Integración de MQL5 con paquetes de procesamiento de datos (Parte 4): Gestión de Big Data

Introducción
Los mercados financieros siguen evolucionando, los operadores ya no solo se enfrentan a gráficos de precios e indicadores simples, sino que deben lidiar con una avalancha de datos procedentes de todos los rincones del mundo. En esta era del big data, el éxito en el trading no solo depende de la estrategia, sino también de la capacidad para filtrar de forma eficiente grandes cantidades de información y encontrar datos útiles. Este artículo, el cuarto de nuestra serie sobre la integración de MQL5 con herramientas de procesamiento de datos, se centra en proporcionarle las habilidades necesarias para manejar conjuntos de datos masivos sin problemas. Desde datos de cotización en tiempo real hasta archivos históricos que abarcan décadas, la capacidad de dominar los macrodatos se está convirtiendo rápidamente en el sello distintivo de un sistema de negociación sofisticado.
Imagina analizar millones de puntos de datos para descubrir tendencias sutiles del mercado o incorporar conjuntos de datos externos, como el sentimiento social o los indicadores económicos, en tu entorno de trading MQL5. Las posibilidades son infinitas, pero solo si se dispone de las herramientas adecuadas. En este artículo, exploraremos cómo llevar MQL5 más allá de sus capacidades integradas mediante su integración con bibliotecas avanzadas de procesamiento de datos y soluciones de big data. Tanto si eres un operador experimentado que busca perfeccionar sus habilidades como si eres un desarrollador curioso que explora el potencial de la tecnología financiera, esta guía promete ser un punto de inflexión. Manténgase al tanto para descubrir cómo puede convertir datos abrumadores en una ventaja decisiva.
Recopilar datos históricos
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTC H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Save the data to a CSV file filename = "BTC_H1.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Para recuperar datos históricos, primero establecemos una conexión con el terminal MetaTrader 5 utilizando la función `mt5.initialize()`. Esto es esencial porque el paquete Python se comunica directamente con la plataforma MetaTrader 5 en ejecución. Configuramos el código para establecer el intervalo de tiempo deseado para la extracción de datos especificando las fechas de inicio y finalización. Los objetos `datetime` se crean en la zona horaria UTC para garantizar la coherencia entre las diferentes zonas horarias. A continuación, el script utiliza la función `mt5.copy-rates-range()` para solicitar datos históricos por hora para el símbolo BTCUSD, desde el 6 de agosto de 2024 hasta la fecha y hora actuales.
Después de desconectarse de la terminal MetaTrader 5 utilizando `mt5.shutdown()` para evitar cualquier conexión innecesaria adicional. Los datos recuperados se muestran inicialmente en su formato sin procesar para confirmar que la extracción de datos se ha realizado correctamente. A continuación, convertimos estos datos en un marco de datos pandas para facilitar su manipulación y análisis. Además, el código convierte las marcas de tiempo Unix a un formato de fecha y hora legible, lo que garantiza que los datos estén bien estructurados y listos para su posterior procesamiento o análisis.
filename = "XAUUSD_H1_2nd.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Como mi sistema operativo es Linux, tengo que guardar los datos recibidos en un archivo. Pero para aquellos que utilizan Windows, pueden recuperar los datos fácilmente con el siguiente script:
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTCUSD H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Display data directly print("\nDisplay dataframe with data") print(rates_frame.head(10))
Y si por alguna razón no puede obtener los datos históricos, puede recuperarlos manualmente en su plataforma MetaTrader 5 siguiendo los siguientes pasos. Inicie su plataforma MetaTrader y, en la parte superior del panel de MetaTrader 5, vaya a > Herramientas y, a continuación, a > Opciones y accederá a las opciones de Gráficos. A continuación, deberá seleccionar el número de barras del gráfico que desea descargar. Es mejor elegir la opción de barras ilimitadas, ya que trabajaremos con fechas y no sabremos cuántas barras hay en un periodo de tiempo determinado.
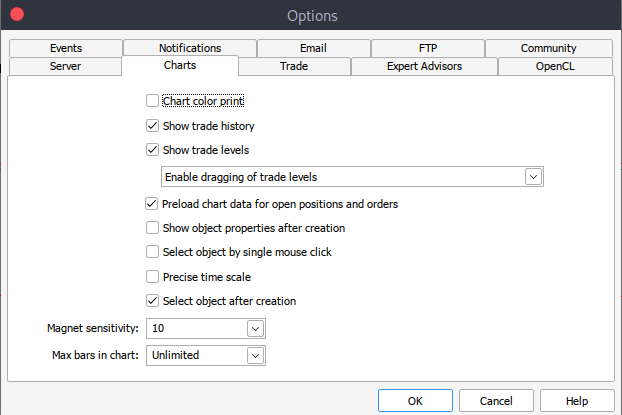
Después de eso, ahora tendrás que descargar los datos reales. Para ello, deberá ir a Ver y, a continuación, a Símbolos, y llegará a la pestaña Especificaciones. Simplemente navega a Barras o Ticks dependiendo del tipo de datos que quieras descargar. Continúe e introduzca el periodo de inicio y finalización de los datos históricos que desea descargar. A continuación, haga clic en el botón de solicitud para descargar los datos y guardarlos en formato CSV.
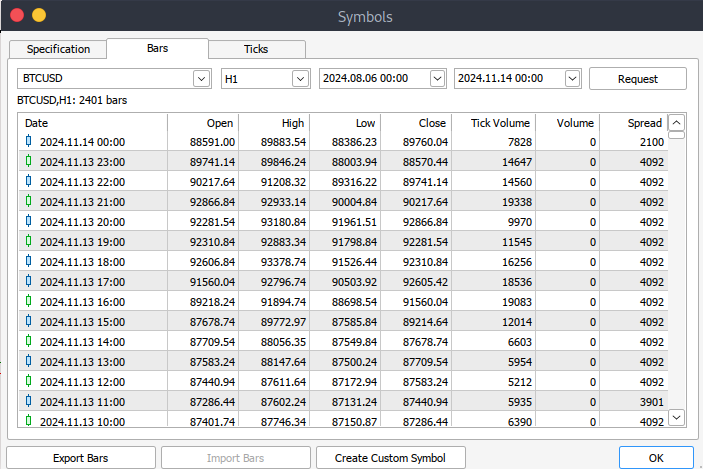
Gestión de big data en MetaTrader 5 con Jupyter Lab
import pandas as pd # Load the uploaded BTC 1H CSV file file_path = '/home/int_junkie/Documents/DataVisuals/BTCUSD_H1.csv' btc_data = pd.read_csv(file_path) # Display basic information about the dataset btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
Salida:
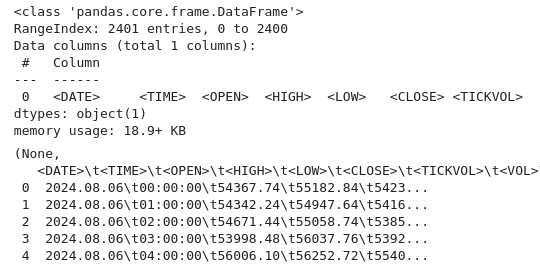
A partir del código anterior, como siempre, inspeccionamos los datos y comprendemos la estructura del conjunto de datos. Comprobamos los tipos de datos, la forma y la integridad (utilizando info()). También obtenemos el contenido y el diseño del conjunto de datos (utilizando head()). Este es un primer paso habitual en el análisis exploratorio de datos para garantizar que los datos se carguen correctamente y familiarizarse con su estructura.
# Reload the data with tab-separated values btc_data = pd.read_csv(file_path, delimiter='\t') # Display basic information and the first few rows after parsing btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
Salida:
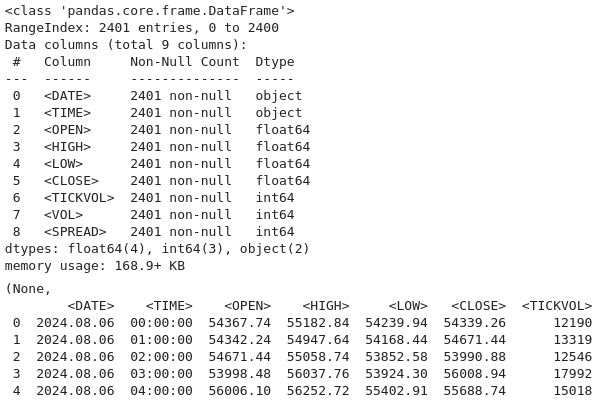
Ahora utilizamos este código para volver a cargar el conjunto de datos desde un archivo que se supone que utiliza valores separados por tabulaciones (TSV) en lugar del formato predeterminado separado por comas. Al especificar `delimiter=`\t`` en `pd.read-csv()`, los datos se analizan correctamente en Pandas `DataFrame` para su posterior análisis. A continuación, utilizamos «btc-data-infor» para mostrar metadatos sobre el conjunto de datos, como el número de filas, columnas, tipos de datos y valores que faltan.
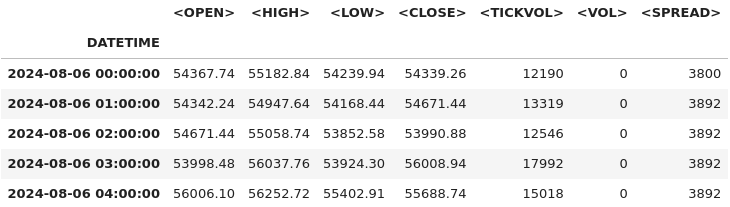
# Combine <DATE> and <TIME> into a single datetime column and set it as the index btc_data['DATETIME'] = pd.to_datetime(btc_data['<DATE>'] + ' ' + btc_data['<TIME>']) btc_data.set_index('DATETIME', inplace=True) # Drop the original <DATE> and <TIME> columns as they're no longer needed btc_data.drop(columns=['<DATE>', '<TIME>'], inplace=True) # Display the first few rows after modifications btc_data.head()
Salida:
# Check for missing values and duplicates missing_values = btc_data.isnull().sum() duplicate_rows = btc_data.duplicated().sum() # Clean data (if needed) btc_data_cleaned = btc_data.drop_duplicates() # Results missing_values, duplicate_rows, btc_data_cleaned.shape
Salida:
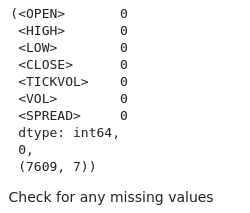
Podemos ver en el resultado que no hay valores perdidos en nuestro conjunto de datos.
# Check for missing values print("Missing values per column:\n", btc_data.isnull().sum()) # Check for duplicate rows print("Number of duplicate rows:", btc_data.duplicated().sum()) # Drop duplicate rows if any btc_data = btc_data.drop_duplicates()
Salida:
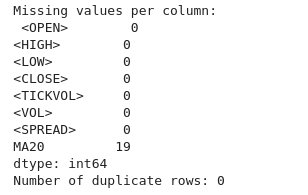
En el resultado, también podemos ver que no hay filas ni columnas duplicadas.
# Calculate a 20-period moving average btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() import ta # Add RSI using the `ta` library btc_data['RSI'] = ta.momentum.RSIIndicator(btc_data['<CLOSE>'], window=14).rsi()
Aquí, calculamos una media móvil de 20 períodos y un RSI de 14 períodos basándonos en los precios de cierre del marco de datos «btc-data». Estos indicadores, ampliamente utilizados en el análisis técnico, se añaden como nuevas columnas (MA-20 y RSI) para su posterior análisis o visualización. Estos pasos ayudan a los operadores a identificar tendencias y posibles condiciones de sobrecompra o sobreventa en el mercado.
import matplotlib.pyplot as plt # Plot closing price and MA20 plt.figure(figsize=(12, 6)) plt.plot(btc_data.index, btc_data['<CLOSE>'], label='Close Price') plt.plot(btc_data.index, btc_data['MA20'], label='20-period MA', color='orange') plt.legend() plt.title('BTC Closing Price and Moving Average') plt.show()
Salida:
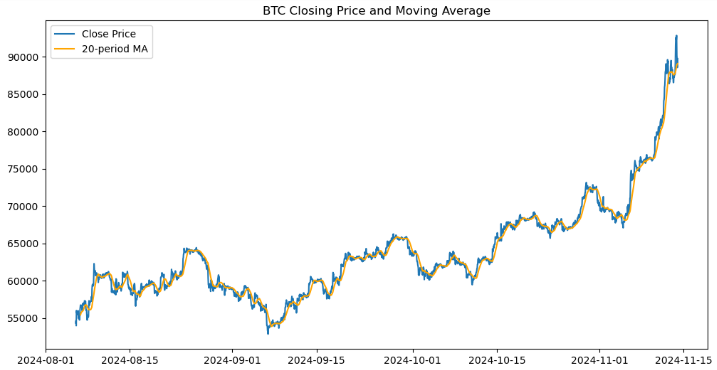
Hemos creado una representación visual de los precios de cierre de Bitcoin y su media móvil de 20 períodos (MA20) utilizando la biblioteca Matplotlib. Inicializa una figura con un tamaño de 12 x 6 pulgadas y traza los precios de cierre frente al índice del DataFrame, etiquetándolo como «Close Price». Superpone un segundo gráfico para la media móvil de 20 períodos en naranja, etiquetado como «20-period MA». Se añade una leyenda para distinguir entre las dos líneas, y el gráfico se titula «BTC Closing Price and Moving Average». Por último, se muestra el gráfico, que ofrece una visualización clara de las tendencias de los precios y su relación con la media móvil.
import numpy as np # Add log returns btc_data['Log_Returns'] = (btc_data['<CLOSE>'] / btc_data['<CLOSE>'].shift(1)).apply(lambda x: np.log(x)) # Save the cleaned data btc_data.to_csv('BTCUSD_H1_cleaned.csv')
Ahora calculamos los rendimientos logarítmicos de los precios de cierre de Bitcoin y guardamos el conjunto de datos actualizado en un nuevo archivo CSV. Los rendimientos logarítmicos se calculan dividiendo cada precio de cierre por el precio de cierre del período anterior y aplicando el logaritmo natural al resultado. Esto se consigue utilizando el método `shift(1)` para alinear cada precio con su predecesor, seguido de la aplicación de una función lambda con `np.log`. Los valores calculados, almacenados en una nueva columna denominada `Log-returns`, proporcionan una medida más fácil de analizar de las variaciones de precios, lo que resulta especialmente útil en la modelización financiera y el análisis de riesgos. Por último, guardamos el conjunto de datos actualizado, incluida la columna «Log-returns» recién añadida, en un archivo denominado «BTCUSD-H1-cleaned.csv» para su posterior análisis.
import seaborn as sns import matplotlib.pyplot as plt # Correlation heatmap sns.heatmap(btc_data.corr(), annot=True, cmap='coolwarm') plt.title('Correlation Heatmap') plt.show()
Salida:
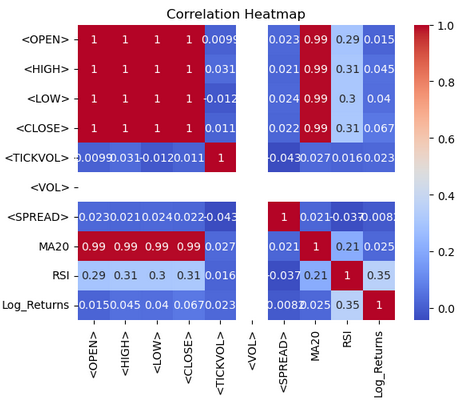
A partir del mapa de calor, visualizamos las correlaciones entre las columnas numéricas del marco de datos `btc-data` utilizando Seaborn y Matplotlib. La función `btc-data.corr()` calcula los coeficientes de correlación por pares para todas las columnas numéricas, cuantificando las relaciones lineales entre ellas. La función `sns.heatmap()` muestra esta matriz de correlación como un mapa de calor, con `annot=True` para mostrar los valores de correlación en cada celda y `cmap='coolwarm'` para utilizar una paleta de colores divergente que facilite la interpretación. Los tonos más cálidos (rojo) representan correlaciones positivas, mientras que los tonos más fríos (azul) indican correlaciones negativas. Se añade un título, «Correlation Heatmap» (Mapa de calor de correlación), utilizando Matplotlib, y el gráfico se muestra con `plt.show()`. Esta visualización ayuda a identificar patrones y relaciones dentro del conjunto de datos de un vistazo.
from sklearn.model_selection import train_test_split # Define features and target variable X = btc_data.drop(columns=['<CLOSE>']) y = btc_data['<CLOSE>'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Preparamos el marco de datos «btc-data» para el aprendizaje automático dividiéndolo en subconjuntos de entrenamiento y prueba. En primer lugar, las características `(x)` se definen eliminando la columna `<CLOSE>` del conjunto de datos, mientras que la variable objetivo `(y)` se establece en la columna `<CLOSE>`, que representa el valor que se va a predecir. A continuación, se utiliza la función «train-test-split» de Scikit-learn para dividir los datos en conjuntos de entrenamiento y prueba, asignando el 80 % de los datos al entrenamiento y el 20 % a la prueba, tal y como se especifica en «test-size=0.2». El parámetro «random-state=42» garantiza que la división sea reproducible, manteniendo la coherencia entre diferentes ejecuciones.
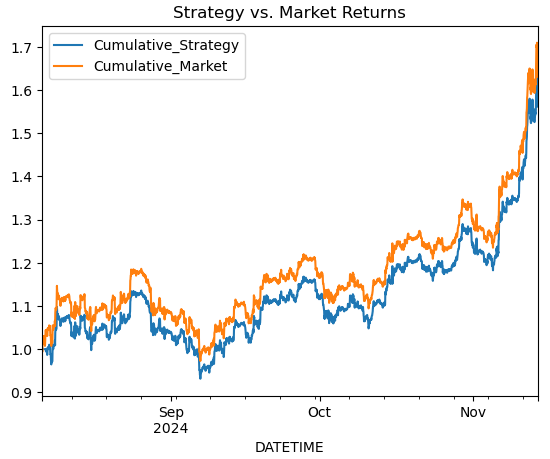
# Simple Moving Average Crossover Strategy btc_data['Signal'] = (btc_data['MA20'] > btc_data['RSI']).astype(int) btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'].shift(1) * btc_data['Returns'] # Plot cumulative returns btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data[['Cumulative_Strategy', 'Cumulative_Market']].plot(title='Strategy vs. Market Returns') plt.show()
Salida:
# Calculate short-term and long-term moving averages btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() btc_data['MA50'] = btc_data['<CLOSE>'].rolling(window=50).mean() # Generate signals: 1 for Buy, -1 for Sell btc_data['Signal'] = 0 btc_data.loc[btc_data['MA20'] > btc_data['MA50'], 'Signal'] = 1 btc_data.loc[btc_data['MA20'] < btc_data['MA50'], 'Signal'] = -1 # Shift signal to avoid look-ahead bias btc_data['Signal'] = btc_data['Signal'].shift(1)
# Calculate returns btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'] * btc_data['Returns'] # Calculate cumulative returns btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() # Plot performance import matplotlib.pyplot as plt plt.figure(figsize=(12, 6)) plt.plot(btc_data['Cumulative_Market'], label='Market Returns') plt.plot(btc_data['Cumulative_Strategy'], label='Strategy Returns') plt.title('Strategy vs. Market Performance') plt.legend() plt.show()
Salida:
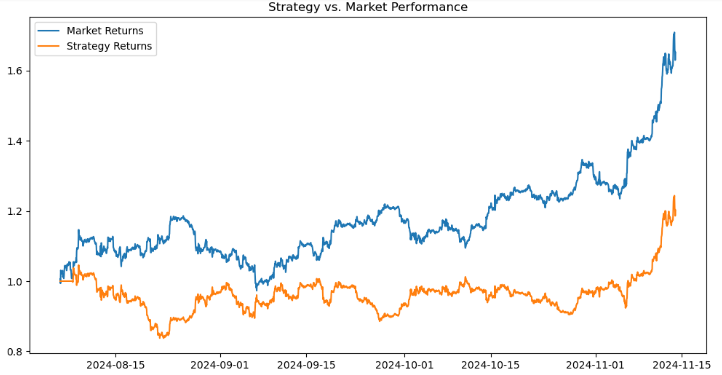
Al evaluar el rendimiento de una estrategia de trading en comparación con el mercado y visualizar los resultados. En primer lugar, calculamos los rendimientos del mercado como el cambio porcentual en los precios `<CLOSE>` utilizando `pct-change()` y lo almacenamos en la columna `Returns`. Los rendimientos de la estrategia se calculan multiplicando la columna «signal» (que representa señales de negociación, como 1 para comprar, -1 para vender o 0 para mantener) por los rendimientos del mercado, y almacenando el resultado en «Strategy_Returns». Los rendimientos acumulados tanto para el mercado como para la estrategia se calculan utilizando `(1 + returns).comprod()`, que simula el crecimiento compuesto de 1 dólar invertido en el mercado `(Cumulative_Market)` o siguiendo la estrategia `(Cumulative_Strategy)`.
# Add RSI from ta.momentum import RSIIndicator btc_data['RSI'] = RSIIndicator(btc_data['<CLOSE>'], window=14).rsi() # Add MACD from ta.trend import MACD macd = MACD(btc_data['<CLOSE>']) btc_data['MACD'] = macd.macd() btc_data['MACD_Signal'] = macd.macd_signal() # Target variable: 1 if next period's close > current close btc_data['Target'] = (btc_data['<CLOSE>'].shift(-1) > btc_data['<CLOSE>']).astype(int)
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, classification_report # Define features and target features = ['MA20', 'MA50', 'RSI', 'MACD', 'MACD_Signal'] X = btc_data.dropna()[features] y = btc_data.dropna()['Target'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train a Random Forest Classifier model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train, y_train) # Evaluate the model y_pred = model.predict(X_test) print("Accuracy:", accuracy_score(y_test, y_pred)) print(classification_report(y_test, y_pred))
Salida:
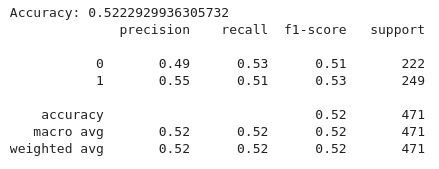
A partir del código anterior, implementamos un proceso de aprendizaje automático para clasificar las señales de trading basadas en indicadores técnicos utilizando un clasificador Random Forest. En primer lugar, se define el conjunto de características `(x)`, que incluye indicadores como las medias móviles de 20 y 50 períodos `(MA20, MA50)`, el índice de fuerza relativa (RSI) y características relacionadas con el MACD `(MACD, MACD_Signal)`. La variable objetivo `(y)` se establece en la `column` (columna) objetivo, que normalmente indica señales de compra, venta o mantenimiento. A continuación, los datos `(x)` y `(y)` se dividen en conjuntos de entrenamiento y prueba, utilizando el 80 % para el entrenamiento y el 20 % para la prueba, lo que garantiza la coherencia mediante `(random-state=42)`.
Un clasificador Random Forest se inicializa con 100 árboles de decisión `(n-estimators=100)` y se entrena con los datos de entrenamiento `(X_train e y_train)`. Las predicciones del modelo sobre el conjunto de prueba `(X_test)` se evalúan utilizando una puntuación de precisión para determinar su corrección y un informe de clasificación para proporcionar métricas detalladas, como la precisión, la recuperación y la puntuación F1 para cada clase.
A continuación, implementamos el modelo utilizando el siguiente código:
import joblib # Save the model joblib.dump(model, 'btc_trading_model.pkl')
Poniendo todo junto en MQL5
Vamos a conectar MQL5 al script de Python que ejecutará nuestro modelo entrenado, para lo cual tendremos que configurar un canal de comunicación entre MQL5 y Python. En este caso, vamos a utilizar WebRequest.
//+------------------------------------------------------------------+ //| BTC-Big-DataH.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #include <Trade\Trade.mqh> CTrade trade;
Todo lo necesario y la biblioteca de operaciones (trade.mqh) para la gestión de operaciones.
// Function to get predictions from Python API double GetPrediction(double &features[]) { // Convert the features array to a JSON-like string string jsonRequest = "["; for (int i = 0; i < ArraySize(features); i++) { jsonRequest += DoubleToString(features[i], 6); if (i != ArraySize(features) - 1) jsonRequest += ","; } jsonRequest += "]"; // Define the WebRequest parameters string url = "http://127.0.0.1:5000/predict"; string hdrs = {"Content-Type: application/json"}; // Add headers if needed char data[]; StringToCharArray(jsonRequest, data); // Convert JSON request string to char array char response[]; ulong result_headers_size = 0; //-------------------------------------------------------------------------------------- string cookie=NULL; char post[], resultsss[]; // Send the WebRequest int result = WebRequest("POST", url, cookie, NULL, 500, post, 0, resultsss, hdrs); // Handle the response if (result == -1) { Print("Error sending WebRequest: ", GetLastError()); return -1; // Return an error signal } // Convert response char array back to a string string responseString; CharArrayToString(response, (int)responseString); // Parse the response (assuming the server returns a numeric value) double prediction = StringToDouble(responseString); return prediction; }
La función `GetPrediction()` envía un conjunto de características de entrada a una API basada en Python y recupera una predicción. Las características se pasan como una matriz de valores dobles, que se convierten en una cadena con formato JSON para que coincida con el formato de entrada esperado por la API. Esta conversión implica iterar a través de la matriz de características y añadir cada valor a una estructura de matriz similar a JSON. La función `DoubleToString` garantiza que los valores se representen con seis decimales. La cadena JSON generada se convierte entonces en una matriz `char`.
A continuación, la función se prepara para realizar una solicitud POST al punto final de la API `(http://127.0.0.1:5000/predict)` utilizando una solicitud web. Se definen los parámetros necesarios. Una vez recibida la respuesta de la API, se vuelve a convertir en una cadena utilizando `CharArrayToString`. Si la solicitud web falla, se registra un error y la función devuelve -1.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick(){ // Calculate indicators double MA20 = iMA(_Symbol, PERIOD_CURRENT, 20, 0, MODE_SMA, PRICE_CLOSE); double MA50 = iMA(_Symbol, PERIOD_CURRENT, 50, 0, MODE_SMA, PRICE_CLOSE); double RSI = iRSI(_Symbol, PERIOD_CURRENT, 14, PRICE_CLOSE); // Declare arrays to hold MACD data double MACD_Buffer[1], SignalLine_Buffer[1], Hist_Buffer[1]; // Get MACD handle int macd_handle = iMACD(NULL, 0, 12, 26, 9, PRICE_CLOSE); if (macd_handle != INVALID_HANDLE) { // Copy the most recent MACD values into buffers if (CopyBuffer(macd_handle, 0, 0, 1, MACD_Buffer) <= 0) Print("Failed to copy MACD"); if (CopyBuffer(macd_handle, 1, 0, 1, SignalLine_Buffer) <= 0) Print("Failed to copy Signal Line"); if (CopyBuffer(macd_handle, 2, 0, 1, Hist_Buffer) <= 0) Print("Failed to copy Histogram"); } // Assign the values from the buffers double MACD = MACD_Buffer[0]; double SignalLine = SignalLine_Buffer[0]; // Assign features double features[5]; features[0] = MA20; features[1] = MA50; features[2] = RSI; features[3] = MACD; features[4] = SignalLine; // Get prediction double signal = GetPrediction(features); if (signal == 1){ MBuy(); // Adjust lot size } else if (signal == -1){ MSell(); } }
El «OnTick» comienza calculando indicadores técnicos clave: las medias móviles simples de 20 y 50 períodos (MA20 y MA50) para seguir la dirección de la tendencia, y el índice de fuerza relativa (RSI) de 14 períodos para medir el impulso del mercado. Además, recupera los valores de la línea MACD, la línea de señal y el histograma utilizando la función `iMACD`, y almacena estos valores en búferes tras validar el identificador MACD. Estos indicadores calculados se agrupan en una matriz de «características», que sirve como entrada para un modelo de aprendizaje automático al que se accede a través de la función «GetPrediction». Este modelo predice una acción comercial, devolviendo 1 para una señal de compra o -1 para una señal de venta. Según la predicción, la función ejecuta una operación de compra con `MBuy` o una operación de venta con `MSell()`.
API de Python
A continuación se muestra una API web que utiliza Flask para proporcionar predicciones a partir de un modelo de aprendizaje automático preentrenado para tomar decisiones de trading con BTC.
from flask import Flask, request, jsonify import joblib import pandas as pd # Load the model model = joblib.load('btc_trading_model.pkl') app = Flask(__name__) @app.route('/predict', methods=['POST']) def predict(): data = request.json df = pd.DataFrame(data) prediction = model.predict(df) return jsonify(prediction.tolist()) app.run(port=5000)
Conclusión
En resumen, hemos desarrollado una solución comercial integral combinando el manejo de big data, el aprendizaje automático y la automatización. Partiendo de datos históricos de BTCUSD, los procesamos y limpiamos para extraer características significativas, como medias móviles, RSI y MACD. Utilizamos estos datos procesados para entrenar un modelo de aprendizaje automático capaz de predecir señales de trading. El modelo entrenado se implementó como una API basada en Flask, lo que permite a los sistemas externos consultar las predicciones. En MQL5, implementamos un Asesor Experto que recopila valores de indicadores en tiempo real, los envía a la API de Flask para realizar predicciones y ejecuta operaciones basadas en las señales devueltas.
Esta solución de trading integrada empodera a los traders al combinar la precisión de los indicadores técnicos con la inteligencia del aprendizaje automático. Al aprovechar un modelo de aprendizaje automático entrenado con datos históricos, el sistema se adapta a la dinámica del mercado y realiza predicciones fundamentadas que pueden mejorar los resultados de las operaciones bursátiles. La implementación del modelo a través de una API ofrece flexibilidad, lo que permite a los operadores integrarlo en diversas plataformas como MQL5.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/16446
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso