
From Basic to Intermediate: Template and Typename (I)

Introduction
In the previous article "From Basic to Intermediate: Overload", we tried to explain one of the most difficult things in programming, especially at the initial stage and when face with something that does not make sense at first glance. Despite all the difficulties that arise when using overload, it is very important to understand what is happening. That is why, without this knowledge, you, dear reader, will be very limited. Even worse, you will not be able to understand other points, which we will discuss in the following articles.
Although many people consider overloading to be a programming error, as it makes the code quite complex, without it we could not create or implement many things. Therefore, in order to understand what will be described in this article, we must understand everything covered in the previous article well. Otherwise, today's topic will become a thorn in your side and it will be almost impossible to understand.
However, without the knowledge provided in this article, it is almost impossible to move forward in search of new programming features and mechanisms. So it is time to focus on what we are going to see in this article, because here we are going to be dealing with something very fun, albeit very complex, depending on the type of things that are being implemented at any given time.
Template and typename
One of the most complicated and difficult concepts that can eventually discourage a novice programmer is overload. However, as you can see from the previous article, overloading is only a small part of what we can implement when the language we use allows us certain things or gives us a certain degree of freedom, as it happens when we start working with overloading more deeply.
The first thing to understand is that overloading, when performed as it was presented in the previous article, clearly demonstrates which types we can use and when we will use them, facilitating work with values of various digit capacity in different scenarios. But here we will see something much more complex, which turns what we saw in the previous article into something exceptionally didactic, since everything described there is applicable here as well, but on a much larger scale.
Some of you may be wondering: do I really need to learn using such a tool? Yes, without such tools, much of what can be done will be completely inaccessible, unless you use much more complex and difficult to learn implementation methods. So would not it be better to postpone this part and leave it for another time to explain? For example, after programming indicators or Expert Advisors. In fact, I have been thinking about this since everything that has been done and shown so far is something any beginner should know before trying to program anything.
However, I see no reason to postpone this topic, if only because I have already told how to implement an Expert Advisor completely from scratch, both for automatic programming and for assistance in manual operations.
You can read about it in the article "Creating an EA that works automatically (Part 15): Automation (VII)”, which described in detail how to do this in a short series of fifteen articles. However, even after these articles were published, I noticed that many people have elementary doubts about some topics, while others do not want to rely on ready-made programs. They want to learn how it all works in order to create their own solutions that meet their needs.
Even after completing the series "Developing a Replay System — Market simulation (Part 01): First experiments (I)” I noticed that many people did not even imagine that it is possible to implement such a thing. Although this series of articles has not yet been fully published, it will happen soon. And since many people may want to improve or understand some part of this code, where (although it has been explained in detail) I have not delved into individual points, these points may be the goal of those who want to work with anything.
Since I do not intend to discuss these topics further (they are already very well studied), at the request of some people I started showing how to work with neural networks in MQL5. I noticed again that some were unable to accomplish much of what was implemented. Again, the lack of sufficient knowledge and basic programming concepts makes any explanation very complicated and difficult for beginners. Many people did not imagine that it was possible to implement a neural network in pure MQL5.
For those who have not read any of my articles on this topic, the first of them is "Neural Network in Practice: Secant Line". However, many articles are yet to be published. But as the articles get published, you will notice that basic programming knowledge is much more important than it might seem.
Although I have already explained more complex concepts in this series of articles, I still had the desire to implement a series of articles focused on the basics of programming. The idea was to start explaining everything from the very basics.
Now I have already explained why (although many people believe that this is not necessary for a novice programmer) availability of a well-structured and solid foundation helps you understand many other codes, even if your goal is something else, for example, to learn how to use a basic Expert Advisor or indicator that will help you trade better. If that is the only goal, then it is better to pay a professional programmer to do it for you, so you will save time and avoid headaches.
But, returning to our main question, again, it is very important to understand the following: everything is based on what was shown in the previous article. And, moreover, without understanding everything previous, nothing will make sense.
Let us start with something simple. And when I say "simple", I mean that it should be quite simple to understand, because despite the simplicity of understanding, this concept has several aspects that are difficult to master, given the amount of knowledge required for this. Take a look at the following code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25.)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(ulong arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(double arg1, double arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2; 20. } 21. //+------------------------------------------------------------------+
Code 01
This code is exactly the same as the one that started the previous article. But why? The reason is that this is an ideal option for familiarizing yourself with templates and to learn what a typename is. In a sense, it would be more correct to show either one or the other term to make it easier to explain. But at the moment, one thing will be closely related to the other. And this is exactly what can lead to the fact that those who are just starting to work will find themselves in complete confusion.
However, in order to simplify the topic initially, we will not enlarge upon practical meaning of each term. I want you to just watch and try to figure out what is going on. Do not try to understand how it works, or how it can be used in other cases. If you try to do this yourself, you will find yourself at a dead end. Therefore, please be patient, because over time we will explain everything, because what needs to be done involves much more than we will see in this simple article.
Now I want you to pay attention to the following: THE ONLY DIFFERENCE between the function in line 10 and the function in line 16 is the expected and returned data type. Nothing else has changed in the above code.
It is VERY IMPORTANT to notice and understand this, much more important than understanding everything else. If you do not see this, everything else will be meaningless. Code 01 works, and the compiler understands what needs to be created. I think everything has become clear, because this was already explained in the previous article. Now the question arises: do we want to write code 01 in the form in which it exists? Or rather, is not there a better and simpler way to write the same code?
If you understand what was discussed in the previous article, then you know that if we need to use types other than those declared, we will have to create additional functions or procedures. And by doing this, we duplicate the code, risking significantly complicating its improvement, since overloaded functions and procedures sooner or later result in certain difficulties. I am saying this based on many years of programming experience. Overloading always leads to long-term problems.
Thinking along these lines, we may say that some languages allow creating something that resembles a template, i.e. something that needs to be amended in just a few places, without having to duplicate its code. This is in theory, since using such a tool is not as easy as it seems. But let us start with the basics. Except that the types used in functions n lines 10 and 16 are different, everything else can be converted to a template. This is the first point to realize.
But despite all this, this code has one factor that makes everything more difficult: line 07. In order not to complicate this initial explanation, let us keep in mind that line 06 uses integer types, and line 07 uses floating-point data. I am imposing this condition on you at the moment, but we will see later that there are ways to change it. All right, this is a deal.
We will see how the same code 01 can be noted as an implementation using a function template. We can see it below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10.0, 25.0)); 08. } 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. T Sum(T arg1, T arg2) 12. { 13. Print(__FUNCTION__, "::", __LINE__); 14. return arg1 + arg2; 15. } 16. //+------------------------------------------------------------------+
Code 02
Now we are getting to a weird part. By executing code 01, you will get the result shown in the image below.
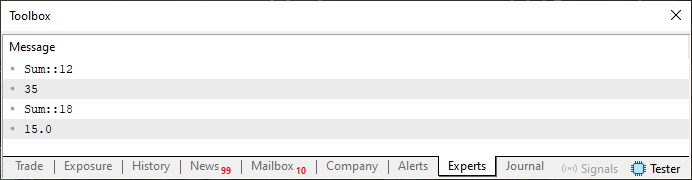
Figure 01
However, when running code 02, we will see what is shown in the figure below.
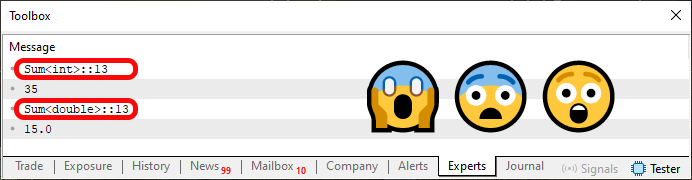
Figure 02
Question: what has happened here? The answer is that we convert these two functions from code 01 to the template that is now shown in code 02. But the question that really matters is to understand what kind of information is highlighted in Figure 02. And this is where things get more complicated if you do not understand what overload of functions or procedures is. This is because in the previous article we explained how the compiler can make a function or procedure to be overloaded. Here we implicitly tell the compiler how it should create this overload.
I use the word "implicitly" because WE DO NOT SAY which type to use. This decision will be made by the compiler. Therefore, in code 01 we used the ulong type in line 06 call, since it will use the function of line 10 which expected type is ulong type values. However, when we allowed the compiler to make a decision, it chose the int type over any other, and this decision is not always the best one. In some cases, this may cause the results of functions or procedures to differ from those expected.
But let us not rush it. We are just starting to work in this new field. We still have a lot to see before we enter this space of values which are other than those expected.
Now, I want you to understand the following. Although in image 02 we have a clear feeling that only one procedure or, as in this case, a function is being implemented; this happens because in both cases we are referring to the same line, that is, to line 13, present in code 02. The Sum function available in code 02 is NOT A FUNCTION, but a template for the function.
And what does this mean in practice? This means that once the compiler finds this function in our code, it will see if there is already one that meets our needs at the moment. If no such function exists, the compiler will create it using the function template declared between lines 10 and 15. Everything between these lines will be duplicated in some way, but adjusted so that it is used correctly, as intended when creating the code.
Now it is fashionable to say that artificial intelligence can create code. What is being done here is very similar, but without using neural networks or anything like that.
To make this clearer, make a minor change to code 02 to use Sum function with other data types. Please, find it just below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(130, 150)); 07. Print(Sum(130.0, 150.0)); 08. { 09. long v1 = 130, v2 = 150; 10. 11. Print(Sum(v1, v2)); 12. } 13. { 14. uchar v1 = 130, v2 = 150; 15. 16. Print(Sum(v1, v2)); 17. } 18. { 19. float v1 = 130, v2 = 150; 20. 21. Print(Sum(v1, v2)); 22. } 23. } 24. //+------------------------------------------------------------------+ 25. template <typename T> T Sum(T arg1, T arg2) 26. { 27. Print(__FUNCTION__, "::", __LINE__); 28. return arg1 + arg2; 29. } 30. //+------------------------------------------------------------------+
Code 03
Please note that we can use both the template writing method shown in code 02 and the method shown in code 03. In this case, in code 03, we do everything in one line, which is not very common in real code, since most programmers do not use this form, which is noted in line 25 of code 03. However, the meaning is the same as in code 02, only somewhat less common.
Fine, but that is not the point. The point is that when executing code 03 you get what you see below.
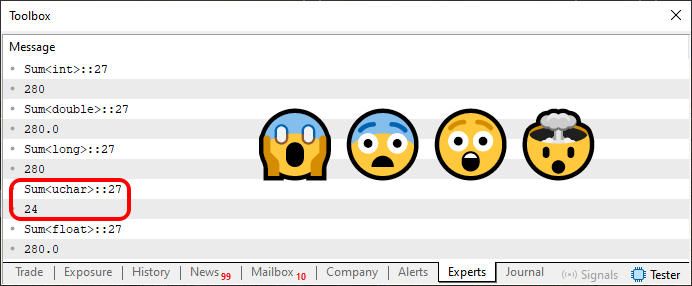
Figure 03
Now the situation has really become more complicated. "I definitely do not understand anything anymore - what crazy, meaningless words! I can see it with my own eyes, but I can't believe it. All the values are equal except for one. This seems absurd to me, and why does one of the sums return a value so different from the others?"
Yeah, did not I say it would be fun? Although it is very difficult to understand at first glance. Let us get this straight.
Remember when I said that the compiler searches for the best type for each case? Therefore, it creates overloaded functions so that the code matches what we need at the moment. Please note the following: when line six is executed, int is the best type. Therefore, an overloaded function is created that uses exactly this type. Immediately after that we have a data type that is entered as a floating point. In this case, the compiler understands that the best type is double. That is why this type is used. In all these cases, the compiler uses an implicit declaration form based on the best implemented data model, which will be used as the default type.
Now, the most interesting things: when entering blocks between lines 08 and 12, 13 and 17, as well as block from lines 18 to 22, we use local variables of different types. If you do not know what I am talking about, I recommend that you read the first articles in the series. There I explain what local variables are and how long each of them will remain active during code execution. Please note that knowledge is accumulating. Therefore, we should not allow the material to accumulate before starting its study and application in practice.
So, in each of these blocks, we have values that vary in bit width, resulting in a possible range. Thus, both the result of the operation and the type of data that the function uses depend on the type of variable used.
So, each of the lines that you can see in Image 03 indicates which type of data is being used and tells us what range the values may be in. I know it does not make sense right now. However, we have already discussed this when we explained the difference between variables and constants. Go back and review these articles: this knowledge will be very important now.
The uchar type has a range from 0 to 255. Since the sum of the values is 280, the value 24 highlighted in image 03 exactly corresponds to the overflow that occurred. Since there are 256 possible elements in the uchar type, if this value is exceeded, we have 24 overflow elements. That is, the counter was reset to zero and proceeded to element 24. Therefore, the result of the sum will be this value.
Note that this became only possible because we explicitly told the compiler that the data type used should be uchar. If another one had been used, the value could have been completely different.
Since these codes will be in the attachment, try changing the data type from uchar to char and observe the result presented. Remember that in this case, the compiler will issue a warning. This is because values 130 and 150 are outside the char range. However, you can reduce these values to fit within the range. How about adding 90 to 80 and adding the char data type to the building blocks? Let me assure you, the result will be very interesting.
Let us try to figure out what is going on here
As you may have noticed, using a function or procedure template saves us from having to create several overloaded functions or procedures, shifting the responsibility and work of creating them to the compiler. This way we can focus on creating the most readable code possible. However, without understanding what is happening, it is difficult to figure out how to expand this valuable resource, which is the template. So, let us forget about everything else and try to focus solely on understanding what is going on with this template that we are creating in the codes presented here. We will mainly focus on code 03, as it uses more data types, which makes it easier to understand.
First, let us take another look at image 03. In this image, you can clearly see that the function name is followed by character "less than", then the type name, and finally character "more than". We are specifically interested in identifying the type shown in Image 03.
If you look at code 03, you will notice that there is NO type identification in line 25. However, there is something interesting here: reserved word "typename" followed by an identifier. The identifier that we see in image 03 is very similar to the space where typename appears in code 03. This, one might say, is the secret.
The identifier following the reserved word typename allows the compiler to determine the data type that the template will use. Please note that the same identifier replaces the standard declaration that we make when defining the expected data type. Programmers usually use T identifier, but we can use any name, as long as it is correctly defined. During the creation of the executable file, this identifier will be replaced by the compiler with the appropriate type.
This gives us more freedom in using this type of resources, as there are ways to solve certain types of complex problems simply and inexpensively. We will talk about that in the next article. So far, I do not want you to get confused with too much information. I just wanted to draw your attention to the fact that the statement that we see in line 25 of code 03 can be changed to make things clearer to you.
For example, we can change line 25 of code 03 by the line shown below. But even in this case, the compiler will still understand how to work with the template.
template <typename Unknown> Unknown Sum(Unknown arg1, Unknown arg2)
Final considerations
In this article, we have started considering one of the concepts that many beginners avoid. This is related to the fact that templates are not an easy topic, as many do not understand the basic principle underlying the template: overload of functions and procedures. Although only the first part of the huge range of features that can be used with templates has been explained so far, understanding this first part is very important. Much of what will be shown and explained in the following articles follows from this basic and initial part.
I believe that those who are just starting to learn programming may get confused about how useful templates are and how to properly use this type of resources available in MQL5. But I want to remind you that this material does not require rapid assimilation. In fact, only time and practice will help you better understand such concept that will be applied in the future.
However, this does not mean that you should stop there and stop practicing what is presented here. Although, studying the codes like those provided in attachments may seem the waste of time at first because of their simplicity, can later save many hours when disassembling more complex codes that use all these resources. Remember:
Knowledge accumulates over time. It does not arise out of nowhere and is not inherited from one person to another.
See you in the next article, where we will delve even deeper into the issue of using templates in their most basic and simple form.
Translated from Portuguese by MetaQuotes Ltd.
Original article: https://www.mql5.com/pt/articles/15658
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use