Integration von MQL5 mit Datenverarbeitungspaketen (Teil 4): Umgang mit großen Daten

Einführung
Die Finanzmärkte entwickeln sich ständig weiter, und die Händler haben es nicht mehr nur mit Kurscharts und einfachen Indikatoren zu tun, sondern mit einer Flut von Daten aus allen Teilen der Welt. Im Zeitalter von Big Data geht es beim erfolgreichen Handel nicht nur um Strategie, sondern auch darum, wie effizient Sie Berge von Informationen durchforsten können, um verwertbare Erkenntnisse zu gewinnen. Dieser Artikel, der vierte in unserer Serie über die Integration von MQL5 mit Datenverarbeitungswerkzeugen, konzentriert sich darauf, Sie mit den Fähigkeiten auszustatten, große Datensätze nahtlos zu verarbeiten. Von Tickdaten in Echtzeit bis hin zu historischen Archiven, die sich über Jahrzehnte erstrecken - die Fähigkeit, Big Data zu bändigen, wird schnell zum Markenzeichen eines hochentwickelten Handelssystems.
Stellen Sie sich vor, Millionen von Datenpunkten zu analysieren, um subtile Markttrends aufzudecken oder externe Datensätze wie soziale Stimmungen oder wirtschaftliche Indikatoren in Ihre MQL5-Handelsumgebung einzubinden. Die Möglichkeiten sind endlos - aber nur, wenn Sie die richtigen Werkzeuge haben. In diesem Beitrag untersuchen wir, wie Sie MQL5 über seine eingebauten Funktionen hinaus erweitern können, indem Sie es mit fortschrittlichen Datenverarbeitungsbibliotheken und Big Data-Lösungen integrieren. Egal, ob Sie ein erfahrener Händler sind, der seinen Vorsprung ausbauen will, oder ein neugieriger Entwickler, der das Potenzial der Finanztechnologie erforscht - dieser Leitfaden verspricht, das Spiel zu verändern. Bleiben Sie dran und erfahren Sie, wie Sie überwältigende Daten in einen entscheidenden Vorteil verwandeln können.
Sammeln der historischen Daten
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTC H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Save the data to a CSV file filename = "BTC_H1.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Um historische Daten abzurufen, stellen wir zunächst mit der Funktion „mt5.initialize()“ eine Verbindung zum MetaTrader 5 Terminal her. Dies ist wichtig, da das Python-Paket direkt mit der laufenden MetaTrader 5-Plattform kommuniziert. Wir konfigurieren den Code, um den gewünschten Zeitraum für die Datenextraktion festzulegen, indem wir das Start- und Enddatum angeben. Die Objekte „datetime“ werden in der UTC-Zeitzone erstellt, um die Konsistenz zwischen verschiedenen Zeitzonen zu gewährleisten. Das Skript verwendet dann die Funktion „mt5.copy-rates-range()“, um stündliche historische Daten für das Symbol BTC/USD ab dem 6. August 2024 bis zum aktuellen Datum und zur aktuellen Uhrzeit abzufragen.
Trennen Sie die Verbindung zum Meta Trader 5 Terminal mit „mt5.shutdown()“, um weitere unnötige Verbindungen zu vermeiden. Die abgerufenen Daten werden zunächst in ihrem Rohformat angezeigt, um die erfolgreiche Datenextraktion zu bestätigen. Anschließend konvertieren wir diese Daten in einen Pandas Data Frame, um sie leichter bearbeiten und analysieren zu können. Darüber hinaus konvertiert der Code die Unix-Zeitstempel in ein lesbares Datetime-Format, sodass die Daten gut strukturiert und für die weitere Verarbeitung oder Analyse bereit sind.
filename = "XAUUSD_H1_2nd.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Da mein Betriebssystem Linux ist, muss ich die empfangenen Daten in einer Datei speichern. Wer jedoch mit Windows arbeitet, kann die Daten mit dem folgenden Skript abrufen:
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTCUSD H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Display data directly print("\nDisplay dataframe with data") print(rates_frame.head(10))
Und wenn Sie aus irgendeinem Grund keine historischen Daten erhalten können, können Sie diese mit den folgenden Schritten manuell auf Ihrer MetTrader5-Plattform abrufen. Starten Sie Ihre MetaTrader-Plattform und navigieren Sie oben in Ihrem MetaTrader 5-Panel zu > Extras und dann > Optionen und Sie gelangen zu den Charts-Optionen. Sie müssen dann die Anzahl der Balken in dem Chart auswählen, das Sie herunterladen möchten. Am besten wählen Sie die Option unbegrenzte Balken, da wir mit dem Datum arbeiten und nicht wissen, wie viele Balken in einem bestimmten Zeitraum vorhanden sind.
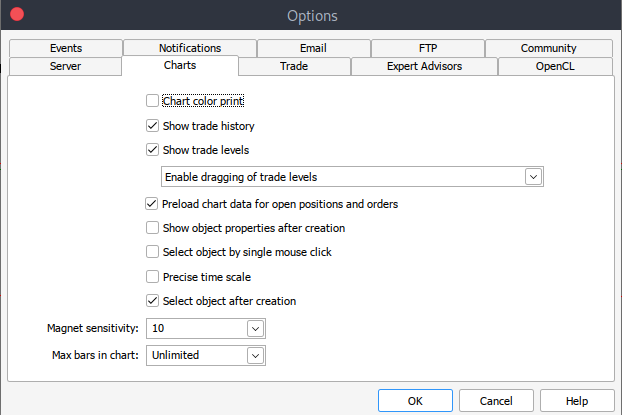
Danach müssen Sie nun die eigentlichen Daten herunterladen. Dazu müssen Sie zu > Ansicht und dann zu > Symbole navigieren, um auf die Registerkarte Spezifikationen zu gelangen. Navigieren Sie einfach zu > Balken oder Ticks, je nachdem, welche Art von Daten Sie herunterladen möchten. Fahren Sie fort und geben Sie das Anfangs- und Enddatum der historischen Daten ein, die Sie herunterladen möchten. Klicken Sie anschließend auf die Schaltfläche „Anfordern“, um die Daten herunterzuladen und im .csv-Format zu speichern.
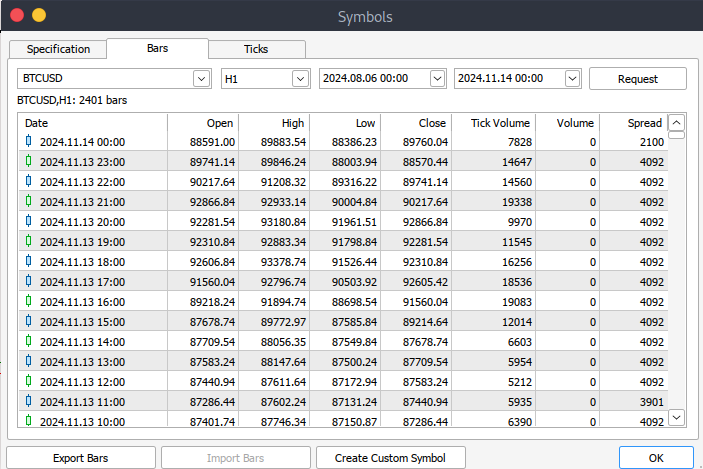
MetaTrader 5 Big Data Handhabung auf Jupyter Lab
import pandas as pd # Load the uploaded BTC 1H CSV file file_path = '/home/int_junkie/Documents/DataVisuals/BTCUSD_H1.csv' btc_data = pd.read_csv(file_path) # Display basic information about the dataset btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
Ausgabe:
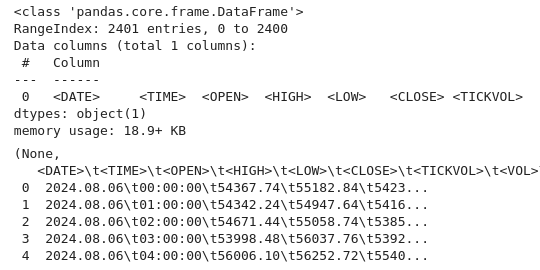
Anhand des obigen Codes können wir wie immer die Daten untersuchen und die Struktur des Datensatzes verstehen. Wir prüfen die Datentypen, die Form und die Vollständigkeit (mit info()). Wir erhalten auch den Inhalt und das Layout des Datensatzes (mit head()). Dies ist ein üblicher erster Schritt bei der explorativen Datenanalyse, um sicherzustellen, dass die Daten korrekt geladen werden und um sich mit ihrer Struktur vertraut zu machen.
# Reload the data with tab-separated values btc_data = pd.read_csv(file_path, delimiter='\t') # Display basic information and the first few rows after parsing btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
Ausgabe:
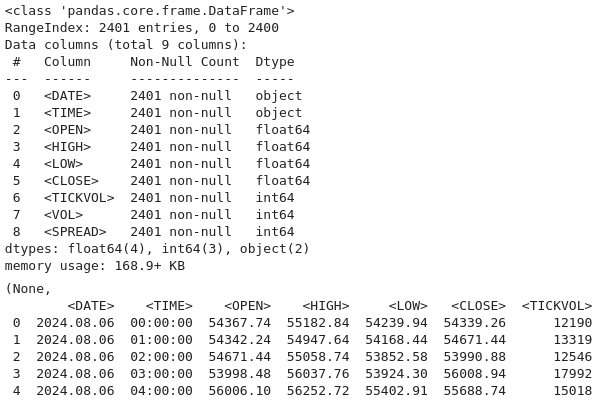
Jetzt verwenden wir diesen Code, um den Datensatz aus einer Datei neu zu laden, bei der angenommen wird, dass sie tabulatorgetrennte Werte (TSV) anstelle des standardmäßigen kommagetrennten Formats verwendet. Durch die Angabe von delimiter=“t“ in pd.read-csv() werden die Daten korrekt in Pandas „DataFrame“ zur weiteren Analyse geparst. Anschließend wird „btc-data-infor“ verwendet, um Metadaten über den Datensatz anzuzeigen, z. B. die Anzahl der Zeilen, Spalten, Datentypen und fehlende Werte.
# Combine <DATE> and <TIME> into a single datetime column and set it as the index btc_data['DATETIME'] = pd.to_datetime(btc_data['<DATE>'] + ' ' + btc_data['<TIME>']) btc_data.set_index('DATETIME', inplace=True) # Drop the original <DATE> and <TIME> columns as they're no longer needed btc_data.drop(columns=['<DATE>', '<TIME>'], inplace=True) # Display the first few rows after modifications btc_data.head()
Ausgabe:
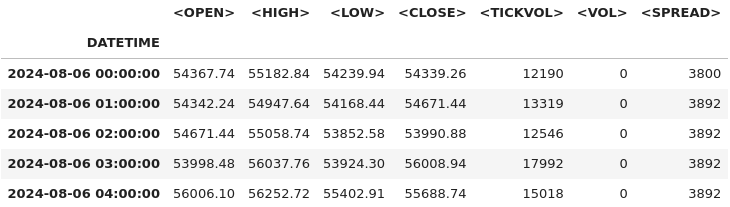
# Check for missing values and duplicates missing_values = btc_data.isnull().sum() duplicate_rows = btc_data.duplicated().sum() # Clean data (if needed) btc_data_cleaned = btc_data.drop_duplicates() # Results missing_values, duplicate_rows, btc_data_cleaned.shape
Ausgabe:
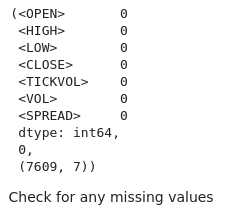
Aus der Ausgabe ist ersichtlich, dass in unserem Datensatz keine Werte fehlen.
# Check for missing values print("Missing values per column:\n", btc_data.isnull().sum()) # Check for duplicate rows print("Number of duplicate rows:", btc_data.duplicated().sum()) # Drop duplicate rows if any btc_data = btc_data.drop_duplicates()
Ausgabe:
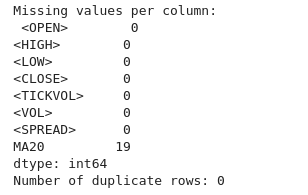
Anhand der Ausgabe können wir auch sehen, dass es keine doppelten Zeilen und Spalten gibt.
# Calculate a 20-period moving average btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() import ta # Add RSI using the `ta` library btc_data['RSI'] = ta.momentum.RSIIndicator(btc_data['<CLOSE>'], window=14).rsi()
Hier berechnen wir einen gleitenden 20-Perioden-Durchschnitt und einen 14-Perioden-RSI basierend auf den Schlusskursen aus dem „btc-data“ Dataframe. Diese Indikatoren, die in der technischen Analyse weit verbreitet sind, werden als neue Spalten (MA-20 und RSI) für weitere Analysen oder Visualisierungen hinzugefügt. Diese Schritte helfen Händlern, Trends und potenzielle überkaufte oder überverkaufte Marktbedingungen zu erkennen.
import matplotlib.pyplot as plt # Plot closing price and MA20 plt.figure(figsize=(12, 6)) plt.plot(btc_data.index, btc_data['<CLOSE>'], label='Close Price') plt.plot(btc_data.index, btc_data['MA20'], label='20-period MA', color='orange') plt.legend() plt.title('BTC Closing Price and Moving Average') plt.show()
Ausgabe:
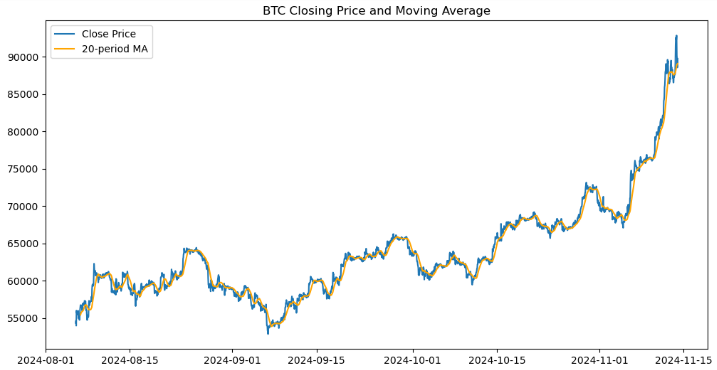
Wir haben eine visuelle Darstellung der Bitcoin-Schlusskurse und des gleitenden 20-Perioden-Durchschnitts (MA20) mithilfe der Matplotlib-Bibliothek erstellt. Es initialisiert eine Abbildung mit einer Größe von 12x6 Zoll und stellt die Schlusskurse gegen den Index des DataFrame dar, wobei es als „Close Price“ bezeichnet wird. Es wird eine zweite Grafik für den gleitenden 20-Perioden-Durchschnitt in Orange eingeblendet, die als „20-Perioden-MA“ gekennzeichnet ist. Es wird eine Legende hinzugefügt, um zwischen den beiden Linien zu unterscheiden, und das Chart trägt den Titel „BTC-Schlusskurs und gleitender Durchschnitt“. Schließlich wird das Chart angezeigt, das eine klare Visualisierung der Preistrends und ihrer Beziehung zum gleitenden Durchschnitt bietet.
import numpy as np # Add log returns btc_data['Log_Returns'] = (btc_data['<CLOSE>'] / btc_data['<CLOSE>'].shift(1)).apply(lambda x: np.log(x)) # Save the cleaned data btc_data.to_csv('BTCUSD_H1_cleaned.csv')
Jetzt berechnen wir die logarithmischen Renditen der Schlusskurse von Bitcoin und speichern den aktualisierten Datensatz in einer neuen CSV-Datei. Die logarithmischen Renditen werden berechnet, indem jeder Schlusskurs durch den Schlusskurs der Vorperiode geteilt und das Ergebnis mit dem natürlichen Logarithmus multipliziert wird. Dazu wird die Methode „shift(1)“ verwendet, um jeden Preis an seinen Vorgänger anzugleichen, gefolgt von der Anwendung einer Lambda-Funktion mit „np.log“. Die berechneten Werte, die in einer neuen Spalte mit der Bezeichnung „Log-Returns“ gespeichert werden, bieten ein analytisch freundlicheres Maß für Preisänderungen, das insbesondere bei der Finanzmodellierung und Risikoanalyse nützlich ist. Schließlich speichern wir den aktualisierten Datensatz einschließlich der neu hinzugefügten Spalte „Log-returns“ in einer Datei mit dem Namen „BTCUSD-H1-cleaned.csv“, um ihn weiter zu analysieren.
import seaborn as sns import matplotlib.pyplot as plt # Correlation heatmap sns.heatmap(btc_data.corr(), annot=True, cmap='coolwarm') plt.title('Correlation Heatmap') plt.show()
Ausgabe:
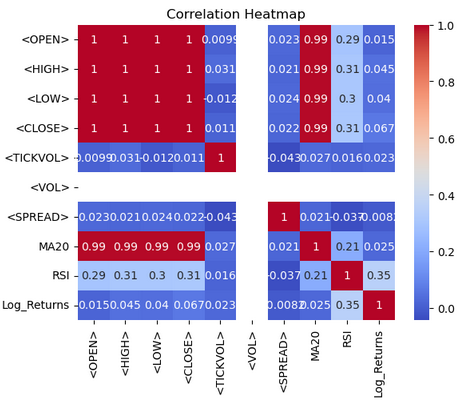
Anhand der Heatmap visualisieren wir die Korrelationen zwischen den numerischen Spalten im „btc-data“ Data frame mit Seaborn und Matplotlib. Die Funktion „btc-data.corr()“ berechnet paarweise Korrelationskoeffizienten für alle numerischen Spalten und quantifiziert die linearen Beziehungen zwischen ihnen. Die Funktion „sns.heatmap()“ zeigt diese Korrelationsmatrix als Heatmap an, mit „annot=True“, um Korrelationswerte in jeder Zelle anzuzeigen, und „cmap='coolwarm'“, um eine abweichende Farbpalette zur leichteren Interpretation zu verwenden. Wärmere Farbtöne (rot) stehen für positive Korrelationen, während kältere Farbtöne (blau) negative Korrelationen anzeigen. Ein Titel, „Correlation Heatmap“, wird mit Matplotlib hinzugefügt, und das Diagramm wird mit „plt.show()“ angezeigt. Diese Visualisierung hilft, Muster und Beziehungen innerhalb des Datensatzes auf einen Blick zu erkennen.
from sklearn.model_selection import train_test_split # Define features and target variable X = btc_data.drop(columns=['<CLOSE>']) y = btc_data['<CLOSE>'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Wir bereiten den Datenrahmen „btc-data“ für das maschinelle Lernen vor, indem wir ihn in Trainings- und Testteilmengen aufteilen. Zunächst werden die Merkmale „(x)“ durch Entfernen der Spalte „<CLOSE>“ aus dem Datensatz definiert, während die Zielvariable „(y)“ auf die Spalte „<CLOSE>“ gesetzt wird, die den vorherzusagenden Wert darstellt. Die Funktion „train-test-split“ von Scikit-learn wird dann verwendet, um die Daten in Trainings- und Testsätze aufzuteilen, wobei 80 % der Daten für das Training und 20 % für das Testen vorgesehen sind, wie durch „test-size=0.2“ festgelegt. Die Angabe „random-state=42“ stellt sicher, dass die Aufteilung reproduzierbar ist und die Konsistenz über verschiedene Läufe hinweg erhalten bleibt.
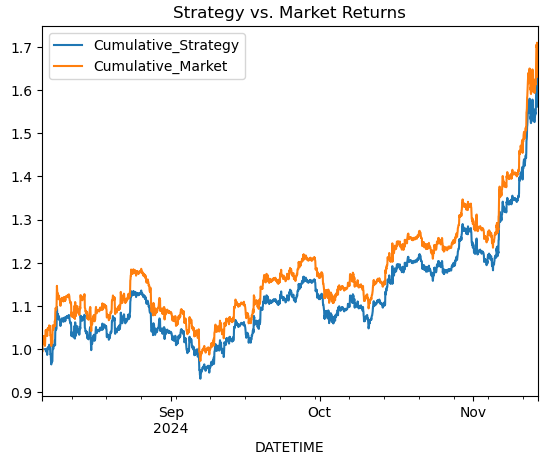
# Simple Moving Average Crossover Strategy btc_data['Signal'] = (btc_data['MA20'] > btc_data['RSI']).astype(int) btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'].shift(1) * btc_data['Returns'] # Plot cumulative returns btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data[['Cumulative_Strategy', 'Cumulative_Market']].plot(title='Strategy vs. Market Returns') plt.show()
Ausgabe:
# Calculate short-term and long-term moving averages btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() btc_data['MA50'] = btc_data['<CLOSE>'].rolling(window=50).mean() # Generate signals: 1 for Buy, -1 for Sell btc_data['Signal'] = 0 btc_data.loc[btc_data['MA20'] > btc_data['MA50'], 'Signal'] = 1 btc_data.loc[btc_data['MA20'] < btc_data['MA50'], 'Signal'] = -1 # Shift signal to avoid look-ahead bias btc_data['Signal'] = btc_data['Signal'].shift(1)
# Calculate returns btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'] * btc_data['Returns'] # Calculate cumulative returns btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() # Plot performance import matplotlib.pyplot as plt plt.figure(figsize=(12, 6)) plt.plot(btc_data['Cumulative_Market'], label='Market Returns') plt.plot(btc_data['Cumulative_Strategy'], label='Strategy Returns') plt.title('Strategy vs. Market Performance') plt.legend() plt.show()
Ausgabe:
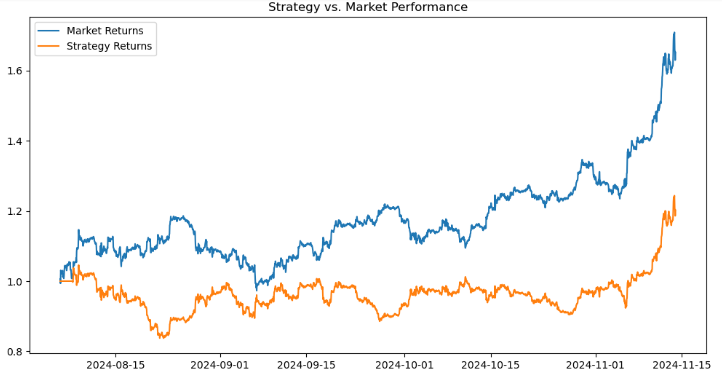
Bei der Bewertung der Leistung einer Handelsstrategie im Vergleich zum Markt und der Visualisierung der Ergebnisse. Zunächst berechnen wir die Marktrenditen als prozentuale Veränderung der „<CLOSE>“-Preise mit „pct-change()“ und speichern sie in der Spalte „Renditen“. Die Strategierenditen werden berechnet, indem die Spalte „Signal“ (die Handelssignale wie 1 für Kaufen, -1 für Verkaufen oder 0 für Halten darstellt) mit den Marktrenditen multipliziert und das Ergebnis in „Strategierenditen“ gespeichert wird. Die kumulierten Renditen sowohl für den Markt als auch für die Strategie werden mit Hilfe von „(1 + returns).comprod()“ berechnet, dies simuliert den Gesamtzuwachs von 1 $, der in den Markt „(Cumulative-market)“ investiert wird oder der Strategie „(Cumulative-strategy)“ folgt.
# Add RSI from ta.momentum import RSIIndicator btc_data['RSI'] = RSIIndicator(btc_data['<CLOSE>'], window=14).rsi() # Add MACD from ta.trend import MACD macd = MACD(btc_data['<CLOSE>']) btc_data['MACD'] = macd.macd() btc_data['MACD_Signal'] = macd.macd_signal() # Target variable: 1 if next period's close > current close btc_data['Target'] = (btc_data['<CLOSE>'].shift(-1) > btc_data['<CLOSE>']).astype(int)
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, classification_report # Define features and target features = ['MA20', 'MA50', 'RSI', 'MACD', 'MACD_Signal'] X = btc_data.dropna()[features] y = btc_data.dropna()['Target'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train a Random Forest Classifier model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train, y_train) # Evaluate the model y_pred = model.predict(X_test) print("Accuracy:", accuracy_score(y_test, y_pred)) print(classification_report(y_test, y_pred))
Ausgabe:
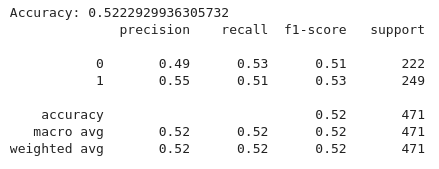
Anhand des obigen Codes implementieren wir eine Pipeline für maschinelles Lernen, um Handelssignale auf der Grundlage technischer Indikatoren mithilfe eines Random Forest-Klassifikators zu klassifizieren. Zunächst wird die Merkmalsgruppe „(x)“ definiert, die Indikatoren wie den gleitenden 20- und 50-Perioden-Durchschnitt „(MA20, MA50)“, den Relative Strength Index (RSI) und MACD-bezogene Merkmale „(MACD, MACD-Signale)“ enthält. Die Zielvariable „(y)“ wird auf die Zielspalte gesetzt, die in der Regel Kauf-, Verkaufs- oder Haltesignale anzeigt. Sowohl die „(x)“ als auch die „(y)“ Daten werden dann in einen Trainings- und einen Testsatz aufgeteilt, wobei 80 % für das Training und 20 % für den Test verwendet werden und die Konsistenz durch „(random-state=42)“ sichergestellt wird.
Ein Random Forest Classifier wird mit 100 Entscheidungsbäumen „(n-estimators=100)“ initialisiert und mit den Trainingsdaten „(X-train und Y-train)“ trainiert. Die Vorhersagen des Modells für den Testsatz (X-Test) werden anhand der Genauigkeit bewertet, um die Korrektheit des Modells zu bestimmen, und anhand des Klassifizierungsberichts, der detaillierte Metriken wie Präzision, Wiedererkennung und F1-Score für jede Klasse enthält.
Anschließend wird das Modell mit folgendem Code eingesetzt:
import joblib # Save the model joblib.dump(model, 'btc_trading_model.pkl')
Alles zusammen auf MQL5
Um MQL5 mit dem Python-Skript zu verbinden, das unser trainiertes Modell ausführen wird, müssen wir einen Kommunikationskanal zwischen MQL5 und Python einrichten. In diesem Fall werden wir WebRequest verwenden.
//+------------------------------------------------------------------+ //| BTC-Big-DataH.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #include <Trade\Trade.mqh> CTrade trade;
Alle notwendigen „includes“ und die Handelsbibliothek „trade.mqh“ für das Handelsmanagement.
// Function to get predictions from Python API double GetPrediction(double &features[]) { // Convert the features array to a JSON-like string string jsonRequest = "["; for (int i = 0; i < ArraySize(features); i++) { jsonRequest += DoubleToString(features[i], 6); if (i != ArraySize(features) - 1) jsonRequest += ","; } jsonRequest += "]"; // Define the WebRequest parameters string url = "http://127.0.0.1:5000/predict"; string hdrs = {"Content-Type: application/json"}; // Add headers if needed char data[]; StringToCharArray(jsonRequest, data); // Convert JSON request string to char array char response[]; ulong result_headers_size = 0; //-------------------------------------------------------------------------------------- string cookie=NULL; char post[], resultsss[]; // Send the WebRequest int result = WebRequest("POST", url, cookie, NULL, 500, post, 0, resultsss, hdrs); // Handle the response if (result == -1) { Print("Error sending WebRequest: ", GetLastError()); return -1; // Return an error signal } // Convert response char array back to a string string responseString; CharArrayToString(response, (int)responseString); // Parse the response (assuming the server returns a numeric value) double prediction = StringToDouble(responseString); return prediction; }
Die Funktion „GetPrediction()“ sendet einen Satz von Eingabemerkmalen an eine Python-basierte API und ruft eine Vorhersage ab. Die Merkmale werden als Array von Doubles übergeben, die in eine JSON-formatierte Zeichenfolge konvertiert werden, um dem erwarteten Eingabeformat der API zu entsprechen. Bei dieser Konvertierung wird das Feature-Array durchlaufen und jeder Wert an eine JSON-ähnliche Array-Struktur angehängt. Die Funktion „DoubleToString“ stellt sicher, dass die Werte mit sechs Dezimalstellen dargestellt werden. Die erzeugte JSON-Zeichenkette wird dann in ein „char“-Array umgewandelt.
Die Funktion bereitet dann eine POST-Anfrage an den API-Endpunkt „http://127.0.0.1:5000/predict“ mittels Webanforderung vor. Die erforderlichen Parameter sind definiert. Sobald die API-Antwort empfangen wurde, wird sie mithilfe von „CharArrayToString“ in eine Zeichenkette zurückverwandelt. Schlägt die Webanforderung fehl, wird ein Fehler protokolliert, und die Funktion gibt -1 zurück.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick(){ // Calculate indicators double MA20 = iMA(_Symbol, PERIOD_CURRENT, 20, 0, MODE_SMA, PRICE_CLOSE); double MA50 = iMA(_Symbol, PERIOD_CURRENT, 50, 0, MODE_SMA, PRICE_CLOSE); double RSI = iRSI(_Symbol, PERIOD_CURRENT, 14, PRICE_CLOSE); // Declare arrays to hold MACD data double MACD_Buffer[1], SignalLine_Buffer[1], Hist_Buffer[1]; // Get MACD handle int macd_handle = iMACD(NULL, 0, 12, 26, 9, PRICE_CLOSE); if (macd_handle != INVALID_HANDLE) { // Copy the most recent MACD values into buffers if (CopyBuffer(macd_handle, 0, 0, 1, MACD_Buffer) <= 0) Print("Failed to copy MACD"); if (CopyBuffer(macd_handle, 1, 0, 1, SignalLine_Buffer) <= 0) Print("Failed to copy Signal Line"); if (CopyBuffer(macd_handle, 2, 0, 1, Hist_Buffer) <= 0) Print("Failed to copy Histogram"); } // Assign the values from the buffers double MACD = MACD_Buffer[0]; double SignalLine = SignalLine_Buffer[0]; // Assign features double features[5]; features[0] = MA20; features[1] = MA50; features[2] = RSI; features[3] = MACD; features[4] = SignalLine; // Get prediction double signal = GetPrediction(features); if (signal == 1){ MBuy(); // Adjust lot size } else if (signal == -1){ MSell(); } }
„OnTick“ beginnt mit der Berechnung wichtiger technischer Indikatoren: die einfachen gleitenden Durchschnitte über 20 und 50 Perioden (MA20 und MA50), um die Trendrichtung zu verfolgen, und der Relative-Stärke-Index (RSI) über 14 Perioden, um die Marktdynamik zu messen. Zusätzlich werden die Werte für die MACD-Linie, die Signallinie und das Histogramm mit der Funktion „iMACD“ abgerufen und nach der Validierung des MACD-Handles in Puffern gespeichert. Diese berechneten Indikatoren werden in einem Array „features“ zusammengefasst, das als Eingabe für ein maschinelles Lernmodell dient, auf das über die Funktion „GetPrediction“ zugegriffen wird. Dieses Modell sagt eine Handelsaktion voraus und liefert 1 für ein Kaufsignal oder -1 für ein Verkaufssignal. Auf der Grundlage der Vorhersage führt die Funktion entweder ein Kaufgeschäft mit „MBuy()“ oder ein Verkaufsgeschäft mit „MSell()“ aus.
Python-API
Nachfolgend finden Sie eine Web-API, die Flask verwendet, um Vorhersagen von einem vortrainierten maschinellen Lernmodell für BTC-Handelsentscheidungen zu liefern.
from flask import Flask, request, jsonify import joblib import pandas as pd # Load the model model = joblib.load('btc_trading_model.pkl') app = Flask(__name__) @app.route('/predict', methods=['POST']) def predict(): data = request.json df = pd.DataFrame(data) prediction = model.predict(df) return jsonify(prediction.tolist()) app.run(port=5000)
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass wir durch die Kombination von Big Data-Verarbeitung, maschinellem Lernen und Automatisierung eine umfassende Handelslösung entwickelt haben. Ausgehend von historischen BTC/USD-Daten haben wir diese verarbeitet und bereinigt, um aussagekräftige Merkmale wie gleitende Durchschnitte, RSI und MACD zu extrahieren. Wir haben diese verarbeiteten Daten verwendet, um ein maschinelles Lernmodell zu trainieren, das Handelssignale vorhersagen kann. Das trainierte Modell wurde als Flask-basierte API implementiert, die es externen Systemen ermöglicht, Vorhersagen abzufragen. In MQL5 haben wir einen Expert Advisor implementiert, der Echtzeit-Indikatorwerte sammelt, sie zur Vorhersage an die Flask-API sendet und Trades auf der Grundlage der zurückgegebenen Signale ausführt.
Diese integrierte Handelslösung unterstützt Händler, indem sie die Präzision technischer Indikatoren mit der Intelligenz des maschinellen Lernens kombiniert. Durch den Einsatz eines maschinellen Lernmodells, das auf historischen Daten trainiert wurde, passt sich das System an die Marktdynamik an und erstellt fundierte Prognosen, die die Handelsergebnisse verbessern können. Die Bereitstellung des Modells über eine API ermöglicht Flexibilität, sodass die Händler es in verschiedene Plattformen wie MQL5 integrieren können.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/16446
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Nutzung des CatBoost Machine Learning Modells als Filter für Trendfolgestrategien
Nutzung des CatBoost Machine Learning Modells als Filter für Trendfolgestrategien
 Risikomodell für ein Portfolio unter Verwendung des Kelly-Kriteriums und der Monte-Carlo-Simulation
Risikomodell für ein Portfolio unter Verwendung des Kelly-Kriteriums und der Monte-Carlo-Simulation
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.