
Do básico ao intermediário: Template e Typename (I)

Introdução
O conteúdo exposto aqui, visa e tem como objetivo, pura e simplesmente a didática. De modo algum deve ser encarado como uma aplicação final, onde o objetivo não seja o estudo dos conceitos aqui mostrados.
No artigo anterior Do básico ao intermediário: Sobrecarga, falamos e tentei explicar uma das coisas mais complicadas de se entender em programação. Principalmente quando estamos iniciando, e nos deparamos com algo, que à primeira vista não faz nenhum sentido. Porém, apesar de toda aquela complicação, que surge quando utilizamos sobrecarga. É muito importante entender o que está acontecendo ali. Isto por que, sem de fato conseguir compreender e assimilar aquele tipo de conhecimento. Você, meu caro e estimado leitor, ficará muito limitado. E pior, não irá conseguir entender outras coisas que iremos fazer no decorrer dos próximos artigos.
Apesar de muitos considerarem a sobrecarga, um erro de programação, devido ao fato de tornar o código bastante complicado. Sem ela, muitas das coisas que fazemos, ou podemos fazer como programadores, não seria de fato possível de ser criado, ou mesmo implementado. Assim sendo, o pré-requisito para entender o que será explicado aqui, neste artigo. É justamente entender o que foi explicado no artigo anterior. Sem cumprir tal objetivo, ou requisito, o tema que será tratado aqui, se tornará uma pedra em seu sapato. Sendo praticamente impossível de ser compreendido adequadamente.
No entanto, sem os conceitos e conhecimento que começaremos a ver, neste artigo. É quase impossível conseguir avançar, em busca de novas oportunidades e mecanismos de programação. Então chegou a hora de relaxar, dar um tempo nas distrações e focar no que será visto neste artigo. Pois aqui iremos tratar de algo muito divertido, porém que pode ser muito complicado, dependendo do tipo de coisa que se esteja implementado em um dado momento.
Template e Typename
Um dos conceitos mais complicados, difíceis e que pode acabar desanimando muito programador iniciante. É a sobrecarga. Porém, a sobrecarga, como foi visto no artigo anterior, é apenas uma pequena amostra do que podemos de fato fazer, quando a linguagem que estamos utilizando, nos permite certas coisas. Ou nos dá um certo grau de liberdade. Como acontece ao começarmos a trabalhar com a sobrecarga de uma maneira mais profunda.
A primeira coisa que você precisa de fato entender, é que a sobrecarga, quando feita da forma que foi vista no artigo anterior. Demonstra claramente quais tipos podemos utilizar e quando vamos utilizar estes mesmos tipos. Sendo mais simples trabalhar com valores de diferentes larguras de bits, em diferentes cenários. Já o que iremos ver aqui, é algo muito mais complicado. Que torna aquilo que foi visto no artigo anterior, algo puramente didático. Já que tudo que foi visto lá, se aplica aqui, mas em uma escala de grandeza muito maior.
Alguns de vocês podem estar pensando: Preciso mesmo, aprender a mexer com este tipo de coisa que você está nos mostrando? Sim, sem tais ferramentas, muitas das coisas que podem ser feitas, ficam completamente fora de alcance. A não ser que você utilize métodos muito mais complicados e de implementação ainda mais difíceis de dominar. Mas então, será que não daria para adiar esta parte? Deixando isto para ser explicado em outro momento? Tipo, depois que já tiver explicado sobre como programar indicadores ou um Expert Advisor? Na verdade, andei pensando sobre isto. Já que tudo que foi feito e mostrado até este ponto. De fato, é algo que todo e qualquer iniciante deveria saber. Isto antes mesmo de tentar programar algo.
Porém, todavia e, entretanto, não vejo motivos para adiar a apresentação deste tema proposto. Mesmo por que, já falei como implementar um Expert Advisor totalmente do zero. Tanto para fins de programação automática, quanto para fins de auxiliar operações manuais.
Você pode ver isto em Aprendendo a construindo um Expert Advisor que opera de forma automática (Parte 15) - Automação (VII), onde em uma pequena serie de quinze artigos, mostro em detalhes como fazer isto. No entanto, mesmo depois de tais artigos terem sido publicados, tenho notado que muitos tem dúvidas básicas sobre certos temas. Enquanto outro, de fato não querem depender de uma programação, já pronta. Querem de fato aprender como tudo funciona. Criando assim suas próprias soluções, que venham a atender aquilo que eles necessitam naquele momento.
Mesmo depois de concluído a sequência sobre Desenvolvendo um sistema de Replay? Simulação de mercado (Parte 01): Primeiros experimentos (I), notei que muitos não faziam ideia de que tal coisa era possível de ser implementada. Se bem que esta sequência de artigos ainda não foi totalmente postada. Mas em breve terá sido postada. E como muitos podem querer melhorar, ou entender parte daquele código. Que apesar de ter sido explicado em detalhes, não me aprofundei em alguns pontos. E é justamente nestes pontos que pode morar aquele objetivo que, este ou aquele iniciante deseja trabalhar.
Como não vou mais mexer nestes temas, visto que acredito que tais temas ficaram muito bem explorados. Comecei a mostrar, a pedido de alguns, como trabalhar com redes neurais usando MQL5. E novamente, acabei percebendo que alguns, não conseguiam de fato acompanhar grande parte do que estava sendo implementado. Novamente, notei que a falta de conhecimento adequado e de conceitos básicos de programação, acabava por tornar, qualquer explicação que estivesse sendo dada. Algo muito complicado e difícil de acompanhar por parte dos iniciantes. Mesmo por que muitos não imaginavam ser possível implementar uma rede neural usando MQL5 puro.
Para quem não viu, nenhum destes meus artigos sobre redes neurais. O primeiro foi Rede neural na prática: Reta Secante. É bem verdade, que ainda faltam muitos dos artigos já prontos para serem publicados. Mas, de fato, conforme os artigos forem saindo, você que vier a acompanhar eles, notará que conhecimento básico de programação é muito mais importante do que possa parecer.
Apesar de em algum momento, eu ter explicado conceitos mais avançados naquela série de artigos. Ainda assim, tive o desejo de implementar uma sequência de artigos voltados para a base da programação. Então daí a ideia de começar a explicar as coisas do básico.
Agora acredito ter explicado o motivo pelo qual, apesar do que está sendo mostrado aqui, ser algo que muitos consideram desnecessário, para um programador iniciante. Ter de fato uma base bem montada e bem sólida, lhe ajuda a entender diversos outros código. Mesmo que seu objetivo venha a ser outro. Como por exemplo, apenas saber como implementar um Expert Advisor básico, ou aquele indicador que pode lhe ajudar a operar melhor. Mas se objetivo for apenas este, talvez seja melhor pagar a um programador profissional para fazer isto para você. Já que o tempo necessário e as dores de cabeça, serão muito menores.
Mas voltando a nossa questão principal, o grande problema no que será explicado aqui, é entender que tudo se baseia no que foi visto no artigo anterior. E mais do que isto. Sem entender, tudo que foi explicado antes de chegarmos aqui. Nada irá fazer sentido.
Então vamos começar por algo que seja o mais simples possível. E quando digo simples, estou dizendo que precisa realmente ser bastante simples. Pois o conceito, apesar de ser fácil de entender, tem diversas coisas difíceis de serem de fato assimiladas. Dada a quantidade de conhecimento requerido para isto. Assim, veja o código logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25.)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(ulong arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(double arg1, double arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2; 20. } 21. //+------------------------------------------------------------------+
Código 01
Este código é EXATAMENTE o mesmo código que abriu o artigo anterior. Exatamente. Mas por que? O motivo é que ele é perfeito para começarmos a entender o que seria template e o que seria typename. De certa maneira o correto seria mostrar um ou outro termo. Isto para facilitar o que será explicado. Porém, aqui, e neste momento, um termo estará intimamente ligado ao outro. E é isto que pode acabar tornando tudo muito confuso para você que esteja iniciando.
No entanto, para simplificar inicialmente qualquer coisa que venhamos a falar. Não iremos entrar em detalhes do que cada termo significa na prática. Quero que você, meu caro leitor, apenas olhe, e procure compreender o que estará sendo feito. Não tente de fato entender, por que funciona e como você pode utilizar isto em mais casos. Se você tentar fazer isto, irá ficar completamente perdido. Assim, peço que você tenha calma e paciência. Pois iremos explicar as coisas ao longo do tempo. Já que é isto que será feito, é algo que envolve muito mais do que o que iremos ver aqui, neste simples artigo.
Agora quero que você preste atenção ao seguinte fato: A ÚNICA DIFERENÇA entre a função da linha dez e da linha dezesseis, é apenas e somente o tipo de dado esperado e de retorno. Nada e absolutamente nada além disto é diferente neste código mostrado acima.
Observar e entender isto, é algo EXTREMAMENTE IMPORTANTE. É muito mais importante entender isto, do que entender qualquer outra coisa. Sem de fato conseguir enxergar, o que acabei de dizer, todo o resto não fará nenhum sentido. Ok, então este código 01, de fato funciona e o compilador consegue compreender o que precisa ser criado. Acredito, que isto tenha ficado claro, já que foi explicado no artigo anterior. Agora vem uma pergunta: Será que precisamos de fato escrever este código 01, da forma como ele se encontra? Ou melhor dizendo: Será que não existe uma forma mais adequada, e simples de escrever este mesmo código?
E se você entendeu o que foi explicado no artigo anterior. Sabe que se precisamos utilizar tipos diferentes, dos que estão sendo declarados. Teremos de criar funções ou procedimentos extras. E ao fazer isto duplicar o código, correndo o risco de ficar com um código muito mais complicado de ser melhorado. Já que funções e procedimentos sobrecarregados, mais hora ou menos hora, acabam nos trazendo alguma dificuldade. Digo isto por experiência de anos programado. Acredite, a sobrecarga sempre nos traz problemas no logo prazo.
Bem, pensando por este lado, algumas linguagens nos permitem criar algo que seria como se fosse um template. Ou seja, algo que precisa ser modificado em apenas alguns pontos, não precisando ter seu código duplicado. Isto em tese. Já que o uso de tal ferramenta não se dá como muitos imaginam. Mas vamos ficar no básico em primeiro lugar. Ok, então tirando o fato de que os tipos utilizados nas funções das linhas dez e dezesseis, são diferentes. Todo o resto pode ser transformado em um template. Este é o primeiro ponto que você precisa entender.
Bem, apesar de tudo, este código 01, tem um pequeno agravante. Que é justamente a linha sete. Mas para não complicar esta explicação inicial. Vamos considerar que a linha seis estará utilizando tipos inteiros e que a linha sete estará utilizando dados do tipo ponto flutuante. Estou impondo esta condição neste momento. Mas depois iremos ver que existe formas de mudar isto. Porém uma coisa de cada vez.
Agora que estamos acertados, podemos ver como este mesmo código 01, seria escrito sobre uma forma de implementação usando um template de função. Isto pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10.0, 25.0)); 08. } 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. T Sum(T arg1, T arg2) 12. { 13. Print(__FUNCTION__, "::", __LINE__); 14. return arg1 + arg2; 15. } 16. //+------------------------------------------------------------------+
Código 02
Agora vem a parte estranha. Quando você executar o código 01, irá ter como resultado o que é visto na imagem abaixo.
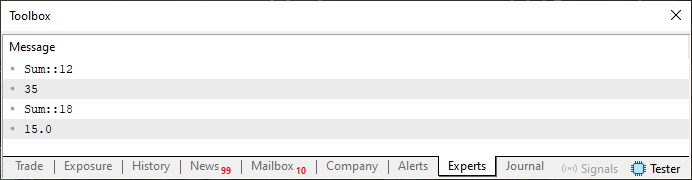
Imagem 01
Porém quando executar o código 02, você irá ter o que é visto na imagem logo na sequência.
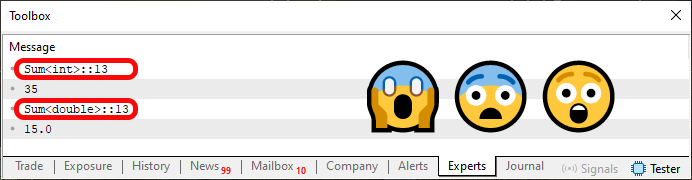
Imagem 02
Pergunta: O que aconteceu aqui? Resposta: Transformamos aquelas duas funções vista no código 01 em um template que agora é visto no código 02. Mas a questão que realmente faz toda a diferença, é entender o que são estas informações que estão sendo destacadas na imagem 02. E é aqui onde a coisa fica complicada, se você não entendeu o que seria uma sobrecarga de funções ou procedimentos. Isto por que, no artigo anterior expliquei como o compilador poderia fazer para que uma função ou procedimento pudesse ser sobrecarregado. Aqui estamos dizendo de maneira implícita, ao compilador, como ele deverá criar esta sobrecarga para nós.
Digo implícita, pois de fato, NÃO ESTAMOS DIZENDO qual tipo usar. Quem decidirá isto será o compilador. Por isto, que no código 01, utilizávamos o tipo ulong no que seria a chamada da linha seis. Já que esta estaria utilizando a função da linha dez, e esta tem como tipo esperado, valores do tipo ulong. No entanto, quando deixamos o compilador decidir isto, ele achou melhor utilizar o tipo int, e não um outro tipo qualquer. Esta decisão nem sempre traz os melhores resultados. Em alguns casos ela acaba por tornar os resultados de funções ou procedimentos, algo diferente do esperado.
Mas vamos com calma. Estamos apenas iniciando nesta nova área. Temos muitas coisas para serem vistas antes de entramos neste campo de valores diferentes do esperado.
Agora o que preciso que você entenda, é o seguinte meu caro leitor. Apesar de que, nesta imagem 02, temos a nítida sensação de que temos apenas um único procedimento, ou função no caso, esteja sendo implementada. Isto por que, em todos os dois casos, estamos nos referindo a mesma linha. No caso a linha 13, presente no código 02. Esta função Sum, presente no código 02, NÃO É UMA FUNÇÃO. Mas sim um template de função.
E o que isto significa na prática? Significa que no momento em que o compilador encontrar esta função sendo utilizada no nosso código. Ele, compilador, irá procurar se já existe uma que atenta a nossa necessidade naquele momento. Caso não exista, o compilador irá criar uma que atenda a esta necessidade. Usando para isto a função template que está sendo declarada entre as linhas 10 e 15. Tudo, absolutamente tudo que existir entre estas linhas será duplicado de alguma forma. Mas ao mesmo tempo será ajustado de forma que venha a ser adequadamente utilizada. Conforme era esperado que fosse criado o código.
Atualmente está muito na moda, dizer que uma inteligência artificial consegue criar um código. Isto que está sendo feito aqui, seria algo muito similar. Mas sem utilizar nenhuma rede neural, ou algo do tipo.
Para tentar deixar isto mais claro, vamos fazer uma pequena mudança no código 02. De forma a usar a função Sum com outros tipos de dados. Isto é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(130, 150)); 07. Print(Sum(130.0, 150.0)); 08. { 09. long v1 = 130, v2 = 150; 10. 11. Print(Sum(v1, v2)); 12. } 13. { 14. uchar v1 = 130, v2 = 150; 15. 16. Print(Sum(v1, v2)); 17. } 18. { 19. float v1 = 130, v2 = 150; 20. 21. Print(Sum(v1, v2)); 22. } 23. } 24. //+------------------------------------------------------------------+ 25. template <typename T> T Sum(T arg1, T arg2) 26. { 27. Print(__FUNCTION__, "::", __LINE__); 28. return arg1 + arg2; 29. } 30. //+------------------------------------------------------------------+
Código 03
Observe que podemos utilizar tanto a forma de escrever o template como mostrado no código 02, como este que podemos ver no código 03. Neste caso do código 03, estamos fazendo tudo em uma única linha, o que não é muito comum de ser visto, em códigos reais. Já que grande parte dos programadores não utilizam esta forma que está sendo escrita na linha 25 do código 03. Mas o significado é o mesmo que pode ser observado no código 02. Apenas algo menos comum.
Ok, mas não é este o ponto, aqui. O ponto, é que quando executado, este código 03 irá produzir o que é visto logo abaixo.
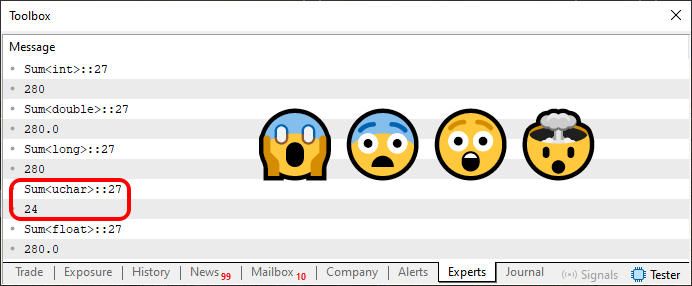
Imagem 03
Agora sim complicou de vez. Definitivamente, não estou conseguindo entender mais nada. Que coisa mais maluca e sem sentido. Estou vendo, mas não estou acreditando. Todos os valores são iguais, menos um. E isto me parece algo absurdo. Poderia me ajudar a entender isto melhor? E por que motivo uma das somas voltou um valor tão diferente dos demais?
Sim, meu caro leitor. Eu não disse que seria algo divertido este tipo de coisa? Apesar de ser algo muito complicado de ser entendido, assim de uma hora para outra? Pois bem, vamos então entender o que está acontecendo aqui.
Lembra que falei que o compilador, procura qual o melhor tipo que deverá ser utilizado, para cada caso? Assim conseguindo criar as funções sobrecarregadas de modo a conseguir adequar o código ao que necessitamos naquele momento? Pois bem, observe o seguinte: Quando a linha seis é executada, o melhor tipo, no caso seria o tipo int. Por isto, uma função sobrecarregada seria criada utilizando exatamente este tipo. Logo depois, temos um tipo de dado que entra como sendo um ponto flutuante. Neste caso, o compilador entende que o melhor tipo seria o tipo double. Por isto a este tipo é utilizado. Em todos estes casos, o compilador está utilizando a forma implícita de declaração. Se baseando no melhor modelo de dado, que ele foi implementado para utilizar como tipo padrão.
Agora vem a parte interessante. Quando entramos nos blocos entre as linhas 08 e 12, linhas 13 e 17 e o bloco da linha 18 e 22, estamos utilizando variáveis locais, de tipos distintos. Se você não sabe do que estou falando, procure ver os primeiros artigos desta série. Lá explico, exatamente o que seria uma variável local. E o tempo de vida que cada variável terá durante a execução do seu código. Note que o conhecimento vai se acumulando. Por isto, não é bom deixar as coisas se acumularem antes de começar a estudar sobre o assunto e praticar o que está sendo mostrado.
Pois bem. Em cada bloco destes, temos valores que mudam em termos de largura de bits. Tendo por consequência um range possível. Assim, tanto o resultado da operação, quanto o tipo de dado que deverá ser utilizado pela função, depende do tipo de variável que estamos utilizando.
Desta forma, cada uma das linhas que você pode observar na imagem 03, indicando que tipo de dados está sendo utilizado. Nos diz qual o range possível que os valores poderão estar contidos. Sei que isto não faz muito sentido agora. Porém, já falamos sobre isto, quando expliquei a questão sobre variáveis e constantes. Volte e reveja estes artigos. Pois agora aquele conhecimento será importante para nós.
O tipo uchar, tem um range que vai de 0 a 255. Como a soma dos valores é igual a 280. O valor 24, que estamos vendo, sendo destacado ali na imagem 03. Corresponde exatamente a este estouro que aconteceu. Como temos 256 elementos ao todo, possíveis de serem representados dentro de um tipo uchar. Ao ultrapassar este valor de 256 elementos, temos 24 elementos de estouro. Ou seja, a contagem, se reiniciou no zero, e foi até o elemento 24. Por isto, o resultado da soma é este valor.
Note que isto somente foi possível, pelo fato de estarmos dizendo explicitamente ao compilador, que o tipo de dado a ser utilizado, deveria ser o uchar. Se fosse utilizado um outro tipo, o valor poderia ser totalmente diferente.
Como estes códigos estarão no anexo. Tente mudar este tipo de dados de uchar para char, e veja o resultado que irá lhe ser apresentado. Lembrando que neste caso, o compilador irá reclamar. Emitindo um alerta. Isto por que, os valores 130 e 150 estão fora do limite do que seria o range de valores char. Mas você pode reduzir estes valores para valores melhores, dentro do range. Quem sabe, fazer a soma de 90 com 80. Adicionando assim o tipo de dado char aos blocos de construção? Garanto que você vai achar o resultado bastante interessante.
Entendendo o que está acontecendo aqui
Como você pode ter notado, o uso de um template de função ou procedimento, nos economiza o trabalho de ter de criar diversas funções ou procedimentos, sobrecarregados. Jogando a responsabilidade e trabalho de fazer isto, para o compilador. Assim, podemos focar em construir um código, que seja o mais legível quando for possível de ser feito. Porém, sem entender o que está de fato acontecendo aqui. Fica um pouco complicado de entender, como expandir este recurso tão valioso, que é o template. Então meu caro leitor, vamos esquecer todo o resto, e procurar focar única e exclusivamente, no fato de tentar compreender o que está ocorrendo com este template que estamos criando nestes códigos visto aqui. Basicamente vamos focar no código 03. Pois será mais simples de entender, pelo fato de nele termos mais tipos de dados sendo utilizados.
Para começar, vamos dar uma nova olhada na imagem 03. Ali você pode observar claramente, que o nome da função está sendo seguido por um símbolo de menor, logo depois o nome de um tipo, para depois um símbolo de maior. A parte que nos interessa é justamente esta identificação do tipo que está sendo mostrado na imagem 03.
Se você olhar o código 03, irá notar que na linha 25, NÃO EXISTE nenhuma identificação de tipo sendo feito. Porém temos algo curioso ali. Que é a palavra reservada typename, seguido de um identificador. A parte curiosa, é que o identificador que estamos vendo na imagem 03, se parece muito justamente com esta região onde typename aparece no código 03. E é aqui que está o segredo, por assim dizer.
O identificador que segue a palavra reservada typename, cria uma forma de permitir ao compilador definir o tipo de dado que será utilizado pelo template. Observe que este mesmo identificador, substitui a declaração padrão que faríamos, ao identificar qual seria o tipo de dados a esperado. Normalmente, programadores utilizam este identificador T, mas podemos usar qualquer nome que desejarmos. Desde que ele seja corretamente definido. Este identificador, será substituído pelo compilador, pelo tipo adequado, no momento em que o executável estiver sendo criado.
Isto de fato, permite que tenhamos muita liberdade no uso deste tipo de recurso. Já que existem maneiras de o utilizar, para conseguir lidar com certos tipos de problemas bem complicados, de uma maneira muito simples e pouco custosa. Mas isto será visto no próximo artigo. Já que por hora, não quero confundir você, meu caro leitor com uma avalanche de informações. Só queria chamar a sua atenção para o fato de que esta declaração que podemos ver na linha 25 do código 03, pode ser modificada. Isto com o objetivo de tornar as coisas mais claras para você.
Por exemplo, podemos modificar a linha 25 do código 03, para a linha mostrada logo abaixo. E mesmo assim, o compilador continuaria a entender como lidar com um template.
template <typename Unknown> Unknown Sum(Unknown arg1, Unknown arg2)
Considerações finais
Aqui neste artigo, começamos a lidar com um dos conceitos, que muitos iniciantes evitam lidar. Isto por conta de que, templates, não é um assunto que podemos dizer, ser simples de entender e utilizar. Já que muitos não compreendem o princípio básico que se encontra por baixo do que seria um template. Que é justamente a sobrecarga de funções e procedimentos. Apesar de neste momento, ter sido explicado apenas, a primeira parte de uma serie enorme de possibilidades que podemos utilizar com o uso de templates. Entender esta primeira parte, é primordial. Isto por que, muito do que será visto e explicado nos próximos artigos, deriva justamente desta parte básica e inicial que foi demonstrado aqui.
Acredito que aquele com menos experiência, ou que estejam começando a estudar programação. Possam estar um tanto quanto confusos a respeito, tanto da utilidade de templates, quanto também na forma de explorar adequadamente este tipo de recurso presente no MQL5. Porém quero lembrar a você, meu caro leitor, que este material, não precisa necessariamente ser assimilado rapidamente. Na verdade, apenas o tempo e a prática irão lhe ajudar a compreender melhor este tipo de conceito que estará sendo aplicado de agora em diante.
No entanto, isto não significa que você, deva deixar de estudar e praticar o que está sendo mostrado aqui. Estudar códigos como estes que estão sendo disponibilizados nos anexos. Apesar de no primeiro momento parecer perda de tempo, devido a simplicidade dos mesmos. Pode lhe poupar muitas horas depois, tentando entender códigos mais elaborados, que farão uso de todos estes recursos. Lembre-se:
O conhecimento vai se acumulando com o tempo. Ele não surge do nada, e não pode ser transferido por osmose entre indivíduos.
Então nos vemos no próximo artigo, onde iremos nos aprofundar ainda mais nesta questão do uso de templates, na sua forma mais básica e simples.
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 MetaTrader 5 no macOS
MetaTrader 5 no macOS
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso