
Нейросети — это просто (Часть 73): АвтоБоты прогнозирования ценового движения

Введение
Эффективное прогнозирование движения валютных пар является ключевым аспектом безопасного управления торговыми операциями. В данном контексте особое внимание уделяется разработке эффективных моделей, способных точно аппроксимировать совместное распределение контекстуальной и временной информации, необходимой для принятия торговых решений. Для решения подобных задач я предлагаю вам познакомиться с методом "Latent Variable Sequential Set Transformers" (AutoBots), представленным в статье "Latent Variable Sequential Set Transformers For Joint Multi-Agent Motion Prediction". Предлагаемый метод основан на архитектуре Энкодер-Декодер, и был разработан для решения задач безопасного управления робототехнических систем. Он позволяет генерировать последовательности траекторий для множества агентов, согласованных со сценой. "Автоботы" могут прогнозировать траекторию одного эго-агента или распределение будущих траекторий для всех агентов на сцене. В нашем случае, мы попробуем применить предложенную модель для генерации последовательностей ценового движения валютных пар, согласованных с динамикой рынка.
1. Алгоритмы “AutoBots”
"Latent Variable Sequential Set Transformers" (AutoBots) — это метод, базирующийся на архитектуре Энкодер-Декодер и обрабатывающий последовательности множеств. AutoBot принимает на вход последовательность множеств X1:t = (X1, …, Xt), которую в задаче прогнозирования движения можно рассматривать как состояние окружающей среды за t временных шагов. Каждое множество содержит M элементов (агентов, финансовых инструментов и/или индикаторов) с K атрибутами (признаками). Для обработки социальной и временной информации в Энкодере применяются следующие две трансформации.
Во-первых, Энкодер AutoBots вводит временную информацию в последовательность множеств с использованием синусоидальной функции позиционного кодирования PE(.). На этом этапе данные анализируются как коллекция матриц, {X0, …, XM}, которые описывают эволюцию агентов во времени. Энкодер обрабатывает временные отношения между множествами с использованием блока многоголового внимания.
Затем обрабатываются временные срезы S, извлекая наборы состояний агентов Sꚍ в какой-то момент времени ꚍ, и обрабатываем их снова в блоке многоголового внимания.
Эти две операции повторяются Lenc раз для получения контекстного тензора C размерностью {dK, M, t}, который подводит итоговое представление всей сцены исходных данных, где t — количество временных шагов в сцене исходных данных.
Целью Декодера является генерация прогнозов, согласованных во времени и социально в контексте многомодальных распределений данных. Для генерации c различных прогнозов для одной и той же сцены исходных данных, Декодер AutoBot использует c матриц обучаемых начальных параметров Qi размерностью {dK, T}, где T — это горизонт планирования.
Интуитивно каждая матрица обучаемых начальных параметров соответствует установке дискретной латентной переменной в AutoBot. Каждая обучаемая матрица Qi затем повторяется M раз вдоль размерности агента, чтобы получить входной тензор Q0i размерностью {dK, M, T}.
Алгоритмом предусмотрена возможность использования дополнительной контекстной информации, которая кодируется с использованием сверточной нейронной сети для создания вектора признаков mi. Чтобы предоставить контекстную информацию всем будущим временным шагам и всем элементам множества, предлагается копировать этот вектор по размерностям M и T, создавая тензор Mi размерности {dK, M, T}. Каждый тензор Q0i затем объединяется с Mi вдоль размерности dK. Этот тензор затем обрабатывается с использованием построчного полносвязного слоя (rFFN) для получения тензора H размерности {dK, M, T}.
Декодирование начинается обработкой временной размерности, обусловленной на выходе Энкодера (C), а так же закодированных начальных параметрах и информации об окружении (H). Декодер обрабатывает каждого агента в H отдельно с использованием блока многоголового внимания. Таким образом мы получаем тензор, кодирующий будущую временную эволюцию каждого элемента множества независимо.
Чтобы обеспечить социальную согласованность будущей сцены между элементами множества, мы обрабатываем каждый временной срез H0, извлекая наборы состояний агентов H0ꚍ в какой-то будущий момент времени ꚍ. Каждый элемент последовательности обрабатывается блоком многоголового внимания. По сути, данный блок выполняет внимание на каждом временном шаге между всеми элементами множества.
Эти две операции повторяются Ldec раз для создания конечного выходного тензора для агента i. Процесс декодирования повторяется c раз с различными обучаемыми начальными параметрами Qi и дополнительной контекстной информацией mi. Выход декодера — это тензор O размерности {dK, M, T, c}, который затем может быть обработан с использованием нейронной сети ф(.), чтобы получить желаемое представление вывода.
Одним из основных вкладов, делающих результат и время обучения AutoBot быстрее по сравнению с другими методами, является использование начальных параметров Q декодера. Эти параметры служат двойной цели. Во-первых, они учитывают разнообразие в прогнозировании будущего, где каждая матрица Qi соответствует одной установке дискретной латентной переменной. Во-вторых, они способствуют ускорению AutoBot, позволяя ему выполнять вывод по всей сцене с одним проходом через Декодер без последовательного выбора.
Авторская визуализация метода представлена ниже.
")
2. Реализация средствами MQL5
Выше мы познакомились с теоретическими аспектами метода "Latent Variable Sequential Set Transformers" (AutoBots). И теперь переходим к практической части нашей статьи, в которой мы реализуем свое видение предложенного метода средствами MQL5.
Для начала следует обратить внимание на следующие моменты.
Первое, в методе предусмотрено позиционное кодирование. Впрочем, это не является чем-то новым и аналогичное позиционное кодирование предусмотрено базовым методом Self-Attention. Но дело в том, что ранее, при изучении методов внимания, позиционное кодирование исходных данных осуществлялось на стороне основной программы. Однако в АвтоБоте позиционное кодирование осуществляется внутри модели после предварительной обработки и создания эмбединга исходных данных. Конечно, мы могли бы вынести предварительную обработку данных в отдельную модель. И осуществлять позиционное кодирование на стороне основной программы перед передачей данных в Энкодер. Но такой вариант реализации потребует дополнительные операции передачи данных между памятью контекста OpenCL и основной программы. Кроме того, такая реализации ограничивает степень нашей свободы с вариациями использования различных архитектур моделей в рамках одной программы без внесения дополнительных корректировок в её код. Поэтому для нас предпочтительней организовать весь процесс в рамках одной модели.
Второй момент, как в Энкодере, так и в Декодере методом "Latent Variable Sequential Set Transformers" (AutoBots) предполагается поочередное использование блоков внимания в рамках различных измерений анализируемых тензоров (анализ временных и социальных зависимостей). Для изменения измерения акцента внимания, нам необходимо внесение изменений в слой многоголового внимания CNeuronMLMHAttentionOCL, или осуществить транспонирование тензоров. Транспонирование тензоров здесь выглядит более простой задачей. И опять же, мы останавливаемся на тех же моментах, которые обсуждались для позиционного кодирования. Мы не будем их повторять, но приходим к необходимости создания слоя транспонирования тензоров на стороне контекста OpenCL.
2.1 Слой позиционного кодирования
Начнем мы работу со слоя позиционного кодирования. Класс слоя позиционного кодирования CNeuronPositionEncoder мы наследуем от базового класса нейронных слоев в нашей библиотеке CNeuronBaseOCL и переопределяем базовый набор методов:
- Init — инициализации
- feedForward — прямого прохода
- calcInputGradients — распределения градиента ошибки к предыдущему слою
- updateInputWeights — обновления весовых коэффициентов
- Save и Load — работы с файлами.
class CNeuronPositionEncoder : public CNeuronBaseOCL { protected: CBufferFloat PositionEncoder; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronPositionEncoder(void) {}; ~CNeuronPositionEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) { return true; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronPEOCL; } virtual void SetOpenCL(COpenCLMy *obj); };
Конструктор и деструктор класса мы оставляем пустыми.
И прежде, чем перейти дальше к рассмотрению методов, давайте немного обсудим функциональность и логику построения класса. В алгоритме Трансформера предусмотрено позиционное кодирование путем добавления к исходным данным синусоидальных гармоник с использованием функций:
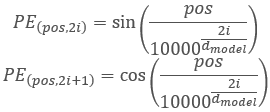
Здесь надо обратить внимание, что в данном случае осуществляется позиционное кодирование элементов в анализируемой последовательности и не связано с используемыми нами ранее гармониками временных меток, которые мы создаем на стороне основной программы. Процесс похожий, но несет иную смысловую нагрузку.
Очевидно, что размер анализируемой последовательности в модели будет всегда постоянным. Поэтому мы можем просто создать и заполнить буфер гармоник PositionEncoder в методе инициализации класса Init. А при прямом проходе в методе feedForward мы лишь прибавим значения гармоник к исходным данным.
С прямым проходом разобрались. А как с обратным проходом? В прямом проходе мы осуществили сложение двух тензоров. Следовательно, градиент ошибки при обратном проходе равномерно распределяется или полностью передается на оба слагаемых. Тензор гармоник позиционного кодирования в нашем случае является константой. Поэтому весь градиент ошибки мы будем передавать на предыдущий слой.
Что же касается обучаемых весовых коэффициентов, то их просто нет в слое позиционного кодирования. Следовательно, метод updateInputWeights переопределен лишь для совместимости классов и всегда возвращает true.
С логикой разобрались. Давайте посмотрим на реализацию. Как уже было сказано выше, инициализация класса осуществляется в методе Init. В параметрах метод получает:
- numOutputs — количество связей с последующим слоем
- open_cl — указатель на контекст OpenCL
- count — количество элементов в последовательности
- window — количество параметров для каждого элемента последовательности
- optimization_type — метод оптимизации параметров.
bool CNeuronPositionEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false;
В теле метода мы сразу вызываем метод инициализации родительского класса, в котором реализован базовый функционал. И проверяем результат выполнения операций.
Далее нам предстоит создать гармоники позиционного кодирования. Для этого мы воспользуемся матричными операциями. Сначала подготовим матрицу.
matrix<float> pe = matrix<float>::Zeros(count, window);
Создадим вектор нумерации позиций элементов в тензоре и константный множитель, который используется для всех элементов.
vector<float> position = vector<float>::Ones(count); position = position.CumSum() - 1; float multipl = -MathLog(10000.0f) / window;
И так как формулами позиционного кодирования предусмотрено чередование синуса и косинуса для гармоник, то заполнять матрицу мы будем в цикле с шагом 2. В теле цикла мы сначала рассчитываем вектор позиционных значений, а затем в четные колонки добавляем синус от вектора позиционных значений. В нечетных колонках запишем косинус от того же вектора.
for(uint i = 0; i < window; i += 2) { vector<float> temp = position * MathExp(i * multipl); pe.Col(MathSin(temp), i); if((i + 1) < window) pe.Col(MathCos(temp), i + 1); }
Полученные позиционные гармоники мы скопируем в буфер данных и перенесем его в контекст OpenCL.
if(!PositionEncoder.AssignArray(pe)) return false; //--- return PositionEncoder.BufferCreate(open_cl); }
После инициализации класса CNeuronPositionEncoder, мы переходим к организации прямого прохода в методе feedForward. Как вы могли заметить, мы не создавали кернел организации процесса на стороне контекста OpenCL, а переходим сразу к реализации метода. Дело в том, что кернел сложения 2 матриц SumMatrix нами уже был создан ранее при реализации метода Self-Attention.
Как обычно, метод прямого прохода feedForward в параметрах получает указатель на предыдущий нейронный слой, который является для нас исходными данными. В теле метода мы проверяем полученный указатель.
bool CNeuronPositionEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!Gradient || Gradient != NeuronOCL.getGradient()) { if(!!Gradient) delete Gradient; Gradient = NeuronOCL.getGradient(); }
И сразу осуществим подмену указателя на буфер градиентов ошибки. Такой нехитрый способ позволит нам при обратном проходе напрямую передавать градиент ошибки от последующего слоя к предыдущему, исключая излишнее копирование данных в нашем слое позиционного кодирования.
Далее мы передаем необходимые данные в параметры кернела сложения векторов.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = Neurons(); if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix1, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix2, PositionEncoder.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix_out, Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_dimension, (int)1)) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_multiplyer, 1.0f)) return false;
И ставим кернел в очередь выполнения.
if(!OpenCL.Execute(def_k_MatrixSum, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel MatrixSum: %d", GetLastError()); return false; } //--- return true; }
Проверяем результаты выполнения операций. И на этом можно считать завершенной организацию процесса прямого прохода.
Как уже было сказано выше, слой позиционного кодирования не содержит обучаемых параметров. Поэтому метод updateInputWeights "пустой" и всегда возвращает true. Подменив указатель буфера градиента ошибки, мы исключили слой позиционного кодирования полностью из процесса распределения градиента ошибки. Следовательно, и метод calcInputGradients, как и метод обновления параметров, остается "пустой" и переопределен только для целей совместимости.
На этом мы заканчиваем рассмотрение методов слоя позиционного кодирования. С полным кодом класса вы можете познакомиться во вложенном файле "...\Experts\NeuroNet_DNG\NeuroNet.mqh", который содержит все классы нашей библиотеки.
2.2 Транспонирование тензоров
Следующий слой, который мы договорились создать — это слой транспонирования тензоров CNeuronTransposeOCL. Как и в случае слоя позиционного кодирования, при создании класса мы наследуемся от базового класса нейронных слоев CNeuronBaseOCL. Список переопределяемых классов остается стандартным. Однако мы добавим 2 переменных в классе для хранения размеров транспонируемой матрицы.
class CNeuronTransposeOCL : public CNeuronBaseOCL { protected: uint iWindow; uint iCount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronTransposeOCL(void) {}; ~CNeuronTransposeOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronTransposeOCL; } };
Конструктор и деструктор класса остаются пустыми. А метод инициализации класса Init максимально упрощен. В теле метода мы лишь вызываем одноименный метод родительского класса и сохраняем, полученные в параметрах, размеры транспонируемой матрицы. Однако не забываем проверить результат выполнения операций.
bool CNeuronTransposeOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false; //--- iWindow = window; iCount = count; //--- return true; }
А вот для метода прямого прохода нам предстоит сначала создать тензор транспонирования матриц Transpose. В параметрах кернела мы будем передавать лишь указатели на буферы матриц исходных данных и результатов. Размеры матриц мы получаем из 2 мерного пространства задач.
__kernel void Transpose(__global float *matrix_in, ///<[in] Input matrix __global float *matrix_out ///<[out] Output matrix ) { const int r = get_global_id(0); const int c = get_global_id(1); const int rows = get_global_size(0); const int cols = get_global_size(1); //--- matrix_out[c * rows + r] = matrix_in[r * cols + c]; }
Алгоритм кернела довольно прост. Мы лишь определяем позиции элемента в матрицах исходных данных и результатов. После чего осуществляем перенос значения.
Вызов кернела осуществляется из метода прямого прохода feedForward. Алгоритм вызова кернела аналогичен указанному выше. Мы сначала определяем пространство задач, только на этот раз в 2 мерном пространстве (количество элементов в последовательности * количество признаков в каждом элементе последовательности). Затем передаем указатели на буферы данных в параметры кернела и осуществляем его постановку в очередь выполнения. При этом не забываем проверить результат выполнения операций.
bool CNeuronTransposeOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iCount, iWindow}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, Output.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
В процессе обратного прохода нам предстоит провести градиент ошибки в обратном направлении. И как ни странно, нам необходимо транспонировать матрицу градиентов ошибки. Следовательно, мы воспользуемся тем же кернелом. Только обратим размерность пространства задач и укажем указатели на буферы градиентов ошибки.
bool CNeuronTransposeOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iWindow, iCount}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, Gradient.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
Как можно заметить, класс CNeuronTransposeOCL не содержит обучаемых параметров, поэтому метод updateInputWeights всегда возвращает true.
2.3 Архитектура "АвтоБота"
Выше мы создали 2 новых довольно универсальных слоя. И теперь можем перейти непосредственно к реализации метода "Latent Variable Sequential Set Transformers" (AutoBots). И сначала мы создадим архитектуру модели прогнозирования ценового движения в методе CreateTrajNetDescriptions. С целью снижения операций на стороне основной программы было принято решение организовать работу АвтоБота в рамках одной модели. Для её описания в метод передается один указатель на динамический массив. В теле метода мы проверяем полученный указатель и, при необходимости, создаем новый экземпляр объекта динамического массива.
bool CreateTrajNetDescriptions(CArrayObj *autobot) { //--- CLayerDescription *descr; //--- if(!autobot) { autobot = new CArrayObj(); if(!autobot) return false; }
На вход модели подается тензор исходных данных. Как и ранее, для оптимизации вычислений в процессе эксплуатации и обучения модели, в качестве исходных данных используется только описание последнего бара. Вся история накапливается внутри буфера слоя Эмбединга.
//--- Encoder autobot.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Первичная обработка исходных данных осуществляется в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000,GPTBars); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
После чего мы генерируем эмбединг состояния и добавляем его в буфер исторических данных.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!autobot.Add(descr)) { delete descr; return false; }
Обратите внимание, что в данном случае мы создаем эмбединг лишь одной сущности описания текущего состояния окружающей среды. И функционал данного слоя приближен к полносвязному. Однако использование слоя CNeuronEmbeddingOCL обусловлено необходимостью создания буфера исторической последовательности эмбедингов. Тем не менее, алгоритм не ограничивает нас анализом только одного бара одного инструмента. Мы можем анализировать как несколько свечей, так и несколько инструментов. Но в таком случае нужно скорректировать массив эмбедингов.
Далее, ко всей исторической последовательности эмбедингов мы добавляем тензор позиционного кодирования.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; }
И осуществляем первый блок внимания, для оценки зависимостей между сценами во времени.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Затем нам предстоит проанализировать зависимости между отдельными признаками. Для этого мы осуществляем транспонирование тензора и применяем блок внимания к транспонированному тензору.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Обратите внимание, после транспонирования мы изменяем и размерности в блоке внимания таким образом, чтобы они соответствовали транспонированному тензору.
Транспонируем тензор еще раз, чтобы вернуть его к исходной размерности. И повторим блоки внимания Энкодера ещё раз.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_wout; descr.window = prev_count; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
На выходе Энкодера мы получаем контекст описания текущего состояния окружающей среды. И нам предстоит передать его в Декодер, для прогноза будущих параметров ценового движения на необходимую глубину планирования. Однако, алгоритмом "Latent Variable Sequential Set Transformers" на данном этапе предусмотрено добавление обучаемых начальных параметров Q. Но в текущей реализации нашей библиотеки обучаются только весовые коэффициенты нейронных слоев. Дабы не усложнять сложившейся процесс, было принято может быть и не стандартное решение, но весьма эффективное. В данном случае мы воспользуемся слоем конкатенации тензоров СNeuronConcatenate. Первая часть слоя заменит полносвязный слой для изменения представления контекста текущего состояния окружающей среды, полученного от Энкодера. А весовые коэффициенты второго блока будут выполнять роль начальных обучаемых параметров Q. Чтобы не искажать значения Q параметров на второй вход мы будем подавать вектор, заполненный "1".
На выходе слоя мы ожидаем получить тензор эмбеддинга состояний на заданную глубину планирования.
//--- Decoder //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = PrecoderBars * EmbeddingSize; descr.window = prev_count * prev_wout; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Как и в Энкодере, мы сначала смотрим на зависимости между состояниями во времени.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = PrecoderBars; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
А затем транспонируем тензор и анализируем контекстную зависимость между отдельным признаками.
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
После чего ещё раз повторяем операции Декодера.
//--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count * prev_wout; descr.window = descr.count; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Обратите внимание, что использование константного вектора из "1" в качестве второго входа модели, позволяет нам многократно повторять слой конкатенации в Декодере. При этом обучаемые весовые параметры выполняют роль Q параметров, уникальных для каждого слоя.
В завершении декодера мы используем полносвязный слой, который позволяет нам представить данные в необходимом формате.
//--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = PrecoderBars * 3; descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 Обучение "АвтоБота"
Выше представлена архитектура модели AutoBot для прогнозирования параметров предстоящего ценового движения на заданную глубину планирования. Использование результатов работы обученной модели ограничивается лишь вашей фантазией. Имея прогноз последующего ценового движения, вы можете построить классический алгоритмический советник для совершения операций в соответствии с полученным прогнозом. А можете передать в модель Актера для генерации непосредственно рекомендаций к действию. В своей работе я воспользовался 2 вариантом. При этом архитектура моделей Актера и постановки целей были заимствованы из предыдущей статьи. Изменения коснулись лишь слоя исходных данных для соответствия результатам вышеприведенной модели AutoBot. Но мы не будем сейчас на них останавливаться. Вы можете самостоятельно с ними ознакомиться во вложении (метод CreateDescriptions). Там же вы можете ознакомиться с точечными корректировками в советнике взаимодействия с окружающей средой "...\Experts\AutoBots\Research.mq5". А мы переходим к организации процесса обучения модели прогнозирования предстоящего ценового движения, который организован в советнике "...\Experts\AutoBots\StudyTraj.mq5".
В данном советнике мы обучаем только одну модель.
CNet Autobot;
В методе инициализации советника OnInit мы сначала загружаем обучающую выборку.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
После чего, пробуем загрузить предварительно обученную модель АвтоБота и, в случае возникновения ошибки, создаем новую модель, инициализированную случайными параметрами.
//--- load models float temp; if(!Autobot.Load(FileName + "Traj.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *autobot = new CArrayObj(); if(!CreateTrajNetDescriptions(autobot)) { delete autobot; return INIT_FAILED; } if(!Autobot.Create(autobot)) { delete autobot; return INIT_FAILED; } delete autobot; //--- }
Затем проверяем архитектуру модели на соответствие основным критериям.
Autobot.getResults(Result); if(Result.Total() != PrecoderBars * 3) { PrintFormat("The scope of the Autobot does not match the precoder bars (%d <> %d)", PrecoderBars * 3, Result.Total()); return INIT_FAILED; } //--- Autobot.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Autobot doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Создаем необходимые буферы данных.
OpenCL = Autobot.GetOpenCL(); if(!Ones.BufferInit(EmbeddingSize, 1) || !Gradient.BufferInit(EmbeddingSize, 0) || !Ones.BufferCreate(OpenCL) || !Gradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; } State.BufferInit(HistoryBars * BarDescr, 0);
И генерируем пользовательское событие начала обучения модели.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
В методе деинициализации советника сохраняем обученную модель и удаляем из памяти динамические объекты.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) Autobot.Save(FileName + "Traj.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; delete OpenCL; }
Обучение модели, как обычно, мы осуществляем в методе Train. В теле метода мы сначала определяем вероятности выбора траекторий, на основании их доходности.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
После чего, объявляем и инициализируем локальные переменные.
vector<float> result, target, inp; matrix<float> targets; matrix<float> delta; STE = vector<float>::Zeros(PrecoderBars * 3); int std_count = 0; int batch = GPTBars + 50; bool Stop = false; uint ticks = GetTickCount(); ulong size = HistoryBars * BarDescr;
Как всегда, при обучении модели траекторий мы будем ограничиваться только подходами, предложенными авторами метода Latent Variable Sequential Set Transformers. В частности, мы будем акцентировать внимание обучения на максимальных отклонениях, как в методе CFPI. Кроме того, для устойчивости работы модели в условиях стохастического рынка, мы "расширим" пространство обучающей выборки путем добавления шума к исходным данным, как было предложено в методе SSWNP. Для реализации указанных подходов в числе локальных переменных мы объявим матрицу изменений параметров delta и вектор среднеквадратических ошибок STE.
Но вернемся к алгоритму нашего метода. В архитектуре нашего "АвтоБота" прогнозирования траектории мы использовали слой Эмбединга с встроенным буфером накопления исторических данных, что позволяет нам не пересчитывать представления повторяющихся данных в процессе эксплуатации модели. Однако, такой подход требует и соблюдения исторической последовательности при подаче исходных данных в процессе обучения. Следовательно, для обучения модели мы будем использовать систему вложенных циклов. Внешний цикл определяет количество итераций обучения.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
В теле цикла мы сэмплируем траекторию из буфера воспроизведения опыта с учетом ранее рассчитанных вероятностей. После чего случайным образом определяем начальное состояние обучения на выбранной траектории.
Тут же мы определяем состояние окончания пакета обучения. Очищаем буферы накопления истории нашего Автобота. И подготовим матрицу для записи изменений параметров.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear(); delta = matrix<float>::Zeros(end - state - 1, Buffer[tr].States[state].state.Size());
Далее мы создаем вложенный цикл работы с чистыми траекториями, в теле которого заполняем буфер исходных данных.
for(int i = state; i < end; i++) { inp.Assign(Buffer[tr].States[i].state); State.AssignArray(inp);
И рассчитаем отклонение в значениях параметров между 2 последующими состояниями окружающей среды.
if(i < (end - 1)) delta.Row(inp, row); if(row > 0) delta.Row(delta.Row(row - 1) - inp, row - 1);
После проведения подготовительной работы мы осуществляем прямой проход нашей модели.
if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Обратите внимание, в качестве второго потока исходных данных мы используем буфер, заполненный константными значениями Ones, как и обсуждалось при описании архитектуры модели. Данный буфер был подготовлен в процессе инициализации советника и не изменяется в процессе всего обучения модели.
За прямым проходом следует обратный проход с обновлением параметров модели. Но перед его вызовом нам предстоит сначала подготовить целевые значения. Для этого мы "заглянем немного в будущее", что в процессе обучения нам позволяет сделать обучающая выборка. Из буфера воспроизведения опыта мы извлекаем описание последующих состояний окружающей среды на заданную глубину планирования. И скопируем необходимые данные в вектор целевых значений target.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Затем мы загружаем результаты прямого прохода Автобота и определяем необходимость осуществления обратного прохода по величине ошибки прогнозирования в текущем состоянии.
Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier;
Обратный проход осуществляется при наличии ошибки прогнозирования хотя бы одного из параметров выше порогового значения, которое связано коэффициентом со среднеквадратической ошибкой прогнозирования модели.
if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Далее мы информируем пользователя о ходе процесса обучения и переходим к следующей итерации обработки пакета чистой траектории.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После завершения пакета обучения чистой траектории, мы переходим ко второму блоку — модели траектории на данных с добавлением шума. Здесь мы сначала определим параметры репараметризации шума.
//--- With noise vector<float> std_delta = delta.Std(0) * STD_Delta_Multiplier; vector<float> mean_delta = delta.Mean(0);
И подготовим массив и вектор для работы с шумом.
ulong inp_total = std_delta.Size(); vector<float> noise = vector<float>::Zeros(inp_total); double ar_noise[];
Мы также сэмплируем траекторию из обучающей выборки. Определяем начальное и конечное состояния пакета обучения на ней. И очищаем исторические буферы нашей модели.
tr = SampleTrajectory(probability); state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; } end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear();
После чего создаем второй вложенный цикл.
for(int i = state; i < end; i++) { if(!Math::MathRandomNormal(0, 1, (int)inp_total, ar_noise)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } noise.Assign(ar_noise); noise = mean_delta + std_delta * noise;
В теле цикла мы генерируем шум и осуществляем его репараметризацию с помощью вышепосчитанных параметров распределения.
Полученный шум мы добавляем к исходным данным и осуществляем прямой проход нашей модели.
inp.Assign(Buffer[tr].States[i].state); inp = inp + noise; State.AssignArray(inp); //--- if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Алгоритм осуществления обратного прохода, включая подготовку целевых данных и определения необходимости его проведения, мы полностью копируем из блока работы с чистой траекторией.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0); Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
В завершение нам остается лишь проинформировать пользователя о ходе процесса обучения и переходим к следующей итерации цикла.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter + 0.5) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После завершения всех итераций системы циклов обучения модели, мы очищаем поле комментариев на графике. Выводим в журнал результаты обучения и завершаем работу советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Autobot", Autobot.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение методов советника обучения модели обучения траектории "...\Experts\AutoBots\StudyTraj.mq5". С его полным кодом вы можете самостоятельно ознакомиться во вложении. Там же вы найдете советники обучения политики Актера "...\Experts\AutoBots\Study.mq5" и тестирования обученной модели на исторических данных "...\Experts\AutoBots\Test.mq5". В указанных советниках мы ограничились лишь точечными правками в части эксплуатации модели АвтоБота, с которыми вы можете ознакомиться самостоятельно. А мы переходим к тестированию проделанной работы.
3. Тестирование
Выше была проделана кропотливая работа по реализации подходов метода "Latent Variable Sequential Set Transformers" (AutoBots) средствами MQL5. И пришло время оценить практические результаты нашего труда. Как всегда, для обучения нашей модели мы используем исторически данные за первые 7 месяцев 2023 года инструмента EURUSD, тайм-фрейм H1. Тестирование обученной политики Актера осуществляется на исторических данных Августа 2023 года. Как можно заметить, тестовый период следует непосредственно за периодом обучения, что обеспечивает максимальную совместимость данных обучающей и тестовой выборок.
Параметры всех индикаторов, используемых для анализа рыночной ситуации, в процессе обучения и тестирования не оптимизировались. Для них были установлены значения по умолчанию.
Как вы могли заметить, состав и структуру исходных данных и результатов работы нашей модели прогнозирования траектории мы перенесли без изменений из предыдущей работы. Следовательно, для обучения модели мы можем воспользоваться ранее созданной базой примеров. Это позволяет нам исключить этап первичного сбора обучающих данных и перейти сразу непосредственно к процессу обучения моделей.
Обучать модели мы будем в 2 этапа:
- обучение модели прогнозирования траектории
- обучение политики Актера.
Модель прогнозирования траектории смотрит только на динамику рынка и анализируемых индикаторов, без привязки к состоянию счета и открытым позициям, которые вносят разнообразие в траектории обучающей выборки. А так как все траектории мы собрали с одного инструмента и на одном историческом промежутке, то в понимании "АвтоБота" все траектории идентичны. Следовательно, мы можем обучать модель прогнозирования ценового движения на одной обучающей выборке без обновления траекторий до получения приемлемых результатов.
И тут я должен сказать, что процесс обучения модели был довольно стабилен и с хорошей динамикой практически постоянного сжижения ошибки. Здесь я должен согласиться с авторами метода, когда они говорят о скорости обучения модели. К примеру, авторами метода утверждается, что в процессе их работы все модели были обучены в течение 48 часов на одном десктопном графическом ускорителе 1080 Ti.
Вдохновленный процессом обучения модели прогнозирования ценового движения, я подумал, что несовсем корректно оценивать алгоритм прогнозирования траектории по результатам работы обученной политики Актера. Да, политика Актера строится на данных полученного прогноза. Но вместе с тем она адаптируется к возможным погрешностям предоставленных прогнозов. Качество такой адаптации это уже другой вопрос, и он относится к архитектуре Актера и процессу его обучения. Однако влияние такой адаптации бесспорно. Поэтому был создан небольшой советник классической алгоритмической торговли "...\Experts\AutoBots\Alternate.mq5".
Советник был создан только для проверки качества прогнозирования ценового движения в условиях Тестера стратегий, и его код, на мой взгляд, не вызывает большого интереса. Поэтому мы не будем на нем останавливаться в рамках данной статьи. А все желающие могут с ним самостоятельно ознакомиться во вложении.
Указанный советник оценивает прогнозное движение и открывает сделки с минимальным лотом в направлении выраженной тенденции на горизонте планирования. Параметры советника не оптимизировались. И тем интереснее полученный результат при проходе советника в тестере стратегий до конца 2023 года.
После обучения модели прогнозирования ценового движения на исторических данных 7 месяцев, мы получили устойчивую тенденцию к росту баланса на протяжении 2 месяцев.

Я напомню, что все сделки совершались с минимальным лотом. А значит, полученный результат зависит только от качества планирования траектории.
Заключение
В данной статье мы познакомились с методом "Latent Variable Sequential Set Transformers" (AutoBots). Предложенные авторами метода подходы основаны на моделировании совместного распределения контекстуальной и временной информации, что предоставляет надежные инструменты для точного (насколько это возможно) прогнозирования предстоящего ценового движения.
AutoBots эксплуатирует архитектуру Энкодер-Декодера и проявляет свою эффективность благодаря использованию многофункциональных блоков внимания, а также внедрению дискретной латентной переменной для моделирования многомодальных распределений.
В практической части статьи мы реализовали предложенные подходы средствами MQL5 и получили многообещающие результаты в части скорости обучения модели и качества прогнозирования.
Таким образом, предложенный алгоритм AutoBots представляет собой перспективный инструмент для решения задач прогнозирования на рынке FOREX, обеспечивая точность, устойчивость к изменениям и способность моделировать многомодальные распределения для более глубокого понимания динамики рыночных движений.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Политики |
| 4 | StudyTraj.mq5 | Советник | Советник обучения модели прогнозирования траектории |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
| 9 | Alternate.mq5 | Советник | Советник тестирования качества прогнозирования траектории |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Не могу найти ресурс, где можно скачать историю сделок. Только текущие сигналы. Скиньте хоть пару ссылок, кто может. Плиз.
На странице Истории любого сигнала внизу есть ссылка
Почему-то все хвалебные отзывы только на забугорных языках. На нашем ни одного.
Это особенность буржуазного менталитета - у них принято хвалить все и вся если только это не явный трэш.
Зайди на любой англоязычный форум и убедишься в этом.
Похоже, что файл NeuroNet.mqh во вложении не содержит новейших функций, которые вы упоминаете в разделе 2.2 Транспонирование тензоров. Я что-то пропустил?
Здравствуйте Дмитрий,
Похоже, что файл NeuroNet.mqh во вложении не содержит новейших функций, которые вы упоминаете в разделе 2.2 Транспонирование тензоров. Я что-то пропустил?