MQL5とデータ処理パッケージの統合(第4回):ビッグデータの取り扱い

はじめに
金融市場は日々進化を続けており、トレーダーはもはや価格チャートや単純なインジケーターだけを扱っているわけではありません。今や世界中から流れ込む膨大なデータと向き合わなければならない時代です。このビッグデータ時代において、取引の成功は戦略そのものだけでなく、膨大な情報の中からどれだけ効率よく有益なインサイトを見つけ出せるかにかかっています。本記事は、MQL5とデータ処理ツールの統合に関する連載の第4回であり、大規模データセットをスムーズに扱うためのスキルを身につけることを目的としています。リアルタイムのティックデータから、数十年分に及ぶ履歴データまで、ビッグデータを自在に扱う力は、洗練された取引システムの新たな基準となりつつあります。
例えば、何百万件ものデータポイントを分析して微細な市場の傾向を読み取ったり、ソーシャル・センチメントや経済指標といった外部データをMQL5の取引環境に統合したりすることを想像してみてください。可能性は無限大です。ただし、それを実現するためには適切なツールが不可欠です。この記事では、MQL5の標準機能を超えて、先進的なデータ処理ライブラリやビッグデータソリューションと統合する方法を解説します。取引の優位性をさらに磨きたい熟練トレーダーの方にも、金融テクノロジーの可能性を探求する開発者の方にも、このガイドは新たな視点をもたらすことでしょう。圧倒的なデータを「決定的な武器」へと変える方法を、ぜひ最後までご覧ください。
履歴データの収集
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTC H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Save the data to a CSV file filename = "BTC_H1.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
履歴データを取得するには、まずmt5.initialize()関数を使用してMetaTrader5端末への接続を確立します。この処理は、Pythonパッケージが実行中のMetaTrader5プラットフォームと直接通信するために不可欠です。コード内で開始日と終了日を指定し、データ抽出に必要な時間範囲を設定します。datetimeオブジェクトはUTCタイムゾーンで作成され、異なるタイムゾーン間での一貫性が確保されます。次に、スクリプトはmt5.copy-rates-range()関数を使用して、2024年8月6日から現在の日時までのBTC/USD銘柄の履歴時間別データを要求します。
不要な接続を回避するために、mt5.shutdown()を使用してMetaTrader5端末から切断します。取得されたデータは最初に生データ形式で表示され、データ抽出が正しく行われたことを確認します。次に、このデータをpandasデータフレームに変換して、操作と分析を容易にします。さらに、Unixタイムスタンプを読み取り可能な日時形式に変換することで、データが適切に構造化され、さらなる処理や分析に対応できる状態にします。
filename = "XAUUSD_H1_2nd.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
私のオペレーティングシステムはLinuxのため、受信したデータをファイルに保存する必要があります。しかし、Windowsをお使いの方は、以下のスクリプトを使用することで、簡単にデータを取得することができます。
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTCUSD H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Display data directly print("\nDisplay dataframe with data") print(rates_frame.head(10))
また、何らかの理由で履歴データを取得できない場合は、以下の手順でMetaTrader5プラットフォーム上で手動で取得することが可能です。まず、MetaTraderプラットフォームを起動し、MetaTrader5のペイン/パネル上部にある[ツール]>[オプション]に移動します。次に、チャートオプションのセクションに進みます。そこで、ダウンロードしたいチャートのバーの数を選択します。一定期間にどれだけのバーが存在するかは予測できないため、「無制限」のオプションを選択することをお勧めします。これにより、日付に基づいてデータを扱う際にも問題なく対応できます。
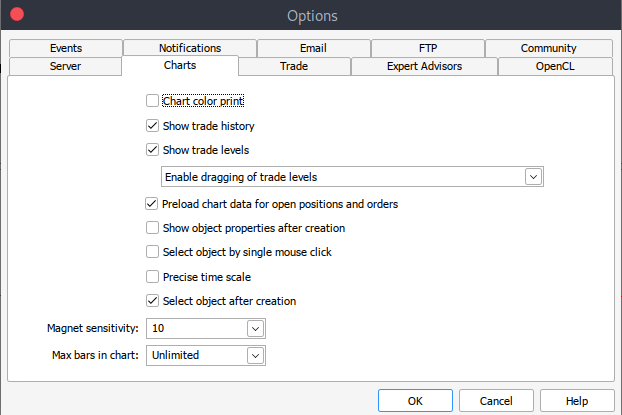
その後、実際のデータをダウンロードする必要があります。手順としては、[表示]>[銘柄]に進み、[仕様]タブに移動します。その後、ダウンロードしたいデータの種類に応じて、[Bars]または[Ticks]を選択します。次に、ダウンロードしたい履歴データの開始日と終了日を入力し、リクエストボタンをクリックします。これにより、データがダウンロードされ、.csv形式で保存されます。
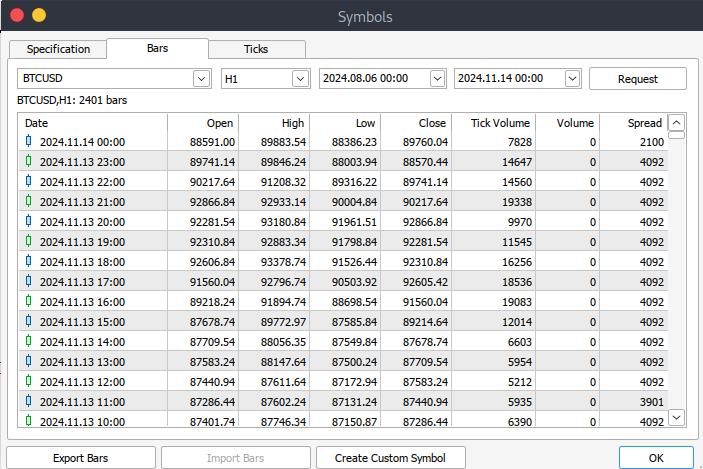
Jupyter LabでのMetaTrader 5ビッグデータの処理
import pandas as pd # Load the uploaded BTC 1H CSV file file_path = '/home/int_junkie/Documents/DataVisuals/BTCUSD_H1.csv' btc_data = pd.read_csv(file_path) # Display basic information about the dataset btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
出力
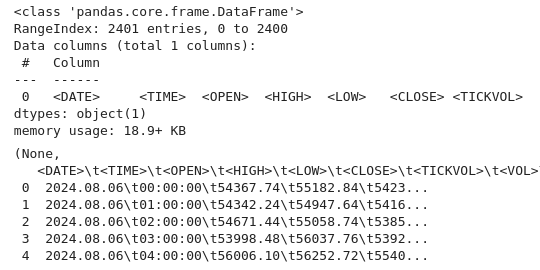
上記のコードから、いつものようにデータを検査し、データセットの構造を理解します。データ型、形状、完全性をチェックします(info()を使用)。また、データセットのコンテンツとレイアウトも取得します(head()を使用)。これは、データが正しくロードされていることを確認し、その構造を理解するための探索的データ分析の一般的な最初のステップです。
# Reload the data with tab-separated values btc_data = pd.read_csv(file_path, delimiter='\t') # Display basic information and the first few rows after parsing btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
出力
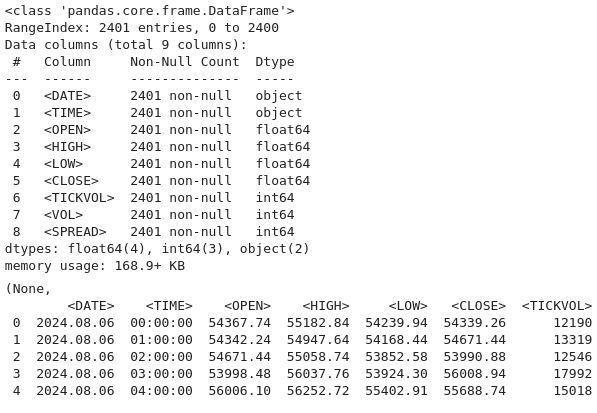
ここで、このコードを使用して、デフォルトのコンマ区切り形式ではなくタブ区切り値(TSV)を使用すると想定されるファイルからデータセットを再ロードします。pd.read-csv()でdelimiter=\tを指定すると、データはPandasDataFrameに正しく解析され、さらに分析できるようになります。次に、btc-data-inforを使用して、行数、列数、データ型、欠損値などのデータセットに関するメタデータを表示します。
# Combine <DATE> and <TIME> into a single datetime column and set it as the index btc_data['DATETIME'] = pd.to_datetime(btc_data['<DATE>'] + ' ' + btc_data['<TIME>']) btc_data.set_index('DATETIME', inplace=True) # Drop the original <DATE> and <TIME> columns as they're no longer needed btc_data.drop(columns=['<DATE>', '<TIME>'], inplace=True) # Display the first few rows after modifications btc_data.head()
出力
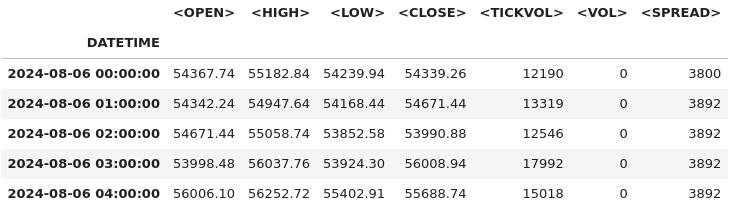
# Check for missing values and duplicates missing_values = btc_data.isnull().sum() duplicate_rows = btc_data.duplicated().sum() # Clean data (if needed) btc_data_cleaned = btc_data.drop_duplicates() # Results missing_values, duplicate_rows, btc_data_cleaned.shape
出力
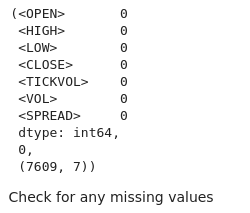
出力から、データセットに欠損値がないことがわかります。
# Check for missing values print("Missing values per column:\n", btc_data.isnull().sum()) # Check for duplicate rows print("Number of duplicate rows:", btc_data.duplicated().sum()) # Drop duplicate rows if any btc_data = btc_data.drop_duplicates()
出力
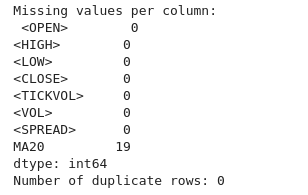
出力から、重複した行や列がないこともわかります。
# Calculate a 20-period moving average btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() import ta # Add RSI using the `ta` library btc_data['RSI'] = ta.momentum.RSIIndicator(btc_data['<CLOSE>'], window=14).rsi()
ここでは、btc-dataデータフレームの終値に基づいて、20期間の移動平均と14期間のRSIを計算します。テクニカル分析で広く使用されているこれらのインジケーターは、さらなる分析や可視化のために新しい列(MA-20およびRSI)として追加されます。これらの手順は、トレーダーが市場の傾向や潜在的な買われすぎや売られすぎの状態を特定するのに役立ちます。
import matplotlib.pyplot as plt # Plot closing price and MA20 plt.figure(figsize=(12, 6)) plt.plot(btc_data.index, btc_data['<CLOSE>'], label='Close Price') plt.plot(btc_data.index, btc_data['MA20'], label='20-period MA', color='orange') plt.legend() plt.title('BTC Closing Price and Moving Average') plt.show()
出力
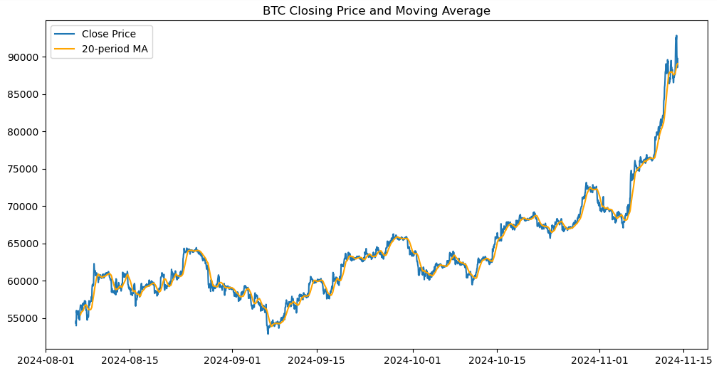
Matplotlibライブラリを使用して、ビットコインの終値と20期間移動平均(MA20)の視覚的表現を作成しました。12x6インチのサイズの図を初期化し、終値をDataFrameのインデックスに対してプロットし、「ClosePrice」というラベルを付けます。20期間の移動平均の2番目のプロットがオレンジ色で重ねられ、「20期間MA」というラベルが付けられています。2つの線を区別するために凡例が追加され、チャートには「BTC終値と移動平均」というタイトルが付けられます。最後に、価格の傾向とそれが移動平均とどのように関係しているかを明確に可視化したプロットが表示されます。
import numpy as np # Add log returns btc_data['Log_Returns'] = (btc_data['<CLOSE>'] / btc_data['<CLOSE>'].shift(1)).apply(lambda x: np.log(x)) # Save the cleaned data btc_data.to_csv('BTCUSD_H1_cleaned.csv')
ここで、ビットコインの終値の対数リターンを計算し、更新されたデータセットを新しいCSVファイルに保存します。対数リターンは、各終値を前期の終値で割り、その結果に自然対数を適用して計算されます。これを実現するために、shift(1)メソッドを使用して各価格を前の価格と合わせ、続いてnp.logを使ったラムダ関数を適用します。 計算された値は「Log-returns」という新しい列に保存され、価格変動のより分析しやすい指標を提供します。これは、特に財務モデリングやリスク分析で有用です。最後に、「Log-returns」列を追加した更新データセットを「BTCUSD-H1-cleaned.csv」という名前で保存し、さらなる分析に備えます。
import seaborn as sns import matplotlib.pyplot as plt # Correlation heatmap sns.heatmap(btc_data.corr(), annot=True, cmap='coolwarm') plt.title('Correlation Heatmap') plt.show()
出力
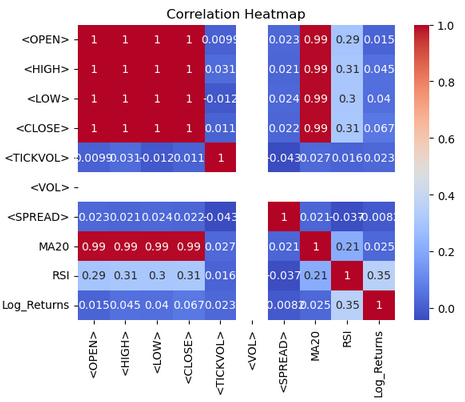
ヒートマップから、SeabornとMatplotlibを使用して、btc-dataデータフレーム内の数値列間の相関関係を可視化します。btc-data.corr()関数は、すべての数値列のペアワイズ相関係数を計算し、それらの間の線形関係を定量化します。sns.heatmap()関数は、この相関行列をヒートマップとして表示します。「annot=True」を指定すると各セルに相関値が表示され、「cmap='coolwarm'」を指定すると、解釈を容易にするために分岐カラーパレットが使用されます。暖色系(赤)は正の相関関係を示し、寒色系(青)は負の相関関係を示します。Matplotlibを使用して「Correlation Heatmap」というタイトルを追加し、plt.show()を使用してプロットを表示します。この可視化により、データセット内のパターンと関係を一目で識別できるようになります。
from sklearn.model_selection import train_test_split # Define features and target variable X = btc_data.drop(columns=['<CLOSE>']) y = btc_data['<CLOSE>'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
機械学習用のbtc-dataデータフレームを訓練サブセットとテストサブセットに分割して準備します。まず、データセットから<CLOSE>列を削除することによって特徴(x)が定義され、ターゲット変数(y)は予測される値を表す<CLOSE>列に設定されます。次に、Scikit-learnのtrain-test-split関数を使用して、データを訓練セットとテストセットに分割します。test-size=0.2で指定されているように、データの80%が訓練に割り当てられ、20%がテストに割り当てられます。random-state=42は、分割が再現可能であることを保証し、異なる実行間で一貫性を維持します。
# Simple Moving Average Crossover Strategy btc_data['Signal'] = (btc_data['MA20'] > btc_data['RSI']).astype(int) btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'].shift(1) * btc_data['Returns'] # Plot cumulative returns btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data[['Cumulative_Strategy', 'Cumulative_Market']].plot(title='Strategy vs. Market Returns') plt.show()
出力
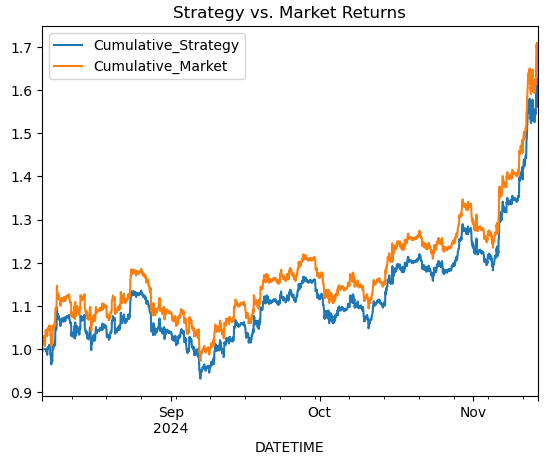
# Calculate short-term and long-term moving averages btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() btc_data['MA50'] = btc_data['<CLOSE>'].rolling(window=50).mean() # Generate signals: 1 for Buy, -1 for Sell btc_data['Signal'] = 0 btc_data.loc[btc_data['MA20'] > btc_data['MA50'], 'Signal'] = 1 btc_data.loc[btc_data['MA20'] < btc_data['MA50'], 'Signal'] = -1 # Shift signal to avoid look-ahead bias btc_data['Signal'] = btc_data['Signal'].shift(1)
# Calculate returns btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'] * btc_data['Returns'] # Calculate cumulative returns btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() # Plot performance import matplotlib.pyplot as plt plt.figure(figsize=(12, 6)) plt.plot(btc_data['Cumulative_Market'], label='Market Returns') plt.plot(btc_data['Cumulative_Strategy'], label='Strategy Returns') plt.title('Strategy vs. Market Performance') plt.legend() plt.show()
出力
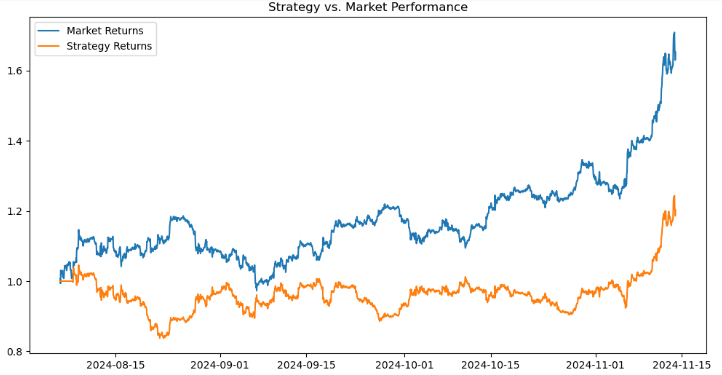
取引戦略のパフォーマンスを市場と比較して評価し、結果を可視化します。まず、pct-change()を使用して<CLOSE>価格の変化率として市場リターンを計算し、それをReturns列に保存します。戦略リターンは、signal列(買いの場合は1、売りの場合は-1、ホールドの場合は0などの取引シグナルを表す)と市場リターンを乗算して計算され、その結果がstrategy-returnsに保存されます。市場と戦略の両方の累積収益は、(1+returns).comprod()を使用して計算されます。これは、市場(Cumulative-market)または戦略(Cumulative-strategy)に従って投資された$1の複利成長をシミュレートします。
# Add RSI from ta.momentum import RSIIndicator btc_data['RSI'] = RSIIndicator(btc_data['<CLOSE>'], window=14).rsi() # Add MACD from ta.trend import MACD macd = MACD(btc_data['<CLOSE>']) btc_data['MACD'] = macd.macd() btc_data['MACD_Signal'] = macd.macd_signal() # Target variable: 1 if next period's close > current close btc_data['Target'] = (btc_data['<CLOSE>'].shift(-1) > btc_data['<CLOSE>']).astype(int)
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, classification_report # Define features and target features = ['MA20', 'MA50', 'RSI', 'MACD', 'MACD_Signal'] X = btc_data.dropna()[features] y = btc_data.dropna()['Target'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train a Random Forest Classifier model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train, y_train) # Evaluate the model y_pred = model.predict(X_test) print("Accuracy:", accuracy_score(y_test, y_pred)) print(classification_report(y_test, y_pred))
出力
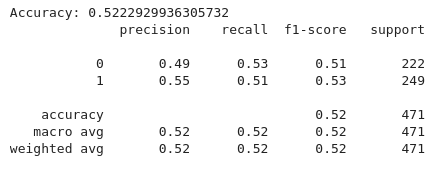
上記のコードから、ランダムフォレスト分類器を使用してテクニカル指標に基づいて取引シグナルを分類する機械学習パイプラインを実装します。まず、20期間および50期間の移動平均(MA20、MA50)、相対力指数(RSI)、およびMACD関連機能(MACD、MACDシグナル)などの指標を含む機能セット(x)が定義されます。目的変数(y)は、目的columnに設定されます。これは通常、買い、売り、またはホールドのシグナルを示します。次に、(x)と(y)の両方のデータが訓練セットとテストセットに分割され、80%が訓練に使用され、20%がテストに使用され、「random-state=42)」によって一貫性が確保されます。
ランダムフォレスト分類器は、100個の決定木(n-estimators=100)で初期化され、訓練データ(X-trainおよびY-train)で訓練されます。 テストセット(X-test)に対するモデルの予測は、正確性を判断するための精度スコアと、各クラスの精度、再現率、F1スコアなどの詳細なメトリックを提供する分類レポートを使用して評価されます。
次に、次のコードを使用してモデルを実装します。
import joblib # Save the model joblib.dump(model, 'btc_trading_model.pkl')
MQL5ですべてをまとめる
MQL5を学習済みモデルを実行するPythonスクリプトに接続するためには、MQL5とPython間の通信チャネルを設定する必要があります。この場合は、WebRequestを使用します。
//+------------------------------------------------------------------+ //| BTC-Big-DataH.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #include <Trade\Trade.mqh> CTrade trade;
取引管理に必要なすべてのインクルードと取引ライブラリ(trade.mqh)。
// Function to get predictions from Python API double GetPrediction(double &features[]) { // Convert the features array to a JSON-like string string jsonRequest = "["; for (int i = 0; i < ArraySize(features); i++) { jsonRequest += DoubleToString(features[i], 6); if (i != ArraySize(features) - 1) jsonRequest += ","; } jsonRequest += "]"; // Define the WebRequest parameters string url = "http://127.0.0.1:5000/predict"; string hdrs = {"Content-Type: application/json"}; // Add headers if needed char data[]; StringToCharArray(jsonRequest, data); // Convert JSON request string to char array char response[]; ulong result_headers_size = 0; //-------------------------------------------------------------------------------------- string cookie=NULL; char post[], resultsss[]; // Send the WebRequest int result = WebRequest("POST", url, cookie, NULL, 500, post, 0, resultsss, hdrs); // Handle the response if (result == -1) { Print("Error sending WebRequest: ", GetLastError()); return -1; // Return an error signal } // Convert response char array back to a string string responseString; CharArrayToString(response, (int)responseString); // Parse the response (assuming the server returns a numeric value) double prediction = StringToDouble(responseString); return prediction; }
関数GetPrediction()は、入力特徴量のセットをPythonベースのAPIに送信し、予測を取得します。特徴量はdoubleの配列として渡され、APIの想定される入力形式に合わせてJSON形式の文字列に変換されます。この変換では、特徴量配列を反復処理し、各値をJSONのような配列構造に追加します。DoubleToString関数は、値が小数点以下6桁で表されることを保証します。生成されたJSON文字列はchar配列に変換されます。
次に、関数はWebリクエストを使用してAPIエンドポイント(http://127.0.0.1:5000/predict)にPOSTリクエストを送信する準備をします。必要なパラメータが定義されています。 API応答が受信されると、CharArrayToStringを使用して文字列に変換されます。Web要求が失敗した場合、エラーがログに記録され、関数は-1を返します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick(){ // Calculate indicators double MA20 = iMA(_Symbol, PERIOD_CURRENT, 20, 0, MODE_SMA, PRICE_CLOSE); double MA50 = iMA(_Symbol, PERIOD_CURRENT, 50, 0, MODE_SMA, PRICE_CLOSE); double RSI = iRSI(_Symbol, PERIOD_CURRENT, 14, PRICE_CLOSE); // Declare arrays to hold MACD data double MACD_Buffer[1], SignalLine_Buffer[1], Hist_Buffer[1]; // Get MACD handle int macd_handle = iMACD(NULL, 0, 12, 26, 9, PRICE_CLOSE); if (macd_handle != INVALID_HANDLE) { // Copy the most recent MACD values into buffers if (CopyBuffer(macd_handle, 0, 0, 1, MACD_Buffer) <= 0) Print("Failed to copy MACD"); if (CopyBuffer(macd_handle, 1, 0, 1, SignalLine_Buffer) <= 0) Print("Failed to copy Signal Line"); if (CopyBuffer(macd_handle, 2, 0, 1, Hist_Buffer) <= 0) Print("Failed to copy Histogram"); } // Assign the values from the buffers double MACD = MACD_Buffer[0]; double SignalLine = SignalLine_Buffer[0]; // Assign features double features[5]; features[0] = MA20; features[1] = MA50; features[2] = RSI; features[3] = MACD; features[4] = SignalLine; // Get prediction double signal = GetPrediction(features); if (signal == 1){ MBuy(); // Adjust lot size } else if (signal == -1){ MSell(); } }
OnTickは、トレンドの方向を追跡するための20期間および50期間の単純移動平均(MA20およびMA50)と、市場の勢いを測定するための14期間の相対力指数(RSI)など、主要なテクニカル指標を計算することから始まります。さらに、iMACD関数を使用してMACDライン、シグナルライン、ヒストグラムの値を取得し、MACDハンドルを検証した後、これらの値をバッファに保存します。これらの計算された指標はfeatures配列に組み立てられ、GetPrediction関数を通じてアクセスされる機械学習モデルの入力として機能します。このモデルは取引アクションを予測し、買いシグナルの場合は1を、売りシグナルの場合は-1を返します。予測に基づいて、関数はMBuyによる買い取引またはMSell()による売り取引のいずれかを実行します。
Python API
以下は、BTC取引の決定のために、事前訓練済みの機械学習モデルからの予測を提供するためにFlaskを使用するWeb APIです。
from flask import Flask, request, jsonify import joblib import pandas as pd # Load the model model = joblib.load('btc_trading_model.pkl') app = Flask(__name__) @app.route('/predict', methods=['POST']) def predict(): data = request.json df = pd.DataFrame(data) prediction = model.predict(df) return jsonify(prediction.tolist()) app.run(port=5000)
結論
要約すると、ビッグデータ処理、機械学習、自動化を組み合わせて、包括的な取引ソリューションを開発しました。過去のBTC/USDデータを使用し、それを処理およびクリーニングして、移動平均、RSI、MACDなどの重要な特徴を抽出しました。この処理されたデータを基に、取引シグナルを予測できる機械学習モデルを訓練しました。訓練されたモデルはFlaskベースのAPIとして実装され、外部システムが予測結果を照会できるようにしました。MQL5では、リアルタイムのインジケーター値を収集し、それらをFlask APIに送信して予測を取得し、返されたシグナルに基づいて取引を実行するエキスパートアドバイザーを実装しました。
この統合された取引ソリューションは、テクニカル指標の精度と機械学習のインテリジェンスを組み合わせることで、トレーダーに力を与えます。履歴データを基に訓練された機械学習モデルを活用することで、システムは市場の動向に適応し、情報に基づいた予測を行い、取引結果を改善することができます。APIを通じてモデルを展開することで、柔軟性が高まり、トレーダーはMQL5などのさまざまなプラットフォームにモデルを統合できるようになります。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/16446
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 CatBoost機械学習モデルをトレンド追従戦略のフィルターとして活用する
CatBoost機械学習モデルをトレンド追従戦略のフィルターとして活用する
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索