
Нейросети — это просто (Часть 70): Улучшение политики с использованием операторов в закрытой форме (CFPI)

Введение
Подход оптимизации политики Агента с учетом ограничений на его поведение оказался перспективным в решении задач обучения с подкреплением в офлайн режиме. С использованием исторических переходов обучается политика поведения Агента, направленная на максимизацию значения функции ценности.
Ограничения на поведение помогают избежать существенных изменений в распределении действий Агента, что дает достаточную уверенность в корректности оценки стоимости действий. В предыдущей статье мы познакомились с методом SPOT, который эксплуатирует данный подход. В качестве продолжения начатой темы предлагаю познакомиться с алгоритмом Closed-Form Policy Improvement (CFPI), который был представлен в статье "Offline Reinforcement Learning with Closed-Form Policy Improvement Operators".
1. Алгоритм Closed-Form Policy Improvement (CFPI)
Выражение в закрытой форме — это математическая функция, выраженная с помощью конечного числа стандартных операций. Оно может содержать константы, переменные, стандартные операции и функции, но обычно не содержит пределы, дифференциальные или интегрирования выражения. Таким образом, рассматриваемый нами метод CFPI вводит некоторые аналитические зерна в алгоритм обучения политики Агента.
Большинство существующих моделей для обучения с подкреплением в офлайн режиме используют стохастический градиентный спуск (SGD) для оптимизации своих стратегий, что может привести к нестабильности в процессе обучения и требует тщательной настройки скорости обучения. Кроме того, производительность стратегий, обученных в офлайн режиме, может зависеть от конкретной точки оценки. А это часто приводит к существенным вариациям в конечной стадии обучения. Такая нестабильность представляет существенную сложность в офлайн обучении с подкреплением, поскольку ограниченный доступ к взаимодействию с окружающей средой делает сложным процесс настройки гиперпараметров. В дополнение к вариациям в различных точках оценки использование SGD для улучшения стратегии может привести к значительным вариациям в производительности при разных случайных начальных условиях.
В своей работе авторы метода CFPI стремятся уменьшить упомянутую нестабильность обучения в офлайн RL. Они разрабатывают стабильные операторы улучшения стратегии. В частности, они отмечают, что необходимость ограничения распределительного сдвига мотивирует использование аппроксимации Тейлора первого порядка, приводящей к линейной аппроксимации целевой функции политики Агента, которая точна в достаточно маленькой окрестности действия стратегии поведения. Основываясь на этом ключевом наблюдении, авторы метода строят операторы улучшения стратегии, возвращающие решения в замкнутой форме.
Моделируя стратегии поведения как единичное гауссовское распределение, предложенный авторами CFPI оператор улучшения стратегии детерминировано сдвигает политику поведения в направлении улучшения значения. В результате, предложенный метод Closed-Form Policy Improvement избегает нестабильности обучения при улучшении стратегии, поскольку используется лишь обучение основных стратегий поведения заданного набора данных.
Авторы метода CFPI также отмечают, что практические наборы данных часто собираются гетерогенными стратегиями. Это может привести к многомодальному распределению действий Агента. И в этом случае единичное гауссовское распределение не сможет захватить многие моды базового распределения, ограничивая потенциал улучшения стратегии. Моделирование политики поведения в виде смеси гауссовских распределений обеспечивает лучшую выразительность, но влечет за собой дополнительные сложности оптимизации. Авторы метода решают эту проблему, используя нижнюю границу LogSumExp и неравенство Йенсена, что также приводит к оператору улучшения стратегии в замкнутой форме, применимому к многомодальным стратегиям поведения.
Авторами выделяются следующие вклады метода Closed-Form Policy Improvement:
- Операторы CFPI, совместимые с одномодовыми и многомодовыми стратегиями поведения и способные улучшать стратегии, изученные другими алгоритмами.
- Эмпирические доказательства преимуществ моделирования стратегии поведения как смеси гауссовских распределений.
- Одношаговые и итеративные варианты предложенного алгоритма превосходят существующие ранее алгоритмы на стандартном бенчмарке.
Авторы CFPI создают аналитический оператор улучшения стратегии без обучения с целью избежания нестабильности в офлайн сценариях. Они отмечают, что оптимизация по отношению к целевой функции порождает стратегию, допускающую ограниченное отклонение от стратегии поведения в офлайн выборке. Следовательно, она будет запрашивать Q-значение только в окрестности действия поведения во время обучения. Это естественным образом мотивирует использование линейной аппроксимации первого порядка.
При этом оценка действий в обновленной политике предоставляет точное линейное приближение изученной функции ценности только в достаточно малой окрестности от распределения обучающей выборки. Поэтому выбор пары "Состояние-Действие" из обучающей выборки имеет решающее значение на конечный результат обучения.
Для решения поставленной задачи авторы предлагают решить следующую приближенную задачу для любого состояния S:
![]()
Следует отметить, что D(•,•) не обязательно должна быть математически определенной функцией расхождения. Любая общая D(•,•), которая может ограничивать отклонение действия политики поведения Агента от распределения обучающей выборки, может быть рассмотрена.
В общем случае приведенная выше задача не всегда имеет решение в замкнутой форме. Авторы метода CFPI анализируют специальный случай:
- Для сбора обучающей выборки используется гауссовская стратегия.
- Обучается детерминированная политика поведения Агента.
- D(•,•) — отрицательная функция правдоподобия.
В таком сценарии разумным выбором для обучения политики является концентрация вокруг распределения обучающей выборки. Тогда предложенную задачу оптимизации можно представить в виде выражения закрытой формы:
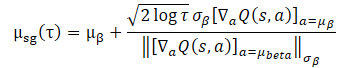
Использование данного выражения закрытой формы для улучшения политики Агента приносит выгодную вычислительную эффективность и избегает потенциальной нестабильности, вызванной SGD. Однако его применимость зависит от предположения о единственном гауссиане для стратегии сбора обучающей выборки. На практике исторические наборы данных обычно собираются разнородными стратегиями с различными уровнями экспертизы. Одномерный гауссиан может не учесть всю картину распределения, поэтому представляется разумным использовать смесь гауссианов для представления политики сбора данных.
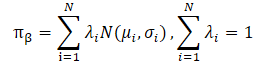
Однако прямая подстановка смеси гауссианов политик сбора обучающих данных нарушает применимость выше представленной задачи, так как приводит к не выпуклой целевой функции. Здесь мы сталкиваемся с двумя основными проблемами при решении задачи оптимизации.
Во-первых, неясно, как выбрать подходящее действие из обучающей выборки. При этом нужно обеспечить, чтобы решение целевой политики находилось в небольшой окрестности выбранного действия.
Во-вторых, использование смеси гауссиан не допускает выпуклой формы, что представляет сложность в оптимизации.
Применение LogSumExp позволяет преобразовать задачу оптимизации.
![]()
Что можно представить в виде выражения закрытой формы.
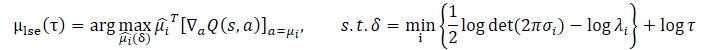
Использование неравенства Йенсена позволяет получить следующую задачу оптимизации:
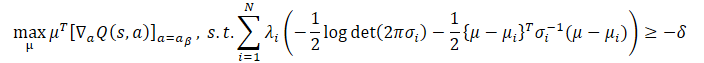
Закрытая форма решения для данной задачи имеет вид:
![]()
В сравнении с исходной задачей оптимизации, оба предложенных дополнения накладывают более строгие ограничения доверительного интервала. Это достигается за счет обеспечения нижней границы логарифмических вероятностей смеси гауссианов выше определенного порогового значения. Одновременно параметр τ контролирует размер доверительного интервала.
Обе задачи оптимизации имеют свои плюсы и минусы. Когда распределение обучающей выборки проявляет очевидную многомодальность, нижняя граница логарифма политики сбора данных, построенная с использованием неравенства Йенсена, не может улавливать различные моды из-за ее вогнутости, теряя преимущество моделирования политики сбора данных в виде смеси гауссианов. В этом случае задача оптимизации LogSumExp может служить разумной заменой исходной задачи оптимизации, поскольку нижняя граница LogSumExp сохраняет многомодальность логарифма политики сбора данных.
Когда же распределение обучающей выборки сводится к единственной гауссиане, аппроксимация с использованием неравенства Йенсена становится равенством. Таким образом, µjensen точно решает поставленную задачу оптимизации. Однако в этом случае степень точности нижней границы LogSumExp в значительной степени зависит от весов λi=1...N.
К счастью, мы можем объединить лучшие качества обоих подходов и получить оператор CFPI, учитывающий все вышеупомянутые сценарии, который возвращает политику поведения, выбирающую более высоко оцененное действие из µlse и µjensen:
![]()
В авторской статье Вы можете найти детальные выкладки и доказательства применимости всех представленных выражений.
Авторы метода CFPI отмечают, что предложенный метод также применим к негауссовким распределениям обучающей выборки. При этом представленные операторы CFPI позволяют создать общий шаблон офлайн обучения с возможностью получения одношаговых, многошаговых и итеративных методов.
Для оценки действий используется предварительно обученная модель Критика. Обучение которого может осуществляться на обучающей выборке любым известным способом. Что, по существу, является первым этапом алгоритма обучения модели.
Далее сэмплируется некоторый пакет Состояний из обучающей выборки. Для данного пакета генерируются Действия с учетом текущей политики Агента. После чего осуществляется оценка полученных действий с учетом выше предложенных операторов CFPI.
По результатам данной оценки выбираются оптимальные состояния, на которых и осуществляется обновление политики Агента.
При построении многошаговых и итеративных методов процессе повторяется.
Хотя разработка операторов CFPI вдохновлена парадигмой ограничения политики Агента по поведению, предложенные подходы совместимы с общими базовыми методами обучения с подкреплением. В авторской статье демонстрируются примеры, когда операторы CFPI повышали эффективность стратегий, выученных c использование других алгоритмов.
2. Реализация средствами MQL5
Выше представлено теоретическое описание метода Closed-Form Policy Improvement. Согласен, что представленные математические формулы могут показаться довольно сложными. Но попробуем разобраться с ними более детально в процессе реализации предложенных подходов.
Сразу следует обратить внимание, что в предложенном авторами статьи алгоритме обучения моделей предусмотрено последовательное обучение Критика и Актера. При этом сначала обучается модель Критика. И лишь затем мы приступаем к обучению политики Актера.
При таком подходе становится не актуальным наш прием, когда Критик использует модель Актера для предварительной обработки исходных данных. Ведь на стадии обучения Критика модель Актера ещё не сформирована. Конечно, мы могли бы сгенерировать модель Актера и использовать её, как и ранее. Но в таком случае мы встречаемся со следующей проблемой — на стадии обучения политики мы алгоритмом CFPI не предусмотрено обновление модели Критика. А изменение параметров Актера в обязательном порядке приведет и к изменению параметров предварительной обработки исходных данных. И в таком случае изменяется распределение на входе Критика. Что в целом ведет к искажению оценки действий Актера.
Для исправления описанной ситуации мы можем отказаться от использования общего Энкодера исходного состояния или вынести его в отдельную модель.
Мы не можем перенести Энкодер в модель Критика, так как для прямого прохода Критика нужны действия, сгенерированные Актером. А для прямого прохода Актера нужны результаты Энкодера. Круг замкнулся.
2.1 Архитектура моделей
В своей реализации я решил вынести Энкодер состояния окружающей среды в отдельную модель, что и отразилось в архитектуре моделей. Описание архитектуры моделей дано в методе CreateDescriptions. Несмотря на последовательное обучение моделей Актера и Критика я не стал разделять описание архитектуры моделей на 2 метода. Поэтому в параметрах метод получает указатели на 3 динамических массива объектов для записи архитектуры моделей.
В теле метода мы проверяем актуальность полученных указателей на объекты и, при необходимости, создаем новые экземпляры объектов массивов.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Первым идет описание архитектуры Энкодера текущего состояния. Архитектура модели начинается со слоя исходных данных, размер которого должен быть достаточен для записи информации о ценовом движении и показателей индикаторов на всю глубину анализируемой истории.
//--- State Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полученные "сырые" данные проходят первичную обработку в слое пакетной нормализации.
Далее идет сверточный блок, который позволяет снизить размерность данных с параллельным выявлением в них устойчивых паттернов.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Результаты сверточного блока обрабатываются 2 полносвызными нейронными слоями.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Обработанные таким образом данные дополняются информацией о состоянии счета, которые включают в себя и гармоники временной метки.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; }
На выходе Энкодера мы создаем стохастичность. Это позволяет нам как снизить возможность переобучения модели, так и повысит стабильность работы нашей модели в стохастической внешней среде.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Следующим идет описание архитектуры Актера. На вход он получает результаты работы описанного выше энкодера окружающей среды.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Как можно заметить, в энкодере проведена вся подготовительная работа по подготовке исходных данных. Это позволяет сделать модель Актера максимально простой. Здесь мы создаем 3 полносвязных слоя.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
А на выходе модели формируем стохастическую политику в непрерывном пространстве действий.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Модель Критика также использует результаты работы Энкодер в качестве исходных данных. Но в отличии от модели Актера, дополняет их вектором оцениваемых Действий. Поэтому после слоя исходных данных мы используем слой конкатенации, который объединяет 2 тензора исходных данных.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
Далее идет блок принятия решения из полносвязных нейронных слоев.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
На этом мы завершаем описание архитектуры моделей и переходим к построению алгоритмом обучения моделей.
Конечно, перед началом обучения моделей нам предстоит собрать обучающую выборку. И на этот раз я не могу сказать, что советники взаимодействия с окружающей средой были перенесены из предыдущих работ без изменений. Изменение архитектуры моделей в части выделения энкодера окружающей среды во внешнюю модель отложило отпечаток и алгоритмы данных советников. Но данные изменения настолько точечные, что я предлагаю Вам самостоятельно ознакомиться с ними в файлах "...\Experts\CFPI\Research.mq5" и "...\Experts\CFPI\Test.mq5". Указанные программы Вы можете найти во вложении. А мы переходим к построению алгоритма обучения Критика.
2.2 Обучение Критика
Алгоритм обучения модели Критика реализован в советнике "...\Experts\CFPI\StudyCritic.mq5". Надо сказать, что в данном советнике осуществляется параллельное обучение 2 моделей Критиков. Как Вы знаете, использование 2 Критиков позволяет повысить стабильность и эффективность последующего обучения политики поведения Актера. И вместе с моделями Критиков мы будем обучать общий Энкодер состояния окружающей среды.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 1e6; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ STrajectory Buffer[]; CNet StateEncoder; CNet Critic1; CNet Critic2;
В методе инициализации советника мы сначала пробуем загрузить обучающую выборку.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
А затем загружаем необходимые модели. При невозможности загрузить предварительно обученные модели, мы генерируем новые, заполненные случайными параметрами.
//--- load models float temp; if(!StateEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); if(!CreateDescriptions(actor, critic, encoder)) { delete actor; delete critic; delete encoder; return INIT_FAILED; } if(!Critic1.Create(critic) || !Critic2.Create(critic) || !StateEncoder.Create(encoder)) { delete actor; delete critic; delete encoder; return INIT_FAILED; } delete actor; delete critic; delete encoder; //--- }
Переносим все модели в единый контекст OpenCL, что позволяет обмениваться данными между моделями без излишней передачи информации в память основной программы и обратно.
//---
OpenCL = Critic1.GetOpenCL();
Critic2.SetOpenCL(OpenCL);
StateEncoder.SetOpenCL(OpenCL);
Для исключения возможных ошибок передачи данных между моделями мы проверяем их соответствие единому макету используемых данных.
//--- StateEncoder.getResults(Result); if(Result.Total() != LatentCount) { PrintFormat("The scope of the State Encoder does not match the latent size count (%d <> %d)", LatentCount, Result.Total()); return INIT_FAILED; } //--- StateEncoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Critic1.GetLayerOutput(0, Result); if(Result.Total() != LatentCount) { PrintFormat("Input size of Critic1 doesn't match State Encoder output (%d <> %d)", Result.Total(), LatentCount); return INIT_FAILED; } //--- Critic2.GetLayerOutput(0, Result); if(Result.Total() != LatentCount) { PrintFormat("Input size of Critic2 doesn't match State Encoder output (%d <> %d)", Result.Total(), LatentCount); return INIT_FAILED; }
После успешного прохождения всех контролей мы инициализируем вспомогательный буфер данных.
//--- Gradient.BufferInit(AccountDescr, 0);
И инициализируем пользовательское событие начала процесса обучения моделей.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
После чего завершаем работу метода инициализации советника.
В методе деинициализации советника мы сохраняем обученные модели и осуществляем очистку памяти.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { StateEncoder.Save(FileName + "Enc.nnw", 0, 0, 0, TimeCurrent(), true); Critic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
Непосредственно процесс обучения моделей осуществляется в методе Train. В теле метода мы сначала рассчитаем взвешенные вероятности выбора траекторий из буфера воспроизведения опыта.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Затем объявим локальные переменные и организуем цикл обучения с числом итераций, которое было указанно пользователем во внешних параметрах советника.
vector<float> rewards, rewards1, rewards2, target_reward; uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) {
В теле цикла обучения мы сэмплируем траекторию и состояние на ней.
int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3)); if(i < 0) { iter--; continue; }
После этого мы заполняем буферы исходных данных. Сначала заполним буфер описания состояния окружающей среды данными о ценовом движении и показателями анализируемых индикаторов и з буфера воспроизведения опыта.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
Затем заполним буфер описания состояния счета и открытых позиций.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Дополним буфер гармониками временной метки.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Собранных данных достаточно для прямого прохода Энкодера состояния окружающей среды.
//--- if(!StateEncoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Как уже было сказано выше, на данном этапе мы не используем модель Актера. Критики обучаются методами обучения с учителем на оценке фактических действий и вознаграждениях, полученных от окружающей среды, которые были предварительно сохранены в обучающей выборке. Следовательно, для прямого прохода обоих Критиков мы используем результаты работы Энкодера окружающей среды и вектор действий из обучающей выборки.
//--- Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Проверяем корректность выполнения операций и загружаем результаты прямого прохода обоих Критиков.
//---
Critic1.getResults(rewards1);
Critic2.getResults(rewards2);
Следующим этапом нам предстоит сформировать целевые значения для обучения моделей. Как уже было сказано выше, обучать мы будем фактическим значениям из обучающей выборки. На данном этапе мы используем вознаграждение за один переход в новое состояние. А для повышения сходимости мы скорректируем направление вектора градиента ошибки с помощью метода CAGrad.
Корректировать параметры моделей мы будем поочередно. Сначала скорректируем параметры первого Критика и следом вызываем метод обратного прохода Энкодера состояния окружающей среды.
rewards.Assign(Buffer[tr].States[i + 1].rewards); target_reward.Assign(Buffer[tr].States[i + 2].rewards); rewards = rewards - target_reward * DiscFactor; Result.AssignArray(CAGrad(rewards - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !StateEncoder.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Затем повторим операции для второго Критика.
Result.AssignArray(CAGrad(rewards - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !StateEncoder.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Обратите внимание, что после обновления каждого Критика корректируются параметры Энкодера. Тем самым мы пытаемся сделать эмбединг состояния окружающей среды максимально информативным и точным.
После успешного обновления параметров моделей нам остается проинформировать пользователя о ходе выполнения обучения и перейти к следующей итерации цикла.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
По завершении всех итераций нашего цикла обучения мы очищаем поле комментариев на графике. Выводим в журнал информацию о результатах обучения и инициируем завершение работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
С полным кодом программы Вы можете ознакомиться во вложении.
2.3 Обучение политики поведения
После обучения Критиков мы переходим к следующему этапу — обучение политики поведения Актера. Данный функционал мы реализуем в советнике "...\Experts\CFPI\Study.mq5". И первым делом мы добавляем во внешние параметры размер пакета, в котором будем выбирать оптимальную точку для обучения.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 10000; input int BatchSize = 256;
В данном советнике мы будем использовать 4 модели, но обучать будем только Актера.
CNet Actor; CNet Critic1; CNet Critic2; CNet StateEncoder;
В методе инициализации советника мы, как и ранее, сначала загружаем обучающую выборку.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
После чего загружаем модели. Сначала мы загружаем предварительно обученные модели Энкодера состояния окружающей среды и Критика. Отсутствие указанных моделей не позволяет нам осуществлять процесс обучения далее. И при возникновении ошибки загрузки моделей мы завершаем работу советника.
//--- load models float temp; if(!StateEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("Cann't load Critic models"); return INIT_FAILED; }
А вот при отсутствии предварительно обученного Актера, мы инициализируем новую модель, заполненную случайными параметрами.
if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Переносим все модели в один контекст OpenCL и отключаем режим обучения Энкодера и Критиков.
OpenCL = Actor.GetOpenCL(); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); StateEncoder.SetOpenCL(OpenCL); //--- StateEncoder.TrainMode(false); Critic1.TrainMode(false); Critic2.TrainMode(false);
После этого мы проверяем соответствие архитектуры моделей и их совместимость.
//--- Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
StateEncoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
StateEncoder.getResults(Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic1 doesn't match output State Encoder (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Critic2.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic2 doesn't match output State Encoder (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Actor.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Actor doesn't match output State Encoder (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Успешное прохождение блока проверок позволяет нам двигаться дальше. Мы инициализируем вспомогательный буфер и генерируем пользовательское событие начала процесса обучения.
Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
На этом мы завершаем операции метода инициализации советника. А в методе деинициализации мы, как обычно, сохраним обученную модель и очистим память.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; delete OpenCL; }
Сам же процесс обучения модели Актера реализован в методе Train. В теле метода мы сначала определим вероятности выбора траекторий из обучающей выборки.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
После чего мы создадим необходимые локальные переменные.
//--- vector<float> rewards, rewards1, rewards2, target_reward; vector<float> action, action_beta; float Improve = 0; int bar = (HistoryBars - 1) * BarDescr; uint ticks = GetTickCount();
И создадим цикл обучения модели с числом итераций, заданным во внешних параметрах советника.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) {
В теле цикла для обучения политики поведения Актера мы будем использовать подходы метода CFPI. Сначала нам предстоит сэмплировать пакет данных из обучающей выборки. Сгенерировать и оценить действия текущей политики Актера в выбранных состояниях. Для выполнения этих операций мы создадим вложенный цикл с числом итераций равным размеру анализируемого пакета. Результаты операций сохраним в локальную матрицу mBatch.
matrix<float> mBatch = matrix<float>::Zeros(BatchSize, 4); for(int b = 0; b < BatchSize; b++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { b--; continue; }
Операции семплирования аналогичны проводимым нами ранее.
Данными каждого выбранного состояния мы заполняем буферы описания состояния окружающей среды.
//--- State
State.AssignArray(Buffer[tr].States[i].state);
И буфер описания состояния счета.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Добавим гармоники временной метки.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
И осуществим метод прямого прохода Энкодера состояния.
//--- State embedding if(!StateEncoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
После формирования эмбединга состояния окружающей среды мы генерируем действия Агента с учетом текущей политики.
//--- Action if(!Actor.feedForward(GetPointer(StateEncoder), -1, NULL, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Сгенерированные действия оцениваются обоими Критиками.
//--- Cost if(!Critic1.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
После успешного прохождения всех операций мы выгружаем результаты в локальные векторы. И тут же формируем аналогичные векторы данных из обучающей выборки.
Critic1.getResults(rewards1); Critic2.getResults(rewards2); Actor.getResults(action); action_beta.Assign(Buffer[tr].States[i].action); rewards.Assign(Buffer[tr].States[i + 1].rewards); target_reward.Assign(Buffer[tr].States[i + 2].rewards);
В нашу матрицу результатов мы сохраняем координаты проанализированного состояния в виде индексов траектории и состояния в ней. А также сохраним отклонение вектора действий и его влияние на результат.
//--- Collect mBatch[b, 0] = float(tr); mBatch[b, 1] = float(i); mBatch[b, 2] = MathMin(rewards1.Sum(), rewards2.Sum()) - (rewards - target_reward * DiscFactor).Sum(); mBatch[b, 3] = MathSqrt(MathPow(action - action_beta, 2).Sum()); }
Затем переходим к семплированию и оценки следующего состояния.
После обработки и сбора данных всего пакета нам предстоит выбрать оптимальное состояние для оптимизации политики поведения Актера. На этом этапе нам предстоит выбрать состояние с достоверной оценкой Критика и максимальным влиянием на результат работы модели.
Касательно достоверности оценки действий мы уже говорили, что оценка действий Критика более точная при минимальных отклонениях от распределения обучающей выборки. При росте же отклонения снижается и точность оценки Критиков. Следуя этой логике, критерием точности оценки действий может служить расстояние между действиями, которое мы сохранили в колонке с индексом 3 нашей аналитической матрицы.
Теперь нам предстоит выбрать доверительный интервал. В своей работе авторы метода CFPI использовали дисперсию распределения. Мы же не можем взять дисперсию для вектора отклонений действий. Дело в том, что дисперсия считается как среднеквадратическое отклонение от средины распределения. В нашем же случае мы сохранили абсолютные значения отклонений. Таким образом, нулевое отклонение, в котором наиболее точная оценка Критика, может быть только экстремумом. Среднее же значение распределения далеко от данной точки. Следовательно, использование дисперсии в данном случае не гарантирует нам желаемую точность оценок действий.
Но здесь мы можем воспользоваться правило "3 сигм" — в нормальном распределении 68% данных не отклоняется от математического ожидания более чем на 1 среднеквадратическое отклонение. А значит для определения доверительного диапазона мы можем воспользоваться квантильной функцией. Путем несложных математических операций мы создаем вектор weights с нулевыми значениями для действий с отклонениями более доверительного интервала и "1" для остальных.
action = mBatch.Col(3); float quant = action.Quantile(0.68); vector<float> weights = action - quant - FLT_EPSILON; weights.Clip(weights.Min(), 0); weights = weights / weights; weights.ReplaceNan(0);
Определившись с доверительным интервалом, мы можем выбрать массив состояний с адекватной оценкой действий. И теперь нам предстоит выбрать состояние наиболее оптимальное для оптимизации политики поведения Актера. С целью упрощения всего алгоритма и ускорения процесса обучения модели я отказался от использования аналитических методов, предложенных авторами CFPI, и использовал более простой.
Думаю очевидно, что в нашем случае наиболее оптимальным направлением оптимизации является то, при котором максимально изменяется доходность политики поведения Агента при минимальном сдвиге в подпространстве действий. Ведь мы стремимся максимизировать доходность нашей политики, а минимальные отклонения позволяют говорить о более точной оценке действий Критиком. Разумеется, что в нашей аналитической матрице есть как положительные, так и отрицательные отклонения в оценке действий. При этом на повышении общей доходности одинаково влияют как повышение прибыли, так и снижение убытков. Поэтому для вычисления критерия выбора оптимального мы используем абсолютное значение отклонения вознаграждения за переход.
rewards = mBatch.Col(2); weights = MathAbs(rewards) * weights / action;
В полученном векторе мы выбираем элемент с максимальным значение. Его индекс укажет нам на оптимальное состояние для использования в алгоритме оптимизации модели.
ulong pos = weights.ArgMax(); int sign = (rewards[pos] >= 0 ? 1 : -1);
Тут же мы в локальную переменную сохраним знак отклонения вознаграждения.
Забегая немного вперед, надо сказать, что обновлять политику поведения Актера мы будем с использование градиентов ошибки, пропущенных через модель Критика. В таком режиме обучения мы не можем посчитать ошибку прогнозов Актера. И для контролирования процесса обучения я ввел показатель коэффициента среднего улучшения используемых состояний.
Improve = (Improve * iter + weights[pos]) / (iter + 1);
Далее следует уже привычный алгоритм оптимизации модели политики. Только на этот раз мы используем не случайное состояние, а в котором мы можем максимально повысить производительность модели.
int tr = int(mBatch[pos, 0]); int i = int(mBatch[pos, 1]);
Как и ранее мы заполняем буферы описания состояния окружающей среды и состояния счета.
//--- Policy study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Добавляем гармоники временной метки.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Генерируем эмбединг состояния окружающей среды.
//--- State if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!StateEncoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Действие Агента с учетом текущей политики.
//--- Action if(!Actor.feedForward(GetPointer(StateEncoder), -1, NULL, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
И оцениваем стоимость действий Агента.
//--- Cost if(!Critic1.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Для оптимизации политики поведения Агента мы используем Критика с минимальной оценкой. А для повышения сходимости корректируем вектор направления градиента с помощью метода CAGrad.
Critic1.getResults(rewards1); Critic2.getResults(rewards2); //--- rewards.Assign(Buffer[tr].States[i + 1].rewards); target_reward.Assign(Buffer[tr].States[i + 2].rewards); rewards = rewards - target_reward * DiscFactor; CNet *critic = NULL; if(rewards1.Sum() <= rewards2.Sum()) { Result.AssignArray(CAGrad((rewards1 - rewards)*sign) + rewards1); critic = GetPointer(Critic1); } else { Result.AssignArray(CAGrad((rewards2 - rewards)*sign) + rewards2); critic = GetPointer(Critic2); }
Мы последовательно осуществляем обратный проход Критика и Актера.
if(!critic.backProp(Result, GetPointer(Actor), -1) || !Actor.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Здесь я хочу напомнить, что на данном этапе мы не оптимизируем модель Критика. Поэтому нет необходимости в обратном проходе Энкодера состояний окружающей среды.
На этом мы завершаем операции одной итерации обновления политики поведения Агента. Информируем пользователя о ходе процесса обучения и переходим к следующей итерации нашего цикла.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> %15.8f\n", "Mean Improvement", iter * 100.0 / (double)(Iterations), Improve); Comment(str); ticks = GetTickCount(); } }
После завершении всех итераций цикла обучения мы очищаем поле комментариев на графике, выводим в журнал информацию о результатах обучения и инициируем завершение работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Mean Improvement", Improve); ExpertRemove(); //--- }
Здесь мы завершаем рассмотрение алгоритмов используемых в статье программ. С их полным кодом Вы можете самостоятельно ознакомиться во вложении. А мы переходим к проверке результатов проделанной работы.
3. Тестирование
Выше мы познакомились с методом Closed-Form Policy Improvement и провели довольно большую работу по реализации его подходов средствами MQL5. Я хочу напомнить, что мы воспользовались предложенными идеями. Но аналитический метод выбора оптимального состояния применили отличный от предложенных в статье. Кроме того, в своей работе мы использовали наработки из своего предыдущего опыта. Поэтому полученные результаты могут в значительной мере отличаться от приведенных авторами метода в своей работе. Ну и конечно, наша тестовая среда отличается от указанных в авторской статье экспериментов.
Как всегда, обучение и тестирование моделей осуществлялось на исторических данных инструмента EURUSD тайм-фрейм H1. Для обучения моделей мы используем данные за первые 7 месяцев 2023 года. Тестирование обученных моделей осуществляется на исторических данных августа 2023 года. Параметры всех анализируемых индикаторов используются по умолчанию.
Реализация метода CFPI потребовала некоторых изменений в архитектуре моделей, но не затронула структуру исходных данных. Поэтому на первом этапе обучения мы можем воспользоваться обучающей выборкой, созданной ранее при тестировании одного из рассмотренных ранее алгоритмов обучения. В своей работе я воспользовался обучающей выборкой из предыдущей статьи. Для этого я создал копию файла с именем "CFPI.bd". Но Вы можете и создать полностью новую обучающую выборку одним из рассмотренных ранее способом. В данной части метод CFPI не накладывает ограничений.
А вот изменения в архитектуре не позволили нам воспользоваться обученными ранее моделями. Поэтому весь процесс обучения проходил, так сказать, "с нуля".
Вначале мы обучали модели Энкодера состояний и Критиков с помощью советника "...\Experts\CFPI\StudyCritic.mq5".
Используемая нами обучающая выборка насчитывала 500 траекторий по 3591 состояние в каждой. Что в целом дает нам около 1.8 млн. комплектов "Состояние-Действие-Вознаграждение". Первичное обучение моделей Критиков было осуществлено на 1 млн. итераций, что теоретически позволяет проанализировать практически каждое второе состояние. Согласитесь, для непрерывных траекторий, когда не каждое новое состояние окружающей среды вносит кардинальные изменения в рыночную ситуацию, это довольно не плохой результат. А с учетом акцента на траектории с максимальной доходностью это позволит Критикам практически полностью изучить такие траектории и расширить "кругозор" на менее доходные проходы.
Следующим этапом мы обучаем политику поведения Актера в советнике "...\Experts\CFPI\Study.mq5". На шаге мы осуществляем 10 тыс. итераций обучения с пакетом из 256 состояний. В целом это позволяет проанализировать более 2,5 млн состояний, что уже превышает нашу обучающую выборку.
Должен сказать, что уже после первой итерации обучений в тестовых прохода можно заметить некоторые предпосылки к созданию прибыльных стратегий. На графиках баланса можно выделить прибыльные участи. В процессе дополнительного сбора обучающих траекторий из 200 проходов 3 завершились с прибылью. Конечно, это может быть как моим субъективным мнением, так и результатом стечение неких факторов, независящих от метода. К примеру, нам повезло, и случайная инициализация моделей дала не плохой результат. Но можно точно сказать, что в результате последующих итераций обучения моделей и сбора дополнительных проходов наблюдается явная тенденция к росту средней доходности и профит-фактора проходов.
После нескольких итераций обучения модели была получена политика поведения Актера, способная генерировать прибыль как на исторических данных обучающей выборки, так и на последующих тестовых данных, не входящих в обучающую выборку. Результаты тестирования модели представлены ниже.


На графике баланса можно заметить некоторую просадку вначале периода тестирования. Но далее модель демонстрирует довольно ровную тенденцию к росту баланса. Что позволяет как вернуть потерянное, так и увеличить прибыль. В целом за период тестирования моделью совершено 125 сделок, 45.6% из которых было закрыто с прибылью. Здесь следует отметить, что максимальная прибыльная и средняя прибыльная сделка на 50% превышают аналогичный убыточный показатель. И это позволяет нам получить профит фактор на уровне 1.23.
Заключение
В данной статье мы познакомились с ещё одним алгоритмом обучения моделей Closed-Form Policy Improvement. Наверное, основным вкладом данного метода является добавление аналитических подходов для выбора направления оптимизации обучаемой модели. Да, этот процесс требует дополнительных вычислительных затрат. Но, как ни странно, данный подход сокращает затраты на обучение модели в целом. Дело в том, что мы не пытаемся повторить полностью лучшую из представленных траекторий. Вместо этого мы концентрируем усиления в местах максимальной эффективности и не тратим время поиск оптимальности в шумовых явлениях.
В практической части нашей работы мы реализовали предложенные авторами метода CFPI идеи, хота и с отступлением от авторских математических выкладок. Тем не менее мы получили положительный опыт и неплохой результат тестирования проделанной работы.
Мое личное мнение, что метод Closed-Form Policy Improvement заслуживает внимания. И мы можем использовать его подходы для построения своих торговых стратегий.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Актера |
| 4 | StudyCritic.mq5 | Советник | Советник обучения Критиков |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования