
Возможности Мастера MQL5, которые вам нужно знать (Часть 58): Обучение с подкреплением (DDPG) совместно с паттернами скользящей средней и стохастика
Введение
В нашей предыдущей статье мы протестировали 10 сигнальных паттернов, полученных с помощью двух наших индикаторов (скользящая средняя и стохастический осциллятор). Семь из них показали устойчивое движение вперед в течение годичного тестового периода. Однако из них только два сделали это, открывая как длинные, так и короткие позиции. Это было связано с ограниченным временем, отведенным на тестирование, поэтому мы настоятельно рекомендуем читателям провести тесты на большем объеме истории, прежде чем двигаться дальше.
В данном случае мы придерживаемся тезиса, согласно которому три основных режима машинного обучения могут использоваться совместно, каждый в своей "фазе". Напомним, что эти режимы включают в себя обучение с учителем (SL), обучение с подкреплением (RL) и обучение на основе вывода (IL). В предыдущей статье мы подробно рассмотрели SL, где комбинированные паттерны скользящего среднего и стохастического осциллятора были нормализованы к бинарному вектору признаков. Затем эти данные были переданы в простую нейронную сеть, которую мы обучили на валютной паре EURUSD на 2023 год, а затем провели форвардные тесты на 2024 год.
Поскольку наш подход основан на тезисе о том, что обучение с подкреплением можно использовать для обучения моделей в процессе их применения, мы хотим продемонстрировать это в данной статье, используя наши предыдущие результаты и сеть, полученные с помощью обучения с учителем. Мы предполагаем, что RL представляет собой форму обратного распространения ошибки, которая при использовании тщательно корректирует наши решения о покупке и продаже, чтобы они не основывались исключительно на прогнозируемых изменениях цены, как это было в модели SL.
Как мы уже видели в предыдущих статьях по обучению с подкреплением, эта «тонкая настройка» объединяет исследование и использование полученных знаний. Таким образом, наша сеть политик, пройдя обучение в условиях реального рынка, определит, в каких состояниях следует совершать покупки или продажи. В некоторых случаях бычий тренд не обязательно означает возможность для покупки, и наоборот. Это означает, что наша модель обучения с подкреплением выступает в качестве дополнительного фильтра для решений, принимаемых моделью обучения с учителем. В нашей модели SL в качестве состояний использовались одномерные непрерывные значения, и это будет очень похоже на пространство действий, которое мы будем использовать.
DDPG
Мы уже рассмотрели ряд различных алгоритмов обучения с подкреплением, а в этой статье мы рассмотрим алгоритм Deep Deterministic Policy Gradient (DDPG). Этот алгоритм чем-то похож на DQN, который мы рассматривали в предыдущей статье. Он служит для прогнозирования в непрерывных пространствах действий. Напомним, что большинство алгоритмов, которые мы недавно рассматривали, были классификаторами, которые выдавали вероятностные распределения того, следует ли предпринять следующие действия: купить, продать или держать (например).
Этот алгоритм не классификатор, а регрессор. Мы определяем пространство действий как значение с плавающей запятой в диапазоне от 0,0 до 1,0. Этот подход можно использовать для калибровки гораздо большего количества параметров, чем просто:
- покупка (все, что выше 0,5);
- продажа (все, что ниже 0,5);
- или удержание (значения, близкие к 0,5)
Этого можно достичь путем введения типов отложенных ордеров или даже определения размера позиции. Изучение этих мер остается на усмотрение читателя, поскольку мы будем придерживаться базового варианта, где 0,5 служит ключевым пороговым значением.
В принципе, DDPG использует нейронные сети для аппроксимации Q-значений (вознаграждений за действия) и напрямую оптимизирует политику (сеть, которая выбирает следующее наилучшее действие при предъявлении состояний окружающей среды), вместо того чтобы просто оценивать Q-значения. В отличие от DQN, который также может использоваться для дискретных/классификационных действий, таких как "влево" или "вправо", DDPG предназначен исключительно для пространств непрерывных действий. (Вспомните углы поворота руля или крутящие моменты двигателей, например, при обучении роботов). Как он работает?
В основном используются две нейронные сети.
- Один из них — это сеть актеров (actor network), задача которой — определить наилучшее действие для заданного состояния среды.
- Другой тип — это сеть критиков (critic network), цель которой — оценить, насколько хорошо выбранное актером действие путем оценки потенциального вознаграждения, которое можно получить за выполнение этого действия.
Эта оценка также называется Q-значением. Также важным элементом в DDPG является буфер воспроизведения опыта. Это позволяет хранить прошлый опыт (обобщенный термин для обозначения состояний, действий, вознаграждений и будущих состояний) в буфере. Случайные выборки из этого буфера используются для обучения нейронных сетей и уменьшения корреляции между обновлениями.
Помимо двух упомянутых выше сетей, задействованы также их эквивалентные копии, называемые "целевыми объектами". Веса этих отдельных копий сетей актеров и критиков обновляются с меньшей скоростью, и это, как считается, помогает стабилизировать процесс обучения, обеспечивая согласованные целевые значения. Наконец, исследование (ключевая особенность обучения с подкреплением) в DDPG получает дальнейшее развитие за счет введения шумового компонента в действия с помощью алгоритмов, наиболее распространенным из которых является шум Орнштейна-Уленбека.
Обучение DDPG, по сути, охватывает 3 аспекта. Во-первых, оно включает в себя улучшение сети актеров, где сеть критиков направляет сеть актеров в определении того, какое действие является хорошим/плохим, чтобы сеть актеров лучше корректировала свой вес при выборе действий, которые максимизируют вознаграждение. Во-вторых, улучшение сети критиков, которая учится лучше оценивать вознаграждения/Q-значения с помощью обновлений Беллмана, как показано в уравнении ниже:

где:
-
Q(s,a) - прогнозируемое значение Q (оценка критика) для выполнения действия a в состоянии s.
-
r - немедленное вознаграждение, полученное после совершения действия a в состоянии s.
-
γ - коэффициент дисконтирования (0≤γ<1), определяющий, насколько высоко ценятся будущие вознаграждения (ближе к 0 = краткосрочная ориентация, ближе к 1 = долгосрочная ориентация.
-
s′ - следующее состояние, наблюдаемое после выполнения действия a в состоянии s.
-
Qtarget(s′,⋅) - оценка Q-значения для следующего состояния s′, полученная целевой Q-сетью (используется для стабилизации обучения).
-
Actortarget(s′) - рекомендуемое действие целевого актера для следующего состояния s′ (детерминированная политика).
Наконец, для моделей "актер-цель" и "критик-цель" выполняются плавные обновления, которые соответствуют основным сетям в соответствии со следующим уравнением:
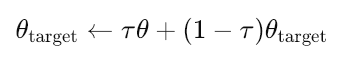
где:
- θtarget - параметры (веса) целевой сети (либо актеров, либо критиков).
- θ - параметры основной (онлайн-) сети (актеров или критиков).
- τ - скорость мягкого обновления (0≪τ≪1, например, 0.001). Управляет скоростью обновления целевых сетей.
- Малое значение τ означает, что целевые сети изменяются очень медленно (более стабильное обучение).
- Большое значение τ означает, что целевые сети обновляются быстрее (менее стабильны, но могут быстрее адаптироваться).
Почему DDPG? Этот метод популярен, потому что он хорошо работает в многомерных непрерывных пространствах действий и сочетает в себе стабильность Q-обучения с гибкостью градиентов политики. Как показано в приведенном выше примере с непрерывным пространством действий в робототехнике, он очень популярен в робототехнике, управлении на основе физических принципов и других подобных сложных задачах. Однако это не означает, что мы не можем использовать его в анализе финансовых временных рядов. Именно этим мы и займемся.
Мы реализуем большую часть нашего кода на Python 3.10 из-за преимуществ, которые он предоставляет при обучении очень глубоких нейронных сетей. Но в этой области время от времени узнаешь что-то новое. В частности, я узнал, что Python действительно способен выполнять такие быстрые вычисления при обучении нейронных сетей (PyTorch и TensorFlow) благодаря якорному коду и классам на C/C++ и CUDA. Сейчас MQL5 очень похож на C, и поддержка OpenCL существует уже некоторое время. Мне кажется, нам не хватает библиотеки с базовыми функциями умножения матриц (частично в OpenCL), чтобы добиться аналогичной производительности в MQL5. Возможно, стоит это изучить.
Буфер воспроизведения
Буфер воспроизведения является очень важным компонентом в DDPG и других алгоритмах обучения с подкреплением вне политики. В основном он используется для разрыва временных корреляций между последовательными выборками, обеспечения повторного использования опыта для повышения эффективности обучения, предоставления разнообразного набора переходов для стабильного обучения и хранения прошлого опыта (состояние, действие, вознаграждение, следующее состояние, готовые кортежи) для использования в процессе обучения/обновления весов сети.
Его основная реализация начинается с функции инициализации:
def __init__(self, capacity): self.buffer = deque(maxlen=capacity)
Мы используем collections.deque с фиксированной максимальной емкостью и автоматически удаляем старые данные при заполнении, используя принцип «первым пришел — первым вышел» (First-In-First-Out). Это очень простое и эффективное с точки зрения использования памяти решение. Далее следует операция добавления данных, в ходе которой буфер хранит полные кортежи переходов и обрабатывает как успешные, так и завершающие переходы (используя флаг "готово" - done). Это обеспечивает минимальные расходы при добавлении новых функций.
def push(self, state, action, reward, next_state, done): self.buffer.append((state, action, reward, next_state, done))
Используемый механизм выборки — это случайная равномерная выборка, которая очень важна для разрушения корреляций. Его эффективность заключается в использовании пакетной обработки с помощью zip(*batch), что помогает разделить компоненты среды. Он возвращает все необходимые компоненты для обновления Q-обучения.
def sample(self, batch_size): batch = random.sample(self.buffer, batch_size) states, actions, rewards, next_states, dones = zip(*batch)
Далее в классе буфера воспроизведения следует преобразование тензоров и обработка устройств для каждого из компонентов среды. Как уже было показано выше, это состояния, действия, награды, следующие состояния и завершенные действия (done). Процесс преобразования очень надежен. Он принимает на вход как массивы NumPy, так и тензоры PyTorch. Это гарантирует, что тензоры (которые можно рассматривать как массивы с прикрепленной информацией о градиенте) будут отделены от вычислительных графов.
Мы передаем данные на центральный процессор (CPU), чтобы избежать конфликтов между устройствами. Также выполняем явное преобразование в тензор типа Float (float-32), что является распространенным предварительным условием для нейронных сетей. Этот тип данных, меньший по размеру, чем тип double, часто используемый в MQL5, значительно эффективнее с точки зрения вычислительных ресурсов. Наконец, благодаря PyTorch (в отличие от TensorFlow) мы можем выбрать конкретное вычислительное устройство, например, графический процессор (GPU), если он доступен.
states = torch.FloatTensor( np.array([s.detach().cpu().numpy() if torch.is_tensor(s) else s for s in states]) ).to(device)
Наш класс буфера воспроизведения хорошо работает с DDPG, поскольку, во-первых, он облегчает обучение вне политики, так как DDPG требует буфера воспроизведения для обучения на исторических данных. В DDPG непрерывные пространства действий хорошо обрабатываются с помощью преобразования в тензоры с плавающей запятой. Это обеспечивает DDPG некоторую стабильность за счет случайной выборки, которая помогает предотвратить коррелированные обновления, способные дестабилизировать обучение. Это также обеспечивает некоторую гибкость благодаря возможности работы как с входными данными NumPy, так и с данными torch, что является распространенными подходами в обучении с подкреплением.
Возможные улучшения включают в себя: приоритетные буферы воспроизведения опыта для обработки важных переходов; использование многошаговых возвратов или n-шагового обучения; разделение/классификацию различных типов опыта; и более эффективные преобразования тензоров, позволяющие избежать промежуточного использования NumPy.
В целом, однако, наш класс буфера воспроизведения является надежным благодаря использованию проверки типов с помощью torch.is_tensor(), обработке устройств для обеспечения совместимости с CPU/GPU и четкому разделению компонентов среды. Производительность также не снижается, поскольку deque предлагает операции добавления и удаления О(1); используется пакетная обработка для минимизации расходов; и реализована случайная выборка, которая эффективна для буферов среднего размера. Кроме того, код легко поддерживать, поскольку он имеет четкую и лаконичную реализацию; его легко расширять или модифицировать; и он обеспечивает хорошую типосогласованность в выходных данных.
Основные ограничения и соображения могут быть связаны с использованием памяти. Для хранения полных переходов в высокоуровневых переходных состояниях объем памяти может быть очень большим. Кроме того, фиксированную мощность, возможно, потребуется скорректировать для различных условий эксплуатации. Еще одно ограничение связано с эффективностью отбора проб. При равномерной выборке важные события не получают приоритета, поскольку всем им придается одинаковый вес. При отборе проб также не обрабатывается граница эпизода.
Возможными альтернативами, позволяющими решить некоторые из этих проблем, могут быть использование дискового хранилища для очень больших буферов; хранение сжатых представлений в виде изображений; а также добавление поддержки хранения дополнительной информации, такой как логи. Подобные изменения могли бы заложить прочную основу для DDPG, позволяя расширять его функциональность в соответствии с конкретными потребностями приложений, сохраняя при этом его основные возможности.
Сети критиков и актеров
Обе эти сети имеют схожую структуру многослойного перцептрона, однако, как и следовало ожидать в обучении с подкреплением, в DDPG они выполняют разные функции. Сеть критиков, также называемая Q-функцией, оценивает значение пар "состояние-действие" (Q-значения или вознаграждения), в то время как сеть актеров, также называемая сетью политики, определяет оптимальное действие для данного состояния.
Инициализация и структура слоев сети критиков имеют следующий вид:
def __init__(self, state_dim, action_dim, hidden_dim): super(Critic, self).__init__() self.fc1 = nn.Linear(state_dim + action_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1)
Ключевые моменты здесь заключаются в следующем: в отличие от функций ценности в других методах, эта сеть принимает на вход как состояния, так и действия (как мы видели в предыдущих алгоритмах обучения с подкреплением); мы реализуем эту сеть с тремя полносвязными слоями со скрытыми нейронами в первых двух слоях; последний выходной слой выдает только одно скалярное Q-значение; и архитектура предназначена для оценки Q(s,a) для непрерывных пространств действий.
Механика прямого прохода (forward pass mechanics) следующая:
def forward(self, state, action): x = torch.cat([state, action], dim=1) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) q_value = self.fc3(x)
В данной реализации критически важными компонентами являются torch.cat, необходимые для оценки ценности действий в DDPG. Перед обработкой он объединяет векторы входных данных состояния и действия. Параметр dim=1 обеспечивает корректное объединение данных для пакетной обработки. Ещё одним заслуживающим внимания фрагментом нашего кода могут быть функции активации. Функция активации ReLU используется для скрытых слоев, поскольку она помогает смягчить проблему затухания градиента. Активация на последнем слое не выполняется, поскольку значения Q могут быть любыми действительными числами.
Информационный поток происходит от пары "состояние-действие" к скрытым слоям и далее к оценке Q-значения. Это ядро функции Q-обучения. Сеть актеров также имеет следующую инициализацию и структуру:
def __init__(self, state_dim, action_dim, hidden_dim): super(Actor, self).__init__() self.fc1 = nn.Linear(state_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, action_dim) self.tanh = nn.Tanh()
Ключевые аспекты, заслуживающие внимания, заключаются в следующем: в качестве входных данных принимается только значение, зависящее от состояния, поскольку политика зависит от состояния. В наших целях она имеет аналогичную трехслойную структуру, как и описанная выше сеть критиков, но с другой обработкой выходных данных. Итоговый размер слоя соответствует размерности пространства действий. Функция активации tanh, используемая для выходного слоя, важна для ограниченных действий. Механика прямого прохода определяется следующим списком:
def forward(self, state):
x = self.relu(self.fc1(state))
x = self.relu(self.fc2(x))
action = self.tanh(self.fc3(x)) Это гораздо проще и понятнее, чем сеть критиков, где обработка состояния принимает на вход только состояние (в отличие от сети критика), а затем строит представление состояния через скрытые слои. Генерация действий обеспечивается активацией Tanh, которая ограничивает выходные значения диапазоном [-1, 1]. Это крайне важно для обеспечения непрерывного взаимодействия в рамках DDPG. Этот фиксированный диапазон можно масштабировать в соответствии с диапазоном действия окружающей среды, например, [0, 1] и т. д. Также следует отметить, что данная политика по своей сути является детерминированной. В результате выполнения действия выдается конкретное действие, а не распределение вероятностей по дискретному набору действий, как это часто бывает в стохастических методах управления политикой.
Специфические проектные решения DDPG, принятые для сети критиков, частично перекликаются с другими алгоритмами обучения с подкреплением, а именно: совместная обработка входных данных, поскольку состояние и действие объединены; наличие скалярного выхода, который хорошо работает в непрерывных пространствах действий; и отсутствие активации, сохраняющее полный диапазон оценок Q-значения. В проектировании сети актеров DDPG были приняты следующие решения: ограничение выходных данных за счет использования алгоритма Tanh, гарантирующего, что действия находятся в пределах обучаемого диапазона; детерминированный характер, поскольку требуется более конкретный вес действия, а не стохастическая политика; и соответствие пространству действий, при котором размер конечного слоя напрямую соответствует размерам действий в окружающей среде.
В нашем примере с DDPG используется одномерное пространство для действий. Пространство состояний также является одномерным, поскольку это результат работы сети контролируемого обучения, использованной в предыдущей статье. Общими архитектурными особенностями являются активации ReLU, которые часто выбирают для скрытых слоев в глубоком обучении с подкреплением. Мы поддерживаем неизменные размеры скрытых областей за счет единообразной размерности на протяжении всего процесса, а также используем структуру MLP, подходящую для низкоразмерных пространств состояний.
Сильные стороны реализации сетей PyTorch не являются особенно выраженными, однако к ним относятся: надежность в обработке размерностей и четкое определение размерностей входных/выходных данных; управление активациями с надлежащим разделением скрытых и выходных активаций; и поддержка пакетной обработки, поскольку все операции (в своих тензорах) поддерживают пакетную размерность. Кроме того, к факторам, повышающим производительность этих сетей, относятся эффективность ReLU, поскольку эта функция активации работает быстрее по сравнению с другими типами активации, простота линейного слоя (без каких-либо сверток или рекуррентных функций) и минимальное количество операций благодаря оптимизированным прямым проходам.
Возможные улучшения для критически важной сети включают: нормализацию слоев, которая может стабилизировать обучение; архитектуру с противодействием и значениями состояний; и множественные Q-выходы, как в TD3, для усеченного двойного Q-обучения. Для сети актеров улучшениями могли бы стать добавление шума для исследования (хотя DDPG использует внешний шум); пакетная нормализация для помощи в работе с различными масштабами состояний; и спектральная нормализация для более стабильного обучения.
В контексте DDPG, для интеграции этих двух элементов следует отметить, что роль сети критиков в процессе обучения заключается в предоставлении оценок Q-значений для обновлений политики, которые затем используются для вычисления целевых значений временной разницы для самой сети. Необходимо точно оценить входные данные, значения "состояние-действие", чтобы количественно определить, насколько нужно скорректировать политику (веса и смещения в сети участников). В процессе обучения роль актера заключается в предоставлении действий как для функционирования среды, так и для вычисления Q-значений, обновлении градиентного подъема на основе Q-значений критика и изучении плавных детерминированных стратегий для непрерывного управления.
Заключение
Перед тем как просматривать отчеты тестировщиков стратегий по 7 паттернам, которые мы смогли освоить на основе предыдущей статьи, нам следует изучить класс агентов DDPG и класс данных Environment. Однако мы рассмотрим их в следующей статье, поскольку эта и так получилась довольно объемной. Большая часть представленного здесь материала написана на Python с целью экспорта сетей ONNX для интеграции в MQL5 в качестве ресурса.
В настоящее время Python важен, потому что он более эффективен при обучении, чем чистый MQL5, однако могут существовать обходные пути с использованием OpenCL, которые мы могли бы рассмотреть в будущих статьях. Типичный код, который мы используем в сборке Мастера из сигнальных классов, также будет рассмотрен в следующей статье, поэтому к этой статье нет прикрепленных файлов.
| Имя | Описание |
|---|---|
| wz_58_ddpg.py | Скрипт реализации алгоритма DDPG с подкреплением на Python |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/17668
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования