
Del básico al intermedio: Plantilla y Typename (I)

Introducción
El contenido expuesto aquí tiene un propósito puramente didáctico. En ningún caso debe considerarse una aplicación final, cuyo objetivo no sea el estudio de los conceptos mostrados aquí.
En el artículo anterior, "Del básico al intermedio: Sobrecarga", intenté explicar una de las cosas más complicadas de entender en programación, especialmente cuando estamos comenzando y nos encontramos con algo que, a primera vista, no tiene sentido. Aunque toda la complicación que surge cuando utilizamos sobrecarga, es muy importante entender lo que está ocurriendo. Por esta razón, sin comprender y asimilar realmente ese tipo de conocimiento, tú, querido lector, estarás muy limitado. Y, peor aún, no lograrás entender otras cosas que presentaremos en los próximos artículos.
Aunque muchos consideran la sobrecarga un error de programación, pues vuelve el código bastante complicado, sin ella muchas de las cosas que hacemos o podríamos hacer como programadores no serían posibles de crear o implementar. Por lo tanto, el requisito previo para entender lo que será explicado en este artículo es precisamente entender lo que fue explicado en el artículo anterior. Sin cumplir ese objetivo, el tema tratado aquí se convertirá en una piedra en tu zapato, siendo prácticamente imposible de comprender adecuadamente.
Sin embargo, sin los conceptos y el conocimiento presentados en este artículo, es casi imposible avanzar en busca de nuevas oportunidades y mecanismos de programación. Así que ha llegado el momento de relajarte, dejar de lado las distracciones y concentrarte en lo que veremos en este artículo, ya que aquí trataremos algo muy divertido, aunque puede ser muy complicado, dependiendo del tipo de cosa que se esté implementando en un momento dado.
Plantilla y typename
Uno de los conceptos más complicados, difíciles y que puede acabar desanimando al programador principiante es la sobrecarga. Sin embargo, como se vio en el artículo anterior, la sobrecarga es solo una pequeña muestra de lo que podemos hacer cuando el lenguaje que estamos utilizando nos permite ciertas cosas o nos da cierto grado de libertad, como ocurre al comenzar a trabajar con la sobrecarga de manera más profunda.
Lo primero que tú necesitas entender es que la sobrecarga, cuando se hace de la forma presentada en el artículo anterior, demuestra claramente qué tipos podemos utilizar y cuándo vamos a utilizarlos, siendo más sencillo trabajar con valores de diferentes anchos de bits en distintos escenarios. Pero lo que veremos aquí es algo mucho más complicado, haciendo que lo visto en el artículo anterior sea algo puramente didáctico, ya que todo lo que se presentó allí se aplica aquí, pero en una escala mucho mayor.
Algunos de ustedes pueden estar pensando: ¿realmente necesito aprender a usar este tipo de herramienta que tú nos estás mostrando? Sí, sin tales herramientas, muchas de las cosas que se pueden hacer quedan completamente fuera de alcance, a no ser que utilices métodos mucho más complicados y de implementación difícil de dominar. Entonces, ¿no sería mejor posponer esta parte, dejándola para ser explicada en otro momento? Por ejemplo, después de que ya se haya explicado cómo programar indicadores o un Asesor Experto. En realidad, estuve pensando en eso, ya que todo lo que se ha hecho y mostrado hasta este punto es algo que cualquier principiante debería conocer antes incluso de intentar programar algo.
Sin embargo, no veo motivos para posponer la presentación de este tema propuesto. Incluso porque ya hablé de cómo implementar un Asesor Experto totalmente desde cero, tanto con fines de programación automática como para asistir en operaciones manuales.
Esto puede verse en "Cómo construir un Asesor Experto que opere automáticamente (Parte 15): Automatización (VII), donde muestro en detalle cómo hacerlo en una pequeña serie de quince artículos. No obstante, incluso después de que esos artículos fueran publicados, he notado que muchos tienen dudas básicas sobre ciertos temas, mientras que otros no quieren depender de una programación ya hecha. Ellos quieren aprender cómo funciona todo para crear sus propias soluciones y atender sus necesidades.
Incluso después de finalizada la secuencia sobre "Desarrollo de un sistema de repetición - Simulación de mercado (Parte 01): Primeros experimentos (I)", noté que muchos no tenían idea de que tal cosa era posible de implementar. Aunque esa secuencia de artículos aún no ha sido publicada por completo, esto ocurrirá pronto. Y, como muchos pueden querer mejorar o entender parte de ese código que, aunque fue explicado en detalle, no profundicé en algunos puntos, es precisamente en esos puntos donde puede residir el objetivo de quien desea trabajar con esto o aquello.
Como no pretendo seguir discutiendo esos temas, pues considero que fueron muy bien explorados, comencé a mostrar, a pedido de algunos, cómo trabajar con redes neuronales usando MQL5. Noté nuevamente que algunos no lograban seguir gran parte de lo que se estaba implementando. Otra vez, observé que la falta de conocimiento adecuado y de conceptos básicos de programación volvía cualquier explicación muy complicada y difícil de seguir para los principiantes. Muchos no imaginaban que fuera posible implementar una red neuronal usando MQL5 puro.
Para quien no haya leído ninguno de mis artículos sobre el tema, el primero fue "Red neuronal en la práctica: Recta secante". Es cierto que aún faltan muchos artículos por ser publicados. Pero, a medida que los artículos vayan siendo publicados, tú que los sigas notarás que el conocimiento básico de programación es mucho más importante de lo que podría parecer.
Aunque ya haya explicado conceptos más avanzados en aquella serie de artículos, aun así tuve el deseo de implementar una secuencia de artículos orientados a la base de la programación. Entonces, la idea fue comenzar a explicar las cosas desde lo básico.
Ahora, creo haber explicado el motivo por el cual, aunque muchos lo consideren innecesario para un programador principiante, tener una base bien estructurada y sólida ayuda a entender muchos otros códigos. Aunque tu objetivo sea otro, como por ejemplo, simplemente saber cómo implementar un Asesor Experto básico o un indicador que pueda ayudarte a operar mejor. Si el objetivo es solo ese, quizá sea mejor pagar a un programador profesional para que lo haga por ti, ya que el tiempo necesario y los dolores de cabeza serán mucho menores.
Pero, volviendo a nuestra cuestión principal, el gran problema en lo que será explicado aquí es entender que todo se basa en lo que se vio en el artículo anterior. Y, más aún, sin entender todo lo que fue explicado antes de llegar aquí, nada tendrá sentido.
Así que, vamos a empezar con algo simple. Y, cuando digo simple, quiero decir que debe ser bastante simple, pues, aunque sea fácil de entender, el concepto tiene varios aspectos difíciles de asimilar, dada la cantidad de conocimiento requerido para ello. Así que, mira el siguiente código.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25.)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(ulong arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(double arg1, double arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2; 20. } 21. //+------------------------------------------------------------------+
Código 01
Este código es EXACTAMENTE el mismo que abrió el artículo anterior. Exactamente. ¿Pero por qué? La razón es que es perfecto para comenzar a entender qué es una plantilla y qué es typename. De cierta manera, lo correcto sería mostrar uno u otro término, para facilitar la explicación. Pero, aquí y en este momento, un término estará íntimamente ligado al otro. Y eso es lo que puede acabar volviendo todo muy confuso para quien está comenzando.
No obstante, para simplificar inicialmente cualquier cosa de la que vayamos a hablar, no entraremos en detalles sobre el significado práctico de cada término. Quiero que tú, querido lector, simplemente observes y procures comprender lo que se está haciendo. No intentes entender cómo funciona ni cómo puedes utilizarlo en más casos. Si intentas hacerlo, quedarás completamente perdido. Así que te pido que tengas calma y paciencia, pues explicaremos las cosas con el tiempo, ya que lo que se va a hacer implica mucho más de lo que veremos aquí en este simple artículo.
Ahora, quiero que prestes atención al siguiente hecho: LA ÚNICA DIFERENCIA entre la función de la línea diez y la de la línea dieciséis es el tipo de dato esperado y de retorno. Nada más es diferente en este código mostrado arriba.
Observar y entender esto es EXTREMADAMENTE IMPORTANTE. Comprenderlo es mucho más importante que entender cualquier otra cosa. Si no logras ver lo que acabo de decir, todo lo demás no tendrá ningún sentido. Bien, entonces este código 01 funciona y el compilador consigue comprender lo que necesita ser creado. Creo que esto quedó claro, ya que fue explicado en el artículo anterior. Ahora viene una pregunta: ¿necesitamos escribir este código 01 de la forma en que se encuentra? O, mejor dicho, ¿no existe una forma más adecuada y sencilla de escribir este mismo código?
Si entendiste lo que fue explicado en el artículo anterior, sabes que, si necesitamos utilizar tipos diferentes de los declarados, tendremos que crear funciones o procedimientos extra. Y, al hacer eso, duplicamos el código, corriendo el riesgo de volverlo mucho más complicado de mejorar, ya que funciones y procedimientos sobrecargados, tarde o temprano, acaban generando alguna dificultad. Lo digo por experiencia de años programando. Créeme, la sobrecarga siempre trae problemas a largo plazo.
Bien, pensando por este lado, algunos lenguajes nos permiten crear algo que sería como una plantilla, es decir, algo que necesita ser modificado en apenas algunos puntos, sin necesidad de duplicar su código. Esto, en teoría, ya que la utilización de tal herramienta no es tan simple como se imagina. Pero comencemos con lo básico. Bien, entonces, quitando el hecho de que los tipos utilizados en las funciones de las líneas diez y dieciséis son diferentes, todo lo demás puede ser transformado en una plantilla. Este es el primer punto que tú necesitas entender.
Bien, a pesar de todo, este código tiene un pequeño agravante: la línea siete. Para no complicar esta explicación inicial, vamos a considerar que la línea seis utiliza tipos enteros y que la línea siete utiliza datos del tipo punto flotante. Estoy imponiendo esta condición en este momento, pero más adelante veremos que existen formas de cambiar esto. Ahora que estamos de acuerdo,
veremos cómo ese mismo código 01 sería escrito en una forma de implementación usando una plantilla de función. Esto puede verse justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10.0, 25.0)); 08. } 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. T Sum(T arg1, T arg2) 12. { 13. Print(__FUNCTION__, "::", __LINE__); 14. return arg1 + arg2; 15. } 16. //+------------------------------------------------------------------+
Código 02
Ahora viene la parte extraña. Al ejecutar el código 01, obtendrás el resultado presentado en la imagen de abajo.
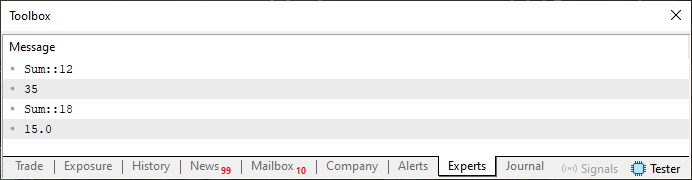
Imagen 01
Sin embargo, al ejecutar el código 02, verás lo que se muestra en la imagen justo a continuación.
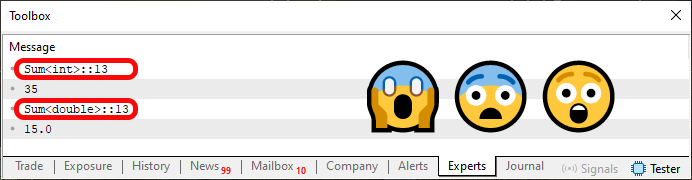
Imagen 02
Pregunta: ¿qué ocurrió aquí? La respuesta es que transformamos aquellas dos funciones vistas en el código 01 en una plantilla que ahora se ve en el código 02. Pero la cuestión que realmente marca toda la diferencia es entender qué son esas informaciones destacadas en la imagen 02. Y es aquí donde la cosa se complica si tú no entendiste qué es la sobrecarga de funciones o procedimientos. Esto se debe a que, en el artículo anterior, expliqué cómo el compilador podía hacer para que una función o procedimiento pudiera ser sobrecargado. Aquí le estamos diciendo, de manera implícita, al compilador cómo deberá crear esta sobrecarga.
Uso “implícita” porque NO ESTAMOS DICIENDO qué tipo usar. Esa decisión será tomada por el compilador. Por eso, en el código 01, utilizábamos el tipo ulong en lo que sería la llamada de la línea seis, ya que esta estaría utilizando la función de la línea diez, cuyo tipo esperado son valores del tipo ulong. Sin embargo, cuando dejamos que el compilador decida, eligió el tipo int, y no otro tipo cualquiera. Esa decisión no siempre es la mejor. En algunos casos, puede hacer que los resultados de funciones o procedimientos sean diferentes a lo esperado.
Pero vamos con calma. Estamos apenas comenzando en esta nueva área. Hay muchas cosas por ver antes de que entremos en este campo de valores diferentes a los esperados.
Ahora, lo que necesito que tú entiendas, mi querido lector, es lo siguiente. A pesar de que, en esta imagen 02, tengamos la clara sensación de que se está implementando solo un procedimiento —o función, en este caso—, esto ocurre porque, en ambos casos, nos estamos refiriendo a la misma línea, es decir, la línea 13 presente en el código 02. La función Sum, presente en el código 02, NO ES UNA FUNCIÓN, sino un modelo de función.
¿Y qué significa esto en la práctica? Significa que, en el momento en que el compilador encuentre esta función siendo utilizada en nuestro código, buscará si ya existe una que satisfaga nuestra necesidad en ese momento. Si no existe, el compilador creará una que cumpla con esa necesidad utilizando la plantilla de función declarada entre las líneas 10 y 15. Todo lo que exista entre esas líneas será duplicado de alguna manera, pero ajustado de modo que sea utilizado adecuadamente, como se espera para la creación del código.
Actualmente, está de moda decir que una inteligencia artificial puede crear un código. Lo que se está haciendo aquí sería algo muy similar, pero sin utilizar ninguna red neuronal ni nada por el estilo.
Para intentar dejar esto más claro, vamos a hacer un pequeño cambio en el código 02 para usar la función Sum con otros tipos de datos. Esto se ve justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(130, 150)); 07. Print(Sum(130.0, 150.0)); 08. { 09. long v1 = 130, v2 = 150; 10. 11. Print(Sum(v1, v2)); 12. } 13. { 14. uchar v1 = 130, v2 = 150; 15. 16. Print(Sum(v1, v2)); 17. } 18. { 19. float v1 = 130, v2 = 150; 20. 21. Print(Sum(v1, v2)); 22. } 23. } 24. //+------------------------------------------------------------------+ 25. template <typename T> T Sum(T arg1, T arg2) 26. { 27. Print(__FUNCTION__, "::", __LINE__); 28. return arg1 + arg2; 29. } 30. //+------------------------------------------------------------------+
Código 03
Observa que podemos utilizar tanto la forma de escribir la plantilla mostrada en el código 02 como la mostrada en el código 03. En este caso del código 03, estamos haciendo todo en una única línea, lo cual no es muy común en códigos reales, ya que la mayoría de los programadores no utiliza esta forma, que está siendo escrita en la línea 25 del código 03. Sin embargo, el significado es el mismo que se puede observar en el código 02, solo que es algo menos común.
Bien, pero ese no es el punto aquí. El punto es que, al ser ejecutado, este código 03 producirá lo que se ve justo abajo.
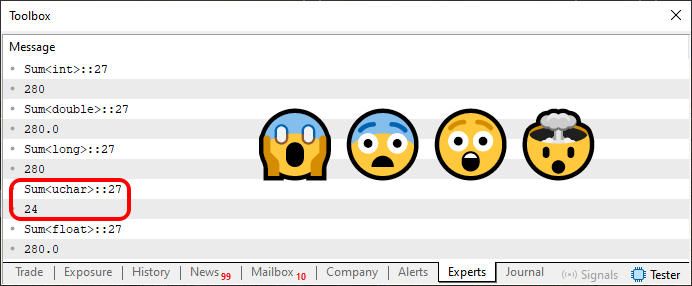
Imagen 03
Ahora sí, la situación se complicó de verdad. Definitivamente, ya no estoy logrando entender nada. ¡Qué cosa más loca y sin sentido! Lo estoy viendo, pero no creo en lo que veo. Todos los valores son iguales, menos uno. Esto me parece absurdo. ¿Podrías ayudarme a entender mejor esto? ¿Y por qué una de las sumas devolvió un valor tan diferente de los demás?
Sí, mi querido lector. ¿No dije que este tipo de cosa sería divertido? A pesar de ser algo muy complicado de entender de golpe. Pues bien, vamos a entender lo que está ocurriendo aquí.
¿Recuerdas que hablé de que el compilador busca cuál es el mejor tipo que debe ser utilizado para cada caso? Así, él crea las funciones sobrecargadas de modo que el código se adecúe a lo que necesitamos en ese momento. Pues bien, observa lo siguiente: cuando la línea seis es ejecutada, el mejor tipo es el int. Por eso, se crea una función sobrecargada utilizando exactamente ese tipo. Justo después, tenemos un tipo de dato que entra como punto flotante. En este caso, el compilador entiende que el mejor tipo es el double. Por eso, este tipo es utilizado. En todos estos casos, el compilador está utilizando la forma implícita de declaración, basándose en el mejor modelo de dato implementado para ser utilizado como tipo predeterminado.
Ahora viene la parte interesante. Al entrar en los bloques entre las líneas 08 y 12, 13 y 17, y el bloque de la línea 18 a la 22, estamos utilizando variables locales de tipos distintos. Si no sabes de qué estoy hablando, te recomiendo leer los primeros artículos de esta serie. Allí explico exactamente qué son las variables locales y durante cuánto tiempo cada variable permanecerá activa durante la ejecución de tu código. Nota que el conocimiento se acumula. Por esta razón, no es bueno dejar que las cosas se acumulen antes de comenzar a estudiar el tema y poner en práctica lo que se está mostrando.
Pues bien. En cada uno de esos bloques, tenemos valores que cambian en términos de ancho de bits, teniendo como consecuencia un rango posible. Así, tanto el resultado de la operación como el tipo de dato que deberá ser utilizado por la función dependen del tipo de variable que estamos utilizando.
De esta forma, cada una de las líneas que puedes observar en la imagen 03 indica qué tipo de datos está siendo utilizado y nos dice cuál es el rango posible en que los valores podrán estar contenidos. Sé que esto no tiene sentido ahora. Sin embargo, ya hablamos de esto cuando expliqué la diferencia entre variables y constantes. Vuelve y repasa esos artículos, pues ahora ese conocimiento será importante.
El tipo uchar tiene un rango que va de 0 a 255. Como la suma de los valores es igual a 280, el valor 24, destacado en la imagen 03, corresponde exactamente al desbordamiento que ocurrió. Como hay 256 elementos posibles de ser representados dentro de un tipo uchar, al superar ese valor, tenemos 24 elementos de desbordamiento. Es decir, la cuenta se reinició en cero y fue hasta el elemento 24. Por eso, el resultado de la suma es este valor.
Nota que esto solo fue posible porque especificamos explícitamente al compilador que el tipo de dato a ser utilizado debería ser uchar. Si se utilizara otro tipo, el valor podría ser totalmente diferente.
Como estos códigos estarán en el anexo, intenta cambiar ese tipo de dato de uchar a char y observa el resultado presentado. Recuerda que, en este caso, el compilador emitirá una advertencia. Esto ocurre porque los valores 130 y 150 están fuera del límite de lo que sería el intervalo de valores char. Sin embargo, puedes reducir esos valores para que encajen dentro del intervalo. ¿Qué tal sumar 90 con 80 y añadir el tipo de dato char a los bloques de construcción? Te aseguro que encontrarás el resultado bastante interesante.
Entender lo que está ocurriendo aquí
Como tú pudiste notar, el uso de una plantilla de función o procedimiento nos ahorra el trabajo de crear diversas funciones o procedimientos sobrecargados, transfiriendo la responsabilidad y el trabajo de hacerlo al compilador. Así, podemos centrarnos en construir un código lo más legible posible. Sin embargo, sin entender lo que realmente está ocurriendo aquí, resulta un poco complicado comprender cómo expandir este recurso tan valioso que es la plantilla. Entonces, mi querido lector, olvidemos todo lo demás y procuremos centrarnos única y exclusivamente en el hecho de intentar comprender lo que está ocurriendo con esta plantilla que estamos creando en estos códigos presentados aquí. Básicamente, vamos a enfocarnos en el código 03, pues en él hay más tipos de datos siendo utilizados, lo que lo hace más sencillo de entender.
Para empezar, echemos un nuevo vistazo a la imagen 03. En ella, es posible observar claramente que el nombre de la función va seguido por un símbolo de menor, luego por el nombre de un tipo y, finalmente, por un símbolo de mayor. La parte que nos interesa es precisamente la identificación del tipo mostrado en la imagen 03.
Si tú observas el código 03, notarás que NO HAY identificación de tipo en la línea 25. Sin embargo, hay algo curioso allí: la palabra reservada "typename", seguida de un identificador. El identificador que vemos en la imagen 03 se parece mucho a la región donde typename aparece en el código 03. Y es aquí donde está el secreto, por así decirlo.
El identificador que sigue a la palabra reservada typename crea una forma de permitir que el compilador defina el tipo de dato que será utilizado por la plantilla. Observa que este mismo identificador sustituye la declaración estándar que haríamos al identificar el tipo de dato esperado. Normalmente, los programadores utilizan el identificador T, pero podemos usar cualquier nombre que deseemos, siempre que esté correctamente definido. En el momento en que se cree el ejecutable, este identificador será sustituido por el compilador por el tipo adecuado.
Esto permite que tengamos mucha libertad para usar este tipo de recurso, ya que existen maneras de utilizarlo para lidiar con ciertos tipos de problemas complicados de manera sencilla y poco costosa. Esto se verá en el próximo artículo. Por ahora, no quiero confundirte, querido lector, con una avalancha de información. Solo quería llamar tu atención al hecho de que esta declaración que vemos en la línea 25 del código 03 puede ser modificada para hacer las cosas más claras para ti.
Por ejemplo, podemos modificar la línea 25 del código 03 por la línea mostrada justo abajo. Aun así, el compilador seguiría entendiendo cómo manejar una plantilla.
template <typename Unknown> Unknown Sum(Unknown arg1, Unknown arg2)
Consideraciones finales
Aquí, en este artículo, comenzamos a tratar uno de los conceptos que muchos principiantes evitan. Esto se debe a que las plantillas no son un tema sencillo de entender y utilizar, ya que muchos no comprenden el principio básico detrás de lo que sería una plantilla: la sobrecarga de funciones y procedimientos. Aunque, en este momento, solo se haya explicado la primera parte de una enorme serie de posibilidades que podemos utilizar con el uso de plantillas, entender esta primera parte es fundamental. Esto se debe a que mucho de lo que será visto y explicado en los próximos artículos deriva precisamente de esta parte básica e inicial.
Creo que quienes tienen menos experiencia o que estén comenzando a estudiar programación pueden estar confundidos sobre la utilidad de las plantillas y sobre cómo explorar adecuadamente este tipo de recurso presente en MQL5. Pero, quiero recordarte, querido lector, que este material no necesita ser asimilado rápidamente. En realidad, solo el tiempo y la práctica te ayudarán a comprender mejor este tipo de concepto que será aplicado de aquí en adelante.
No obstante, esto no significa que debas dejar de estudiar y practicar lo que se está presentando aquí. Estudiar códigos como los que están disponibles en los anexos, aunque parezca una pérdida de tiempo al principio debido a su simplicidad, puede ahorrarte muchas horas después, al intentar entender códigos más elaborados que harán uso de todos estos recursos. Recuerda:
El conocimiento se acumula con el tiempo. No surge de la nada ni puede transferirse por ósmosis entre individuos.
Entonces, nos vemos en el próximo artículo, donde profundizaremos aún más en la cuestión del uso de plantillas en su forma más básica y simple.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15658
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso