
PythonとMQL5でロボットを開発する(第2回):モデルの選択、作成、訓練、Pythonカスタムテスター

前回の記事の簡単な要約
前回の記事では、機械学習について簡単に説明し、データ拡張をおこなって将来のモデルのための特徴量を開発し、その中から最適なものを選び出しました。次のステップとして、これらの特徴量から学習して取引をおこなう(うまくいけば成功する)実用的な機械学習モデルを作成します。また、モデルのパフォーマンスとテスト結果の可視化を向上させるため、カスタムPythonテスターを構築します。テストグラフの見栄えやモデルの安定性を向上させるために、過程でいくつかの古典的な特徴量も取り入れます。
最終的な目標は、価格予測と取引に役立つ、機能的で最大限の利益を生み出すモデルを作成することです。すべてのコードはPythonで記述し、MQL5ライブラリも使用します。
Pythonのバージョンと必要なモジュール
作業ではPythonバージョン3.10.10を使用しました。 以下に添付されているコードには、データの前処理、特徴量の抽出、機械学習モデルの訓練のためのいくつかの関数が含まれています。具体的には、次のものが含まれます。
- sklearnライブラリのガウス混合モデル(GMM)を使用した特徴量クラスタリング関数
- sklearnライブラリの再帰的特徴量除去と交差検証(RFECV: Recursive Feature Elimination with Cross-Validation)を使用した特徴量抽出関数
- XGBoost分類器を訓練するための関数
コードを実行するには、次のPythonモジュールをインストールする必要があります。
- pandas
- numpy
- sklearn
- xgboost
- matplotlib
- seaborn
- MetaTrader 5
- tqdm
これらは、Pythonのパッケージインストールユーティリティである「pip」を使ってインストールできます。以下は、必要なモジュールをすべてインストールするコマンドの例です。
pip install pandas numpy sklearn xgboost matplotlib seaborn tqdm MetaTrader5
さて、始めましょう。
分類か回帰か?
これは、データ予測における永遠の疑問の1つです。分類は、明確な「はい」または「いいえ」の回答が必要な二値分類問題に適しています。また、多クラス分類もあり、これはモデルのパフォーマンスを大幅に向上させる可能性があるため、今後の連載記事で取り上げる予定です。
一方、回帰は価格系列を含む連続的なデータにおいて、特定の将来の値を予測するのに適しています。しかし、回帰は便利ではあるものの、ラベル付けが難しいトピックであることも事実です。なぜなら、資産の将来価格を予測する以外にできることがほとんどないためです。
個人的には、分類の方がデータラベル付けが簡単であるため好んでいます。多くのケースで「はい/いいえ」の条件に当てはめることができ、さらに多クラス分類は、Smart Moneyのような複雑な手動取引システムに適用可能です。本連載の前回の記事で既にデータラベル付けのコードを見てきましたが、これは明らかに二値分類に適しています。したがって、この特定のモデル構造を採用することにしました。
あとはモデルそのものを決めるだけです。
分類モデルの選択
選択した特徴量を使用して、データに最適な分類モデルを選定する必要があります。この選択は、特徴量の数、データの型、およびクラスの数によって異なります。
人気のあるモデルには、二値分類に適したロジスティック回帰、高次元および非線形性に強いランダムフォレスト、複雑な問題に対応可能なニューラルネットワークなどがあります。選択肢は非常に多岐にわたりますが、いろいろ試した結果、現在の状況ではブースティングおよびそれに基づくモデルが最も効果的だという結論に至りました。
最先端のXGBoostモデル(正規化、並列処理、そして多数の設定を用いた決定木でのブースティング)を採用することに決めました。XGBoostは、その高い精度によりデータサイエンスのコンテストでしばしば優勝しており、この点がモデル選定の主な基準となりました。
分類モデルコードの生成
このコードでは、最先端のXGBoostモデル(決定木に対する勾配ブースティング)を使用しています。XGBoostの特別な特徴は、最適化に2次導関数を使用することです。これにより、他のモデルと比較して効率性と精度が向上します。
train_xgboost_classifier関数は、データとブースティングラウンドの数を受け取り、データを特徴量(x)とラベル(y)に分割します。その後、ハイパーパラメータ調整を行い、XGBClassifierモデルを作成し、fit()メソッドを使用して訓練を行います。
データは訓練用とテスト用に分割され、関数を使用して訓練データでモデルが訓練されます。残りのデータでモデルをテストし、予測精度を計算します。
XGBoostの主な利点は、勾配ブースティングを用いて複数のモデルを1つの高精度なモデルに統合し、さらに効率性を高めるために2次導関数を最適化する点です。
OpenMPランタイムライブラリを使用するには、これもインストールする必要があります。Windows環境では、Pythonのバージョンに対応するMicrosoft Visual C++再頒布可能パッケージをダウンロードする必要があります。
コード自体に移りましょう。コードの冒頭で、次の方法でxgboostライブラリをインポートします。
import xgboost as xgb 以下は残りのコードです。
import xgboost as xgb def train_xgboost_classifier(data, num_boost_rounds=500): # Check if data is not empty if data.empty: raise ValueError("Data should not be empty") # Check if all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check if all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create an XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Test the model on all data train_data = raw_data[raw_data.index <= FORWARD] # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate prediction accuracy accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
モデルを訓練し、精度が52%であることを確認してみましょう。
収益性の高いラベルの分類精度は現在53%です。ここで言う「収益性の高いラベル」とは、価格がテイクプロフィット(200ピップ)を超えて変化し、テールがストップ(100ピップ)に触れていない状況を予測することを指しています。実際には、プロフィットファクターは約3となり、これは収益性の高い取引として十分な値です。次のステップとして、Pythonでカスタムテスターを作成し、モデルの収益性をUSD(ポイントではなく)で分析することが重要です。この分析により、モデルがマークアップを考慮して利益を上げているのか、それとも資金を浪費しているのかを確認することができます。
Pythonでカスタムテスターの機能を実装する
def test_model(model, X_test, y_test, markup, initial_balance=10000.0, point_cost=0.00001): balance = initial_balance trades = 0 profits = [] # Test the model on the test data predicted_labels = model.predict(X_test) for i in range(len(predicted_labels) - 48): if predicted_labels[i] == 1: # Open a long position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price > entry_price + markup: # Close the long position with profit profit = (exit_price - entry_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the long position with loss loss = (entry_price - exit_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) elif predicted_labels[i] == 0: # Open a short position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price < entry_price - markup: # Close the short position with profit profit = (entry_price - exit_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the short position with loss loss = (exit_price - entry_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) # Calculate the cumulative profit or loss total_profit = balance - initial_balance # Plot the balance change over the number of trades plt.plot(range(trades), [balance + sum(profits[:i]) for i in range(trades)]) plt.title('Balance Change') plt.xlabel('Trades') plt.ylabel('Balance ($)') plt.xticks(range(0, len(X_test), int(len(X_test)/10)), X_test.index[::int(len(X_test)/10)].strftime('%Y-%m-%d')) # Add dates to the x-axis plt.axvline(FORWARD, color='r', linestyle='--') # Add a vertical line for the FORWARD date plt.show() # Print the results print(f"Cumulative profit or loss: {total_profit:.2f} $") print(f"Number of trades: {trades}") # Get test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] # Test the model with markup and target labels initial_balance = 10000.0 markup = 0.00001 test_model(xgb_clf, X_test, y_test, markup, initial_balance)
このコードは、テストデータで機械学習モデルをテストし、マークアップ(スプレッドの損失やさまざまな種類の手数料を含む)を考慮して収益性を分析する関数を作成します。スワップは動的であり、主要レートに依存するため、考慮されません。マークアップに数ピップを追加するだけで、スワップを考慮できます。
この関数は、モデル、テストデータ、マークアップ、初期残高を受け取ります。取引は、モデル予測を使用してシミュレートされます。ロングは1、ショートは0です。利益がマークアップを超えると、ポジションはクローズされ、利益が残高に追加されます。
各ポジションの取引と損益が保存され、バランスチャートが作成されます。累計総損益が計算されます。
最後に、テストデータを取得し、不要な列を削除します。訓練されたxgb_clfモデルは、指定されたマークアップと初期残高でテストされます。テストしてみましょう。
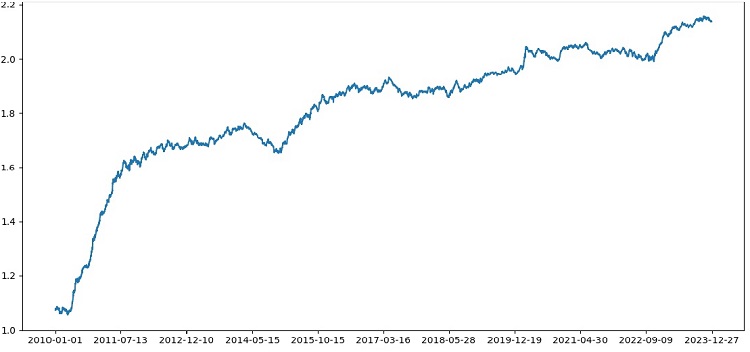
テスターは全体的に正常に動作し、非常に美しい収益性グラフが表示されます。これは、マークアップとラベルを考慮して機械学習取引モデルの収益性を分析するためのカスタムテスターです。
モデルに交差検証を実装する
機械学習モデルの品質をより確実に評価するには、交差検証を使用する必要があります。交差検証により、複数のデータサブセットでモデルを評価できるため、過剰適合を回避し、より客観的な評価をおこなうことができます。
今回のケースでは、5分割交差検証を使用してXGBoostモデルを評価します。これをおこなうには、sklearnライブラリのcross_val_score関数を使用します。
train_xgboost_classifier関数のコードを次のように変更してみましょう。
def train_xgboost_classifier(data, num_boost_rounds=500): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data using cross-validation scores = cross_val_score(clf, X, y, cv=5) # Calculate the mean accuracy of the predictions accuracy = scores.mean() print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Train the model on the data without cross-validation clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Accuracy: {accuracy:.2f}")
モデルを訓練する際、train_xgboost_classifier関数は5分割交差検証をおこない、平均予測精度を出力します。訓練には引き続きFORWARD日付までのサンプルが含まれます。訓練には、FORWARDの日付までのサンプルも含まれます。
交差検証は、モデルを評価するためだけに使用され、訓練には使用されません。訓練は、交差検証なしでFORWARD日付までのすべてのデータに対して実行されます。
交差検証により、モデルの品質をより信頼性高く客観的に評価できるようになり、理論的には新しい価格データに対する堅牢性が向上します。それとも違うのでしょうか。テスターがどのように機能するか確認してみましょう。
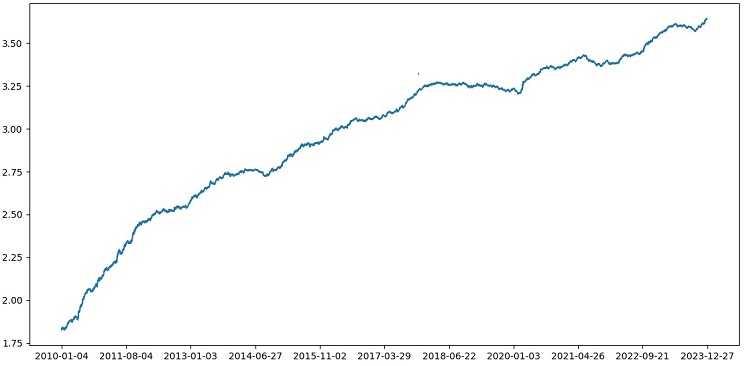
1990年から2024年までのデータでXGBoostを使用してXGBoostをテストしたところ、2010年以降のテストで56%の精度が得られました。モデルは最初の試行で新しいデータに対して優れた堅牢性を示しました。精度もかなり向上しており、これは朗報です。
グリッド上でのモデルのハイパーパラメータの最適化
ハイパーパラメータの最適化は、機械学習モデルを作成してその精度とパフォーマンスを最大化するための重要なステップです。これはMQL5 EAの最適化に似ていますが、EAの代わりに機械学習モデルがあると想像してください。グリッド検索を使用して、最高のパフォーマンスを発揮するパラメータを見つけます。
Scikit-learnを使用してグリッドベースのXGBoostハイパーパラメータの最適化を見てみましょう。
Scikit-learnのGridSearchCVを使用して、グリッドのすべてのハイパーパラメータセットにわたってモデルを相互検証します。交差検証で平均精度が最も高いセットが選択されます。
以下が最適化コードです。
from sklearn.model_selection import GridSearchCV
# Define the grid of hyperparameters
param_grid = {
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.1, 0.3, 0.5],
'n_estimators': [100, 500, 1000]
}
# Create XGBoost model
clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1)
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best hyperparameters:", grid_search.best_params_)
# Print the mean accuracy of the predictions on cross-validation for the best hyperparameters
print("Mean prediction accuracy on cross-validation:", grid_search.best_score_)
ここでは、ハイパーパラメータのグリッドparam_gridを定義し、XGBoostのclfモデルを作成した後、GridSearchCVメソッドを使用してグリッド上で最適なハイパーパラメータを探索します。その後、最適なハイパーパラメータgrid_search.best_params_と、平均交差検証予測精度grid_search.best_score_を出力します。
このコードでは、交差検証を使ってハイパーパラメータを最適化しており、これにより、モデルの品質についてより信頼性が高く客観的な評価が得られます。
コードを実行すると、XGBoostモデルに最適なハイパーパラメータと交差検証での平均予測精度が得られます。その後、最適なハイパーパラメータを使用してすべてのデータでモデルを訓練し、新しいデータでテストできます。
したがって、グリッド上でモデルのハイパーパラメータを最適化することは、機械学習モデルを作成する際に非常に重要なプロセスです。Scikit-learnライブラリのGridSearchCVメソッドを利用することで、このプロセスを自動化し、特定のモデルとデータに最適なハイパーパラメータを簡単に見つけることができます。
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 5, 7, 10], 'learning_rate': [0.05, 0.1, 0.2, 0.3, 0.5], 'n_estimators': [50, 100, 600, 1200, 2000] } # Train the model on the data using cross-validation and grid search grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Return the trained model with the best hyperparameters return grid_search.best_estimator_
モデルアンサンブル
モデルをさらに強化するための次のステップに進みましょう。モデルアンサンブルは、複数のモデルを組み合わせることで予測精度を向上させる、機械学習における非常に強力なアプローチです。一般的な手法には、バギング(異なるサブサンプルで複数のモデルを訓練する方法)や、ブースティング(モデルを順次訓練し、前のモデルの誤差を修正していく方法)があります。
今回のタスクでは、バギングとブースティングを組み合わせたXGBoostアンサンブルを使用します。異なるサブサンプルで訓練された複数のXGBoostモデルを作成し、それらの予測を組み合わせます。また、各モデルのハイパーパラメータは、GridSearchCVを使って最適化します。
アンサンブルの利点は、予測精度の向上、分散の低減、そして全体的なモデルの品質向上です。
最終的なモデル訓練関数では、交差検証、アンサンブル、グリッドによるバギングのハイパーパラメータ選択を活用して、最適なモデルを構築します。
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Missing required columns in data: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 7, 12], 'learning_rate': [0.1, 0.3, 0.5], 'n_estimators': [100, 600, 1200] } # Train the model on the data using cross-validation and hyperparameter tuning grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean accuracy on cross-validation: {accuracy:.2f}") # Return the trained model return grid_search.best_estimator_ labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Test data test_data = raw_data[raw_data.index <= EXAMWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
バギングを通じてモデルアンサンブルを実装し、テストを実行して次のテスト結果を取得します。
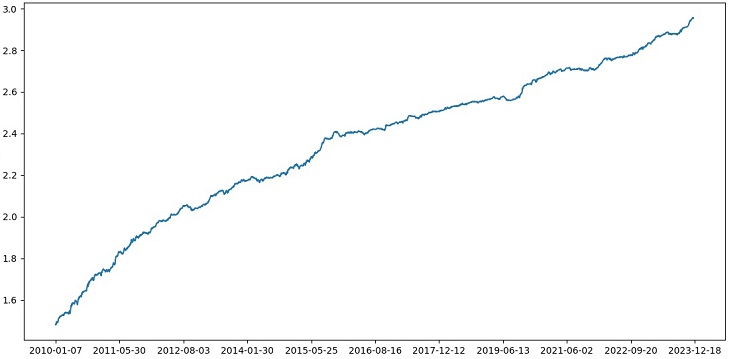
リスクと報酬の比率が1:8の取引を分類する精度が73%に向上しました。つまり、アンサンブルとグリッド検索を用いることで、以前のコードバージョンと比較して分類精度が大幅に向上しています。これは非常に優れた成果であり、フォワードセクションのモデルパフォーマンスに関する以前のグラフからも、コードが進化するにつれてモデルがどれほど強化されたかを明確に理解できます。
テストサンプルの実装とモデルの頑健性のテスト
現在、EXAMWARDの日付以降のデータをテストに使用しています。これにより、モデルの訓練やテストに使われていない完全に新しいデータを使って、モデルのパフォーマンスを検証できます。この方法により、実際の状況でモデルがどのように機能するかを客観的に評価することが可能です。
テストサンプルでのテストは、機械学習モデルの検証において非常に重要なステップです。これにより、モデルが新しいデータに対して適切に機能しているかどうかを確認し、実際のパフォーマンスを把握できます。この過程では、サンプルサイズを正確に決定し、そのサンプルが代表的であることを確認することが重要です。
今回の場合、EXAMWARD後のデータを使用して、訓練やテストに含まれない未知のデータでモデルを検証しています。これにより、モデルの効率性や実際の使用における準備状況を客観的に評価することができます。
2000年から2010年までのデータで訓練をおこない、2010年から2019年のデータでテストを実施しました。その後、2019年以降のデータを使って再度テストをおこないました。テストにおいては、未知の将来における取引をシミュレートしています。
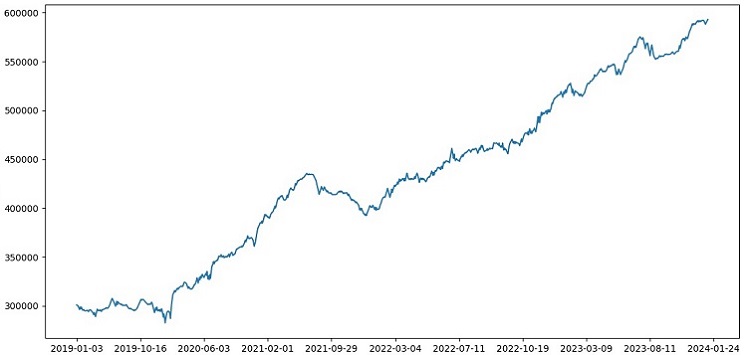
全体的に、すべて順調に進んでいます。テストの精度は60%に低下しましたが、重要なのは、モデルが収益性が高く、非常に堅牢であると同時に、大きなドローダウンが発生していないことです。モデルがリスク/報酬の概念を学習し、リスクが低く、潜在的な利益が高い状況(リスクと報酬の比率1:8)を予測している点は喜ばしい結果です。
結論
これで、Pythonで自動売買ロボットを作成する連載の第2回目の記事が終了しました。現時点では、データの操作、特徴量の生成・選択、モデルの選定・訓練といった課題を解決することができました。また、モデルをテストするためのカスタムテスターも実装し、すべてが順調に機能しているようです。ちなみに、最もシンプルな特徴量を含む他の特徴量も試してデータを単純化してみましたが、うまくいきませんでした。これらの特性を持つモデルは、テスター上で口座を枯渇させる結果となりました。この経験を通じて、特徴量とデータの重要性を再確認することができました。優れたモデルを作成し、さまざまな改善や手法を適用できても、特徴量が効果を発揮しない場合、未知のデータで資金を浪費してしまいます。逆に、優れた特徴量があれば、シンプルなモデルでも安定した結果を得ることができます。
さらなる発展
今後、利便性をさらに高めるために、MetaTrader 5端末上でオンライン取引が可能なカスタムバージョンを作成し、Python経由で直接取引できるようにする予定です。Python専用のバージョンを作成する主な動機は、MQL5における特徴量移行の問題に対応するためでしたが、特徴量選択やデータのラベル付け、データ拡張といった操作をPythonで処理する方が、私にとっては依然として遥かに効率的で便利です。
PythonのMQL5ライブラリは不当に過小評価されていると感じています。利用者が少ないのは事実ですが、このライブラリは、見た目にも財布にも嬉しい、優れたモデルを作成するために使用できる強力なソリューションです。
また、将来的には、実際の取引所(CMEやMOEX)における市場深度の履歴データから学習するバージョンも実装したいと考えています。これも有望な取り組みであり、さらなる改善が期待できる分野です。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14910
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ユージン、あなたの記事を読んで、MLについて勉強し始めました。
以下の点について教えてください。
label_data 関数がデータを処理した後、その量は大幅に減少します(関数の条件を満たすバーのランダムな セットを取得します)。その後、データはいくつかの関数を経て、訓練サンプルとテストサンプルに分けられます。モデルは訓練サンプルで学習される。その後、テストサンプルから['labels']列を取り除き、その値を予測してモデルを推定します。テストデータには概念の置き換えはないのでしょうか?結局のところ、テストにはlabel_data 関数を通過したデータ(つまり、将来のデータを考慮する関数によって事前に選択された非連続バーのセット)を使用します。そして、テスターにはパラメータ10があり、私が理解するところでは、何本のバーで取引を終了させるかを担当するはずですが、非連続的なバーのセットを持っているため、何が得られるかは明らかではありません。
次のような疑問が生じます:どこが間違っているのか?なぜすべてのバー >= FORWARD をテストに使用しないのですか?また、すべてのバー >= FORWARD を使用しない場合、将来を知らずに予測に必要なバーをどのように選択できますか?
ありがとうございます。
とても興味深く、実践的で地に足の着いた素晴らしい仕事だ。結果が伴わない理論だけでなく、これほど優れた実例が掲載された記事はなかなかお目にかかれない。あなたの仕事と分かち合いに心から感謝します。
本当にありがとう!そうですね、ONNXへの翻訳を含む今回のアイデアの拡張を含め、この先もまだ多くのアイデアが実装されることでしょう)
重大な欠陥
改善のための提言