
Neural networks made easy (Part 79): Feature Aggregated Queries (FAQ) in the context of state

Introduction
Most of the methods we discussed earlier analyze the state of the environment as something static, which fully corresponds to the definition of a Markov process. Naturally, we filled the description of the environment state with historical data to provide the model with as much necessary information as possible. But the model does not evaluate the dynamics of changes in states. This also refers to the method presented in the previous article: DFFT was developed for detecting objects in static images.
However, observations of price movements indicate that the dynamics of changes can sometimes indicate the strength and direction of the upcoming movement with sufficient probability. Logically, we now turn our attention to methods for detecting objects in video.
Object detection in video has a number of certain characteristics and must solve the problem of changes in object features caused by motion, which are not encountered in the image domain. One of the solutions is to use temporal information and combine features from adjacent frames. The paper "FAQ: Feature Aggregated Queries for Transformer-based Video Object Detectors" proposes a new approach to detecting objects in video. The authors of the article improve the quality of queries for Transformer-based models by aggregating them. To achieve this goal, a practical method is proposed to generate and aggregate queries according to the features of the input frames. Extensive experimental results provided in the paper validate the effectiveness of the proposed method. The proposed approaches can be extended to a wide range of methods for detecting objects in images and videos to improve their efficiency.
1. Feature Aggregated Queries Algorithm
The FAQ method is not the first to use the Transformer architecture to detect objects in video. However, existing video object detectors using Transformer improve the representation of object features by aggregating Queries. The naive vanilla idea is to average Queries from neighboring frames. Queries are initialized randomly and used during the training process. Neighboring Queries are aggregated into Δ𝑸 for the current frame 𝑰 and are represented as:
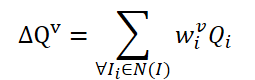
Where w are learnable weighs for aggregation.
The simple idea of creating learnable weights is based on the cosine similarity of the features of the input frame. Following existing video object detectors, the authors of the FAQ method generate aggregation weights using the formula:
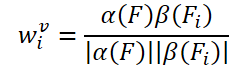
Where α, β are mapping functions, and |⋅| denotes normalization.
Relevant features of the current frame 𝑰 and its neighboring 𝑰i are denoted as 𝑭 and 𝑭i. As a result, the probability of identifying an object can be expressed as:
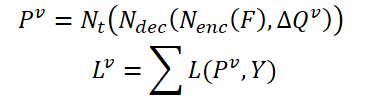
Where 𝑷v is the predicted probability using aggregated queries Δ𝑸v.
There is an issue in the vanilla query aggregation module: these neighboring queries 𝑸i are initialized randomly and are not associated with their corresponding frames 𝑰i. Therefore, neighboring queries 𝑸i do not provide enough temporal or semantic information to overcome performance degradation issues caused by fast motion. Although the weights wi used for aggregation are related to the functions 𝑭 and 𝑭i, there are not enough constraints on the number of these randomly initiated queries. Therefore, the authors of the FAQ method suggest updating the aggregation module Query to a dynamic version that adds constraints to queries and can adjust weights according to neighboring frames. The simple implementation idea is to generate queries 𝑸i directly from the features 𝑭i of the input frame. However, experiments conducted by the authors of the method show that this method is difficult to train and always generates worse results. In contrast to the naive idea mentioned above, the authors of the method propose to generate new queries, adaptive to the original data, from the randomly initialized Queries. First, we define two types of Query vectors: basic and dynamic. During the learning and operating processes, dynamic Queries are generated from basic Queries in accordance with the features 𝑭i, 𝑭 of input frames as:
![]()
Where M is a mapping function for building a relationship of the base query Qb with dynamic Qd in accordance with the features 𝑭 and 𝑭i.
First, let's split the basic queries into groups according to r queries. Then, for each group, we use the same weights 𝑽 to determine the weighted average query in the current group:
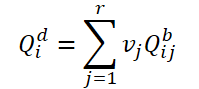
To build a relationship between dynamic queries 𝑸d and the corresponding frame 𝑰i, the authors of the method propose to generate weights 𝑽 using global features:
![]()
Where A is a global pooling operation to change the dimension of the feature tensor and create global-level features,
G is a mapping function that allows you to project global features into the dimension of the dynamic tensor Query.
Thus, the process of dynamic query aggregation based on the source data features can be updated as follows:
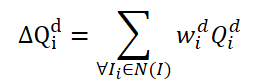
During training, the authors of the method propose to aggregate both dynamic queries and basic ones. Both types of queries are aggregated with the same weights and corresponding predictions 𝑷d and 𝑷b are generated. Here we also calculate the two-way agreement error for both predictions. The hyperparameter γ is used to balance the effect of errors.
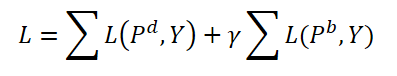
During operation, we use only dynamic queries 𝑸d and their corresponding predictions 𝑷d as final results that only slightly complicate the original models.
Below is the authors' visualization of the method.

2. Implementation using MQL5
We have considered the theoretical aspects of the algorithms. Now, let us move on to the practical part of our article, in which we will implement the proposed approaches using MQL5.
As can be seen from the above description of the FAQ method, its main contribution is the creation of a module for generating and aggregating the dynamic query tensor in the Transformer Decoder. I would like to remind you that the authors of the DFFT method excluded the decoder due to its ineffectiveness. Well, in the current work we will add a Decoder and will evaluate its effectiveness in the context of using dynamic Query entities proposed by the authors of the FAQ method.
2.1 Dynamic Query Class
To generate dynamic queries, we will create a new class CNeuronFAQOCL. The new object will inherit from the neural layer base class CNeuronBaseOCL.
class CNeuronFAQOCL : public CNeuronBaseOCL { protected: //--- CNeuronConvOCL cF; CNeuronBaseOCL cWv; CNeuronBatchNormOCL cNormV; CNeuronBaseOCL cQd; CNeuronXCiTOCL cDQd; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronFAQOCL(void) {}; ~CNeuronFAQOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronFAQOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
In the new method, in addition to the basic set of overridden methods, we will add 5 internal neural layers. We will explain their purposes during implementation. We declared all internal objects static, which allows us to leave the constructor and destructor of the class empty.
A class object is initialized in the CNeuronFAQOCL::Init method. In the method parameters, we get all the key parameters for initializing internal objects. In the body of the method, we call the relevant method of the parent class. As you already know, this method implements the minimum necessary control of the received parameters and initialization of inherited objects.
bool CNeuronFAQOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
There is no activation function specified for our class.
activation = None;
Next, we initialize the internal objects. Here we turn to the approaches to generating dynamic Queries proposed by the authors of the Query method. To generate aggregation weights for the base Queries based on the features of the source data, let's create 3 layers. First, we pass the features of the source data through a convolutional layer, in which we analyze the patterns of neighboring environmental states.
if(!cF.Init(0, 0, OpenCL, 3 * window, window, 8, fmax((int)input_units - 2, 1), optimization_type, batch)) return false; cF.SetActivationFunction(None);
To increase the stability of the model training and operation processes, we normalize the received data.
if(!cNormV.Init(8, 1, OpenCL, fmax((int)input_units - 2, 1) * 8, batch, optimization_type)) return false; cNormV.SetActivationFunction(None);
Then we will compress the data to the size of the weight tensor of basic query aggregation. To ensure that the resulting weights are in the range [0,1], we use a sigmoid activation function.
if(!cWv.Init(units_count * window_out, 2, OpenCL, 8, optimization_type, batch)) return false; cWv.SetActivationFunction(SIGMOID);
According to the FAQ algorithm, we have to multiply the resulting vector of aggregation coefficients by the matrix of basic Queries which are randomly generated at the beginning of training. In my implementation, I decided to go a little further and train basic queries. Well, I haven't come up with anything better than using a fully connected neural layer. We feed the layer a vector of aggregation coefficients, while the weight matrix of the fully connected layer is a tensor of the basic queries being trained.
if(!cQd.Init(0, 4, OpenCL, units_count * window_out, optimization_type, batch)) return false; cQd.SetActivationFunction(None);
Next comes the aggregation of dynamic Queries. FAQ method authors in their paper present the results of experiments with various aggregation methods. The most effective was the dynamic Query aggregation using the Transformer architecture. Following the above results, we use the CNeuronXCiTOCL class object for aggregating dynamic queries.
if(!cDQd.Init(0, 5, OpenCL, window_out, 3, heads, units_count, 3, optimization_type, batch)) return false; cDQd.SetActivationFunction(None);
To eliminate unnecessary data copying operations, we replace the results buffers of our class and error gradients.
if(Output != cDQd.getOutput()) { Output.BufferFree(); delete Output; Output = cDQd.getOutput(); } if(Gradient != cDQd.getGradient()) { Gradient.BufferFree(); delete Gradient; Gradient = cDQd.getGradient(); } //--- return true; }
After initializing the object, we move on to organizing the feed-forward process in the CNeuronFAQOCL::feedForward method. Everything here is quite simple and straightforward. In the method parameters, we receive a pointer to the source data layer with parameters for describing the state of the environment. In the body of the method, we alternately call the relevant feed-forward methods for internal objects.
bool CNeuronFAQOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cF.FeedForward(NeuronOCL)) return false;
We first transfer the description of the environment through a convolutional layer and normalize the resulting data.
if(!cNormV.FeedForward(GetPointer(cF))) return false;
Then we generate aggregation coefficients of the base Queries.
if(!cWv.FeedForward(GetPointer(cNormV))) return false;
Creating dynamic Queries.
if(!cQd.FeedForward(GetPointer(cWv))) return false;
Aggregating them in the CNeuronXCiTOCL class object.
if(!cDQd.FeedForward(GetPointer(cQd))) return false; //--- return true; }
Since we have the substitution of data buffers, the results of the internal layer cDQd are reflected in the results buffer of our CNeuronFAQOCL class without unnecessary copying operations. Therefore, we can complete the method.
Next, we create the backpropagation methods CNeuronFAQOCL::calcInputGradients and CNeuronFAQOCL::updateInputWeights. Similar to the feed-forward method, here we call the relevant methods on internal objects, but in reverse order. Therefore, we will not consider in detail their algorithm in this article. You can study the complete code of all methods of the dynamic query generation class CNeuronFAQOCL using the attchments to the article.
2.2 Cross-Attention Class
The next step is to create a Cross-Attention class. Earlier, within the framework of the implementation of the ADAPT method, we already created a cross-attention layer CNeuronMH2AttentionOCL. However, that time we analyzed the relationships between different dimensions of one tensor. Now the task is a little different. We need to evaluate the dependencies of the generated dynamic Queries from the CNeuronFAQOCL class to the compressed state of the environment from the Encoder of our model. In other words, we need to evaluate the relationship between 2 different tensors.
To implement this functionality we will create a new class CNeuronCrossAttention, which will inherit part of the necessary functionality from the CNeuronMH2AttentionOCL class mentioned above.
class CNeuronCrossAttention : public CNeuronMH2AttentionOCL { protected: uint iWindow_K; uint iUnits_K; CNeuronBaseOCL *cContext; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); virtual bool attentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool AttentionInsideGradients(void); public: CNeuronCrossAttention(void) {}; ~CNeuronCrossAttention(void) { delete cContext; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); //--- virtual int Type(void) const { return defNeuronCrossAttenOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); };
In addition to the standard set of overridden methods, you can notice 2 new variables here:
- iWindow_K — the size of the description vector for one element of the 2nd tensor;
- iUnits_K — the number of elements in the sequence of of the 2nd tensor.
Additionally, we will add a dynamic pointer to the auxiliary neural layer cContext, which will be initialized as a source object if necessary. Since this object performs an optional auxiliary role, the constructor of our class remains empty. But in the class destructor, we need to delete the dynamic object.
~CNeuronCrossAttention(void) { delete cContext; }
As usual, the object is initialized in the CNeuronCrossAttention::Init method. In the method parameters, we obtain the necessary data about the architecture of the created layer. In the body of the method, we call the relevant method of the base neural layer class CNeuronBaseOCL::Init.
bool CNeuronCrossAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Please note that we are calling the initialization method not of the direct parent class CNeuronMH2AttentionOCL, but of the base class CNeuronBaseOCL. This is due to differences in the architectures of the CNeuronCrossAttention and CNeuronMH2AttentionOCL classes. Therefore, further in the body of the method we initialize not only new, but also inherited objects.
First, we save our layer settings.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iWindow_K = fmax(window_k, 1); iUnits_K = fmax(units_k, 1); iHeads = fmax(heads, 1); activation = None;
Next we initialize the Query entity generation layer.
if(!Q_Embedding.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, optimization_type, batch)) return false; Q_Embedding.SetActivationFunction(None);
Perform the same for the Key and Value entities.
if(!KV_Embedding.Init(0, 0, OpenCL, iWindow_K, iWindow_K, 2 * iWindowKey * iHeads, iUnits_K, optimization_type, batch)) return false; KV_Embedding.SetActivationFunction(None);
Please do not confuse the Query entities generated here with dynamic queries generated in the CNeuronFAQOCL class.
As part of the implementation of the FAQ method, we will input the generated dynamic queries into this class as initial data. We can say here that the Q_Embedding layer distributes them among attention heads. And the KV_Embedding layer generates entities from a compressed representation of the environmental state received from the Encoder.
But let's return to our class initialization method. After initializing the entity generation layers, we will create a dependency coefficient matrix buffer Score.
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits_K * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Here we also create a layer of the multiheaded attention results.
if(!MHAttentionOut.Init(0, 0, OpenCL, iWindowKey * iUnits * iHeads, optimization_type, batch)) return false; MHAttentionOut.SetActivationFunction(None);
And a layer of aggregation of attention heads.
if(!W0.Init(0, 0, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, optimization_type, batch)) return false; W0.SetActivationFunction(None); if(!AttentionOut.Init(0, 0, OpenCL, iWindow * iUnits, optimization_type, batch)) return false; AttentionOut.SetActivationFunction(None);
Next comes the FeedForward block.
if(!FF[0].Init(0, 0, OpenCL, iWindow, iWindow, 4 * iWindow, iUnits, optimization_type, batch)) return false; if(!FF[1].Init(0, 0, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, optimization_type, batch)) return false; for(int i = 0; i < 2; i++) FF[i].SetActivationFunction(None);
At the end of the initialization method, we organize the substitution of buffers.
Gradient.BufferFree(); delete Gradient; Gradient = FF[1].getGradient(); //--- return true; }
After initializing the class, we, as usual, proceed to organizing the feed-forward pass. Within this class, we will not create new kernels on the OpenCL program side. In this case, we will use kernels created to implement processes of the parent class. However, we need to make some minor adjustments to the methods for calling the kernels. For example, in the CNeuronCrossAttention::attentionOut method, we will only change the arrays indicating the task space and local groups in terms of the size of the Key entity sequence (highlighted in the code in red).
bool CNeuronCrossAttention::attentionOut(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits_K/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits_K, 1}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, MHAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
The entire feed-forward algorithm is described at the top level, in the CNeuronCrossAttention::feedForward method. Unlike the relevant method of the parent class, this method receives pointers to 2 objects of neural layers in its parameters. They contain the data of 2 tensors for dependence analysis.
bool CNeuronCrossAttention::feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context) { //--- if(!Q_Embedding.FeedForward(NeuronOCL)) return false; //--- if(!KV_Embedding.FeedForward(Context)) return false;
In the method body, we first generate entities from the received data. Then we call the multi-head attention method.
if(!attentionOut()) return false;
We aggregate the results of attention.
if(!W0.FeedForward(GetPointer(MHAttentionOut))) return false;
And sum them up with the source data. After that we normalize the result within the elements of the sequence. In the context of the FAQ method implementation, normalization will be performed in the context of individual dynamic queries.
if(!SumAndNormilize(W0.getOutput(), NeuronOCL.getOutput(), AttentionOut.getOutput(), iWindow)) return false;
The data then passes through the FeedForward block.
if(!FF[0].FeedForward(GetPointer(AttentionOut))) return false; if(!FF[1].FeedForward(GetPointer(FF[0]))) return false;
Then we sum up and normalize the data again.
if(!SumAndNormilize(FF[1].getOutput(), AttentionOut.getOutput(), Output, iWindow)) return false; //--- return true; }
After successfully completing all of the above operations, we terminate the method.
With this, we complete the description of the feed-forward method and move on to organizing the backpropagation pass. Here we also use the kernel created as part of the implementation of the parent class and make specific changes to the kernel call method CNeuronCrossAttention::AttentionInsideGradients.
bool CNeuronCrossAttention::AttentionInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindowKey, iHeads}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_qg, Q_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kvg, KV_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_outg, MHAttentionOut.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kunits, (int)iUnits_K)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
The process of propagating the error gradient through our cross-attention layer is implemented in the CNeuronCrossAttention::calcInputGradients method. Like to the feed-forward method, in parameters to this method we pass pointers to 2 layers with 2 data threads.
bool CNeuronCrossAttention::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context) { if(!FF[1].calcInputGradients(GetPointer(FF[0]))) return false; if(!FF[0].calcInputGradients(GetPointer(AttentionOut))) return false;
Thanks to the substitution of data buffers, the error gradient obtained from the subsequent layer is immediately propagated to the error gradient buffer of the 2nd layer of the FeedForward block. Therefore, we don't need to copy the data. Next, we immediately call the methods for distributing the error gradient of the internal layers of the FeedForward block.
At this stage, we have to add the error gradient received from the block FeedForward and from the subsequent neural layer.
if(!SumAndNormilize(FF[1].getGradient(), AttentionOut.getGradient(), W0.getGradient(), iWindow, false)) return false;
Next, we distribute the error gradient across the attention heads.
if(!W0.calcInputGradients(GetPointer(MHAttentionOut))) return false;
Call the method to propagate the error gradient to the Query, Key and Value entities.
if(!AttentionInsideGradients()) return false;
The gradient from the Key and Value entities is transferred to the Context (Encoder) layer.
if(!KV_Embedding.calcInputGradients(Context)) return false;
The gradient from Query is transfered to the previous layer.
if(!Q_Embedding.calcInputGradients(prevLayer)) return false;
Do not forget to sum up the error gradients.
if(!SumAndNormilize(prevLayer.getGradient(), W0.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
Then we complete the method.
The CNeuronCrossAttention::updateInputWeights method for updating internal object parameters is pretty simple. It just calls the relevant methods on internal objects one by one. You can find them in the attachment. Also, the attachment contains the required file operation methods. In addition, it contains the complete code of all programs and classes used in this article.
With this, we complete the creation of new classes and move on to describing the model architecture.
2.3 Model architecture
The architecture of the models is presented in the CreateDescriptions method. The current architecture of the models is largely copied from the implementation of the DFFT method. However, we have added a Decoder. Therefore, the Actor and Critic receive data from the Decoder. Thus, to create a description of the models, we need 4 dynamic arrays.
bool CreateDescriptions(CArrayObj *dot, CArrayObj *decoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
The Encoder model (dot) has been copied from the previous article without changes. You can find its detailed description here.
The Decoder uses the latent data of the Encoder at the level of the positional encoding layer as input data.
//--- Decoder decoder.Clear(); //--- Input layer CLayerDescription *po = dot.At(LatentLayer); if(!po || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = po.count * po.window; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Let me remind you that at this level, we remove embeddings of several environmental states stored in the local stack with added positional encoding labels. Actually, these embeddings contain a sequence of signs describing the state of the environment for GPTBars candlesticks. This can be compared to the frames of the video series. Based on this data, we generate dynamic Queries.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFAQOCL; { int temp[] = {QueryCount, po.count}; ArrayCopy(descr.units, temp); } descr.window = po.window; descr.window_out = 16; descr.optimization = ADAM; descr.step = 4; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
And implement Cross-Attention.
//--- layer 2 CLayerDescription *encoder = dot.At(dot.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {QueryCount, encoder.count}; ArrayCopy(descr.units, temp); } { int temp[] = {16, encoder.window}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
The Actor receives data from the Decoder.
//--- Actor actor.Clear(); //--- Input layer encoder = decoder.At(decoder.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = encoder.units[0] * encoder.windows[0]; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
And combines it with the description of the account status.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
After that, the data passes through 2 fully connected layers.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
At the output, we add stochasticity to the Actor's policy.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
The critic model has been copied almost as is. The only change is that the source of initial data has been changed from Encoder to Decoder.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(1)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 Environmental Interaction EAs
When preparing this article, I used 3 environmental interaction EAs:
- Research.mq5
- ResearchRealORL.mq5
- Test.mq5
EA "...\Experts\FAQ\ResearchRealORL.mq5" is not linked to the model architecture. Since all the EAs are trained and tested by analyzing the same initial data that describes the environment, this EA is used in different articles without any chnages. You can find a full description of its code and use approaches here.
In the code of the EA "...\Experts\FAQ\Research.mq5", we add a Decoder model.
CNet DOT; CNet Decoder; CNet Actor;
Accordingly, in the initialization method, we add loading of this model and, if necessary, initializing it with random parameters.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; //--- if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; } //--- Decoder.SetOpenCL(DOT.GetOpenCL()); Actor.SetOpenCL(DOT.GetOpenCL()); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Please note that in this case we are not using the Critic model. Its functionality is not involved in the process of interacting with the environment and collecting data for training.
The actual process of interaction with the environment is organized in the OnTick method. In the method body, we first check the occurrence of a new bar opening event.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
The entire process is based on the analysis of closed candles.
When a required event occurs, we first download historical data.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
We transfer the data to the buffer describing the current state of the environment.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Then we collect data on the account status and open positions.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
The received data is grouped into the account status buffer.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
We also add the timestamp harmonics here.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
The collected data is first fed to the Encoder input.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
The Encoder operation results are transferred to the Decoder.
if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer,(CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Then they are transferred to the Actor.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } //--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
We load the actions predicted by the Actor, and exclude counter operations.
vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Then we decode the forecast actions and perform the necessary trading actions. First we implement long positions.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Then Short positions.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
At the end of the method, we save the results of interaction with the environment into the experience replay buffer.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
The rest of the EA's methods have not undergone any changes.
Similar changes have been made to the EA "...\Experts\FAQ\Test.mq5. You can study the full code of both EAs yourself using the codes from the attachment.
2.5 Model training EA
The models are trained in the "...\Experts\FAQ\Study.mq5" EA. As with previously developed EAs, the structure of the EA is copied from previous works. In accordance with changes in the model architecture, we add a Decoder.
CNet DOT; CNet Decoder; CNet Actor; CNet Critic;
As you can see, the Critic also participates in the model training process.
In the EA initialization method, we first load the training data.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Then we try to load the pre-trained models. If we cannot load the models, then we create new models and initialize them with random parameters.
//--- load models float temp; if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Decoder.Load(FileName + "Dec.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor) || !Critic.Create(critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; }
We transfer all models into one OpenCL context.
OpenCL = DOT.GetOpenCL(); Decoder.SetOpenCL(OpenCL); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
We implement minimal control over the compliance of the model architecture.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
We create auxiliary data buffers.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
Generate a custom event for the start of the learning process.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
In the EA deinitialization method, we save the trained models and clear the memory of dynamic objects.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); DOT.Save(FileName + "DOT.nnw", 0, 0, 0, TimeCurrent(), true); Decoder.Save(FileName + "Dec.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
The process of training models is implemented in the Train method. In the body of the method, we first determine the probability of choosing trajectories in accordance with their profitability.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Then we declare local variables.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Then we create a system of nested loops for the learning process.
The Encoder architecture provides an Embedding layer with an internal buffer for accumulating historical data. This kind of architectural solution is very sensitive to the historical sequence of the source data received. Therefore, to train models, we organize a system of nested loops. The outer loop counts the number of training batches. In a nested loop within the training batch, the initial data is fed in historical chronology.
In the body of the outer loop, we sample a trajectory and the state to start the training batch.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Clearing the internal buffer used for the accumulation of historical data.
DOT.Clear();
Determining the state of the end of the training package.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
Then we organize a nested learning loop. In its body, we first load a historical description of the environment state from the experience replay buffer.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
With the available data, we run a feed-forward pass through the Encoder and Decoder.
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer, (CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
We also load the corresponding description of the account state from the experience replay buffer and transfer the data to the appropriate buffer
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Adding the timestamp harmonics.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
The process completely repeats that of the EAs for interaction with the environment. However, we do not poll the terminal but load all the data from the experience replay buffer.
After receiving the data, we can perform a sequential feed-forward pass for the Actor and Critic.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(Decoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
The feed-forward pass is followed by a backpropagation pass, during which the model parameters are optimized. First, we will perform a backpropagation pass of the Actor to minimize the error till the actions from the experience replay buffer.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) ||
The error gradient from the Actor is transfered to the Decoder.
!Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) ||
The Decoder, in turn, transmits the error gradient to the Encoder. Pay attention that the Decoder takes the initial data from 2 layers of the Encoder and transmits the error gradient to 2 corresponding layers. To correctly update the model parameters, we need to first propagate the gradient from the latent layer.
!DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) ||
And only then - through the entire Encoder model.
!DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Next, we determine the reward for the upcoming transition.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result);
And we optimize the Critic parameters with subsequent transmission of the error gradient to all participating models.
if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient), -1, false) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
At the end of the operations within the loop system, we inform the user about the training progress and move on to the next iteration.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
After successfully completing all iterations of the model training loop system, we clear the comments field on the chart.
Comment("");
We also print model training results to the log and initiate EA termination.
PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
This concludes the description of the algorithms of the programs used. The full codes of these EAs are attached below. We now move on to the final part of the article, in which we will test the algorithm.
3. Testing
In this article, we got acquainted with the Feature Aggregated Queries method and implemented its approaches using MQL5. Now it's time to evaluate the results of the work we have done. As always, I trained and tested my model on historical data of the EURUSD instrument with the H1 timeframe. The models are trained on a historical period for the first 7 months of 2023. To test the trained models, we use historical data from August 2023.
The model discussed in this article analyzes input data similar to the models from previous articles. The vectors of the Actor actions and rewards for completed transitions to a new state are also identical to the previous articles. Therefore, to train models, we can use the experience replay buffer collected while training the models from previous articles. For this, we rename the file to "FAQ.bd".
However, if you do not have a file from previous works or you want to create a new one for some reasons, I recommend first saving a few passes using the trade history of real signals. This was described in the article describing the RealORL method.
Then you can supplement the experience replay buffer with random passes using the EA "...\Experts\FAQ\Research.mq5". For this, run slow optimization of this EA in the MetaTrader 5 Strategy Tester on historical data from the training period.
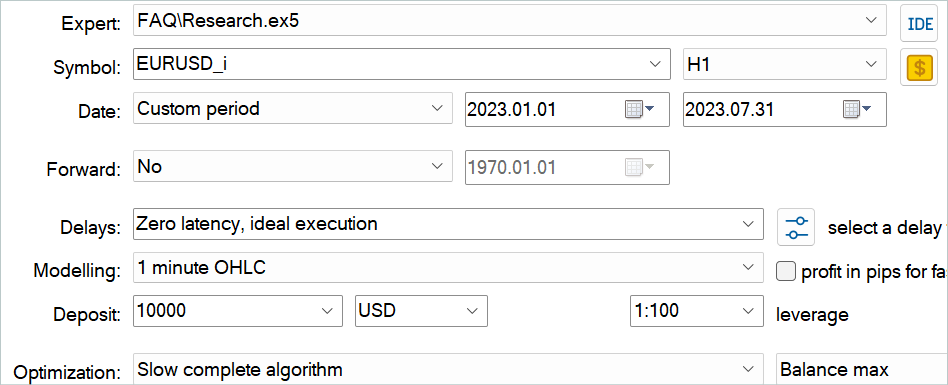
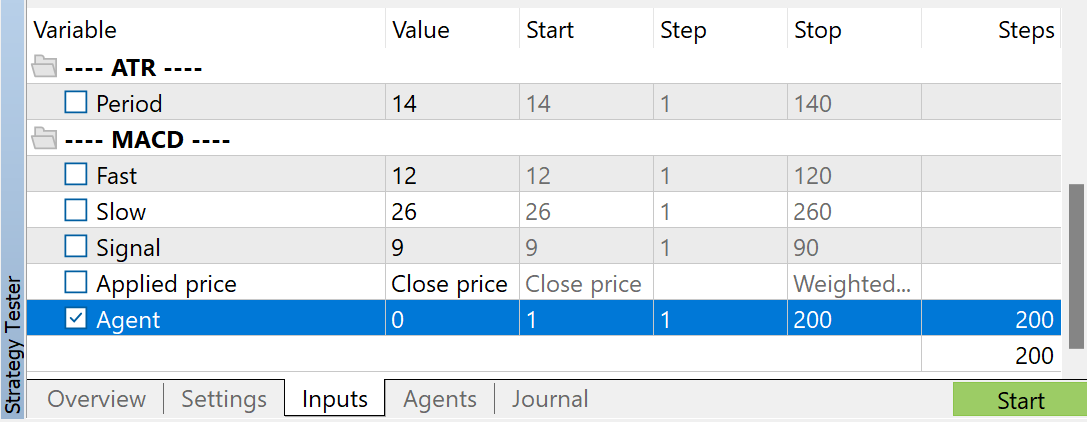
You can use any indicator parameters. However, make sure to use the same parameters when collecting a training dataset and testing the trained model. Also, save the parameters for the model operation. When preparing this article, I used the default settings for all indicators.
To regulate the number of collected passes, I use optimization for the Agent parameter. This parameter was added to the EA only to regulate optimization passes and is not used in the EA code.
After collecting training data, we run the EA "...\Experts\FAQ\Study.mq5" on the chart in real time. The EA trains models using the collected training dataset without performing trading operations. Therefore, the EA operation on a real chart will not affect your account balance.
Typically, I use an iterative approach to train models. During this process, I alternate training models with collecting additional data into the training set. With this approach, the size of our training dataset is limited and is not able to cover the entire variety of Agent behaviors in the environment. During the next launches of the EA "...\Experts\FAQ\Research.mq5", in the process of interaction with the environment, it is no longer guided by random policy. Our trained policy is used instead. Thus, we replenish the experience replay buffer with states and actions close to our policy. By doing so, we explore the environment around our policy, similar to the online learning process. This means that during subsequent training, we receive real rewards for actions instead of interpolated ones. This will help our Actor adjust the policy in the right direction.
At the same time, we periodically monitor training results on data not included in the training dataset.
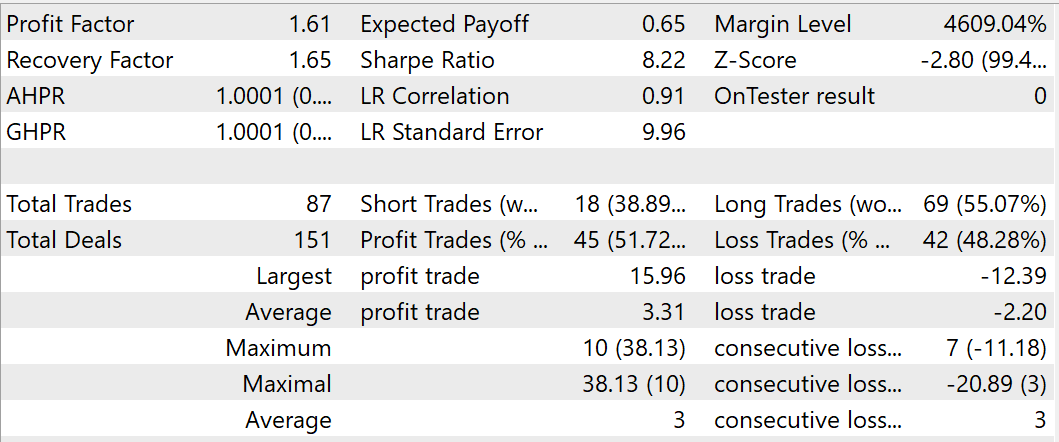
During the training process, I managed to obtain a model capable of generating profit on the training and test datasets. While testing the trained model, during August 2023, the EA performed 87 trades, 45 of which were closed with a profit. This is equal to 51.72%. The profits of the highest and average profitable deal exceed the corresponding values of losing trades. During the testing period, the EA reached a profit factor of 1.61 and a recovery factor of 1.65.
Conclusion
In this article, we got acquainted with the Feature Aggregated Queries (FAQ) method for detecting objects in video. The authors of this method focused on initializing queries and aggregating them based on input data for detectors based on the Transformer architecture to balance the efficiency and performance of the model. They developed a query aggregation module that extends their representation to object detectors. This improves their performance on video tasks.
In addition, the authors of the FAQ method have extended the query aggregation module to a dynamic version, which can adaptively generate query initializations and adjust query aggregation weights according to the source data.
The proposed method is a plug-and-play module that can be integrated into most modern Transformer-based object detectors to solve problems in video and other time sequences.
In the practical part of this article, we implemented the proposed approaches using MQL5. We trained the model on real historical data and tested it on a time period outside the training set. Our test results confirm the effectiveness of the proposed approaches. However, the training and testing period is quite short to draw any specific conclusions. All the programs presented in this articles are intended only to demonstrate and test the proposed approaches.
References
Programs used in the article
| # | Issued to | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA for collecting examples |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA for collecting examples using the Real-ORL method |
| 3 | Study.mq5 | Expert Advisor | Model training EA |
| 4 | Test.mq5 | Expert Advisor | Model testing EA |
| 5 | Trajectory.mqh | Class library | System state description structure |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Code Base | OpenCL program code library |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/14394
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

 Creating an Interactive Graphical User Interface in MQL5 (Part 1): Making the Panel
Creating an Interactive Graphical User Interface in MQL5 (Part 1): Making the Panel
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use