
Do básico ao intermediário: Classes (I)

Introdução
No artigo anterior Do básico ao intermediário: Filas, Listas e Árvores (V), começamos a ver como seria a implementação de um mecanismo de árvore. Porém, toda via e, entretanto, existe uma questão da qual precisamos falar antes de podermos continuar a trabalhar com aquele assunto. Até este exato momento, tenho procrastinado em falar sobre este assunto. No entanto, não estou tendo outra escolha. Já que sem dar alguma explicação a respeito de como a programação orientada em objetos funciona, fica difícil continuar explicado a respeito de como implementar os mecanismos que precisaremos criar. No entanto, apesar deste aparente desconforto que tem sido dado nos últimos artigos, devido ao fato de eu já estar utilizando algo que se refere a programação orientada em objetos, sem de fato ter explicado tais pontos. O conteúdo visto anteriormente não necessitava de muitos detalhes, a respeito deste tipo de programação, para que você o pudesse entender.
Porém, o mesmo não acontece com o conteúdo que será mostrado nos próximos artigos. Mesmo por que, se você entendeu de forma adequada o artigo anterior. Deve ter notado que temos o tempo todo o disparo de alguns alertas por parte do MetaTrader 5, a respeito de objetos ou memória não liberada. E apesar de aqueles avisos serem um tanto quanto chatos. Já que temos que corrigir o nosso código para que eles parem de surgir. A correção, ou melhor dizendo, o que precisa ser implementado no código, envolve justamente entender como a programação orientada em objetos trabalha. Por isto, vamos dar uma breve pausa, naquele assunto, para que possamos explicar, pelo menos o básico a respeito de programação orientada em objetos.
Então sem mais delongas, já que procrastinei bastante até este momento. Vamos dar uma pausa nas coisas que possam nos distrair e focar no que será o tema principal a ser tratado aqui.
Classes (I)
Como o próprio título deste tópico, já indica, aqui iremos começar a falar sobre classes. Ou mais comumente conhecida, a tal falada: Programação orientada em objetos. Detalhe, o que iremos ver aqui neste primeiro momento, é apenas o básico necessário para que você possa acompanhar os próximos artigos. Não iremos neste momento, nos aprofundar muito com relação a todas as questões a que se refere as classes. Mesmo por que, algumas já foram tratadas quando expliquei sobre programação estrutural. Veja os artigos anteriores para mais detalhes a este respeito.
Porém, apesar disto, existem algumas coisas que se fazem necessárias de serem devidamente explicadas, para você consiga compreender algumas das características, ou capacidades presentes nas classes. Isto a fim de conseguir entender por que os códigos que serão vistos depois, funcionam e como podemos tirar proveito do que eles podem fazer. Mas o ponto principal mesmo, é que você precisa conseguir entender os códigos, com o mínimo de explicações dadas por mim. Já que conforme o tempo for passando, começarei a dar cada vez menos explicações a respeito de certos detalhes presentes nos códigos.
Assim sendo, vamos a primeira das questões. Para começar, a base necessária para entender as classes, começa entendendo um outro conceito explicado em alguns dos artigos anteriores. Sendo o principal conceito, o da estrutura.
No artigo Do básico ao intermediário: Struct (I), começamos a falar sobre estruturas de dados. Que seria uma forma de organizar as informações, a fim de as condensar dentro do que poderia ser definido, como sendo um tipo de variável de usuário, criada pelo programador. Apesar deste não ser o único artigo no qual foi falado e explicado como estruturas poderiam ser utilizadas. Este seria de fato, o primeiro artigo dentro desta série, voltada exclusivamente para explicar as estruturas. Isto a fim de que você começasse a compreender o que seria uma programação estrutural.
Apesar de não parecer, entender este conceito, do que seria uma programação estrutural, antes mesmo de começar a entender a programação orientada em objetos. Torna muito mais simples e fácil, compreender as classes. Isto por conta que o próprio desenvolvimento das classes, surgiu depois que a programação estrutural, já havia sido bastante explorada. Dando assim demonstrações do que precisaria ser melhorado. Fazendo assim, com que a programação orientada em objetos, surgisse naturalmente. Então se você não tem, o conceito de estrutura muito bem definido e assimilado em sua mente. Sugiro que você volte nos artigos anteriores e estude aquele material. Já que aqui vamos apenas dar um passo adiante. Sem de fato retornar as coisas que já foram explicadas.
Ok, durante alguns artigos, em que falamos sobre estruturas, demonstrei que podíamos criar códigos estruturados. E expliquei, por que tais códigos recebem esta denominação. Porém se você procurou estudar com calma e tentou criar algumas coisas, usando para isto, um código estrutural. Deve ter notado que temos um pequeno inconveniente neste tipo de modelo de programação. Apesar de ele ser muito mais adequado para se produzir código bem mais complexos e de maneira muito mais simples, do que seria feito, usando uma programação legada. Onde a ideia de estrutura de dados simplesmente não existe. Então o tal inconveniente, do qual menciono, e que você deve ter notado, se deve justamente, a maneira utilizada, como forma de efetuar a inicialização das variáveis, isto dentro da própria estrutura.
Mas espere um pouco. Não entendi o que você está querendo dizer. Como assim temos um problema para inicializar as variáveis da estrutura? Não existe problema com isto, tudo que precisamos fazer é declarar um procedimento e chamar o mesmo em algum momento no nosso código. Isto antes mesmo de vir a utilizar as variáveis da estrutura. Não vejo problema em se fazer isto. De fato, à primeira vista, isto não é de fato problema, meu caro leitor. Visto que podemos fazer o que você acabou de mencionar, demonstrando de fato que você procurou estudar e compreender o material visto nos artigos anteriores.
Porém, existem situações em que esta abordagem, de chamar algum procedimento a fim de inicializar as variáveis da estrutura, pode não ser realmente efetuada. Embora tais situações, na maior parte das vezes, se mostrar raras de ocorrem, elas podem realmente surgirem, dificultando assim o processo de programação. E existem muitas outras, que simplesmente nos esquecemos de inicializar as variáveis da estrutura. O que se diga por passagem, ser algo muito mais comum do que a primeira situação mencionada. E isto, pelo simples fato de que não efetuamos a chamada correta, cujo objetivo seria justamente, o de tornar esta inicialização possível. E é neste tipo de situação que a estrutura começa a se tornar bem menos adequada de ser utilizada. Pedindo assim, algum tipo de melhoria.
Para lhe ajudar a entender esta segunda situação, que como mencionei, é algo bastante comum, e isto de maneira prática e simples. Vamos utilizar um código igualmente muito simples. Este pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct stDemo 05. { 06. private: 07. int value; 08. //+----------------+ 09. void Message_0(void) 10. { 11. Print(__FUNCTION__); 12. } 13. //+----------------+ 14. void Message_1(void) 15. { 16. Print(__FUNCTION__); 17. } 18. //+----------------+ 19. public : 20. //+----------------+ 21. void Init(void) 22. { 23. value = 1; 24. } 25. //+----------------+ 26. void Check(void) 27. { 28. switch (value) 29. { 30. case 1: 31. Message_0(); 32. break; 33. case 2: 34. Message_1(); 35. break; 36. default: 37. Print("Unknown [ ", value, " ]..."); 38. }; 39. } 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. stDemo demo; 46. 47. demo.Init(); 48. demo.Check(); 49. } 50. //+------------------------------------------------------------------+
Código 01
Este código 01, que acredito não vir a precisar ser explicado como funciona. Já que ele utiliza coisas que foram explicadas em detalhes em outros artigos. É capaz de ilustrar perfeitamente bem, o tipo de problema que podemos ter, devido ao fato de não inicializarmos as variáveis dentro de uma estrutura.
Quando este código 01 é compilado como ele se apresenta acima. O resultado gerado no terminal do MetaTrader 5, será o que podemos ver logo abaixo.
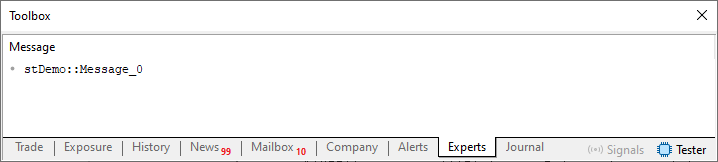
Imagem 01
No entanto, se apenas uma única coisa for feita. Como pode ser visto logo abaixo, teremos um resultado diferente.
. . . 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. stDemo demo; 46. 47. // demo.Init(); 48. demo.Check(); 49. } 50. //+------------------------------------------------------------------+
Fragmento 01
Observe que neste Fragmento 01, apenas comentamos, o que seria o equivalente, a não termos implementado a linha 47 no código 01. Dando assim um outro tipo de comportamento ao código compilado. Pode perfeitamente demonstrar, o tipo de problema gerado por esquecimento de inicialização, feita durante a fase de codificação de código perfeitamente estrutural. Assim depois de compilar, novamente o código 01. Iremos ver o resultado é o que é mostrado logo na sequência.
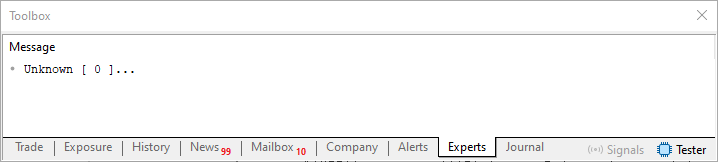
Imagem 02
Agora preste atenção a um seguinte fato, meu caro leitor. Quando na linha 45, declaramos a estrutura, o compilador irá de maneira automática, alocar memória suficiente para os dados presentes dentro da estrutura. E ao fazer isto, o compilador irá, por padrão, inicializar esta região alocada com valores iguais a zero. Apesar de você imaginar que isto sempre acontece, na verdade não é bem assim. No caso a região será inicializada, devido ao fato de estarmos utilizando o MQL5. Porém, dependendo da linguagem adotada, pode ser que venhamos a ter lixo na região da memória, que iremos utilizar.
Por exemplo, no caso de um código em C legado, o compilador apenas diz para o sistema operacional, quanto de memória deverá ser reservada para os dados. Porém, não existe nenhum tipo de limpeza sendo feita naquela região. Este tipo de coisa, faz com que possamos ver coisas estranhas e muitas vezes bem interessantes. Fato é que isto era muito usado como uma forma de burlar a segurança do sistema operacional. Mas isto já é uma outra história.
No entanto, quando a programação orientada em objetos começou a ser tornar realidade. Tais problemas como o que é visto acima, começaram a deixar de existir. Na verdade eles ainda podem ocorrer, porém é bem mais difícil de acontecerem. Isto por que, passamos a contar com um mecanismo que antes não existia. E que agora nos permitiria inicializar as variáveis de uma estrutura, no momento em que esta estrutura fosse declarada. Mais ou menos, como seria feito pelo compilador. Muito bem, agora começamos a chegar na parte que realmente nos interessa. Que é justamente o surgimento das classes.
Muita gente, principalmente iniciantes, imaginam que classes, nada tem a ver com estruturas. Que estudar estruturas é pura perda de tempo e que deveríamos partir direto para o estudo de classes e não perder tempo tentando entender como as estruturas funcionam. Mas posso afirmar que isto é um grande equívoco, por parte destas pessoas. Já que uma classe é uma estrutura, só que uma estrutura especial. E entender como estruturas funcionam, e como programar códigos estruturados, irá com certeza, lhe ajudar muito no entendimento sobre com classes trabalham. Por isto, abordei o tema estruturas a um certo tempo, dando assim a oportunidade de você se inteirar e compreender como elas funcionam. Pois as classes, apenas irão incrementar o que já foi visto no que rege o assunto estruturas.
Porém vale, neste momento abrir um parêntese aqui. Diferente do que acontece com códigos C++, aqui no MQL5, muitas das coisas que podemos fazer com as classes em C++, NÃO SÃO POSSIVEIS. Acredito que o motivo, seja simplificar a vida de novos programadores. Já que existem coisas que podemos fazer em C++, que são muito confusas de compreender. Ainda mais quando são levadas ao extremo, com uso de uma série de mecanismos a fim de modificar temporariamente como a classe funciona. Seja no âmbito do encapsulamento, seja no âmbito da herança. Mas enfim, isto é assunto para um outro momento e para um nível bem mais elevado de programação. Aqui iremos até o que considero ser um nível intermediário.
Assim sendo, se você desejar se aprofundar no assunto, aconselho fazer isto com muita calma. Já que no MQL5, usamos classes no seu nível mais simples possível, sem muitas complicações. Muito diferente do que você irá ver caso venha a se interessar em programar em C++, usando com base o conhecimento adquirido aqui nestes artigos relacionados ao MQL5.
Certo, então voltemos a nossa questão. Para tornar o código 01, fácil de ser trabalhado, e com menos risco de acontecer algo, como deixar de inicializar as variáveis da estrutura. Precisamos modificar algumas coisas nele. Tais mudanças são bem simples de serem entendidas e podem ser vistas logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. class stDemo 05. { 06. private: 07. int value; 08. //+----------------+ 09. void Message_0(void) 10. { 11. Print(__FUNCTION__); 12. } 13. //+----------------+ 14. void Message_1(void) 15. { 16. Print(__FUNCTION__); 17. } 18. //+----------------+ 19. public : 20. //+----------------+ 21. stDemo() 22. { 23. value = 1; 24. } 25. //+----------------+ 26. void Check(void) 27. { 28. switch (value) 29. { 30. case 1: 31. Message_0(); 32. break; 33. case 2: 34. Message_1(); 35. break; 36. default: 37. Print("Unknown [ ", value, " ]..."); 38. }; 39. } 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. stDemo demo; 46. 47. demo.Check(); 48. } 49. //+------------------------------------------------------------------+
Código 02
Este código 02, está propositalmente muito parecido com o código 01. No entanto, isto está sendo feito, justamente para que você entenda como a programação orientada em objetos, pode lhe ajudar a tornar mais simples criar um código estruturado, que agora deixará de receber este nome, e passará a ser chamado de código orientado em objetos. Mas para não tornar a coisa confusa, vou por hora, o chamar de código estruturado. Observe atentamente as mudanças que foram feitas.
Primeiro na linha quatro, onde trocamos a palavra reservada struct pela palavra reservada class. Neste momento, aquele mesmo código estruturado visto em código 01, passa a ser visto de uma forma um pouco diferente pelo compilador. Isto por que, toda classe, sem exceção, contém duas chamadas especiais, que podem ou não estarem sendo implementadas em seu código. Se não estiver sendo implementada de maneira explicita pelo seu código, o compilador irá criar estas chamadas de maneira implícita. Mas de qualquer forma ambas irão existir.
A primeira chamada é conhecida como constructor. Esta tem como objetivo, inicializar a própria classe. E a segunda chamada é conhecida como destructor. Esta tem como objetivo destruir qualquer coisa feita ou criada pela classe. Ou seja, o que uma faz a outra desfaz. Porém apesar da aparente simplicidade envolvida aqui. As coisas precisam ser muito bem entendidas, para que você possa realmente saber como lidar com estas duas chamadas.
Como nosso código 02 é algo relativamente simples. Temos aqui apenas o constructor sendo implementado de maneira explicita. Agora preste atenção, pois isto é importante. Existem diversos tipos de constructores possíveis. Porém apenas um único tipo de destructor é permitido, isto será visto depois. Este constructor, que você pode ver na linha 21, do código 02. Faz exatamente o que era feito na mesma linha 21 do código 01. Porém note a diferença na declaração. No caso do código 01, estávamos declarando um procedimento Init, que deveria ser chamado pelo nosso código. Isto a fim de inicializar a variável interna da estrutura. Você pode ver isto sendo feito na linha 47 do código 01. Tanto que quando tal procedimento não fosse executado, teríamos um resultado diferente do esperado.
Entretanto, quando este código 02 é compilado. Na linha 45, o compilador irá procurar um constructor adequado para ser utilizado pelo código. Isto porque estamos utilizando uma classe. Caso nenhum constructor adequado fosse encontrado, o compilador poderia se negar a gerar o executável. Porém como estamos apenas iniciando os estudos a respeito de classes. Sempre teremos um constructor adequado. Seja ele declarado explicitamente, como é o caso do código 02, ou esteja ele sendo declarado de maneira implícita, que veremos depois.
De qualquer forma, você precisa entender que esta linha 45 do código 02, está de fato dizendo ao compilador para executar o código presente na linha 21. E mais um detalhe a ser observado. O constructor deve obrigatoriamente ter o mesmo nome da classe em que ele está sendo declarado. Se o nome for diferente, não será visto pelo compilador como sendo um constructor, mas sim como uma função ou procedimento qualquer.
Ok, como a linha 45, está fazendo o papel de inicializar as variáveis da classe. Podemos ignorar aquela mesma chamada presente no código 01, que teria tal responsabilidade e partir direto para o código de checagem. Com isto, o resultado da execução do código 02 é o mesmo que podemos ver na imagem 01.
Muito legal, não é mesmo meu caro leitor? Com uma simples mudança no código, acabamos de tornar as coisas muito mais confiáveis e fáceis de serem feitas. No entanto, estamos apenas começando. Então não perca o foco. Ok, mas e se não tivéssemos implementado o constructor, como é visto neste código 02. O que aconteceria? Bem, neste caso teríamos um código levemente diferente sendo gerado pelo compilador. Para tornar isto um tanto quanto mais fácil de entender. Vejamos o código 03. Que é basicamente este mesmo código 02, porém com uma pequena diferença.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. class stDemo 05. { 06. private: 07. int value; 08. //+----------------+ 09. void Message_0(void) 10. { 11. Print(__FUNCTION__); 12. } 13. //+----------------+ 14. void Message_1(void) 15. { 16. Print(__FUNCTION__); 17. } 18. //+----------------+ 19. public : 20. //+----------------+ 21. void Check(void) 22. { 23. switch (value) 24. { 25. case 1: 26. Message_0(); 27. break; 28. case 2: 29. Message_1(); 30. break; 31. default: 32. Print("Unknown [ ", value, " ]..."); 33. }; 34. } 35. //+----------------+ 36. }; 37. //+------------------------------------------------------------------+ 38. void OnStart(void) 39. { 40. stDemo demo; 41. 42. demo.Check(); 43. } 44. //+------------------------------------------------------------------+
Código 03
Observe que neste código 03, JÁ NÃO TEMOS MAIS o constructor sendo implementado de maneira explicita. Porém, isto não quer dizer que ele não exista. Pelo contrário. Ele continua existindo, no entanto, agora ele será criado pelo compilador de forma implícita. E por conta disto, teremos na execução deste código 03, a mesma saída vista na imagem 02.
Cara, isto parece um tanto quanto confuso. Mas acho que estou conseguindo entender, a lógica por debaixo desta coisa de classe. Me corrija se eu estiver errado. Quando declaramos uma estrutura de dados, conseguimos uma forma de representar algum tipo de registro particular. Sendo que no momento em que for necessário utilizar esta estrutura de registro, precisaremos em muitos dos casos inicializar os valores a fim de evitar problemas. E fazemos isto por meio de algum procedimento ou função. Certo? Correto meu caro leitor. Ok, esta parte então consegui entender. Porém devido a possibilidade de que venhamos a nos esquecer de declarar esta inicialização no nosso código. Pegamos e transformamos aquela mesma função ou procedimento usado para inicializar as variáveis em um constructor. Assim evitamos problemas de nos esquecermos de inicializar as variáveis da estrutura de registro. Estou certo?
Neste caso, mais ou menos. Isto porque, se para inicializar os dados você precisava utilizar uma função, não poderá utilizar um constructor para este mesmo proposito. Isto porque um constructor, assim como o destructor que iremos ver depois, NÃO RETORNA NENHUM VALOR. Ele apenas é executado. Mas o conceito básico, aparentemente foi bem assimilado. Só faltando mencionar o detalhe de que, quando transformamos um procedimento de inicialização em um constructor. Estamos sim, dizendo ao compilador, que queremos tomar o controle, de como as coisas irão ser inicializadas. E não queremos que ele venha a fazer isto por nós. Mas quanto o restante, você está correto.
Hum, legal. De fato, acho que esta coisa de programação orientada em objetos, parece ser algo bem interessante. Por isto, diversos programadores gostam de fazer uso dela. Já que você passa a ter um controle maior e muito melhor sobre o que o código está de fato fazendo. Mas agora me veio uma dúvida na mente. No caso estamos utilizando o código 01, para conseguir entender como começar a trabalhar com programação orientada em objetos. Porém, neste código 01, não estamos permitindo ao programador definir um valor inicial para a variável. E é neste ponto que surge a tal dúvida. E se fosse possível, que na linha 47 do código 01, fosse passado um parâmetro para ser utilizado na inicialização. Como isto iria afetar o nosso código? Não na questão do código 01, mas sim na questão do código 02? Onde estamos usando a programação orientada em objetos.
Bem, meu caro leitor. Está de fato é uma dúvida muito boa. E como é algo bastante plausível de ocorrer. Vamos criar um código que melhor represente esta situação especifica, que você acabou de levantar. Assim será mais simples explicar outras coisas também. Vamos começar com o código visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct stDemo 05. { 06. private: 07. int value; 08. //+----------------+ 09. void Message_0(void) 10. { 11. Print(__FUNCTION__); 12. } 13. //+----------------+ 14. void Message_1(void) 15. { 16. Print(__FUNCTION__); 17. } 18. //+----------------+ 19. public : 20. //+----------------+ 21. void Init(int arg) 22. { 23. value = 1; 24. Check(__FUNCTION__); 25. value = arg; 26. } 27. //+----------------+ 28. void Check(string arg) 29. { 30. Print("Call coming from: ", arg); 31. switch (value) 32. { 33. case 1: 34. Message_0(); 35. break; 36. case 2: 37. Message_1(); 38. break; 39. default: 40. Print("Unknown [ ", value, " ]..."); 41. }; 42. } 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. void OnStart(void) 47. { 48. stDemo demo; 49. 50. demo.Init(2); 51. demo.Check(__FUNCTION__); 52. } 53. //+------------------------------------------------------------------+
Código 04
Assim como os demais códigos vistos até aqui, este código é muito básico, não sendo necessário que percamos tempo o explicando. Porém quando o executamos o resultado é visto logo abaixo.
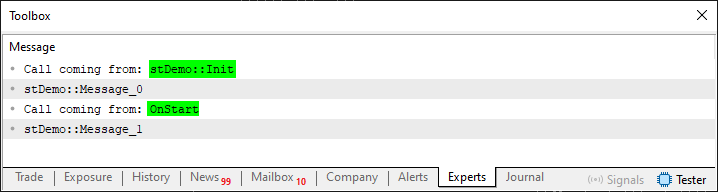
Imagem 03
Agora vamos entender uma coisa aqui, meu caro leitor. Observe que nesta imagem 03, estou destacando alguns pontos. Eles nos dizem de onde a chamada se originou. Isto porque na linha 30 estamos justamente imprimindo a string que está sendo repassada pelo chamado. Mas note uma coisa interessante aqui. Na linha 21 estamos querendo que o chamador, nos repasse um valor a fim de inicializar as variáveis, ou variável no caso, da própria estrutura. Como não estamos definindo um valor padrão, ou default, a ser utilizado, o chamador é obrigado a informar um valor. E isto é feito na linha 50 do código 04.
Agora vem a parte que muita gente fica confusa. Como transformar este mesmo código 04, em um código que faça uso da programação orientada em objetos? Bem, para fazer isto existem caminhos levemente diferentes. Porém o mais importante aqui é perceber que no código 04, estamos utilizando um procedimento de inicialização. E não uma função.
Entendido isto, podemos partir para a fase de transformar o código 04 em algo parecido com o que foi feito nos códigos anteriores. E isto é conseguido fazendo a escolha de duas maneiras levemente diferentes, de implementar as coisas. A primeira é mostrada logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct stDemo 05. { 06. private: 07. int value; 08. //+----------------+ 09. void Message_0(void) 10. { 11. Print(__FUNCTION__); 12. } 13. //+----------------+ 14. void Message_1(void) 15. { 16. Print(__FUNCTION__); 17. } 18. //+----------------+ 19. public : 20. //+----------------+ 21. stDemo(int arg) 22. { 23. value = 1; 24. Check(__FUNCTION__); 25. value = arg; 26. } 27. //+----------------+ 28. void Check(string arg) 29. { 30. Print("Call coming from: ", arg); 31. switch (value) 32. { 33. case 1: 34. Message_0(); 35. break; 36. case 2: 37. Message_1(); 38. break; 39. default: 40. Print("Unknown [ ", value, " ]..."); 41. }; 42. } 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. void OnStart(void) 47. { 48. stDemo demo(2); 49. 50. demo.Check(__FUNCTION__); 51. } 52. //+------------------------------------------------------------------+
Código 05
Agora preste muita atenção, pois as coisas começam a ficar um tanto quanto confusas, se você se distrair com alguma outra coisa. Observe que da mesma maneira que transformamos o código 01 no código 02. Aqui estamos fazendo o mesmo tipo de coisa. Onde transformamos o código 04 no código 05. Porém, toda via e, entretanto, quero chamar a sua atenção para a linha 48. Isto por que o que fazemos nesta linha 48, faz toda e total diferença no tipo de resposta que o nosso código irá nos fornecer.
Novamente, vamos pelo princípio mais simples. E se você não entendeu o que foi feito antes. Volte e procure entender sobre esta questão do constructor. Pois entender como um constructor funciona, faz toda a diferença aqui, para entender como este código 05 funciona.
Da forma como este código 05, se encontra implementado. O resultado é visto logo abaixo.
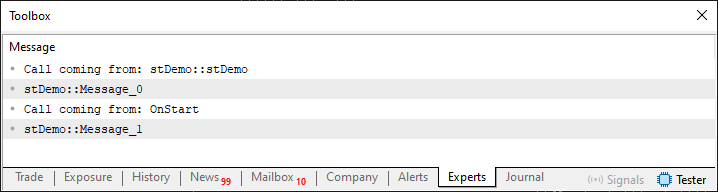
Imagem 04
Note que a diferença entre a imagem 03 e a imagem 04 é justamente a parte referente a origem da primeira chamada. Que pode ser vista na primeira linha de ambas as imagens. Demonstrando assim, que ambos códigos são compatíveis e funcionam da mesma maneira. Ou seja, não existe grandes problemas aqui, para interpretar como estes códigos trabalham.
Mas lembra que informei que existem duas formas de se fazer, este mesmo tipo de coisa no constructor? Pois bem, chegou a hora de observarmos a segunda forma. E como todo o restante do código permanecerá sem nenhuma mudança. Vamos fazer a mudança dentro de um fragmento. E este pode ser visto logo abaixo.
. . . 20. //+----------------+ 21. stDemo(int arg) 22. :value(1) 23. { 24. Check(__FUNCTION__); 25. value = arg; 26. } 27. //+----------------+ . . .
Fragmento 02
Este fragmento 02 irá substituir o que é visto no código 05. Nas mesmas linhas. No entanto, repare uma coisa um tanto quanto curiosa sendo feita aqui no fragmento 02. Aqui a variável está sendo inicializada, ANTES mesmo do código, de fato vir a ser executado. Porém, apesar de isto está sendo feito, o resultado é o mesmo visto na imagem 04.
Mas por que estaríamos declarando as coisas como é visto neste fragmento 02? Isto me parece muito mais confuso. Na verdade, meu caro leitor, isto que estamos vendo sendo feito no fragmento 02. É uma maneira de inicializarmos as coisas, antes mesmo de elas virem a ser utilizadas pelo nosso código, presente dentro da classe. Quando formos abordar um pouco mais afundo as próprias classes, iremos retornar a esta questão, vista neste fragmento 02, e você entenderá porque as vezes precisamos fazer as coisas assim. Por hora, apenas tente compreender que sim. Podemos declarar as coisas desta mesma maneira vista no fragmento 02. E o compilador irá conseguir entender o código sem nenhum problema.
Considerações finais
Neste artigo, começamos a ver o que seria as classes, e por que elas foram criadas. Porém, apesar deste artigo ser apenas um artigo de iniciação sobre o assunto. Você que vem estudando os artigos anteriores, já deve ter notado que podemos começar a fazer diversas coisas com as classes. Tendo assim algumas vantagens frente ao que seria o uso de simples estruturas no código. Isto apenas modificando ligeiramente um código originalmente feito para ser estrutural, para agora ser orientado em objetos.
Apesar de muita gente, costumar fazer um grande barulho, tornando assim a programação orientada em objetos como sendo algo aparentemente difícil e complexo. Você, neste artigo, deve ter notado que na prática não é bem assim. Muito pelo contrário, já que uma vez que o conceito de programação estrutural esteja bem definido em sua cabeça, entender o conceito de programação orientada em objetos se torna algo muito mais simples.
E com aqui, foi apenas uma introdução, não tendo sido mostrado pontos igualmente importantes, para voltarmos ao assunto sobre filas, listas e árvores. No próximo artigo, continuaremos a falar sobre classe. Mas como o foco voltado a implementação e uso dos destructores. Que aqui foram apenas mencionados. Mas serão vistos de fato no próximo artigo. Então nos vemos lá.
| Arquivo | Descrição |
|---|---|
| Code 01 | Arquivo de demonstração |
| Code 02 | Arquivo de demonstração |
| Code 03 | Arquivo de demonstração |
| Code 04 | Arquivo de demonstração |
| Code 05 | Arquivo de demonstração |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso