
Von der Grundstufe bis zur Mittelstufe: Template und Typename (I)

Einführung
Im vorherigen Artikel „Von der Grundstufe zur Mittelstufe: Überladen“, haben wir versucht, eines der schwierigsten Dinge beim Programmieren zu erklären, besonders in der Anfangsphase und wenn man mit etwas konfrontiert wird, das auf den ersten Blick keinen Sinn ergibt. Trotz aller Schwierigkeiten, die bei der Verwendung von Überlast auftreten, ist es sehr wichtig zu verstehen, was passiert. Deshalb werden Sie, liebe Leserin, lieber Leser, ohne dieses Wissen sehr eingeschränkt sein. Schlimmer noch, Sie werden andere Punkte, die wir in den folgenden Artikeln besprechen werden, nicht verstehen können.
Obwohl viele Menschen das Überladen für einen Programmierfehler halten, da es den Code ziemlich komplex macht, könnten wir ohne es viele Dinge nicht erstellen oder implementieren. Um zu verstehen, was in diesem Artikel beschrieben wird, müssen wir also alles, was im vorherigen Artikel behandelt wurde, gut verstehen. Andernfalls wird Ihnen das heutige Thema ein Dorn im Auge sein, und es wird fast unmöglich sein, es zu verstehen.
Ohne das in diesem Artikel vermittelte Wissen ist es jedoch fast unmöglich, auf der Suche nach neuen Programmierfunktionen und -mechanismen voranzukommen. Es ist also an der Zeit, sich auf das zu konzentrieren, was wir in diesem Artikel sehen werden, denn wir werden es hier mit etwas zu tun haben, das sehr unterhaltsam, wenn auch sehr komplex ist, je nach der Art der Dinge, die zu einem bestimmten Zeitpunkt implementiert werden.
Template und Typename
Eines der kompliziertesten und schwierigsten Konzepte, das einen unerfahrenen Programmierer irgendwann entmutigen kann, ist die Überlastung. Wie Sie jedoch aus dem vorangegangenen Artikel ersehen können, ist das Überladen nur ein kleiner Teil dessen, was wir implementieren können, wenn die von uns verwendete Sprache uns bestimmte Dinge erlaubt oder uns ein gewisses Maß an Freiheit gibt, wie es der Fall ist, wenn wir anfangen, tiefer mit Überladen zu arbeiten.
Das erste, was man verstehen muss, ist, dass das Überladen, wenn es so durchgeführt wird, wie es im vorherigen Artikel vorgestellt wurde, deutlich zeigt, welche Typen wir verwenden können und wann wir sie verwenden werden, was die Arbeit mit Werten verschiedener Ziffernkapazität in verschiedenen Szenarien erleichtert. Aber hier werden wir etwas viel Komplexeres sehen, was das, was wir im vorherigen Artikel gesehen haben, in etwas außergewöhnlich Didaktisches verwandelt, da alles, was dort beschrieben wurde, auch hier anwendbar ist, aber in einem viel größeren Maßstab.
Einige von Ihnen werden sich vielleicht fragen: Muss ich wirklich lernen, ein solches Werkzeug zu verwenden? Ja, ohne solche Werkzeuge ist vieles von dem, was getan werden kann, völlig unzugänglich, es sei denn, man verwendet sehr viel komplexere und schwer zu erlernende Implementierungsmethoden. Wäre es also nicht besser, diesen Teil zu verschieben und auf ein anderes Mal zu verschieben, um ihn zu erklären? Zum Beispiel nach der Programmierung von Indikatoren oder Expert Advisors. Tatsächlich habe ich darüber nachgedacht, denn alles, was bisher getan und gezeigt wurde, ist etwas, das jeder Anfänger wissen sollte, bevor er versucht, etwas zu programmieren.
Ich sehe jedoch keinen Grund, dieses Thema zu verschieben, und sei es nur, weil ich bereits erklärt habe, wie man einen Expert Advisor von Grund auf implementiert, sowohl für die automatische Programmierung als auch zur Unterstützung bei manuellen Operationen.
Sie können darüber in dem Artikel „Erstellen eines EA, der automatisch funktioniert (Teil 15): Automatisierung (VII)“ lesen, in der in einer kurzen Serie von fünfzehn Artikeln detailliert beschrieben wurde, wie dies zu bewerkstelligen ist. Doch auch nach der Veröffentlichung dieser Artikel habe ich festgestellt, dass viele Menschen elementare Zweifel an einigen Themen haben, während andere sich nicht auf vorgefertigte Programme verlassen wollen. Sie wollen lernen, wie alles funktioniert, um ihre eigenen Lösungen zu entwickeln, die ihren Bedürfnissen entsprechen.
Auch nach Abschluss der Serie „Entwicklung eines Replay-Systems — Marktsimulation (Teil 01): Erste Versuche (I)“ ist mir aufgefallen, dass viele Leute sich gar nicht vorstellen können, dass man so etwas umsetzen kann. Obwohl diese Artikelserie noch nicht vollständig veröffentlicht wurde, wird dies bald geschehen. Und da viele Leute vielleicht einen Teil dieses Codes verbessern oder verstehen wollen, wo ich (obwohl er ausführlich erklärt wurde) nicht auf einzelne Punkte eingegangen bin, können diese Punkte das Ziel derjenigen sein, die mit irgendetwas arbeiten wollen.
Da ich nicht vorhabe, diese Themen weiter zu erörtern (sie sind bereits sehr gut erforscht), habe ich auf Wunsch einiger Leute begonnen zu zeigen, wie man mit neuronalen Netzen in MQL5 arbeitet. Ich habe wieder festgestellt, dass einige nicht in der Lage waren, viel von dem, was umgesetzt wurde, zu verwirklichen. Auch hier macht der Mangel an ausreichenden Kenntnissen und grundlegenden Programmierkonzepten jede Erklärung sehr kompliziert und schwierig für Anfänger. Viele Leute konnten sich nicht vorstellen, dass es möglich ist, ein neuronales Netz in reinem MQL5 zu implementieren.
Für diejenigen, die noch keinen meiner Artikel zu diesem Thema gelesen haben, ist der erste von ihnen „Neuronales Netz in der Praxis: Die Sekante“. Viele Artikel müssen jedoch noch veröffentlicht werden. Aber wenn die Artikel veröffentlicht werden, werden Sie feststellen, dass grundlegende Programmierkenntnisse viel wichtiger sind, als es vielleicht den Anschein hat.
Obwohl ich in dieser Artikelserie bereits komplexere Konzepte erklärt habe, hatte ich dennoch den Wunsch, eine Artikelserie zu implementieren, die sich auf die Grundlagen der Programmierung konzentriert. Die Idee war, alles von den Grundlagen her zu erklären.
Ich habe bereits erklärt, warum (obwohl viele Leute glauben, dass dies für einen Programmieranfänger nicht notwendig ist) die Verfügbarkeit einer gut strukturierten und soliden Grundlage Ihnen hilft, viele andere Codes zu verstehen, selbst wenn Ihr Ziel etwas anderes ist, zum Beispiel zu lernen, wie man einen grundlegenden Expert Advisor oder Indikator verwendet, der Ihnen hilft, besser zu handeln. Wenn das das einzige Ziel ist, ist es besser, einen professionellen Programmierer dafür zu bezahlen, damit Sie Zeit sparen und Kopfschmerzen vermeiden.
Aber um auf unsere Hauptfrage zurückzukommen, ist es sehr wichtig, Folgendes zu verstehen: Alles basiert auf dem, was im vorherigen Artikel gezeigt wurde. Außerdem macht nichts Sinn, wenn man nicht alles vorher verstanden hat.
Lassen Sie uns mit etwas Einfachem beginnen. Und wenn ich „einfach“ sage, meine ich, dass es recht einfach zu verstehen sein sollte, denn trotz der Einfachheit des Verständnisses hat dieses Konzept mehrere Aspekte, die angesichts des dafür erforderlichen Wissens schwierig zu meistern sind. Werfen Sie einen Blick auf den folgenden Code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25.)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(ulong arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(double arg1, double arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2; 20. } 21. //+------------------------------------------------------------------+
Code 01
Dieser Code ist genau derselbe wie derjenige, mit dem der vorherige Artikel begann. Aber warum? Der Grund dafür ist, dass dies eine ideale Option ist, um sich mit Templates vertraut zu machen und zu lernen, was „typename“ ist. In gewissem Sinne wäre es richtiger, entweder den einen oder den anderen Begriff anzugeben, um die Erklärung zu erleichtern. Aber im Moment wird das eine mit dem anderen eng verbunden sein. Und genau das kann dazu führen, dass diejenigen, die gerade erst anfangen zu arbeiten, in völlige Verwirrung geraten.
Um das Thema zunächst zu vereinfachen, werden wir jedoch nicht auf die praktische Bedeutung der einzelnen Begriffe eingehen. Ich möchte, dass Sie einfach zusehen und versuchen, herauszufinden, was vor sich geht. Versuchen Sie nicht zu verstehen, wie es funktioniert oder wie es in anderen Fällen verwendet werden kann. Wenn Sie versuchen, dies selbst zu tun, werden Sie sich in einer Sackgasse wiederfinden. Haben Sie also bitte etwas Geduld, denn wir werden Ihnen im Laufe der Zeit alles erklären, denn was zu tun ist, umfasst viel mehr, als wir in diesem einfachen Artikel sehen werden.
Jetzt möchte ich, dass Sie auf Folgendes achten: DER EINZIGE UNTERSCHIED zwischen der Funktion in Zeile 10 und der Funktion in Zeile 16 ist der erwartete und der zurückgegebene Datentyp. Ansonsten hat sich an dem obigen Code nichts geändert.
Es ist SEHR WICHTIG, dies zu bemerken und zu verstehen, viel wichtiger als alles andere zu verstehen. Wenn Sie das nicht erkennen, ist alles andere bedeutungslos. Code 01 funktioniert, und der Compiler versteht, was erstellt werden muss. Ich denke, jetzt ist alles klar, denn das wurde bereits im vorherigen Artikel erklärt. Nun stellt sich die Frage: Wollen wir den Code 01 in der Form schreiben, in der er vorliegt? Oder gibt es nicht vielmehr eine bessere und einfachere Möglichkeit, denselben Code zu schreiben?
Wenn Sie verstanden haben, was im vorherigen Artikel besprochen wurde, dann wissen Sie, dass wir zusätzliche Funktionen oder Prozeduren erstellen müssen, wenn wir andere als die deklarierten Typen verwenden wollen. Dadurch duplizieren wir den Code und riskieren, seine Verbesserung erheblich zu erschweren, da überladene Funktionen und Prozeduren früher oder später zu gewissen Schwierigkeiten führen. Ich sage dies aufgrund meiner langjährigen Programmiererfahrung. Eine Überlastung führt immer zu langfristigen Problemen.
In diesem Sinne kann man sagen, dass einige Sprachen es ermöglichen, etwas zu erstellen, das einem Template ähnelt, d. h. etwas, das nur an wenigen Stellen geändert werden muss, ohne dass der Code dupliziert werden muss. Theoretisch, denn die Verwendung eines solchen Instruments ist nicht so einfach, wie es scheint. Aber lassen Sie uns mit den Grundlagen beginnen. Abgesehen davon, dass die in den Funktionen in den Zeilen 10 und 16 verwendeten Typen unterschiedlich sind, kann alles andere in ein Template umgewandelt werden. Dies ist der erste Punkt, der zu beachten ist.
Aber trotz alledem hat dieser Code einen Faktor, der alles noch schwieriger macht: Zeile 07. Um diese anfängliche Erklärung nicht zu verkomplizieren, sei daran erinnert, dass in Zeile 06 Ganzzahltypen und in Zeile 07 Fließkommadaten verwendet werden. Ich erlege Ihnen diese Bedingung im Moment auf, aber wir werden später sehen, dass es Möglichkeiten gibt, sie zu ändern. In Ordnung, das ist ein Deal.
Wir werden sehen, wie derselbe Code 01 als Implementierung unter Verwendung einer Funktionsvorlage notiert werden kann. Wir können es unten sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10.0, 25.0)); 08. } 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. T Sum(T arg1, T arg2) 12. { 13. Print(__FUNCTION__, "::", __LINE__); 14. return arg1 + arg2; 15. } 16. //+------------------------------------------------------------------+
Code 02
Jetzt kommen wir zu einem merkwürdigen Teil. Wenn Sie den Code 01 ausführen, erhalten Sie das in der folgenden Abbildung dargestellte Ergebnis.
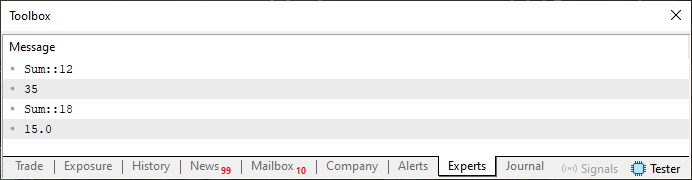
Abbildung 01
Wenn wir jedoch den Code 02 ausführen, sehen wir, was in der folgenden Abbildung dargestellt ist.
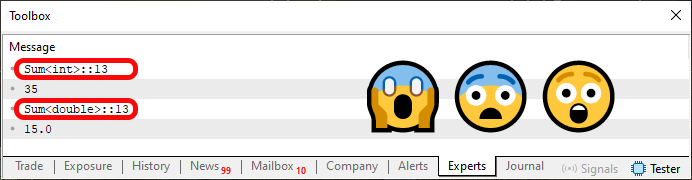
Abbildung 02
Frage: Was ist hier geschehen? Die Antwort ist, dass wir diese beiden Funktionen aus Code 01 in das Template umwandeln, die jetzt in Code 02 gezeigt wird. Die wirklich wichtige Frage ist jedoch, welche Art von Informationen in Abbildung 02 hervorgehoben wird. Und hier wird es noch komplizierter, wenn Sie nicht wissen, was eine Überladung von Funktionen oder Prozeduren ist. Im vorherigen Artikel haben wir nämlich erklärt, wie der Compiler eine Funktion oder Prozedur überladen kann. Hier teilen wir dem Compiler implizit mit, wie er diese Überladung erzeugen soll.
Ich verwende das Wort „implizit“, weil WIR NICHT SAGEN welcher Typ zu verwenden ist. Diese Entscheidung wird vom Compiler getroffen. Daher haben wir in Code 01 den Typ ulong in Zeile 06 verwendet, da die Funktion in Zeile 10 verwendet wird, deren erwarteter Typ ulong-Werte sind. Wenn wir jedoch den Compiler eine Entscheidung treffen lassen, wählt er den Typ int gegenüber allen anderen, und diese Entscheidung ist nicht immer die beste. In einigen Fällen kann dies dazu führen, dass die Ergebnisse von Funktionen oder Verfahren von den erwarteten Ergebnissen abweichen.
Aber wir sollten es nicht überstürzen. Wir fangen gerade erst an, in diesem neuen Bereich zu arbeiten. Es bleibt noch viel abzuwarten, bis wir in den Bereich der Werte vordringen, die anders sind als erwartet.
Jetzt möchte ich, dass Sie Folgendes verstehen. Im Bild 02 hat man zwar den Eindruck, dass nur eine Prozedur oder, wie in diesem Fall, eine Funktion implementiert wird, aber das liegt daran, dass wir uns in beiden Fällen auf dieselbe Zeile beziehen, nämlich auf die Zeile 13, die im Code 02 vorhanden ist. Die in Code 02 verfügbare Funktion Summe ist KEINE FUNKTION, sondern ein Template für die Funktion.
Und was bedeutet das in der Praxis? Das bedeutet, dass der Compiler, sobald er diese Funktion in unserem Code findet, prüft, ob es bereits eine Funktion gibt, die unseren Anforderungen entspricht. Existiert eine solche Funktion nicht, erstellt der Compiler sie unter Verwendung der zwischen den Zeilen 10 und 15 deklarierten Funktionsvorlage. Alles, was zwischen diesen Zeilen steht, wird in irgendeiner Weise dupliziert, aber so angepasst, dass es korrekt verwendet wird, wie es bei der Erstellung des Codes beabsichtigt war.
Jetzt ist es in Mode zu sagen, dass künstliche Intelligenz Code erstellen kann. Was hier gemacht wird, ist sehr ähnlich, aber ohne neuronale Netze oder ähnliches.
Um dies zu verdeutlichen, nehmen Sie eine kleine Änderung an Code 02 vor, um die Funktion Summe mit anderen Datentypen zu verwenden. Sie finden sie weiter unten.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(130, 150)); 07. Print(Sum(130.0, 150.0)); 08. { 09. long v1 = 130, v2 = 150; 10. 11. Print(Sum(v1, v2)); 12. } 13. { 14. uchar v1 = 130, v2 = 150; 15. 16. Print(Sum(v1, v2)); 17. } 18. { 19. float v1 = 130, v2 = 150; 20. 21. Print(Sum(v1, v2)); 22. } 23. } 24. //+------------------------------------------------------------------+ 25. template <typename T> T Sum(T arg1, T arg2) 26. { 27. Print(__FUNCTION__, "::", __LINE__); 28. return arg1 + arg2; 29. } 30. //+------------------------------------------------------------------+
Code 03
Bitte beachten Sie, dass wir sowohl die in Code 02 gezeigte Methode zum Schreiben von Templates als auch die in Code 03 gezeigte Methode verwenden können. In diesem Fall, in Code 03, machen wir alles in einer Zeile, was in echtem Code nicht sehr üblich ist, da die meisten Programmierer diese Form nicht verwenden, was in Zeile 25 von Code 03 vermerkt ist. Die Bedeutung ist jedoch dieselbe wie bei Code 02, nur etwas weniger häufig.
Gut, aber das ist nicht der Punkt. Der Punkt ist, dass Sie beim Ausführen von Code 03 das erhalten, was Sie unten sehen.
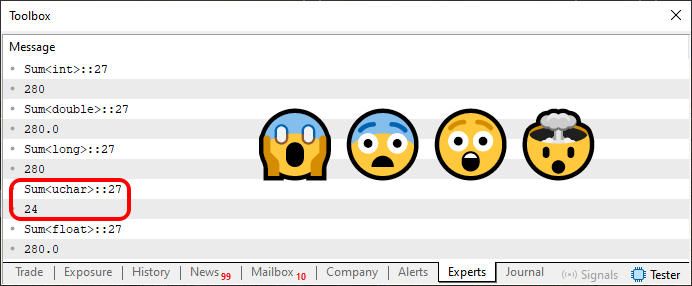
Abbildung 03
Jetzt ist die Situation wirklich komplizierter geworden. „Ich verstehe überhaupt nichts mehr - was für verrückte, sinnlose Worte! Ich kann es mit meinen eigenen Augen sehen, aber ich kann es nicht glauben. Alle Werte sind gleich, außer einem. Das erscheint mir absurd, und warum liefert eine der Summen einen so unterschiedlichen Wert als die anderen?“
Ja, habe ich nicht gesagt, es würde Spaß machen? Obwohl es auf den ersten Blick sehr schwer zu verstehen ist. Lassen Sie uns das klarstellen.
Erinnern Sie sich, als ich sagte, dass der Compiler für jeden Fall den besten Typ sucht? Deshalb werden überladene Funktionen erstellt, damit der Code dem entspricht, was wir gerade brauchen. Bitte beachten Sie Folgendes: Wenn Zeile sechs ausgeführt wird, ist int der beste Typ. Daher wird eine überladene Funktion erstellt, die genau diesen Typ verwendet. Unmittelbar danach haben wir einen Datentyp, der als Fließkomma eingegeben wird. In diesem Fall versteht der Compiler, dass der beste Typ double ist. Aus diesem Grund wird dieser Typ verwendet. In all diesen Fällen verwendet der Compiler eine implizite Deklarationsform auf der Grundlage des am besten implementierten Datenmodells, das als Standardtyp verwendet wird.
Und nun das Interessanteste: Bei der Eingabe der Blöcke zwischen den Zeilen 08 und 12, 13 und 17 sowie des Blocks von Zeile 18 bis 22 verwenden wir lokale Variablen verschiedener Typen. Wenn Sie nicht wissen, wovon ich spreche, empfehle ich Ihnen, die ersten Artikel dieser Reihe zu lesen. Dort erkläre ich, was lokale Variablen sind und wie lange jede von ihnen während der Codeausführung aktiv bleibt. Bitte beachten Sie, dass das Wissen zunimmt. Daher sollten wir nicht zulassen, dass sich das Material anhäuft, bevor wir mit dem Studium und der Anwendung in der Praxis beginnen.
In jedem dieser Blöcke gibt es also Werte, die in der Bitbreite variieren, was zu einem möglichen Bereich führt. So hängen sowohl das Ergebnis der Operation als auch die Art der Daten, die die Funktion verwendet, vom Typ der verwendeten Variablen ab.
Jede der Zeilen, die Sie in Abbildung 03 sehen, gibt also an, welche Art von Daten verwendet wird und in welchem Bereich sich die Werte befinden können. Ich weiß, dass es im Moment keinen Sinn macht. Wir haben dies jedoch bereits besprochen, als wir den Unterschied zwischen Variablen und Konstanten erklärt haben. Gehen Sie zurück und lesen Sie diese Artikel noch einmal: Dieses Wissen wird jetzt sehr wichtig sein.
Der Typ uchar hat einen Bereich von 0 bis 255. Da die Summe der Werte 280 beträgt, entspricht der in Abbildung 03 hervorgehobene Wert 24 genau dem aufgetretenen Überlauf. Da es beim Typ uchar 256 mögliche Elemente gibt, ergeben sich bei Überschreitung dieses Wertes 24 Überlaufelemente. Das heißt, der Zähler wurde auf Null zurückgesetzt und ging weiter zu Element 24. Daher wird das Ergebnis der Summe dieser Wert sein.
Beachten Sie, dass dies nur möglich wurde, weil wir dem Compiler ausdrücklich mitgeteilt haben, dass der verwendete Datentyp uchar sein soll. Wäre ein anderer verwendet worden, hätte der Wert ganz anders ausfallen können.
Da sich diese Codes in der Anlage befinden, sollten Sie versuchen, den Datentyp von uchar in char zu ändern und das Ergebnis zu beobachten. Denken Sie daran, dass der Compiler in diesem Fall eine Warnung ausgeben wird. Dies liegt daran, dass die Werte 130 und 150 außerhalb des Zeichenbereichs liegen. Sie können diese Werte jedoch reduzieren, damit sie in den Bereich passen. Wie wäre es, 90 zu 80 zu addieren und den Datentyp char zu den Bausteinen hinzuzufügen? Ich kann Ihnen versichern, dass das Ergebnis sehr interessant sein wird.
Versuchen wir herauszufinden, was hier vor sich geht
Wie Sie vielleicht bemerkt haben, erspart uns die Verwendung einer Funktions- oder Prozedurvorlage die Erstellung mehrerer überladener Funktionen oder Prozeduren, da die Verantwortung und die Arbeit für deren Erstellung auf den Compiler verlagert wird. Auf diese Weise können wir uns darauf konzentrieren, einen möglichst lesbaren Code zu erstellen. Wenn man jedoch nicht versteht, was vor sich geht, ist es schwierig herauszufinden, wie man diese wertvolle Ressource, nämlich das Template, erweitern kann. Vergessen wir also alles andere und konzentrieren wir uns ausschließlich darauf, zu verstehen, was mit diesem Template geschieht, die wir mit den hier vorgestellten Codes erstellen. Wir werden uns vor allem auf den Code 03 konzentrieren, da er mehr Datentypen verwendet, was ihn leichter verständlich macht.
Werfen wir zunächst einen weiteren Blick auf Bild 03. In diesem Bild ist deutlich zu erkennen, dass auf den Funktionsnamen das Zeichen „kleiner als“, dann der Typname und schließlich das Zeichen „größer als“ folgt. Wir sind speziell daran interessiert, den in Abbildung 03 gezeigten Typ zu identifizieren.
Wenn Sie sich den Code 03 ansehen, werden Sie feststellen, dass es in Zeile 25 KEINE Typenbezeichnung gibt. Allerdings gibt es hier etwas Interessantes: das reservierte Wort „typename“ gefolgt von einem Bezeichner. Der Bezeichner, der in Abbildung 03 zu sehen ist, ähnelt sehr stark der Stelle, an der „typename“ in Code 03 erscheint. Das ist das Geheimnis, könnte man sagen.
Der Bezeichner nach dem reservierten Wort „typename“ ermöglicht es dem Compiler, den Datentyp zu bestimmen, den das Template verwenden wird. Bitte beachten Sie, dass der gleiche Bezeichner die Standarddeklaration ersetzt, die wir bei der Definition des erwarteten Datentyps machen. Programmierer verwenden in der Regel T-Bezeichner, aber wir können jeden Namen verwenden, solange er korrekt definiert ist. Bei der Erstellung der ausführbaren Datei wird dieser Bezeichner durch den Compiler durch den entsprechenden Typ ersetzt.
Dies gibt uns mehr Freiheit bei der Nutzung dieser Art von Ressourcen, da es Möglichkeiten gibt, bestimmte Arten von komplexen Problemen einfach und kostengünstig zu lösen. Darüber werden wir im nächsten Artikel sprechen. Bis jetzt möchte ich Sie nicht mit zu vielen Informationen verwirren. Ich wollte Sie nur darauf aufmerksam machen, dass die Anweisung in Zeile 25 von Code 03 geändert werden kann, um die Dinge für Sie klarer zu machen.
Zum Beispiel können wir die Zeile 25 des Codes 03 durch die unten gezeigte Zeile ersetzen. Aber selbst in diesem Fall versteht der Compiler noch, wie er mit das Template arbeiten kann.
template <typename Unknown> Unknown Sum(Unknown arg1, Unknown arg2)
Abschließende Überlegungen
In diesem Artikel haben wir mit der Betrachtung eines der Konzepte begonnen, das viele Anfänger vermeiden. Das hängt damit zusammen, dass Templates kein einfaches Thema sind, da viele das Grundprinzip, das den Templates zugrunde liegt, nicht verstehen: die Überladung von Funktionen und Prozeduren. Obwohl bisher nur der erste Teil der riesigen Palette von Funktionen, die mit Templates verwendet werden können, erläutert wurde, ist das Verständnis dieses ersten Teils sehr wichtig. Vieles von dem, was in den folgenden Artikeln gezeigt und erklärt wird, folgt aus diesem grundlegenden und ersten Teil.
Ich glaube, dass diejenigen, die gerade erst anfangen, das Programmieren zu lernen, verwirrt sein könnten, wie nützlich Templates sind und wie man diese Art von Ressourcen, die in MQL5 verfügbar sind, richtig nutzt. Aber ich möchte Sie daran erinnern, dass dieses Material nicht schnell aufgenommen werden muss. Nur mit der Zeit und der Praxis werden Sie solche Konzepte, die in der Zukunft angewendet werden sollen, besser verstehen.
Das bedeutet jedoch nicht, dass Sie dort aufhören sollten, das hier Vorgestellte zu praktizieren. Obwohl das Studium der Codes, wie sie in den Anhängen zur Verfügung gestellt werden, wegen ihrer Einfachheit zunächst als Zeitverschwendung erscheinen mag, kann es später viele Stunden sparen, wenn man komplexere Codes zerlegt, die alle diese Ressourcen verwenden. Vergessen Sie nicht:
Wissen sammelt sich mit der Zeit an. Sie entsteht nicht aus dem Nichts und wird nicht von einer Person zur anderen vererbt.
Wir sehen uns im nächsten Artikel, in dem wir uns noch eingehender mit der Verwendung von Templates in ihrer grundlegendsten und einfachsten Form befassen werden.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15658
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.