
Нейросети — это просто (Часть 67): Использование прошлого опыта для решения новых задач

Введение
Обучение с подкреплением построено на максимизации вознаграждения, получаемого от окружающей среды в процессе взаимодействия с ней. Очевидно, что в процессе обучения необходимо постоянное взаимодействие с окружающей средой. Но ситуации бывают разные. И при решении некоторых задач могут встречаться различные ограничения на подобное взаимодействие с окружающей средой. В таких ситуациях нам на помощь приходят алгоритмы офлайн обучения с подкреплением. Они позволяют обучать модели на ограниченном архиве траекторий, собранном при предварительном взаимодействии с окружающей средой в период её доступности.
Конечно, офлайн обучение с подкреплением не лишено недостатков. В частности, проблема изучения окружающей среды становится ещё более остро ввиду ограниченности обучающей выборки, которая попросту не в состоянии вместить всю многогранность окружающей среды. Особенно остро это проявляется в сложных стохастических средах. С одним из вариантов решения данной проблемы (метод ExORL) мы познакомились в предыдущей статье.
Однако, порой ограничения на взаимодействия с окружающей средой могут быть довольно критичны. Процесс исследования окружающей среды может сопровождаться положительными и отрицательными вознаграждениями. Отрицательные вознаграждения могут быть крайне нежелательны и сопровождаться к финансовыми убытками или какими-либо другими нежелательными потерями, на которые вы не можете пойти. Но задачи довольно редко "рождаются на пустом месте". Чаще всего мы оптимизируем существующий процесс. И в наш "век информационных технологий" практически всегда можно найти опыт взаимодействия с исследуемой окружающей средой в процессе решения задач, подобных поставленной перед нами. Возможно использование данных реального взаимодействия с окружающей средой, которые могут в той или иной степени покрывать требуемое пространство действий и состояний. Об экспериментах с использованием подобного опыта для решения новых задач при управлении реальными роботами рассказывается в статье "Real World Offline Reinforcement Learning with Realistic Data Source". В своей работе авторы статьи предлагают новый фреймворк обучения моделей Real-ORL.
1. Фреймворк Real-ORL
Офлайн обучение с подкреплением (ORL) моделирует среду Марковского процесса принятия решений. При этом предполагается наличие доступа к предварительно сгенерированному набору данных в виде траекторий, собранных с использованием одной или смеси поведенческих политик. Цель ORL — использовать офлайн набор данных для обучения почти оптимальной политики π. В общем случае отсутствует возможность обучения оптимальной политики π* из-за недостаточного исследования и ограниченности обучающего набора данных. В этом случае мы стремимся найти лучшую политику, которую возможно обучить на основе доступного набора данных.
Большинство алгоритмов офлайн обучения с подкреплением включают в себя некую форму регуляризации или консерватизма. Которые могут принимать следующие формы, но не ограничиваться ими:
- Регуляризация градиента политики;
- Приближенное динамическое программирование;
- Обучение с использованием модели окружающей среды.
Авторы фреймворка Real-ORL не предлагают новые алгоритмы обучения моделей. В своей работе они исследуют спектр ранее представительных алгоритмов ORL и оценивают их эффективность на физическом роботе в реалистичных сценариях использования. Авторы фреймворка отмечают, что проанализированные в статье алгоритмы обучения большей частью ориентированы на симуляцию, используя идеальные наборы данных, независимые и одновременные выборки. Однако такой подход некорректен в реальном стохастическом мире, действия в котором сопровождаются операционными задержками. Что в целом ограничивает использование обученных политик на физических роботах. Ведь неясно, могут ли результаты из симулированных бенчмарков или ограниченной оценки оборудования быть обобщены на процессы в реальном мире. Работа "Real World Offline Reinforcement Learning with Realistic Data Source" направлена на заполнение этого пробела. В ней представлены эмпирические исследования нескольких алгоритмов офлайн обучения с подкреплением на задачах изучения реального мира с акцентом на обобщение вне области обучающей выборки.
В свою очередь, имитационное обучение представляет собой альтернативный подход к обучению управляющих политик для робототехники. В отличие от RL, который обучает политики, оптимизируя вознаграждения, имитационное обучение направлено на повторение демонстраций эксперта. И в большинстве случаев эксплуатирует подходы обучения с учителем, что исключает функцию вознаграждения из процесса обучения. Так же интересно сочетание обучения с подкреплением и имитационного обучения.
В своей работе авторы фреймворка Real-ORL используют офлайн набор данных, состоящий из траекторий от эвристической ручной политики. Траектории были собраны под наблюдением эксперта и представляют собой набор данных достаточно высокого качества. Авторы метода рассматривают офлайн имитационное обучение (клонирование поведения, в частности), в качестве базового алгоритма в своем эмпирическом исследовании.
Для максимальной объективности оценки методов обучения в статье рассматриваются четыре классические манипуляционные задачи, которые представляют собой набор общих вызовов манипуляции. Каждая задача моделируется как MDP с уникальной функцией вознаграждения. И каждый из анализируемых методов обучения применяется для решения всех 4 задач, что ставит все алгоритмы в абсолютно равные условия.
Как уже было сказано выше, сбор обучающих данных осуществляется с использованием политики, разработанной под наблюдением эксперта. В основном были собраны успешные траектории во всех четырех задачах. Авторы фреймворка считают, что сбор субоптимальных траекторий или искажение экспертных траекторий различным шумом не допустимо для робототехники, так как искаженное или случайное поведение небезопасно и вредно для технического состояния оборудования. В то же время использование данных, собранных из различных задач, предлагает более реалистичную среду для применения офлайн обучения с подкреплением на реальных роботах по трем причинам:
- Сбор "случайных/исследовательских" данных на реальном роботе автономно потребует обширных ограничений безопасности, надзора и сопровождения экспертов.
- Привлекать экспертов для записи таких случайных данных в больших количествах имеет меньший смысл, чем использование их для сбора значимых траекторий по реальной задаче.
- Разработка стратегий, специфичных для задачи, и стресс-тестирование способности ORL на основе такого сильного набора данных более жизнеспособно, чем использование компрометированного набора данных.
Авторы фреймворка Real-ORL, чтобы избежать предвзятости в пользу задачи (или алгоритма), заранее заморозили собранный набор данных.
Для обучения политик агентов во всех задач авторы Real-ORL разбивают каждую задачу на более простые этапы, помеченные подцелями. Агент выполняет маленькие шаги к подцелям до тех пор, пока не будут выполнены некоторые критерии, специфические для поставленной задачи. Обученные таким образом политики не достигли теоретически максимально возможных результатов из-за шумов контроллеров и погрешности отслеживания. Тем не менее, они завершают задачу с высокой успешностью и имеют сопоставимую производительность с демонстрациями человека.
Авторы Real-ORL провели эксперименты с использованием более 3000 обучающих траекторий, более 3500 оценочных траекторий и трудозатратами более 270 человеко-часов. И в результате исследований пришли к следующим выводам:
- Для задач за пределами области применения алгоритмы обучения с подкреплением могли обобщаться к областям задач с недостатком данных и к динамическим задачам.
- Изменение производительности ORL после использования разнородных данных склонно различаться в зависимости от агентов, конструкции задачи и характеристик данных.
- Определенные разнородные, независящие от задачи траектории могут обеспечить перекрывающуюся поддержку данных и обеспечивать лучшее обучение, позволяя агентам ORL улучшить свою производительность.
- Лучший агент для каждой задачи — это либо алгоритм ORL, либо паритет между ORL и BC. Приведенные в статье оценки указывают на то, что даже в режиме данных за пределами области применения, более реалистичным для реального мира, офлайн обучение с подкреплением является эффективным подходом.
Ниже представлена авторская визуализация фреймворка Real-ORL.
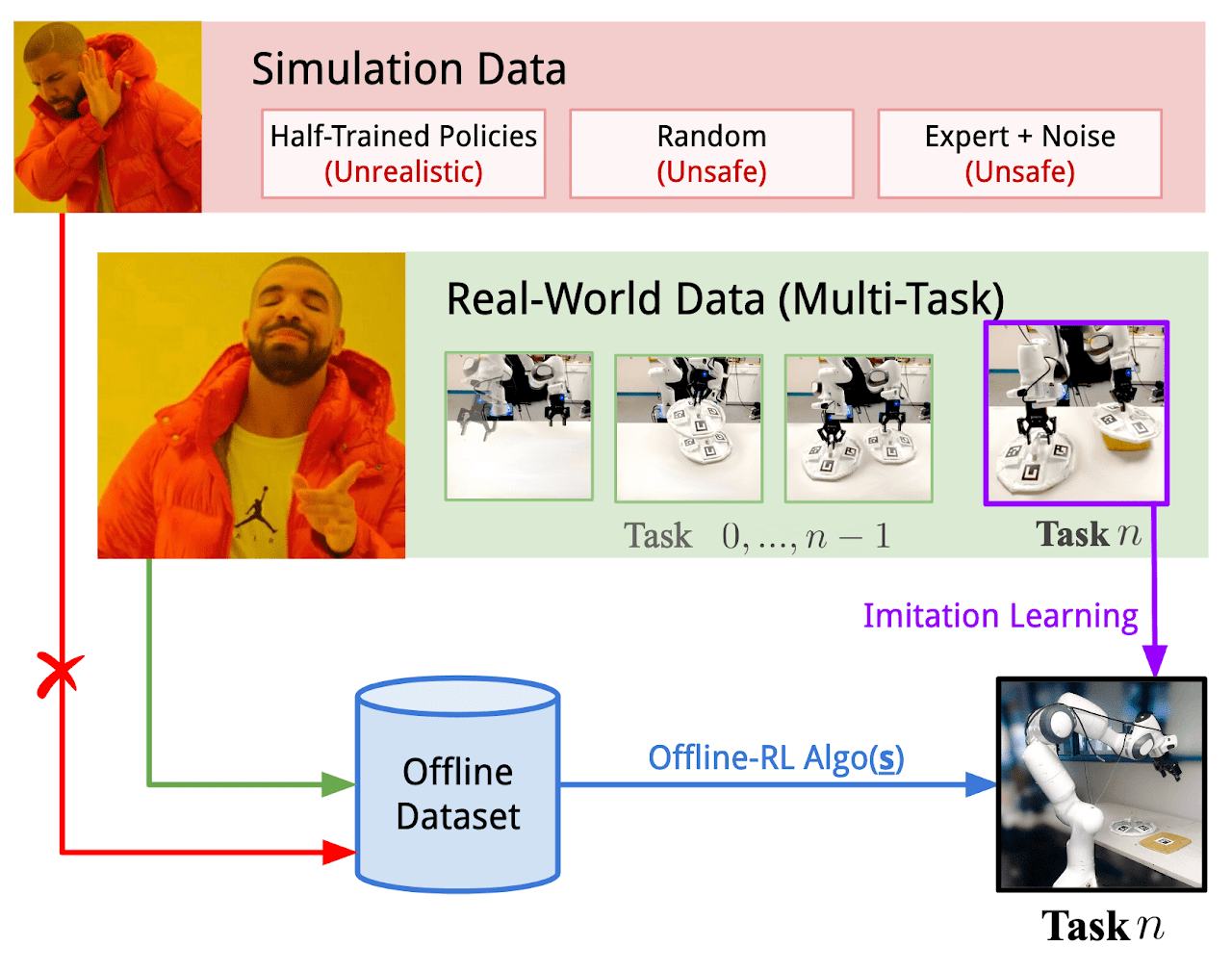
2. Реализация средствами MQL5
В статье "Real World Offline Reinforcement Learning with Realistic Data Source" эмпирически подтверждается эффективность методов офлайн обучения с подкреплением для решения реальных задач. Но мое внимание привлекло использование данных о решении аналогичных или подобных задач для построения своей политики Агента. При этом единственным критерием к данным является окружающая среда. То есть они должны быть собраны в результате взаимодействия с анализируемой нами окружающей средой.
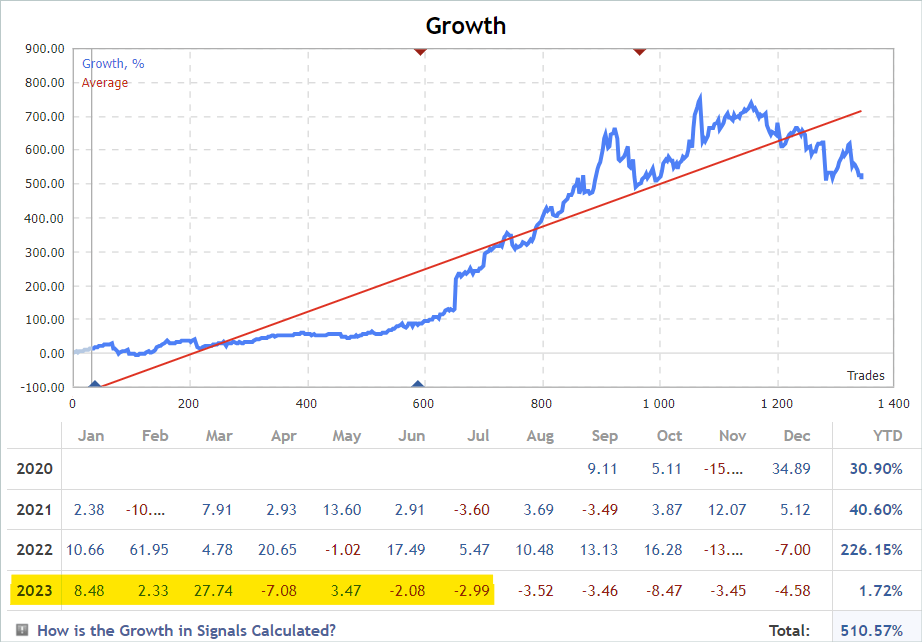
Что это дает нам? Как минимум мы получаем обширную информации об исследовании окружающей среды, в нашем случае финансовых рынков. Мы много раз говорили об одной из основных проблем обучения с подкреплением — исследование окружающей среды. И в то же время перед нами всегда был огромный объем информации, который мы не использовали. Я говорю о сигналах. В представленном ниже скриншоте я намеренно удалили авторов и названием сигналов. В нашем эксперименте единственным критерием к сигналам является наличие сделок на историческом отрезке периода обучения по интересующему нас финансовому инструменту.

Обучение моделей мы осуществляем на временном отрезке за первые 7 месяцев 2023 года инструмента EURUSD. По данным критериям мы и осуществим отбор сигналов. Это могут как платные, так и бесплатные сигналы. Обратите внимание, что в платных сигналах часть истории скрыта. Но скрываются последние сделки. Нас же интересует история, которая открыта.
На вкладке "Счет" мы проверяем наличие операции в интересуемом периоде.
А на вкладке "Статистики" проверяем наличие операций по интересующему нас финансовому инструменту. При этом мы не ищем сигналы, работающие только по интересующему инструменту. Лишние сделки мы исключим позже.
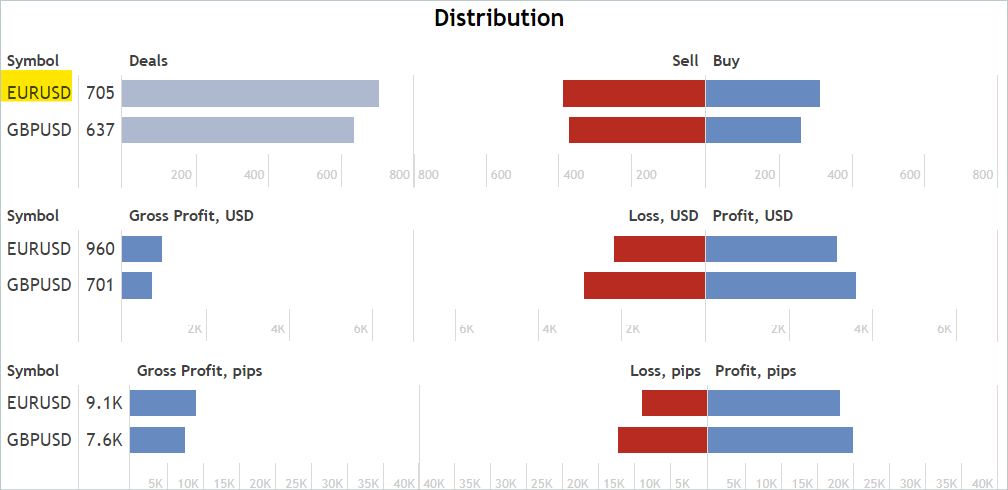
Я согласен, что это довольно приближенный и косвенный анализ. И он не гарантирует наличие сделок по анализируемому финансовому инструменту в интересующем нас историческом периоде. Но вероятность их наличия довольно высока. Такой анализ довольно прост и легко выполним.
При нахождении подходящего сигнала мы переходим на вкладку "История сделок" сигнала и загружаем csv-файл с историей операций.

Обратите внимание, что загруженные файлы необходимо сохранять в общей папке MetaTrader 5 "...\AppData\Roaming\ MetaQuotes\ Terminal\ Common\ Files\". Для удобства использования я создал подкаталог "Signals" и файлы всех сигналов переименовал в "SignalX.csv", где X — порядковый номер сохраненной истории сигнала.
Здесь следует обратить внимание, что рассматриваемый фреймворк Real-ORL подразумевает использование отобранных траекторий в качестве некоторого опыта взаимодействия с окружающей средой. И, отнюдь, не обещает полного клонирования траекторий. Поэтому при отборе траекторий мы не проверяем корреляцию (или какой-либо иной статистический анализ) сделок с используемыми нами индикаторами. По этой же причине не стоит ожидать от обученной модели полного повтора действий наиболее прибыльного или какого-либо другого из используемых сигналов.
Таким образом я отобрал 20 сигналов. Однако, в чистом виде полученные сsv-файлы мы не можем использовать для обучения наших моделей. Нам необходимо сопоставить сделки с историческими данными ценового движения и показаниями индикаторов в момент совершения операций и собрать уже привычные траектории для каждого из используемого сигнала. Данный функционал мы выполним в советнике "...\RealORL\ResearchRealORL.mq5", но прежде проведем небольшую подготовительную работу.
Для записи каждой торговой операции из истории сделок сигнала мы создадим класс CDeal. Данный класс предполагается только для внутреннего использования. И для исключения излишних операций мы опустим обертки обращения к переменным класса. Объявим все переменные публично.
class CDeal : public CObject { public: datetime OpenTime; datetime CloseTime; ENUM_POSITION_TYPE Type; double Volume; double OpenPrice; double StopLos; double TakeProfit; double point; //--- CDeal(void); ~CDeal(void) {}; //--- vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
Переменные класса сопоставимы с полями сделки в MetaTrader 5. Мы лишь опустили переменную для названия инструмента, так как предполагается работа с одним финансовым инструментом. Если же Вы строите мультивалютную модель, то рекомендую добавить название инструмента.
И еще один момент, в сделке мы указываем стоп-лосс и тейк-профит в виде цены, а модель генерирует действие Агента в относительных единицах. Для возможности конвертации данных мы сохраним размер одного пункта инструмента в переменной point.
В конструкторе класса мы заполним переменные начальными значениями. Деструктор класса остается пустым.
void CDeal::CDeal(void) : OpenTime(0), CloseTime(0), Type(POSITION_TYPE_BUY), Volume(0), OpenPrice(0), StopLos(0), TakeProfit(0), point(1e-5) { }
Для конвертации сделки в вектор действий Агента мы создадим метод Action, в параметрах которого будем передавать дату и время открытия текущего бара, цены спроса и предложения, а также интервал анализируемого тайм-фрейма в секундах. Напомню, что анализ рынка и все торговые операции мы осуществляем на открытии каждого бара.
Здесь стоит обратить внимание, что время торговых операций в истории собранных нами сигналов может отличаться от времени открытия бара, используемого нами тайм-фрейма. И если закрытие позиции мы можем осуществить по стоп-лоссу или тейк-профиту внутри бара, то открыть позицию мы можем только на открытии бара. Поэтому здесь мы делаем допущение и небольшую поправку к цене и времени открытия позиции — мы открываем позицию на открытии бара если в истории сигнала она открывается до его закрытия.
Следуя указанной логике, в коде метода если текущее время меньше времени открытия позиции с учетом поправки или больше времени закрытия позиции, то метод вернет нулевой вектор действий Агента.
vector<float> CDeal::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); if((OpenTime - period_seconds) > current || CloseTime <= current) return result;
Обратите внимание, что мы сначала создаем нулевой вектор результатов, а лишь потом осуществляем контроль времени и возвращаем результат. Такой подход позволяет нам далее оперировать с уже сформированным нулевым вектором результатов. Следовательно, при необходимости заполнения вектора действий мы заполняем лишь не нулевые элементы.
Заполнение вектора действий осуществляется в теле оператора выбора switch в зависимости от типа позиции. В случае длинной позиции мы записываем объем операции в элемент с индексом "0". После чего мы проверяем тейк-профит и стоп-лосс на отличие от "0" и, в случае необходимости, конвертируем цену в относительное значение. Полученные значения записываем в элементы с индексами "1" и "2", соответственно.
switch(Type) { case POSITION_TYPE_BUY: result[0] = float(Volume); if(TakeProfit > 0) result[1] = float((TakeProfit - ask) / (MaxTP * point)); if(StopLos > 0) result[2] = float((ask - StopLos) / (MaxSL * point)); break;
Аналогичные операции совершаются и для короткой позиции, но со смещением индексов элементов вектора на 3.
case POSITION_TYPE_SELL: result[3] = float(Volume); if(TakeProfit > 0) result[4] = float((bid - TakeProfit) / (MaxTP * point)); if(StopLos > 0) result[5] = float((StopLos - bid) / (MaxSL * point)); break; }
Сформированный вектор мы возвращаем вызывающей программе.
//--- return result; }
Все сделки одного сигнала мы объединим в классе CDeals. Данный класс будет содержать динамический массив объектов, в который мы добавим экземпляры выше созданного класса CDeal, и 2 метода:
- LoadDeals — загрузки сделок из csv-файла истории;
- Action — формирования вектора действий Агента.
class CDeals { protected: CArrayObj Deals; public: CDeals(void) { Deals.Clear(); } ~CDeals(void) { Deals.Clear(); } //--- bool LoadDeals(string file_name, string symbol, double point); vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
В конструкторе и деструкторе класса мы очищаем динамический массив сделок.
Рассмотрение методов класса предлагаю начать с загрузки истории сделок из csv-файла LoadDeals. В параметрах метода мы передаем имя файла, наименование анализируемого инструмента и размер пункта. Я намеренно вынес наименование инструмента в параметры, так как часто встречаются различия в наименованиях финансовых инструментах у различных брокеров. Следовательно, даже при запуске советника на графике анализируемого инструмента, его наименование может отличаться от унифицированного в файле истории сигнала.
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
В теле метода мы сначала проверяем имя файла и его наличие в общей папке терминалов. В случае отсутствия необходимого файла мы проинформируем пользователя и завершим работу метода с результатом false.
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
Следующим шагом мы проверяем наименование указанного финансового инструмента. И при его отсутствии записываем наименование инструмента графика, на котором запущен советник.
if(symbol == NULL) { symbol = _Symbol; point = _Point; }
После успешного прохождения контрольного блока мы открываем указанный в параметрах метода файл и сразу проверяем результат выполнения операции по полученному значения хендла. Если по какой-либо причине не удалось открыть файл, то информируем пользователя о возникшей ошибке и завершаем работу метода с отрицательным результатом.
ResetLastError(); int handle = FileOpen(file_name, FILE_READ | FILE_ANSI | FILE_CSV | FILE_COMMON, short(';'), CP_ACP); if(handle == INVALID_HANDLE) { PrintFormat("Error of open file %s: %d", file_name, GetLastError()); return false; }
На этом этап подготовительной работы завершен, и мы переходим к организации цикла чтения данных. Перед каждой итерацией цикла мы проверяем достижения конца файла.
FileSeek(handle, 0, SEEK_SET); while(!FileIsEnding(handle)) { string s = FileReadString(handle); datetime open_time = StringToTime(s); string type = FileReadString(handle); double volume = StringToDouble(FileReadString(handle)); string deal_symbol = FileReadString(handle); double open_price = StringToDouble(FileReadString(handle)); volume = MathMin(volume, StringToDouble(FileReadString(handle))); datetime close_time = StringToTime(FileReadString(handle)); double close_price = StringToDouble(FileReadString(handle)); s = FileReadString(handle); s = FileReadString(handle); s = FileReadString(handle);
В теле цикла мы сначала считываем всю информацию по одной сделке и записываем её в локальные переменные. Согласно структуре файла последние 3 элемента содержат комиссию, своп и прибыль по сделке. В нашей траектории мы не используем эти данные, так как время и цена открытия могут отличаться от указанных в истории. А вместе с ними будут отличаться и значения прибыли. К тому же комиссия и свопы зависят от настроек брокера.
Далее мы проверяем соответствие финансового инструмента торговой операции и анализируемого нами, который был передан в параметрах. В случае несоответствия инструментов переходим к следующей итерации цикла.
if(StringFind(deal_symbol, symbol, 0) < 0) continue;
Если же сделка совершена по интересующему нас финансовому инструменту, то мы создаем экземпляр объекта описания сделки.
ResetLastError(); CDeal *deal = new CDeal(); if(!deal) { PrintFormat("Error of create new deal object: %d", GetLastError()); return false; }
И заполняем его, но здесь есть нюанс. Мы без труда можем сохранить:
- тип позиции;
- время открытия и закрытия;
- цену открытия;
- объем сделки;
- размер 1 пункта.
Только вот в истории операций не указаны цены стоп-лосса и тейк-профита. Вместо них указана лишь цена фактического закрытия позиции. Здесь мы используем довольно простую логику:
- Вводим допущение, что позиция закрылась по стоп-лоссу или тейк-профиту.
- В таком случае, если позиция закрылась с прибылью, то закрытие произошло по тейк-профиту. В противном случае закрытие произошло по стоп-лоссу. В соответствующем поле указываем цену закрытия.
- Противоположное поле остается пустым.
deal.OpenTime = open_time; deal.CloseTime = close_time; deal.OpenPrice = open_price; deal.Volume = volume; deal.point = point; if(type == "Sell") { deal.Type = POSITION_TYPE_SELL; if(close_price < open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } } else { deal.Type = POSITION_TYPE_BUY; if(close_price > open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } }
Я полностью понимаю риски торговли без стоп-лоссов, но при этом ожидаю минимизацию данного во время дообучения модели.
Созданное описание сделки мы добавляем в динамический массив и переходим к следующей итерации цикла.
ResetLastError(); if(!Deals.Add(deal)) { PrintFormat("Error of add new deal: %d", GetLastError()); return false; } }
После достижения конца файла мы закрываем его и завершаем работу метода с результатом true.
FileClose(handle); //--- return true; }
Алгоритм метода формирования вектора действий Агента довольно прост. Мы лишь перебираем весь массив сделок и вызываем одноименные методы каждой сделки.
vector<float> CDeals::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); for(int i = 0; i < Deals.Total(); i++) { CDeal *deal = Deals.At(i); if(!deal) continue; vector<float> action = deal.Action(current, ask, bid, period_seconds);
Но и здесь есть некоторые тонкости. Мы допускаем, что в истории сигнала могут быть одновременно открыто несколько позиций, в том числе и разнонаправленных. Поэтому нам необходимо сложить вектора, полученные от всех сделок из архива. Но складывать мы можем только объемы. Простое сложение уровней стоп-лосса и тейк-профита будет некорректным. И тут надо напомнить, что в качестве стоп-лосса и тейк-профита в векторе действий Агента указывается смещение в относительных единицах от текущей цены. С учетом сказанного, при сложении векторов для уровней стоп-лосса и тейк-профита мы берем максимальное отклонение. Незакрытые вовремя объемы будут закрыты советником на открытии новой свечи, так как в этом случае мы ожидаем уменьшение общего объема суммарной позиции.
result[0] += action[0]; result[3] += action[3]; result[1] = MathMax(result[1], action[1]); result[2] = MathMax(result[2], action[2]); result[4] = MathMax(result[4], action[4]); result[5] = MathMax(result[5], action[5]); } //--- return result; }
Итоговый вектор действий Агента мы передаем вызывающей программе и завершаем работу метода.
На этом мы завершаем подготовительную работу и переходим к работе над советником "...\RealORL\ResearchRealORL.mq5". Здесь надо сказать, что советник был создан на базе ранее рассмотренных советников "...\...\Research.mq5" и унаследовал их шаблон построения. И вместе с тем были унаследованы все внешние параметры.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = -10000; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price //--- input int Agent = 1;
При этом данный советник не использует ни одной модели, так как принятие решения о торговых операциях уже было принято за нас, и мы используем историю сделок сигнала. Следовательно, мы удаляем все объекты моделей и добавляем один объект массива сделок сигнала CDeals.
SState sState; STrajectory Base; STrajectory Buffer[]; STrajectory Frame[1]; CDeals Deals; //--- float dError; datetime dtStudied; //--- CSymbolInfo Symb; CTrade Trade; //--- MqlRates Rates[]; CiRSI RSI; CiCCI CCI; CiATR ATR; CiMACD MACD; //--- double PrevBalance = 0; double PrevEquity = 0;
Аналогично, в методе инициализации советника вместо загрузки предварительно обученной модели мы загружаем историю торговых операций.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- load history if(!Deals.LoadDeals(SignalFile(Agent), "EURUSD", SymbolInfoDouble(_Symbol, SYMBOL_POINT))) return INIT_FAILED; //--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Обратите внимание, что при загрузке данных сделок сигнала вместо имени файла мы указываем SignalFile(Agent). Здесь мы используем макроподстановку и именно для этого мы ранее создали унифицированные имена файлов сигналов "SignalX.csv". Макроподстановка возвращает нам унифицированное имя файла истории сигнала с указанием значения внешнего параметра Agent в качестве идентификатора.
#define SignalFile(agent) StringFormat("Signals\\Signal%d.csv",agent)
Это позволяет нам в дальнейшем запускать "...\RealORL\ResearchRealORL.mq5" в режиме оптимизации тестера стратегий MetaTrader 5. А оптимизация по параметру Agent позволит каждому проходу работать со своим файлом истории сигнала. Таким образом мы сможем параллельно обрабатывать несколько файлов сигналов и собирать по ним траектории взаимодействия с окружающей средой.
Взаимодействие с окружающей средой осуществляется в методе OnTick. Здесь мы как обычно сначала проверяем наступление события открытия нового бара.
void OnTick() { //--- if(!IsNewBar()) return;
И, при необходимости, загружаем исторические данные ценового движения. А также обновляем буфера объектов работы с индикаторами.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Отсутствие моделей для принятия решение влечет за собой отсутствие необходимости заполнения буферов данных. Однако, для сохранении информации в траектории взаимодействия с окружающей средой нам предстоит заполнить структуру состояния необходимыми данными. Вначале мы соберем данные о ценовом движении и показателях индикаторов.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
Затем внесем информацию о состоянии счета и открытых позициях. Тут же мы укажем время открытия текущего бара. Обратите внимание, что на данном этапе мы сохраняем только одно значение времени без создания гармоник временной метки. Это позволяет нам сократить объем сохраняемых данных без потери информации.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
И сразу заполним в векторе вознаграждения элементы влияния изменения баланса и эквити.
sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(1.0 - sState.account[1] / PrevBalance);
И сохраним значения баланса и эквити, которые нам потребуются на следующем баре для расчёта вознаграждения.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Вместо прямого прохода Агента мы запрашиваем вектор действий из истории сделок сигнала.
vector<float> temp = Deals.Action(TimeCurrent(), SymbolInfoDouble(_Symbol, SYMBOL_ASK), SymbolInfoDouble(_Symbol, SYMBOL_BID), PeriodSeconds(TimeFrame) );
Обработка и дешифровка вектора действий осуществляется по алгоритму, отработанному нами ранее. Сначала мы исключаем разнонаправленные объемы.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Затем мы корректируем длинную позицию. Но только вот ранее мы не допускали возможности открытия позиции без указания стоп-лосса или тейк-профита. А сейчас это вынужденная мера. Поэтому мы вносим корректировки в части проверки закрытия ранее открытых позиции и указания цен стоп-лосса / тейк-профита.
//--- buy control if(temp[0] < min_lot || (temp[1] > 0 && (temp[1] * MaxTP * Symb.Point()) <= stops) || (temp[2] > 0 && (temp[2] * MaxSL * Symb.Point()) <= stops)) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = (temp[1] > 0 ? NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double buy_sl = (temp[2] > 0 ? NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Аналогичные корректировки вносим в блоке корректировки короткой позиции.
//--- sell control if(temp[3] < min_lot || (temp[4] > 0 && (temp[4] * MaxTP * Symb.Point()) <= stops) || (temp[5] > 0 && (temp[5] * MaxSL * Symb.Point()) <= stops)) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = (temp[4] > 0 ? NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double sell_sl = (temp[5] > 0 ? NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
В завершении метода мы дополняем вектор вознаграждений, копируем вектор действий и передаем структуру для добавления в траекторию.
if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove(); }
На этом мы завершаем рассмотрение методов советника "...\RealORL\ResearchRealORL.mq5", так как остальные методы были перенесены без изменений. А с полным кодом советника, как и всех программ, используемых в статье, Вы можете ознакомиться во вложении.
Авторы метода Real-ORL не предлагают нового метода обучения политики Актера. И мы для своего эксперимента не стали вносить изменений ни в алгоритм обучения политики, ни в архитектуру модели. Такой шаг мы делаем осознанно для сопоставимости условий с обучением модели из предыдущей статьи. Что в конечном итоге позволит оценить влияние непосредственно фреймворка Real-ORL на результат обучения политики.
3. Тестирование
Выше была проведена работа по сбору информации о торговых операциях различных сигналов и подготовлен советник для преобразования собранной информации в траектории взаимодействия с окружающей средой. Теперь мы переход к тестированию проделанной работы и оценке влияния отобранных траекторий на результаты обучения модели. В данной работе мы будем обучать полностью новые модели, инициализированными случайными параметрами. Напомню, что в предыдущей статье мы оптимизировали ранее обученные модели.
Вначале мы осуществляем запуск советник преобразования истории сигналов в траектории "...\RealORL\ResearchRealORL.mq5". Запускать мы будем советник в режиме полной оптимизации.
Оптимизировать мы будем только по одному параметру Agent. В диапазоне параметров мы укажем первый и последний идентификатор файлов сигналов с шагом "1".
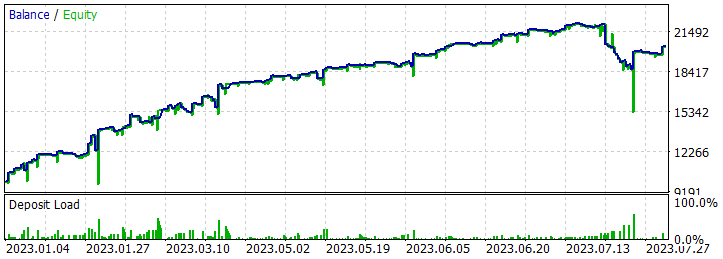
Должен сказать, что в результате получились довольно интересные траектории.
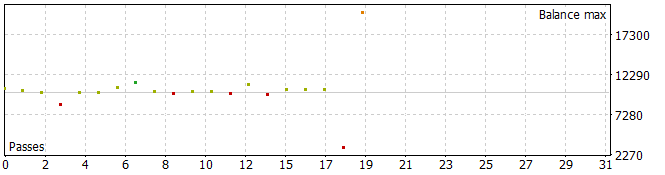
Пять из проходов за анализируемый период закрылись с убытком, а одна удвоила баланс.
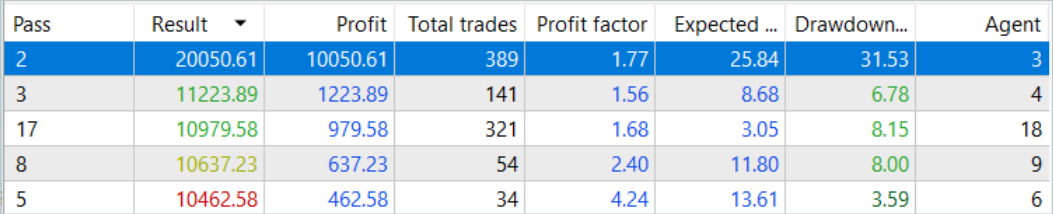
Одиночный проход наиболее прибыльной траектории продемонстрировал довольно глубокую просадку в 7.02.2023 и 25.07.2023. Не буду обсуждать стратегию, используемую автором сигнала, так как не знаком с ней. К тому же вполне возможно, что просадка вызвана ранним открытием позиции, спровоцированным смещением точки открытия позиции на начало бара анализируемого тайм-фрейма. И, конечно, использование стоп-лоссов, которые мы осознанно обнулили, приведет к фиксации убытков в подобных ситуациях.
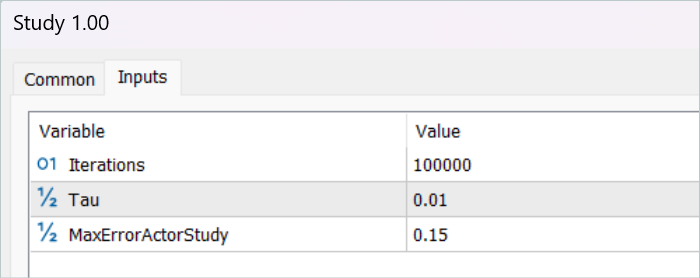
После сохранения траекторий мы переходим к обучению модели. Для этого мы запускаем советник "...\RealORL\Study.mq5".
Первичное обучение осуществлялось только на данных траекторий, собранных по результатам работы сигналов. И должен сказать, что чуда не произошло. Результаты работы модели после первичного обучения были далеки от желаемых. Обученная политика генерировала убыток как за период обучения в первые 7 месяцев 2023 года, так и на тестовом историческом интервале за август 2023 года. Но, честно говоря, я бы не стал говорить о неэффективности предложенного фреймворка Real-ORL. Отобранные 20 траекторий далеки от 3000 траекторий, используемых авторами фреймворка. И уж точно 20 траекторий не покрывают даже малой части многообразия возможных действий агента.
Перед продолжением обучения буфер обучающих траекторий был пополнен с помощью советника "...\RealORL\Research.mq5". Напомню, что данный советник осуществляет проходы с принятием решений на основании предварительно обученной политики Агента. А исследование окружающей среды осуществляется благодаря стохастичности латентного состояния и политики Агента. 2 стохастичности создают довольно большое разнообразие действий Агента, что позволяет изучать окружающую среду. По мере обучения политики Агента обе стохастичности снижаются, благодаря уменьшению дисперсии каждого параметра. Это делает действия Агента более предсказуемыми и осознанными.
Мы добавляем в буфер 200 новых траекторий и повторяем процесс обучения моделей.
На этот раз процесс обучения политики Агента был довольно длительный. Мне потребовалось много раз обновлять буфер воспроизведения опыта с использованием советника "...\RealORL\Research.mq5" прежде чем получить прибыльную политику. Однако должен указать, что в процессе обновления буфера воспроизведения опыта после его полного заполнения мы заменяем траекторий с максимальным убытком (минимальной прибылью) более прибыльными. Следовательно, осуществлялась только замена траекторий, собранных с помощью советника "...\RealORL\Research.mq5". Траектории от сигналов ввиду своей общей доходности постоянно оставались в буфере воспроизведения опыта.
Как я уже сказал, в результате длительного обучения была получена политика, способная генерировать прибыль на обучающей выборке. Более того, полученная политика способна обобщать полученный опыт на новые данные. Об этом свидетельствует получение прибыли на исторических данных вне периода обучения.


На исторических данных тестовой выборки Агент совершил 131 сделку, 48.85% из которых было закрыто с прибылью. Максимальная прибыльная сделка почти на 10% ниже максимального убытка (379.89 против 398.49 соответственно). В то же время средняя прибыльная сделка на 40% превышает средний убыток. В результате профит-фактор за период тестирования составил 1.34, а фактор восстановления 0.94.
Так же следует отметить практически паритет между длинными (70) и короткими (61) сделками. Это свидетельствует о возможности Агента выделять локальные тенденции, а не только следовать глобальному тренду.
Заключение
В данной статье мы познакомились с фреймворком Real-ORL, который пришел к нам из робототехники. Авторы фреймворка в своей работе проводят довольно широкие эмпирические исследования с использованием реального робота, что позволяет им сделать нижеследующие выводы:
- Для задач за пределами области применения алгоритмы обучения с подкреплением могли обобщаться к областям задач с недостатком данных и к динамическим задачам.
- Изменение производительности ORL после использования разнородных данных склонно различаться в зависимости от агентов, конструкции задачи и характеристик данных.
- Определенные разнородные, независящие от задачи траектории могут обеспечить перекрывающуюся поддержку данных и обеспечивать лучшее обучение, позволяя агентам ORL улучшить свою производительность.
- Лучший агент для каждой задачи — это либо алгоритм ORL, либо паритет между ORL и BC. Приведенные в статье оценки указывают на то, что даже в режиме данных за пределами области применения, более реалистичным для реального мира, офлайн обучение с подкреплением является эффективным подходом.
В своей работе мы рассматриваем возможность использования предложенного фреймворка для использования в области финансовых рынков. В частности, подходы, предложенные авторами фреймворка Real-ORL, позволяют нам эксплуатировать историю широкого спектра различных сигналов, представленных на рынке, для обучения моделей. Однако, для максимального представления многообразия окружающей среды нам требуется большое количество траекторий. И, следовательно, должна быть проведена работа по сбору максимально возможного количества разнообразных траекторий. Использование только 20 траекторий в данной работе, наверное, можно считать ошибкой. Авторы Real-ORL в своей работе использовали более 3000 траекторий.
Мое личное мнение, что метод может и должен быть использован для первичного обучения моделей и имеет преимущество перед сбором случайных траекторий. Однако, использование только "замороженных" данных траекторий недостаточно для построения оптимальной политики Агента. От малого количества отобранных мной траекторий сложно ожидать серьёзных результатов. Но Авторы метода в своей работе так же не смогли получить максимальных теоретически возможных результатов. Кроме того, информация о сигналах ограничена и не позволяет учесть всех рисков. К примеру, в сигналах нет информации о стоп-лоссах и тейк-профитах. Их отсутствие не дает возможности полностью оценивать и контролировать риски. Поэтому, модели, обученной на траекториях сигналов, необходима последующая тонкая настройка на дополнительных траекториях, полученных уже с учетом предварительно обученной политики.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | ResearchExORL.mq5 | Советник | Советник сбора примеров методом ExORL |
| 4 | Study.mq5 | Советник | Советник обучения агента |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Если владеете темой, напишите статью про использование Google Colab + Tensor Flow. Могу дать реальную задачу по трейдингу и рассчитаю входные данные.
Не знаю насколько это в тематике данного сайта?
Привет @Дмитрий Гизлык
Прежде всего, снимаю шляпу перед вашими усилиями по созданию этой замечательной серии статей по AI и ML.
Я просмотрел все статьи с 1 по 30 подряд за один день. Большинство предоставленных вами файлов работали без проблем.
Однако я перешел к статье 67 и попытался запустить 'ResearchRealORL'. Я получаю следующие ошибки.
Не могли бы вы помочь, где я ошибаюсь?
С уважением, большое спасибо за все ваши усилия по обучению нас ML на MQL5.
你好@Дмитрий吉兹利克
首先,向您为创建这个关于 AI 和 ML 的精彩系列文章所做的努力致敬。
我在一天内连续浏览了从 1 到 30 的所有文章。您提供的大多数文件都可以正常工作。
但是,我转到了第 67 条并尝试运行“ResearchRealORL”。我收到以下错误。
你能帮我解决我错的地方吗?
衷心感谢您在MQL5中教我们ML的所有努力。
Явыполняю код в Neural networks made easy (Part 67): Использование прошлого опыта для решения новых задач
У менята же проблема, касающаяся следующего.
2024.04.21 18:00:01.131 Core 4 pass 0 tested with error "OnInit returned non-zero code 1" in 0:00:00.152
Похоже, это связано с командой 'FileIsExist'.
Но, я не могу решить эту проблему.
Вы знаете, как ее решить?