
Нейросети — это просто (Часть 78): Детектор объектов на основе Трансформера (DFFT)

Введение
В предыдущих статьях мы много уделили внимания вопросу прогнозирования предстоящего ценового движения. Мы анализировали исторические данные. И на основе данного анализа различными способами пытались спрогнозировать наиболее вероятное предстоящее ценовое движение. Некоторые строили целый спектр прогнозных движений и пытались оценить вероятность каждого из построенных прогнозов. Естественно, что обучение и эксплуатация подобных моделей требует значительных вычислительных ресурсов.
Но настолько ли нам надо прогнозировать предстоящее ценовое движение? Тем более что точность полученных прогнозов далека от желаемой.
Нашей конечной целью является получение прибыли. Которую мы планируем получить благодаря успешной торговли нашего Агента. Который, в свою очередь, выбирает оптимальные действия исходя из полученных прогнозных ценовых траекторий.
Следовательно, погрешность в построении прогнозных траекторий потенциально приведет к еще большей погрешности при выборе действий Агентом. Здесь я говорю "потенциально приведет" потому, что в процессе обучения Актер может подстроиться под погрешности прогнозов и немного нивелировать ошибку. Однако, такая ситуация возможна при относительно постоянной погрешности прогнозов. В случае стохастической ошибки прогнозов, погрешность действий Агента только усилится.
В такой ситуации мы ищем пути минимизации ошибки. А что, если мы исключим промежуточный этап прогнозирования траектории предстоящего ценового движения. Вернемся к классическому подходу обучения с подкреплением. И позволим Актеру выбирать действия на основе анализа исторических данных. Но при этом мы сделаем не шаг назад, а скорее в сторону.
Я предлагаю Вам познакомиться с одним интересным методом, который был представлен для решения задач в области машинного зрения. Это метод Decoder-Free Fully Transformer-based (DFFT), который был представлен в статье "Efficient Decoder-free Object Detection with Transformers".
Предложенный в статье метод DFFT обеспечивает высокую эффективность как на этапе обучения, так и на этапе эксплуатации. Авторы метода упрощают обнаружение объектов до одноуровневой задачи плотного прогнозирования, используя только энкодер. И сосредотачивают свои усилия на решение 2 задач:
- Устранение неэффективного декодера и использование 2 мощных энкодеров для сохранения точности прогнозирования одноуровневой карты признаков;
- Изучение низкоуровневых семантических признаков для задачи обнаружения с ограниченными вычислительными ресурсами.
В частности, авторы метода предлагают новую легковесную магистраль преобразователя, ориентированную на обнаружение, которая эффективно фиксирует низкоуровневые признаки с богатой семантикой. Приведенные в статье эксперименты показывают снижение затрат на вычисления и меньшее количество эпох обучения.
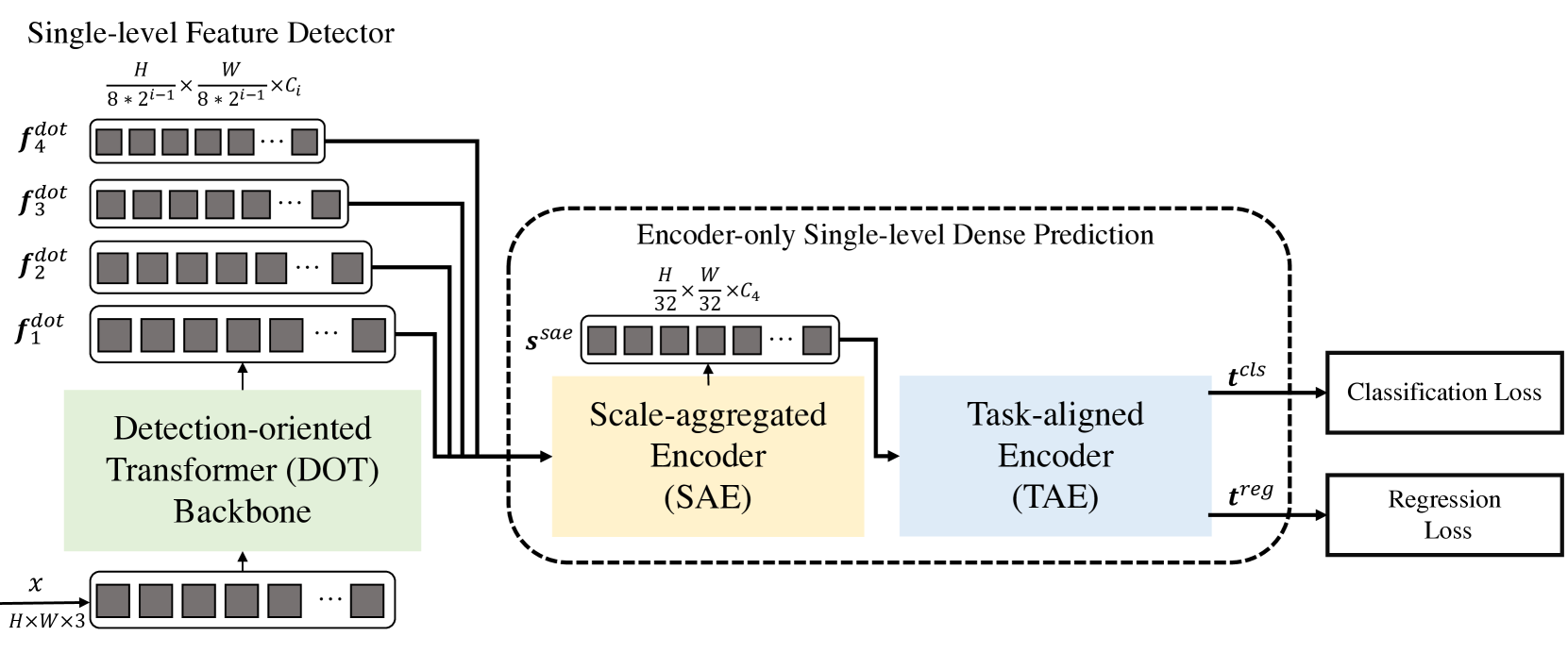
1. Алгоритм DFFT
Метод Decoder-Free Fully Transformer-based (DFFT) — эффективный детектор объектов, полностью основанный на Трансформерах без декодера. Магистраль Трансформера ориентирована на обнаружение объектов. Извлекает их в четырех масштабах и отправляет на следующий одноуровневый модуль прогнозирования плотности, предназначенный только для кодировщика. Модуль прогнозирования сначала агрегирует многомасштабный объект в единую карту объектов с помощью кодировщика Scale-Aggregated Encoder.
Затем авторы метода предлагают использовать кодировщик Task-Aligned Encoder для одновременного согласования функций для задач классификации и регрессии.
Ориентированная на обнаружение магистраль трансформера (Detection-Оriented Тransformer — DOT) предназначена для извлечения многомасштабных признаков со строгой семантикой. Она иерархически укладывает один модуль Эмбединга и четыре этапа DOT. Новый модуль семантически расширенного внимания агрегирует низкоуровневую семантическую информацию каждых двух последовательных этапов DOT.
При обработке карт признаков с высоким разрешением при плотном прогнозировании обычные блоки-трансформера снижают вычислительные затраты, заменяя слой Self-Attention с несколькими головками (MSA) слоем локального пространственного внимания и смещенного оконного многоголового Self-Attention (SW-MSA). Однако такая структура снижает производительностью обнаружения, так как извлекает только многомасштабные объекты с ограниченной низкоуровневой семантикой.
Для смягчения этого недостатка авторы метода DFFT добавляют в блок DOT несколько блоков SW-MSA и один глобальный блок внимания по каналам. Обратите внимание, что каждый блок внимания содержит слой внимания и слой FFN.
Авторы метода обнаружили, что размещение легкого слоя внимания по каналам после последовательных локальных пространственных слоев внимания может помочь в выводе семантики объекта в каждом масштабе.
В то время как блок DOT улучшает семантическую информацию в низкоуровневых признаках за счет глобального внимания по каналам, семантика может быть улучшена еще больше, чтобы улучшить задачу обнаружения. Для этого авторы метода предлагают новый модуль семантического повышенного внимания (Semantic-Augmented Attention — SAA), который обменивается семантической информацией между двумя последовательными уровнями DOT и дополняет их характеристики. SAA состоит из слоя повышающей дискретизации и глобального блока внимания по каналам. Авторы метода добавляют SAA в каждые два последовательных блока DOT. Формально SAA принимает результаты работы текущего блока DOT и предыдущего этапа DOT, а затем возвращает семантическую расширенную функцию, которая отправляется на следующий этап DOT и также вносит свой вклад в окончательные многомасштабные признаки.
В целом ориентированный на обнаружения этап состоит из четырех слоев DOT, где каждая ступень включает в себя один блок DOT и один модуль SAA (кроме первой ступени). В частности, первая ступень содержит один блок DOT и не содержит модуля SAA, поскольку входы модуля SAA поступают из двух последовательных ступеней DOT. Далее следует слой пониженной дискретизации для восстановления входного измерения.
Следующий модуль предназначен для повышения эффективности как инференса, так и эффективности обучения модели DFFT. Сначала используется кодировщик с агрегированием масштаба (Scale-Aggregated Encoder — SAE) для агрегирования многомасштабных объектов от магистрали DOT в одну карту объектов Ssae.
Затем используется кодировщик с выравниванием по задачам (Task-Aligned Encoder — TAE) для создания функции выровненной классификации 𝒕cls и регрессионная функция 𝒕reg одновременно в одной голове.
Кодировщик с агрегированным масштабом строится из 3 блоков SAE. Каждый блок SAE принимает в качестве исходных данных два объекта и агрегирует их шаг за шагом по всем блокам SAE. Авторы метода используют масштаб конечного агрегирования объектов для балансировки точности обнаружения и вычислительных затрат.
Обычно, детекторы выполняют классификацию и локализацию объектов независимо друг от друга с помощью двух отдельных ветвей (несвязанных голов). Такая структура с двумя ветвями не учитывает взаимодействие между двумя задачами и приводит к несогласованным прогнозам. Между тем, при изучении признаков для двух задач в сопряженной голове обычно существуют конфликты. Авторы DFFT предлагают использовать кодировщик, ориентированный на задачу, который обеспечивает лучший баланс между изучением интерактивных функций и функций, специфичных для конкретной задачи, путем объединения групповых блоков внимания по каналам в связанной голове.
Этот энкодер состоит из двух видов канальных блоков внимания. Во-первых, многоуровневые групповые блоки внимания по каналам выравнивают и разделяют агрегированные объекты Ssae на 2 части. Во-вторых, глобальные блоки внимания по каналам кодируют один из двух разделенных объектов для последующей задачи регрессии.
В частности, различия между групповым блоком внимания по каналам и глобальным блоком внимания по каналам заключаются в том, что все линейные проекции, за исключением проекций для вложений Query/Key/Value в групповом блоке внимания по каналам, выполняются в двух группах. Таким образом, признаки взаимодействуют в операциях внимания, в то время как выводятся отдельно в выходных проекциях.
Авторская визуализация метода представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода Decoder-Free Fully Transformer-based (DFFT) мы переходим к практической реализации предложенных подходов средствами MQL5. Однако, наша модель будет несколько отличаться от авторской. Так как при её построении мы учитываем различия в специфике задач компьютерного зрения, для которых был предложен метод, и работе на финансовых рынках, для которых мы строим свою модель.
2.1 Построения блока DOT
И приступая к работе, стоит отметить, что предложенные подходы довольно сильно отличаются от построенных нами ранее моделей. В том числе, и блок DOT отличается от рассмотренных нами ранее блоков внимания. Поэтому, начинаем мы свою работу с построения нового нейронного слоя CNeuronDOTOCL. Свой новый слой мы создаем наследником нашего базового класса нейронных слоев CNeuronBaseOCL.
Аналогично другим блокам внимания, мы добавим переменные для сохранения ключевых параметров:
- iWindowSize — размер окна одного элемента последовательности;
- iPrevWindowSize — размер окна одного элемента последовательности предыдущего слоя;
- iDimension — размер вектора внутренних сущностей Query, Key и Value;
- iUnits — количество элементов в последовательности;
- iHeads — количество голов внимания.
Думаю, вы обратили внимание на переменную iPrevWindowSize. Её добавление позволит нам реализовать возможность сжатия данных от слоя к слою, как это предусмотрено методом DFFT.
Также, с целью минимизации работы непосредственно в новом классе и максимальной эксплуатации ранее созданных наработок, часть функционала мы реализуем с использованием вложенных нейронных слоев из нашей библиотеки. С их функционалом мы познакомимся в ходе реализации методов прямого и обратного прохода.
class CNeuronDOTOCL : public CNeuronBaseOCL { protected: uint iWindowSize; uint iPrevWindowSize; uint iDimension; uint iUnits; uint iHeads; //--- CNeuronConvOCL cProjInput; CNeuronConvOCL cQKV; int iScoreBuffer; CNeuronBaseOCL cRelativePositionsBias; CNeuronBaseOCL MHAttentionOut; CNeuronConvOCL cProj; CNeuronBaseOCL AttentionOut; CNeuronConvOCL cFF1; CNeuronConvOCL cFF2; CNeuronBaseOCL SAttenOut; CNeuronXCiTOCL cCAtten; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool DOT(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool updateRelativePositionsBias(void); virtual bool DOTInsideGradients(void); public: CNeuronDOTOCL(void) {}; ~CNeuronDOTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint dimension, uint heads, uint units_count, uint prev_window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronDOTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
В целом же список переопределяемых методов довольно стандартен.
В теле класса мы используем статические объекты. Что позволяет нам оставить конструктор и деструктор класса пустыми.
Инициализации класса осуществляется в методе Init. В параметрах методу мы будем передавать всю необходимую информацию. Минимально необходимый контроль которой осуществляется в одноименном методе родительcкого класса. Там же осуществляется инициализация унаследованных объектов.
bool CNeuronDOTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint dimension, uint heads, uint units_count, uint prev_window, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Затем мы проверяем соответствие размера исходных данных и параметров текущего слоя. При необходимости инициализируем слой масштабирования данных.
if(prev_window != window) { if(!cProjInput.Init(0, 0, OpenCL, prev_window, prev_window, window, units_count, optimization_type, batch)) return false; }
Далее мы сохраняем полученные от вызывающей программы основные константы, определяющие архитектуру слоя во внутренние переменные класса.
iWindowSize = window; iPrevWindowSize = prev_window; iDimension = dimension; iHeads = heads; iUnits = units_count;
После чего последовательно инициализируем все внутренние объекты. Первым мы инициализируем слой генерации сущностей Query, Key и Value. Все 3 сущности мы будем генерировать параллельно в теле одного нейронного слоя cQKV.
if(!cQKV.Init(0, 1, OpenCL, window, window, dimension * heads, units_count, optimization_type, batch)) return false;
Далее мы создадим буфер для записи коэффициентов зависимости объектов iScoreBuffer. Здесь надо отметить, что в блоке DOT мы сначала анализируем локальную семантику. Для этого мы будем проверять зависимость между объектом и 2 его ближайшими соседями. Поэтому размер буфера Score мы определим как iUnits * iHeads * 3.
Кроме того, сохраняемые в буфер коэффициенты пересчитываются при каждом прямом проходе. И используются только при следующем обратном проходе. Поэтому данные буфера мы не будем сохранять в файл сохранения модели. Более того, мы не будем даже создавать буфер в памяти основной программы. Нам достаточно создать буфер в памяти контекста OpenCL. На стороне основной программы мы сохраним только указатель на буфер.
//--- iScoreBuffer = OpenCL.AddBuffer(sizeof(float) * iUnits * iHeads * 3, CL_MEM_READ_WRITE); if(iScoreBuffer < 0) return false;
В механизме Self-Attention с окнами, в отличие от классического трансформера, каждый токен взаимодействует только с токенами в пределах определенного окна. Это существенно снижает вычислительную сложность. Однако данное ограничение также означает, что модели должны учитывать относительные позиции токенов внутри окна. Для реализации этого функционала вводятся обучаемые параметры cRelativePositionsBias. Для каждой пары токенов (i, j) внутри окна iWindowSize, cRelativePositionsBias содержит вес, который определяет важность взаимодействия между этими токенами на основе их относительного расположения.
Легко догадаться, что размер этого буфера равен размеру буфера коэффициентов Score. Однако, для обучения параметров помимо буфера самих значений нам потребуются и дополнительные буферы. С целью сокращения количества внутренних объектов и читабельности кода, для cRelativePositionsBias мы объявим объект нейронного слоя, который содержит все дополнительные буферы.
if(!cRelativePositionsBias.Init(1, 2, OpenCL, iUnits * iHeads * 3, optimization_type, batch)) return false;
Аналогично добавим остальные элементы механизма Self-Attention.
if(!MHAttentionOut.Init(0, 3, OpenCL, iUnits * iHeads * iDimension, optimization_type, batch)) return false; if(!cProj.Init(0, 4, OpenCL, iHeads * iDimension, iHeads * iDimension, window, iUnits, optimization_type, batch)) return false; if(!AttentionOut.Init(0, 5, OpenCL, iUnits * window, optimization_type, batch)) return false; if(!cFF1.Init(0, 6, OpenCL, window, window, 4 * window, units_count, optimization_type,batch)) return false; if(!cFF2.Init(0, 7, OpenCL, window * 4, window * 4, window, units_count, optimization_type, batch)) return false; if(!SAttenOut.Init(0, 8, OpenCL, iUnits * window, optimization_type, batch)) return false;
В качестве глобального блока внимания вы воспользуемся слоем CNeuronXCiTOCL.
if(!cCAtten.Init(0, 9, OpenCL, window, MathMax(window / 2, 3), 8, iUnits, 1, optimization_type, batch)) return false;
Для минимизации операций копирования данных между буферами мы осуществим подмену объектов и буферов.
if(!!Output) delete Output; Output = cCAtten.getOutput(); if(!!Gradient) delete Gradient; Gradient = cCAtten.getGradient(); SAttenOut.SetGradientIndex(cFF2.getGradientIndex()); //--- return true; }
И завершаем работу метода.
После инициализации класса мы переходим к построению алгоритма прямого прохода. И здесь нам предстоит начать работу с организации механизма Self-Attention с окнами на стороне OpenCL программы. Для этого мы создадим кернел DOTFeedForward. В параметрах кернелу мы будем передавать указатели на 4 буфера данных:
- qkv — буфер сущностей Query, Key и Value,
- score — буфер коэффициентов зависимости,
- rpb — буфер позиционных смещений,
- out — буфер результатов многоголового Self-Attention с окнами.
__kernel void DOTFeedForward(__global float *qkv, __global float *score, __global float *rpb, __global float *out) { const size_t d = get_local_id(0); const size_t dimension = get_local_size(0); const size_t u = get_global_id(1); const size_t units = get_global_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
Кернел мы планируем запускать в 3 мерном пространстве задач. И в теле кернела мы сразу идентифицируем поток во всех 3 измерения. Здесь надо отметить, что в первом измерении размерности сущностей Query, Key и Value мы создаем рабочую группу с совместным использованием буфера в локальной памяти.
Далее мы определяем смещения в буферах данных до начала анализируемых объектов.
uint step = 3 * dimension * heads; uint start = max((int)u - 1, 0); uint stop = min((int)u + 1, (int)units - 1); uint shift_q = u * step + h * dimension; uint shift_k = start * step + dimension * (heads + h); uint shift_score = u * 3 * heads;
И тут же мы создаем локальный буфер для обмена данными между потоками одной рабочей группы.
const uint ls_d = min((uint)dimension, (uint)LOCAL_ARRAY_SIZE); __local float temp[LOCAL_ARRAY_SIZE][3];
Как уже было сказано ранее, локальную семантику мы определяем по 2 ближайшим соседям к объекту. Вначале мы определим влияние соседей на анализируемый объект. Посчитаем коэффициенты зависимости в рамках рабочей группы. Сначала мы попарно умножим элементы сущностей Query и Key в параллельных потоках.
//--- Score if(d < ls_d) { for(uint pos = start; pos <= stop; pos++) { temp[d][pos - start] = 0; } for(uint dim = d; dim < dimension; dim += ls_d) { float q = qkv[shift_q + dim]; for(uint pos = start; pos <= stop; pos++) { uint i = pos - start; temp[d][i] = temp[d][i] + q * qkv[shift_k + i * step + dim]; } } barrier(CLK_LOCAL_MEM_FENCE);
А затем суммируем полученные произведения.
int count = ls_d; do { count = (count + 1) / 2; if(d < count && (d + count) < dimension) for(uint i = 0; i <= (stop - start); i++) { temp[d][i] += temp[d + count][i]; temp[d + count][i] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); }
К полученным значениям прибавим параметры смещения и нормализуем функцией SoftMax.
if(d == 0) { float sum = 0; for(uint i = 0; i <= (stop - start); i++) { temp[0][i] = exp(temp[0][i] + rpb[shift_score + i]); sum += temp[0][i]; } for(uint i = 0; i <= (stop - start); i++) { temp[0][i] = temp[0][i] / sum; score[shift_score + i] = temp[0][i]; } } barrier(CLK_LOCAL_MEM_FENCE);
Результат сохраним в буфер коэффициентов зависимости.
Теперь мы можем умножить полученными коэффициенты на соответствующие элементы сущности Value для определения результатов блока многоголового Self-Attention с окнами.
int shift_out = dimension * (u * heads + h) + d; int shift_v = dimension * (heads * (u * 3 + 2) + h); float sum = 0; for(uint i = 0; i <= (stop - start); i++) sum += qkv[shift_v + i] * temp[0][i]; out[shift_out] = sum; }
Полученные значения сохраняем в соответствующие элементы буфера результатов и завершаем работу кернела.
После создания кернела мы возвращаемся к нашей основной программе, в которой мы создаем методы нашего нового класса CNeuronDOTOCL. Вначале мы создадим метод DOT, в котором осуществляется постановка выше созданного кернела в очередь выполнения.
Алгоритм метода довольно прост. Мы лишь осуществляем передачу кернелу внешних параметров.
bool CNeuronDOTOCL::DOT(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iUnits, iHeads}; uint local_work_size[3] = {iDimension, 1, 1}; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_qkv, cQKV.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_score, iScoreBuffer)) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_out, MHAttentionOut.getOutputIndex())) return false;
После чего отправляем кернел в очередь выполнения.
ResetLastError(); if(!OpenCL.Execute(def_k_DOTFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
При этом не забываем контролировать процесс выполнения операций на каждом этапе.
После завершения подготовительной работы мы переходим к созданию метода CNeuronDOTOCL::feedForward, в котором мы верхнеуровнево определим алгоритм прямого прохода нашего слоя.
В параметрах метода мы получаем указатель на слой предыдущего нейронного слоя. Для удобства работы сохраним полученный указатель в локальную переменную.
bool CNeuronDOTOCL::feedForward(CNeuronBaseOCL *NeuronOCL)
{
CNeuronBaseOCL* inputs = NeuronOCL;
Далее мы проверяем отличается ли размер исходных данных от параметров текущего слоя. Если есть необходимость, то масштабируем исходные данные и вычисляем сущности Query, Key и Value.
В случае равенства буферов данных мы опускаем шаг масштабирования и сразу генерируем сущности Query, Key и Value.
if(iPrevWindowSize != iWindowSize) { if(!cProjInput.FeedForward(inputs) || !cQKV.FeedForward(GetPointer(cProjInput))) return false; inputs = GetPointer(cProjInput); } else if(!cQKV.FeedForward(inputs)) return false;
Следующим этапом мы вызываем выше созданный метод Self-Attention с окнами.
if(!DOT()) return false;
Понижаем размерность данных.
if(!cProj.FeedForward(GetPointer(MHAttentionOut))) return false;
И складываем результат с буфером исходных данных.
if(!SumAndNormilize(inputs.getOutput(), cProj.getOutput(), AttentionOut.getOutput(), iWindowSize, true)) return false;
Проведем результат через блок FeedForward.
if(!cFF1.FeedForward(GetPointer(AttentionOut))) return false; if(!cFF2.FeedForward(GetPointer(cFF1))) return false;
И снова суммируем буферы результатов. На это раз с выходом блока Self-Attention с окнами.
if(!SumAndNormilize(AttentionOut.getOutput(), cFF2.getOutput(), SAttenOut.getOutput(), iWindowSize, true)) return false;
В завершении блока идет этап глобального Self-Attention. В качестве которого мы используем слой CNeuronXCiTOCL.
if(!cCAtten.FeedForward(GetPointer(SAttenOut))) return false; //--- return true; }
Проверяем результаты операций и завершаем работу метода.
На этом мы завершаем рассмотрение реализации прямого прохода нашего класса и переходим к работе над методами обратного прохода. Здесь мы также начинаем работу с создания кернела обратного прохода блока Self-Attention с окнами DOTInsideGradients. Как и кернел прямого прохода, новый кернел мы будем запускать в 3 мерном пространстве задач. Только на это раз без создания локальных групп.
В параметрах кернел получает указатели на все необходимые буфера данных.
__kernel void DOTInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *rpb, __global float *rpb_g, __global float *gradient) { //--- init const uint u = get_global_id(0); const uint d = get_global_id(1); const uint h = get_global_id(2); const uint units = get_global_size(0); const uint dimension = get_global_size(1); const uint heads = get_global_size(2);
А в теле кернела мы сразу идентифицируем поток по всем 3 измерениям. И определяем пространство задач, которое нам укажет на размерность полученных буферов.
Тут же мы определим смещение в буферах данных.
uint step = 3 * dimension * heads; uint start = max((int)u - 1, 0); uint stop = min((int)u + 1, (int)units - 1); const uint shift_q = u * step + dimension * h + d; const uint shift_k = u * step + dimension * (heads + h) + d; const uint shift_v = u * step + dimension * (2 * heads + h) + d;
После чего переходим непосредственно к распределению градиента. Сначала мы определим градиент ошибки для элемента Value. Для этого умножим полученный градиент на соответствующий коэффициент влияния.
//--- Calculating Value's gradients float sum = 0; for(uint i = start; i <= stop; i ++) { int shift_score = i * 3 * heads; if(u == i) { shift_score += (uint)(u > 0); } else { if(u > i) shift_score += (uint)(start > 0) + 1; } uint shift_g = dimension * (i * heads + h) + d; sum += gradient[shift_g] * scores[shift_score]; } qkv_g[shift_v] = sum;
Следующим этапом мы определим градиент ошибки для сущности Query. Здесь алгоритм немного сложнее. Сначала нам необходимо определить градиент ошибки для соответствующего вектора коэффициентов зависимости. Скорректировать полученный градиент на производную функции SoftMax. И лишь после этого мы можем умножить полученный градиент ошибки коэффициентов зависимости на соответствующий элемент тензора сущностей Key.
Здесь стоит обратить внимание, что перед нормализацией коэффициентов зависимости мы складывали их с элементами позиционного смещения внимания. Как Вы знаете, при сложении градиент мы в полном объеме передаем в обоих направлениях. Двойной учет ошибки легко нивелируется малым коэффициентом обучения. Следовательно, градиент ошибки на уровне матицы коэффициентов зависимости мы переносим в буфер градиентов ошибки позиционного смещения.
//--- Calculating Query's gradients float grad = 0; uint shift_score = u * heads * 3; for(int k = start; k <= stop; k++) { float sc_g = 0; float sc = scores[shift_score + k - start]; for(int v = start; v <= stop; v++) for(int dim=0;dim<dimension;dim++) sc_g += scores[shift_score + v - start] * qkv[v * step + dimension * (2 * heads + h) + dim] * gradient[dimension * (u * heads + h) + dim] * ((float)(k == v) - sc); grad += sc_g * qkv[k * step + dimension * (heads + h) + d]; if(d == 0) rpb_g[shift_score + k - start] = sc_g; } qkv_g[shift_q] = grad;
Далее нам остается аналогичным образом определить градиент ошибки для сущности Key. Алгоритм аналогичный Query, но в другом измерении матрицы коэффициентов.
//--- Calculating Key's gradients grad = 0; for(int q = start; q <= stop; q++) { float sc_g = 0; shift_score = q * heads * 3; if(u == q) { shift_score += (uint)(u > 0); } else { if(u > q) shift_score += (uint)(start > 0) + 1; } float sc = scores[shift_score]; for(int v = start; v <= stop; v++) { shift_score = v * heads * 3; if(u == v) { shift_score += (uint)(u > 0); } else { if(u > v) shift_score += (uint)(start > 0) + 1; } for(int dim=0;dim<dimension;dim++) sc_g += scores[shift_score] * qkv[shift_v-d+dim] * gradient[dimension * (v * heads + h) + d] * ((float)(d == v) - sc); } grad += sc_g * qkv[q * step + dimension * h + d]; } qkv_g[shift_k] = grad; }
На этом мы завершаем работу с кернелом и возвращаемся к работе с нашим классом CNeuronDOTOCL, в котором мы создадим метод DOTInsideGradients для вызова выше созданного кернела. Алгоритм остается прежним:
- определяем пространство задач
bool CNeuronDOTOCL::DOTInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iUnits, iDimension, iHeads};
- передаем параметры
if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_qkv, cQKV.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_qkv_g, cQKV.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_scores, iScoreBuffer)) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_rpb_g, cRelativePositionsBias.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_gradient, MHAttentionOut.getGradientIndex())) return false;
- ставим в очередь выполнения
ResetLastError(); if(!OpenCL.Execute(def_k_DOTInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
- проверяем результат выполнения операций и завершаем работу метода.
Непосредственный алгоритм обратного прохода мы верхнеуровнево описываем в методе calcInputGradients. В параметрах данный метод получает указатель на объект предыдущего слоя, которому предстоит передать градиент ошибки. В теле метода мы сразу проверяем актуальность полученного указателя. Ведь при недействительном указателе нам некуда передавать градиент ошибки. И логический смысл всех операций близок к "0".
bool CNeuronDOTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Далее мы повторяем операции прямого прохода в обратном порядке. При инициализации нашего класса CNeuronDOTOCL мы предусмотрительно осуществили замену буферов. И теперь, при получении градиента ошибки от последующего нейронного слоя мы получили его сразу в слой глобального внимания. Следовательно, мы опускаем уже излишнюю операции копирования данных и сразу вызываем одноименный метод внутреннего слоя глобального внимания.
if(!cCAtten.calcInputGradients(GetPointer(SAttenOut))) return false;
Здесь мы также использовали прием с подменой буферов и сразу пропускаем градиент ошибки через блок FeedForward.
if(!cFF2.calcInputGradients(GetPointer(cFF1))) return false; if(!cFF1.calcInputGradients(GetPointer(AttentionOut))) return false;
Далее мы суммируем градиент ошибки из 2 потоков.
if(!SumAndNormilize(AttentionOut.getGradient(), SAttenOut.getGradient(), cProj.getGradient(), iWindowSize, false)) return false;
И распределяем его по головам внимания.
if(!cProj.calcInputGradients(GetPointer(MHAttentionOut))) return false;
Вызываем наш метод распределения градиента ошибки через блок Self-Attention с окнами.
if(!DOTInsideGradients()) return false;
После чего проверяем соответствие размером предыдущего и текущего слоя. При необходимости масштабирования данных мы сначала спускаем градиент ошибки на слой масштабирования. Суммируем градиенты ошибки с 2 потоков. И лишь затем масштабируем градиент ошибки на предыдущий слой.
if(iPrevWindowSize != iWindowSize) { if(!cQKV.calcInputGradients(GetPointer(cProjInput))) return false; if(!SumAndNormilize(cProjInput.getGradient(), cProj.getGradient(), cProjInput.getGradient(), iWindowSize, false)) return false; if(!cProjInput.calcInputGradients(prevLayer)) return false; }
В случае равенства нейронных слоев мы сразу передаем градиент ошибки на предыдущий слой. И затем дополняем его градиентом ошибки от второго потока.
else { if(!cQKV.calcInputGradients(prevLayer)) return false; if(!SumAndNormilize(prevLayer.getGradient(), cProj.getGradient(), prevLayer.getGradient(), iWindowSize, false)) return false; } //--- return true; }
После распределения градиента ошибки между всеми нейронными слоями нам предстоит обновить параметры модели для минимизации ошибки. И здесь было бы все тривиально, если бы не одно "но". Помните буфер параметров позиционного влияния элементов? Нам необходимо обновить его параметры. Для выполнения данного функционала мы создаем кернел RPBUpdateAdam. В параметрах кернелу передаем указатели на буфер текущих параметров, градиент ошибки. А также вспомогательные тензоры и константы метода Adam.
__kernel void RPBUpdateAdam(__global float *target, __global const float *gradient, __global float *matrix_m, ///<[in,out] Matrix of first momentum __global float *matrix_v, ///<[in,out] Matrix of seconfd momentum const float b1, ///< First momentum multiplier const float b2 ///< Second momentum multiplier ) { const int i = get_global_id(0);
В теле кернела мы идентифицируем поток, который нам указывает на смещение в буферах данных.
Далее объявим локальные переменные и сохраним в них необходимые значения глобальных буферов.
float m, v, weight; m = matrix_m[i]; v = matrix_v[i]; weight = target[i]; float g = gradient[i];
В соответствии с методом Adam сначала определим моменты.
m = b1 * m + (1 - b1) * g; v = b2 * v + (1 - b2) * pow(g, 2);
На основании полученных моментов посчитаем необходимую корректировку параметра.
float delta = m / (v != 0.0f ? sqrt(v) : 1.0f);
И сохраним все данные в соответствующие элементы глобальных буферов.
target[i] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[i] = m; matrix_v[i] = v; }
Возвращаемся к нашему классу CNeuronDOTOCL и создадим метод updateRelativePositionsBias вызова кернела по уже классической схеме. Здесь мы используем 1 мерное пространство задач.
bool CNeuronDOTOCL::updateRelativePositionsBias(void) { if(!OpenCL) return false; //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {cRelativePositionsBias.Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_gradient, cRelativePositionsBias.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_matrix_m, cRelativePositionsBias.getFirstMomentumIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_matrix_v, cRelativePositionsBias.getSecondMomentumIndex())) return false; if(!OpenCL.SetArgument(def_k_RPBUpdateAdam, def_k_rpbw_b1, b1)) return false; if(!OpenCL.SetArgument(def_k_RPBUpdateAdam, def_k_rpbw_b2, b2)) return false; ResetLastError(); if(!OpenCL.Execute(def_k_RPBUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Подготовительная работа завершена. И мы переходим к созданию верхнеуровневого метода обновления параметров блока updateInputWeights. В параметрах метод получает указатель на объект предыдущего слоя. В данном случае мы опускаем проверку полученного указателя, так как она будет выполнена в методах внутренних слоев.
Сначала мы проверяем необходимость обновления параметров слоя масштабирования. И в случае необходимости вызываем одноименный метод указанного слоя.
if(iWindowSize != iPrevWindowSize) { if(!cProjInput.UpdateInputWeights(NeuronOCL)) return false; if(!cQKV.UpdateInputWeights(GetPointer(cProjInput))) return false; } else { if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; }
Затем мы обновляем параметры слоя генерации сущностей Query, Key и Value.
Аналогичным образом обновляем параметры всех внутренних слоев.
if(!cProj.UpdateInputWeights(GetPointer(MHAttentionOut))) return false; if(!cFF1.UpdateInputWeights(GetPointer(AttentionOut))) return false; if(!cFF2.UpdateInputWeights(GetPointer(cFF1))) return false; if(!cCAtten.UpdateInputWeights(GetPointer(SAttenOut))) return false;
И в завершении метода осуществляем обновления параметров позиционного смещения.
if(!updateRelativePositionsBias()) return false; //--- return true; }
При этом не забываем контролировать процесс выполнения операций на каждом шаге.
На этом мы завершаем рассмотрение методов нового нейронного слоя CNeuronDOTOCL. С полным кодом класса и всех его методов, в том числе которые не были описаны в данной статье, Вы можете самостоятельно ознакомиться во вложении.
А мы двигаемся дальше и переходим к построению архитектуры нашей новой модели.
2.2 Архитектура модели
Как обычно, архитектуру нашей модели мы будем описывать в методе CreateDescriptions. В параметрах метод получает указатели на 3 динамических массива для сохранения описания моделей. В теле метода мы сразу проверяем актуальность полученных указателей и, при необходимости, создаем новые экземпляры массивов.
bool CreateDescriptions(CArrayObj *dot, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Как Вы могли заметить, мы будем создавать 3 модели:
- DOT
- Actor
- Critic.
Блок DOT предусмотрен архитектурой DFFT, чего не скажешь об Актере и Критике. Но я хочу Вам напомнить, что методом DFFT предлагается создание блока TAE с выходами классификации и регрессии. Последовательное использование Актера и Критика должно эмитировать блок TAE. Актер является классификатором действий, а Критик — регрессией вознаграждения.
На вход модели DOT мы подаем описание текущего состояние окружающей среды.
//--- DOT dot.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
"Сырые" данные мы обрабатываем в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
После чего создаем эмбединг последних данных и добавляем их в стек.
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!dot.Add(descr)) { delete descr; return false; }
Далее мы добавляем позиционное кодирование данных.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!dot.Add(descr)) { delete descr; return false; }
До этого момента мы повторили архитектуру эмбедингов из прошлых работ. Но далее начинаются изменения. Мы добавляем первый блок DOT, в котором осуществляется анализ в разрезе отдельных состояний.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
В следующем блоке мы сжимаем данные в 2 раза, но продолжаем анализировать в разрезе отдельных состояний.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; prev_wout = descr.window = prev_wout / 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
Далее мы группируем данные для анализа в размере 2 последовательных состояний.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; prev_count = descr.count = prev_count / 2; prev_wout = descr.window = prev_wout * 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
И ещё раз сжимаем данные.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; prev_wout = descr.window = prev_wout / 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
Последний слой модели DOT выходит за рамки метода DFFT. Здесь я добавил слой кросс-внимания.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMH2AttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = prev_wout / descr.step; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
Модель Актера получает на вход обработанные в модели DOT состояния окружающей среды.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count*prev_wout; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полученные данные объединяются с текущим состоянием счета.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
Данные обрабатываются 2 полносвязными слоями.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И на выходе генерируем стохастическую политику Актера.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Критик также использует обработанные состояния окружающей среды в качестве исходных данных.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; }
Описание состояния окружающей среды дополняем действиями Агента.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; }
Данные обрабатываются 2 полносвязными слоями с вектором вознаграждений на выходе.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.3 Советник взаимодействия с окружающей средой
После составления архитектуры моделей мы переходим к созданию советника взаимодействия с окружающей "...\Experts\DFFT\Research.mq5". Данный советник предназначен для сбора первичной обучающей выборки и последующего обновления буфера воспроизведения опыта. Советник так же может использоваться для тестирования обученной модели. Хотя для выполнения данного функционала предусмотрен советник "...\Experts\DFFT\Test.mq5". Оба советника имеют похожий алгоритм. Только последний не сохраняет данные в буфер воспроизведения опыта для последующего обучения. Это сделано для "честного" теста обученной модели.
Сразу скажу, что оба советника во многом скопированы из предыдущих работ. В рамках статьи мы лишь точечно остановимся на изменениях, имеющих отношения к специфике моделей.
В рамках функционала сбора данных мы не будем использовать модель Критика.
CNet DOT; CNet Actor;
В методе инициализации советника мы сначала подключаем необходимые индикаторы.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- load models float temp;
После чего пробуем загрузить предварительно обученные модели.
if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, actor, critic)) { delete dot; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Actor.Create(actor)) { delete dot; delete actor; delete critic; return INIT_FAILED; } delete dot; delete actor; delete critic; }
Если не удалось загрузить модели, то мы инициализируем новые модели случайными параметрами. После чего обе модели переносим в единый контекст OpenCL.
Actor.SetOpenCL(DOT.GetOpenCL());
И осуществляем минимальную проверку архитектуры модели.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
И сохраним состояние баланса в локальной переменной.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Непосредственное взаимодействие с окружающей средой и сбор данных осуществляется в методе OnTick. В теле метода мы сначала проверяем наступление события открытия нового бара. Весь анализ мы осуществляем только на новой свече.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Далее мы обновляем исторические данные.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
И заполняем буфер описания состояния окружающей среды.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Следующим этапом мы собираем данные о текущем состоянии счета.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Собранные данные консолидируем в буфере описания состояния счета.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
Здесь же добавим временную метку текущего состояния.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); //--- if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return;
После сбора исходных данных мы осуществляем прямой проход Энкодера.
if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
И сразу осуществляем прямой проход Актера.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(DOT), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Мы получаем результаты работы модели.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions);
И дешифруем их с совершением торговых операций.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Данные, полученные от окружающей среды, мы сохраняем в буфер воспроизведения опыта.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
Остальные методы советника перенесены без изменений. И Вы можете самостоятельно ознакомиться с ними во вложении.
2.4 Советник обучения моделей
После сбора обучающей выборки мы переходим к построению советника обучения моделей "...\Experts\DFFT\Study.mq5". Как и советники взаимодействия с окружающей средой, его алгоритм был во многом заимствован из предыдущих работ. Поэтому в рамках данной статьи я предлагаю рассмотреть лишь метод непосредственного обучения моделей Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
В теле метода мы сначала генерируем вектор вероятностей выбора траекторий из обучающей выборки в соответствии с их доходностью. Наиболее прибыльные проходы будут использоваться чаще для обучения моделей.
Далее мы объявим необходимые локальные переменны.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
После завершения подготовительной работы мы организуем систему циклов обучения моделей. Напомню, что в модели Энкодера мы использовали стек исторических данных. Такая модель сильно чувствительна к исторической последовательности подаваемых данных. Поэтому во внешнем цикле мы будем сэмплировать траекторию из буфера воспроизведения опыта и начальное состояние для обучения на этой траектории.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
После чего мы очистим внутренний стек модели.
DOT.Clear();
И организуем вложенный цикл извлечения из буфера воспроизведения опыта последовательных исторических состояний для обучения модели. Пакет обучения модели мы установили на 2 суток больше глубины внутреннего стек модели.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
В теле вложенного цикла мы извлекаем из буфера воспроизведения опыта одно состояние окружающей среды и используем его для прямого прохода Энкодера.
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Для обучения политики Актера нам сначала необходимо заполнить буфер описания состояния счета, как мы это делали в советнике взаимодействия с окружающей средой. Только сейчас мы не опрашиваем окружающую среду, а извлекаем данные из буфера воспроизведения опыта.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Мы так же добавляем временную метку.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
После чего осуществляем прямой проход Актера и Критика.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(DOT), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(DOT), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее обучаем Актера действиям из буфера воспроизведения опыта с передачей градиента на модель Энкодера. Классификация объектов в блоке TAE, как предлагается методом DFFT.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее мы определяем вознаграждение за следующий переход в новое состояние окружающей среды.
result.Assign(Buffer[tr].States[i+1].rewards); target.Assign(Buffer[tr].States[i+2].rewards); result=result-target*DiscFactor;
И обучаем модель Критика с передачей градиента ошибки обоим моделям.
Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Здесь стоит обратить внимание, что во многих алгоритмах ранее мы старались избегать взаимной адаптации моделей. С опасением получения нежелательных результатов. Авторы же метода DFFT, напротив, утверждают, что такой подход позволит более полно настроить параметры Энкодера на извлечение максимальной информации.
После обучения моделей мы информируем пользователя о ходе процесса обучения и переходим к следующей итерации цикла.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После успешного завершения всех итераций процесса обучения мы очищаем поле комментариев на графике. Выводим результаты обучения в журнал. И инициализируем завершение работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение методов советника обучения моделей. С полным кодом советника Вы можете самостоятельно ознакомиться во вложении. Там же Вы найдете все программы, используемые при подготовке данной статьи.
3. Тестирование
Выше была проведена довольно большая работа по имплементации метода Decoder-Free Fully Transformer-based (DFFT) средствами MQL5. И теперь пришло время 3 части нашей статьи — тестирование проделанной работы. Как всегда, обучение и тестирование новой модели осуществляется на исторических данных инструмента EURUSD тайм-фрейм H1. Параметры всех индикаторов используются по умолчанию.
Для обучения модели было собрано 500 случайных траекторий на временном отрезке в первые 7 месяцев 2023 года. Тестирования обученной модели осуществлялось на исторических данных за август 2023 года. Как можно заметить, тестовые интервал не входил в обучающую выборку. Что позволяет оценить работу модели на новых данных.
Должен признать, что модель получилась довольно "лёгкая" в плане потребления вычислительных ресурсов как в процессе обучения, так и в режиме эксплуатации при тестировании.
Процесс обучения был довольно стабильным с плавным снижением ошибки как Актера, так и Критика. В процессе обучения была получена модель, способная генерировать незначительную прибыль как на обучающих, так и на тестовых данных. Тем не менее, уровень доходности хотелось бы получить выше, а линию баланса более ровной.
Заключение
В данной статье мы познакомились с методом DFFT — эффективным детектор объектов на основе трансформера без использования декодера, который был представлен для решения задач компьютерного видения. Основные особенности данного подхода включают использование трансформера для извлечения признаков и плотного прогнозирования на одной карте признаков. Метод предлагает новые модули для улучшения эффективности обучения и эксплуатации модели.
Авторы метода продемонстрировали, что DFFT обеспечивает высокую точность детекции объектов при сравнительно низких вычислительных затратах.
В практической части данной статьи мы реализовали предложенные подходы средствами MQL5. Провели обучение и тестирование построенной модели на реальных исторических данных. Полученные результаты подтверждают эффективность предложенных алгоритмов и заслуживают более детального практического исследования.
А я Вам хочу напомнить, что все программы, представленные в статье, носят сугубо ознакомительный характер. И созданы только для демонстрации предложенных подходов, а также их возможностей. Перед использованием на реальных финансовых рынках программы должны быть доработаны и тщательно протестированы.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Привет, Дмитрий!
В первую очередь большое спасибо за данный алгоритм. Возможно ли обучить модель на исторических данных и использовать обученные данные в активной ситуации?
Rgs
Андреас