
Python과 MQL5로 로봇 개발하기(2부): 모델 선택, 생성 및 훈련, Python 사용자 지정 테스터

이전 글에 대한 간략한 요약
이전 기사에서 우리는 머신 러닝에 대해 조금 알아보고, 데이터 증강을 수행하고, 미래 모델을 위한 피처를 개발하고, 그 중 가장 좋은 것을 선택했습니다. 이제 다음 단계로 넘어가서 우리의 피처를 학습하고 (성공적으로) 거래할 수 있도록 작동하는 머신러닝 모델을 만들어야 할 때입니다. 모델을 평가하기 위해 우리는 모델의 성능과 테스트 그래프의 아름다운 모습을 평가하는 데 도움이 되는 사용자 정의 Python 테스터를 작성할 것입니다. 더욱 아름다운 테스트 그래프는 물론 모델 안정성을 높이기 위해 여러 가지 고전적인 머신 러닝 기능도 함께 개발할 것입니다.
우리의 궁극적인 목표는 가격을 예측하여 거래를 하기 위해 수익성을 극대화하는 모델을 만드는 것입니다. 모든 코드는 MQL5 라이브러리가 포함된 파이썬으로 작성됩니다.
파이썬 버전 및 필수 모듈
제 작업에는 파이썬 버전 3.10.10을 사용했습니다. 아래에 첨부된 코드에는 데이터 전처리, 피처 추출, 머신 러닝 모델 훈련을 위한 몇 가지 함수가 포함되어 있습니다. 특히 다음이 포함됩니다:
- sklearn 라이브러리의 가우스 혼합 모델(GMM)을 사용한 특징 클러스터링 함수
- sklearn 라이브러리에서 교차 검증을 통한 재귀적 피처 제거(RFECV)를 사용한 피처 추출 함수
- XGBoost 분류기 훈련 함수
코드를 실행하려면 다음과 같은 Python 모듈을 설치해야 합니다:
- pandas
- numpy
- sklearn
- xgboost
- matplotlib
- seaborn
- MetaTrader 5
- tqdm
파이썬 패키지 설치 유틸리티인 'pip'를 사용하여 설치할 수 있습니다. 다음은 필요한 모든 모듈을 설치하는 예제 명령어입니다:
pip install pandas numpy sklearn xgboost matplotlib seaborn tqdm MetaTrader5
해 봅시다!
분류 또는 회귀?
이것은 데이터 예측의 영원한 질문 중 하나입니다. 분류는 명확한 예/아니오 답변이 필요한 이진형 문제에 더 적합합니다. 다중 클래스 분류도 있습니다. 모델을 크게 강화할 수 있습니다. 이는 이후의 시리즈 기사에서 다룰 것입니다.
회귀는 가격 계열을 포함한 연속형 계열의 특정 미래 값을 예측하는 데 적합합니다. 한편으로 회귀는 훨씬 더 편리할 수 있지만 다른 한편으로는 회귀를 위한 데이터 레이블링은 레이블 자체와 마찬가지로 자산의 미래 가격을 취하는 것 외에는 할 수 있는 일이 거의 없기 때문에 까다로운 주제입니다.
저는 개인적으로 분류를 더 좋아하는데 분류는 데이터 레이블링 작업을 간소화하기 때문입니다. 많은 것들이 예-아니요 조건으로 구동될 수 있으며 다중 클래스 분류는 스마트 머니와 같은 복잡한 수동 거래 시스템 전체에 적용할 수 있습니다. 이 시리즈의 이전 글에서 데이터 레이블링 코드를 이미 보셨을 것입니다. 이 코드는 이진 분류에 매우 적합합니다. 그렇기 때문에 우리는 이 특정 모델 구조를 취할 것입니다.
모델 자체를 결정할 일이 아직 남아 있습니다.
분류 모델 선택
우리는 선택한 피처로 데이터에 적합한 분류 모델을 선택해야 합니다. 선택은 피처 수, 데이터 유형 및 클래스 수에 따라 달라지며
이진 분류를 위한 로지스틱 회귀, 고차원 및 비선형성을 위한 랜덤 포레스트, 복잡한 문제를 위한 신경망 등이 널리 사용되는 모델입니다. 선택의 폭이 넓습니다. 많은 것을 시도해 본 결과 저는 오늘날 가장 효과적인 것은 부스팅과 이를 기반으로 한 모델이라는 결론에 도달했습니다.
저는 정규화, 병렬 처리 및 다양한 설정으로 의사 결정 트리를 부스트하는 최첨단 XGBoost 모델을 사용하기로 결정했습니다. XGBoost는 높은 정확도 덕분에 데이터 과학 경연 대회에서 종종 우승합니다. 이것이 모델 선택의 주요 기준이 되었습니다.
분류 모델 코드 생성
이 코드는 의사 결정 트리를 통한 경사 부스팅인 최첨단 XGBoost 모델을 사용합니다. XGBoost의 특별한 피처는 최적화를 위해 두 번째 파생물을 사용하며 이를 통해 다른 모델에 비해 효율성과 정확성을 높입니다.
train_xgboost_classifier 함수는 데이터와 부스팅 라운드 수를 수신합니다. 이 함수는 데이터를 X 피처와 Y 레이블로 분할하고 하이퍼파라미터 튜닝을 통해 XGBClassifier 모델을 생성한 후 fit() 메서드를 사용하여 학습시킵니다.
데이터는 훈련/테스트로 나뉘며 함수를 사용하여 훈련 데이터에서 모델을 훈련시킵니다. 남은 데이터에서 모델이 테스트 되고 예측의 정확도가 계산됩니다.
XGBoost의 주요 장점은 경사 부스팅을 사용하여 여러 모델을 매우 정확한 모델로 결합하고 효율성을 위해 두 번째 파생물에 최적화하는 것입니다.
이를 사용하려면 OpenMP 런타임 라이브러리를 설치해야 합니다. Windows의 경우 파이썬 버전과 일치하는 Microsoft Visual C++ 재배포판을 다운로드해야 합니다.
코드로 넘어가 보겠습니다. 코드의 시작 부분에서 다음과 같은 방법으로 xgboost 라이브러리를 임포트 합니다:
import xgboost as xgb 나머지 코드입니다:
import xgboost as xgb def train_xgboost_classifier(data, num_boost_rounds=500): # Check if data is not empty if data.empty: raise ValueError("Data should not be empty") # Check if all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check if all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create an XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Test the model on all data train_data = raw_data[raw_data.index <= FORWARD] # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate prediction accuracy accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
모델을 학습시키고 정확도가 52%인 것을 확인해 보겠습니다.
현재 수익성 있는 레이블의 분류 정확도는 53%에 달합니다. 우리는 가격이 테이크프로핏(200핍) 이상 변동하고 꼬리가 스톱(100핍)에 닿지 않은 상황을 예측하는 것에 대해 이야기하고 있다는 점에 유의하시기 바랍니다. 실제로는 약 3의 수익률을 가지며 이는 수익성 있는 트레이딩을 하기에 충분합니다. 다음 단계는 파이썬으로 사용자 지정 테스터를 작성하여 모델의 수익성을 포인트가 아닌 달러로 분석하는 것입니다. 마크업을 고려하여 모델이 수익을 창출하고 있는지 아니면 자금을 낭비하고 있는지 파악할 필요가 있습니다.
custom tester 함수 구현하기
def test_model(model, X_test, y_test, markup, initial_balance=10000.0, point_cost=0.00001): balance = initial_balance trades = 0 profits = [] # Test the model on the test data predicted_labels = model.predict(X_test) for i in range(len(predicted_labels) - 48): if predicted_labels[i] == 1: # Open a long position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price > entry_price + markup: # Close the long position with profit profit = (exit_price - entry_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the long position with loss loss = (entry_price - exit_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) elif predicted_labels[i] == 0: # Open a short position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price < entry_price - markup: # Close the short position with profit profit = (entry_price - exit_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the short position with loss loss = (exit_price - entry_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) # Calculate the cumulative profit or loss total_profit = balance - initial_balance # Plot the balance change over the number of trades plt.plot(range(trades), [balance + sum(profits[:i]) for i in range(trades)]) plt.title('Balance Change') plt.xlabel('Trades') plt.ylabel('Balance ($)') plt.xticks(range(0, len(X_test), int(len(X_test)/10)), X_test.index[::int(len(X_test)/10)].strftime('%Y-%m-%d')) # Add dates to the x-axis plt.axvline(FORWARD, color='r', linestyle='--') # Add a vertical line for the FORWARD date plt.show() # Print the results print(f"Cumulative profit or loss: {total_profit:.2f} $") print(f"Number of trades: {trades}") # Get test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] # Test the model with markup and target labels initial_balance = 10000.0 markup = 0.00001 test_model(xgb_clf, X_test, y_test, markup, initial_balance)
이 코드는 테스트 데이터에 대해 머신러닝 모델을 테스트하고 마크업을 고려하여 수익성을 분석하는 함수를 생성합니다(여기에는 스프레드 및 다양한 유형의 수수료 등이 손실이 포함되어야 합니다). 스왑은 동적이며 주요 환율에 따라 달라지므로 고려되지 않으나 마크업에 몇 핍만 추가하면 이를 고려할 수 있습니다.
이 함수는 모델, 테스트 데이터, 마크업 및 초기 잔고를 받습니다. 거래는 모델 예측을 사용하여 시뮬레이션 됩니다(1에서 매수, 0에서 매도). 수익이 마크업을 초과하면 포지션이 청산되고 수익이 잔고에 추가됩니다.
각 포지션의 거래 및 수익/손실이 저장됩니다. 잔고 차트가 작성됩니다. 누적된 총 수익/손실이 계산됩니다.
마지막으로 테스트 데이터를 얻고 불필요한 열을 제거합니다. 학습된 xgb_clf 모델은 주어진 마크업과 초기 잔고로 테스트됩니다. 이제 테스트해 봅시다!

테스터는 전반적으로 성공적으로 작동하며 아름다운 수익성 그래프를 보여줍니다. 이것은 마크업과 레이블을 고려한 머신러닝 트레이딩 모델의 수익성을 분석하기 위한 맞춤형 테스터입니다.
모델에 교차 검증 구현하기
머신러닝 모델의 품질에 대한 보다 신뢰할 수 있는 평가를 얻으려면 교차 검증을 사용해야 합니다. 교차 검증을 사용하면 여러 데이터 하위 집합에서 모델을 평가할 수 있으며 이는 과적합을 방지하고 보다 객관적인 평가를 제공하는 데 도움이 됩니다.
우리의 경우 5배 교차 검증을 사용하여 XGBoost 모델을 평가할 것입니다. 이를 위해 우리는 sklearn 라이브러리의 cross_val_score 함수를 사용할 것입니다.
train_xgboost_classifier 함수의 코드를 다음과 같이 변경해 보겠습니다:
def train_xgboost_classifier(data, num_boost_rounds=500): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data using cross-validation scores = cross_val_score(clf, X, y, cv=5) # Calculate the mean accuracy of the predictions accuracy = scores.mean() print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Train the model on the data without cross-validation clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Accuracy: {accuracy:.2f}")
모델을 훈련할 때 train_xgboost_classifier 함수는 5배 교차 검증을 수행하여 평균 예측 정확도를 출력합니다. 훈련에는 FORWARD 날짜까지의 샘플이 계속 포함됩니다.
교차 검증은 모델을 평가하는 데만 사용되며 모델을 훈련하는 데는 사용되지 않습니다. 훈련은 교차 검증 없이 포워드 날짜까지의 모든 데이터에 대해 수행됩니다.
교차 검증을 통해 모델의 품질을 보다 신뢰할 수 있고 객관적으로 평가할 수 있으며 이론적으로는 새로운 가격 데이터에 대한 견고성을 높일 수 있습니다. 그렇지 않을까요? 테스터가 어떻게 작동하는지 확인해 보겠습니다.
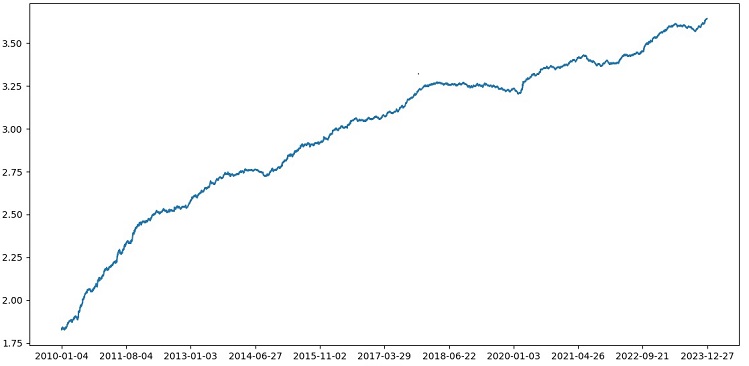
1990~2024년 데이터에 대한 교차 검증을 통해 XGBoost를 테스트한 결과 2010년 이후 테스트에서 56%의 정확도를 기록했습니다. 이 모델은 첫 번째 시도에서 새로운 데이터에 대해 우수한 견고성을 보여주었습니다. 정확도도 상당히 개선되었습니다. 좋은 소식입니다.
그리드에서 모델 하이퍼파라미터 최적화
하이퍼파라미터 최적화는 머신러닝 모델의 정확도와 성능을 극대화하도록 하기 위한 중요한 단계입니다. MQL5 EA 최적화와 비슷하지만 EA 대신 머신 러닝 모델이 있다고 생각하면 됩니다. 그리드 검색을 사용하면 결과가 가장 좋은 매개변수를 찾을 수 있습니다.
Scikit-learn을 사용한 그리드 기반 XGBoost 하이퍼파라미터 최적화에 대해 살펴보겠습니다.
그리드의 모든 하이퍼파라미터 세트에서 모델을 교차 검증하기 위해 Scikit-learn의 GridSearchCV를 사용할 것입니다. 교차 유효성 검사에서 평균 정확도가 가장 높은 세트가 선택됩니다.
최적화 코드:
from sklearn.model_selection import GridSearchCV
# Define the grid of hyperparameters
param_grid = {
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.1, 0.3, 0.5],
'n_estimators': [100, 500, 1000]
}
# Create XGBoost model
clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1)
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best hyperparameters:", grid_search.best_params_)
# Print the mean accuracy of the predictions on cross-validation for the best hyperparameters
print("Mean prediction accuracy on cross-validation:", grid_search.best_score_)
여기서는 하이퍼파라미터의 그리드 param_grid를 정의하고 XGBoost clf 모델을 생성한 다음 GridSearchCV 메서드를 사용하여 그리드에서 최적의 하이퍼파라미터를 검색합니다. 그런 다음 최상의 하이퍼파라미터 grid_search.best_params_와 평균 교차 검증 예측 정확도 grid_search.best_score_를 출력합니다.
이 코드에서는 교차 유효성 검사를 사용하여 하이퍼파라미터를 최적화합니다. 이를 통해 모델의 품질에 대한 보다 신뢰할 수 있고 객관적인 평가를 얻을 수 있습니다.
이 코드를 실행하면 XGBoost 모델에 가장 적합한 하이퍼파라미터와 교차 검증 시 평균 예측 정확도를 얻을 수 있습니다. 그런 다음 우리는 최상의 하이퍼파라미터를 사용하여 모든 데이터에 대해 모델을 훈련시키고 새로운 데이터에 대해 테스트할 수 있습니다.
따라서 머신러닝 모델을 만들 때 그리드를 통해 모델 하이퍼파라미터를 최적화하는 것은 중요한 작업입니다. Scikit-learn 라이브러리의 GridSearchCV 메서드를 사용하면 이 프로세스를 자동화하고 주어진 모델과 데이터에 가장 적합한 하이퍼파라미터를 찾을 수 있습니다.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 5, 7, 10], 'learning_rate': [0.05, 0.1, 0.2, 0.3, 0.5], 'n_estimators': [50, 100, 600, 1200, 2000] } # Train the model on the data using cross-validation and grid search grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Return the trained model with the best hyperparameters return grid_search.best_estimator_
모델 앙상블
이제 우리 모델을 더욱 멋지게 만들 시간입니다! 모델 앙상블은 예측 정확도를 향상시키기 위해 여러 모델을 결합하는 것으로 머신 러닝의 강력한 접근 방식입니다. 널리 사용되는 방법으로는 배깅(다양한 데이터 하위 샘플에 대한 모델 생성)과 부스팅(이전 모델의 오류를 수정하기 위해 순차적으로 모델을 훈련시키는 것)이 있습니다.
이 작업에서는 배깅 및 부스팅과 함께 XGBoost 앙상블을 사용합니다. 우리는 서로 다른 하위 샘플에 대해 훈련된 여러 XGBoost를 생성하고 예측을 결합합하고 각 모델의 하이퍼파라미터를 GridSearchCV로 최적화합니다.
앙상블의 이점: 정확도 향상, 분산 감소, 전반적인 모델 품질 개선.
최종 모델 훈련 함수는 교차 검증, 앙상블 및 그리드 배깅 하이퍼파라미터 선택을 사용합니다.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Missing required columns in data: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 7, 12], 'learning_rate': [0.1, 0.3, 0.5], 'n_estimators': [100, 600, 1200] } # Train the model on the data using cross-validation and hyperparameter tuning grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean accuracy on cross-validation: {accuracy:.2f}") # Return the trained model return grid_search.best_estimator_ labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Test data test_data = raw_data[raw_data.index <= EXAMWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
배깅을 통해 모델 앙상블을 구현하고 테스트를 수행하여 다음과 같은 테스트 결과를 얻습니다:

위험-보상 비율이 1:8인 거래를 분류하는 정확도가 73%로 증가했습니다. 다시 말해 앙상블과 그리드 검색을 통해 이전 버전의 코드에 비해 분류 정확도가 크게 향상되었다는 것입니다. 저는 이것이 우수한 결과라고 생각합니다. 여러분은 포워드 섹션의 모델 성능에 대한 이전 차트를 보면 코드가 진화하는 동안 얼마나 강화되었는지 명확하게 이해할 수 있을 것입니다.
검사 샘플 구현 및 모델 견고성 테스트하기
이제 EXAMWARD 이후의 데이터를 시험에 사용합니다. 이렇게 하면 모델 훈련이나 테스트에 사용되지 않은 완전히 새로운 데이터에 대해 모델 성능을 테스트할 수 있으며 모델이 실제 조건에서 어떻게 작동할지 객관적으로 평가할 수 있습니다.
시험 샘플에서 테스트 하는 것은 머신러닝 모델을 검증하는 중요한 단계입니다. 이를 통해 모델이 새로운 데이터에서 잘 작동하는지 확인하고 실제 현실에서 구현되는 성능에 대한 아이디어를 얻을 수 있습니다. 여기서 우리는 샘플의 크기를 정확하게 결정하고 이들이 대표성을 가진다는 점을 명확히 해야 합니다.
제 경우에는 훈련 및 테스트 외의 전혀 생소한 데이터에서 모델을 테스트하기 위해 EXAMWARD 이후 데이터를 사용합니다. 이렇게 하면 모델의 효율성과 실제 사용의 준비 상태를 객관적으로 평가할 수 있습니다.
2000년부터 2010년까지의 데이터에 대한 훈련, 2010년부터 2019년까지의 테스트, 2019년부터 시험에 대한 훈련을 실시했습니다. 이 시험은 미지의 미래에서 트레이딩을 시뮬레이션 합니다.
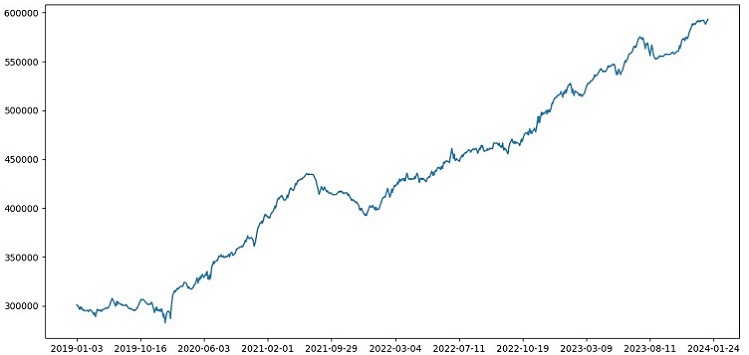
전반적으로 모든 것이 좋아 보입니다. 시험의 정확도는 60%로 떨어졌지만 가장 중요한 점은 모델이 수익성이 높고 매우 견고하면서도 큰 단점이 없다는 것입니다. 모델이 위험/보상의 개념을 학습하여 위험은 낮고 잠재적 수익은 높은 상황을 예측한다는 점이 만족스럽습니다(1:8의 위험-보상 비율 사용).
결론
이것으로 파이썬으로 트레이딩 로봇을 만드는 시리즈의 두 번째 글을 마칩니다. 현재 우리는 데이터 작업, 피처 작업, 피처의 선택 및 생성 문제, 모델 선택 및 훈련 문제를 해결했습니다. 또한 우리는 모델을 테스트하는 사용자 지정 테스터를 구현했는데 모든 것이 잘 작동하는 것 같습니다. 그런데 저는 데이터를 단순화하기 위해 가장 간단한 피처를 포함한 다른 피처들도 사용해 보았지만 아무 소용이 없었습니다. 이러한 특성을 가진 모델은 테스터의 계정을 갉아 먹었습니다. 이는 피처와 데이터가 모델 자체 만큼이나 중요하다는 것을 다시 한 번 확인시켜 줍니다. 우리는 좋은 모델을 만들고 다양한 개선과 방법을 적용할 수 있지만 피처들이 쓸모 없다면 알 수 없는 데이터에 우리의 예치금을 낭비하게 될 것입니다. 반대로 좋은 피처들을 사용하면 평범한 모델에서도 안정적인 결과를 얻을 수 있습니다.
추후 개발 사항
향후에는 파이썬을 통해 직접 거래할 수 있도록 MetaTrader 5 터미널에서 사용자 지정 버전의 온라인 트레이딩을 만들어 편의성을 높여 볼 계획입니다. 제가 파이썬 전용 버전을 만들게 된 동기는 MQL5로 피처들을 이전하는 문제점이었습니다. 저의 경우는 피처, 피처의 선택, 데이터 레이블링 및 데이터 증강을 Python으로 처리하는 것이 훨씬 더 빠르고 편리합니다.
저는 Python용 MQL5 라이브러리가 부당하게 과소평가 되고 있다고 생각합니다. 사용하는 사람이 거의 없다는 것은 분명합니다. 그러나 이 라이브러리는 사람들의 눈과 지갑을 모두 만족시키는 정말 아름다운 모델을 만드는 데 사용할 수 있는 강력한 솔루션입니다!
저는 또한 실제 거래소인 CME 또는 MOEX의 과거 시장 심도 데이터를 통해 학습하는 버전을 구현하고 싶습니다. 이 또한 유망한 시도입니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/14910
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

유진님, 트레이딩과 관련하여 ML에 대해 공부하기 시작했는데, 정말 감사합니다.
다음 사항에 대해 설명해 주시겠습니까?
label_data 함수가 데이터를 처리하면 데이터의 양이 크게 줄어듭니다(함수의 조건을 만족하는 무작위 막대 집합을 얻습니다 ). 그런 다음 데이터는 여러 함수를 거쳐 훈련 샘플과 테스트 샘플로 나뉩니다. 모델은 훈련 샘플에 대해 훈련됩니다. 그 후 테스트 샘플에서 ['레이블'] 열을 제거하고 그 값을 예측하여 모델을 추정합니다. 테스트 데이터에 개념 대체가 없나요? 결국 테스트에는 label_data 함수를 통과한 데이터 (즉, 미래 데이터를 고려하는 함수에 의해 미리 선택된 비순차 막대 집합)를 사용합니다 . 그리고 테스터에는 매개 변수 10이 있는데, 제가 알기로는 거래를 마감 할 막대 수를 담당해야하지만 순차적이지 않은 막대 세트가 있기 때문에 우리가 얻는 것이 무엇인지 명확하지 않습니다.
다음과 같은 질문이 생깁니다: 제가 어디가 틀렸나요? 왜 모든 막대 >= FORWARD가 테스트에 사용되지 않나요? 그리고 모든 막대 >= FORWARD를 사용하지 않는다면 미래를 모르는 상태에서 예측에 필요한 막대를 어떻게 선택할 수 있나요?
감사합니다.
매우 흥미롭고 실용적이며 현실적인 훌륭한 글입니다. 결과 없는 이론이 아닌 실제 사례를 통해 이렇게 좋은 기사를 보기는 어렵습니다. 작업과 공유에 정말 감사드리며, 이 시리즈를 팔로우하고 기대하겠습니다.
감사합니다! 예, ONNX로의 번역을 통해 이 아이디어를 확장하는 것을 포함하여 앞으로 많은 아이디어 구현이 남아 있습니다.)
중대한 결함:
개선 권장 사항