
Нейросети — это просто (Часть 79): Агрегирование запросов в контексте состояния (FAQ)

Введение
Большинство из рассмотренных нами ранее методов анализируют состояние окружающей среды как нечто статичное, что вполне соответствует определению марковского процесса. Мы, конечно, наполняли описание состояния окружающей среды историческими данными, чтобы предоставить модели максимум необходимой информации. Но модель не оценивает динамику изменения состояний. В том числе, представленный в предыдущей статье, метод DFFT был разработан для обнаружения объектов на статических изображениях.
Однако, наблюдения за ценовыми движениями свидетельствуют, что динамика изменений порой может указать силу и направление предстоящего движения с достаточной вероятностью. И вполне логично, что мы обращаем свое внимание в сторону методов обнаружения объектов на видео.
Обнаружение объектов на видео обладает рядом особенностей и должно решать проблемы изменения характеристик объектов, вызванное движением, которые не встречаются в области изображений. Одним из решений является использование временной информации и объединение признаков из соседних кадров. В статье "FAQ: Feature Aggregated Queries for Transformer-based Video Object Detectors" предложен новый подход к обнаружению объектов на видео. Авторы статьи улучшают качество запросов к моделям на основе Transformer путем их агрегации. Для достижения этой цели предлагается практичный метод генерации и агрегирования запросов в соответствии с особенностями входных фреймов. Обширные экспериментальные результаты, предоставленные в статье, подтверждают эффективность предложенного метода. Предложенные подходы могут быть расширены на широкий список методов обнаружения объектов на изображениях и видео для повышения их эффективности.
1. Алгоритм Feature Aggregated Queries
Надо сказать, что метод FAQ далеко не первый, который использует архитектуру Transformer для обнаружения объектов на видео. Однако существующие ранее детекторы объектов на видео, использующие Transformer, улучшают представление характеристик объекта путем агрегирования Query. Наивная ванильная идея — усреднять Query из соседних кадров. Query инициализируются случайным образом и используются во время процесса обучения. Соседние Query агрегируются в Δ𝑸 для текущего кадра 𝑰 и представлен как:
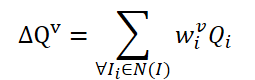
где w — это обучаемые веса для агрегирования.
Простая идея создания обучаемых весов основана на косинусном сходстве характеристик входного кадра. Следуя существующим детекторам объектов на видео, авторы метода FAQ генерируют веса агрегирования по формуле:
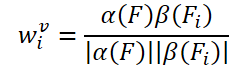
где α, β — функции меппинга, и |⋅| обозначает нормализацию.
Соответствующие особенности текущего кадра 𝑰 и его соседних 𝑰i обозначаются как 𝑭 и 𝑭i. В итоге вероятность определения объекта можно выразить как:
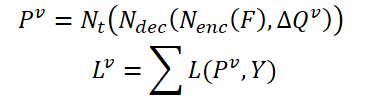
где 𝑷v — прогнозируемая вероятность с помощью агрегированных запросов Δ𝑸v.
В модуле агрегации ванильных запросов существует проблема, связанная с тем, что эти соседние запросы 𝑸i инициализируются случайным образом и не связаны с соответствующими им кадрами 𝑰i. Поэтому соседние запросы 𝑸i не предоставляют достаточно временной или семантической информации, чтобы устранить проблемы ухудшения характеристик, вызванные быстрым движением. Хотя веса wi, используемые для агрегирования, связаны с функциями 𝑭 и 𝑭i, недостаточно ограничений на количество этих случайно инициализированных запросов. Поэтому авторы метода FAQ предлагают обновить модуль агрегации Query до динамической версии, которая добавляет ограничения к запросам и может корректировать веса в соответствии с соседними кадрами. Простая в реализации идея состоит в том, чтобы сгенерировать запросы 𝑸i непосредственно из признаков 𝑭i входного кадра. Однако проведенные авторами метода эксперименты показывают, что этот способ сложно обучать и он всегда дает худшие результаты. В отличие от наивной идеи, упомянутой выше, авторы метода предлагают генерировать новые запросы, адаптивные к исходным данным, из случайно инициализированных Query. Сначала определяем два типа векторов Query: базовые и динамические. В ходе процессов обучения и эксплуатации динамические Query генерируются из базовых Query в соответствии с признаками 𝑭i, 𝑭 подаваемых на вход кадров как:
![]()
где M — это функция сопоставления для построения связи базового запроса Qb c динамическим Qd в соответствии с признаками 𝑭 и 𝑭i.
Сначала разделим базовые запросы на группы по r запросов. Затем для каждой группы мы используем одни и те же веса 𝑽 для определения средневзвешенного запроса в текущей группе:
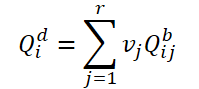
Чтобы построить связь между динамическими запросами 𝑸d и соответствующим кадром 𝑰i, авторы метода предлагают генерировать веса 𝑽, используя глобальные признаки:
![]()
где A — это глобальная операция объединения для изменения размерности тензора признаков и создания признаков глобального уровня,
G — это функция меппинга, позволяющая проецировать глобальные признаки в размерность тензора динамических Query.
Таким образом, процесс динамической агрегации запросов на основе особенностей исходных данных можно обновить следующим образом:
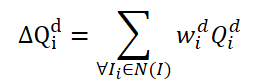
Во время обучения авторы метода предлагают агрегировать как динамические запроса, так и базовые. Оба типа запросов агрегируются с одними весами и генерируются соответствующие прогнозы 𝑷d и 𝑷b. При этом вычисляется ошибка двустороннего согласования для обоих прогнозов. Гиперпараметр γ используется для балансировки влияния ошибок.
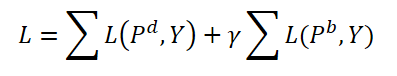
В процессе эксплуатации используются только динамические запросы 𝑸d и соответствующие им прогнозы 𝑷d в качестве окончательных результатов, которые лишь немного усложняют исходные модели.
Ниже представлена авторская визуализация метода.

2. Реализация средствами MQL5
После рассмотрения теоретических аспектов предложенного метода мы переходим к практической части нашей статьи, в которой имплементируем предложенные подходы средствами MQL5.
Как можно заметить из представленного выше описания метода FAQ, основным его вкладом является создание модуля генерации и агрегации тензора динамических запросов в Декодере Transformer. И здесь я хочу напомнить, что авторы метода DFFT отказались от использования декодера ввиду его не эффективности. Что ж, в данной работе мы добавим Декодер и оценим его эффективность в условиях использования динамических Query, предложенных авторами метода FAQ.
2.1 Класс динамических запросов
Для генерации динамических запросов мы создадим новый класс CNeuronFAQOCL. Новый объект будет наследоваться от базового класса нейронных слоев нашей библиотеки CNeuronBaseOCL.
class CNeuronFAQOCL : public CNeuronBaseOCL { protected: //--- CNeuronConvOCL cF; CNeuronBaseOCL cWv; CNeuronBatchNormOCL cNormV; CNeuronBaseOCL cQd; CNeuronXCiTOCL cDQd; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronFAQOCL(void) {}; ~CNeuronFAQOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronFAQOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Здесь надо сказать, что помимо базового набора переопределяемых методов в новом классе мы добавим 5 внутренних нейронных слоев, с назначением которых мы познакомимся в ходе реализации. Все внутренние объекты мы объявили статическими, что позволяет нам оставить пустыми конструктор и деструктор класса.
Инициализация объекта класса осуществляется в методе CNeuronFAQOCL::Init. В параметрах метода мы получаем все ключевые параметры для инициализации внутренних объектов. И в теле метода мы сразу вызываем одноименный метод родительского класса. Как Вы уже знаете, в данном методе осуществляется минимально-необходимый контроль полученных параметров и инициализация унаследованных объектов.
bool CNeuronFAQOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Для нашего класса не указывается функция активации.
activation = None;
Далее мы инициализируем внутренние объекты. И тут следует обратиться к предложенным авторами метода FAQ подходам к генерации динамических Query. Для генерации весов агрегирования базовых Query на основе признаков исходных данных мы создадим 3 слоя. Вначале, признаки исходных данных мы пропустим через сверточный слой, в котором мы проанализируем паттерны соседних состояний окружающей среды.
if(!cF.Init(0, 0, OpenCL, 3 * window, window, 8, fmax((int)input_units - 2, 1), optimization_type, batch)) return false; cF.SetActivationFunction(None);
С целью повышения стабильности процесса обучения и эксплуатации модели мы нормализуем полученные данные.
if(!cNormV.Init(8, 1, OpenCL, fmax((int)input_units - 2, 1) * 8, batch, optimization_type)) return false; cNormV.SetActivationFunction(None);
После чего сожмем данные до размера тензора весовых коэффициентов агрегирования базовых запросов. Чтобы полученные веса были в диапазоне [0,1], мы воспользуемся сигмовидной функцией активации.
if(!cWv.Init(units_count * window_out, 2, OpenCL, 8, optimization_type, batch)) return false; cWv.SetActivationFunction(SIGMOID);
Согласно алгоритму FAQ полученный вектор коэффициентов агрегирования нам предстоит умножить на матрицу базовых Query, которые генерируются случайным способом в начале обучения. В своей реализации я решил пойти немного дальше и обучать базовые запросы. И здесь я не придумал ничего более оригинального, как воспользоваться полносвязным нейронным слоем. На вход слоя мы будем подавать вектор коэффициентов агрегирования, а матрица весов полносвязного слоя представляет собой тензор обучаемых базовых запросов.
if(!cQd.Init(0, 4, OpenCL, units_count * window_out, optimization_type, batch)) return false; cQd.SetActivationFunction(None);
Далее идет агрегирование динамических Query. Авторы метода FAQ в своей статье приводят результаты экспериментов с различными методами агрегирования. Но наиболее эффективным оказалось агрегирование динамических Query с использованием архитектуры Transformer. Придерживаясь приведенных результатов мы используем объект класса CNeuronXCiTOCL для агрегирования динамических запросов.
if(!cDQd.Init(0, 5, OpenCL, window_out, 3, heads, units_count, 3, optimization_type, batch)) return false; cDQd.SetActivationFunction(None);
И с целью исключения излишних операций копирования данных мы осуществим подмену буферов результатов работы нашего класса и градиентов ошибки.
if(Output != cDQd.getOutput()) { Output.BufferFree(); delete Output; Output = cDQd.getOutput(); } if(Gradient != cDQd.getGradient()) { Gradient.BufferFree(); delete Gradient; Gradient = cDQd.getGradient(); } //--- return true; }
После инициализации объекта мы переходим к организации процесса прямого прохода в методе CNeuronFAQOCL::feedForward. Здесь все довольно просто и тривиально. В параметрах метода мы получаем указатель на слой исходных данных с параметрами описания состояния окружающей среды. А в теле метода мы поочередно вызываем аналогичные методы прямого прохода внутренних объектов.
bool CNeuronFAQOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cF.FeedForward(NeuronOCL)) return false;
Сначала мы пропускаем описание окружающей среды через сверточный слой и нормализуем полученные данные.
if(!cNormV.FeedForward(GetPointer(cF))) return false;
После чего генерируем коэффициенты агрегирования базовых Query.
if(!cWv.FeedForward(GetPointer(cNormV))) return false;
Создаем динамические Query.
if(!cQd.FeedForward(GetPointer(cWv))) return false;
И агрегируем их в объекте класса CNeuronXCiTOCL.
if(!cDQd.FeedForward(GetPointer(cQd))) return false; //--- return true; }
Благодаря подмене буферов данных результаты работы внутреннего слоя cDQd отражаются в буфере результатов нашего класса CNeuronFAQOCL без излишних операций копирования. Поэтому мы смело завершаем работу метода.
Далее мы выполнили работу по созданию методов обратного прохода CNeuronFAQOCL::calcInputGradients и CNeuronFAQOCL::updateInputWeights. Аналогично методу прямого прохода, в них мы вызываем одноименные методы внутренних объектов, только в обратном порядке. Поэтому мы не будем детально останавливаться на рассмотрении их алгоритма в данной статье. А с полным кодом всех методов класса генерации динамических запросов CNeuronFAQOCL вы можете самостоятельно ознакомиться во вложении.
2.2 Класс Кросс-Внимания
Следующим этапом нам предстоит создать класс Кросс-Внимания. Надо сказать, что в рамках реализации метода ADAPT мы уже создавали слой кросс-внимания CNeuronMH2AttentionOCL. Только тогда мы осуществляли анализ отношений разных измерений одного тензора. Сейчас же задача немного другая. Нам предстоит оценить зависимости сгенерированных динамических Query из класса CNeuronFAQOCL к сжатому состоянию окружающей среды из Энкодера нашей модели. Иными словами, нам предстоит оценить отношения между 2 разными тензорами.
Для реализации данного функционала мы создадим класс CNeuronCrossAttention, который унаследует часть необходимого функционала от упомянутого выше класса CNeuronMH2AttentionOCL.
class CNeuronCrossAttention : public CNeuronMH2AttentionOCL { protected: uint iWindow_K; uint iUnits_K; CNeuronBaseOCL *cContext; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); virtual bool attentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool AttentionInsideGradients(void); public: CNeuronCrossAttention(void) {}; ~CNeuronCrossAttention(void) { delete cContext; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); //--- virtual int Type(void) const { return defNeuronCrossAttenOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); };
Помимо стандартного набора переопределяемых методов здесь можно заметить 2 новых переменных:
- iWindow_K — размер вектора описания одного элемента 2-го тензора;
- iUnits_K — количество элементов в последовательности 2-го тензора.
Кроме того, мы добавим динамический указатель на вспомогательный нейронный слой cContext, который будет инициализироваться при необходимости в качестве объекта исходных. Так как данный объект выполняет не обязательную вспомогательную роль, то конструктор нашего класса остается пустым. А вот в деструкторе класса мы удалим динамический объект.
~CNeuronCrossAttention(void) { delete cContext; }
Инициализация объекта, как обычно, осуществляется в методе CNeuronCrossAttention::Init. В параметрах метода мы получаем необходимые данные об архитектуре создаваемого слоя. А в теле метода мы вызываем одноименный метод базового класса нейронных слоев CNeuronBaseOCL::Init.
bool CNeuronCrossAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Обратите внимание, что мы вызываем метод инициализации не прямого родительского класса CNeuronMH2AttentionOCL, а базового CNeuronBaseOCL. Это связано с отличиями архитектуры классов CNeuronCrossAttention и CNeuronMH2AttentionOCL. Поэтому далее в теле метода мы инициализируем не только новые, но и унаследованные объекты.
Сначала мы сохраним параметры нашего слоя.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iWindow_K = fmax(window_k, 1); iUnits_K = fmax(units_k, 1); iHeads = fmax(heads, 1); activation = None;
Далее мы инициализируем слой генерации сущностей Query.
if(!Q_Embedding.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, optimization_type, batch)) return false; Q_Embedding.SetActivationFunction(None);
А так же сущностей Key и Value.
if(!KV_Embedding.Init(0, 0, OpenCL, iWindow_K, iWindow_K, 2 * iWindowKey * iHeads, iUnits_K, optimization_type, batch)) return false; KV_Embedding.SetActivationFunction(None);
Прошу не путать генерируемые здесь сущности Query с динамическими запросами, генерируемыми в классе CNeuronFAQOCL.
В рамках реализации метода FAQ сгенерированные динамические запросы мы будем подавать на вход данного класса в качестве исходных данных. И здесь можно сказать, что слой Q_Embedding осуществляет их распределение по головам внимания. А вот слой KV_Embedding будет генерировать сущности из сжатого представления состояния окружающей среды, получаемого от Энкодера.
Но вернемся к нашему методу инициализации класса. После инициализации слоев генерации сущностей мы создадим буфер матрицы коэффициентов зависимости Score.
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits_K * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Тут же мы создаем слой результатов многоголового внимания.
if(!MHAttentionOut.Init(0, 0, OpenCL, iWindowKey * iUnits * iHeads, optimization_type, batch)) return false; MHAttentionOut.SetActivationFunction(None);
И слой агрегации голов внимания.
if(!W0.Init(0, 0, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, optimization_type, batch)) return false; W0.SetActivationFunction(None); if(!AttentionOut.Init(0, 0, OpenCL, iWindow * iUnits, optimization_type, batch)) return false; AttentionOut.SetActivationFunction(None);
Далее следует блок FeedForward.
if(!FF[0].Init(0, 0, OpenCL, iWindow, iWindow, 4 * iWindow, iUnits, optimization_type, batch)) return false; if(!FF[1].Init(0, 0, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, optimization_type, batch)) return false; for(int i = 0; i < 2; i++) FF[i].SetActivationFunction(None);
И в завершении метода инициализации мы организуем подмену буферов.
Gradient.BufferFree(); delete Gradient; Gradient = FF[1].getGradient(); //--- return true; }
После инициализации класса мы, как обычно, переходим к организации прямого прохода. Надо сказать, что в рамках данного класса мы не будем создавать новые кернелы на стороне OpenCL программы. В данном случае мы воспользуемся кернелами, созданными для реализации процессов родительского класса. А вот в методы вызова кернелов нам предстоит внести небольшие корректировки. К примеру, в методе CNeuronCrossAttention::attentionOut мы изменим лишь массивы указания пространства задач и локальных групп в части размере последовательности сущности Key (в коде выделено красным).
bool CNeuronCrossAttention::attentionOut(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits_K/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits_K, 1}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, MHAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Весь же алгоритм прямого прохода верхнеуровнево описан в методе CNeuronCrossAttention::feedForward. В отличии от аналогичного метода родительского класса, данный метод в параметрах получает указатели на 2 объекта нейронных слоев. Которые содержат данные 2 тензоров для анализа зависимостей.
bool CNeuronCrossAttention::feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context) { //--- if(!Q_Embedding.FeedForward(NeuronOCL)) return false; //--- if(!KV_Embedding.FeedForward(Context)) return false;
В теле метода мы сначала генерируем сущности из полученных данных. А затем вызывает метод много-голового внимания.
if(!attentionOut()) return false;
Результаты внимания агрегируем.
if(!W0.FeedForward(GetPointer(MHAttentionOut))) return false;
И суммируем с исходными данными. После чего результат нормализуем в рамках элементов последовательности. В контексте реализации метода FAQ нормализация будет осуществляться в разрезе отдельных динамических запросов.
if(!SumAndNormilize(W0.getOutput(), NeuronOCL.getOutput(), AttentionOut.getOutput(), iWindow)) return false;
Затем данные проходят блок FeedForward.
if(!FF[0].FeedForward(GetPointer(AttentionOut))) return false; if(!FF[1].FeedForward(GetPointer(FF[0]))) return false;
Снова суммируем и нормализуем данные.
if(!SumAndNormilize(FF[1].getOutput(), AttentionOut.getOutput(), Output, iWindow)) return false; //--- return true; }
После успешного выполнения всех выше указанных операций мы завершаем работу метода.
На этом мы завершаем описание реализации прямого прохода и переходим к организации обратного прохода. Здесь мы так же используем кернел, созданный в рамках реализации родительского класса, и вносим точечные правки в метод его вызова CNeuronCrossAttention::AttentionInsideGradients.
bool CNeuronCrossAttention::AttentionInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindowKey, iHeads}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_qg, Q_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kvg, KV_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_outg, MHAttentionOut.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kunits, (int)iUnits_K)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Процесс распределения градиента ошибки через наш слой кросс-внимания организован в методе CNeuronCrossAttention::calcInputGradients. Как и методу прямого прохода, в параметрах методу передаются указатели на 2 слоя с 2 потоками информации.
bool CNeuronCrossAttention::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context) { if(!FF[1].calcInputGradients(GetPointer(FF[0]))) return false; if(!FF[0].calcInputGradients(GetPointer(AttentionOut))) return false;
Благодаря подмене буферов данных градиент ошибки, получаемый от последующего слоя, сразу попадает в буфер градиентов ошибки 2 слоя блока FeedForward. Поэтому нам нет необходимости копировать данные. И мы сразу вызываем методы распределения градиента ошибки внутренних слоев блока FeedForward.
На этом этапе нам предстоит сложить градиент ошибки, полученный от блока FeedForward и последующего нейронного слоя.
if(!SumAndNormilize(FF[1].getGradient(), AttentionOut.getGradient(), W0.getGradient(), iWindow, false)) return false;
Далее мы распределим градиент ошибки по головам внимания.
if(!W0.calcInputGradients(GetPointer(MHAttentionOut))) return false;
И вызовем метод передачи градиента ошибки до сущностей Query, Key и Value.
if(!AttentionInsideGradients()) return false;
Градиент с сущностей Key и Value мы передадим на слой Контекста (Энкодеру).
if(!KV_Embedding.calcInputGradients(Context)) return false;
А от Query на предыдущий слой.
if(!Q_Embedding.calcInputGradients(prevLayer)) return false;
И здесь мы не забываем суммировать градиенты ошибки.
if(!SumAndNormilize(prevLayer.getGradient(), W0.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
После чего завершаем работу метода.
Метод обновления параметров внутренних объектов CNeuronCrossAttention::updateInputWeights довольно прост. В нем лишь осуществляется поочередный вызов одноименных методов внутренних объектов. И я предлагаю Вам самостоятельно ознакомиться с ним во вложении. Там же Вы найдете методы работы с файлами. А так же полный код всех программ и классов, используемых при подготовке данной статьи.
На этом мы завершаем работу по созданию новых классов и переходим к описанию архитектуры модели.
2.3 Архитектура моделей
Архитектура моделей, как всегда, представлена в методе CreateDescriptions. Надо сказать, что архитектура моделей во многом заимствована из реализации метода DFFT. Однако, мы добавили Декодер. И, соответственно, Актер и Критик получают данные от Декодера. Таким образом, для создания описания моделей нам потребуется 4 динамических массива.
bool CreateDescriptions(CArrayObj *dot, CArrayObj *decoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Модель Энкодера (dot) перенесена из предыдущей статьи без изменений. А с её описанием можно ознакомиться здесь.
Декодер (decoder) в качестве исходных данные использует латентные данные Энкодера на уровне слоя позиционного кодирования.
//--- Decoder decoder.Clear(); //--- Input layer CLayerDescription *po = dot.At(LatentLayer); if(!po || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = po.count * po.window; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Напомню, что на данном уровне мы снимаем эмбединги нескольких состояний окружающей среды, сохраненных в локальном стеке с добавленными метками позиционного кодирования. По существу, эти данные содержат последовательность признаков описания состояния окружающей среды за GPTBars свечей. Что можно отождествить с кадрами видео ряда. На основании этих данных мы генерируем динамические Query.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFAQOCL; { int temp[] = {QueryCount, po.count}; ArrayCopy(descr.units, temp); } descr.window = po.window; descr.window_out = 16; descr.optimization = ADAM; descr.step = 4; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
И осуществим Кросс-Внимание.
//--- layer 2 CLayerDescription *encoder = dot.At(dot.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {QueryCount, encoder.count}; ArrayCopy(descr.units, temp); } { int temp[] = {16, encoder.window}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Актер получает данные с Декодера.
//--- Actor actor.Clear(); //--- Input layer encoder = decoder.At(decoder.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = encoder.units[0] * encoder.windows[0]; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Объединяет их с описание состояния счета.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
После чего данные проходят через 2 полносвязных слоя.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И на выходе придаем стохастичности политике Актера.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Модель критика перенесена без изменений, за исключением замены источника исходных данных с Энкодера на Декодер.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(1)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 Советники взаимодействия со средой
При подготовке данной статьи я использовал 3 советника взаимодействия с окружающей средой:
- Research.mq5
- ResearchRealORL.mq5
- Test.mq5
Советник "...\Experts\FAQ\ResearchRealORL.mq5" не привязан к архитектуре моделей. А благодаря тому, что все советнике обучаются и тестируются на анализе одних исходных данных описания окружающей среды, данный советник переносится из статьи в статью без малейших изменений. С полным описанием его кода и подходов к использованию можно познакомиться здесь.
В коде советника "...\Experts\FAQ\Research.mq5" мы добавили модель Декодера.
CNet DOT; CNet Decoder; CNet Actor;
Соответственно, в методе инициализации мы добавили загрузку данной модели и, при необходимости, инициализацию её случайными параметрами.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; //--- if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; } //--- Decoder.SetOpenCL(DOT.GetOpenCL()); Actor.SetOpenCL(DOT.GetOpenCL()); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Обратите внимание, что в данном случае мы не используем модель Критика. В процессе взаимодействия с окружающей средой и сбора данных для обучения его функционал не участвует.
Непосредственно процесс взаимодействия с окружающей средой организован в методе OnTick. В теле метода мы сначала проверяем наступление события открытия нового бара.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Напомню, что весь процесс построен на анализе закрытых свечей.
При наступлении необходимого события мы сначала загружаем исторические данные.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Которые переносим в буфер описания текущего состояния окружающей среды.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Затем собираем данные о состоянии счета и открытых позициях.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Полученные данные группируем в буфер состояния счета.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
Сюда же добавляем гармоники временной метки.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Собранные данные сначала подаем на вход Энкодера.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Результаты работы Энкодера передаем в Декодер.
if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer,(CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
И затем Актеру.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } //--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Мы загружаем действия, спрогнозированные Актером. И исключаем встречные операции.
vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
После чего декодируем прогнозные действия с совершением необходимых торговых действий. Сначала по длинным позициям.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Затем по коротким.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
В завершении метода мы сохраняем в буфер воспроизведения опыта результаты взаимодействия с окружающей средой.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
Остальные методы советника не претерпели изменений.
Аналогичные изменения были внесены в советник "...\Experts\FAQ\Test.mq5. А с полным кодом обоих советников Вы можете самостоятельно ознакомиться во вложении.
2.5 Советник обучения моделей
Обучение моделей осуществляется в советнике "...\Experts\FAQ\Study.mq5". Как и в случае предыдущих советников, структура советника перенесена из прошлых работ. В соответствии с изменениями в архитектуре моделей мы добавили Декодер.
CNet DOT; CNet Decoder; CNet Actor; CNet Critic;
Как можно заметить, в процессе обучения моделей участвует и Критик.
В методе инициализации советника мы сначала загружаем данные для обучения.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
А затем пытаемся загрузить предварительно обученные модели. Если загрузить модели не удается, то создаем новые модели и инициализируем их случайными параметрами.
//--- load models float temp; if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Decoder.Load(FileName + "Dec.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor) || !Critic.Create(critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; }
Все модели переносим в один контекст OpenCL.
OpenCL = DOT.GetOpenCL(); Decoder.SetOpenCL(OpenCL); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
Осуществляем минимальный контроль соответствия архитектуры моделей.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Создаем вспомогательные буфера данных.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
И генерируем пользовательское событие начала процесса обучения.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
В методе деинициализации советника мы сохраняем обученные модели и очищаем память динамических объектов.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); DOT.Save(FileName + "DOT.nnw", 0, 0, 0, TimeCurrent(), true); Decoder.Save(FileName + "Dec.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
Сам же процесс обучения моделей осуществляется в методе Train. В теле метода мы сначала определяем вероятность выбора траекторий в соответствии с их доходностью.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Затем объявим локальные переменные.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
И создадим систему вложенных циклов процесса обучения.
Напомню, что в архитектуре Энкодере предусмотрен слой Эмбединга с внутренним буфером накопления исторических данных. Такого рода архитектурные решения очень чувствительны к исторической последовательности получаемых исходных данных. Поэтому, для обучения моделей мы организуем систему вложенных циклов. Где внешний цикл отсчитывает количество пакетов обучения. А во вложенном цикле в рамках пакета обучения подаются исходные данные в исторической хронологии.
В теле внешнего цикла мы сэмплируем траекторию и состояния начала пакета обучения на ней.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Очищаем внутренний буфер накопления исторических данных.
DOT.Clear();
И определяем состояние окончание пакета обучения.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
После чего организуем вложенный цикл обучения. В теле которого мы сначала загружаем историческое описание состояния окружающей среды из буфера воспроизведения опыта.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
С имеющимися данными осуществляем прямой проход Энкодера и Декодера.
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer, (CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Кроме того, мы загружаем из буфера воспроизведения опыта соответствующее описание состояния счета с переносом данных в соответствующий буфер
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Тут же добавляем гармоники временных меток.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Процесс полностью повторяет подобный из советников взаимодействия с окружающей средой. Только мы не опрашиваем терминал, а все данные загружаем из буфера воспроизведения опыта.
После получения данных мы можем осуществить последовательный прямой проход для Актера и Критика.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(Decoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
За прямым проходом следует обратный проход, в процессе которого осуществляется оптимизация параметров моделей. Сначала мы осуществим обратный проход Актера с минимизацией ошибки до действий из буфера воспроизведения опыта.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) ||
Градиент ошибки от Актера передается к Декодера.
!Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) ||
А тот в свою очередь передает градиент ошибки энкодеру. И тут следует обратить внимание, что Декодер берет исходные данные с 2 слоев Энкодера. И градиент ошибки отдает на 2 соответствующих слоя. Для корректно обновления параметров модели нам необходимо сначала пропустить градиент с латентного слоя.
!DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) ||
И только потом через всю модель Энкодера.
!DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее мы определяем вознаграждение за предстоящий переход.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result);
И оптимизируем параметры Критика с последующей передачей градиента ошибки всем участвующим моделям.
if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient), -1, false) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
В завершении операций внутри системы циклов мы информируем пользователя о ходе обучения и переходим к следующей итерации.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После успешного завершения всех итераций системы циклов обучения моделей мы очищаем поле комментариев на графике.
Comment("");
Выводим в журнал терминала результаты обучения и инициализируем процесс завершения работы советника.
PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем описание алгоритмов используемых программ. С полным их кодом Вы можете самостоятельно ознакомиться во вложении. А мы переходим к заключительной части статьи — тестированию проделанной работы.
3. Тестирование
В данной статье мы познакомились с методом Feature Aggregated Queries и реализовали его подходы средствами MQL5. И теперь пришло время проверить результаты проделанной нами работы. Как всегда, свою модель я обучал и тестировал на исторических данных инструмента EURUSD тайм-фрейм H1. Обучение моделей осуществляется на историческом отрезке за первые 7 месяцев 2023 года. Тестирование обученной модели осуществляется на данных августа 2023 года.
Рассматриваемая в данной статье модель анализирует исходные данные, аналогичные моделям из предыдущих статей. Вектора действий Актера и вознаграждений за совершенные переходы в новое состояние так же идентичны предыдущим статьям. Поэтому, для обучения моделей мы можем воспользоваться буфером воспроизведения опыта, собранным в процессе обучения моделей из предыдущих статей. Для этого достаточно переименовать файл в "FAQ.bd".
Однако, если у вас нет файла от предыдущих работ. Или по каким-либо причинам Вы хотите создать новый, я рекомендую сначала сохранить несколько проходов с использованием истории сделок реальных сигналов. Как это описано в статье, посвященной методу RealORL.
Затем Вы можете дополнить буфер воспроизведения опыта случайными проходами с помощью советника "...\Experts\FAQ\Research.mq5". Для этого Вам необходимо запустить медленную оптимизацию данного советника в тестере стратегий MetaTrader 5 на исторических данных периода обучения.
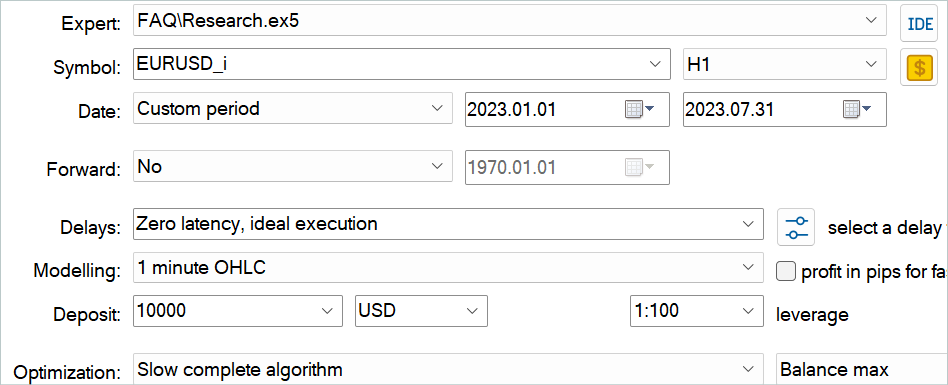
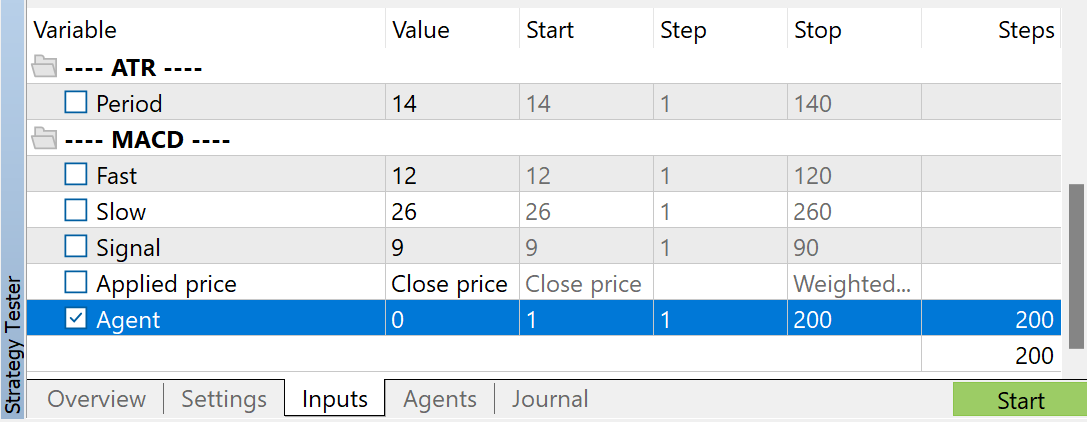
Вы можете использовать любые параметры индикаторов. Но очень важно, чтобы при сборе обучающей выборки и тестировании обученной модели использовались одни параметры. Их же нужно будет сохранить и для эксплуатации модели. При подготовке статьи я использовал параметры всех индикаторов, установленные по умолчанию.
Для регулирования количества собираемых проходов я использую оптимизацию по параметру Agent. Данный параметр добавлен советник только для регулирования проходов оптимизации и не используется в коде советника.
После сбора обучающих данных мы запускаем на графике советник "...\Experts\FAQ\Study.mq5" в режиме реального времени. В коде советника осуществляется обучения моделей с использование собранной обучающей выборки без совершения торговых операций. Поэтому работа советника на реальном графике не отразится на балансе Вашего счета.
Как правило, для обучения моделей я использую итерационный подход. В ходе которого я чередую обучение моделей со сбором дополнительных данных в обучающую выборку. Данный подход примечателен тем, что размеры нашей обучающей выборки ограничены и не способны охватить все разнообразие поведений Агента в окружающей среде. А при последующих запусках советника "...\Experts\FAQ\Research.mq5", в процессе взаимодействия с окружающей средой он руководствуется уже не случайной, а нашей обученной политикой. Таким образом, мы пополняем буфер воспроизведения опыта состояниями и действиями близкими к нашей политики. Тем самым мы исследуем окружающую среду в окрестностях действия нашей политики, аналогично процессу онлайн обучению. А значит при последующем обучении мы получаем не интерполированные, а реальные вознаграждения за действия. Что поможет нашему Актеру скорректировать политику в нужном направлении.
При этом мы периодически контролируем результаты обучения на данных, не входящих в обучающую выборку.
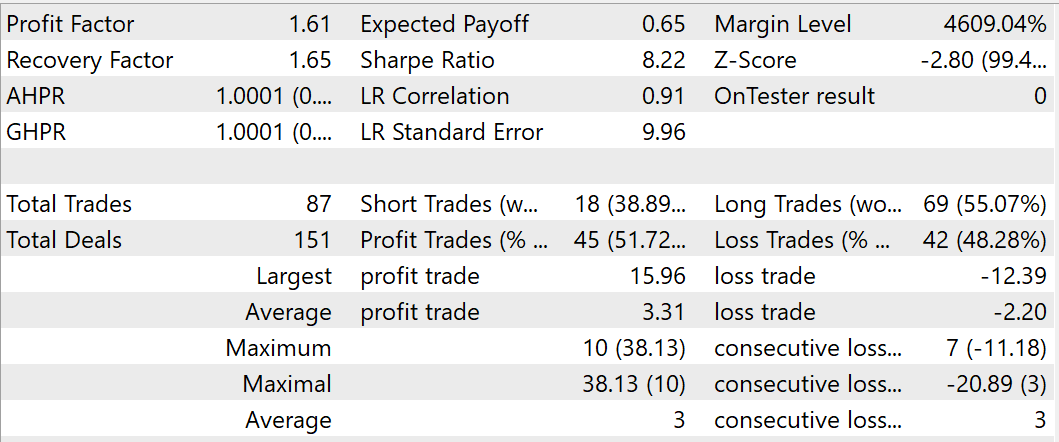
В процессе обучения мне удалось получить модель, способную генерировать прибыль на обучающей и тестовой выборке. По результатам тестирования обученной модели за август 2023 года было совершено 87 сделок, 45 из которых было закрыто с прибылью. Что составило 51.72%. Мы наблюдаем превышение как максимальной, так и средней прибыльной сделки над соответствующими показателями убыточных сделок. В целом за период тестирования был достигнут профит-фактор на уровне 1.61, фактор восстановления — 1.65.
Заключение
В данной статье познакомились с методом обнаружения объектов на видео Feature Aggregated Queries. Авторы данного метода сосредоточились на инициализации запросов и агрегировании их на основе исходных данных для детекторов на основе архитектуры Transformer, чтобы сбалансировать эффективность и производительность модели. Они разработали модуль агрегации запросов, который расширяет их представление для детекторов объектов. Это позволяет повысить их производительность при выполнении задач в области видео.
Кроме того, авторы метода FAQ расширили модуль агрегации запросов до динамической версии, которая может адаптивно генерировать инициализацию запросов и корректировать веса для агрегации запросов в соответствии с исходными данными.
Предложенный метод представляет собой модуль plug-and-play, который можно интегрировать в большинство современных детекторов объектов на базе Трансформатора для решения задач в области видео и других временных последовательностей.
В практической части данной статьи мы реализовали предложенные подходы средствами MQL5. Обучили модель на реальных исторических данных и протестировали её на временном отрезке за пределами обучающей выборки. Результаты наших тестов подтверждают эффективность предложенных подходов. Однако, период обучения и тестирования довольно мал, чтобы делать далеко идущие выводы. Все программы, приведенные в данной статье предназначены только для демонстрации и тестирования предложенных подходов.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования