
Sviluppo di un robot in Python e MQL5 (parte 2): Selezione, creazione e addestramento del modello, tester personalizzato in Python

Breve riassunto dell'articolo precedente
Nell'articolo precedente abbiamo parlato un po' di apprendimento automatico, abbiamo eseguito l'incremento dei dati, sviluppato le caratteristiche per il futuro modello e selezionato le migliori. Ora è il momento di andare avanti e creare un modello di apprendimento automatico funzionante che apprenda dalle nostre caratteristiche e faccia trading (si spera con successo). Per valutare il modello, scriveremo un tester Python personalizzato che ci aiuterà a valutare le prestazioni del modello e la bellezza dei grafici di prova. Per ottenere grafici di prova più belli e una maggiore stabilità del modello, svilupperemo anche una serie di funzionalità classiche dell'apprendimento automatico.
Il nostro obiettivo finale è creare un modello funzionante e profittevole al massimo per la previsione dei prezzi e il trading. Tutto il codice sarà in Python, includendo la libreria MQL5.
Versione di Python e moduli richiesti
Nel mio lavoro ho utilizzato la versione 3.10.10 di Python. Il codice allegato di seguito contiene diverse funzioni per la preelaborazione dei dati, l'estrazione delle caratteristiche e l'addestramento di un modello di apprendimento automatico. In particolare, include:
- La funzione per il raggruppamento (clustering) delle caratteristiche utilizzando Gaussian Mixture Model (GMM) dalla libreria sklearn
- La funzione di estrazione delle caratteristiche utilizzando la funzione Recursive Feature Elimination con Cross-Validation (RFECV) della libreria sklearn
- La funzione per l'addestramento, il classificatore XGBoost
Per eseguire il codice, è necessario installare i seguenti moduli Python:
- pandas
- numpy
- sklearn
- xgboost
- matplotlib
- seaborn
- MetaTrader 5
- tqdm
È possibile installarli utilizzando "pip", l'utilità di installazione dei pacchetti Python. Ecco un esempio di comando per installare tutti i moduli richiesti:
pip install pandas numpy sklearn xgboost matplotlib seaborn tqdm MetaTrader5
Andiamo!
Classificazione o regressione?
Questa è una delle domande eterne della previsione dei dati. La classificazione è più adatta per problemi binari in cui è necessaria una risposta chiara del tipo sì-no. Esiste anche una classificazione multiclasse. Ne parleremo nei prossimi articoli della serie, poiché può rafforzare in modo significativo i modelli.
La regressione è adatta per una previsione specifica di un certo valore futuro di una serie continua, compresa una serie di prezzi. Da un lato, questo può essere molto più conveniente, ma dall'altro l'etichettatura dei dati per la regressione, proprio come le etichette stesse, è un argomento impegnativo, perché c'è poco da fare se non prendere il prezzo futuro dell'asset.
Personalmente preferisco la classificazione perché semplifica il lavoro con l'etichettatura dei dati. Molte cose possono essere ricondotte a condizioni sì-no, mentre la classificazione multiclasse può essere applicata a interi sistemi di trading manuale complessi come Smart Money. Avete già visto il codice di etichettatura dei dati nel precedente articolo della serie ed è chiaramente adatto alla classificazione binaria. Ecco perché prenderemo questo particolare modello di struttura.
Resta da decidere il modello stesso.
Selezione di un modello di classificazione
Dobbiamo selezionare un modello di classificazione adatto ai nostri dati con le caratteristiche selezionate. La scelta dipende dal numero di caratteristiche, dai tipi di dati e dal numero di classi.
I modelli più diffusi sono la regressione logistica per la classificazione binaria, la foresta casuale per le dimensioni elevate e le non linearità, le reti neurali per i problemi complessi. La scelta è enorme. Dopo aver provato molte cose, sono giunto alla conclusione che nelle condizioni attuali il più efficace è il boosting e i modelli basati su di esso.
Ho deciso di utilizzare il modernissimo modello XGBoost - boosting su alberi decisionali con regolarizzazione, parallelismo e molte impostazioni. XGBoost vince spesso le competizioni di scienza dei dati grazie alla sua elevata precisione. Questo è diventato il criterio principale per la scelta del modello.
Generazione del codice del modello di classificazione
Il codice utilizza il modernissimo modello XGBoost - gradient boosting su alberi decisionali. Una caratteristica speciale di XGBoost è l'uso delle derivate seconde per l'ottimizzazione, che aumenta l'efficienza e la precisione rispetto ad altri modelli.
La funzione train_xgboost_classifier riceve i dati e il numero di cicli di boosting. Suddivide i dati in caratteristiche X ed etichette y, crea il modello XGBClassifier con la regolazione degli iperparametri e lo addestra con il metodo fit().
I dati vengono suddivisi in training/test, il modello viene addestrato sui dati di training utilizzando la funzione. Il modello viene testato sui dati rimanenti e viene calcolata l'accuratezza delle previsioni.
I principali vantaggi di XGBoost sono la combinazione di modelli multipli in uno altamente accurato, utilizzando il gradient boosting e ottimizzando le derivate seconde per garantire l'efficienza.
Per utilizzarlo, è necessario installare la libreria di runtime OpenMP. Per Windows, è necessario scaricare il Microsoft Visual C++ Redistributable corrispondente alla versione di Python in uso.
Passiamo al codice vero e proprio. All'inizio del codice, importiamo la libreria xgboost nel modo seguente:
import xgboost as xgb Il resto del codice:
import xgboost as xgb def train_xgboost_classifier(data, num_boost_rounds=500): # Check if data is not empty if data.empty: raise ValueError("Data should not be empty") # Check if all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check if all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create an XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Test the model on all data train_data = raw_data[raw_data.index <= FORWARD] # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate prediction accuracy accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Addestriamo il modello e vediamo l'accuratezza al 52%.
La nostra precisione di classificazione è ora pari al 53% delle etichette profittevoli. Notare che qui stiamo parlando di situazioni di previsione quando il prezzo è cambiato di più del take profit (200 pip) e non ha toccato lo stop (100 pip) con la sua coda. In pratica, avremo un fattore di profitto di circa tre, che è abbastanza sufficiente per un trading profittevole. Il passo successivo è la scrittura di un tester personalizzato in Python per analizzare la redditività dei modelli in USD (non in punti). È necessario capire se il modello sta guadagnando tenendo conto del markup o se sta prosciugando i fondi.
Implementazione della funzione del tester personalizzato in Python
def test_model(model, X_test, y_test, markup, initial_balance=10000.0, point_cost=0.00001): balance = initial_balance trades = 0 profits = [] # Test the model on the test data predicted_labels = model.predict(X_test) for i in range(len(predicted_labels) - 48): if predicted_labels[i] == 1: # Open a long position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price > entry_price + markup: # Close the long position with profit profit = (exit_price - entry_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the long position with loss loss = (entry_price - exit_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) elif predicted_labels[i] == 0: # Open a short position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price < entry_price - markup: # Close the short position with profit profit = (entry_price - exit_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the short position with loss loss = (exit_price - entry_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) # Calculate the cumulative profit or loss total_profit = balance - initial_balance # Plot the balance change over the number of trades plt.plot(range(trades), [balance + sum(profits[:i]) for i in range(trades)]) plt.title('Balance Change') plt.xlabel('Trades') plt.ylabel('Balance ($)') plt.xticks(range(0, len(X_test), int(len(X_test)/10)), X_test.index[::int(len(X_test)/10)].strftime('%Y-%m-%d')) # Add dates to the x-axis plt.axvline(FORWARD, color='r', linestyle='--') # Add a vertical line for the FORWARD date plt.show() # Print the results print(f"Cumulative profit or loss: {total_profit:.2f} $") print(f"Number of trades: {trades}") # Get test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] # Test the model with markup and target labels initial_balance = 10000.0 markup = 0.00001 test_model(xgb_clf, X_test, y_test, markup, initial_balance)
Il codice crea una funzione per testare il modello di apprendimento automatico su dati di prova e analizzare la sua profittabilità tenendo conto del markup (questo dovrebbe includere le perdite sugli spread e vari tipi di commissioni). Gli swap non sono presi in considerazione, poiché sono dinamici e dipendono dai tassi di riferimento. Possono essere considerati semplicemente aggiungendo un paio di pips al markup.
La funzione riceve un modello, i dati di prova, il markup e il saldo iniziale. Il trading è simulato utilizzando le previsioni del modello: long a 1, short a 0. Se il profitto supera il markup, la posizione viene chiusa e il profitto viene aggiunto al saldo.
Vengono salvati i trade e i profitti/perdite di ogni posizione. Viene costruito il diagramma del saldo. Viene calcolato il profitto/perdita totale accumulato.
Alla fine, otteniamo i dati di prova e rimuoviamo le colonne non necessarie. Il modello xgb_clf addestrato viene testato con il markup e il saldo iniziale indicato. Mettiamolo alla prova!

Il tester funziona complessivamente con successo e vediamo un bellissimo grafico di redditività. Si tratta di un tester personalizzato per analizzare la profittabilità di un modello di trading di apprendimento automatico tenendo conto di markup ed etichette.
Implementazione della convalida incrociata nel modello
È necessario utilizzare la convalida incrociata per ottenere una valutazione più affidabile della qualità di un modello di apprendimento automatico. La convalida incrociata consente di valutare un modello su più sottoinsiemi di dati, evitando così l'overfitting e fornendo una valutazione più obiettiva.
Nel nostro caso, utilizzeremo una convalida incrociata di 5 volte per valutare il modello XGBoost. Per farlo, utilizzeremo la funzione cross_val_score della libreria sklearn.
Modifichiamo il codice della funzione train_xgboost_classifier come segue:
def train_xgboost_classifier(data, num_boost_rounds=500): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data using cross-validation scores = cross_val_score(clf, X, y, cv=5) # Calculate the mean accuracy of the predictions accuracy = scores.mean() print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Train the model on the data without cross-validation clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Accuracy: {accuracy:.2f}")
Durante l'addestramento del modello, la funzione train_xgboost_classifier esegue una convalida incrociata a 5 volte e fornisce l'accuratezza media della previsione. L’addestramento comprenderà comunque il campione fino alla data FORWARD.
La convalida incrociata viene utilizzata solo per valutare il modello, non per addestrarlo. L'addestramento viene eseguito su tutti i dati fino alla data FORWARD, senza convalida incrociata.
La convalida incrociata consente una valutazione più affidabile e oggettiva della qualità del modello, che in teoria ne aumenterà la robustezza sui nuovi dati dei prezzi. Oppure no? Controlliamo e vediamo come funziona il tester.
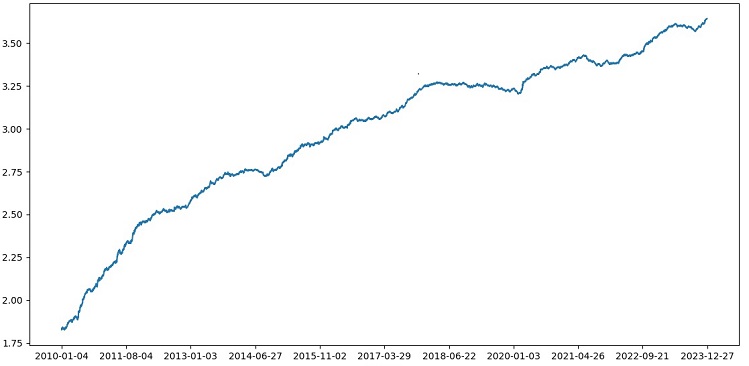
Il test di XGBoost con convalida incrociata sui dati del periodo 1990-2024 ha prodotto un'accuratezza del 56% sul test dopo il 2010. Il modello ha mostrato una buona robustezza ai nuovi dati al primo tentativo. Anche la precisione è migliorata parecchio, il che è una buona notizia.
Ottimizzazione degli iperparametri del modello su una griglia
L'ottimizzazione degli iperparametri è una fase importante nella creazione di un modello di apprendimento automatico per massimizzarne l'accuratezza e le prestazioni. È simile all'ottimizzazione degli EA MQL5, ma immaginate che al posto di un EA ci sia un modello di apprendimento automatico. Utilizzando la ricerca a griglia, si trovano i parametri che funzioneranno meglio.
Esaminiamo l'ottimizzazione degli iperparametri di XGBoost basata sulla griglia utilizzando Scikit-learn.
Utilizzeremo GridSearchCV di Scikit-learn per effettuare una convalida incrociata del modello su tutti i set di iperparametri della griglia. Verrà selezionato il set con l'accuratezza media più elevata nella convalida incrociata.
Codice di ottimizzazione:
from sklearn.model_selection import GridSearchCV
# Define the grid of hyperparameters
param_grid = {
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.1, 0.3, 0.5],
'n_estimators': [100, 500, 1000]
}
# Create XGBoost model
clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1)
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best hyperparameters:", grid_search.best_params_)
# Print the mean accuracy of the predictions on cross-validation for the best hyperparameters
print("Mean prediction accuracy on cross-validation:", grid_search.best_score_)
Qui definiamo una griglia di iperparametri param_grid, creiamo il modello XGBoost clf e cerchiamo gli iperparametri ottimali sulla griglia usando il metodo GridSearchCV. Si ottengono quindi i migliori iperparametri grid_search.best_params_ e l'accuratezza media della previsione nella convalida incrociata grid_search.best_score_.
Notare che in questo codice utilizziamo la convalida incrociata per ottimizzare gli iperparametri. Questo ci permette di ottenere una valutazione più affidabile e oggettiva della qualità del modello.
Dopo l'esecuzione di questo codice, si ottengono i migliori iperparametri per il nostro modello XGBoost e l'accuratezza media della previsione sulla convalida incrociata. Possiamo quindi addestrare il modello su tutti i dati utilizzando i migliori iperparametri e testarlo su nuovi dati.
Pertanto, l'ottimizzazione degli iperparametri del modello su una griglia è un compito importante quando si creano modelli di apprendimento automatico. Utilizzando il metodo GridSearchCV della libreria Scikit-learn, possiamo automatizzare questo processo e trovare i migliori iperparametri per un determinato modello e dati.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 5, 7, 10], 'learning_rate': [0.05, 0.1, 0.2, 0.3, 0.5], 'n_estimators': [50, 100, 600, 1200, 2000] } # Train the model on the data using cross-validation and grid search grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Return the trained model with the best hyperparameters return grid_search.best_estimator_
Ensembling di modelli
È ora di rendere il nostro modello ancora più cool e migliore! L'ensembling di modelli è un approccio potente nell'apprendimento automatico che combina più modelli per migliorare l'accuratezza della previsione. I metodi più diffusi includono il bagging (creazione di modelli su diversi sottocampioni di dati) e il boosting (addestramento sequenziale di modelli per correggere gli errori di quelli precedenti).
Nel nostro compito, utilizziamo l'ensemble XGBoost con bagging e boosting. Creiamo diversi XGBoost addestrati su diversi sottocampioni e combiniamo le loro previsioni. Ottimizziamo anche gli iperparametri di ciascun modello con GridSearchCV.
Vantaggi dell'ensembling: maggiore accuratezza, riduzione della varianza, miglioramento della qualità complessiva del modello.
La funzione finale di addestramento del modello utilizza la convalida incrociata, l'ensembling e la selezione degli iperparametri con grid bagging.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Missing required columns in data: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 7, 12], 'learning_rate': [0.1, 0.3, 0.5], 'n_estimators': [100, 600, 1200] } # Train the model on the data using cross-validation and hyperparameter tuning grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean accuracy on cross-validation: {accuracy:.2f}") # Return the trained model return grid_search.best_estimator_ labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Test data test_data = raw_data[raw_data.index <= EXAMWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Implementare l'ensemble di modelli attraverso il bagging, eseguire il test e ottenere il seguente risultato:
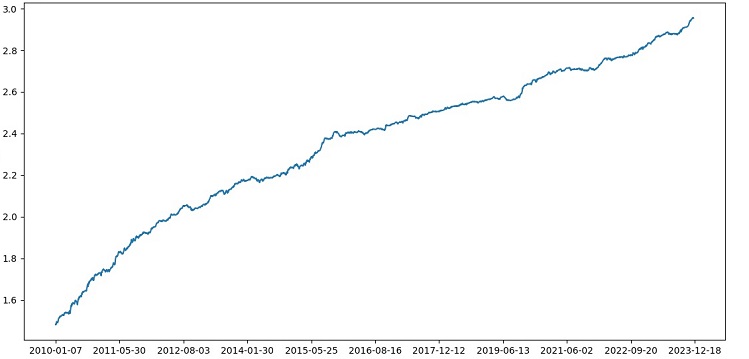
L'accuratezza della classificazione delle operazioni con un rapporto rischio/rendimento di 1:8 è aumentata al 73%. In altre parole, l'ensembling e la ricerca a griglia ci hanno dato un enorme spinta all'accuratezza della classificazione rispetto alla versione precedente del codice. Lo considero un risultato più che eccellente, e dai precedenti grafici delle prestazioni del modello nella sezione forward, si capisce chiaramente quanto si sia rafforzato durante l'evoluzione del codice.
Implementazione del campione d'esame e test della robustezza del modello
Ora utilizzo i dati dopo la data EXAMWARD per il test. Questo mi permette di testare le prestazioni del modello su dati completamente nuovi che non sono stati utilizzati ne per addestrare ne per testare il modello. In questo modo posso valutare oggettivamente come funzionerà il modello in condizioni reali.
Il test su un campione d'esame è un passo importante nella validazione di un modello di apprendimento automatico. Questo assicura che il modello si comporti bene su nuovi dati e dà un'idea delle sue prestazioni nel mondo reale. In questo caso è necessario determinare correttamente la dimensione del campione e assicurarsi che sia rappresentativo.
Nel mio caso, utilizzo i dati post-EXAMWARD per testare il modello su dati completamente sconosciuti al di fuori dell’addestramento e del test. In questo modo ottengo una valutazione oggettiva dell'efficienza del modello e della sua idoneità all'uso reale.
Ho condotto l’addestramento sui dati del periodo 2000-2010, il test sul periodo 2010-2019, l'esame dal 2019. L'esame simula il trading in un futuro sconosciuto.
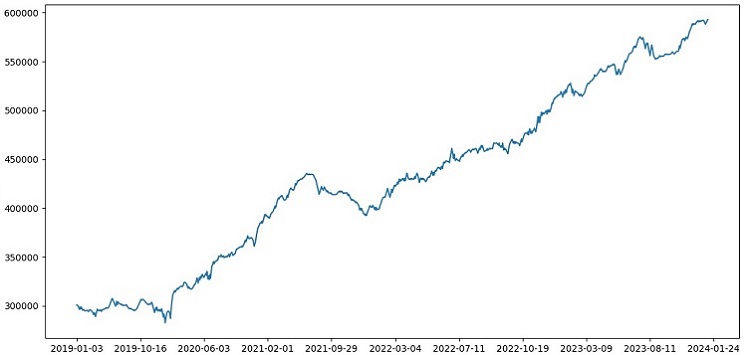
Nel complesso, tutto sembra buono. L'accuratezza dell'esame è scesa al 60%, ma l'aspetto principale è che il modello è redditizio e abbastanza robusto, pur non avendo forti drawdown. È positivo che il modello apprenda il concetto di rischio/rendimento - prevede situazioni con basso rischio e alto profitto potenziale (usiamo un rapporto rischio/rendimento di 1:8).
Conclusioni
Questo conclude il secondo articolo della serie sulla creazione di un robot di trading in Python. Al momento, siamo riusciti a risolvere i problemi di lavoro con i dati, di lavoro con le caratteristiche, i problemi di selezione e persino di generazione delle caratteristiche, nonché il problema della selezione e dell'addestramento di un modello. Abbiamo anche implementato un tester personalizzato che testa il modello e sembra che tutto funzioni abbastanza bene. Tra l'altro, ho provato altre caratteristiche, comprese quelle più semplici, cercando di semplificare i dati senza successo. I modelli con queste caratteristiche hanno prosciugato il conto nel tester. Questo conferma ancora una volta che le caratteristiche e i dati non sono meno importanti del modello stesso. Possiamo creare un buon modello e applicare vari miglioramenti e metodi, ma se le caratteristiche sono inutili, allora prosciugherà senza vergogna il nostro deposito su dati sconosciuti. Al contrario, con buone caratteristiche, è possibile ottenere un risultato stabile anche con un modello mediocre.
Successivi sviluppi
In futuro, ho intenzione di creare una versione personalizzata del trading online nel terminale MetaTrader 5 per operare direttamente attraverso Python, per aumentare la convenienza. Dopo tutto, il mio incentivo iniziale a creare una versione specifica per Python è stato il problema di trasferire le caratteristiche a MQL5. Per me è ancora molto più veloce e comodo gestire le caratteristiche, la loro selezione, l'etichettatura dei dati e l'incremento dei dati in Python.
Credo che la libreria MQL5 per Python sia ingiustamente sottovalutata. È chiaro che poche persone la usano. Si tratta di una soluzione potente che può essere utilizzata per creare modelli veramente belli e piacevoli sia per l'occhio che per il portafoglio!
Mi piacerebbe anche implementare una versione che impari dai dati storici della profondità di mercato di una borsa reale - CME o MOEX. Anche questo è un progetto promettente.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/14910
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Eugene, grazie ai tuoi articoli ho iniziato a studiare il ML in relazione al trading, ti ringrazio molto per questo.
Potresti spiegare i seguenti punti.
Dopo che la funzione label_data elabora i dati, il loro volume viene notevolmente ridotto ( otteniamo un insieme casuale di barre che soddisfano le condizioni della funzione). Quindi i dati passano attraverso diverse funzioni e vengono suddivisi in campioni di addestramento e di prova. Il modello viene addestrato sul campione di addestramento. Successivamente, le colonne ['etichette'] vengono rimosse dal campione di prova e cerchiamo di prevedere i loro valori per stimare il modello. Non ci sono sostituzioni di concetti nei dati di test? Dopotutto, per i test utilizziamo dati che hanno superato la funzione label_data (cioè un insieme di barre non sequenziali selezionate in anticipo da una funzione che tiene conto dei dati futuri). E poi nel tester c'è il parametro 10, che, a quanto ho capito, dovrebbe essere responsabile di quante barre chiudere l'operazione, ma poiché abbiamo un insieme di barre non sequenziali, non è chiaro cosa otteniamo.
Sorgono le seguenti domande: Dove sbaglio? Perché non vengono utilizzate tutte le barre >= FORWARD per i test? E se non utilizziamo tutte le barre >= AVANTI, come possiamo scegliere le barre necessarie per la previsione senza conoscere il futuro?
Grazie.
Ottimo lavoro, molto interessante, pratico e concreto. È difficile vedere un articolo così bello con esempi reali e non solo teoria senza risultati. Grazie mille per il tuo lavoro e la tua condivisione, seguirò e aspetterò con ansia questa serie.
Grazie mille! Sì, ci sono ancora molte implementazioni di idee da fare, compresa l'espansione di questa con la traduzione in ONNX).
Difetti critici:
Raccomandazioni per il miglioramento: