
初級から中級まで:テンプレートとtypename(I)

はじめに
前回の「初級から中級まで:オーバーロード」では、プログラミングにおいて最も難しいことのひとつを説明しようとしました。特に初心者にとっては、初見では意味がわからないことも多いテーマです。オーバーロードを使う際には多くの困難が伴いますが、それが何を意味するのかを理解することは非常に重要です。この知識がなければ、親愛なる読者の皆さんは非常に制限されてしまいます。さらに悪いことに、次の記事で説明する他のポイントも理解できなくなります。
多くの人はオーバーロードをプログラミング上のエラーだと考えます。確かにコードを複雑にする要因にはなりますが、オーバーロードがなければ実現できないことも多くあります。そのため、この記事で説明する内容を理解するには、前回の記事で扱った内容を十分に理解しておく必要があります。そうでなければ、今日のテーマは理解しにくくなり、ほとんど手に負えないものになってしまいます。
しかし、この記事で提供する知識がなければ、新しいプログラミング機能やメカニズムを探求することはほぼ不可能です。ですから、ここで扱う内容に集中する時が来たのです。今回扱うのは非常に面白いテーマですが、同時に実装する内容によっては非常に複雑にもなるものです。
テンプレートとtypename
初心者プログラマーを挫折させる可能性がある、最も複雑で難しい概念のひとつがオーバーロードです。しかし、前回の記事で示した通り、オーバーロードは私たちが実装できることのほんの一部に過ぎません。使用する言語が一定の自由度を提供する場合、より深くオーバーロードを扱うことが可能になります。
最初に理解すべきことは、前回の記事で示したようにオーバーロードを使うことで、どの型を使うか、いつそれを使うかを明確に示すことができ、異なる桁数の値を異なるシナリオで扱いやすくなるということです。しかし今回扱う内容はさらに複雑で、前回の記事で見た内容をより大規模で教育的に拡張するものです。前回の記事で説明されたことはここでも適用されますが、より大きなスケールで応用されます。
中には、本当にこんなツールを学ぶ必要があるのかと疑問に思う方もいるでしょう。答えは「ある」です。こうしたツールがなければ、多くは全く実現できなくなります。もっと複雑で習得が難しい実装方法を使わない限り、不可能です。では、この部分を後回しにして、インジケーターやエキスパートアドバイザー(EA)のプログラミングを学んだ後に説明した方がよいのでしょうか。実際のところ、これまで示してきた内容は、初心者が何かをプログラムする前に知っておくべきことだからです。
しかし、私はこのテーマを後回しにする理由を見出せません。すでに、スクラッチからEAを完全に実装する方法を、自動化プログラムと手動操作補助の両方で解説しているからです。
これについては、「自動で動作するEAを作成する(第15回):自動化(VII)」という記事で、15回に分けて短い連載で詳しく説明しています。しかし、記事が公開された後でも、多くの人が基本的な疑問を抱き、既存のプログラムに頼りたくない状況が見受けられました。自分で仕組みを理解し、自分のニーズに合ったソリューションを作りたいのです。
さらに、「リプレイシステムの開発 - 市場シミュレーション(第1回):最初の実験(I)」の連載を終えた後、多くの人はこのようなことを実装できるとは想像もしていませんでした。この連載はまだ完全には公開されていませんが、近日中に公開予定です。そして、多くの人がこのコードの一部を改善したり理解したりしたいと思うかもしれません。コードの詳細は説明済みですが、個々のポイントには深く触れていないため、そうした部分が学習や作業の目標になる可能性があります。
私はこれ以上この話題を掘り下げるつもりはありません(十分に研究済みです)が、要望に応じてMQL5でのニューラルネットワークの扱い方を示し始めました。こでも、いくつかの人は実装された多くのことを達成できないことに気づきました。やはり、十分な知識や基本的なプログラミング概念が欠けていると、初心者にとって説明は非常に複雑で理解が難しいのです。多くの人は、純粋なMQL5でニューラルネットワークを実装できるとは想像していませんでした。
このテーマに関する私の記事をまだ読んでいない方は、最初の記事「ニューラルネットワークの実践:割線」を参照してください。しかし、多くの記事はまだ公開されていません。記事が公開されるにつれ、基本的なプログラミング知識が見た目以上に重要であることがわかるでしょう。
私はすでに、この連載でより複雑な概念を説明しましたが、それでもプログラミングの基礎に焦点を当てた連載記事を作りたいという思いがありました。アイデアとしては、すべてを基礎から順を追って説明することです。
そして、すでに説明したように(多くの人は初心者にとって不要だと思うかもしれませんが)、しっかり構築された堅固な基盤があることは、他のコードを理解する助けになります。たとえ目標が別のことであっても、たとえば基本的なEAやインジケーターの使い方を学んでより良く取引できるようになることが目的であっても、この基盤は役立ちます。もしそれだけが目標であれば、プロのプログラマーに依頼した方が時間を節約でき、頭痛も避けられます。
しかし、元の話題に戻ると、ここで改めて理解すべきことは次の通りです。すべては前回の記事で示された内容に基づいています。さらに言えば、前回の内容を理解していなければ、今回の内容は全く意味を成しません。
では、まず簡単なものから始めましょう。「簡単」と言うのは、理解するのが比較的容易であるという意味です。しかし、理解自体は簡単でも、この概念には習得が難しい複数の側面があります。必要な知識の量を考えると、マスターするのが難しいのです。次のコードを見てください。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25.)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(ulong arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(double arg1, double arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2; 20. } 21. //+------------------------------------------------------------------+
コード01
このコードは、前の記事の冒頭で紹介したコードとまったく同じです。でも、なぜでしょうか。その理由は、テンプレートに慣れ、typenameが何であるかを学ぶのに最適な例だということです。ある意味では、どちらか一方の用語だけを用いたほうが説明は簡単になります。しかし現時点では、一方が他方と密接に関連しています。これが、これから学び始める人にとって完全な混乱を招く要因となるのです。
ただし、最初はテーマを簡単にするために、各用語の実践的な意味には触れません。まずはコードを見て、何が起きているのかを理解することに集中してください。どのように動作するのか、他のケースでどのように使えるのかを理解しようとしないでください。自分でそれを理解しようとすると、行き詰まってしまいます。ですから、辛抱強く見てください。時間が経つにつれ、必要なことはすべて解説します。この単純な記事で示す以上の内容が必要だからです。
ここで注目すべきことは次の通りです。10行目の関数と16行目の関数の唯一の違いは、期待されるデータ型と返されるデータ型です。それ以外は上記のコードで変更されていません。
これは非常に重要です。これを認識し、理解することは、他のすべてを理解するよりも重要です。これに気づかなければ、他のすべてが意味を持ちません。コード01は動作し、コンパイラは何を作成すべきかを理解します。前回の記事で説明済みなので、ここは明確でしょう。ここで疑問が生じます。コード01をそのままの形で書くべきでしょうか。あるいは、同じコードをより簡単に書く方法があるのではないでしょうか。
前回の記事の内容を理解していれば、宣言された型以外を使う場合は、追加の関数や手続きを作成する必要があることがわかります。そうすると、コードが複製され、改善が大幅に難しくなるリスクがあります。オーバーロードされた関数や手続きは、遅かれ早かれ問題を引き起こすのです。これは長年のプログラミング経験から言えることです。オーバーロードは常に長期的な問題をもたらします。
この考え方に沿って言えば、一部の言語では、テンプレートのような仕組みを作ることが可能です。つまり、コードを複製せずに、いくつかの場所だけを修正すれば済むものです。理論上はそうですが、こうしたツールを使うことは見た目ほど簡単ではありません。では、基本から始めましょう。10行目と16行目の関数で使用されている型が異なること以外は、それ以外の部分はすべてテンプレートに変換可能です。これが最初に理解すべきポイントです。
しかし、それにもかかわらず、このコードにはすべてを複雑にする要素があります。それが7行目です。この初期の説明を複雑にしないために、6行目は整数型、7行目は浮動小数点型を使っていることを前提とします。この条件を今は課しますが、後で変更方法があることも確認します。この前提で進めます。
次に、同じコード01を関数テンプレートを使った実装として表記する方法を見てみましょう。以下で確認できます。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10.0, 25.0)); 08. } 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. T Sum(T arg1, T arg2) 12. { 13. Print(__FUNCTION__, "::", __LINE__); 14. return arg1 + arg2; 15. } 16. //+------------------------------------------------------------------+
コード02
やや込み入った部分に入ります。コード01を実行すると、下の画像に示す結果が得られます。
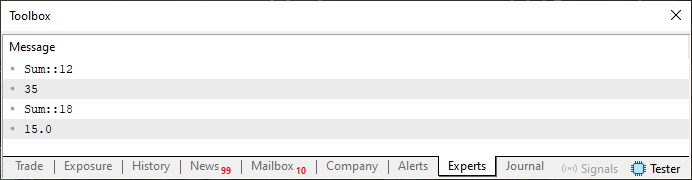
図01
ただし、コード02を実行すると、下の図に示すような結果になります。
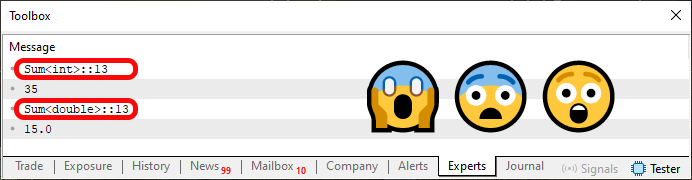
図02
質問です。ここで何が起こったのでしょうか。答えは、コード01の二つの関数を、コード02に示されているテンプレートへ変換した、ということです。ですが本当に重要な質問は、図02においてどのような情報が強調されているのかを理解することです。もし「関数や手続きのオーバーロード」を理解していなければ、この部分はより複雑に感じられるでしょう。というのも、前回の記事で私たちは、コンパイラがどのようにして関数や手続きをオーバーロードできるかを説明しました。ここでは、コンパイラに対して「暗黙的に」そのオーバーロードを作るよう指示しています。
私が「暗黙的に」と言うのは、どの型を使うかを私たちが明示的に指定していないからです。この決定はコンパイラによっておこなわれます。したがってコード01では、6行目の呼び出しでulong型を使いました。これは10行目の関数がulong型の値を引数として受け取るためです。しかしコンパイラに決定を委ねると、他の型よりもint型を優先的に選んでしまいます。そしてこの決定は必ずしも最適とは限らず、場合によっては関数や手続きの結果が期待したものと異なることがあります。
しかし、焦る必要はありません。私たちはまだこの新しい領域を探り始めたばかりなのです。想定外の値の世界に入る前に、まだ学ぶべきことがたくさんあります。
ここで理解してほしいのは次の点です。図02を見ると、あたかも一つの手続き、あるいはこの場合は一つの関数だけが実装されているかのように見えます。しかし実際には、両方の場合とも同じ行、つまりコード02の13行目を指しています。コード02にあるSum関数は関数そのものではなく、関数のテンプレートなのです。
では、これは実際にどういう意味を持つのでしょうか。 これは、コンパイラがこの関数をコード内で見つけたとき、その時点で必要に合致する関数が既に存在するかどうかを確認するということです。もし存在しなければ、コンパイラは10行目から15行目の間に宣言されている関数テンプレートを使って、新しく関数を生成します。その間に記述されている内容は、ある意味「複製」されますが、コード作成時に意図された通り正しく使用できるよう調整されます。
近年では、人工知能がコードを生成できるとよく言われます。ここでおこなわれていることも非常によく似ていますが、ニューラルネットワークなどを使っているわけではありません。
これをさらに明確にするために、コード02に小さな変更を加えて、Sum関数を他のデータ型でも使えるようにしてください。その例は、このすぐ下に示されています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(130, 150)); 07. Print(Sum(130.0, 150.0)); 08. { 09. long v1 = 130, v2 = 150; 10. 11. Print(Sum(v1, v2)); 12. } 13. { 14. uchar v1 = 130, v2 = 150; 15. 16. Print(Sum(v1, v2)); 17. } 18. { 19. float v1 = 130, v2 = 150; 20. 21. Print(Sum(v1, v2)); 22. } 23. } 24. //+------------------------------------------------------------------+ 25. template <typename T> T Sum(T arg1, T arg2) 26. { 27. Print(__FUNCTION__, "::", __LINE__); 28. return arg1 + arg2; 29. } 30. //+------------------------------------------------------------------+
コード03
ご注意ください。コード02に示されたテンプレートの記述方法と、コード03に示された方法の両方を使うことができます。コード03の場合、すべてを1行で記述していますが、これは実際のコードではあまり一般的ではありません。というのも、ほとんどのプログラマーはこの形式を使わないからであり、そのことはコード03の25行目に表れています。しかし、意味としてはコード02と同じであり、ただしやや珍しい書き方であるにすぎません。
さて、それは本題ではありません。本題は、コード03を実行すると以下のような結果が得られる、という点です。
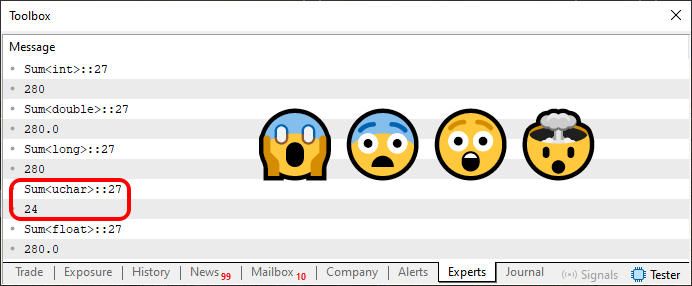
図03
さて、ここから状況は本当に複雑になってきました。「もうまったく理解できない。なんてめちゃくちゃで意味不明な言葉なんだ。自分の目で見てはいるけれど、信じられない。すべての値は同じなのに、ひとつだけ違っている。これは不条理に思えるし、なぜひとつの合計だけが他とまったく異なる値を返すんですか。」
面白いと言ったでしょう?一見しただけでは理解するのが非常に難しいのです。では、整理していきましょう。
以前、コンパイラが各ケースに最適な型を探すと言いました。つまり、必要に応じてコードが一致するようにオーバーロード関数を生成するのです。ここで注目してほしいのは次の点です。6行目が実行されるとき、最適な型はintです。したがって、この型を使ったオーバーロード関数が生成されます。その直後には浮動小数点型のデータが入力されます。この場合、コンパイラはdoubleが最適だと判断します。だからその型が使用されるのです。これらすべてのケースで、コンパイラは「最適に実装されたデータモデル」に基づく暗黙的な宣言形式を利用し、それをデフォルト型として適用します。
ここからがさらに面白い部分です。8~12行、13~17行、そして18~22行のブロックに入るとき、それぞれ異なる型のローカル変数を使っています。ここで何を言っているかわからなければ、このシリーズの最初の記事を読むことをお勧めします。そこでローカル変数とは何か、コード実行中にそれぞれがどのくらいの期間有効なのかを説明しました。知識は積み重なっていくものです。ですから、学習や実践を始める前に資料をため込みすぎないようにしましょう。
こうして各ブロックでは、ビット幅の異なる値を扱うため、取り得る範囲も異なります。その結果、演算の結果も、関数が使うデータ型も、どの変数型を使用しているかによって変わってくるのです。
したがって、図03に表示されている各行は「どのデータ型が使用されているのか」を示し、その型が取り得る値の範囲を教えてくれます。今はあまり意味がないかもしれません。しかし、変数と定数の違いを説明したときにすでに触れています。記事を振り返って復習してください。この知識が今非常に重要になります。
uchar型の範囲は0~255です。値の合計が280となるため、図03で強調されている「24」という値はまさにオーバーフローの結果に相当します。uchar型では256個の要素しか持てないため、この値を超えると24のオーバーフローが発生します。つまりカウンタがゼロにリセットされ、要素24から再スタートしたわけです。したがって、合計の結果はこの値となります。
注意してほしいのは、この結果が得られたのはコンパイラに明示的にuchar型を使うよう指示したからです。もし別の型を使っていたら、結果はまったく異なっていたでしょう。
これらのコードは添付ファイルに含まれていますので、ぜひuchar型をchar型に変えて結果を観察してみてください。この場合、コンパイラは警告を出します。なぜなら、値130と150はcharの範囲外だからです。ただし、これらの値を範囲内に収まるように減らすことも可能です。たとえば90と80を加算し、ブロックのデータ型をcharにしてみてください。きっととても興味深い結果が得られるはずです。
では、ここで何が起こっているのかを理解してみましょう。
お気づきのとおり、関数や手続きのテンプレートを使用することで、複数のオーバーロード関数や手続きを自分で作成する必要がなくなり、それをコンパイラに任せることができます。こうすることで、私たちはできるだけ可読性の高いコードを書くことに集中できるのです。しかし、仕組みを理解していなければ、この便利な「テンプレート」という資源をどのように拡張すればよいのかを見極めるのは難しいでしょう。ですので、他のことはいったん忘れて、このコードで作成しているテンプレートの仕組みを理解することだけに集中しましょう。ここでは主にコード03に注目します。なぜなら、コード03ではより多くのデータ型が使われているため、理解しやすいからです。
まず、もう一度図03を見てください。この図では、関数名の後に「小なり(<)」、その後に型名、そして最後に「大なり(>)」が続いているのがはっきりと確認できます。ここで特に注目したいのは、図03に表示されている型です。
コード03を見ると、25行目には型の指定がありません。しかし、ここに面白い点があります。予約語typenameの後に識別子が続いているのです。図03で見られる識別子は、コード03におけるtypenameの位置と非常によく似ています。これが、いわば「秘密」なのです。
予約語typenameに続く識別子は、テンプレートが使用するデータ型をコンパイラに決定させる役割を持っています。重要なのは、この識別子が、私たちが通常、期待するデータ型を定義するときにおこなう標準的な宣言の代わりを果たすという点です。プログラマーは慣例的にこの識別子にTを使いますが、正しく定義されていればどんな名前でもかまいません。実行ファイルが生成される際、この識別子はコンパイラによって適切な型に置き換えられるのです。
これにより、テンプレートという仕組みを使う自由度が広がり、ある種の複雑な問題をシンプルかつ低コストで解決できるようになります。このことについては次回の記事で詳しく扱います。今回は、情報を詰め込みすぎて混乱させたくありません。ただ、コード03の25行目に書かれている宣言は、わかりやすくするために変更できるという点に注意してほしかったのです。
たとえば、コード03の25行目を次のように書き換えることができます。それでもなお、コンパイラはテンプレートの扱い方を理解します。
template <typename Unknown> Unknown Sum(Unknown arg1, Unknown arg2)
最終的な考察
この記事では、多くの初心者が避けがちな概念の1つを取り上げました。これはテンプレートに関連する話題で、多くの人がテンプレートの基本原理を理解していないため、決して簡単なテーマではありません。その基本原理とは、関数や手続きのオーバーロードです。テンプレートで使える膨大な機能のうち、今回はまだその最初の部分しか説明していませんが、この第一歩を理解することは非常に重要です。これから紹介・解説していく内容の多くは、この基本的で初歩的な部分から派生していくからです。
プログラミングを学び始めたばかりの人にとっては、テンプレートがどれほど便利で、どう使うべきなのかがわかりにくいかもしれません。しかし忘れないでください。この学習内容はすぐに消化する必要はありません。むしろ、時間と実践を通じてのみ、この概念がより深く理解できるようになり、将来に活かせるようになります。
とはいえ、そこで立ち止まって、ここで示したことの練習をやめてしまってはいけません。添付ファイルにあるようなシンプルなコードを学習することは、一見すると時間の無駄に思えるかもしれません。しかし、こうした学習は後々、これらのリソースをフル活用する複雑なコードを分解するときに、何時間もの節約につながります。覚えておいてください。
知識は時間とともに積み重なっていくものです。突然生まれるものではなく、他人からそのまま受け継げるものでもありません。
次回の記事でまたお会いしましょう。そこではテンプレートを、最も基本的かつシンプルな形で使う方法について、さらに深く掘り下げていきます。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15658
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索