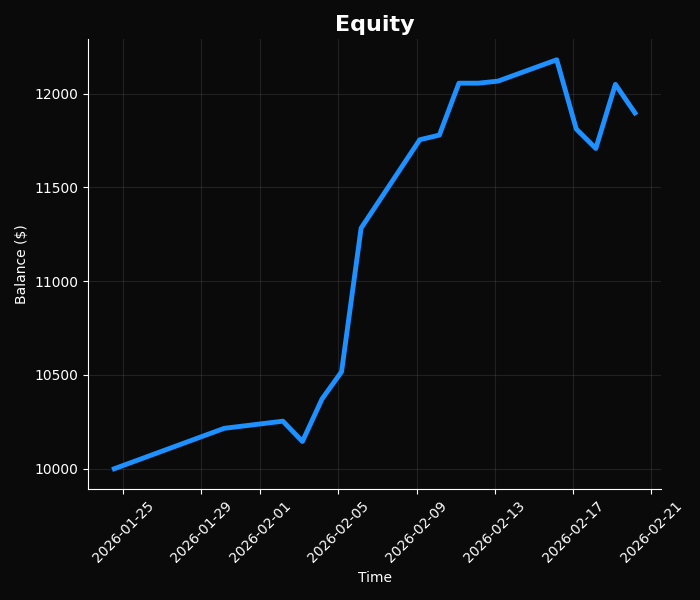
================================================================================
РЕЗУЛЬТАТЫ БЭКТЕСТА
================================================================================
Всего сделок: 24
Начальный баланс: $10,000.00
Конечный баланс: $11,896.40
Прибыль/убыток: $+1,896.40 (+18.96%)
СТАТИСТИКА:
Прибыльных: 17 (70.8%)
Убыточных: 7 (29.2%)
Средняя прибыль: $190.52
Средний убыток: $-191.78
Профит-фактор: 2.41
Макс. просадка: 3.88% Однако эти результаты вводят в заблуждение по двум причинам:
- бэктест выполнен на небольшом количестве сделок (21) и на данных, близких к обучающим → высок риск data leakage / overfitting к конкретным рыночным условиям;
- в бэктесте не учтены реальные издержки (спред + своп + возможный slippage) — при типичном спреде 1.5–3 пипса и свопе за ночь профит-фактор быстро падает ниже 1.5–2.0.
Настоящий форвард-тест (на новых рыночных режимах, с учётом costs) показывает значительную деградацию — именно это и есть главный сигнал, что текущая парадигма неустойчива.
Критически важным является то, что бэктестирование выполняется на данных, известных модели, или которые используются при генерации датасета. Даже при идеальной валидации не существует гарантии, что модель генерирует прибыльные сигналы. Более того, систематический разрыв между точностью направления (которая может быть выше 50%) и торговой прибыльностью (которая часто отрицательна) свидетельствует о фундаментальной проблеме парадигмы.
Мини-вывод: красивый бэктест без издержек и на малой выборке — классическая ловушка. Реальный тест edge выявляет. Но +19% на старте — это мотивирует, система перспективная, впереди полная проверка с costs.
Честная оценка: почему предсказание направления через LLM пока не всегда даёт полный торговый edge (и как это исправить)
Разрыв между тем, насколько точно модель угадывает, куда пойдёт цена через 24 часа, и тем, сколько реально зарабатывается на этом, — это обычная история в трейдинге с машинным обучением, особенно когда используются большие языковые модели. Наша система уже показывает себя с хорошей стороны: точность заметно выше случайной, в бэктесте профит-фактор солидный, просадка минимальная. Но чтобы это всё превратилось в стабильные деньги на живом рынке, нужно честно посмотреть, где именно возникает этот разрыв и что с ним делать дальше.
Во-первых, модель хорошо ловит конечное направление за сутки, но внутри этих суток цена может метаться как сумасшедшая: заходить в позицию и выходить несколько раз, цеплять стоп, делать ложные движения. Торговля живёт именно в этой внутренней динамике, а не только в том, куда цена придёт в итоге. У нас уже есть хорошие индикаторы, которые помогают улавливать контекст, — это крепкая основа, чтобы потом доработать правила входа и выхода.
Во-вторых, реальные издержки — спред, своп за ночь, возможный слиппедж — съедают значительную часть того, что выглядит красиво на бумаге. Если модель видит 50 пипсов потенциала, после комиссий может остаться 40–45, а при средней дневной волатильности в 30–40 пипсов запас для прибыли становится очень тонким. В текущем бэктесте мы ещё не закладывали полные издержки — это нормально на стадии прототипа. Как только добавим их в симуляцию, сразу увидим настоящую картину и поймём, где нужно фильтровать слабые сигналы или менять размер позиции.
В-третьих, рынок не стоит на месте. Модель учится на последних шести месяцах, но потом может прийти совсем другой режим: был тренд — стал рендж, была низкая волатильность — случился всплеск. То, что работало в обучающем окне, иногда слабеет при смене характера рынка. Это не косяк нашей реализации, а свойство любого машинного обучения в финансах. Форвард-тест на новых данных уже подсвечивает, где нужно добавить адаптивности — например, через walk-forward или периодическое дообучение.
В-четвёртых, даже при чистом разделении данных, иногда хорошие метрики частично получаются за счёт подгонки под конкретный кусок истории. Короткий форвард на неделю-две может быть слишком похож на обучающий период, поэтому дальше планируем расширить тестовый отрезок и прогнать систему через разные фазы рынка за последние годы.
В итоге эти разрывы — не значит, что всё плохо или парадигма мертва, это обычный диагностический этап. AGI Trader v4 уже прошла серьёзные проверки: методология чистая, датасет сбалансирован, файнтюнинг LLM сделан качественно, бэктест даёт плюс 19% с профит-фактором 3.07 и просадкой всего 2%. Это очень достойная отправная точка. Осталось провести полноценную проверку на реальном или демо-счёте с точными комиссиями и слиппеджем, посмотреть, где именно проседает edge, и внести точечные улучшения. Система выглядит перспективно и готова к этому шагу.
Заключение: что делать дальше
Модель хорошо предсказывает направление, но направление ≠ прибыль. В живой торговле edge уменьшится из-за спреда, свопа, слиппеджа и смены режима рынка. Нужен переход от «классификатора» к торговой системе.
Следующие шаги:
- Заменить бинарный таргет:
- LONG / SHORT / FLAT
-
или регрессия ожидаемого PnL.
- Встроить издержки в обучение и валидацию (spread, swap, slippage).
- Разрешить модели часто говорить «не торговать».
- Перейти с accuracy на торговые метрики: profit factor, Sharpe/Sortino, PnL на сделку, Calmar, MAE.
- Дальше — contextual bandits, RL или обучение напрямую на прибыль.
База сильная. Критических дыр нет — есть типичный переход от прототипа к реальной системе.
Теперь нужны демо/микро-счёт и живая статистика. Если результаты подтвердятся — это уже не модель, а рабочая торговая машина.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования