
从基础到中级:模板和类型名称(一)

概述
在上一篇文章“从基础到中级:重载”中,我们试图解释编程中最困难的事情之一,特别是在初始阶段以及面对乍一看没有意义的东西时。尽管使用重载时会出现所有困难,但了解发生了什么非常重要。这就是为什么,如果没有这些知识,亲爱的读者,你的能力将会受到很大限制。更糟糕的是,您将无法理解其他要点,我们将在以下文章中讨论这些要点。
尽管许多人认为重载是一种编程错误,因为它使代码变得相当复杂,但没有它,我们就无法创建或实现许多东西。因此,为了理解本文将要描述的内容,我们必须很好地理解前一篇文章中涵盖的所有内容。否则,今天的话题将成为你的眼中钉,几乎不可能理解。
然而,如果没有本文提供的知识,几乎不可能继续寻找新的编程特性和机制。因此,是时候关注我们将在本文中看到的内容了,因为在这里,我们将处理一些非常有趣的事情,尽管非常复杂,这取决于在任何给定时间正在实现的事情的类型。
模板和类型名称
最复杂、最困难的概念之一就是重载,它最终会让新手程序员灰心丧气。然而,正如你在上一篇文章中看到的,当我们使用的语言允许我们做某些事情或给我们一定程度的自由时,重载只是我们可以实现的一小部分,就像我们开始更深入地处理重载时发生的那样。
首先要理解的是,当按照前一篇文章中的方式执行重载时,它清楚地表明了我们可以使用哪些类型以及何时使用它们,从而方便了在不同场景中使用各种数字容量的值。但在这里,我们将看到更复杂的东西,这将把我们在上一篇文章中看到的内容变成了非常有教育意义的东西,因为那里描述的一切也适用于这里,但范围要大得多。
你们中的一些人可能会想:我真的需要学习使用这样的工具吗?是的,如果没有这些工具,许多可以完成的事情将完全无法访问,除非你使用更复杂、更难学习的实现方法。那么,推迟这一部分,留待下次解释,不是更好吗?例如,在编程指标或 EA 交易之后。事实上,我一直在思考这个问题,因为到目前为止所做和展示的一切都是任何初学者在尝试编程之前都应该知道的。
然而,我认为没有理由推迟这个话题,哪怕只是因为我已经告诉过如何从头开始完全实现 EA 交易系统,无论是自动编程还是手动操作的帮助。
您可以在文章“创建自动运行的 EA(第 15 部分):自动化(七) ”中读到,该系列文章用十五篇文章详细描述了如何做到这一点。然而,即使在这些文章发表后,我注意到许多人对某些主题有基本的怀疑,而另一些人则不想依赖现成的程序。他们想了解这一切是如何运作的,以便创建自己的解决方案来满足他们的需求。
即使完成了该系列开发回放系统 —— 市场模拟(第 01 部分):第一次实验(一) “,我注意到很多人甚至没有想象过这样的事情是可以实现的。虽然这一系列文章尚未完全发表,但很快就会发表。由于许多人可能想改进或理解这段代码的某些部分,尽管已经详细解释过,但我还没有深入探讨其中的各个要点,这些要点可能是那些想使用任何东西的人的目标。
由于我不打算进一步讨论这些主题(它们已经得到了很好的研究),应一些人的要求,我开始展示如何在 MQL5 中使用神经网络。我再次注意到,有些人无法完成大部分已实施的工作。同样,缺乏足够的知识和基本的编程概念使得任何解释对初学者来说都非常复杂和困难。许多人没有想到可以用纯 MQL5 实现神经网络。
对于那些还没有读过我关于这个主题的文章的人来说,第一篇是“神经网络实践:割线“。然而,许多文章尚未发表。但是随着文章的发表,你会注意到基本的编程知识比看起来要重要得多。
尽管我在本系列文章中已经解释了更复杂的概念,但我仍然希望实现一系列专注于编程基础的文章。我们的想法是从最基础的开始解释一切。
现在我已经解释了为什么(尽管许多人认为这对新手程序员来说不是必需的)一个结构良好、坚实的基础可以帮助你理解许多其他代码,即使你的目标是别的,例如,学习如何使用基本的 EA 交易系统或指标来帮助你更好地交易。如果这是唯一的目标,那么最好付钱给专业程序员为你做这件事,这样你就可以节省时间,避免头痛。
但是,再次回到我们的主要问题,理解以下内容非常重要:一切都是基于上一篇文章中所展示的内容。此外,如果不了解之前的一切,一切都将失去意义。
让我们从简单的事情开始。当我说“简单”时,我的意思是它应该很容易理解,因为尽管理解很简单,但考虑到所需的知识量,这个概念有几个方面很难掌握。看一下下面的代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25.)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(ulong arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(double arg1, double arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2; 20. } 21. //+------------------------------------------------------------------+
代码 01
这段代码和上一篇文章开头的代码一模一样。但是为什么呢?原因是,这是熟悉模板和了解类型名的理想选择。从某种意义上说,为了更容易解释,显示一个或另一个术语会更正确。但目前,一件事将与另一件事紧密相关。这正是导致那些刚刚开始工作的人会发现自己完全困惑的原因。
然而,为了最初简化主题,我们不会详细说明每个术语的实际含义。我希望你只是看着,试着弄清楚发生了什么。不要试图理解它是如何工作的,或者如何在其他情况下使用它。如果你试图自己做这件事,你会发现自己陷入了死胡同。因此,请耐心等待,因为随着时间的推移,我们会解释一切,因为需要做的事情比我们在这篇简单的文章中看到的要多得多。
现在我希望你注意以下几点:第 10 行中的函数和第 16 行中的函数之间的唯一区别是预期和返回的数据类型。上述代码中没有其他更改。
注意并理解这一点非常重要,比理解其他一切都重要得多。如果你看不到这一点,其他一切都将毫无意义。代码 01 有效,并且编译器了解需要创建什么。我认为一切都已经清楚了,因为上一篇文章已经解释过了。现在出现了一个问题:我们是否想以它现在的形式编写代码 01?或者更确切地说,难道没有更好、更简单的方法来编写相同的代码吗?
如果你理解上一篇文章中讨论的内容,那么你就知道,如果我们需要使用声明类型以外的类型,我们将不得不创建额外的函数或过程。通过这样做,我们复制了代码,有可能使其改进变得非常复杂,因为重载的函数和过程迟早会导致某些困难。我这么说是基于多年的编程经验。重载总是会导致长期问题。
按照这些思路思考,我们可以说,一些语言允许创建类似于模板的东西,即只需要在几个地方进行修改的东西,而不必复制其代码。这是理论上的,因为使用这样的工具并不像看起来那么容易。但让我们从基础开始。除了函数第 10 行和第 16 行中使用的类型不同外,其他所有内容都可以转换为模板。这是首先要认识到的一点。
但尽管如此,这段代码有一个因素使一切变得更加困难:第 07 行。为了不使这个最初的解释复杂化,让我们记住,第 06 行使用整数类型,第 07 行使用浮点数据。我现在把这个条件强加给你,但我们稍后会看到有办法改变它。好吧,这是交易。
我们将看到如何将相同的代码 01 标记为使用函数模板的实现。我们可以在下面看到它。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10.0, 25.0)); 08. } 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. T Sum(T arg1, T arg2) 12. { 13. Print(__FUNCTION__, "::", __LINE__); 14. return arg1 + arg2; 15. } 16. //+------------------------------------------------------------------+
代码 02
现在我们到了一个奇怪的部分。通过执行代码 01,您将得到下图所示的结果。
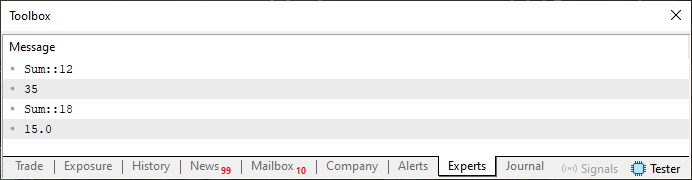
图 01
然而,当运行代码 02 时,我们将看到下图所示的内容。
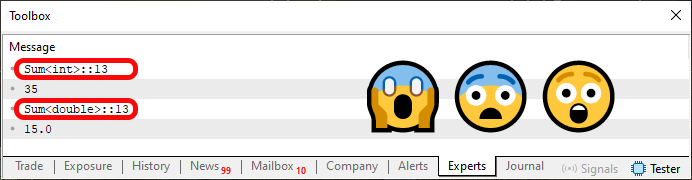
图 02
问题:这里发生了什么事?答案是,我们将这两个函数从代码 01 转换为现在代码 02 中显示的模板。但真正重要的问题是了解图 02 中突出显示的信息类型。如果您不了解函数或过程的重载是什么,事情就会变得更加复杂。这是因为在上一篇文章中,我们解释了编译器如何使函数或过程重载。在这里,我们隐式地告诉编译器应该如何创建此重载。
我使用“隐式”这个词是因为我们不会说使用哪种类型。该决定将由编译器做出。因此,在代码 01 中,我们在第 06 行调用中使用了 ulong 类型,因为它将使用第 10 行的函数,该函数的预期类型是 ulong 类型值。然而,当我们允许编译器做出决定时,它选择了 int 类型而不是其他类型,而这个决定并不总是最好的。在某些情况下,这可能会导致函数或过程的结果与预期不同。
但我们不要操之过急。我们才刚刚开始在这个新领域工作。在我们进入这个数值空间之前,我们还有很多东西要看,这些数值空间与预期不同。
现在,我希望您了解以下内容。尽管在图 02 中我们清楚地感觉到只有一个过程,或者像本例中那样,只有一个函数正在实现;发生这种情况是因为在两种情况下我们都指的是同一行,即代码 02 中的第 13 行。代码 02 中可用的 Sum 函数不是一个函数,而是该函数的模板。
这在实践中意味着什么? 这意味着,一旦编译器在我们的代码中找到此函数,它将查看是否已经有一个满足我们当前需求的函数。如果不存在这样的函数,编译器将使用第 10 行到第 15 行之间声明的函数模板来创建它。这些行之间的所有内容都将以某种方式复制,但会进行调整,以便在创建代码时按预期正确使用。
现在流行的说法是,人工智能可以创建代码。这里正在做的事情非常相似,但没有使用神经网络或类似的东西。
为了使这一点更清楚,对代码 02 进行微小更改,以将 Sum 函数与其他数据类型一起使用。请在下方找到它。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(130, 150)); 07. Print(Sum(130.0, 150.0)); 08. { 09. long v1 = 130, v2 = 150; 10. 11. Print(Sum(v1, v2)); 12. } 13. { 14. uchar v1 = 130, v2 = 150; 15. 16. Print(Sum(v1, v2)); 17. } 18. { 19. float v1 = 130, v2 = 150; 20. 21. Print(Sum(v1, v2)); 22. } 23. } 24. //+------------------------------------------------------------------+ 25. template <typename T> T Sum(T arg1, T arg2) 26. { 27. Print(__FUNCTION__, "::", __LINE__); 28. return arg1 + arg2; 29. } 30. //+------------------------------------------------------------------+
代码 03
请注意,我们既可以使用代码 02 中所示的模板编写方法,也可以使用代码 03 中所示的方法。在这种情况下,在代码 03 中,我们在一行中完成所有操作,这在实际代码中并不常见,因为大多数程序员不使用这种形式,这在代码 03 的第 25 行中有所说明。然而,其含义与代码 02 中的含义相同,只是不太常见。
好吧,但这不是重点。关键在于,当执行代码 03 时,你会得到下面看到的内容。
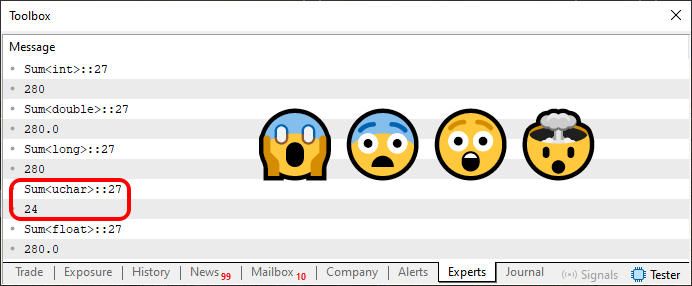
图 03
现在情况确实变得更加复杂了。“我肯定什么都不懂了 —— 多么疯狂、毫无意义的话!我能亲眼看到,但我不敢相信。除了一个之外,所有值都相等。在我看来,这似乎很荒谬,为什么其中一个总和的返回值与其他总和如此不同?"
是啊,我不是说过会很有趣吗?虽然乍一看很难理解。让我们把这件事弄清楚。
还记得我说过编译器会为每种情况搜索最佳类型吗?因此,它创建了重载函数,以便代码与我们当前所需的相匹配。请注意以下几点:当执行第六行时,int 是最好的类型。因此,创建了一个使用这种类型的重载函数。紧接着,我们有一个以浮点形式输入的数据类型。在这种情况下,编译器认为最好的类型是 double。这就是为什么使用这种类型。在所有这些情况下,编译器使用基于最佳实现的数据模型的隐式声明形式,该形式将用作默认类型。
现在,最有趣的事情是:在第 08 行和第 12 行、第 13 行和第 17 行之间以及第 18 行到第 22 行之间的块中,我们使用不同类型的局部变量。如果你不知道我在说什么,我建议你阅读本系列的第一篇文章。在这里,我解释了什么是局部变量,以及在代码执行过程中,每个局部变量将保持活动状态多长时间。请注意,知识是不断积累的。因此,在开始研究和实践应用之前,我们不应该让材料积累。
因此,在每个块中,我们都有位宽不同的值,从而产生一个可能的范围。因此,操作的结果和函数使用的数据类型都取决于所使用的变量的类型。
因此,您在图 03 中看到的每一行都表示正在使用哪种类型的数据,并告诉我们值可能在哪个范围内。我知道现在这没有意义。然而,我们在解释变量和常量之间的区别时已经讨论过这一点。回过头来回顾这些文章:这些知识现在将非常重要。
uchar 类型的范围是 0 到 255。由于值的总和为 280,因此图 03 中突出显示的值 24 恰好对应于发生的溢出。由于 uchar 类型中有 256 个可能的元素,如果超过该值,则我们有 24 个溢出元素。也就是说,计数器被重置为 0 并继续发展到元素 24。因此,求和的结果将是这个值。
请注意,这之所以成为可能,是因为我们明确告诉编译器所使用的数据类型应该是 uchar。如果使用另一个类型,其值可能会完全不同。
由于这些代码将在附件中,请尝试将数据类型从 uchar 更改为 char 并观察所呈现的结果。请记住,在这种情况下,编译器将发出警告。这是因为值 130 和 150 超出了 char 的范围。但是,您可以减少这些值以适应该范围。将 90 加到 80 并将 char 数据类型添加到构建块怎么样?我向你保证,结果将会非常有趣。
让我们试着弄清楚这里发生了什么
您可能已经注意到,使用函数或过程模板使我们不必创建多个重载函数或过程,从而将创建它们的责任和工作转移给编译器。这样我们就可以专注于创建最具可读性的代码。然而,如果不了解正在发生的事情,就很难弄清楚如何扩展这个宝贵的资源,即模板。所以,让我们忘记其他一切,试着只专注于理解我们在这里提供的代码中创建的这个模板发生了什么。我们将主要关注代码 03,因为它使用了更多的数据类型,这使得它更容易理解。
首先,让我们再看一下图 03。在此图中,您可以清楚地看到函数名称后面跟着字符“<”,然后是类型名称,最后是字符“>”。我们特别感兴趣的是识别图 03 中显示的类型。
如果您查看代码 03,您会注意到第 25 行没有类型标识。然而,这里有一些有趣的东西:保留字 “typename” 后跟一个标识符。我们在图 03 中看到的标识符与代码 03 中 typename 出现的空间非常相似。有人可能会说,这就是秘密。
保留字 typename 后面的标识符允许编译器确定模板将使用的数据类型。请注意,相同的标识符替换了我们在定义预期数据类型时所做的标准声明。程序员通常使用 T 标识符,但我们可以使用任何名称,只要它被正确定义。在创建可执行文件期间,此标识符将被具有适当类型的编译器替换。
这让我们在使用这类资源时有了更多的自由,因为有一些方法可以简单而廉价地解决某些类型的复杂问题。我们将在下一篇文章中讨论这个问题。到目前为止,我不想让你被太多的信息所混淆。我只是想提请您注意,我们可以更改代码 03 第 25 行中的语句,以便让您更清楚地了解情况。
例如,我们可以通过下面所示的代码行来更改代码 03 的第 25 行。但即使在这种情况下,编译器仍然会理解如何使用模板。
template <typename Unknown> Unknown Sum(Unknown arg1, Unknown arg2)
最后的探讨
在本文中,我们开始考虑许多初学者避免的概念之一。这与模板不是一个容易的话题有关,因为许多人不理解模板的基本原理:函数和过程的重载。尽管到目前为止只解释了可用于模板的大量功能的第一部分,但理解这第一部分非常重要。以下文章将展示和解释的大部分内容都来自这一基本和初始部分。
我相信那些刚开始学习编程的人可能会对模板的实用性以及如何正确使用 MQL5 中提供的此类资源感到困惑。但我想提醒你,这些材料不需要快速吸收。事实上,只有时间和实践才能帮助你更好地理解这种将在未来应用的概念。
然而,这并不意味着你应该止步于此,停止练习这里介绍的内容。虽然,研究附件中提供的代码起初可能看起来很浪费时间,因为它们很简单,但后来在分解使用所有这些资源的更复杂的代码时可以节省很多时间。请记住:
知识随着时间的推移而积累。它不是凭空而来的,也不是从一个人遗传给另一个人的。
在下一篇文章中见,我们将更深入地探讨以最基本和最简单的形式使用模板的问题。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/15658
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 价格行为分析工具包开发(第 17 部分):TrendLoom EA 工具
价格行为分析工具包开发(第 17 部分):TrendLoom EA 工具
